install Oracle 12 c and migrate data from 9i to 12 c on Solaris
HI: this is a primary control to check IAM step by step. I need to migrate the server Oracle 9i (Solaris) to 12 c (Solaris) to the customer request. I have the instruction of installation YES from the team, the draft plan is:
1. install Oracle 12 c binary on Solaris Server
2 exp/imp, method to move data to 12 c 9i.
Should I create a database "empty" by script until I use the exp/imp method to migrate data from 9i? Or, is it better to use the option 'create the single database instance' in YES during the installation of 12 c, then exp/imp? How about the "plug-in database" or the "CBD/PDB' concept to 12 c? It's still new and I am not master familiar with it, that I have to use all "CBD/PDB' 12 c or not?
Any problem that I need to know?
Thank you very much!
You have your point of disagreement, but it is the best approach of guys Upgrade Oracle, google for Mike Dietrich blogs on updates. And your concern that make upgrades does not allow you to practice, well, you could easily make a few tests on my upgrade on a test environment, I really don't agree with your point here...
Sorry - but I agree with the ground.
Anyone who still uses 9i has some questions SERIOUS architecture dealing with totally outside the DB and data. There is just too much features auxiliary available (e.g., ASM, GRID, EM) which did NOT exist in 9i or substantially changed.
It is also a non-starter, IMHO, not to recommend as an upgrade to 11g without even knowing the 9i version that uses OP. A direct upgrade to 11g is NOT possible since the first versions of 9i. So if such a version uses OP they couldn't make a direct upgrade anyway. They will need first to upgrade to the last version 9i and then level it to 11g. Then, they should adapt to 12 c.
Then you must take account of the need for BACKUP:
1. PRIOR to starting to do something
2. AFTER the upgrade to 9.2.04
3. AFTER the upgrade to 11 g
4. AFTER the upgrade to 12 c
Compare that to the approach of that ground is recommended to use export/import. There is NO need to save the source DB at all since the process will NOT change. Simply a backup after upgrading to 12 c.
Tags: Database
Similar Questions
-
original title: robocopy
I'm trying to migrate data from a server to a new one with the file permissions of the files of users and records lost. So far, that's what I did, I used \\server1\share \\server2\share/sec /mir robocopy and robocopy \\server1\share \\serve2\share/e/s /copyall. It seams like they copied all files with the permissions of the user for the files, but not files. For example, if a user makes a folder with the files in the folder appear them have permissions appropriate for them but not the root folder or subfolders, they did... How can I fix this and what is the difference between / s /mir and/e/s /copyall?
Hello
You can find the Server forums on TechNet support, please create a new post at the following link:
http://social.technet.Microsoft.com/forums/en/category/WindowsServer/
-
Need assistance to migrate data from XML to oracle table.
Hey Odie,
Im trying to insert data from an xml file into a table.
My XML file is as follows.
<? XML version = "1.0" encoding = "UTF-8" standalone = 'yes' ?>
< Ingredient > I3261 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 3.5 < / MDispensedQty >< / SubBatchDetail >
- < SubBatchDetail >< Ingredient > I3235 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 0,5 < / MDispensedQty >< / SubBatchDetail >
- < SubBatchDetail >< Ingredient > I3142 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 0,2 < / MDispensedQty >< / SubBatchDetail >
</SubBatch>
< SubBatchName > ZB97913 < / SubBatchName >< SubBatchStatus > incomplete < / SubBatchStatus >- < SubBatchDetail >< Ingredient > I3309 < / > of theingredient< DispensedQty > 0,75 < / DispensedQty >< MDispensedQty > 0,0 < / MDispensedQty >< / SubBatchDetail >
- < SubBatchDetail >< Ingredient > I3436 < / > of theingredient< DispensedQty > 0,0 < / DispensedQty >< MDispensedQty > 0,05 < / MDispensedQty >< / SubBatchDetail >
</SubBatch>
<Final>false</Final>< / TransferXML >
With the help of your previous posts I've migrated data from this xml file in a table that works perfectly well. But these data repeats instead of giving 6 lines that his return 12 lines guide please.
CREATE TABLE XXBATCH AS
SELECT A.BatchName, A.BatchStatus, B.SubBatchName, B.SubBatchStatus, C.Ingredient, C.DispensedQty, C.MDispensedQty, A.FINAL
OF (XMLTable ('/ TransferXML'))
from xmltype)
BFILENAME('APPS_DATA_FILE_DIR','HJ69240.) XML')
nls_charset_id ('AL32UTF8')
) COLUMNS
BatchName VARCHAR2 path (99) "BatchName.
, Path of the BatchStatus VARCHAR2 (999) "BatchStatus.
Path VARCHAR2 (99) final 'Final')),
(XMLTable ('/ TransferXML/SubBatch '))
from xmltype)
BFILENAME('APPS_DATA_FILE_DIR','HJ69240.) XML')
nls_charset_id ('AL32UTF8')
) COLUMNS
Path of SubBatchName VARCHAR2 (99) "SubBatch/SubBatchName".
, Path of the SubBatchStatus VARCHAR2 (99) "SubBatch/SubBatchStatus".
(B)
(XMLTable ('/ TransferXML/SubBatch/SubBatchDetail '))
from xmltype)
BFILENAME('APPS_DATA_FILE_DIR','HJ69240.) XML')
nls_charset_id ('AL32UTF8')
) COLUMNS
Path of the ingredient VARCHAR2 (99) SubBatchDetail/ingredient"."
, Path of the DispensedQty VARCHAR2 (99) "SubBatchDetail/DispensedQty".
, Path of the MDispensedQty VARCHAR2 (99) "SubBatchDetail/MDispensedQty".
(C)
I didn't test your query, but apparently it's because you have access to the same file three times instead of spend one XMLTable to another correlated nested groups.
Better, this should work:
SELECT A.BatchName
A.BatchStatus
B.SubBatchName
B.SubBatchStatus
C.Ingredient
C.DispensedQty
C.MDispensedQty
A.FINAL
FROM XMLTable ('/ TransferXML')
PASSAGE xmltype (bfilename('TEST_DIR','HJ69240.xml'), nls_charset_id ('AL32UTF8'))
Path of COLUMNS BatchName VARCHAR2 (99) "BatchName.
, Path of the BatchStatus VARCHAR2 (999) "BatchStatus.
, Path VARCHAR2 (99) final "Final."
, Path of XMLTYPE «SubBatch» SubBatchList
) AT
, XMLTable ('/ SubBatch')
PASSAGE SubBatchList
Path of COLUMNS SubBatchName VARCHAR2 (99) "SubBatchName".
, Path of the SubBatchStatus VARCHAR2 (99) "SubBatchStatus".
, Path of XMLTYPE «SubBatchDetail» SubBatchDetailList
) B
, XMLTable ('/ SubBatchDetail')
PASSAGE SubBatchDetailList
Path VARCHAR2 (99) ingredient of COLUMNS "Ingredient."
, Path of the DispensedQty VARCHAR2 (99) "DispensedQty".
, Path of the MDispensedQty VARCHAR2 (99) "MDispensedQty".
) C
;
Post edited by: odie_63
-
What is the best strategy to migrate data from Windows to one Mac to another? I use Parallels Desktop to run Windows on my current Mac but want to use Bootcamp on my new.
If it is only the data (not apps) I use Dropbox. It turned out to be the best way to move things between the side Mac and the bootcamped Windows of my iMac side. I don't see why it would not work to move data from a virtual machine installation of Win to a BootCamp installation.
-
How to migrate data from a source to multiple targets (tables)?
How to migrate data from a source to multiple targets (tables)? Describe the General steps, please or point me to a tutorial
Yes, a table in a mapping element can be source and target at the same time (i.e. a target can be reused as a source for the rest of the map on the right side of the table).
Don't forget to check the order of loading (in the property map), to ensure that the reused as source is loaded before the final table target table.
I tested it and it works. However, the documentation is not said in the link I gave you above:
"Each element of data store that has entries but no exits in the logical diagram is considered a target."
Usually, I tend not to do. I am in favour of a Divide and Conquer approach and try to have my mapping as simple as possible. It is easier to debug and maintain.
-
Prob w/Importing Favorites and other data from Internet Explorer
Everything by following the steps described in the forum article titled "Importing Favorites and other data from Internet Explorer" after completing step 3, select which points to import, if I select all the option or just the Favorites, I get the same error "Firefox has stopped working... close the program."
I am importing of IE 8 on laptop Win7 OS. I tried importing every time and cannot get past this error. I made an export of IE8 that takes the form of a html file that there is apparently no option in Firefox to use.
in Firefox:
Bookmarks > organize bookmarks-> import and backup - import HTML... = HTML file -
install esxi 4.1 and the data store on the same server
Hello
I want to install esxi 4.1 and the data store on the same server.
My problem is that I can't make partitions to really separate them and I would reinstall esxi without wiping the data store.
Y at - it another way to put a record out of the raid only to install esxi.
I also do not install on a USB key.
Thank you
AZEL says:
Hello
I want to install esxi 4.1 and the data store on the same server.
My problem is that I can't make partitions to really separate them and I would reinstall esxi without wiping the data store.
Y at - it another way to put a record out of the raid only to install esxi.
I also do not install on a USB key.
Thank you
AZEL,
Can you give us more details about your current environment? What is the size and the data store space used? Do you have any storage of additional network attached to the host (for backup purposes)?
My assumptions of your post do you have 1 stand-alone host with ESXi 4.1 aready installed and you also have a local data store on the same host, but you want to re - install ESXi 4.1 while keeping the contents fo the data store. Is this correct?
-
How to migrate data from Oracle 11.2 Standard Edition to Oracle 11 g XE Beta
Hello
Can someone help me by giving steps to migrate from Oracle 11.2 Standard Edition data to Oracle 11 g XE Beta. The database size is 6 GB.
Thank you
AshrafHello Ashraf.
use datapump (expdp/impdp).
-Udo
-
The HARD drive that was my OS (Windows XP Pro SP3) failed and lost quite a few areas which are essential for the operating system running. Other data is still readable. A got another HARD drive and installed Windows XP SP2, Firefox and other programs. I was able to retrieve the bookmarks, security certificates, and other profile information using the information found in bandages.
None of them addressed how do to recover the modules or their data. Specifically, there are several large, elegant scripts that took months to develop and customize.
Articles related to migration and other do not work for me because they require the old copy of FF is functional, that is not because the OS on this HARD drive is damaged. Is it possible to recover these data, similar (or not) about how I could get the other profile info?
Have you copied the entire folder C:\Documents and Settings\username \Application Data\Mozilla\Firefox\ on the old drive?
If this is not the case, can you?
If so, make a copy and save this folder just in case.If so, you could replace this folder on the new facility by \Profiles\ [with your profiles inside] folder and the profiles.ini file [delete all other files / folders that may also be in the folder "Firefox"] -and then replace with the same folder named from the old failed drive. Note that you will lose what you already have with the new installation / profile!
Your profile folder contains all your personal data and customizations, including looking for plugins, themes, extensions and their data / customizations - but no plugins.
But if the user logon name is different on the new facility that the former, any extension that uses an absolute path to the file in its prefs will be problems. Easily rectified, by changing the path to the file in the file prefs, js - keep the brake line formatting intact. The extensions created after the era of Firefox 2.0 or 3.0, due to changes in the 'rules' for creating extensions usually are not a problem, but some real old extensions that need only "minor" since that time can still use absolute paths - even though I have not seen myself since Firefox Firefox 3.6 or 4.0.View instead of 'Modules' I mentioned the 4 types of 'Modules' separately - Plugins are seen as 'Add-ons', but they are not installed in the profile [except those mislabelled as a "plugin", when they are installed via an XPI file], but rather in the operating system where Firefox 'find' through the registry.
Note: Migration articles can tell you do not re - use the prefs.js file, due to an issue that I feel is easily fixed with a little inspection and editing. I think you can manage that my perception is that you have a small shovel in your tool box, if you encounter a problem you are able to do a little digging and fixing problems with the paths to files - once you have been warned.
Overall, if you go Firefox 35 35 or even Firefox 34 to 35, I don't think you will run in all the problems that you can not handle [that I cross my fingers and "hope" that I'm not on what it is obvious].
With regard to the recovery of the 'data' for individual extensions - there are many ways that extension developers used to store their data and pref. The original way should save in prefs.js or their own file RDF in the profile folder. While Firefox has been developed more, developers started using their own files in the profile folder. And because Mozilla has started using sqlite database files in Firefox 3.0, Mozilla extended their own use of sqlite, as have extension developers.
Elegant uses the file stylish.sqlite to store 'styles', but something in the back of my mine tells me that 'the index' maybe not in this file with the data. But then again, I can be confusing myself a question I had with GreaseMonkey awhile back where I copied the gm_scripts folder in a new profile and with already installed GreaseMonkey but with no script. These GM scripts worked, but I could not see them or modify them - they do not appear in the user GM extension interface window in Firefox. -
global variable functional to read and write data from and to the parallel loops
Hello!
Here is the following situation: I have 3 parallel while loops. I have the fire at the same time. The first loop reads the data from GPIB instruments. Second readers PID powered analog output card (software waveform static timed, cc. Update 3 seconds interval) with DAQmx features. The third argument stores the data in the case of certain conditions to the PDM file.
I create a functional global variable (FGV) with write and read options containing the measured data (30 double CC in cluster). So when I get a new reading of the GPIB loop, I put the new values in the FGV.
In parallel loops, I read the FGV when necessary. I know that, I just create a race condition, because when one of the loops reads or writes data in the FGV, no other loops can access, while they hold their race until the loop of winner completed his reading or writing on it.
In my case, it is not a problem of losing data measured, and also a few short drapes in some loops are okey. (data measured, including the temperature values, used in the loop of PID and the loop to save file, the system also has constants for a significant period, is not a problem if the PID loop reads sometimes on values previous to the FGV in case if he won the race)
What is a "barbarian way" to make such a code? (later, I want to give a good GUI to my code, so probably I would have to use some sort of event management,...)
If you recommend something more elegant, please give me some links where I can learn more.
I started to read and learn to try to expand my little knowledge in LabView, but to me, it seems I can find examples really pro and documents (http://expressionflow.com/2007/10/01/labview-queued-state-machine-architecture/ , http://forums.ni.com/t5/LabVIEW/Community-Nugget-2009-03-13-An-Event-based-messageing-framework/m-p/... ) and really simple, but not in the "middle range". This forum and other sources of NEITHER are really good, but I want to swim in a huge "info-ocean", without guidance...

I'm after course 1 Core and Core 2, do you know that some free educational material that is based on these? (to say something 'intermediary'...)
Thank you very much!
I would use queues instead of a FGV in this particular case.
A driving force that would provide a signal saying that the data is ready, you can change your FGV readme... And maybe have an array of clusters to hold values more waiting to be read, etc... Things get complicated...
A queue however will do nicely. You may have an understanding of producer/consumer. You will need to do maybe not this 3rd loop. If install you a state machine, which has (among other States): wait for the data (that is where the queue is read), writing to a file, disk PID.
Your state of inactivity would be the "waiting for data".
The PID is dependent on the data? Otherwise it must operate its own, and Yes, you may have a loop for it. Should run at a different rate from the loop reading data, you may have a different queue or other means for transmitting data to this loop.
Another tip would be to define the State of PID as the default state and check for new data at regular intervals, thus reducing to 2 loops (producer / consumer). The new data would be shared on the wires using a shift register.
There are many tricks. However, I would not recommend using a basic FGV as your solution. An Action Engine, would be okay if it includes a mechanism to flag what data has been read (ie index, etc) or once the data has been read, it is deleted from the AE.
There are many ways to implement a solution, you just have to pick the right one that will avoid loosing data. -
Can I migrate data from PI 2.1 to clean PI 3.0 installation?
I want to skip the process of double upgrade (2.1 to 2.2 and 3.0, 2.1 to 3.0 because directly is not supported).
Can I just back up data PI2.0 and give him a new installation of PI3.0?
Thank you!
Naor.
Hi Naorel,
As per top document Cisco do not support ranging from 2.1 to 3.0 via the backup/restore or upgrade online if you don't have much choice but to go to 2.2 first.
From experience I find easier to do a side-by-side migration (by providing resources are available) and export/import the nodes and map data. It's only because a backup/restore failed completely to me a few times.
See you soon,.
Ric
-
replace a 3 years old macbook pro with a new - try to migrate data using thunderbolt cable. When the cable is plugged into laptops, its not known how to fix this?
The two Macs have a Thunderbolt port? The old Mac may have a mini displayport that is used for video only, but accepts a Thunderbolt since video Jack mini displayport is a subset of Thunderbolt.
In addition, you use a bolt of lightning and not a cable mini displayport? They look alike at first sight, but Thunderbolt should have an icon of lightning on each card.
Also, if you look in System profiler
OS X: about system information and System Profiler - Apple Support
under lightning shows as being connected?
-
Collect and display data from several workstations
Currently, the data in the CSV format locally on several workstations running Labview and the format of the recorded data is the same for each workstation. Data are recorded roughly every 2 minutes at each station and at different times.
Computers of these stations are connected network but no saves a copy of their files CSV to the server that I know is not ideal, but a part of memory original. What is now there that a computer on the network brings together these data by workstations and then the poster showing trends in workstations etc. in graphic format and possibly Excel.
What I'm looking for is some advice on the best way forward.
I looked at shared variables as a possible solution, but it is work stations send their respective data to the 'central' PC or this PC "questions" workstations that seems inefficient.
Another thought was using Active X workstations to write in an Excel file running on the "central" PC
Finally thought that workstations have record their findings to a server and then 'central' PC to access that data, it brings together and then displays the results combined.
There are several things that remains to be clarified.
- All LabVIEW programs, individual data record data in the same format and the same number of data points?
- Record all programs of LabVIEW at exactly the samerate?
- Are all data on a be saved in a single file of the Machine, or each reading (at intervals of 2 minutes) in a separate file?
- You are trying to combine data from different machines such that it is collected or after the entire collection was done, and all files have been written?
- Another that the timestamp of the data file, is there a "time stamp" in (all) the individual data files?
- If you assume that the data of different machines are more synchronized, you have in mind a way to combine the different readings of the time? What happens if they are sufficiently different that, say, the Machine has 20 readings more (because it started much earlier) than other PCs?
- If the machines are not saving at the same rate, how will handle you that?
A single method, you might consider is to write a program that works on any network connected PC, including a no participate in the recording of data. For simplicity, assume that each machine "participatant" starts at around the same time, saves exactly at the same rate, written a single data file and has already closed. If the program "Combining" knows where all data files (because he knows the name of each machine and the location of the file on each machine), it can open all the files, collect all the data and treat it but want to (including a 'combined Excel workbook"writing with a spreadsheet separate for each PC, or combining them all on one sheet). Just decide what you want to do in the context of the issues raised above.
Bob Schor
-
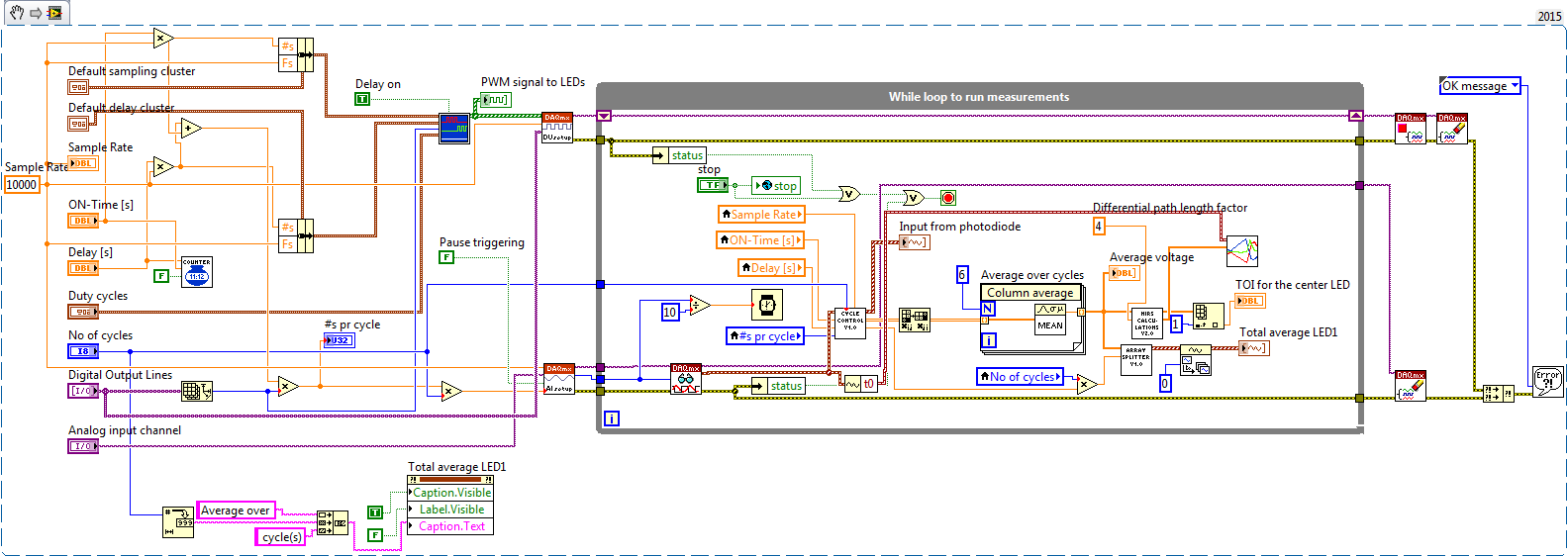
Save and write data from table to table - easy
Hello
I got this system delivered to me. I'm new to LabView and just save the data from the table "average voltage" (inside the while loop) to do some additional testing of our product.
I will like to do similar to this.
(1) save in excel file.
(2) save only when a button button and save it then 5 ilteration.
(3) save and manipulate the data, so it is displayed in 6 columns (each LED 1) instead of 1 long colum.
I tried different things with structure business T/F, which resolved the buttom-request. But I am in doubt I should use, writing to the file of the measurement or write to us to the worksheet (by using labview 15.0)-delimited according to my offer the best possible?
He also seems to be too much to handle when I try to write in txt file, because it pops up with and error that I do not know how to fix, but it says this:
Error-200279
Possible reasons:
The application is not able to cope with the acquisition of equipment.
Increase in the size of buffer, most frequently the reading of data or by specifying a fixed number of samples to read instead of reading all available samples would correct the problem.
Property: RelativeTo
Corresponding value: current playback Position
Property: Offset
Corresponding value: 0
Task name: analog channel
Thanks in advance
I agree with Taki, but want to make some additional remarks:
- LabVIEW is a data flow language. Think of the "flow" of your data. You talk about "save only when a key is pressed" and a finite set of data. You are collecting before the press the button and everything just do not save?
- Data are collected at some rate, and likely, you don't want to "Miss" data points. This means that you shouldn't do anything in the loop of the Collection that takes a long time. If your recovery rate is low and your treatment is fast, you can have everything in a single loop. Otherwise, to use the technical stream (producer/consumer is a good) to process the data in a single loop in parallel with the collection in a loop independent (and asynchronously).
- How do you write your data? You want to write "on the fly", as it is, or can you wait, collect everything, any format and then write it "all at once"?
- What do you mean by 'save the file in Excel? Do you mean a 'native' Excel file, one with the extension .xls or .xlsx? Do you mean a Comma-Separated Variable (.csv) file this reading peut of Excel (and, indeed, usually registers itself to read, change the icon of the .csv files to "look like" it is really an Excel file)? If the first case, I recommend using the report generation tool. But for the latter, you can also use write delimited spreadsheet, which can be easier to use.
Bob Schor
-
Update hard drive and transfer data from the old disk
I want to spend my hard drive in a 1 TB and the transfer of the data from my old drive again.

Thank you teacher sounds like a good plan to me.
Solutions & KUDO
Maybe you are looking for
-
Is it safe to update to the marshmallow? (Vibe P1 Turbo)
Hello, I just bought this phone and so far, it's very good. I am currently in 5.1 Lolipop, is it safe to take Marshmallow 6.0.1? Y at - it a bug? So far, I've heard there is a battery on MM drain... the drain is really bad? Thank you and sorry for a
-
Hi, I have just had my monitor (XB271HU) and follow the instructions in 'spin' on G-Sync. The thing is how to know is turned on? Windows, game mode mode (full screen) still shows blue LED. I use Geforce GTX980 Ti. Need help & thank you!
-
Impossible to uninstall programs to all the
Word, publisher, internet, etc do not open. I can't even open internet to install cleaning software. When you try to remove a program, service error 1719 windows install could not be accessed. Also a DeviceManager.exe message comes saying that it doe
-
I run Windows 7 Ultimate 64 bit, Skype, Teamviewer, client Pidgin, mIRC, Firefox, Kaspersky Internet Security 2010, openDNS updater, iTunes, and Outlook 2007. This problem has caused a unbootible machine when it happened first. It stops happening whe
-
W3C Validator has stopped working
HelloI use Dreamweaver CS6 and CC. I've been using W3C validator with no problems until today. Today whenever I ran it, I got these two messages:"You are being re-directed to a new website. Any information you exchanged with the site current could b