Is there a shorter way (better) with analytical functions?
Here's a little test scenario:create table t
( id number,
pos number,
typ number,
m number);
insert into t values (1,1,1,100);
insert into t values (1,2,1,100);
insert into t values (1,3,2, 50);
insert into t values (2,1,3, 30);
insert into t values (2,2,4, 70);
insert into t values (3,1,1,100);
insert into t values (3,2,2, 50);
insert into t values (4,1,3, 30);
insert into t values (4,2,5, 80);
insert into t values (4,3,3, 30);
insert into t values (5,1,3, 30);
insert into t values (5,2,6, 30);
insert into t values (6,1,2, 50);
insert into t values (6,2,7, 50);
insert into t values (6,3,2, 50);
insert into t values (7,1,4, 70);
insert into t values (7,2,4, 70);
insert into t values (7,3,4, 70);with t1 as
(select
id,
typ,
min(m) m1
from t
group by id, typ)
select
id,
sum(m1) f
from t1
group by id
order by 1;
ID F
---------- ----------
1 150
2 100
3 150
4 110
5 60
6 100
7 70 select
id,
sum(m) over (partition by distinct typ) F -- this does not work. It's only an idea how it might look like
from t
group by id;This is firstly a collection with the id, type with calculation of the min for each id, type the combination.
By subsequently for each id of the sum of the minutes (for each combination of id, type for this particular id) is summarized.
select distinct
id, sum(min(m)) over (partition by id)
from data
group by id, typ
order by id
Published by: chris227 on 15.03.2013 07:39
Tags: Database
Similar Questions
-
get a single result with analytical functions
SELECT delrazjn. TYPE, delrazjn. DATE, delrazjn. USER, delrazjn. The IID OF the ZKET_DR delraz, ZKET_DR_JN delrazjn
WHERE delraz. IID = delrazjn. IID
AND (delrazjn. TYPE = 'UP2' GOLD delrazjn. TYPE = 'An increase in 1') AND delrazjn. IID_N IS NOT NULL
This is an example of my sql. But there is more than one result of delrazjn. IID. How can I get the first enterd in DB and ignore others, there will only be one result and no more.
The first result came in, that I can see for delrazjn. DATE.
I try to do that with analytical functions, but without success.You're right, I told you that I can't test the code.
I hope this works now:
SELECT delrazjn.TYPE, delrazjn.DATE, delrazjn.USER, delrazjn.IID FROM ZKET_DR delraz, ZKET_DR_JN delrazjn WHERE delraz.IID = delrazjn.IID AND (delrazjn.TYPE = 'UP2' OR delrazjn.TYPE = 'UP1') AND delrazjn.IID_N IS NOT NULL and delrazjn.date=(select min(d.date) from ZKET_DR_JN d where d.type=delrazjn.type and d.user=delrazjn.user) -
Problem with analytical function for date
Hi all
ORCL worm:
Oracle Database 11 g Enterprise Edition Release 11.2.0.2.0 - 64 bit Production
PL/SQL Release 11.2.0.2.0 - Production
"CORE 11.2.0.2.0 Production."
AMT for Linux: Version 11.2.0.2.0 - Production
NLSRTL Version 11.2.0.2.0 - Production
I have a problem with the analtical for the date function. I'm trying to group records based on timestamp, but I'm failing to do.
Could you please help me find where I'm missing.
THXThis is the subquery. No issue with this. I'm just posting it for reference. select sum(disclosed_cost_allocation.to_be_paid_amt) amt, substr(reference_data.ref_code,4,10) cd, to_char(external_order_status.status_updated_tmstp, 'DD-MON-YYYY HH24:MI:SS') tmstp, DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID id FROM Deal.Fee_Mapping_Definition , Deal.Fee_Index_Definition , Deal.Fee_Closing_Cost_Item, Deal.Closing_Cost, Deal.Document_Generation_Request, deal.PRODUCT_REQUEST, deal.External_Order_Request, deal.External_Order_Status, deal. DISCLOSED_CLOSING_COST, deal.DISCLOSED_COST_ALLOCATION, deal.reference_data WHERE Fee_Mapping_Definition.Fee_Code = Fee_Index_Definition.Fee_Code AND Fee_Index_Definition.Fee_Index_Definition_Id = Fee_Closing_Cost_Item.Fee_Index_Definition_Id AND Fee_Closing_Cost_Item.Closing_Cost_Id = Closing_Cost.Closing_Cost_Id AND CLOSING_COST.PRODUCT_REQUEST_ID = Document_Generation_Request.Product_Request_Id AND closing_cost.product_request_id = product_request.product_request_id AND Product_Request.Deal_Id = External_Order_Request.Deal_Id AND external_order_request.external_order_request_id = external_order_status.external_order_request_id AND external_order_request.external_order_request_id = disclosed_closing_cost.external_order_request_id AND DISCLOSED_CLOSING_COST. DISCLOSED_CLOSING_COST_ID = DISCLOSED_COST_ALLOCATION.DISCLOSED_CLOSING_COST_ID AND Fee_Index_Definition.Fee_Index_Definition_Id = Disclosed_Closing_Cost.Fee_Index_Definition_Id AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id = Reference_Data.Reference_Data_Id AND Document_Generation_Request.Document_Package_Ref_Id IN (7392 ,2209 ) AND External_Order_Status.Order_Status_Txt = ('GenerationCompleted') AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id IN ( 7789, 7788,7596 ) AND FEE_MAPPING_DEFINITION.DOCUMENT_TYPE_REF_ID = 1099 AND Document_Generation_Request.Product_Request_Id IN (SELECT PRODUCT_REQUEST.PRODUCT_REQUEST_id FROM Deal.Disclosed_Cost_Allocation, Deal.Disclosed_Closing_Cost, DEAL.External_Order_Request, DEAL.PRODUCT_REQUEST, Deal.Scenario WHERE Disclosed_Cost_Allocation.Disclosed_Closing_Cost_Id = Disclosed_Closing_Cost.Disclosed_Closing_Cost_Id AND Disclosed_Closing_Cost.External_Order_Request_Id = External_Order_Request.External_Order_Request_Id AND External_Order_Request.Deal_Id = Product_Request.Deal_Id AND product_request.scenario_id = scenario.scenario_id AND SCENARIO.SCENARIO_STATUS_TYPE_REF_ID = 7206 AND product_request.servicing_loan_acct_num IS NOT NULL AND product_request.servicing_loan_acct_num = 0017498379 --AND Disclosed_Cost_Allocation.Disclosed_Cost_Allocation_Id = 5095263 ) GROUP BY DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID, External_Order_Status.Status_Updated_Tmstp, Reference_Data.Ref_Code, disclosed_cost_allocation.to_be_paid_amt order by 3 desc, 1 DESC; Result: 2000 1304-1399 28-JUL-2012 19:49:47 6880959 312 1302 28-JUL-2012 19:49:47 6880958 76 1303 28-JUL-2012 19:49:47 6880957 2000 1304-1399 28-JUL-2012 18:02:16 6880539 312 1302 28-JUL-2012 18:02:16 6880538 76 1303 28-JUL-2012 18:02:16 6880537 But, when I try to group the timestamp using analytical function, select amt ,cd ,rank() over(partition by tmstp order by tmstp desc) rn from (select sum(disclosed_cost_allocation.to_be_paid_amt) amt, substr(reference_data.ref_code,4,10) cd, to_char(external_order_status.status_updated_tmstp, 'DD-MON-YYYY HH24:MI:SS') tmstp, DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID id FROM Deal.Fee_Mapping_Definition , Deal.Fee_Index_Definition , Deal.Fee_Closing_Cost_Item, Deal.Closing_Cost, Deal.Document_Generation_Request, deal.PRODUCT_REQUEST, deal.External_Order_Request, deal.External_Order_Status, deal. DISCLOSED_CLOSING_COST, deal.DISCLOSED_COST_ALLOCATION, deal.reference_data WHERE Fee_Mapping_Definition.Fee_Code = Fee_Index_Definition.Fee_Code AND Fee_Index_Definition.Fee_Index_Definition_Id = Fee_Closing_Cost_Item.Fee_Index_Definition_Id AND Fee_Closing_Cost_Item.Closing_Cost_Id = Closing_Cost.Closing_Cost_Id AND CLOSING_COST.PRODUCT_REQUEST_ID = Document_Generation_Request.Product_Request_Id AND closing_cost.product_request_id = product_request.product_request_id AND Product_Request.Deal_Id = External_Order_Request.Deal_Id AND external_order_request.external_order_request_id = external_order_status.external_order_request_id AND external_order_request.external_order_request_id = disclosed_closing_cost.external_order_request_id AND DISCLOSED_CLOSING_COST. DISCLOSED_CLOSING_COST_ID = DISCLOSED_COST_ALLOCATION.DISCLOSED_CLOSING_COST_ID AND Fee_Index_Definition.Fee_Index_Definition_Id = Disclosed_Closing_Cost.Fee_Index_Definition_Id AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id = Reference_Data.Reference_Data_Id AND Document_Generation_Request.Document_Package_Ref_Id IN (7392 ,2209 ) AND External_Order_Status.Order_Status_Txt = ('GenerationCompleted') AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id IN ( 7789, 7788,7596 ) AND FEE_MAPPING_DEFINITION.DOCUMENT_TYPE_REF_ID = 1099 AND Document_Generation_Request.Product_Request_Id IN (SELECT PRODUCT_REQUEST.PRODUCT_REQUEST_id FROM Deal.Disclosed_Cost_Allocation, Deal.Disclosed_Closing_Cost, DEAL.External_Order_Request, DEAL.PRODUCT_REQUEST, Deal.Scenario WHERE Disclosed_Cost_Allocation.Disclosed_Closing_Cost_Id = Disclosed_Closing_Cost.Disclosed_Closing_Cost_Id AND Disclosed_Closing_Cost.External_Order_Request_Id = External_Order_Request.External_Order_Request_Id AND External_Order_Request.Deal_Id = Product_Request.Deal_Id AND product_request.scenario_id = scenario.scenario_id AND SCENARIO.SCENARIO_STATUS_TYPE_REF_ID = 7206 AND product_request.servicing_loan_acct_num IS NOT NULL AND product_request.servicing_loan_acct_num = 0017498379 --AND Disclosed_Cost_Allocation.Disclosed_Cost_Allocation_Id = 5095263 ) GROUP BY DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID, External_Order_Status.Status_Updated_Tmstp, Reference_Data.Ref_Code, disclosed_cost_allocation.to_be_paid_amt order by 3 desc, 1 DESC); Result: 312 1302 1 2000 1304-1399 1 76 1303 1 312 1302 1 2000 1304-1399 1 76 1303 1 Required output: 312 1302 1 2000 1304-1399 1 76 1303 1 312 1302 2 2000 1304-1399 2 76 1303 2
Rod.Hey, Rod,
My guess is that you want:
, dense_rank () over (order by tmstp desc) AS rnRANK means you'll jump numbers when there is a link. For example, if all 3 rows have the exact same last tmstp, all 3 rows would be assigned number 1, GRADE would assign 4 to the next line, but DENSE_RANK attributes 2.
"PARTITION x" means that you are looking for a separate series of numbers (starting with 1) for each value of x. If you want just a series of numbers for the entire result set, then do not use a PARTITION BY clause at all. (PARTITION BY is never required.)
Maybe you want to PARTITIONNER IN cd. I can't do it without some examples of data, as well as an explanation of why you want the results of these data.
You certainly don't want to PARTITION you BY the same expression ORDER BY; It simply means that all the lines are tied for #1.I hope that answers your question.
If not, post a small example data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and also publish outcomes from these data.
Explain, using specific examples, how you get these results from these data.
Simplify the problem as much as possible.
Always tell what version of Oracle you are using.
See the FAQ forum {message identifier: = 9360002}Published by: Frank Kulash, August 1, 2012 13:20
-
More help with analytical functions
I had great hellp here yesterday and I need once more today. I guess I'm still not able to get a solid understanding of analytical functions. So here's the problem:
table with 3 collars:
product_id (int), sale_date (to date), count_sold (int) - each file show that the number of items have been sold for the product at a given date.
The query should return the 3 passes of the table AND a fourth column that contains the date with the best sales of the product. If there are two or more dates with equal sales, the last being is chosen.
Is this possible using an analytical function appropriately and without using a subquery?
example:
product_id, sale_date, count_sold, high_sales_date
1, 01-01-2008, 10, 05/10/2008,.
1, 2008-03-10, 20, 10/05/2008
1, 10/04/2008, 25, 05/10/2008
1, 10/05/2008, 25, 05/10/2008
1, 01/06/2008, 22, 05/10/2008
2, 05/12/2008, 12, 05/12/2008
2, 06/01/2009, 10, 05/12/2008
Thank youHello
Try this:
SELECT product_id , sale_date , count_sold , FIRST_VALUE (sale_date) OVER ( PARTITION BY product_id ORDER BY count_sold DESC , sale_date DESC ) AS high_sales_date FROM table_x;If you would post INSERT statements for your data, then I could test it.
Focus issue: Why use FIRST_VALUE with descending order and not LAST_VALUE (ASCending) ORDER of default?
-
order by with analytic function
Hi gurus
Need your help again.
I have the following data.
Examples of data
Select * from
(
As with a reference
(
Select ' 100 ', ' 25' grp lb, to_date('2012-03-31') ter_dt, 'ABC' package_name FROM DUAL union all
Select ' 100 ', ' 19', to_date ('2012-03-31'), 'AA' OF the whole union DOUBLE
Select ' 200 ', ' 25', to_date('2012-03-31'), 'CC' FROM DUAL union all
Select ' 300 ', ' 28', to_date('2012-03-31'), 'XX' from DUAL union all
Select ' 300 ', ' 28', to_date('4444-12-31'), 'XY' from DUAL
)
Select the grp, lb, ter_dt, Package_name
ROW_NUMBER() over (partition by order of grp by case when lb = '19' then 1)
When lb = '25' then 2
ro_nbr end)
Reference)
-where ro_nbr = 1
;
-----------
The query above returns the following result:
Existing query result
GRP LB TER_DT package_name RO_NBR
100 19 03/12/31 AA 1 100 25 03/12/31 ABC 2 200 25 03/12/31 CC 1 300 28 03/12/31 XX 1 300 28 44 12-31 XY 2 If you can see the data above then I use the order clause with function row_number analytic and prioritize data according to LB using the order by clause.
Now the problem is I need simple stored against each group so I write the following query:
Query
Select * from
(
As with a reference
(
Select ' 100 ', ' 25' grp lb, to_date('2012-03-31') ter_dt, 'ABC' package_name FROM DUAL union all
Select ' 100 ', ' 19', to_date ('2012-03-31'), 'AA' OF the whole union DOUBLE
Select ' 200 ', ' 25', to_date('2012-03-31'), 'CC' FROM DUAL union all
Select ' 300 ', ' 28', to_date('2012-03-31'), 'XX' from DUAL union all
Select ' 300 ', ' 28', to_date('4444-12-31'), 'XY' from DUAL
)
Select the grp, lb, ter_dt, Package_name
ROW_NUMBER() over (partition by order of grp by case when lb = '19' then 1)
When lb = '25' then 2
ro_nbr end)
Reference)
where ro_nbr = 1
;
The query result
GRP LB TER_DT RO_NBR
100 19 03/12/31 AA 1 200 25 03/12/31 CC 1 300 28 03/12/31 XX 1 My required result is that 300 GRP contains 2 folders and I need the record with the latest means of ter_dt and right now, I only get the latest.
My output required
GRP LB TER_DT RO_NBR
100 19 03/12/31 AA 1 200 25 03/12/31 CC 1 300 28 44 12-31 XY 1 Please guide. Thank you
Hello
The query you posted is the ro_nbr assignment based on nothing other than lb. When there are 2 or more lines that have an equal claim to get assigned ro_nbr = 1, then one of them is chosen arbitrarily. If, when a tie like that occurs, you want the number 1 to be assigned based on some sort, and add another expression of Analytics ORDER BY clause, like this:
WITH got_ro_nbr AS
(
SELECT the grp, lb, ter_dt, nom_package
ROW_NUMBER () OVER (PARTITION BY grp
ORDER OF CASES
WHEN lb = '19' THEN 1
WHEN lb = '25' THEN 2
END
, ter_dt DESC-* NEW *.
) AS ro_nbr
REFERENCE
)
SELECT the grp, lb, ter_dt, nom_package
OF got_ro_nbr
WHERE ro_nbr = 1
;
-
Help with analytical functions
Hi all
I'm on Oracle 11g DB and have records in the table that look like this
Analytical, I generate rownumber by Ref single transaction as follows:transaction_ref line_type description -------------------- -------------- --------------- 10 DETAIL abc123 10 DETAIL abc978 10 DETAIL test 10 DETAIL test 10 DETAIL test 20 DETAIL abcy 20 DETAIL abc9782 20 DETAIL test12 20 DETAIL test32
However, for my needs, I need my rownumber as follows:SELECT row_number() over (partition by transaction_ref order by 1) rownumber FROM mytable ; transaction_ref line_type description rownumber -------------------- -------------- --------------- ---------------- 10 DETAIL abc123 1 10 DETAIL abc978 2 10 DETAIL test 3 10 DETAIL test 4 10 DETAIL test 5 20 DETAIL abcy 1 20 DETAIL abc9782 2 20 DETAIL test12 3 20 DETAIL test32 4
with the exception of number 1 of Clotilde, I want to increment the number of lines per 3
Thank youtransaction_ref line_type description rownumber -------------------- -------------- --------------- ---------------- 10 DETAIL abc123 1 10 DETAIL abc978 4 10 DETAIL test 7 10 DETAIL test 10 10 DETAIL test 13 20 DETAIL abcy 1 20 DETAIL abc9782 4 20 DETAIL test12 7 20 DETAIL test32 10 ....
Maëlle
Published by: user565538 on June 4, 2011 17:32
Published by: user565538 on June 4, 2011 17:34
Published by: user565538 on June 4, 2011 17:35with mytable as ( select 10 transaction_ref,'DETAIL' line_type,'abc123' description from dual union all select 10,'DETAIL','abc978' from dual union all select 10,'DETAIL','test' from dual union all select 10,'DETAIL','test' from dual union all select 10,'DETAIL','test' from dual union all select 20,'DETAIL','abcy' from dual union all select 20,'DETAIL','abc9782' from dual union all select 20,'DETAIL','test12' from dual union all select 20,'DETAIL','test32' from dual ) SELECT transaction_ref, line_type, description, (row_number() over (partition by transaction_ref order by 1) - 1) * 3 + 1 rownumber FROM mytable / TRANSACTION_REF LINE_T DESCRIP ROWNUMBER --------------- ------ ------- ---------- 10 DETAIL abc123 1 10 DETAIL abc978 4 10 DETAIL test 7 10 DETAIL test 10 10 DETAIL test 13 20 DETAIL abcy 1 20 DETAIL abc9782 4 20 DETAIL test12 7 20 DETAIL test32 10 9 rows selected. SQL>SY.
-
Help with analytical functions - Windowing
Hello
I'm using Oracle 11.2.0.4.0.
I want to do the sum of all amounts for each window of 3 days from the date of the oldest rolling. I also want to name each window with the date limit for the period of 3 days.
My requirement is slightly more complicated, but I use this example to illustrate what I'm trying to
create table test (dt date, amt, run_id number);
Insert test values (to_date (' 22/04/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 23/04/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 24/04/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 25/04/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 27/04/2015 ',' dd/mm/yyyy'), 5, 1);
Insert test values (to_date (' 28/04/2015 ',' dd/mm/yyyy'), 2, 1);
Insert test values (to_date (' 29/04/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 04/30/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 01/05/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 02/05/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 03/05/2015 ',' dd/mm/yyyy'), 1, 1);
Insert test values (to_date (' 04/05/2015 ',' dd/mm/yyyy'), 1, 1);
The output should look like the example below. The period column requires
to show the end of each 3-day study:
AMT DT SUM_PER_PERIOD PERIOD
22/04/2015 1 1 24/04/2015
23/04/2015 1 2 24/04/2015
24/04/2015 1 3 24/04/2015
25/04/2015 1 3 27/04/2015
27/04/2015 5 6 27/04/2015
28/04/2015 2 7 30/04/2015
29/04/2015 20 27 30/04/2015
30/04/2015 30 52 30/04/2015
05/01/2015 5 55 3/05/2015
05/02/2015 5 50 3/05/2015
05/02/2015 10 50 3/05/2015
05/03/2015 1 21/3/05/2015
All I can manage this is
Select dt
TN
, sum (amt) on sum_per_period (PARTITION BY run_id ORDER BY dt vary from 2 PAST current line)
of the test
order by dt;
Can anyone help?
It's very kind of you to give the insert and create instructions... but I corrected the data a bit
It does not match the output see you below
starting from 29/04, you forgot to change the dates and numbers of...
insert into test values (to_date('22/04/2015','dd/mm/yyyy'),1,1); insert into test values (to_date('23/04/2015','dd/mm/yyyy'),1,1); insert into test values (to_date('24/04/2015','dd/mm/yyyy'),1,1); insert into test values (to_date('25/04/2015','dd/mm/yyyy'),1,1); insert into test values (to_date('27/04/2015','dd/mm/yyyy'),5,1); insert into test values (to_date('28/04/2015','dd/mm/yyyy'),2,1); insert into test values (to_date('29/04/2015','dd/mm/yyyy'),20,1); insert into test values (to_date('30/04/2015','dd/mm/yyyy'),30,1); insert into test values (to_date('01/05/2015','dd/mm/yyyy'),5,1); insert into test values (to_date('02/05/2015','dd/mm/yyyy'),5,1); insert into test values (to_date('02/05/2015','dd/mm/yyyy'),10,1); insert into test values (to_date('03/05/2015','dd/mm/yyyy'),1,1);your periods will change if you insert a new first date...
so I guess you want a specific date... in this case 22/04/2015 and a specific end date
creation of periods from this first date and then grouping of these periods is easier with a first fixed date and a delta of 3 days.
the first step is to match the periods to your data (adapted)
with periods as ( select date_start + (level-1) * period_days period_start, date_start + level * period_days period_end, period_days from ( select to_date('21/04/2015', 'dd/mm/yyyy') date_start, to_date('04/05/2015', 'dd/mm/yyyy') date_end, 3 period_days from dual) connect by date_start + level * period_days < date_end) select * from test t, periods p where t.dt > p.period_start and t.dt <= p.period_endThis gives your data with the dates of beginning and ending period
DT AMT RUN_ID PERIOD_START PERIOD_END PERIOD_DAYS 22/04/2015 1
1
21/04/2015 24/04/2015 3
23/04/2015 1
1
21/04/2015 24/04/2015 3
24/04/2015 1
1
21/04/2015 24/04/2015 3
25/04/2015 1
1
24/04/2015 27/04/2015 3
27/04/2015 5
1
24/04/2015 27/04/2015 3
28/04/2015 2
1
27/04/2015 30/04/2015 3
29/04/2015 20
1
27/04/2015 30/04/2015 3
30/04/2015 30
1
27/04/2015 30/04/2015 3
05/01/2015 5
1
30/04/2015 05/03/2015 3
05/02/2015 5
1
30/04/2015 05/03/2015 3
05/02/2015 10
1
30/04/2015 05/03/2015 3
05/03/2015 1
1
30/04/2015 05/03/2015 3
and then sum the amt during the 3 days
with periods as ( select date_start + (level-1) * period_days period_start, date_start + level * period_days period_end, period_days from ( select to_date('21/04/2015', 'dd/mm/yyyy') date_start, to_date('04/05/2015', 'dd/mm/yyyy') date_end, 3 period_days from dual) connect by date_start + level * period_days < date_end) select t.dt, t.amt, sum(amt) over (order by t.dt range between 2 preceding and current row) sum_per_period, p.period_end period from test t, periods p where t.dt > p.period_start and t.dt <= p.period_endgiving your output as requested:
DT AMT SUM_PER_PERIOD PERIOD 22/04/2015 1
1
24/04/2015 23/04/2015 1
2
24/04/2015 24/04/2015 1
3
24/04/2015 25/04/2015 1
3
27/04/2015 27/04/2015 5
6
27/04/2015 28/04/2015 2
7
30/04/2015 29/04/2015 20
27
30/04/2015 30/04/2015 30
52
30/04/2015 05/01/2015 5
55
05/03/2015 05/02/2015 5
50
05/03/2015 05/02/2015 10
50
05/03/2015 05/03/2015 1
21
05/03/2015 -
Performance with Analytic functions
Hello
The following query takes more than 3 hours to run (10.2.0.4)
any help to optimize this?
Thanks for your help
SELECT DISTINCT MAX (NVL (A.DB_SOURCE, 'SIGNIFY')) OVER (PARTITION BY C.COUNTRY) DB_SOURCE, A.SUBJECTNUMBERSTR, A.SUBJECTID, MAX (A.SITECOUNTRY) OVER (PARTITION BY C.COUNTRY) SITECOUNTRY, C.COUNTRY, C.CENTRE, C.COUNTRY || '-' || C.CENTRE AS SITEMNEMONIC, A.VISITMNEMONIC, A.VISITID, A.FROZENSTATE, A.SIGNEDSTATE, A.INCLUS, A.VISDATRECTHEO, A.VISIT, A.VISIT_THEO, B.DOV, MAX (C.STUDY_INCL) OVER () STUDY_INCL, MAX (C.COUNTRY_INCL) OVER (PARTITION BY C.COUNTRY) COUNTRY_INCL, MAX (C.CENTRE_INCL) OVER (PARTITION BY C.COUNTRY, C.CENTRE) CENTRE_INCL, MAX (NVL (C.NB_VISIT_ATTENDUES_GLOBAL, 0)) OVER () NB_VISIT_ATTENDUES_GLOBAL, MAX (NVL (C.NB_VISIT_ATTENDUES_COUNTRY, 0)) OVER (PARTITION BY C.COUNTRY) NB_VISIT_ATTENDUES_COUNTRY, MAX (NVL (C.NB_VISIT_ATTENDUES_CENTRE, 0)) OVER (PARTITION BY C.COUNTRY, C.CENTRE) NB_VISIT_ATTENDUES_CENTRE, MAX (D.NB_VISIT_CLEAN_GLOBAL) OVER () NB_VISIT_CLEAN_GLOBAL, MAX (D.NB_VISIT_CLEAN_COUNTRY) OVER (PARTITION BY C.COUNTRY) NB_VISIT_CLEAN_COUNTRY, MAX (D.NB_VISIT_CLEAN_COUNTRY) OVER (PARTITION BY C.COUNTRY, C.CENTRE) NB_VISIT_CLEAN_CENTRE, MAX (D.NB_VISIT_CLEAN_INCLUS_GLOBAL) OVER () NB_VISIT_CLEAN_INCLUS_GLOBAL, MAX (D.NB_VISIT_CLEAN_INCLUS_COUNTRY) OVER (PARTITION BY C.COUNTRY) NB_VISIT_CLEAN_INCLUS_COUNTRY, MAX (D.NB_VISIT_CLEAN_INCLUS_COUNTRY) OVER (PARTITION BY C.COUNTRY, C.CENTRE) NB_VISIT_CLEAN_INCLUS_CENTRE FROM CL316257083_ECRF_DW.T_BILANS_MENSUELS_TMP A, CL316257083_ECRF_DW.T_PASTA_UNION B, CL316257083_ECRF_DW.T_BILAN_SETHI C, CL316257083_ECRF_DW.T_BILAN_QUERIES D WHERE ( A.DB_SOURCE = B.DB_SOURCE(+) AND A.SUBJECTID = B.SUBJECTID(+) AND A.VISITID = B.VISITID(+)) AND (C.COUNTRY = A.COUNTRY(+) AND C.CENTRE = A.CENTRE(+)) AND (D.COUNTRY(+) = A.COUNTRY AND D.CENTRE(+) = A.CENTRE); Plan hash value: 3745247003 -------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | -------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 10025 | 1556K| | 1544 (13)| 00:00:02 | | 1 | HASH UNIQUE | | 10025 | 1556K| 3496K| 1544 (13)| 00:00:02 | | 2 | WINDOW SORT | | 10025 | 1556K| 3496K| 1544 (13)| 00:00:02 | |* 3 | HASH JOIN OUTER | | 10025 | 1556K| | 915 (20)| 00:00:01 | |* 4 | HASH JOIN OUTER | | 5543 | 703K| | 720 (20)| 00:00:01 | |* 5 | HASH JOIN OUTER | | 5543 | 552K| | 359 (21)| 00:00:01 | | 6 | TABLE ACCESS FULL| T_BILAN_SETHI | 1277 | 43418 | | 4 (0)| 00:00:01 | | 7 | TABLE ACCESS FULL| T_BILANS_MENSUELS_TMP | 259K| 16M| | 342 (18)| 00:00:01 | | 8 | TABLE ACCESS FULL | T_PASTA_UNION | 105K| 2884K| | 355 (19)| 00:00:01 | | 9 | TABLE ACCESS FULL | T_BILAN_QUERIES | 107K| 3057K| | 189 (16)| 00:00:01 | -------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("D"."COUNTRY"(+)="A"."COUNTRY" AND "D"."CENTRE"(+)="A"."CENTRE") 4 - access("A"."DB_SOURCE"="B"."DB_SOURCE"(+) AND "A"."SUBJECTID"="B"."SUBJECTID"(+) AND "A"."VISITID"="B"."VISITID"(+)) 5 - access("C"."COUNTRY"="A"."COUNTRY"(+) AND "C"."CENTRE"="A"."CENTRE"(+)) 24 rows selected. Elapsed: 00:00:11.15with tab as ( SELECT --+ materialize DISTINCT A.SUBJECTNUMBERSTR, A.SUBJECTID, C.COUNTRY, C.CENTRE, C.COUNTRY || '-' || C.CENTRE AS SITEMNEMONIC, A.VISITMNEMONIC, A.VISITID, A.FROZENSTATE, A.SIGNEDSTATE, A.INCLUS, A.VISDATRECTHEO, A.VISIT, A.VISIT_THEO, B.DOV FROM CL316257083_ECRF_DW.T_BILANS_MENSUELS_TMP_MDE A, CL316257083_ECRF_DW.T_PASTA_UNION B, CL316257083_ECRF_DW.T_BILAN_SETHI C, CL316257083_ECRF_DW.T_BILAN_QUERIES D WHERE ( A.DB_SOURCE = B.DB_SOURCE(+) AND A.SUBJECTID = B.SUBJECTID(+) AND A.VISITID = B.VISITID(+)) AND (C.COUNTRY = A.COUNTRY(+) AND C.CENTRE = A.CENTRE(+)) AND (D.COUNTRY(+) = A.COUNTRY AND D.CENTRE(+) = A.CENTRE) ) SELECT -- DISTINCT MAX (NVL (A.DB_SOURCE, 'SIGNIFY')) OVER (PARTITION BY C.COUNTRY) DB_SOURCE, A.SUBJECTNUMBERSTR, A.SUBJECTID, MAX (A.SITECOUNTRY) OVER (PARTITION BY C.COUNTRY) SITECOUNTRY, C.COUNTRY, C.CENTRE, C.COUNTRY || '-' || C.CENTRE AS SITEMNEMONIC, A.VISITMNEMONIC, A.VISITID, A.FROZENSTATE, A.SIGNEDSTATE, A.INCLUS, A.VISDATRECTHEO, A.VISIT, A.VISIT_THEO, B.DOV, MAX (C.STUDY_INCL) OVER () STUDY_INCL, MAX (C.COUNTRY_INCL) OVER (PARTITION BY C.COUNTRY) COUNTRY_INCL, MAX (C.CENTRE_INCL) OVER (PARTITION BY C.COUNTRY, C.CENTRE) CENTRE_INCL, MAX (NVL (C.NB_VISIT_ATTENDUES_GLOBAL, 0)) OVER () NB_VISIT_ATTENDUES_GLOBAL, MAX (NVL (C.NB_VISIT_ATTENDUES_COUNTRY, 0)) OVER (PARTITION BY C.COUNTRY) NB_VISIT_ATTENDUES_COUNTRY, MAX (NVL (C.NB_VISIT_ATTENDUES_CENTRE, 0)) OVER (PARTITION BY C.COUNTRY, C.CENTRE) NB_VISIT_ATTENDUES_CENTRE, MAX (D.NB_VISIT_CLEAN_GLOBAL) OVER () NB_VISIT_CLEAN_GLOBAL, MAX (D.NB_VISIT_CLEAN_COUNTRY) OVER (PARTITION BY C.COUNTRY) NB_VISIT_CLEAN_COUNTRY, MAX (D.NB_VISIT_CLEAN_COUNTRY) OVER (PARTITION BY C.COUNTRY, C.CENTRE) NB_VISIT_CLEAN_CENTRE, MAX (D.NB_VISIT_CLEAN_INCLUS_GLOBAL) OVER () NB_VISIT_CLEAN_INCLUS_GLOBAL, MAX (D.NB_VISIT_CLEAN_INCLUS_COUNTRY) OVER (PARTITION BY C.COUNTRY) NB_VISIT_CLEAN_INCLUS_COUNTRY, MAX (D.NB_VISIT_CLEAN_INCLUS_COUNTRY) OVER (PARTITION BY C.COUNTRY, C.CENTRE) NB_VISIT_CLEAN_INCLUS_CENTRE FROM tab; -- group by ??? -
Need help with analytical function (LAG)
The requirement is as I have a table with described colums
col1 County flag Flag2
ABC 1 Y Y
XYZ 1 Y Y
XYZ 1 O NULL
xyz *2* N N
XYZ 2 Y NULL
DEF 1 Y Y
DEF 1 N NULL
To get the columns Flag2
1 assign falg2 as indicator for rownum = 1
2 check the colm1, count of current line with colm1, Earl of the previous line. The colm1 and the NTC are identical, should assign null...
Here's the query I used to get the values of Flag2
SELECT colm1, count, flag
BOX WHEN
LAG(Count, 1,null) OVER (PARTITION BY colm1 ORDER BY colm1 DESC NULLS LAST) IS NULL
and LAG(flag, 1, NULL) PLUS (SCORE FROM colm1 ORDER BY colm1, cycle DESC NULLS LAST) IS NULL
THEN the flag
END AS Flag2
FROM table1
but the query above returns the o/p below which is false
col1_ County flag Flag2
ABC 1 Y Y
XYZ 1 Y Y
XYZ 1 O NULL
xyz *2* N NULL
XYZ 2 Y NULL
DEF 1 Y Y
DEF 1 N NULL
Thank you
Published by: user9370033 on April 8, 2010 23:25Well, you have not enough explained your full requirement in this
1 assign falg2 as indicator for rownum = 1
2 check the colm1, count of current line with colm1, Earl of the previous line. The colm1 and the NTC are identical, should assign null...as you say not what Flag2 must be set on if com1 and cnt are not the same as the previous row.
But how about this as my first guess what you mean...
SQL> with t as (select 'abc' as col1, 1 as cnt, 'Y' as flag from dual union all 2 select 'xyz', 1, 'Y' from dual union all 3 select 'xyz', 1, 'Y' from dual union all 4 select 'xyz', 2, 'N' from dual union all 5 select 'xyz', 2, 'Y' from dual union all 6 select 'def', 1, 'Y' from dual union all 7 select 'def', 1, 'N' from dual) 8 -- END OF TEST DATA 9 select col1, cnt, flag 10 ,case when lag(col1) over (order by col1, cnt) is null then flag 11 when lag(col1) over (order by col1, cnt) = col1 and 12 lag(cnt) over (order by col1, cnt) = cnt then null 13 else flag 14 end as flag2 15 from t 16 / COL CNT F F --- ---------- - - abc 1 Y Y def 1 Y Y def 1 N xyz 1 Y Y xyz 1 Y xyz 2 Y Y xyz 2 N 7 rows selected. SQL> -
version 9.2
Here is a sample
Output: number of separate orders for each dateWITH temp AS (SELECT 10 ID, TRUNC (SYSDATE - 1) dt, 101 ord_id FROM DUAL UNION SELECT 11 ID, TRUNC (SYSDATE - 1) dt, 101 ord_id FROM DUAL UNION SELECT 11 ID, TRUNC (SYSDATE) dt, 103 ord_id FROM DUAL UNION SELECT 13 ID, TRUNC (SYSDATE) dt, 104 ord_id FROM DUAL) SELECT * FROM temp
Dt Count 1/25 1 1/26 2ME_XE?WITH temp AS 2 (SELECT 10 ID, TRUNC (SYSDATE - 1) dt, 101 ord_id 3 FROM DUAL 4 UNION 5 SELECT 11 ID, TRUNC (SYSDATE - 1) dt, 101 ord_id 6 FROM DUAL 7 UNION 8 SELECT 11 ID, TRUNC (SYSDATE) dt, 103 ord_id 9 FROM DUAL 10 UNION 11 SELECT 13 ID, TRUNC (SYSDATE) dt, 104 ord_id 12 FROM DUAL) 13 SELECT dt, count(distinct ord_id) 14 FROM temp 15 group by dt; DT COUNT(DISTINCTORD_ID)-------------------------- ---------------------25-JAN-2009 12 00:00 126-JAN-2009 12 00:00 2 2 rows selected. Elapsed: 00:00:00.01ME_XE?ME_XE?
-
Easy way to locate the function used on the diagram by name?
Is there an easy way to locate the functions used in the diagram under the name of the generic function?
I have user appears somewhat to the user on my diagram functions to help me debug a difficult sequence of agross events live multiple now that it works, I want to go back and disable most of these postings. Most of them went up to now within the layers a little structure and is not easy to find.
So is there an easy way to get a list of where these functions are used so that I can quickly go and edit them?
I find the function is with the display hierarchy that does just what I need.
Thank you.
-
How to use Group by in the analytic function
I need to write the Department that has the minimum wage in a row. She must be with analytical function, but I have problem in group by. I can't use min() without group by.
Select * from (min (sal) select min_salary, deptno, RANK() ON RN (ORDER BY sal CSA, CSA rownum) of the Group of emp by deptno) < 20 WHERE RN order by deptno;
Published by: senza on 6.11.2009 16:09Hello
senza wrote:
I need to write the Department that has the minimum wage in a row. She must be with analytic functionTherefore with an analytic function? Looks like it is a duty.
The best way to get these results is with an aggregate, not analysis, function:
SELECT MIN (deptno) KEEP (DENSE_RANK FIRST ORDER BY sal) AS dept_with_lowest_sal FROM scott.emp ;Note that you do not need a subquery.
This can be modififed if, for example, you want the lowest Department with the sal for each job.But if your mission is to use an analytical function, that's what you have to do.
but I have problem in group by. I can't use min() without group by.
Of course, you can use MIN without GROUP BY. Almost all of the aggregate (including MIN) functions have analytical equivalents.
However, in this issue, you don't need to. The best analytical approach RANK only, not use MIN. If you ORDER BY sal, the lines with rank = 1 will have the minimum wage.Select * from (min (sal) select min_salary, deptno, RANK() ON RN (ORDER BY sal CSA, CSA rownum) of the Group of emp by deptno) WHERE the RN< 20="" order="" by="">
Try to select plain old sal instead of MIN (sal) and get reid of the GROUP BY clause.
Add ROWNUM in the ORDER BY clause is to make RANK return the same result as ROW_NUMBER, every time that it is a tie for the sal, the output will still be distinct numbers. which line gets the lower number will be quite arbitrary, and not necessarily the same every time you run the query. For example, MARTIN and WARD have exactly the same salary, 1250. The query you posted would assign rn = 4 to one of them and rn = 5 to another. Who gets 4? It's a toss-up. It could be MARTIN the first time you try, and WARD the next. (In fact, in a very small table like scott.emp, it probably will be consistent, but always arbitrary.) If this is what you want, it would be clearer and simpler just to use ROW_NUMEBR instead of RANK.
-
There must be a better way to do this (frustration of RAM Preview)
I loaded one 01:20 second Full HD clip in sequels. I need to edit the video based on some sounds in the video and see if I match them correctly by the image previewed with the sound.
The problem is that I'm frustrated due to After effects does not not like first. First who thought it was a good idea is not to integrate sound in sequels? Secondly, I have an i7 processor sandy bridge, and 16 GB of ram, but he always takes time to render the preview ram (with still no effect on it).
Ram preview is my only option for sound, but the problem is every time I hit the ram preview it starts the video all the way from the beginning. It's frustrating because I want to start at a specific time. Imagine having a video more long where editing must take place at the end.
Professional projects of people out there doing a lot more complicated, you guys how to work around this problem?
Why can't after that effects do some basic things like first as make fast with the sound? Is it because of the Mercury engine and 64-bit?
It is one of the best products on the market, there must be a better way of doing things?
No need to preview RAM just to hear the sound, use the comma on the numeric keypad key to play an audio preview only.
If you want to mark certain audio events, twirl down the properties for the audio until you see the waveform and then use it to synchronize audio and animations.
And if you want RAM Preview from your current position, simply press the 'B' button to set your start of work area to the playhead, and then the RAM previews will begin from that point.
Use ctrl - drag to scrub audio & video. Use ctrl-alt-drag to scrub just audio.
AE has all the audio features of first (and), he just behaves in a different way.
-
Legends and anchored objects - there must be a better way to do
I spent a lot of time in the last six months, reconstruct PDF files in InDesign. It is part of my regular responsibilities, but I do a lot more of him for some reason any. Because I send you the text of these rebuild on documents for translation, I like that all of the text in a single story. It really helps to have the text in 'logical order', I think; When I prepare a trifold brochure, I try pretty hard to make sure that the order in which readers will read the text is reproduced in the stream of history throughout the identity document.
So I'm rebuilding a manual as a form of 3 columns on letter paper and it is full of legends. Full of em. They are not pull quotes, either; each of these has unique text. Keeping in mind that I would like the text of those legends to stay in the same position in the text once I connected all the stories and exported a RTF for translation, which is the best way to handle them? What I do is insert a frame drawn emptly as an anchored object, size and position to sit above the text which is supposed to be shouted. When my translations come back, so they are always longer than the source document, as I crawl through the text, I resize the anchored images to match the size and position of the new extension translated the text and then move them in place with the keyboard.
There must be a better way.
It is better, right? I don't actually know too. If I really want to fill these frames anchored with text, I can't screw the them in the history. I suppose I could just put on the frames of the legend and assign two RTFs for translation instead of one, but then the 'logic' of my text order is thrown out the window. So, I am asking myself "what's more important? reduction of formatting time or maintenance of the flow of the story? "If there's something that miss me let me to dodge this decision, I would love to hear about it. The only thing I can think would work like this:
(1) reproduce the text of the legend in the history with a custom sample "Invisible."
(2) create "CalloutText" parastyle with "Invisible" swatch and apply it to the caption text
(3) Insert the anchor for framework anchored immediately before the content of CalloutText
(4) send it out for translation
(5) while I'm waiting to get him back, write a script that would be (don't know if this is possible):
(a) to scroll through the main story looking for any instance of CalloutText
(b) copies an instance of contiguous to this style to the Clipboard
(c) look back in history for the first preceding the instance of CalloutText anchor
(d) fill the object anchored with the text on the Clipboard (that's where I'm really naïve)
(e) implement a new parastyle the text of the legend
(f) continue step by step through the story, looking for other instances of CalloutText
If this is really the only decent solution, I'll simply go to the Scripting forum for more help with d). Any of you can make other suggestions?
N ° there is no plugin dependencies (as long as you do not use
APID version 1.0.46 - who had a bug that caused the warnings warning). Round-
trigger by INX dirty not the text. If you return
using the most recent version of the APID (version 1.0.47 pre5 and later - not)
really yet published), plugin data should be preserved as well.
Substances
-
There must be a better way to do this
There must be a better way to do this!
25 separate reports - 1 voltage recorded by chanel every minute for 21 hours (end - times will have to be changed)
Anyone has ideas/directions
CC
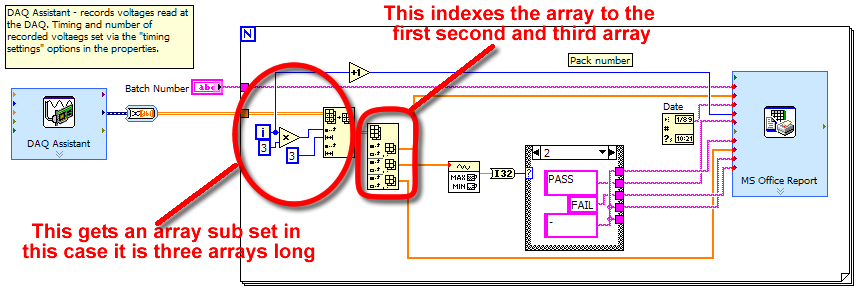
The DAQ Assistant reads the tensions based on the timings specified, which means that if I set the number of samples finish say 20 and the frequency of samples to 1, then data acquisition will take 20 seconds to save 20 data points (one second) per channel. Then the DAQ pump data to the loop that creates reports (N number of reports).
TO answer this question: the DAQ Assistant will do exactly what you suggest here.
Two questions:
-the loop will be able to separate the different channels ie first report contains data AI1, AI2 and AI3, then the second contains data AI4, AI5 AI6 etc.. ? What is the purpose of the table screws?
TO answer this question: If you look inside the front loop, you see I have the sub table value function. I have set the index to the increment and then multiply 3 X. The first time in the loop take 0 and multiply by 3 and I get zero. second time through I multiply 1 X 3 and get 3. The second thing I have on the sub table set is giving him a length of 3. This will make return three matrices. So this will give me the next three tables each time through. So the first time through I get AI0 AI1, AI2 AI3 AI4, AI5 second time or however you have configured channels.
- and what is the function of painting that the subset of table is wired to (can not find the icon of my pallet table)?
TO answer this question: Index table. Handel, it automatically becomes a 2D array.
Maybe you are looking for
-
After clicking on a link in Thunderbird e-mail, Firefox opens the first time, but after the closure, I am unable to open it again, as it says that Firefox still works even if it isn't. The process runs as indicated by the Task Manager again and I at
-
Activation of the LAN after reinstalling Windows - Satellite Pro A10
I gave my laptop Toshiba Satellite Pro A10 an a copy of Windows XP Pro format. In general, I use a PCMCIA Wireless Internet card, but I don't want to connect to my laptop via a physical Ethernet cable. Unfortunately I can not understand how to turn t
-
Try to burn JPEGs on a cd in "master" mode to make them playable on standard dvd players. the computer will burn on the cd and the images can be viewed on another computer, but cannot be viewed on a DVD player? any help would be great.
-
BlackBerry Smartphones pine bar code
I have a blackberry curve 9300 and I am new to the world of blackberry. So I was wondering how to scan a barcode that doesn't have to do with a contact. I mean with codes bar on posters or pamphlets that someone can tell me how to do this. Because I
-
Problems with Wifi on windows 8
Dear Microsoft I report a serious problem with loss of WiFi connectivity on windows computers 8. Sometimes many different problems occur when trying to restart our system of windows 8, after that we had problems with our applications, we had problems