issue update a table using a function in pipeline
BANNER
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bi
PL/SQL Release 10.2.0.4.0 - Production
CORE 10.2.0.4.0 Production
TNS for HPUX: Version 10.2.0.4.0 - Production
NLSRTL Version 10.2.0.4.0 - ProductionI try to make updates or inserts in the tables and I use a function pipeline for this bed of the same tables of the to do.
and it gives me
ORA-04091: table DSAMSTRC.T is mutating, trigger/function may not see it
ORA-06512: at "DSAMSTRC.GET_T_ARRAY", line 6Here's my example
DROP TABLE t;
------------------------------------------------------------------------------------
CREATE TABLE t
AS
SELECT LEVEL id, 'A' txt
FROM DUAL
CONNECT BY LEVEL <= 10;
-------------------------------------------------------------------------------------
CREATE OR REPLACE TYPE t_table_type AS OBJECT
(id NUMBER, txt VARCHAR2 (200));
------------------------------------------------------------------------------------
CREATE OR REPLACE TYPE t_array AS TABLE OF t_table_type;
-----------------------------------------------------------------------------------
CREATE OR REPLACE FUNCTION get_t_array (v_txt IN t.txt%TYPE)
RETURN t_array
PIPELINED
IS
BEGIN
FOR EACH IN (SELECT id, txt
FROM t
WHERE t.txt = v_txt)
LOOP
PIPE ROW (t_table_type (EACH.id, EACH.txt));
END LOOP;
RETURN;
END;
---------------------------------------------------------------------------------------
UPDATE t
SET txt = 'B'
WHERE id IN (SELECT id FROM TABLE (get_t_array ('A')));
You can create a global temporary table that has the same columns that use your function to insert in there, and then use it to update t.
CREATE GLOBAL TEMPORARY TABLE t_temp
(id INTEGER,
txt VARCHAR2(100))
ON COMMIT DELETE ROWS;
INSERT INTO t_temp
(SELECT id, txt FROM get_t_array('A'));
UPDATE t
SET t.txt = (SELECT txt FROM t_temp
WHERE t_temp.id = t.id)
WHERE t.id IN (SELECT id FROM t_temp);
Tags: Database
Similar Questions
-
Update a table using the clause
Hello
I want to update a table using the selected values.
Cases in the sample:
create table as empsalary)
Select 1 as empid, 0 in the wages of all the double union
Select option 2, the double 0);
Data update are as follows
with saldata as
(
Select 1 as empid, 5000 as wages, 500 as double pf
Union of all the
Select option 2, 10000,1000 like double pf
)
Select empid, salary saldata
I tried the following query but does not work
updated set of empsalary table (empid, salary) =
(
Select * from)
with saldata as
(
Select 1 as empid, salary, 500 5000 as pf Union double all the
Select option 2, 10000,1000 like double pf
)
Select empid, salary saldata
) sl
where sl.empid = empsalary.empid
)
I use oracle 10g.
Help, please.
Krishna Devi wrote:
Hello
I want to update a table using the selected values.
Cases in the sample:
create table as empsalary)
Select 1 as empid, 0 in the wages of all the double union
Select option 2, the double 0);
Data update are as follows
with saldata as
(
Select 1 as empid, 5000 as wages, 500 as double pf
Union of all the
Select option 2, 10000,1000 like double pf
)
Select empid, salary saldata
I tried the following query but does not work
updated set of empsalary table (empid, salary) =
(
Select * from)
with saldata as
(
Select 1 as empid, salary, 500 5000 as pf Union double all the
Select option 2, 10000,1000 like double pf
)
Select empid, salary saldata
) sl
where sl.empid = empsalary.empid
)
I use oracle 10g.
Help, please.
Thanks for posting creates table and test data.
The error message would have helped because it's pretty obvious that this is the problem:
Update table empsalary
*
ERROR on line 1:
ORA-00903: invalid table name
Just remove the word "table".
-
I want the single update query without using the function.
I want to update sells_table selling_code field with product_code date product table max.
In the product table, there are several product_code date wise.
I did with below charly with the use of the service, but we can do in the query what a single update
without using the function.
UPDATE sells_table
SET selling_code = MAXDATEPRODUCT (ctd_vpk_product_code)
WHERE NVL(update_product_flag,0) = 0;
(P_product IN VARCHAR2) RETURN of HVL.maxdateproduct NUMBER FUNCTION to CREATE or REPLACE
IS
max_date_product VARCHAR2 (100);
BEGIN
BEGIN
SELECT NVL (TRIM (product_code), 0)
IN max_date_product
FROM (SELECT product_code, xref_end_dt)
PRODUCT
WHERE TO_NUMBER (p_product) = pr.item_id
ORDER BY xref_end_dt DESC)
WHERE ROWNUM = 1; -He'll be back a single line - max date product code
EXCEPTION
WHILE OTHERS
THEN
RETURN 0;
END;
RETURN max_date_product;
END maxdateproduct;
Thanks in advance.Hello
Something like that.
update setlls_table st set selling_code =(select nvl(trim(product_code)) from (select product_code , rank() over (partition by item_id order by xref_end_dt DESC) rn from product ) pr where rn =1 and pr.item_id = st.ctd_vpk_product_code ) where NVL(update_product_flag,0) = 0 ;That such is not tested due to lack of sampling input.
Concerning
Anurag Tibrewal. -
Update the table using discoverer
Hello
I'm trying to update a table whenever the user runs a report of the Office of the discoverer. I tried to use a function to do the job, but I get the error below.
ORA-14551: cannot perform the DML operation within a query.
I also tried to
1. create a procedure and update the table in this procedure.
2. function to create and call the procedure created earlier in this function and use it in the discoverer, but still does not work and I get the same error ORA-14551.
Please let me know if this is possible at all the. If SO, let me know the steps to do so.
Thank you.Hello
Yes you can update the discoverer dashboards using a PL/SQL function. You must make the function a standalone transaction. for example
FUNCTION update_record (key_field VARCHAR2) RETURN VARCHAR2
IS
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
..
UPDATE your_table
..
COMMIT;
..Rod West
-
Problem with update of table (using the subquery to retrieve value)
Hello
I update a table based on the value of the subquery.
Here's the update statement.
UPDATING temp xm
SET xm.col1 = (SELECT DISTINCT col1
Of
(SELECT col1, col2 COUNT (col2)
FROM table2
WHERE col1 = xm.col1
AND col2 = xm.col2
GROUP BY col1)
where col2 in (select... in the table3)
)
WHERE xm.col5 = < value >
AND xm.col6 = < value >
When I run this statement I get following error.
ORA-00904: "XM". "" Col1 ": invalid identifier.
Can someone help me why I get this error?
Why doesn't the main table alias in the subquery?
Is it possible to avoid this / re - write the query in a different way?
Thank you
Published by: user552703 on November 2, 2009 20:42You can nest only 1 level deep (referring to the table to be updated).
Have you looked at using the MERGE command? It is "easier" perform updates of this nature, assuming you are using a recent version of Oracle (9 or MORE).
-
using the function in pipeline
Hello
I defined a VC_ARRAY_1 as
and the work that the test shows below:create or replace TYPE "VC_ARRAY_1" as table of varchar2(4000)
But, when I use the function thatselect * from table(VC_ARRAY_1('qqqq', pppp')) COLUMN_VALUE qqqq pppp
I get an error ORA_00936 missing expression (the column personkey is a vrachar2 (4000)). What is the problem with the use of the second?select * from table (vc_array_1(select personkey from tbl_persons))
Thank you
RoseElle rose says:
What is the problem with the use of the second?Everything. You need to throw query results in collection type:
select * from table( cast( multiset( select personkey from tbl_persons ) as vc_array_1 ) ) /SY.
P.S. and where is a function in pipeline in all this? -
update a table using a date to_char
Hello all;
I have the following query and the table below
and I have the following update statementcreate table t1 ( cid varchar2(200), yearid varchar2(200), begin_date date ); insert into t1 (cid, yearid, begin_date) values ('A', '2010_1', sysdate); insert into t1 (cid, yearid, begin_date) values ('B', '2010_1', to_date('03/04/2011', 'MM/DD/YYYY')); insert into t1 (cid, yearid, begin_date) values ('C', '2010_1', to_date('01/02/2011', 'MM/DD/YYYY'));
what I'm trying is basically update table t1 yearid which is a varchar2 in to_char start the date are irregular... so in my case of the sample,update t1 t set t.yearid = '2011_1' where to_char(t.begin_date, 'YYYY') = substr(t.yearid, 1, 4);
TO_CHAR date start back a 2011
Therefore, the yearid must be 2011_1 instead.
However, my udate statement does not work wellDon't know what exactly you want, but it looks like everything that you need is to change = to! = where year clause and using begin_date in update the value:
SQL> select * from t1; CID YEARID BEGIN_DAT --- ---------- --------- A 2010_1 26-JAN-11 B 2010_1 04-MAR-11 C 2010_1 02-JAN-11 SQL> update t1 t 2 set t.yearid = to_char(t.begin_date, 'YYYY') || '_1' 3 where to_char(t.begin_date, 'YYYY') != substr(t.yearid, 1, 4); 3 rows updated. SQL> select * from t1 2 / CID YEARID BEGIN_DAT --- ---------- --------- A 2011_1 26-JAN-11 B 2011_1 04-MAR-11 C 2011_1 02-JAN-11 SQL>SY.
-

11.0.13 does not have this problem, but we can not feasible to push Adobe to the entire organization. If I remove the site in areas of trust in Internet Explorer, it works. This is not an option since our users would be invited for the username and password continuously. Someone at - it a fix for this problem? Adobe is going to release another update as soon as POSSIBLE the resolution it?
Hi chem20006,
It is a known issue and a bug report is already placed for this.
For more details, please see this thread: I think the Adobe Pro XI 11.0.14 update is the reason I'm now getting a script error when I try to save PDFs for SharePoint, anyone else having this problem?
Kind regards
Meenakshi
-
Update a table using COUNT (*)
I was wondering if there is a way to write the following code uses a single stmt:
Kind regards.FOR update_rec IN ( SELECT CODE, COUNT(APPOINTMENT) TOT FROM TEST GROUP BY CODE ) LOOP UPDATE TEST SET TOT_APPOINTMENT = update_rec.TOT WHERE CODE = update_rec.CODE; END LOOP;You can use what is called a statement update correlated . Note that this is not tested:
UPDATE test t1 SET tot_appointment = ( SELECT COUNT(*) FROM test t2 WHERE t1.code = t2.code ) ; -
Update the Table with the push button
Hi I want to update my table using the push button that requires a transfer of account
For example a single account transactions into 2nd account
I used this query, but his does not work
Update of cb
Set cb_acc_id =: block3.acc_id_target
where
cb_acc_id =: block3.acc_id_source;
Concerning
Wasim IsmailYou may forgot to validate your update...
BTW:
your form will not recognize, you start a transaction and make an update in the database. -
Aggregattion and function of pipeline
Hi all)
I need use this statement in sql as follows
Select sum (a.value) of (table (pipeline_function ()))
and in this case, I have a few questions if the piplene function works other 10 seconds. (This function get data through WebServices)
Someone uses the function of PipeLine in the grouping feature? You know some workarounds or tricks to work with this case?http://Essbase.ru/ wrote:
I need use this statement in sql as follows
Select sum (a.value) of (table (pipeline_function ()))
and in this case, I have a few questions if the piplene function works other 10 seconds. (This gunction obtain data through WebServicres)Someone uses the function of PipeLine in the grouping feature? You know some workarounds or tricks to work with this case?
How can you make faster in PL/SQL when the majority of the time is very probably pass through the remote web service doing what it must provide this stream of http data and that the data flowing in the network infrastructure?
To resolve a performance problem, you must first know WHAT is the problem. No use to try to resolve the PL/SQL code when the network is slow. No use to try to resolve the network when the remote web service is slow in providing data.
It is premature to put then the performance problem at the door of the PL/SQL code. I expect the web service and the network to contribute the most to the elapsed time. But I would like also to isolate and test the performance of each component before deciding how to deal with the problem.
Also keep in mind that aggregation or filtering of the data produced by a pipeline, means on a "raw" SQL data structure It is not indexed. It cannot be partitioned.
If the pipeline is too slow to use interactively, alternatives may be considered as materialized views. Or in the implementation of a data cache local (via the SQL tables) where pipelines previous data in memory cache and where new pipeline applications can check for sets of data set caching to use, instead of hitting the web service.
-
Updating column in the table using forms...
Well Guyz I got my submission today... everything went well... .but yet they want to add IE more features want to donate this application at different times working in the company on different projects... .initailly told me that u have to create this application for just our project, now they use my work to give to other PMsss:(et prendre tout le crédit avec aucun faisait pour moi u n personnes m'a beaucoup aidé dans la construction de cette application...) Well, they want to create an application where they can change some columns... that is to say over write the existing value in a column with a new value.
Now, suppose I have col1, col2 in the table paymast, how should I proceed to create trigger for when I press the button on the form is updated to the number of given employee (I want to say if enter the respective information for the particular EMP as soon as I press the button the old values shud b replaced by new values...)
A method that I have noe is to use the wizard to create the form n, and then enter the value of the respective areas of the column to be updated n, then press F6 DB... .i do not want to use this function...
I want to update the application by pressing the button
soon :)
Published by: Chase Suhail on Nov 15, 2009 12:26 AM
Published by: Chase Suhail on Nov 15, 2009 12:29 AM
Published by: Chase Suhail on Nov 15, 2009 12:30 AM
Published by: Chase Suhail on 15 Nov 2009 02:05I don't know a lot of your application, but if you build it near standard forms (e.g. base your blocks on the tables), then its standard Frédérique you type the new value in the field and press save. the button... do you want to the "economy"? then put a DO_KEY ('COMMIT_FORM'); in it.
-
I have been using the functionality of Firefox in which I could have multiple sets of tabs open, but only see the game I was working with. I have updated and now the feature disappeared. I had a small icon on the top right of my toolbar. I used it all the time to keep windows separated for financial, plans to travel items, news, etc.. Has it been removed from Firefox?
Hello
The feature of tab groups is always present. You can try with the button right of the + after the last tab and Customize. If the icon is hidden behind the other, or if it is available inside the mini window customize, you can put it back. If the problem persists, you can also try of reset toolbars and controls: and start to make changes and restart in Safe Mode screen.
-
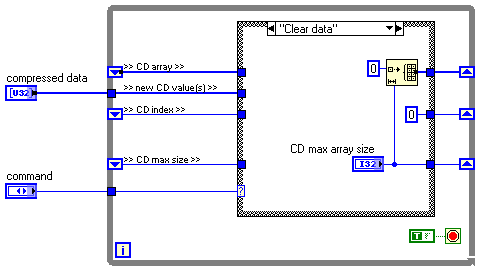
Global functional table uses 2 x initialized space?
I had a thread going on the reduction of the memory allocation on our LabView RT system located here for reference http://forums.ni.com/ni/board/message?board.id=170&thread.id=413552 .
I use a global functional / Action engine to add to a U32 table that I'll be back to our FPGA PXI via DMA reads cards. In order to keep the determinism, for the first time this table through the AE to its maximum size (18Million). During my debugging process, I decided to run the 'Performance and Memory '. When I put the number of elements to initialize to 18,000,000 I expect the performance tool to show me that this VI takes over 18 000 000 * 4 bytes = 72Mbyte. However, after this VI running by clicking on the button instant I see this VI meet twice as many 144Mbyte, extactly!
Then I ran the tool to 'See the distributions of buffer' and with 'Tables' checked, I see a black dot on the table to initialize primitive and a black point on the passage of the leftmost register. By clicking on the button "help" in this tool I see it say under the table section "to avoid abuse of global and local variables when working with arrays. Reading of a global or local variable causes LabVIEW to generate a copy of the data. "This must be what happens now, but how am I supposed to store these data with the flexibility of an adverse event and do not have an extra copy floating around?
Here is the part pertient EI for your reference:
Hello
When you use the function "Initialize the array", you create an additional table. Use the function "Remodeler Array" reuse the already existing table. See attachment.
-
What API can be used to update the table cs_estimate_details (repair)
I need to update the columns 'pricing_context' and 'pricing_attribute1' in the cs_estimate_details table.
Which API can be used to update the columns. Where can I update the table directly?
Try to use this "CS_Charge_Details_PVT" which in turn call "CS_ESTIMATE_DETAILS_PKG".

Maybe you are looking for
-
Hola, tengo a imac 27 "Core i5 Intel con cuatro nucleos has 3, 1 mhz, 2011 con tarjeta grafica Radeon 6970 M, Pronto al trabajar en photoshop is empezo a apagar the pantalla, luego actualice a mac osx sierra y al iniciar the pantalla sale verde, is l
-
Should I uninstall Firefox and start over? Perhaps there is a file in the settings of the profile that has changed?
-
after upgrade to version 15 or 16, I can't open my https sites that are signed by my CA
My CA certificate has been imported to Firefox for centuries. I have had no problems to open my secured sites. After the upgrade from 15 to 16, I started to receive warnings from unreliable connections. The certification authority: -----BEGIN CERTIFI
-
Equium A210-1AS screen goes suddenly blank
Hello I got my Equium for about 6 months and from time to time so that I use the screen goes suddenly blank.It may be while it is plugged in or during the use of the battery. It doesn't seem to be a special moment happen. Blue light 'on' poster still
-
I accidentally placed window off screen and can't get it back
While moving Messenger on screen, windows froze and when she came back I had pushed the window messenger off the screen and now I can't get it back.