little analytical challenge SQL - data production
Hello worldI would like to calculate a LOV which lists a number of options % depending on incoming of a certain value.
That is to say, the most long duration, more options to annotate % completion.
3 return lines 33, 67, 100
4 would be at 25, 50, 75, 100
and so on
I started with
select tot, round(sum(tot/cnt) over (order by lvl rows unbounded preceding)) perc
from (
select 100 tot, level lvl, count(*) over (order by null rows between unbounded preceding and unbounded following) cnt
from dual
connect by level <= 4 -- this value may vary
)with data as (select 4 qty from dual)
select 100, round(sum(100/qty) over (order by level rows unbounded preceding)) perc
from data
connect by level <= qtyI'm still deciding if I want to include a line for zero, but it would be useful to consider it as an option.
Scott
Why not just diveid?
select 100,round(100/qty*level) perc
from data -- or use DUAL directly
connect by level <= qty
And to, 0
select 100,round(100/qty*(level-1)) perc
from dual
connect by level <= qty +1
Published by: JAC on March 12, 2013 15:07
Tags: Database
Similar Questions
-
The maximum size of the model in SQL Data Modeler?
Hello
The number of objects is the maximum value that can be used in a model in SQL data maker. I reverse engineered a scheme (see previous posts - thank you to all that helped) which contains 1000 + tables (a candidate for remanufacturing if ever I saw a!) but the Data Modeler is struggling to display them and performs very slowly. I can pull the same schema in the Oracle Designer and that works well, as ERwin-t - y at - it something I can do to improve the performance of the Data Modeler?
Or people would recommend cutting the model into smaller pieces, which will be a little difficult because it's a bit of a rat's nest.
John
Hi John,.
You can try to fix the memory usage - Re: problem of memory with large model
And you may have better performance if divide you large diagram in subviews.
Philippe
-
Does not not for java.sql.Date sort field
Hi Experts ADF,
JDev version 11.1.1.7.0
I use a POJO based datacontrol, who is dragged like a table on page JSFF. One of the field is a java.sql.Date data type in POJO.
So for example in the table 4 values are there to this date field as
2.2.2014
3.2.2014
31.1.2014
to 31.12.2013
So while sorting in ascending order, it should come as below
to 31.12.2013
31.1.2014
2.2.2014
3.2.2014
And vice-versa.
But if I click on sort it sorts by the first 2 digits only, and I'm under results for sorting (ascending)
2.2.2014
3.2.2014
31.1.2014
to 31.12.2013
Please suggest on this. Thanks in advance.
Thank you
Animesh
Hi This sorting has been solved by changing of java.util.Date.
Yes his watch to the client as an outputText inside the table. Sorting option is there for af:column.
Thank you
Roy
-
Hello world
During playback of Oracle ADF Real World Developer's Guide, I noticed the dates match occurring in JDeveloper is different from what is the list in the book. JDeveloper is failing to oracle.jbo.domain.Date, but according to the book:
DATE java.sql.Date DATE type is mapped to java.sql.Date if the column in the table is a no time didn't need information zone. DATE java.sql.Timestamp DATE type is mapped to java.sql.Timestamp if the column in the table has a component "time" and that the client needs to zone information. TIMESTAMP java.sql.Timestamp The TIMESTAMP type is mapped to java.sql.Timestamp if nanosecond precision is used in the database. In general, is it better to use java.sql.Date and java.sql.Timestamp instead of oracle.jbo.domain.Date? Using java.sql.Date and java.sql.Timestamp could save me some headaches conversion date. And, is there a place in JDeveloper to display these maps? I looked around and didn't see anything.
Thank you.
James
User, what version of jdev we are talking about?
In GR 11, 1 material versions db types date and timestamp are mapped to types of domain data that represents a wrapper for the native data types. The reason was that the framework can work with the domain types regardless of the underlying data type.
Since Oracle 11 GR 2 maps the types DB to java types (default selection, you can change it when you create a model project, you can set the Data Type Mapping). Once the pilot has business components define you cannot change this setting it would break existing components such as eo or vo.
So if you are working wit 11 GR 1 subject, you must use the domain types, if you work with GR 11, 2 or 12 c, you can use the domain types, but it is recommended to use the java type mapping.
Timo
-
Problem with the two EA DEVELOPER SQL DATA MODELING 3.0.0.665 and 3.1
I created a model of very large data using SQL Developer data 3.0.0.665 and 3.1 EA maker. Its having a lot of check constraints. Whenever I am the design of the fence and the DOF and reopening export to import the DDL file failure to import completely check constraints. It is important to check constraints, but without any range of values inside. Its very frustrating because whenever you open import ddl, you must manually add again all the details of data check range constraint.
OS: Windows XP.
Check in the two EA Developer SQL Data Modeler 3.0.0.665 and 3.1
-------------------------------------------
Here are the contents of the .dmd file.
-------------------------------------------
* <? XML version = "1.0" encoding = "UTF - 8"? > *.
* < OSDM_Design class = "oracle.dbtools.crest.model.design.Design" name = 'Admin_Panel' id = "9BE18B0A-6C67-2E5B-00DE-BD8312189ECB" version = "3.41" > * "
* < createdBy > administrator < / createdBy > *.
* < Createduserid > 2011-10-17 08:32:18 UTC < / Createduserid > *.
* < Admin_Panel ownerDesignName > < / ownerDesignName > *.
* < false capitalNames > < / capitalNames > *.
* < designId > 9BE18B0A-6C67-2E5B-00DE-BD8312189ECB < / designId > *.
* < / OSDM_Design > *.
-------------------------------------------------------------------------------
An example how the check constraints to get dirty.
-------------------------------------------------------------------------------
Initial check constraint is as below:
======================
ALTER TABLE test_table
ADD CONSTRAINT Active_Flag_ck
CHECK (Active_Flag IN ('A', 'I'))
*;*
Below how it occurs once I have imported the ddl and re-export:
============================================
ALTER TABLE test_table
ADD CONSTRAINT Active_Flag_ck
(CHECK)
*;*
I'm in trouble as I already in the middle of the my development using SQL Developer Data Modeler.
Please help me soon.
JeanHi John,.
Every time I'm fence design and export the ddl and reopening through the import of the DDL file
Why are you doing this? Once the DDL file is imported and then save the drawing and open simply saved design, no need to generate the DDL and import it every time that you start Modeler data.
On the list of values - forced as this CHECK (Active_Flag IN ('A', 'I')) are imported as constraint check plain and not as a list of values.
There are the more specific elements import of check constraint - they are defined as type database constraint that you select during the import. Accordingly if you import your DOF as Oracle 10 g DDL, then you will get forced correct check in DDL generated for Oracle 10 g and Oracle 11 g. Constraint of evil will be generated for Oracle 9i. You can move the constraint for Oracle 9i (in the check constraint dialog box) or generic if it can be treated as such constraint.I logged for DOF bad bug.
Philippe
-
java.lang.ClassCastException:String cannot be cast to java.sql.Date
I have a date component. MinValue named Id2 and the following code is to run a class cast exception indicating that the string value cannot be cast to a date sql
java.sql.Date dateNeeded = (java.sql.Date) this.getId2 () .getValue ();
can someone help me to overcome this problem.
Thanks and greetings
Janak
Published by: new_to_ORACLE on February 18, 2011 16:56
Published by: new_to_ORACLE on February 18, 2011 16:58the Date attribute is of type object oracle.jbo.domain.Date
so, first try to cast to oracle.jbo.domain.Date. then to java.sql.Date objectIf you need to cast to another Date object, see this site:
http://www.ecotronics.ch/webdesign/javadate.htmPublished by: M.Jabr on February 19, 2011 11:53
-
Problem with analytical function for date
Hi all
ORCL worm:
Oracle Database 11 g Enterprise Edition Release 11.2.0.2.0 - 64 bit Production
PL/SQL Release 11.2.0.2.0 - Production
"CORE 11.2.0.2.0 Production."
AMT for Linux: Version 11.2.0.2.0 - Production
NLSRTL Version 11.2.0.2.0 - Production
I have a problem with the analtical for the date function. I'm trying to group records based on timestamp, but I'm failing to do.
Could you please help me find where I'm missing.
THXThis is the subquery. No issue with this. I'm just posting it for reference. select sum(disclosed_cost_allocation.to_be_paid_amt) amt, substr(reference_data.ref_code,4,10) cd, to_char(external_order_status.status_updated_tmstp, 'DD-MON-YYYY HH24:MI:SS') tmstp, DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID id FROM Deal.Fee_Mapping_Definition , Deal.Fee_Index_Definition , Deal.Fee_Closing_Cost_Item, Deal.Closing_Cost, Deal.Document_Generation_Request, deal.PRODUCT_REQUEST, deal.External_Order_Request, deal.External_Order_Status, deal. DISCLOSED_CLOSING_COST, deal.DISCLOSED_COST_ALLOCATION, deal.reference_data WHERE Fee_Mapping_Definition.Fee_Code = Fee_Index_Definition.Fee_Code AND Fee_Index_Definition.Fee_Index_Definition_Id = Fee_Closing_Cost_Item.Fee_Index_Definition_Id AND Fee_Closing_Cost_Item.Closing_Cost_Id = Closing_Cost.Closing_Cost_Id AND CLOSING_COST.PRODUCT_REQUEST_ID = Document_Generation_Request.Product_Request_Id AND closing_cost.product_request_id = product_request.product_request_id AND Product_Request.Deal_Id = External_Order_Request.Deal_Id AND external_order_request.external_order_request_id = external_order_status.external_order_request_id AND external_order_request.external_order_request_id = disclosed_closing_cost.external_order_request_id AND DISCLOSED_CLOSING_COST. DISCLOSED_CLOSING_COST_ID = DISCLOSED_COST_ALLOCATION.DISCLOSED_CLOSING_COST_ID AND Fee_Index_Definition.Fee_Index_Definition_Id = Disclosed_Closing_Cost.Fee_Index_Definition_Id AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id = Reference_Data.Reference_Data_Id AND Document_Generation_Request.Document_Package_Ref_Id IN (7392 ,2209 ) AND External_Order_Status.Order_Status_Txt = ('GenerationCompleted') AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id IN ( 7789, 7788,7596 ) AND FEE_MAPPING_DEFINITION.DOCUMENT_TYPE_REF_ID = 1099 AND Document_Generation_Request.Product_Request_Id IN (SELECT PRODUCT_REQUEST.PRODUCT_REQUEST_id FROM Deal.Disclosed_Cost_Allocation, Deal.Disclosed_Closing_Cost, DEAL.External_Order_Request, DEAL.PRODUCT_REQUEST, Deal.Scenario WHERE Disclosed_Cost_Allocation.Disclosed_Closing_Cost_Id = Disclosed_Closing_Cost.Disclosed_Closing_Cost_Id AND Disclosed_Closing_Cost.External_Order_Request_Id = External_Order_Request.External_Order_Request_Id AND External_Order_Request.Deal_Id = Product_Request.Deal_Id AND product_request.scenario_id = scenario.scenario_id AND SCENARIO.SCENARIO_STATUS_TYPE_REF_ID = 7206 AND product_request.servicing_loan_acct_num IS NOT NULL AND product_request.servicing_loan_acct_num = 0017498379 --AND Disclosed_Cost_Allocation.Disclosed_Cost_Allocation_Id = 5095263 ) GROUP BY DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID, External_Order_Status.Status_Updated_Tmstp, Reference_Data.Ref_Code, disclosed_cost_allocation.to_be_paid_amt order by 3 desc, 1 DESC; Result: 2000 1304-1399 28-JUL-2012 19:49:47 6880959 312 1302 28-JUL-2012 19:49:47 6880958 76 1303 28-JUL-2012 19:49:47 6880957 2000 1304-1399 28-JUL-2012 18:02:16 6880539 312 1302 28-JUL-2012 18:02:16 6880538 76 1303 28-JUL-2012 18:02:16 6880537 But, when I try to group the timestamp using analytical function, select amt ,cd ,rank() over(partition by tmstp order by tmstp desc) rn from (select sum(disclosed_cost_allocation.to_be_paid_amt) amt, substr(reference_data.ref_code,4,10) cd, to_char(external_order_status.status_updated_tmstp, 'DD-MON-YYYY HH24:MI:SS') tmstp, DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID id FROM Deal.Fee_Mapping_Definition , Deal.Fee_Index_Definition , Deal.Fee_Closing_Cost_Item, Deal.Closing_Cost, Deal.Document_Generation_Request, deal.PRODUCT_REQUEST, deal.External_Order_Request, deal.External_Order_Status, deal. DISCLOSED_CLOSING_COST, deal.DISCLOSED_COST_ALLOCATION, deal.reference_data WHERE Fee_Mapping_Definition.Fee_Code = Fee_Index_Definition.Fee_Code AND Fee_Index_Definition.Fee_Index_Definition_Id = Fee_Closing_Cost_Item.Fee_Index_Definition_Id AND Fee_Closing_Cost_Item.Closing_Cost_Id = Closing_Cost.Closing_Cost_Id AND CLOSING_COST.PRODUCT_REQUEST_ID = Document_Generation_Request.Product_Request_Id AND closing_cost.product_request_id = product_request.product_request_id AND Product_Request.Deal_Id = External_Order_Request.Deal_Id AND external_order_request.external_order_request_id = external_order_status.external_order_request_id AND external_order_request.external_order_request_id = disclosed_closing_cost.external_order_request_id AND DISCLOSED_CLOSING_COST. DISCLOSED_CLOSING_COST_ID = DISCLOSED_COST_ALLOCATION.DISCLOSED_CLOSING_COST_ID AND Fee_Index_Definition.Fee_Index_Definition_Id = Disclosed_Closing_Cost.Fee_Index_Definition_Id AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id = Reference_Data.Reference_Data_Id AND Document_Generation_Request.Document_Package_Ref_Id IN (7392 ,2209 ) AND External_Order_Status.Order_Status_Txt = ('GenerationCompleted') AND Fee_Mapping_Definition.Document_Line_Series_Ref_Id IN ( 7789, 7788,7596 ) AND FEE_MAPPING_DEFINITION.DOCUMENT_TYPE_REF_ID = 1099 AND Document_Generation_Request.Product_Request_Id IN (SELECT PRODUCT_REQUEST.PRODUCT_REQUEST_id FROM Deal.Disclosed_Cost_Allocation, Deal.Disclosed_Closing_Cost, DEAL.External_Order_Request, DEAL.PRODUCT_REQUEST, Deal.Scenario WHERE Disclosed_Cost_Allocation.Disclosed_Closing_Cost_Id = Disclosed_Closing_Cost.Disclosed_Closing_Cost_Id AND Disclosed_Closing_Cost.External_Order_Request_Id = External_Order_Request.External_Order_Request_Id AND External_Order_Request.Deal_Id = Product_Request.Deal_Id AND product_request.scenario_id = scenario.scenario_id AND SCENARIO.SCENARIO_STATUS_TYPE_REF_ID = 7206 AND product_request.servicing_loan_acct_num IS NOT NULL AND product_request.servicing_loan_acct_num = 0017498379 --AND Disclosed_Cost_Allocation.Disclosed_Cost_Allocation_Id = 5095263 ) GROUP BY DISCLOSED_CLOSING_COST.DISCLOSED_CLOSING_COST_ID, External_Order_Status.Status_Updated_Tmstp, Reference_Data.Ref_Code, disclosed_cost_allocation.to_be_paid_amt order by 3 desc, 1 DESC); Result: 312 1302 1 2000 1304-1399 1 76 1303 1 312 1302 1 2000 1304-1399 1 76 1303 1 Required output: 312 1302 1 2000 1304-1399 1 76 1303 1 312 1302 2 2000 1304-1399 2 76 1303 2
Rod.Hey, Rod,
My guess is that you want:
, dense_rank () over (order by tmstp desc) AS rnRANK means you'll jump numbers when there is a link. For example, if all 3 rows have the exact same last tmstp, all 3 rows would be assigned number 1, GRADE would assign 4 to the next line, but DENSE_RANK attributes 2.
"PARTITION x" means that you are looking for a separate series of numbers (starting with 1) for each value of x. If you want just a series of numbers for the entire result set, then do not use a PARTITION BY clause at all. (PARTITION BY is never required.)
Maybe you want to PARTITIONNER IN cd. I can't do it without some examples of data, as well as an explanation of why you want the results of these data.
You certainly don't want to PARTITION you BY the same expression ORDER BY; It simply means that all the lines are tied for #1.I hope that answers your question.
If not, post a small example data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and also publish outcomes from these data.
Explain, using specific examples, how you get these results from these data.
Simplify the problem as much as possible.
Always tell what version of Oracle you are using.
See the FAQ forum {message identifier: = 9360002}Published by: Frank Kulash, August 1, 2012 13:20
-
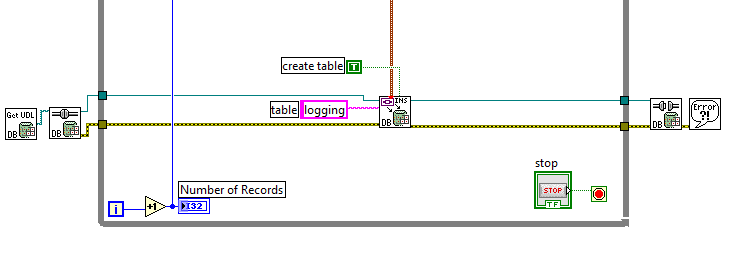
Database and SQL (data logger)
Hi all
I made the database (see photo) to save my data.
Now I want to connect to this database in SQL, but found no example of it on the forum; I read some tutorials but I am little confused with UDL... Second question is where these data are stored on my PC (mdb file)
Thank you.
-
Hello
IM only a beginner in oracle and I have recently started working with XML DB, I read on the XMLType storage models and I think that the structured storage is the best option for the project, our xml data is very structured and has a predictable structure.
I recorded a schema in oracle (im using XE for test purposes) and run this statement:
Start
DBMS_XMLSCHEMA. REGISTERSCHEMA (SCHEMAURL = > 'PRODUCTOS.xsd', SCHEMADOC = > ' <? xml version = "1.0" encoding = "UTF - 8"? >)
" < xs: Schema elementFormDefault ="qualified"xmlns: XS =" http://www.w3.org/2001/XMLSchema ">
< xs: element name = "LISTA_PRODUCTOS" >
< xs: complexType >
< xs: SEQUENCE >
< xs: element name = "PRODUCTO" maxOccurs = "unbounded" minOccurs = "1" >
< xs: complexType >
< xs: SEQUENCE >
< xs: ELEMENT type = "xs: String" name = "i" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "IT" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "quantity" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "Center" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "customer" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "concepto" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "descripcionProducto" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "espacioM2" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "important" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "marca" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "medida" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "modelo" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "package" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "pesoUnitario" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "price" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "reference" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "remolque" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = 'series' > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "UM" > < / xs: element >
< xs: ELEMENT type = "xs: String" name = "valorUnitario" > < / xs: element >
< / xs: SEQUENCE >
< / xs: complexType >
< / xs: element >
< / xs: SEQUENCE >
< / xs: complexType >
< / xs: element >
< / xs: Schema > ', LOCAL = > true, GENTYPES = > true, GENBEAN = > false, GENTABLES = > true,
FORCE = > false, OWNER = > 'TEST');
commit;
end;
/
and automatically created objects:
LISTA_PRODUCTOS451_TAB (LISTA_PRODUCTOS448_T RELATIONAL OBJECT XMLtype STORAGE TYPE)
DESC LISTA_PRODUCTOS448_T-> PRODUCTO (type PRODUCTO450_COLL)DESC PRODUCTO450_COLL-> i ' VARCHAR2 (4000 TANK), THE VARCHAR2 (4000 CHAR), quantity VARCHAR2(4000 CHAR)... valorUnitario VARCHAR2 (4000 TANK).
If I run a select statement on LISTA_PRODUCTOS448_T (by selecting t.getClobVal () in LISTA_PRODUCTOS448_T t) I can see all the data xml, but im confused, I don't know if it is possible to run a traditional sql query and get the data as a simple recordset or if it is necessary to use the functions of XMLtype and procedures using the XPath syntax or something else. I mean why he created all of this?
And besides I don't know how to set the size of the memory of the LISTA_PRODUCTOS451_TAB table, if I try to insert 20 xml nodes in a row, it saves all 20 nodes in a single line and if I try to save 1000 select returns an ORA-06502: digital or value error: character string buffer too small.
Thanks in advance and sorry for my English.
Create a temporary table (or a regular table, but you will have to do the cleaning yourself at the end of the procedure):
create a table temporary global xmltype tmp_xml
binary XmlType securefile XML store;
In the SP, insert the incoming XML document.
Purpose of test, I'll use this simplified version:
1 ABC 10 X 1000234 2 ABC 10 Y 1000234 3 DEF 20 Z 1000234 Then you can use XQuery to access data:
SQL > select x.*
tmp_xml 2 t
3, xmltable)
4 ' / LISTA_PRODUCTOS/PRODUCT.
5 passage t.object_value
path number 6 columns article 'i '.
7 road of VARCHAR2 (3) of THIS 'it '.
8 road number amount 'amount '.
9 road to varchar2 (1) centro "centro".
10 road of varchar2 (30) client 'client '.
(11) x
12;
ARTICLE THIS AMOUNT CENTRO CLIENT
---------- --- ---------- ------ ------------------------------
1 ABC 10 X 1000234
2 ABC 10 Y 1000234
3 DEF 20 Z 1000234
-
SNMP, generic SQL data loader, and built-in Port adapters
Anyone have any success with using the SNMP (default MIB) and/or adapters third generic data SQL Loader?
I'm under vCenter operations v5.7 VAPP and test the custom UI. I have installed the SNMP card, but when adding my own MIB they do not appear in the drop-down list when you try to add a new resource. I followed the docs to update the card with your own MIB files and everything is a - ok until I actually try to add a resource.
I saw this KB:
But I loadded a few different mibs, poking around them in a mib browser, and each of them meet the requirements of that article.
Regarding the SQL adapter. I add my instance of the adapter and the credentials and it tests fine, but when you add the resource to the environment overview screen, the 'Resource Type' dropdown is empty/non-editable. When I click ok, it of course gives me an error:
The field 'type of Resrouce' is a required field. Please enter a value.
Anyone who cross?
Finally, there is documentation for the built-in Port Adapter? There is a very small excerpt in the card Guide:
Reads a text that you set to determine the hosts and ports to monitor.
But... where did you put this text?
Two problems solved.
First of all, the SNMP MIB has not picked up due to permissions on the file that I was transferred to the analytical VM. Duh. Evolution of the property of admin: admin corrects this problem. VMWare has taken this error.
Also found a solution to the question SQL by clicking... the random button it appears that does not refresh the kind of resources until you run an auto-discovery. After crossing the Autodiscover queries, the drop-down list the type of resource is now available from the manual discovery. However, to make changes to the query/discovery files requires another automatic discovery for the changes to be picked up.
-
Because of this problem with the Date format of wire I came with a little challenge.
Consider the following two statements. All were executed in the same 11.2.0.3 session. No other fraud took place.
alter session set nls_date_format=###SECRETDATEFORMAT###; create table mytest (myday date); truncate table mytest ; insert into mytest values (to_date('08/15/2013')); insert into mytest values (to_date('15/08/2013')); select myday from mytest; MYDAY 08/15/2013 15/08/2013Question is: what format mask is entered?
I think that several solutions are possible.
@Kendenny: never say never!
There are several possibilities. MI/ss/yyyy or YYYY/mi/ss would work. Then use HH24 instead of mid or ss.
Justin
-
SQL Data Model 3.0 EA1 trying to create the primary key on OT
Hello
I am trying to change a primary key of a table of the object that has been reversed (imported) from an Oracle 11.2.x RDBMS and get the error message "the incomplete Index Definition. It is displayed in the window "columns transfer Index." I get to the window"properties of primary key 'by pressing the 'Properties' button on the 'table properties'-> 'Primary key'. If I try to change the expression, and then press Ok or apply buttons I get the error. With this be corrected in the production version? That we will be able to create a model in the SQL Developer Data Modeler, which generates a SQL statement similar to the following:
ALTER TABLE x_flags
ADD (CONSTRAINT x_flags_pk PRIMARY KEY (flags.id))
?
Thank you
Scott KHi Scott,.
I am trying to change a primary key of a table of the object that has been reversed (imported) from an Oracle 11.2.x RDBMS and get the error message "the incomplete Index Definition"... With this be corrected in the production version?
Yes
That we will be able to create a model in the SQL Developer Data Modeler, which generates a SQL statement similar to the following:
ALTER TABLE x_flags
ADD (CONSTRAINT x_flags_pk PRIMARY KEY (flags.id))I guess that 'flags' is the type of the object column and 'id' attribute of this type. I logged for this bug, there are however not for 3.0.
Philippe
-
Any SQL data source in Essbase 11 EAS on Linux - help ODBC
Hi all
Oracle Application Server 32-bit 10.1.3.1, Hyperion 11.1.1.3, Oracle 10.2.0.4 64-bit and Oracle Enterprise Linux 64-bit 32-bit
In the data preparation Editor, I am trying to create a rules file. However, when I go to file > open SQL and enter my server/application information, an error is raised: there is no data source is defined. Please create one to continue.
Below is the content of my odbc.ini. When I launch the executable demoodbc (after hyperion/products/Essbase/eis/server/is.sh.) and connect to the db using my name of user and password, the connection succeeds and the query is executed successfully. But for some reason, EE is not able to use the same odbc connection.
I don't know where to look in the determination of this question. None of the sources of data that were originally in odbc.ini (different connections of the wires, etc.) appears in the SQL open either, so...?
Where should I start looking on that?
Thank you!
[ODBC data sources]
kcdbnk = KCDBNK on ORCL102
[kcdbnk]
QEWSD = 40161
Driver=/app/Oracle/product/Hyperion/common/ODBC/Merant/5.2/lib/ARora22.so
Description = KCDBNK on ORCL102
AlternateServers =
ApplicationUsingThreads = 1
ArraySize = 60000
CachedCursorLimit = 32
CachedDescLimit = 0
CatalogIncludesSynonyms = 1
CatalogOptions = 0
ConnectionRetryCount = 0
ConnectionRetryDelay = 3
DefaultLongDataBuffLen = 1024
DescribeAtPrepare = 0
EnableDescribeParam = 0
EnableNcharSupport = 0
EnableScrollableCursors = 1
EnableStaticCursorsForLongData = 0
EnableTimestampWithTimeZone = 0
Host name = linux
Load balancing = 0
LocalTimeZoneOffset =
LockTimeOut =-1
LogonID = username
Password = PASSWORD
Port number = 1521
ProcedureRetResults = 0
ReportCodePageConversionErrors = 0
ReportRecycleBin = 0
SID = ORCL102
TimestampeEscapeMapping = 0
UseCurrentSchema = 1
WireProtocolMode = 1
Published by: JustJames on December 16, 2009 20:36Some positions that may be useful for you
Re: ODBC. INI - Essbase for the Oracle database connection
Re: How to Configure DSN in Linux for Essbase?See you soon
John
http://John-Goodwin.blogspot.com/ -
Essbase Studio Error (1021001): could not establish a connection with SQL data
Hello.
I try to deploy a cube Essbase Studio but I get the error: "* Error (1021001): could not establish connection to the SQL database server."
My environment is Linux 5, Oracle 11 g and EMP 11.1.1.2. Database Oracle and Essbase has been installed with different users. The .bash_profile to hypadmin user (i.e. install Essbase) I put the following variables
ORACLE_BASE=/U01/app/OracleDB/product/11.1.0
ORACLE_HOME = $ORACLE_BASE/db_1
LD_LIBRARY_PATH = / usr/X11R6/lib: $ORACLE_HOME/lib: $LD_LIBRARY_PATH
ORACLE_HOSTNAME = DevBi.sigfe2
PATH = $ORACLE_HOME/bin: $ORACLE_HOME/jdk/bin: $ORACLE_HOME/bin: / sbin: $ORACLE_HOME/opmn/bin: $PATH
ORACLE_SID = orcl
JAVA_HOME=/U01/app/InstallFiles/JDK1.5.0_19
In my pc (windows xp), I can open the Essbase Studio console, the connection to the Oracle server, get the tables and create a minischema of measures and hierarchies (I can see the preview of hierarchies). I also can create cubes with EAS and can connect with MAXSHELL to essbase.
When I try to deploy the cube of Essbaes Studio there get the error ' Error (1021001): failed to establish connection to SQL Database Server.
The Essbase Studio log file says:
+ 12: 40:16 24/07/09 (admin-1) NEWS beginning hierarchical creation in the database "5.4.0.41:1423.POC_ESS. POC_ESS1 '... +»
+ 12: 40:16 24/07/09 (admin-1) FINA signed on Essbase by CSS token "5.4.0.41:1423" successfully... +.
+ 12: 40:16 24/07/09 (admin-1) building INFO Start dimension 'DM_CIUDADES'... +.
+ 12: 40:16 24/07/09 (admin-1) MAS FINA start creating rule file... +.
+ 12: 40:16 24/07/09 (admin-1) INFO SQL statement was created and implemented rule /home/hypadmin/hyperion/products/Essbase/EssbaseStudio/Server/./ess_japihome/data/DM_CIU.rul"+ file «»
+ 12: 40:16 24/07/09 INFO (admin-1) the query is "SELECT (CONCAT ("reg_", CAST (cp_105." ((ID_REGIONPADRE' AS VARCHAR2 (1000))) as 'REGION_PADRE', (CONCAT ("reg_", CAST (cp_105. (("' Be ' AS VARCHAR2 (1000))) as 'REGION_HIJO', cp_105. "' DE_REGION ' as 'REGION_HIJO. Defaults to"GO"POC ". "" Cp_105 ORDER BY DM_REGIONES_ESS3 cp_105. "" CSA DE_NIVEL ', cp_105. "" CSA ID_REGIONPADRE ', cp_105. "' BE ' ASC ' + '.
+ 12: INFO file 40:16 24/07/09 (admin-1) rule has been created and saved as "/home/hypadmin/hyperion/products/Essbase/EssbaseStudio/Server/./ess_japihome/data/DM_CIU.rul"+ ".
+ 12: 40:16 24/07/09 (admin-1) FINA Essbase starts to add members to DM_CIUDADES dimensioin based on the rules file. +
+ 12: 40:16 24/07/09 (admin-1) ADVERTENCIA (1021001): error al set conexion con el servidor SQL databases. Check out el registro for more information. +
+ 12: 40:16 24/07/09 (admin-1) ADVERTENCIA essbaseDriver.FailedToBuildDimensionException +.
+ 12: unexpected exception SERIOUS cubes from 24/07/09 (admin-1) 40:16 + EssbaseExport to be deployed
-Exception-
com.hyperion.cp.datasources.export.essbase.EssbaseDriverException: could not deploy Essbase cube
....
Thank you for everyone who has an idea to help me solve this problem.
A.S.Hello
If you type database SID lowercase, try entering ITO uppercase. Strange, but my colleagues and I encounter this behavior several times.
-
Hierarchical Oracle or MS SQL data
This query to MSSQL
SELECT AreaID , AreaName , AreaSeq , ISNULL(( SELECT TOP 1 t1.AreaName FROM dbo.Area t1 WHERE t1.AreaSeq > dbo.Area.AreaSeq ORDER BY t1.AreaSeq ), '') AS AppearBeforeArea , ISNULL(( SELECT TOP 1 t2.AreaSeq FROM dbo.Area t2 WHERE t2.AreaSeq > dbo.Area.AreaSeq ORDER BY t2.AreaSeq ), -1) AS AppearBeforeSeq FROM dbo.Area ORDER BY Area.AreaSeq;
Gives this result

In Oracle 12 c
Create a Table Script:
create table Area( AreaID Number(5,0), AreaName Varchar2(50 char) , AreaSeq Number(5,0) );
Insert data:
Insert Into Area Values(1,'Shastri Nagar', 0); Insert Into Area Values(3,'Saraswati Nagar', 1); Insert Into Area Values(2,'Sardar Pura', 2); Insert Into Area Values(5,'Sojati Gate', 3); Insert Into Area Values(4,'Polo Ground', 4);
I tried with this hierarchical query but have no idea how to extract columns of rows child/Leaf;
SELECT AREAID , AREANAME , AREASEQ FROM Area START WITH AREASEQ = 0 CONNECT BY PRIOR AREASEQ < AREASEQ ORDER SIBLINGS BY AREASEQ ;
I use Oracle 12 c;
My Question is can I how ResultSet even return with Oracle query without using the service?
No need for the recursive query... just use an analytic function:
WITH box (AreaID, AreaName, AreaSeq)
(SELECT 1, 'Shastri Nagar', 0 double UNION ALL)
SELECT 3, 'Saraswati Nagar', 1 FROM dual UNION ALL
SELECT 2, "Sardar Pura", 2 FROM dual UNION ALL
SELECT 5, "Door of Sojati", 3 FROM dual UNION ALL
Select the OPTION 4, 'Polo Ground', 4 DOUBLE)
SELECT areaId, name of the area, AreaSeq
, lead (areaName) OVER (ORDER BY AreaSeq ASC) AS beforeAreaName
, lead (areaSeq, 1, -1) OVER (ORDER BY AreaSeq ASC) AS beforeAreaSeq
area
/
HTH

Maybe you are looking for
-
Z1 HP preinstalled: MXM fan/radiator
I still buy a Z1 and before that I have to spend thousands on that I would like to know if I buy the low-end without no graphics machine, there the fan/radiator ready for a card? I'll get a Quadro card later down the track, so I would like to know if
-
How to cancel the purchase of the app?
Hello How can I cancel my purchase? The useless app for me and don't do what I expected. I wrote the message on the page report a problem and asked to cancel the purchase. Now this purchase of the status "pending". App Store does not work for me and
-
Running Windows 7, received 4 BSOD today. Checking through the Device Manager so that all drivers are up to date. 10/03/2014 - unit replaced HDD and RAM.
-
HelloMy main e-mail associated with my Adobe ID account address no longer exists and I would like to change my current email address, but for some reason, my changes will not be saved. Any ideas why or how I could change that? Any help would be great
-
Questions about Enterprise Manager
Hi DBAs,11.2.0.4, RHEL-6, 64XbitCould you please clarify my doubts about EM?(1) can we configure Enterprise Manager (NOT GRID Control) in the database pending?If so, can you suggest any link/doc-id mos pls(2) can us password LOCKING of SYSMAN and DBS