parallel processing
I use LView 8.6.1 and I am very new to LabView. I have two functions completely aysnchronous in a physical machine. The first function looks at temperatures of a couple of Thermistors and runs a PID controller to maintain a setpoint. The second function is running an engine step by step to perform a mixing function has nothing to do with the function of the temperature. Both functions require calls to a set of 3 rd-party of vi, and these vi is integrated in the two parallel loops in a while loop, shown external attachment (generic version due to confidentiality issues). .
When the same VI is used in both loops, I have them made re-entrant. I added at least 100 mS wait States to each loop displayed to allow the switching of the CPU. I have 2 nuclei and the max machine reports 5% CPU usage. I wired the device configuration and management errors in the parallel between the two loops to avoid the unintentional flow of data series.
I spent hours and hours searching through posts on this forum and others to try to determine how * completely * asynchronous use these two functions and avoiding of upsetting someone, but no matter how I do it, it seems that some level of dependency is created between the loops. This can be seen because the loop faster (temperature) ends correctly, but then is forced to wait until the iteration of the slower loop to a conclusion. I got it to a point where the dependence is tolerable (at one point one of the loops has not yet run!, the other dominated the treatment completely) but I would prefer a real independence because of timing related to the façade being insufficient, how it currently works. When the loops run in the first place, they do so at independent rates just as I would like. So independent treatment is possible. That's when a loop ends, he must wait for each other to end before starting. I tried loops clocked with a dedicated CPU core and that has not changed anything. The outer while loop doesn't seem to be the culprit.
Question: it seems that no matter what, some level of control of the running serially is inherent in a multi-threaded data process. Queues, notifiers, semaphores, States, engines machines of the action, event - all seem to link a process to another. Is there a truly independently to address the process completely separated in LabView so that each runs at the rate defined by respective waiting functions and have nothing to do with each other otherwise?
Thank you.
You can run the initialization code before starting all parallel loops using the wire of the error as a means of controlling the flow of execution. See below:
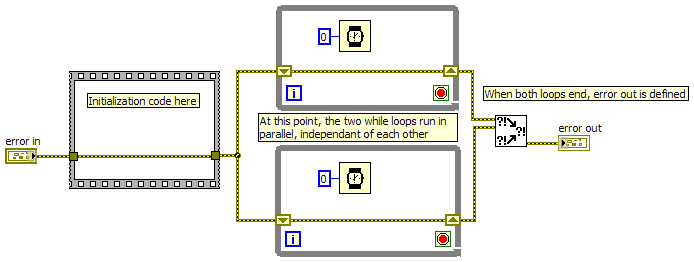
Tags: NI Software
Similar Questions
-
A single button to launch several parallel processes
When I change my template to the parallel process, I see that each process has its own button 'OK '. I would like to have a button to start the process. How should I do this?
Batch processing model can no longer make sense for your situation then.
-Doug
-
Implementation of the synchronization steps without using batch or parallel processing sequences
We use a model of customized integrated process based on sequential process model.
I have to call the Synchronization Manager in order to use the steps of synchronization when you do not use batch or models of parallel process?
All operations (locks, Rendezvous, Notifications, queues, etc.) and the steps of synchronization works in any model or a model, with the exception of the synchronization of the lot.
If you need batch synchronization, your model must use synchronization > advanced > step type specification of batch processing to specify what threads are in the batch. Since you are not from the model of batch processing, I doubt that you have to worry about this.
-
Hello
This question confued me recently, I would use a parallel process of model and to finish running at the same time.
If there are action steps in order, it seemed that will put an end to the execution of all.
However, I put a wait instead of steps of the action function, there are a few executions not interrupted while I pressed the button finish everything in the toolbar.
Hope someone can give me help. Thank you very much.
PS. the number of testsockets has the value 9 in my teststand.
I ran your sequence again, and I have reproduced the issue.
It seems the action of the polls Test for success/failure of the VI at full speed.
It will consume your CPU resource to 100%.
So I add some delay in the VI to prevent election full speed.
Please see the following block diagram.
I tried and it seems resolved the problem.
Ting
-
What happens when two parallel process call the same VI in an FPGA?
Hi all
I was wondering, what happens when say two parallel processes call the same Subvi in an FPGA? I think that the FPGA would create two instances of the Subvi, not sure. Any point of view?
Thank you
Altras
I don't know if the FPGA adds any ordinary special, but in LabVIEW rule and in LabVIEW Real-time, a VI by default is not reentrant. Therefore, a process that is called when it is already in use is blocked and must wait.
If the VI is reentrant, however, then you have two (or more) for the VI dataspaces, so that each can run independently.
-
Prompt the user for a parallel process
Hello
I am developing a software where I constantly read data from equipment. There is a command that requires a password to enter in this software. I tried to use the query the user entry to receive the password for the user. However when the guest user screen opens, my software stops the reading of data from the equipment until the user enters the password. I don't want that. I want to read the data coming from the equipment, while the user inserts the password again.
Is it possible to run the query the user entered a parallel process during execution of the read data part? Is there another way to request a password from the user?
Thank you for helping!
Hi Ariyoshi,
LabVIEW is based on DATA streams. When there is no dependence on the data between segments of code, and then they run in parallel.
Put your password dialog box in a parallel loop...
-
Can we use DBMS_JOB for parallel processing?
Hi all
I wonder if we create 10 jobs each inserts 100 rows in a specific table. Will it be parallel? In other words, please correct me if I'm wrong, when a job starts Oracle does not wait for it until he finished. It run other respectively, right? If this logic is true, then we can use DBMS_JOB and DBMS_SCHEDULER for parallel processing?
Thanks in advance.
Yes, you can use these 2 packets for parallel processing. I suggest using DBMS_SCHEDULER instead, because it is much more powerful than DBMS_JOB. I noticed a kind of latency using DBMS_JOB between the presentation of each batch.
I usually combine DBMS_SCHEDULER with DBMS_ALERT to acknowledge the completion of the work.
As suggested, you can also use DBMS_PARALLEL_EXECUTE. This package uses the dbms_scheduler logic.
-
Unable to capture logs while using parallel processing of ODI
Hi all
I have a requirement to run a same package at the same time in different executions. I used parallel processing in ODI by changes to the physical topology pattern and changing the km.
Execution seems fine. But I am facing problem while capturing errors by using step sqlunload.
I give the query as below
Select the id of E$ _ '#V_Session' _employee
V_Session is a variable of refreshment where I enter the session number
employee is my target table.
This step is to throw an error "SQL COMMAND NOT PROPERLY ENDED"
I tried all the operator of concatenation of sets are also used, but did not work
Any help on this is much appreciated
Thanks in advance
Hello
In the module knowledge IKM, after validation transaction add a step further and place it under code command on the target tab and choose tehcnology as tool ODI
«OdiSqlUnload "-LEADER = D:\LOG_DATA\E$ _ <%=odiRef.getSession("SESS_NO")%>.log '"-DRIVER = oracle.jdbc.OracleDriver "«-URL=jdbc:oracle:thin:@localhost:1521:XE ' '-USER = test" "-PASS = aYyaJAjLcbZAyaAiJMYtdp" "-FILE_FORMAT = VARIABLE" "-ROW_SEP = \r\n" "-DATE_FORMAT = YYYY/MM/DD hh: mm:" "-CHARSET_ENCODING = ISO8859_1" ""-XML_CHARSET_ENCODING = ISO-8859-1 "»
Select * from E$ _ <%=snpRef.getSession("SESS_NO")%>
Note: Change the below set values in above content
-FILE
-PILOT
-URL
USER
PASS
Kind regards
Phanikanth
-
FDM batch Loader - error 5: Invalid procedure or augument - parallel process call
Hi guru FDM.
I am using FDM version 11.1.2.1. I try to use the function in the FDM of FDM batch workbench and received the following errors:
* Start the journal entry for the Runtime Error FDM [2013-06-18 18:32:54] *.
-------------------------------------------------------------
ERROR:
Code............................................. 5
Description... Argument - parallel process ID or 0 = Invalid procedure call
Process... clsBatchLoader.ExecuteProcessShell
The component... upsWBatchLoaderDM
Version.......................................... 1112
Thread........................................... 42428
* Start the journal entry for the Runtime Error FDM [2013-06-18 18:32:57] *
-------------------------------------------------------------
ERROR:
Code............................................. 1000
Description... Parallel process [1] shell could not start
Process... clsBatchLoader.mFileCollectionProcessParallel
The component... upsWBatchLoaderDM
Version.......................................... 1112
Thread........................................... 42428
-Lot controls in the FDM workbench are as follows:
Batch type - Standard
Level of process - import
Process method - series (I tried both serial and Parallel)
Filename delimiter - _ (underscore stroke)
-Batch file names follow the instructions in the Administrator's guide - < version > _ < location > _ < category > _ < period > _RR.txt (e.g. 1_TESTING_ACTUAL_Q1 - 2012_RR.txt)
-J' also checked and the FDM data in the shared drive folder comes with a complete access control (read/write).
-Batch files have been moved to another file sibiling as OpenBatch with a unique name, but the data could not import into the locations.
-J' also created and launched the script from a web client and the batch workbench.
I look at what has gone wrong... I want to ask you expert advice. Any help would be appreciated, thanks in advance!
Hi all
Thanks a lot for all your response. This issue is resolved as soon as possible and I want to just share what we have done and close this post.
By my team, the FDM Task Manager has not been configured properly for the loader commands to run. Therefore,.
1. to configure the FDM Task Manager
For the file name, such as we would use the description for the period (e.g. T1 - 2012), so
2. we need to enable the setting "Allows a description custom period." (in the Admin--> Configuration); and
3. put the spaces between Q1-2012 in file naming for batch loading (for example, we cannot put
_ _ _Q1 2012 .txt, must be _ _ _Q1 - 2012 .txt) The batch charger works fine now.
-
Hi experts,
I have 30 + files in text format, that contain the partitions of the same table. These partitions can / must go through the same parallel processing and must then be added to one big file.
I would have no problem in designing the transformations in ODI (since I have the SQL code), but I'm looking for "elegant" way solve the problem. By elegant I mean modular, with minimal work replication, etc.
Thank you very much.
Joan1. create a dummy data store in ODI with column structure imitating the structure of your file under file template
2 duplicate this data store in the Oracle model.
3 duplicate the LKM file to oracle using the charger and modify it so that the two target table and data path/file come from options KM (add these options if they are not already).
4. develop an interface with these data banks and new LKM. Use an IKM that makes a straight line create a target table and load without worrying about creating I$ (IKM SQL append seems ideal, but you may need to change in order to ensure that the target table is variable). Use two variables (var2 and var3) to specify the new options in LKM (and if necessary IKM).
5. create a scenario.
6. create an Oracle table that contains a sequence, the target_table_name and the source_file_with_path.
7. create a package, which defines the variable (say var1) to 1, use two other variables to store target_table_name and source_file_with_path based on var1 and call your scenario. Check for error and success, var1 and loop increment.
8. in the end, create your large table with partitions and write an ODI procedure to loop through the tables to the target and make a partition change.This is the more modular approach, I can think.
-
Implementation of a parallel process using DBMS_JOB
Hi all
We use oralce 9.2.0.8.0 d/b,.
There are procedures (3) running for each provider sequentially and inserting/updating of values in different tables
These jobs longer account of the needs both to reduce the time to take for these jobs.
I am using dbms_job to treat this work in parallel so that all tasks will run in parallel.
is that this approach will lock the tables at the level of the table or simply stored?
I can't able to establish the parallel process on planning the tool itself, which is the best approach...?
do I need consider as all other settings before approacing... ?
Thank you
ARD986803 wrote:
If two different jobs insert 2 different rows in the same table then so there is no problem locking?If you have a table with no index, no trigger, etc. two sessions making INSERT operations are never blocks between them. If you have no trigger, no index bitmap and you can ensure that only unique index on the table is a column on which no two sessions will never be in conflict, the two sessions does not block each other.
I am a little concerned by your description of the index, however. It does not seem logical that something like unique VENDOR_ID otherwise than in the VENDOR table. You say that each session has a different VENDOR_ID which seems to imply that there are only 3 values VENDOR_ID (one per post). Which implies that he can never y 3 rows in the table (one per VENDOR_ID) which seems unlikely in particular where you plan jobs running in parallel.
Justin
-
Multi-threading parallel processing of stored procedures
Hi guys,.
I have the following scenario, and I would like to realize parallel processing to increase the performance of data refresh:
Stored procedure "SP1" - refresh table A
Stored procedure 'SP2' - Update table B
Stored procedure "SP3" - updates table C
I would like to be able to update table A, B and C table at the same time, could someone help me identify ways in what could be achieved if something like this is possible?
I use collections in stored procedures SP1, SP2 and SP3 to accelerate the time to refresh table, although would like to know how parallel update tables.
I have briefly heard the dbms_pipe package, which would be useful in this scenario?
Thank you
Rohanrbha4 wrote:
I use collections in stored procedures SP1, SP2 and SP3 to accelerate the time to refresh table, although would like to know how parallel update tables.
As already mentioned - perform these distinct process procedures in planning jobs. DBMS_JOB and DBMS_SCHEDULER interfaces can be used. If the work queue manager supports (has been configured) with 3 or more processes working slots and these are empty and not used, then all the 3 procedures can be performed in parallel.
This can be as simple as running the following anonymous block to schedule 3 jobs for immediate execution:
declare jobID number; begin DBMS_JOB.Submit( jobID, 'procA;', sysdate ); DBMS_JOB.Submit( jobID, 'procB;', sysdate ); DBMS_JOB.Submit( jobID, 'procC;', sysdate ); commit; end;I have briefly heard the dbms_pipe package, which would be useful in this scenario?
Only when the IPC (Inter Process Communication) is required only if the database pipes best fits this requirement.
-
What views of $ v can I use to monitor the parallel process?
Hi all
The version of DB is 11.1.
I ran a sql in parallel. And I got the SessionID for the session.
But when I referred to v$ px_session, v$ px_process or sql_monitor $ v even with this session id, I have nothing from these points of view.
The exectuion plan showed that it used parallel exectuion.
Could someone tell me what is the problem with my approach? Or it means that my sql has not used the parallel at all?
Best regards
LeonPARALLEL_MAX_SERVERS to 0 for the database instance. Confirm that there are no PX processes running on the instance of database (these would be process "ora_p0xx_SID", where xx is 00 to 99 (or 128)) on the server.
Then set PARALLEL_MAX_SERVERS to 8 or 16 or more.
Run your query/dml.
Now, see if the ora_p0xx_SID process has created.
Hemant K Collette
-
Parallelism; How many parallel processes can begin?
DB version: 10.2.0.4
OS: Sun SPARC 5.10
I want to do Oracle parallel features such as
I want to know the maximum number of processes I can spawn to do things like above. Is there an init.ora parameter I could check?EXEC UTL_RECOMP.recomp_parallel(4); -- Recompile all objects in the DB CREATE TABLE xx2 NOLOGGING PARALLEL 4 AS SELECT * FROM xx;Hello
It's 10.gR2 documentation:
PARALLEL_MAX_SERVERS specifies the maximum number of processes to run in parallel and processes of parallel recovery of an instance. As demand increases, Oracle increases the number of process the one created at the start of the proceeding up to this value.Husbands
-
parallel processing: for loop taking place
Hallo,
I have a loop 'for' runnin on this system: LabVIEW2009, windows7, intel i7.
I wonder if and how I can tell to LabVIEW that he would be allowed to run different iterations of the loop at the same time (concurrently) on my processor with 8 cores.
Now, it will execute the next iteration when it ended the previous, even one so is there no dependencies in iterations.
I want to give a 'ownership' of the loop, which means that it can be "unfolded" for parallel execution.
Thank you
Pier
pop up on for loop and select "configure interation Prallelism."
Activate it.
Wire a certain number to the new 'P' of entry to specify how many processors to spread it everywhere.
Ben
Maybe you are looking for
-
Satellite L300 - nothing happens if I start the recovery disk
I have a laptop of 1AS L300 Satellite equipped of Vista and I want to restore configuration as when purchased. I created 2 DVD restore discs when the first program installation.When I boot from the DVD drive with restore discs, I get to choose the la
-
Hi people, I have a project in VB. NET (VS2010 specifically), which has been updated from an old VB6 project. The old project use Niglobal.bas and Vbib - 32.bas to communicate with the GPIB plugged into one of our litters.Now in the 64-bit Win7 with
-
Use of memory in a while loop with a xy chart
Hi all I have problems using memory with a vi that loops, records data and plots in a xy running chart. I wrote it using shift registers and functions "subset of the table", which I assumed would reduce overhead costs, but apparently this is incorre
-
Ideas: Programma u lapses problems encountered Foutberichten Recent p die u aan uw computer Wat I al geprobeerd om het op clean would you lossenDon't forget not - says is een openbaar due forum private information such as E-mail bericht van telefoonn
-
Z30 on networks blackBerry error message "unauthorized device. #6 "on Z30 MM
Hello, I've been on vodacom then moved to the cell c network but sometimes the phone work and sometimes I get this error message "device not allowed. MM #6 "how I can remove it.