Question about data store more than 2 TB on ESXi 5.5
I have a data store that is currently 2 TB. I need to grow a little bigger for the snapshot space. We run ESXi 5.5. Is there something special I need to do or worry about when adding space to the LUN to make it more 2 TB? It's the first data store that I got is that great so I want to see if there are special considerations.
I intend to go in my SAN management software, increase the size of the LUN and then go to vSphere, rescan storage and add extra space for the data store.
Thank you!
Who should do - the only isssue is if it is a VMFS (improved VMFS3) legacy data store that is my understanding evan if he has been upgraded to VMFS5 you will not be able to go beyond 2 TB.
Tags: VMware
Similar Questions
-
ESXI 4.1, 348481 Question about data store, not be able to use all the free space?
I am working on installing ESXi 4.1 on a Dell R710 with 3.7 to with SATA, RAID 5 disks. My problem is when I'm going to create my store of data it shows I have 3.7 TB of free space. I told him to use all but the data store comes out 1.63 TB. I deleted that and made a 1 TB data store, but when I went to create a new one he would not give me the ability to use the remaining free space. I'm really green when it comes to the implementation of VMWARE for any help would be greatly appreciated.
Thank you, Don
Hello.
The maximum size for a single volume must be 2 TB - 512 bytes, as described in KB 3371739. Use the RAID Dell utilities to carve up the storage volumes of that size or smaller.
Good luck!
-
Hi Please specify me the system requirements so that I don't have tables and data on more than 20 billion?
SET ECHO OFF;
SET FEEDBACK OFF;
SET SERVEROUTPUT ON;
GAME CHECK
SET PAGES 0;
ALIGN THE HEAD
Set linesize 200 trimspool on
the value of colsep «,»;
SELECT 2013 AS YEAR, 3 AS A PERIOD, 'RQ' AS PERIOD_TYP, 'SRVC_DT' AS ANALYSIS_TYP, NO_MEM_SRVCD AS MLTS_TYP, SRVC_CATG_CDE, SRVC_SUB_CATG, SUM (COST), SUM (NO_CLAIMS) AS NO_CLAIMS, SUM (NO_MEM_SRVCD) AS 'NMLTS '.
OF ICUSER. CLAIM_DETAIL, ICUSER. SSCATG_SCATG_MAP_MSTR
WHERE SRVC_SUB_CATG = SRVC_SUB_CATG_CDE
AND ((YEAR_SRVC = 2013 ET MONTH_SRVC))<=>
OR (YEAR_SRVC = 2012 AND MONTH_SRVC > = 10))
GROUP HERE 2013, 3, 'RQ', 'SRVC_DT', 'NMLTS', SRVC_CATG_CDE, SRVC_SUB_CATG
COIL C:\Users\ATCS23\Desktop\Sql_Ldr\testscript10.txt
/
spool off
You may need to adjust the number of linesize.
David Fitzjarrell
-
Data store is no longer visible in ESXi 5.0
Hello
I'm running the ESXi 5.0 and I recently updated. I have a Dell PowerVault MD3200 connected, and a running data store called "Storegrid '. I had extended hard disk MD3200 to 2.73 to space a few weeks without question or problem. A few days ago, I tried to increase the size of the data store 'Storegrid' to include the size of the entire disk, previous size was 1.8 to. I received an error message indicating that the operation has failed and has noticed that the data store is more listed. I've attached screenshots showing the list of data stores and the list of storage adapters. Any idea?
Thank you!
I just did some testing in my lab, reproduce your problem. It worked as planned, however I don't test the integrity of all virtual machines on this data store. Assuming that the host ESXi 5.0 is the only host access the data store, a possible solution could look like this:
- resize the VMFS partition "lost" to a size > 1.8 to (~1.9 TB) to ensure that the 'old' end of partition is included
partedUtil resize 1 128 4080219008 /vmfs/devices/disks/naa.6782bcb0003ec6c6000002364e5797e0 - in the vSphere Client, perform a rescan (if the datatstore appears as invalid, wait a few seconds, then click Refresh)
- If the data store becomes available, plan to run a full backup of the VM before
The following steps should be done only, if no older than 5.0 ESXi host requires access to the data store.
- Select the data store, and then click the link to upgrade to VMFS-5
- Click with the right button on the data store, select Properties, and click the button increase to grow the data to the full size LUN store
Yet once, I did in my lab. I always recommend to open a call with VMware.
André
- resize the VMFS partition "lost" to a size > 1.8 to (~1.9 TB) to ensure that the 'old' end of partition is included
-
Should what data type I use to store more than 4000 characters in a column
Hello friends,
I am currently using the suite oracle version for my database:
SQL > select * from v version $;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.1.0.6.0
PL/SQL release 11.1.0.6.0
SQL > create table clobexample (clob t1);
SQL > insert into clobexample values ('aaaaaaaaaaaaaaaaaaaa... ») ;
Error in the command line: 2 column: 8
Error report:
SQL error: ORA-01704: string literal too long
01704 00000 - "string literal too long."
* Cause: The string literal is longer than 4000 characters.
* Action: Use a string literal of more than 4,000 characters.
Longer values can only be entered using bind variables.
My request is that what kind of data can I use table to enter more than 4000 characters in the table, I even tried with clob (example) above, but it is not favourable.
Is there another way of letting?
Please help me.
Thank you in advance.
Kind regards.Hello
You can use the same CLOB, but you cannot insert directly, you may need to use the pl/sql.
Try the method mentioned in this link.
http://www.orafaq.com/Forum/t/48485/0/
see you soon
VT
-
Cannot create the local data store more Go 558,75
See attachment.
New installation of ESXi 4.1.0 try adding a local data store. Local volume is a to 4.55 RAID 5, fully initialized.
Add storage
Choose the device, etc. Choose the size of 8MB block and "ability to mazimize. Summary On screen looks like its going to do what I ask... I cliquerai finish.
Produces final is 558,75 Go. Any ideas?
ESX(I) supports no more than a little less than 2 TB LUN. Divide your table into smaller LUNs
-
How to get the data from more than 100 domains in bulk API V2.0?
Hi all
I try to get data from Eloqua by APIs in bulk because of big data.
But my Contact 186 fields (more than the majority of export limitation 100). I think I need to get all the data by 2 exports.
How could I corresponds to 2 parts of a line and join together?
I'm afraid that any change of data between 2 relative to exports 2 synchronizations would make different order.
FOR EXAMPLE:
1. any document is deleted or modified (if it matches do not filter) after obtaining data of the first part and before getting the second part, then everyone behind it would have back in part result.
2. the data in some fields (included in both parts) are changed between the 2 synchronizations, then the values of the second part are more recent but the values of the first part are old.
All suggestions should.
Thank you
Biao
bhuang -
I don't know that you ever go to work around the fact that things will change in your database while you are synchronizing the data. You have to have a way to create exceptions on the side of the synchronization.
If I pushed Eloqua data to a different database and had to contend with the problem of matches change while I'm syncing, I would create a few additional columns in my database to track the status of synchronization for this folder. Or create another small table to track the data map. Here's how I'd do.
- I would have two additional columns: 'mapped fields 1' and '2 fields' mapped. They would be all two datetime fields.
- I would do only one set of synchronization both. First of all, synchronize all records for email + 99 fields. Do the entire list. For each batch, the datetime value of the lot in 'mapped fields 1' column.
- I would then synchronize all folders of email + other 86 fields. Repeat the entire list. For this batch of the datetime value of each batch in their 'mapped the 2 fields' column to now().
- For all records that had only 'mapped fields filled, 1' but' fields mapped 2' was empty, I would be re - run the second query Eloqua API using e-mail as the search value. If no results were returned, I would remove the line. Otherwise, update and the value 'mapped fields in 2' now
- For all the records that were only "fields mapped 2', I re - run against the first email query API Eloqua, fill in the missing data and define 'mapped the fields of 1' of the current datetime object." If the record has not returned, remove the line because it is probably not in the search longer.
- Finally, the value 'mapped fields 1' and 'mapped 2 fields' empty for all records, since you know that data is synchronized. This will allow you to use the same logic above on your next synchronization.
Who is? It is not super clean, but it will do the job, unless your synchronizations take a ridiculous amount of time and your great data changes often.
-
Hello
I have over 200 short videos that need:
D ' have trimmed the beginning and the end
D ' have a static title added at beginning and end
-Made in more than 200 separate files.
-Some videos must be split into 2 or more separate videos, with the added titles.
What is the best way to do it?
Now I have to:
-Drag the video in a new timeline with the mouse
-Press on 'C' and cut the ends
-Drag the title in the timeline with the mouse, click on option and move the title to the end
-Sometimes, command-x a clip, creating a new timeline and command + v at the beginning of the clip.
-Make the file
Tiny efficiency I can find: save a mouse click, record a sequence of keys, can lead to hours of recorded time. Any way I can improve this workflow? Thank you very much.
-Neil
Hello
For repetitive tasks like these, I found a lot of success with Keyboard Maestro. It easily allows you to create a macro that can process all the clips on the timeline, after you have registered on a single action.
Use the up/down arrow keys to move the playhead to the beginning/end of a clip, and then use Shift + left/right arrows to set trim distance that then Q & W to cut. You can specify the walking distance front/rear step in the preferences (under playback) If you wish.
To export, you can use the Ctrl key (or is it order?) + low shortcut to select the next clip, use "/" to mark the selection, command + M to open the export dialog box, then count the number of times where you have to hit tab to get, activate the button of "Tail" and press the SPACEBAR to press the button of the queue.
Once you have a macro work, everything should finish in under a minute, even if you have hundreds of clips.
The only thing to watch is to put a pretty decent in Keyboard Maestro between actions break as well as first has enough time to complete each action (usually about 300-400 milliseconds makes the case for me).
This is one of the capabilities of Mac OS X that I have sorely missed under Windows.
Edit: On the titles you mentioned, you can also get a macro goes for it - a few things need to be set in motion for this, but I can see how it can work:
-If each element requires a unique title, you will of course have to create that manually.
-To create your titles, set the duration to default image in the preferences for the duration you need of your titles to be. Each title that you create will be the correct time.
-Set preferences to set the focus on the timeline when you insert/overwrite changes.
-In the creation of securities, their name so that they are sorted in the same order as the clips.
Once you have prepared titles, you can use the up/down arrow keys to position the playhead in the timeline panel, use the Shift + 1 to switch to the project Panel, press down to select the next title then "." key to insert the title (cursor is placed to the timeline, because of the preference has changed and you can use the arrow down to move to the next item and have the macro repeat for you.)
Good luck.
-
Questions about the stores in iProcurement
All,
I have a few questions about the implementation of iProcurement stores-
1 oracle comes seeded with 2 stores "Backend" and "Exchange.Oracle.com. We do not have the use of these stores. I don't see an option to turn them off. Is it advisable to delete them? They occupy unnecessary space and are seen first. I read this on Metalink Note ID 429470.1 - "NOTE: while the value can be changed, it is highly recommended to not under any circumstances ever remove"Main store"page stores to manage content in iProcurement catalog administrator responsibility.» Do not know why.
2. we have a Punchout for Dell U.S. catalog store and a catalog of information for Dell International. Buyers of Dell are iProcurement to each punchout to place their orders from Dell for the USA (shopping cart returns to iProcurement) - or - just use the store Dell International to go to an external URL and place their orders here (who do not return to iProcurement). What we see is - when the user clicks on the icon Dell us, it is taken directly to the URL of the PunchOut of Dell, but when he clicks on the Dell International icon, he was first taken to the list of catalogs available to the store (only 1 available catalog) and the user must then click again on the link Dell International. Is there a way to configure the Dell International icon to behave the way behaves in the Punchout icon - i.e. directly take the user to the Dell page without a need to show the list of catalogs.Hey,.
To answer your Questions
1. you can always delete those either if you want to... The reason why the link Meta Notes say not only not to delete the main store is
i. because main store has all of the Local content in iProcurement (i.e. If you have any installation of items in the inventory you and them Module iProcurement Enabled (IE can be purchased at iProcurement) and any other article of local catalogues/categories Loaded using the BULK LOADING in iProcurement is also removed.)
II. you can always delete the information Exchange Oracle store if you do not use.
I would advise so do not remove the main store. Instead, you can change the sequence of the display of the stores you iProcurement Page.
Browsing ==> Internet shopping Catalog Admin (RESP) ==> eContent crib ==> content management ==> stores ==> press the update sequence and make sure that the sequence number for main is superior to any other store so that the hand store falls last in the House of iProcurement Page2.i don't think that there is no option to do this. but you can always open an SR with Oracle about it and ask this question\
hope that answers your Question.
Thank you
SANTU -
Data store for config files shared with esxi and free license
Hello
currently I am setting up a test environment with two esxi nodes that share a database on an EMC Clariion. Virtual disks itself will be shared by RDM, there is no problem.
But if I change the configuration of a virtual machine to a physical computer (node A) the other (node B) still use the old configuration, node B does not notice the change applied to node A. What I am doing wrong? Is there a set up where node B will automatically refresh the virtual machine configuration after modification on node A?
If I download the file vmx of navigation on the B node data store, I see the applied changes written to the file. So I guess it isn't a caching issue. The vmx file we re - read when turn on/off the virtual machine? Why isn't she re-read on the opening of the vm configuration dialog box?
What is the recommended set for two guests free esxi who should be able to run virtual machines in the other machine? I don't think that of VMotion or HA! I just want if node A has a power outage on some VMs on the node B.
Thank you!
Good bye
Daniel
You must not register VMs on of two ESXi. Installing vCenter or register VMs on host-host these specific VMs will run on. If you need to move the VM to an another ESXi then delete the inventory on the single host and add to the inventory on the other.
---
VMware vExpert 2009
-
LAbview program behind schedule and displays the data arriving more than two minutes ago
I am currently using two OR 6070e daq cards PCI (16 analog inputs on one) which are syncronised in the software. In the producer I loop gain of 32 channels data and do my processing on the data in the loop of the consumer. Each signal is displayed on a waveform graph. I have sample at 32 kHz to my problem is that my software works well, but it lags behind in the necessary time sto updated graphics. More I run the software becomes more lag. For example, data showed the field of waveform if poster both 5 minutes after the due event. Even if I use a lower sampling rate (3 kHz) continues to accuse software. The number of samples, I've read is always a second of data. How can I make this software performing near real time with out such a big lag. I need to run my software on a windows OS. I know that you won't get no hard real-time running labview Windows OS, what can be done to improve the speed of my program.
1. another question on the data sheet of the data acquisition card NOR 6070e PCI indicates the size of the buffer FIFO is 512 S. Why can I in labview set myh size buffer to a value greater than 512 samples. For example when I taste 1000 Hz and read 1000 Hz off buffer I exceed the isze of buffer FIFO data acquisition card, but my program still works.
Cordially (sorry for the spelling error typed this quickly)
the main VI is DP_software
You do not have something interesting to look at.
-
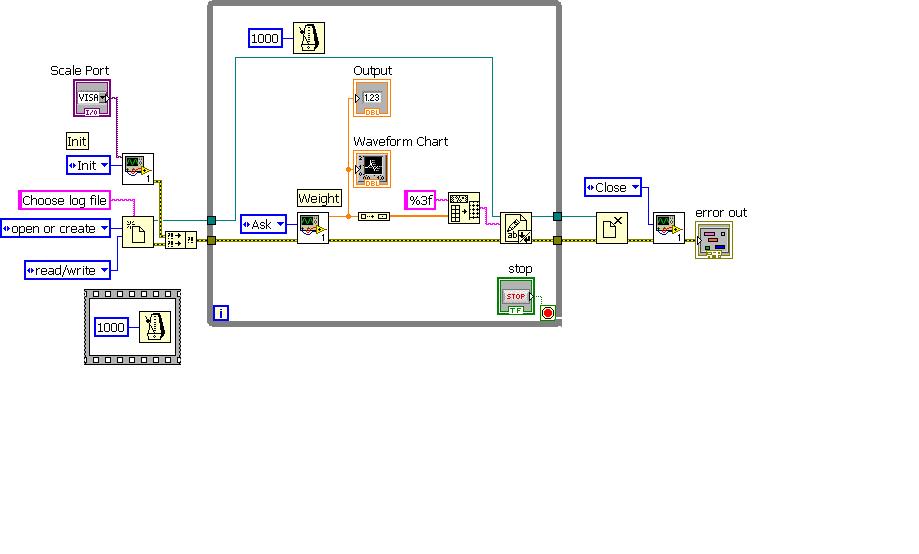
Collection of data from more than an instrument via the same labVIEW program
Hello
I have a program whereby I collect data on a scale of and save the data in the text file. Now, I need to collect data of three identical scales and save the data. I wonder if it is possible to do so in the same program? I mean how to manage three ports and save three different text files?
I enclose the current program. Communication with the scale series and I use VI:s. thanks in advance for the help = VISA)
This is easily possible with a single program, and there are several ways to do so. I recommend the following:
- Take data from these devices in a separate loop (this could be in a separate - VI, as well). These loops should be state machines if you can start and stop the acquisitions in a clean way. This assumes that the instruments are on separate ports. If they are on the same port, you probably want to use the same loop.
- Write to the file in a single loop. This, too, should be a state machine.
- Queues to send data from the acquisition of loops to the loop of file I/O.
- Use still another loop for your user interface. It must contain a structure of the event.
To do this, you will need to learn more about the State machines and producer/consumer architectures. Start with the help of LabVIEW, then search these forums. There are a multitude of implementations of State machines and producer/consumer architectures. If you have the time, I highly recommend you learn and to use the classes in LabVIEW (requires LabVIEW 8.2 or later). This will facilitate your work in the long term.
Let us know if you encounter any problems...
-
How can I do data with more than 72 dpi in loose 8?
When I want to print or send my photos, I get the message that it is printed with less than 220 dpi (in fact it's 70 or 72 dpi). How can I make my data with the normal 600 dpi?
You must resample the image by Image > resize > image size.
Please look at this from the help file:
Note that for printing, it is desirable to have the resolution = 240-300 px / in. If it's a very large print, you can come out with a lower resolution, as the eye of the observer is at a greater distance.
The 220 px/guest to come up now and then, and most of the time I ignore it.
For web work, 72px / is fine.
If you have additional questions, please repost.
-
How to store more than 4000 characters in a table
I have a requirement to store 4000 + string in the table. CLOB and BLOB cannot me because he has limitations of 4000 characters.
Any suggestions please.Pentaho seems based jdbc then look for an example of a jdbc clob insertion.
For example http://www.oracle.com/technology/sample_code/tech/java/codesnippet/jdbc/clob10g/handlingclobsinoraclejdbc10g.htmlThis will probably be a better approach than messing around with blocks anonymous plsql, etc. that do not sound relevant to what you're trying to reach really.
This forum comment made me smile of the 'Integration of data head' @ Pentaho can:
http://forums.Pentaho.com/showthread.php?62231-insert-a-string-in-a-CLOBIt should work just fine. You probably need to swap your JDBC driver or something. Oracle can be mysterious in that dept. xxx xxxxxx, Chief Data Integration Pentaho, Open Source Business IntelligenceReassuring.
-
Question about real store type value in the database on Z10
Hi all
I'm trying to store a value in the database (datatype is defined as REAL), but the result on Simulator and Z10 is totally different, the two of them, the SDK version is the same (10.0.10.672)
on the simulation, the value in the database is correct, like this
Z10, the valve can become bad like this.
Define a type of incorrect data or someone has an idea?
Thank you.
I think I have sloved... the problem before you record a double or real value in the database, convert QString
fenceValue["latitude1"] = QString::number(m_FenceFromJson->m_PointFs.at(0).x(), 'f', 6);


Maybe you are looking for
-
Toshiba Stor.e Partner - cannot find Nero serial number
Hello I try to install my new partner of Toshiba Stor.e 1 TB on my Windows Vista computer and the installation, it asks me a Nero BackItUp 12 Essentials serial number to validate. I assumed it would be the serial number on the bottom of the HARD driv
-
Sony Handycam DCR-SR30E - download software Imagemixer?
Have a Sony Handycam DCR-SR30E. Swapping to new computer and can not find the disc ImageMixer. Options?
-
matter what emulator for development?
Hello I'm using labview in 2013 in development. I have the labview installed in the computer in which the DAQ installed maps. But I'll expand the code in the home computer to which no card installed DAQ. So is there any DAQ device emulator so I can c
-
After trying the dvd player and external hard drive. After completing the course he is coming up with ' the process cannot access the file because it is being used by another process. " can my knowledged be expanded on this topic.
-
blue screen after installing new graphics card
Just install my new geforce gt 240 to replace my 9400gt. After reinstalled vista driver & restart, my system to start start then goes to a white screen for 2-3mins fight & displays a blue screen quickly and then restart & repeat once again. Vista wil