Rebuild all indexes of a table
DB version: 10.2.0.4Rather than rebuild indexes to help
ALTER INDEX index_name REBUILD;y at - it a single command that would rebuild all indexes of a table?
No, but you can use
select 'ALTER INDEX '||INDEX_NAME||' REBUILD' from user_indexes
where table_name=
And you can run this query.
Tags: Database
Similar Questions
-
Re-create all indexes on new data files
Hello
on FSCN 9.2 on Win 2008
We'll re-create all indexes (belonging to sysadm) in the new data files.
-Are there any script or utility to do this?
-can you offer me any scenario?
Otherwise, I think only of:
0-extract DDL for all areas of storage and index.
1-drop tablesapces
2 Create tablespaces (by the DBMS_GETDLL script ('TABLESPACE'...)
3 re-create all indexes (by the DBMS_GETDLL script ('INDEX',...))
4 rebuild all indexes.
Any idea?
Thank you.
of 786997.1
There is no trace of PeopleTools that stores the name of the tablespace for the index.
Here's how to work the tablespaces.
There is a table called PSDDLMODEL where we store the information of DOF model for index and table creation, among other things. DDL models contain a template with replaceable parameters. One of the parameters in the create index Oracle is a field called INDEXSPC. This field by default is PSINDEX.
If you wish to override this value, you can go in the App Designer, open a folder, select Tools-> data Administrations-> select Index to edit the index and then select modify DDL, then select change the setting for the Create Index and Create Unique Index model. This replaces PSINDEX for this record. The name of the underlying table is PSIDXDDLPARM.
If you want to change the default PSINDEX to something else, go to the utilities Menu and use DOF model by default and change the PSINDEX to something else. Once you change this setting, the next time that you create the index, it will be created in the tablespace.
If you create an index in a different tablespace outside PeopleSoft, we have no knowledge of this and do not update our tables in order to take into account where he currently resides. Once you have updated the default template and replaced the records you want to replace, you can make a Data Mover, followed of a Data Mover import export and the index will be created as they have been redefined. Or you can just do a SQL Create Index and re-create all of them.
-
Index rebuild required after truncate the table and load data
Hello
I have a situation that we truncate tables bit and then we loaded data [only content] on these tables. What you need to rebuild the index online is necessary or not?
And another question is if we drop a few clues is the total amount of space is released or not. And re-create indexes will use the same amount of space. As I don't have disk space more? In this situation, rebuild the index online will be a better idea...
Can you please on this...
truncate the table some the few loading tables + reconstruction markings online is the best (or) droping little tables, a few tables loading + re-create the index is better
Can you suggest the best way... We have a time that it currently we don't have enough space on the disk... [Option should not effect the space] user13095767 wrote:
Ok. I have it...
u want to say if we disbale the index while loading... Next, we need to spend the time to build.
If the indexes are enabled, then rebuild again is not necessary after loading tables...
Please answer if my understanding is correct...
above is correct
>
If so, how abt the differences in the space occupied by the spaces of storage during the index rebuild and re-create... T he acquires more space if recreate us [deletion and creation] or rebuild online is preferable to an index...?
space used is the same for all options.
-
Find the table if element have the same element in all indexes
Hello
I need to check if a table have the same element in all its indexes. (Example: an array of size 4, should have index 0... 3 1 and during the next iteration index whether no. 2 overall indexes...) How can I check if all indexes have same number)
Attached to the VI I did.
Anyone can offer better than this.
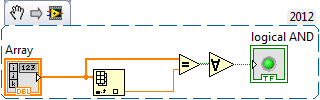
get the first element, compare it with the hole dashboard, AND all items
-
Shrink the table, rebuild the index?
I need to reduce some very large tables after the removal of lines and I want to validate the script to run. I was thinking something like this:
run_deleting_process;
change the movement line of table my_tableI enable;
ALTER table my_table retractable space WATERFALL;
change the movement line of table my_tableI disable;
I need to rebuild the index after that?, or if I rebuild the markings, can I delete clause CASCADE of the command? It is recommended to run utltrp.sql after shrink the table?, maybe some dependent object needs to be recompiled after the reduction of a table?
The database version is 11.1.0.7 and documentation does not specify that the index rebuild is required, but I realized it is a desition normall when the narrowing of the tables.
Thank you No there is no rebuild the index after shrinkage. And if you use "cascade", your index will be supported. You do very well.
Visit this link as well.
http://www.orafaq.com/Forum/t/137522/2/
-
Capture the Index Rebuild process time in a table
Dear Experts,
I have a stored procedure to rebuild the indexes. I would like to capture reconstruction of start and end time for a table. I created the table with structure below: I am writing an insert statement in the procedure that captures rebuild timings, might well want to suggest how to implement this?
MAINT DESC
Name Null? Type
------------------------------------------- ------------------------------------
OWNER VARCHAR2 (30)
TABLE-NAME VARCHAR2 (30)
START_TIME DATE
END_TIME DATE
VARCHAR2 (200) COMMENTS
CODE PLEASE
=======
CREATE OR REPLACE PROCEDURE "USER1". "" ONLINE_REORG ".
(v_owner IN varchar2, v_tablename IN varchar2) AS
v_rebuild_statement VARCHAR2 (1000);
v_rebuild_statement1 VARCHAR2 (1000);
err_msg VARCHAR2 (100);
v_cdc number (6);
cursor c1 is select master index_name table_name, nom_tablespace
of dba_indexes
where table_owner = upper (v_owner) and
nom_tablespace is not null and
index_type = 'NORMAL' and
table_name = Upper (v_tablename);
BEGIN
DBMS_OUTPUT. Put_line ('Rebuild Index procedure begins execution At' | to_char (sysdate, ' DD-MM-YYYY HH24:MI:SS'));))
FOR c1_rec IN c1 LOOP
Start
v_rebuild_statement: = 'edit index' | c1_rec. Owner: '.' | c1_rec.index_name |' REBUILD PARALLEL 6 LOGGING COMPRESS TABLESPACE ' | c1_rec.tablespace_name;
DBMS_OUTPUT. Put_line(v_rebuild_statement||';');
EXECUTE IMMEDIATE v_rebuild_statement;
exception when others then
null;
end;
Start
v_rebuild_statement: = 'edit index' | c1_rec. Owner: '.' | c1_rec.index_name |' NOPARALLEL ';
DBMS_OUTPUT. Put_line(v_rebuild_statement||';');
EXECUTE IMMEDIATE v_rebuild_statement;
exception when others then
null;
end;
END LOOP;
DBMS_OUTPUT. Put_line ("Rebuild Index procedure completes execution to ' |") TO_CHAR
(sysdate, ' DD-MM-YYYY HH24:MI:SS'))) ;
EXCEPTION
WHILE OTHERS THEN
DBMS_OUTPUT. Put_line ("Rebuild Index ended execution without success to")
' || TO_CHAR (sysdate, ' DD-MM-YYYY HH24:MI:SS'));)
err_msg: = SUBSTR (SQLERRM, 1, 100);
raise_application_error(-20001,err_msg);
END;
-
ORA-14456: can not rebuild the index on a temporary table
change the IND_DEBITDOCUMENT TABLESPACE INDEXDATA index rebuild
*
ERROR on line 1:
ORA-14456: can not rebuild the index on a temporary table
why it is given such error?
Thanks in advance. This information is always kept to user_ | all_ | dba_ tables, in this case in the temporary column.
Obvious, isn't it?
---------
Sybrand Bakker
Senior Oracle DBA
-
Hello
I have unusable a clue. Now I want to rebuild the index for this I have to rebuild the partition and the tablespace in two different command as
Index_name ALTER INDEX REBUILD PARTITION p1;
Index_name ALTER INDEX REBUILD PARTITION p1 TABLESPACE INDX_TS;
now my question is when I run first command and check the index of fof status it shows not usable. In the same way when I ran only 2nd order also rebuild successfully. If I ran only 2nd command works fine?
why it displays usable after only rebuild partition?
I have script for all indexes on user like this
Select 'ALTER INDEX' | index_name |' rebuild partition '. Nom_partition | ';' in USER_IND_PARTITIONS
Select 'ALTER INDEX' | index_name |' rebuild partition '. NOM_PARTITION | 'SPACE '. nom_tablespace | ';' in USER_IND_PARTITIONS Why you set all the indexes to be UNUSABLE?
(Please don't keep saying "unuse index", do you mean "occupies an unusable index"!)
The instance / session SKIP_UNUSABLE_INDEXES setting determines the behavior of DML. In 9i, it is false by default. In 10g, it is by default true. Thus, in the 10g (unless you have changed it back to FALSE), INSERT/DELETE operations can succeed even if an Index is UNUSABLE. However, indexes to enforce PRIMARY KEY constraints or unique indexes (index created in CREATE a UNIQUE or apply INDEX of UNIQUE constraints) cannot be ignored by normal DML.
(Direct path operations automatically update the index and, therefore, can leave clues in an unusable state temporary.) These look like actually to DDL operations and lock the partition table/preventing simultaneous updates).
-
Rebuild the indexes in Win Explorer: old folder back.
I rebuild my index every month. When I do, I get an old folder in the My Documents folder. It appears once I do the reconstruction.
Here's what I do:
Control-> system and Maintenance-> Indexing Options Control Panel
Click on the Advanced button
Re-index selected location: click the Refresh button
Places that have always been selected for reconstruction are:
OneNote
IE
Start menu
Users
The old folder that keeps appearing once completed the reconstruction process is not among the users of--> username--> Documents folder under the location list.
It is not a big problem for me to remove this old issue of each month. But I would like to know what is happening here in case there is something wrong with my system.
I discovered what was going on. I hope it's useful to someone.
I use a software CoffeeCup HTML editor. In the window of the preferences of this application, I had the path to the 'default Web site project folder"pointing to the folder that kept reappearing. When I changed the path to an existing folder, I got is no longer this mysterious folder reappears.
It is logical. The application was create the folder whenever I opened it because he needed new projects.
I also tested this theory by creating a new default folder, delete and then opening the application. He kept creating the folder.
A big "thank you" to all of you who have looked at this and I tried to understand.
-
Partitioned global index on partitioned table range, but the index partition does not work
Hello:
I was creating an index partitioned on table partitioned and partitioned index does not work.
create table table_range)
CUST_FIRST_NAME VARCHAR2 (20).
CUST_GENDER CHAR (1),
CUST_CITY VARCHAR2 (30),
COUNTRY_ISO_CODE CHAR (2),
COUNTRY_NAME VARCHAR2 (40),
COUNTRY_SUBREGION VARCHAR2 (30),
PROD_ID NUMBER NOT NULL,
CUST_ID NUMBER NOT NULL,
TIME_ID DATE NOT NULL,
CHANNEL_ID NUMBER NOT NULL,
PROMO_ID NUMBER OF NON-NULL,
QUANTITY_SOLD NUMBER (10.2) NOT NULL,
AMOUNT_SOLD NUMBER (10.2) NOT NULL
)
partition by (range (time_id)
lower partition p1 values (u01 tablespace to_date('2001/01/01','YYYY/MM/DD')),
lower partition (to_date('2002/01/01','YYYY/MM/DD')) tablespace u02 p2 values
);
create index ind_table_range on table2 (prod_id)
() global partition range (prod_id)
values less than (100) partition p1,
lower partition p2 values (maxvalue)
);
SQL > select TABLE_NAME, SUBPARTITION_COUNT, HIGH_VALUE, nom_partition NUM_ROWS of user_tab_partitions;
TABLE_NAME NOM_PARTITION SUBPARTITION_COUNT HIGH_VALUE NUM_ROWS
----------- ---------------- ------------------ -------------------------------------------------------------------------------- ----------
TABLE_RANGE P2 0 TO_DATE (' 2002-01-01 00:00:00 ',' SYYYY-MM-DD HH24:MI:SS ',' NLS_CALENDAR = GREGORIA 259418)
TABLE_RANGE P1 0 TO_DATE (' 2001-01-01 00:00:00 ',' SYYYY-MM-DD HH24:MI:SS ',' NLS_CALENDAR = GREGORIA 659425)
SQL > select INDEX_NAME, NUM_ROWS nom_partition, HIGH_VALUE user_ind_partitions;
INDEX_NAME NOM_PARTITION HIGH_VALUE NUM_ROWS
------------------------------ ------------------------------ -------------------------- ----------
P1 IND_TABLE_RANGE 100 479520
IND_TABLE_RANGE P2 MAXVALUE 439323
SQL > EXECUTE DBMS_STATS. GATHER_TABLE_STATS (USER, 'TABLE_RANGE');
SQL > EXECUTE DBMS_STATS. GATHER_TABLE_STATS (USER, 'TABLE_RANGE', GRANULARITY = > 'PARTITION');
SQL > EXECUTE DBMS_STATS. GATHER_INDEX_STATS (USER, 'IND_TABLE_RANGE');
SQL > EXECUTE DBMS_STATS. GATHER_INDEX_STATS (USER, 'IND_TABLE_RANGE', GRANULARITY = > 'PARTITION');
SQL > set autotrace traceonly
SQL > alter shared_pool RAS system;
SQL > changes the system built-in buffer_cache;
SQL > select * from table_range
where prod_id = 127;
---------------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time | Pstart. Pstop |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 16469 | 1334K | 3579 (1) | 00:00:43 | | |
| 1. RANGE OF PARTITION ALL THE | | 16469 | 1334K | 3579 (1) | 00:00:43 | 1. 2.
|* 2 | TABLE ACCESS FULL | TABLE_RANGE | 16469 | 1334K | 3579 (1) | 00:00:43 | 1. 2.
---------------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
2 - filter ("PROD_ID" = 127)
Statistics
----------------------------------------------------------
320 recursive calls
2 db block Gets
13352 consistent gets
11820 physical reads
0 redo size
855198 bytes sent via SQL * Net to client
12135 bytes received via SQL * Net from client
1067 SQL * Net back and forth to and from the client
61 sorts (memory)
0 sorts (disk)
15984 rows processed
Once the sentence you say ' does not ' and then you go to paste plans that seem to show that it "works".
What gives?
In fact, if you look at the plans - think Oracle you have 16 k rows in the table and he'll be back k 12 rows for your select statement. In this case, Oracle is picking up the right plan - full scan 16 ranks of k is a lot less work to digitize the index lines k 12 followed by the research of rank k 12 rowid.
-
CTXCAT index on partitioned tables
Hi all
I use an oracle 11.2 database and try to use the index for a sample application oracle CTXCAT.
I saw that oracle reference documentation "the CTXCAT index can't stand table and index partitioning, not...» "in http://docs.oracle.com/cd/B28359_01/text.111/b28303/ind.htm#BEIIEAFD
But I was able to create a CTXCAT index on a partitioned table query to use it successfully.
So can someone tell me exactly it meaning in the documentation of oracle developer "CTXCAT index does not support index and table partitioning?
Thanks in advance,
Mor.
This simply means that you cannot create a LOCAL partitioned index on a table partitioned using the CTXCAT indextype. There is not probably the creation of a global index (ie. covering all partitions) on a partitioned table.
The wording could be clearer.
-
reconstruction of indexes on a table with version
Hello
I'm under oracle 11.1.0.7 on Windows.
I would like to rebuild some clues that have gotten big enough and also move to a different tablespace (the tablespace in a also increased big enough). I'm new on the Workspace Manager and when I tried to do the 'alter index... rebuild' command has encountered an error. I was told that I could use this package:
AlterVersionedTable
Modifies a table compatible version to add valid time support, rename a constraint or rename an index.
Syntax
DBMS_WM. () AlterVersionedTable
table_name IN VARCHAR2,
alter_option IN VARCHAR2,
parameter_options IN VARCHAR2 DEFAULT NULL,
ignore_last_error IN BOOLEAN DEFAULT FALSE);
Parameters
Table 4-5 procedure AlterVersionedTable parameters
Parameter
Description
table_nameInvalid name of the compatible version table to add support for time. The name is not case sensitive.
alter_optionOne of the following values: ADD_VALID_TIME to add valid time support DDL to make changes DDL, RENAME_CONSTRAINT to rename a constraint, REBUILD_INDEX to rebuild an index, RENAME_INDEX to rename an index, or both USE_SCALAR_TYPES_FOR_VALIDTIME or USE_WM_PERIOD_FOR_VALIDTIME to specify if the views on a table compatible existing version must use two scalar columns for the valid time interval.
See the Usage Notes for more information on these options, including when you need and can use this procedure to rename an index or a constraint.
parameter_optionsA quoted string (in the general format ' keyword = value keyword2 = value2,...) ") containing the valid keywords for the specified alter_option value of the parameter." See notes on the use of the keywords that are valid for each alter_option value to the parameter.
ignore_last_errorBoolean value ( TRUE ) or FALSE ).
TRUEdoes not realize the last error, if any, that occurred during the previous call to the BeginBulkLoading procedure. Information about the last error is stored in the USER_WM_VT_ERRORS and ALL_WM_VT_ERRORS of the data static dictionary views, which are described in Chapter 5. See usage for more information Notes.
FALSE(by default) don't ignore the last error, if any, that occurred during the previous call to the procedure of AlterVersionedTable.
I install a simple test case:
DBMS_WM EXEC. AlterVersionedTable('PASIKOWN.) NP_ROAD_PIECE ',' REBUILD_INDEX ',' index_owner is pasikown, index_name = np_road_piece_pk, tablespace = quest_128k "(, NULL);"
and it seemed to run ok. Stamped it 'last ddl' on the change of index so I guess that he rebuilt the index (my test cases was very small, so I see no difference in the number of extensions. However, he did not the indexes in the tablespace that I listed.
Is it still possible?
My humble thanks
Nicole
Hi Nicole,.
When you use the dbms_wm REBUILD_INDEX. The AlterVersionedTable procedure, the only supported parameters are index_owner and index_name. That's why specifying that storage space makes no difference. To move an index that is not a primary key in a different tablespace, you do not want to use dbms_wm.beginDDL and dbms_wm.commitDDL and cause a 'alter index... rebuild "command on the table of the skeleton.
For example,.
SQL > exec dbms_wm.beginDDL('PASIKOWN.) NP_ROAD_PIECE');
SQL > alter index rebuild tablespace pasikown.np_road_piece_pk quest_128k;
SQL > exec dbms_wm.commitDDL('PASIKOWN.) NP_ROAD_PIECE');
However, according to the name of the index you specified, I guess that's the primary key. We do not support the amendments of the primary key index once it was created during the EnableVersioning by beginDDl/commitDDL. Therefore, you must use the option of dbms_wm DDL. AlterVersionedTable and use the following as a parameter of the ddl: 'ddl = "alter index rebuild tablespace quest_128k pasikown.np_road_piece_pk" '. See the documentation for details on this option.
Kind regards
Ben
-
How to create faster index in the table of 500 GB
Dear Experts,
I have to create 20 index on table data-ware house. This table is of size 500 GB.
freshen up this weekly chart using the external table.
creating 20 indexes on this table consumes a lot of time.
I have 40 GB of ram on 2012 box windows with 8 processors.
I installed 11 GR 2.
I have 4 drives C D E F
for AN index, it takes 4 hours
I added enough space to the tablespace
I put the tablespace in a drive D:\
I'm under control to create indexes below
create index X_3_INVEN_ITEM_ID_IDX on X_3_PV_TD_2 (INVENTORY_ITEM_ID) parallel 32 nologging;
output long ops
SID, SERIAL # CONTEXT SOFAR TOTALWORK LESS TARGET % _COMPLETE TIME_REMAINING
---------- ---------- ---------- ---------- ---------- ---------------------------------------------------------------- ---------------------------------------------------------------- ---------- --------------
108 10 0 3758 140973 Rowid Scan AD range. X_3_PV_TD_2 2.67 256
173 23 0 5279 141470 Rowid Scan AD range. X_3_PV_TD_2 3.73 258
114 6 0 10092 141786 Rowid Scan AD range. X_3_PV_TD_2 7.12 261
99 59 0 46283 325908 Sort Output 14.2 15207
68 214 0 46763 323623 Sort Output 14.45 14973
35 93 0 47531 318364 Sort Output 14.93 14570
164 70 0 45058 288506 Sort Output 15.62 12886
227 31 0 44130 282285 Sort Output 15.63 13011
13 3 0 51890 309515 Sort Output 16.76 12874
222 67 0 28837 141380 Rowid Scan AD range. X_3_PV_TD_2 20.4 343
73 37 0 32472 141488 Rowid Scan AD range. X_3_PV_TD_2 22.95 212
47 8 0 34332 141154 Rowid Scan AD range. X_3_PV_TD_2 24,32 202
176 20 0 35197 141161 Rowid Scan AD range. X_3_PV_TD_2 24.93 205
19 7 0 35239 141325 Rowid Scan AD range. X_3_PV_TD_2 24.93 205
80 4 0 40399 141611 Rowid Scan AD range. X_3_PV_TD_2 28,53 193
144 20 0 44960 141481 Rowid Scan AD range. X_3_PV_TD_2 31,78 182
233 101 0 74086 169228 Rowid Scan AD range. X_3_PV_TD_2 43,78 176
128 165 0 78765 141436 Rowid Scan AD range. X_3_PV_TD_2 55.69 173
235 1 0 41199796 70035728 table Scan AD. X_3_PV_TD_2 58,83 19804
199 6 0 52748651 70035728 table Scan AD. X_3_PV_TD_2 75,32-9709
44 2 0 53686039 70035728 table Scan AD. X_3_PV_TD_2 76,66 9022
204 26 0 119969 141464 Rowid Scan AD range. X_3_PV_TD_2 84.81 40
202 48 0 138880 162276 Rowid Scan AD range. X_3_PV_TD_2 85.58 43
17 33 0 126506 141778 Rowid Scan AD range. X_3_PV_TD_2 89.23 28
48 7 0 137772 141360 Rowid Scan AD range. X_3_PV_TD_2 97.46 15
Temp tablespace
USED_MB USED TOT_MB % NOM_TABLESPACE
------------------------------ ---------- ---------- ----------
TEMP 11533 286719 4.02
temporary tables
OWNER SEGMENT_NAME SEGMENT_TY TABLESPACE_NAME EXTENTS BYTES_
---------- ------------------------------ ---------- -------------------- ---------- ---------------
AD 156.1601650 TEMPORARY USERS 96 209,715,200
Question:
How to fix this?
(a) run several parallel create sqlplus statement index different sessions
(b) create a tablespace to put data files in different hard drives like D: E: F: C:
(c) create the separate tablespace for each hard drive and map it to a single disk IO benefit
(d) I have 8 processors but parallel 32 is not speed
(e) how these clues I can run in parallel. Is it OK to run 20 parallel index 32 sqlplus sessions
All that I have to create 20 index on the table of 500 GB
target memory = 30GB
index of names to create 20, each index is 10 GB
his is of 80 hours (4 hours per index)
This machine is waiting, I just used all the resources of the machine to accelerate.
Thanks for reading this
Thanks for the help in advance
I was talking about your end of issue speed up construction of index, where I proposed
orclz >
orclz > alter session set workarea_size_policy = manual;
Modified session.
orclz > alter session set sort_area_size = 2147483647;
Modified session.
orclz > create index
Post edited by: JohnWatson
Sorry, I misread it: this question was not from you. My apologies. My solution should work for you, however: give yourself a big PGA, manually. Automatic PGA management using not will never give you enough.
-
Remove all InDex markers in empty cells
I have a doc with a lot of tables with empty cells. Each empty cells have a markers to index in it and I need to delete all the.
The replacement of find/replace ' ^ I ' of "(Nothing) do not remove.
Is their a way to remove all Index markers via a script?
Jean-Claude
Can you send an example idml or inx?
If not maybe you can try something like this:
var aDoc = app.documents[0];
var allTables = aDoc.stories.everyItem().tables.everyItem().getElements();
app.findTextPreferences = app.changeTextPreferences = null;
app.findTextPreferences.findWhat = "";
app.changeTextPreferences.changeTo = "";
aDoc.stories.everyItem().tables.everyItem().changeText();
app.findTextPreferences = app.changeTextPreferences = null;
alert("done");
It is a part of a screenplay written by Uwe Laubender. I think this could help you.
-
Request from oracle to MySql using dblink read all rows in the table
Hello
I use the heterogeneous connectivity between oracle 10204 to the Mysql database.
I have a database of link on the side of the oracle.
I request a table in MySql with 10 million rows.
His is not serious if I am running:
' Select * from ' CDR_Accounts"@mysql where 'id '= 7675405;
or
Select * from 'CDR_Accounts"@mysql;
There is an index on the column id.
It seems that the Mysql is feteching all rows in the table, all data is transferred to oracle on the dblink and only after the required lines are back to the client.
The /etc/odbcinst.ini file is as follows:
[odbcprd:oracle@odbc /software/oracle]$ cat /etc/odbcinst.ini
[myodbc3]
Description = Mysql connector to mysql version 3.5
Driver = /software/oracle/MysqlOdbc/3.52/lib/libmyodbc3-3.51.25.so
Driver64 = /usr/lib
Setup = /software/oracle/MysqlOdbc/3.52/lib/libmyodbc3S-3.51.25.so
Setup64 = /usr/lib
UsageCount = 1
CPTimeout = 3600
CPReuse =
Please advice
Thank you Initialization of gateway open tha file located in $ORACLE_HOME/hs/admin called init .ora and change HS_FDS_TRACE_LEVEL to HS_FDS_TRACE_LEVEL =WE.
ATTENTION:
Do not forget t turn off after all your tests.
Maybe you are looking for
-
iPhoto should not run every time that a device is connected
iPhoto should not start when I plug any device on a computer. This should be controlled by the owner of the device on the device. And this should be a configurable feature on the computer. There should be a check box that says "Click here to have
-
I'm using Labview 2014 to communicate on a rack of Opto22 and I'm having a problem with the snap-snap-IN-IDC5Q which is defined as a counter in quadrature. I use datasocket links to communicate with points (none module DSC, don't want that). I can re
-
Can Lenovo t510 I put the 1366 x 768 to 1920 x 1080 resolution
I have a lenovo T510, which has a maximum resolution of 1366 x 768, it has nvidia NVS 3100 M. Ive checked with nvidia graphics card and it says that the gfx card support 1920 x 1080. If its possible could I buy an LCD 1920 x 1080 and adapt it to this
-
I installed a new copy of windows ultimate 32 bit on my laptop of friends with all the drivers and software necessary and now every time I turn it on and go to the desktop it crashes after a few minutes. No matter what I do it allows me to do whateve
-
ASA remote VPN with DHCP failed
I am running a version 8.3 ASA5540 (2). I have several deletion of vpn users working on this server. Lately, I have had problems with people starting or being not not able to route any where and it seems to be cause that they fight for the same IP ad
