regular expression replacement
Hi gurus,
I have a requirement where I have to replace some characters in duplicate and retain the values of this column in order of alphabatic and digital control. Please find below examples of data
Thanks in advance
sample data:
SELECT 'ZZYYXXAAABBBDDDCCC' DOUBLE COL1
UNION ALL
SELECT 'DDDCCCAAA' OF THE DOUBLE
UNION ALL
SELECT 'SDBBACCCC' OF THE DOUBLE
UNION ALL
SELECT "99988866332154" DOUBLE
UNION ALL
SELECT "77663322996" DOUBLE
Expected:
ABCDXYZ
ADC
ABCD
12345689
23679
Hello
I don't think that regular expressions will help with that.
Here's a way to do it:
WITH single_characters AS
(
SELECT DISTINCT
col1
, SUBSTR (col1, LEVEL 1) AS a_char
OF sample_data
CONNECT BY LEVEL<= length="">
AND PRIOR col1 = col1
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT LISTAGG (a_char) WITHIN GROUP (ORDER BY a_char) AS expected
OF single_characters
GROUP BY col1
;
This assumes that col1 is unique. If this is not the case, use all that is unique, even something drift of ROWID or ROWNUM, in CONNECT BY and GROUP BY clauses.
The output I get is exactly what you posted:
EXPECTED
--------------------------------------------------------------------------------
23679
12345689
ACD
ABCD
ABCDXYZ
I guess that's what you really want.
Regular expressions can not re - organize a string so that the characters are in order; you need to split the string into pieces, order parts and then put back together them. Given that you have to do it just to get the characters in order, it's simple remove duplicates without problem with regular expressions.
Tags: Database
Similar Questions
-
Need help with a simple regular expression replacement
Hello everyone,
He comes to the table that I have to work with.
My select statement isCREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (129,'Kirby Hotel','25A Aitken Street Wellington','Wellington','04 918 8513','[email protected]','Deahdoow Maharg','A',null,null,'LEAN',to_date('14/02/13','DD/MM/RR'),'027 356 4333'); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (167,'Avenue ee','10 Wellington Street Wellington','Wellington','4444444','[email protected]','James','A',null,null,'LEAN',to_date('21/02/13','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (185,'Quadrant Hotel','10 Waterloo Quadrant, Auckland','Auckland','9555555','[email protected]','Quentin QQ','A',null,null,'LEAN',to_date('04/03/13','DD/MM/RR'),null);
I have to use the function replace twice. One is to replace the Chr (13) a comma is second band a comma where there are two commas.SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_ID
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.
Thanks in advance
AnnHi, Ann.
Ann586341 wrote:
Hello everyone,He comes to the table that I have to work with.
CREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); ...Thanks for posting the sample data. You post the results, but the validation of the existing query which I suppose, produced good results. I can't run this query, because it requires the ijs_seminar table and a connection variable that also has no post, but I can just comment on the join and the WHERE clause.
Is this really the best set of sample data for this question? This problem involves Chr (13) and repeated commas, but I don't see any s CHR (13) or repeated commas in the sample data. In addition, it seems that there are a lot of columns that play no role in this issue and just to make things difficult to read.
My select statement is
SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_IDI have to use the function replace twice. We need to replace the Chr (13) by a comma,.
As posted, inside REPLACE replaces Chr (13) with a comma and a space which could be important if you then pick up consecutive commas.
second is the band a comma where there are two commas.
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.Assuming you want to replace Chr (13) with just a comma, then an equivalent would be:
SELECT acc.hotel_name || '(' || REGEXP_REPLACE ( acc.address , '[,' || CHR (13) || ']{1,2}' , ',' ) || ')' AS h FROM tbl_accommodation acc INNER JOIN ijs_seminar s ON acc.accommodation_id = s.accommodation_id WHERE s.seminar_id = :P27_SEMINAR_ID ;In the argument to REGEXP_REPLACE 2nd
[xy]{1,2}medium 1 to 2 characters of set of x and y. This could be
x or
there or it could be 2 characters
XY or the other way
YX or it could be the same characters 2
XX or
YYREGEXP_REPLACE is slower that REPLACE. Even if your original expression is longer, it may be more effective. (Performance may be not a problem in this case.)
-
Regular expression, replace all commas between double quotes ONLY
Hello
I want to remove all commas between double quotes:
I tried under model, but it does not replace all if we have more than one comma in double quotes.
SELECT REGEXP_REPLACE (123, "45.6" Hello, "John, Mike, Marc", 456, "-Anne, Anna"', ' "([^"]*),([^"]*)" ', '"\1;\2" ', 1, 0) suite
FROM DUAL;
Result
--------------------------------------------------------------------------
123, '45; 6"," Hello, "John, Mike;" "Marc", 456, "Anne-; Anna.
the first comma between 'John, Mike; Marc"is not replaced...
Recursion can do if you insist on the SQL solution
with
correct (INP, orig, CNT, res, Step) as
(select str,
substr(STR,2),
-case when substr (str, 1, 1) = ""' then 1 else 0 end,
substr (STR, 1, 1),
1
of (select 123, '45.6,' Hello, ' John, Mike, Marc ", 456, '-Anne, Anna', 'single_value' ' str of union double all the)
Select "123456789" across double Union
Select ' ""' of all the double union
Select "" 123,456,789"" Union double all the
Choose 123, '45.6,' Hello, ' John, Mike, Marc ", 456, 'Ann-Marie, Anna', 'unique value' ' double str
)
Union of all the
Select the inp
substr(orig,2),
CNT + case when substr (orig, 1, 1) = ""' then 1 else 0 end,
RES | cases where substr (orig, 1, 1) = ','
so to case when mod(cnt,2) = 1
then ' ~'
else «»
end
of another substr (orig, 1, 1)
end,
Step + 1
Rectifier
where orig is not null
)
Select the inp, res
Rectifier
where the orig is null
INP RES "" "" 123456789 123456789 "123456789". "123 ~ 456 ~ 789". 123, '45.6' Hello, ' John, Mike, Marc ", 456, '-Anne, Anna', 'single_value '. "123," "45 ~ 6 ', Hello," John ~ Mike ~ Marc ", 456," Anne-~ Anna ',' single_value '. 123, '45.6' Hello, ' John, Mike, Marc ", 456,"Ann-Marie, Anna","unique value ". "123," "45 ~ 6 ', Hello," John ~ Mike ~ ~ ~ Marc ', 456,' Anne-Marie ~ Anna "," unique value ". Concerning
Etbin
-
I have query
It is output asselect '011:100.0|016:100.0|017:100.0|020:100.0021:100.0|022:100.0|025:100.0|026:100.0031:100.0|041:100.0|051:100.0|061:100.0' a from dual union all select '011:00.0|016:00.0|017:00.0|020:00.0|021:00.0|022:00.0025:00.0|026:00.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual union all select '011:00.0|016:00.0|017:00.0|020:100.0|021:100.0|022:100.0025:100.0|026:100.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual union all select '011:100.0|016:100.0|017:100.0|020:100.0|021:100.0|022:100.0025:100.0|026:100.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual union all select '011:100.0|016:100.0|017:100.0|020:00.0|021:00.0|022:00.0025:00.0|026:00.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual
I want below output011:100.0|016:100.0|017:100.0|020:100.0021:100.0|022:100.0|025:100.0|026:100.0031:100.0|041:100.0|051:100.0|061:100.0 011:00.0|016:00.0|017:00.0|020:00.0|021:00.0|022:00.0025:00.0|026:00.0031:00.0|041:00.0|051:00.0|061:00.0 011:00.0|016:00.0|017:00.0|020:100.0|021:100.0|022:100.0025:100.0|026:100.0031:00.0|041:00.0|051:00.0|061:00.0 011:100.0|016:100.0|017:100.0|020:100.0|021:100.0|022:100.0025:100.0|026:100.0031:00.0|041:00.0|051:00.0|061:00.0 011:100.0|016:100.0|017:100.0|020:00.0|021:00.0|022:00.0025:00.0|026:00.0031:00.0|041:00.0|051:00.0|061:00.0011:100.0|016:100.0|017:100.0|020:100.0|021:100.0|022:100.0|025:100.0|026:100.0|031:100.0|041:100.0|051:100.0|061:100.0 011:00.0|016:00.0|017:00.0|020:00.0|021:00.0|022:00.0|025:00.0|026:00.0|031:00.0|041:00.0|051:00.0|061:00.0 011:00.0|016:00.0|017:00.0|020:100.0|021:100.0|022:100.0|025:100.0|026:100.0|031:00.0|041:00.0|051:00.0|061:00.0 011:100.0|016:100.0|017:100.0|020:100.0|021:100.0|022:100.0|025:100.0|026:100.0|031:00.0|041:00.0|051:00.0|061:00.0 011:100.0|016:100.0|017:100.0|020:00.0|021:00.0|022:00.0|025:00.0|026:00.0|031:00.0|041:00.0|051:00.0|061:00.0with t as ( select '011:100.0|016:100.0|017:100.0|020:100.0021:100.0|022:100.0|025:100.0|026:100.0031:100.0|041:100.0|051:100.0|061:100.0' a from dual union all select '011:00.0|016:00.0|017:00.0|020:00.0|021:00.0|022:00.0025:00.0|026:00.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual union all select '011:00.0|016:00.0|017:00.0|020:100.0|021:100.0|022:100.0025:100.0|026:100.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual union all select '011:100.0|016:100.0|017:100.0|020:100.0|021:100.0|022:100.0025:100.0|026:100.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual union all select '011:100.0|016:100.0|017:100.0|020:00.0|021:00.0|022:00.0025:00.0|026:00.0031:00.0|041:00.0|051:00.0|061:00.0' a from dual ) select regexp_replace(a,'\.0(\d)','.0|\1') from tKind regards
Sayan M. -
Regular Expression search and replace question - please help!
I was wondering if someone could help me I have a lot of paper with notes like this: [1], but I need them to look like in this [1].
I don't know what to put in the section find [[\d]*] , but I need help with what to put in the field replace to make < sup > numbers]
In fact, your regular expression is false. What you need is the following:
(\[\d+\])
The field replace must contain this:
$1
-
Grouping and backreferences with regular expressions on the window to replace the text
I'm really appreciate the inclusion of regular Expressions in the search and replace functionality. One thing miss me that East of backreferences in the replacement expression. For example, in unix tools vi or sed, I could do something like this:
that allow me to switch the places of first and secondPart and substitute totally thirdPart. If grouping and backreferences are already present in the window replace text, how do you properly call them?s/\(firstPart\) \(secondPart\) \(oldThirdPart\)/\2 \1 newThirdPart/g
Published by: Justin.Warwick on August 23, 2011 08:26You can vote on the request for this to the exchange of SQL Developer, to add weight to the implementation as soon as possible: https://apex.oracle.com/pls/apex/f?p=43135:7:3693861354483465:NO:RP, 7:P7_ID:16761
Kind regards
K. -
Find and replace - regular expression to help?
How can I find ' <!-* PAGE footer AREA *-> "and replace it and evething after with my new coding of footer on all my pages.
The problem is:
The code in my existing page footer area is not the same on all pages.
I want to replace it with a new one on all pages
I watch the operators of regular expressions, not found patern that works...
Thanks in advence for your help
The following regular expression is the and everything up, but not including the closing tag:
[\s\S]+(?=<\/body>)
Use it in the search field and put the comment and the code to the footer in the field replace. Select use regular expression.
Always make a backup before using a regular expression on many pages.
-
Regular expression find and replace with wildcards
Hello!For the world of me, I can't understand the right way to do it.
I made a list of family names, first names. I want to have a different style than the first name, last name.
So that's what I have now:
< b > AAGAARD, TODD, s. < /b > < br >
AAMOT, KARI, < b > < /b > < br >
< b > AARON, MARJORIE, c. < /b > < br >and that's what I have:
< span class = "Name" > AAGAARD </span > < span class = "FirstName" >, TODD, s. </span > < br / >
< span class = "Name" > AAMOT </span > < span class = "FirstName" >, KARI, </span > < br / >
< span class = "Name" > AARON </span > < span class = "FirstName" >, MARJORIE, C. </span > < br / >
Any ideas?
Thank you!
Make a backup first.
In the use of the search box:
(\w+),\s+([^<]+)<\/b>\s*
In the field using replace:
$1 $2
Select use regular expression. Light blue paper touch, then click on replace all.
-
Replace with complex logical regular expression
What is the best way to replace the input string with the following rules:
1. all sequential occurrences of two or several hyphen-symbols (symbol: '-') must be replaced by a hyphen. So, if the input string is "-" then output should be ' - '. If the entry was "a-a-a", then output remains what it is.
2. all occurrences of two or more space sequential symbols (symbol: "" "") must be replaced by a space. If the input string is "" then exit must therefore «» If the entry was "one one one" then exit remains as it is.
3. once the 1-2 rules are applied after the rule applies: all occurrences of the space symbol followed immediately after the hyphen-symbol or vice verse-trait of Union followed by space should be replaced with the hyphen. So, if the input string is "»" or "-" then the output should be "«»". " If the entry was 'a - a', then output remains what it is.
4. once the 1-2-3 rules are apllied follows the rule should be applied: String beginning and symbol of the end can only be space or hyphen. Therefore, if the input string is 'a' or '-a ' or 'a' or 'a-' and then the output should be 'a '.
All rules 1 to 4 must be apllied to the input string.
Example of replacement logic:
entry: 'an aa - ss-ee -'
output: "an aa-ss-ee."
I think that I should use the function "regexp_replace" somehow.
This solution below does not work because it produces two consecuent dashes "-":
Can you suggest a regular expression for it?with t as( select 'a aa ---- ss-ee -' str from dual ) select regexp_replace(str, '--','-') a from t; /*a aa -- ss-ee -*/Maybe something like this:
SQL> with t as( 2 select 'a aa ---- ss-ee -' str from dual 3 ) 4 select rtrim(rtrim(ltrim(ltrim( 5 regexp_replace(regexp_replace(str, '(-| )\1+','\1'), '( -|- )', ' ') 6 , '-') , ' '), '-'), ' ') a from t; A ----------- a aa ss-eeNotice how it ends with 2 spaces in a row in the Middle, because there was a segment with '-' (space followed by '-') which was replaced by a space.
-
I solved this by using the following regular expression in find DW and replace dialogue, it will be all the html on several lines between two specified comments:
<!-NameofStartingComment--(.| \s)*?--NameofEndingComment-->)
Hello
I have structured my site in dreamweaver with each page between the comments section:
<! - navBarStart - >
HTML here
<! - naveBarEnd - >
I used this method because I wanted to be able to easily use the find and replace dialogue with regular expressions to update pieces of code throughout my site. However, I have real problems finding the correct regular expression to use.
So in every page I have my <! - startHtmlSection - > <!-endHtmlSection-> between these two tags, I sometimes have different HTML. I want to find the regular expression I could use 'generic' of all the html to a find a replacement between two of my comments specified. Can anyone help? I googled and tried everything what is obvious (after you have selected the regular expressions in the find and Replace dialog) but DW never find the tags in the pages of sites.
I solved this by using the following regular expression in find DW and replace dialogue, it will be all the html on several lines between two specified comments:
Hello
I have structured my site in dreamweaver with each page between the comments section:
HTML here
I used this method because I wanted to be able to easily use the find and replace dialogue with regular expressions to update pieces of code throughout my site. However, I have real problems finding the correct regular expression to use.
So in every page I have my between these two tags, I sometimes have different HTML. I want to find the regular expression I could use 'generic' of all the html to a find a replacement between two of my comments specified. Can anyone help? I googled and tried everything what is obvious (after you have selected the regular expressions in the find and Replace dialog) but DW never find the tags in the pages of sites.
-
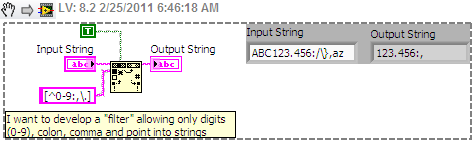
Allow specific characters - Regular Expression
Hello everyone
I am new to the regular expression and I have a very simple question. I use the function "read from the text file" to load a file delimited by tabs with 3 columns in my VI. Then, the string is converted to table and I use the values.
Nevertheless, I would like to develop a "filter" that allows only digits (0-9), colon, comma , and point to strings.
Using the function "matches regular expression", I tried a regular expression like this:
[^ 0-9] | [^\]. [|^:]| [^,]
But it does not work.
Could someone help me with this problem?
Thank you
Dan07
Use search and replace with regular Expression String selected.
-
Regular Expressions do not work
With the help of sensors 4.X, VMS2.2
It seems that the normal regualar expressions are not accepted as valid by CiscoWorks. Example:
If I wanted to match for "Red Duck", but the number of spaces between each letter had to be 0-5 I would use spaces:
[R] {0-5} e [] {0-5} [d] {0-5} D {0-5} [] u] {0-5} [c] {0-5} k [] {0-5}
That the expression would be: R e d D uc k, Red D u c k and similar.
Why they are not allowed in String.TCP?
SO the question is, WHERE can find a list of regular expressions ACCEPTED, that works with sensors 4.X. I found a list that works with 3.X sensors... it did not work at all. Here, any help would be great.
Eric
Duck of red in google returns as red + duck in Google. Space will be replaced by a plus (+) sign or % 20 as it goes over HTTP (the browser for this).
The regular expression must be (including breaks):
[Rr] [+] * [Ee] [+] * [JJ] [+] * [JJ] [+] * [Uu] [+] * [Cc] [+] * [Kk]
You can't repeat a pattern of three characters like [%] 20.
-
Divide a CSV with a regular Expression
I'm working on a script that will read the CMYK values from a CSV file and add the nuances of the Swatches palette. I can easily split the CSV entering a comma (.split(",");), but I can't seem to get a regular expression to separate by commas and new lines.
Here is the code snippet I have right now is not working:var fileIn = new File("/Users/brianp/Desktop/AVL-PMS-TEMP.csv"); fileIn.open(); var csvIn = fileIn.read(); fileIn.close(); var regEx = "/,|\\n/"; csvRecords = csvIn.split(regEx);I am barking the wrong tree here?
I could change the CSV advance to find all line breaks and replace them with commas, but it looks more elegant to adapt my code for the CSV file is delivered.
Thanks in advance!
csvRecords = csvIn.split(/[,\n\r]/);
This is the shortcut. To preset the regex, to leave out the quotation marks:
var regEx = / | \n/ ;
Better to add the CR (\r) as well.
Use the classes of characters [...] If you can instead of alternatives (... |...), they are more effective (allegedly).
Peter
-
Validation using regular expressions or oracle fn
Hello
I want to apply validation to a column. I'm trying to see if I can use the regexp_replace function to find a boss and see if I can replace it to a better format. Can someone help me with these rules?
1. only the characters a - z, A - Z, 0-9, ', - is allowed. If there are no other characters, then these characters must be removed.
2. name should not begin with a symbol.
3. If there is any symbol permitted in the name, (for example the hyphen) then the hyphen should be preceded and followed by a space.
I would like to know if the above can be obtained by regular expressions or any other function will be useful to achieve the same.
Thank you very muchCherkaoui
HI, Charan,
Whenever you have a problem, please post a small example data (CREATE TABLE and only relevant columns, INSERT statements) of all the tables involved, so that people who want to help you can recreate the problem and test their ideas.
Also post the exact results you want from this data, as well as an explanation of how you get these results from these data, with specific examples. Post in this case, maybe 5 or 10 strings, and what you would like to see (a string corrected, or a 'yes' / 'No' flag saying if this string follows rules.)
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum: Re: 2. How can I ask a question on the forums?
2784427 wrote:
Hello
I want to apply validation to a column. I'm trying to see if I can use the regexp_replace function to find a boss and see if I can replace it to a better format. Can someone help me with these rules?
1. only the characters a - z, A - Z, 0-9, ', - is allowed. If there are no other characters, then these characters must be removed.
2. name should not begin with a symbol.
3. If there is any symbol permitted in the name, (for example the hyphen) then the hyphen should be preceded and followed by a space.
I would like to know if the above can be obtained by regular expressions or any other function will be useful to achieve the same.
Thank you very much
Cherkaoui
Sorry, we don't know what you want to do.
1 seems to mean you want to change the given string so that it follows the rules. (What exactly are special characters? Are there only 2 special characters: single quotation mark and hyphen?)
2 seems to tell us that you want to check if it meets the rules
3. can be a
I'll assume that you want to modify the string so that the returned value corresponds to rules. This means that if the given string violates, 2 symbols will be removed from the beginning of the string, and if it violates 3, then spaces will be added.
I don't think that there is a way to do this with a regular expression.
You can make each with a separate REGEXP_REPLACE corrections, and make all in the same query by one nesting inside each other, like this:
SELECT REGEXP_REPLACE (REGEXP_REPLACE (REGEXP_REPLACE (: str)))
, "[^ a-zA-Z0-9 cm-]"
)
, '^[''-]+'
)
, ' *([''-]) *'
, ' \1 '
) AS new_str
OF the double
;
of course, I can't test it, until post you some sample data and the exact results you want from these data.
Here, the inner REGEXP_REPLACE rule 1 applies. It deletes all characters except a to z small letters, capital letters A to Z, numbers, spaces, single quotes and hyphens.
Rule 2 applies the REGEXP_REPLACE middle. It removes the single quotes and hyphens that appear at the beginning of the string.
The external REGEXP_REPLACE rule 3. It guarantees that each single quotation mark or a hyphen is preceded and followed by a space. If there is already a space (or several spaces) before and/or after the special symbol, they are replaced by a single space. If this isn't what you want, it can be fixed, but it will make the expression even messier.
You might consider to write a user-defined function to normalize strings. In a function procedure, you can apply the rules one after the other. you need not nesting complicated like that. Of course, a user-defined function will be slower, but maybe it's not a problem.
Still, the above query converts the string so that the production rules.
If you just want to check whether a string conforms to the rules, you can compare the original string to the output of the above expression. If they are identical, then the string is in accordance with the rules.
-
Hello
Can you help me how to replace all the commad located on a string between double quotes 2?
for example, I have a text file that contains data such as as follows
A, "-16,12","178,245", "-15,506"
B, "-16,12","178,245", "-15,506"
C, 0, 0.1
I need a result like this:
A, "-16.12", "-178.245", "-15.506".
B, "-16.12", "-178.245", "-15.506".
C, 0, 0.1
I did this, but without the regular expression. It seems to me that a regular expression, it is more elegant to parse each line and replace it.
Thank you
in which case you can be sure that all the change always are enclosed in doublequotes the regex would be like this:
line.replaceAll("(\"-?\\d*),(\\d*\")","$1.$2");Good bye
DPT
Maybe you are looking for
-
How to reorder the icons in the app on iPhone 7?
When I hold down the app icon now, I get a pop-up menu. It's great practice. Which is also used to be how I rearrange and remove applications. How to reorder apps now?
-
Skype blue screens my computer when I get a call. I came across the help forums for this problem maybe 4 months ago. Someone tried to help diagnose the problem, but they ended up just saying em download an older version of Skype. Well, last night, co
-
HP Pavilion p117na 15: Beats audio HP Pavilion 15-p117na does not
Hello Beats Audio does not work on my new laptop HP. Setting audio beats in panel simply doesn't work. I have download IDT high definition Audio drivers sp63932.exe & sp63555.exe HP support site but no work. Laptop- laptop HP Pavilion TouchSmart (En
-
Is it possible to have an accordion several tabs?
Hi everyone, I am new to Adobe Muse and would really like some advice. My design idea equipped with 2/3 rows of images clickable wagon that would ideally expand to show additional content. When the content area develops I would also like for the next
-
install after effect in a new computer
HelloI buy software adobe after effect and after that I bought a new computer. How to move the effect on the new computer?