Selective table average
Hello
I have a 2D chart. The following code generates a random array of 3 x 3.
I want to get the mean (or average) only values greater than a set value (user-defined) in the table.
Could someone help me.
I tried to use a "superior to", type the case statement, but when I do this, for less than the value set elements a zero is placed in a new table. This changes the average because it includes the zero element.
Almost, I need to create a table 1 d of the righteous elements above the value of the definition of the matrix 3 x 3.
I want to adapt what I learn here much larger bays of 400 x 400 and upwards.
Any help would be appreciated.
Thank you
K
Attached to the LV 8.6. Please note that I have not downconvert another example since it is my humble opinion, nothing is done for you.
Norbert
Tags: NI Software
Similar Questions
-
Transformation of Scripts that run only on the selected Tables
I'm relatively new to Data Modeler, but found almost everything to be very intuitive. I'm now doing use custom transformation scripts to dynamically add custom DDL elements. I wrote a transformation script that adds a sequence at the end of my DDL trigger successfully, and I'm happy with the results. The problem I run into is that we have two different categories of tables that require slightly different sequence triggers, but as my model is set to the level of database, my transformation scripts are applied to all arrays regardless they come what schema. Do you have any suggestions on how to limit the tables which proceeds by a transformation script? I thought to add if statements to check what schema tables are coming from, but if I have a situation where I have two different tables that require two different processing scripts, but they are in the same pattern, how can that I manage that? Ideally, I'd like to just pick a table and apply a transformation script for this table individually. Is this possible?
I work in a relational model with Data Modeler 4.0.
to dynamically add items customized to DDL
you need to check the custom of DDL in DM 4.1 features - "tools > rules and design transformations > Table DDL transformations"-DM 4.1 comes with example to generate tables of the newspaper and associated trigger.
. I wrote successfully in a transformation script that adds a sequence at the end of my DDL trigger
Data Modeler can generate the sequence and relaxation for you - you need to define the column as 'auto increment' / identity and set in preferences, you want "trigger" put in place. 4.1 DM added support for z/OS, DB2 LUW DB2 and MS SQL Server 2012.
Do you have any suggestions on how to limit the tables which proceeds by a transformation script? I thought to add if the instructions to check the schema, the tables are coming, but if I have a situation where I have two different tables that require two different processing scripts, but they are in the same schema
Well you need to sort it out on yourself - you can use classification types, dynamic properties user defined properties (in DM 4.1) or put paintings in various subviews or use the search feature (4.0.3 DM / DM 4.1 comes for example how to use the search results to create subview).
Ideally, I'd like to just pick a table and apply a transformation script for this table individually. Is this possible?
Here is an example of how get selected tables:
appv = model.getAppView(); dpv = appv.getCurrentDPV(); //check there is a diagram selected and it belongs to the same model if(dpv!=null && dpv.getDesignPart() == model){ tvs = dpv.getSelectedTopViews(); for(var i=0;iPhilippe
-
Ongoing replication of the selected tables from Oracle to SQL Server
Hi all
How can we replicate selected tables to Oracle 11 g for SQL Server 2008/2012?
Is GoldenGate the only option
No matter who did it before or have the steps to do it?
Thank you
Define "replicate".
If you have no budget, you can open a connection directly from SQL Server to Oracle, or vice versa. In Oracle, they are called links DB; in SQL Server, they are called "linked servers".
Datanamic also have tools that claim to do the cross-DB replication. I have no experience with them and is not an endorsement - I know they exist.
-
'shift' key does not work in the multiple selection table
I created a table by dragging default datacontrol vo, the multiple value RowSelection, override the SelectionListener a manageBean method as follows:
{} public void tableMakeCurrent (SelectionEvent selectionEvent)
RowKeySet rks = selectionEvent.getAddedSet ();
System.out.println (RKS. GetSize());
Iterator it = rks.iterator ();
{while (IT.hasNext ())}
System.out.println (IT. Next());
}
}
The problem is when I use 'shift' button help me select several lines, it will only print the last line, which I selected.
Is there a way to fix this? Thank you...
jdeveloper11.1.1.3for rowSelection multiple = to work with 'shift' you should not have the selectionListener or selectedrowkeys for your af:table
http://www.adftips.com/2010/11/ADF-UI-implementing-multi-select-table.html
delete selectedrowkeys and ownership selectionListener in the table and you will get select using the 'shift '. -
I cannot select table jump extensions associated with lost data files?
Hi ~.
I need your help to recover my database.
I use oracle 9.2.0.8 to Fedora 3 with mode-archive.
and I have no backup.
Last night, I have experienced hard drive failure.
I tried the recovery at the level of the BONE, but I lost some data from the tablespace files.
in any case, I wanted to recover my database without the data of lost data files.
then, I published 'drop alter database datafile offline' and
Start the oracle instance.
But, data files were not eliminated from dba_data_files view and
extensions associated with lost data files were not removed from dba_extents view!
Query a selection table containing extensions associated with lost data files.
I have "ORA-00376: file xxx cannot be interpreted at this time" message.
So, my question is that...
HOW CAN I SELECT TABLE WITHOUT EXTENSIONS RELATED TO THE LOSS OF DATA SCANNING FILES?
Thank you.Hello
Without being in archivelog and without backup, can't make any sort of recovery. This is why the backups and archivelog are so important.The offline data file command never actually drops the data file. It simply tells the control file now the tablespace of the said is also abandoned. It refreshes not any notice that the files are not supposed to be used or shown more than you.
What documentation is the recovery of the database in the mode NoARch.
http://download.Oracle.com/docs/CD/B19306_01/backup.102/b14191/osrecov.htm#i1007937Do you need a backup in order to recover the tables being played. Oracle is not have all the features that can currently out / skip missing extensions for you and you can read the data without them.
HTH
Aman... -
Hi all
I have 3 fields with numeric values in a table.
How can I make the average to the values to zero?
Example:
10 20 30 = 60/3 = 20
10 0 20 = 30/2 = 15 - divided by two, because one of the values is equal to zero.
0 6 0 = 6/1 = 6
I can probably make a case statement for a long time, but I wonder if it's a better way.
Thanks in advancewith t as ( select 10 col1,20 col2,30 col3 from dual union all select 10,0,20 from dual union all select 0,6,0 from dual ) select (nvl(col1,0) + nvl(col2,0) + nvl(col3,0)) / (sign(abs(nvl(col1,0))) + sign(abs(nvl(col2,0))) + sign(abs(nvl(col3,0)))) avg from t / AVG ---------- 20 15 6 SQL>SY.
-
Hello community,
Using 32-bit Teststand 2014
I have a one-dimensional array with a size ten (Array [10]). I want to be able to take an average of this table in Teststand. Using an expression of the statement, I am able to do digital = ((Array [0] + tableau [1] +...)) Array [10]) / 10), but this is tedious. Especially, if I have a table for more than a decade.
In Teststand, is there a mathematical operation or another way to get the middle range?
I don't think it's possible in a single expression. Consider the attached example that does it in a single step.
Hope this helps,
-
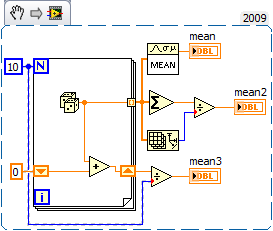
Hello
I try to have a vi that receives an array of file, and then built the sup boards (according to the FPS/mid-range everything), then take the average, detects the difference between each data point and count the number of times where the difference is greater than the threshold. Please see the attached file - my block diagram.
At this point, the vi is running but the is a bug in the code that I can't find :-(.
When I run it on a counter of data sample returned ~ 350 where it suppose to be only 3.
I will appreciate if you can take a look.
Thank you
PS.
I am happy to download the vi and an example of data file if necessary.
simply_me,
You take a subset of the table, get the average which seems ok. But then understand you the difference between the average and all you started with instead of the subset of the array that allowing you to calculate the average. Guess you have to do this.

-
creating a table/average question
I'm new to labview and I have problems to understand how to create a table.
I use an Arduino Uno as my DAQ and when I take an anolog measure I've seen a lot of fuctuation to my measure. I know with arduino, you can perform with an average simple by using the function "Get a finished sample of Analog", but I know that I not be using an Arduino in the long term and trying to figure out the right way to do it.
When I have on average with the Arduino IDE I usually code that looks like this:
float analogsum = 0;
for (int i = 0; i)< 10;="">
analogSum += analogRead (analogPin); where analogRead converts the analog value to a value\ digital 10-bit
}
average = analogSum/10;
I am trying to create this same feature in LabView. The only way I can imagine the analog value of each iteration, in summary would be to store each value in a table, then add them together and divide by the number of iterations in my loop for.
How would I do this in Labview?
Hi awwende,
show all 3 suggestions above:
You really should go LabVIEW101 the ni.com site to learn the fundamentals of LabVIEW!
-
Returns the selected table column header
I don't know there is probably a way to do this. But I have not yet found.
I am building an application that will act as a sort of "universal" reports generator for a MySQL database tables.
At startup, a drop-down list box is filled with the names of tables in the database. When the user selects one of these tables, the column names are taken from the base and used to fill the column headers for the table of LabVIEW.
The idea is that the user can select this column and enter the constraints of filter in a text box. These constraints will then be added to the WHERE statement for this column.
So far I've been able to find a way to return the Active cell or a selection of cells, when the user clicks on the actual data of the table.
Is there a direct way to retrun a selected in LabVIEW column header value?
I am dreaming that there may be some sort of workaround using transparent controls over the headers. But because different tables will have a different number of columns that the user defines the width, I'm not really sure that it will work more.
If you the editable headers, this allows Active cells specify that your column is - 1 column selected active line is the selected column. You may need to use the mouse down? to filter the possibility for the user to change the right column headings.
-
Hi guys,.
There I am facing a problem I need to create the table in the select statement result 0 records as output.
Sue, the error displayed is:
SQL error: ORA-01723: columns null are not allowed
01723 00000 - "columns null are not allowed.
* Cause: Columns with a length zero could not.
* Action: Correct use of the column.
no selected line
Can you please suggest a way?
I need to create several tables like that of the select statement.
As Johan has picked up on, if the VEL_CEM_ALL_CONTENT is a point of view, then the data types will be those of the columns returned in the select from this point of view, and if one of those is null then you will get the error.
-
How to treat only selected tables?
I am writing a transformation I only applied to certain tables in the model. I found the "isSelected()' on the table object function, but appears not to do what I thought, he does. If I selected a table in the user interface and apply my transformation, the table not treated. Passage through the debugger shows that the isSelected() function returns false for all my paintings.
Here is the code I use to test...
tables = model.getTableSet () .toArray ();
for (t = 0; t < tables.length; t ++) {}
table = table [t];If (table.isSelected ()) {}
table.setName ("Found_You");
}
}Is it possible for me to treat only the tables that are currently selected in the user interface?
Thank you
Eric
Hi Eric,.
Must be something like this
importPackage(javax.swing); mainView = model.getMainView(); selObjects = mainView.getSelectedObjects(); for (var t = 0; t
-
"Dependencies" tab shows all the information for a version of the selected table 4.0
Hello
I work with SQL Developer 4.0.0.13. I can see 20 tables in the list. When I select a table to the tabs on the right side, I can see the information for the 'columns' and 'data' and 'constraints' and 'index'... but the "Dependencies" tab does not display an information about references between this table and other tables in the schema.
Oracle database is v11.2
Can you please tell me what should I do to see the information on the tab "Dependencies" for a table?
Thank you
Milan
The page dependencies in the object editor reflects the content of the window to ALL_DEPENDENCIES - I don't think includes FKs.
Since the DOCS
ALL_DEPENDENCIESDescribes the dependencies among procedures, packages, functions, package bodies and triggers available to the current user, including dependencies on views created without database links. This view does not display theSCHEMAIDcolumn. -
Hi all, I have two paintings as follows
1.
Select strc_id, strc_name, STRC_TYPE Glu;
o/p
STRC_ID STRC_NAME STRC_UOM
1 Roads Square Yards
2 Fields Square Yards
3 power each, linear feet
4 irrigation each, linear feet
5 navigation each, linear feet
6 Museum Each
7 storage each, linear feet
Measures (UDM) has their numbers defined as follows in the other table. That is to say
2. Select UOM_ID, UOM_NAME from UOM_TYPE;
UOM_ID UOM_NAME
1 each
Track 2 Miles
3 linear feet
4 miles
5 square yards
6 square feet
I wrote a query against the table 1 i.e STRC_TYPE who willl divide the STRC_UOM
Select STRC_ID, STRC_NAME, substr)
STRC_UOM,
InStr ("," |) STRC_UOM, ', ', 1, seq).
InStr ("," |) STRC_UOM | (",", "," 1, seq + 1)-instr ("," |) STRC_UOM, ', ', 1, seq)-1) STRC_UOM
of STRC_TYPE, (select seq level of the double connect by level < = 100000) seqgen
where instr ("," |) STRC_UOM, ', ', 1, seq) > 0 order by STRC_NAME;
O/P:
It divides as follows of the UOM_NAME
STRC_ID STRC_NAME STRC_UOM
1 Roads Square Yards
2 Fields Square Yards
3 Power Each
4. Power Linear Feet
5. Irrigation Each
6 irrigation linear feet
....
....
but now I would create an intermediate table and wait for the exit as follows and need there should be a constraint of integrity on the staging table.
Expected results
Table_ABC
STRC_ID STRC_NAME UOM_CODE (this is the pseudonym of UOM_ID in table 2 above)
1 5 roads (the UOM_ID is 5 of the table above for square yards)
2 Fields 5
3 Power 1
4. Power 3
5 irrigation 1
6 irrigation 3
...
...
can you please suggest me how to write code for this requirement.
Thank you
with
strc_type as
(select 1 strc_id, strc_name 'Roads', 'Square Yards"uom of union double all the)
Select 2, 'Fields', 'Square yards' double Union all
Select 3, 'power', 'Each, linear feet' from dual union all
Select option 4, 'Irrigation', 'Each, linear feet' from dual union all
Select 5, "Navigation", "Each, linear feet" dual Union all
Select 6, 'Museum', 'Each' from dual union all
Select 7, 'Storage', 'Each, linear feet' of the double
),
uom_type as
(select 1 uom_id, 'Each' uom_name of all the double union)
Select 2, 'Lane Miles' from dual union all
Select 3, 'The linear feet' from dual union all
Select option 4, 'Miles' from dual union all
Select 5, "Square Yards' from dual union all
Select 6, 'Square Feet' from dual
)
Select row_number() on strc_id (st.strc_id, st.strc_name),
St.strc_name,
UT.uom_id uom_code
from (select strc_id,
strc_name,
-case when instr (Glu, ',') > 0
then substr (Glu, 1, instr (Glu, ',') - 1)
unit of measure to another
unit of measure of end
of strc_type
Union of all the
Select strc_id,
strc_name,
LTRIM (substr (UOM, InStr (GLU, ',') + 1))
of strc_type
where instr (Glu, ',') > 0
) st.
uom_type ut
where st.uom = ut.uom_name
STRC_ID STRC_NAME UOM_CODE 1 Roads 5 2 Fields 5 3 Power 1 4 Power 3 5 Irrigation 1 6 Irrigation 3 7 Navigation 1 8 Navigation 3 9 Museum 1 10 Storage 3 11 Storage 1 Concerning
Etbin
-
Insert the problem using a SELECT table with an index by TRUNC function
I came across this problem when you try to insert a select query, select returns the correct results, but when you try to insert the results into a table, the results are different. I found a work around by forcing a selection order, but surely this is a bug in Oracle as how the value of select statements may differ from the insert?
Platform: Windows Server 2008 R2
11.2.3 Oracle Enterprise Edition
(I've not tried to reproduce this on other versions)
Here are the scripts to create the two tables and the data source:
Now, execute the select statement:CREATE TABLE source_data ( ID NUMBER(2), COUNT_DATE DATE ); CREATE INDEX IN_SOURCE_DATA ON SOURCE_DATA (TRUNC(count_date, 'MM')); INSERT INTO source_data VALUES (1, TO_DATE('20120101', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120102', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120103', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120201', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120202', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120203', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120301', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120302', 'YYYYMMDD')); INSERT INTO source_data VALUES (1, TO_DATE('20120303', 'YYYYMMDD')); CREATE TABLE result_data ( ID NUMBER(2), COUNT_DATE DATE );
You should get the following:SELECT id, TRUNC(count_date, 'MM') FROM source_data GROUP BY id, TRUNC(count_date, 'MM')
Now insert in the table of results:1 2012/02/01 1 2012/03/01 1 2012/01/01
Select the table, and you get:INSERT INTO result_data SELECT id, TRUNC(count_date, 'MM') FROM source_data GROUP BY id, TRUNC(count_date, 'MM');
The most recent month is repeated for each line.1 2012/03/01 1 2012/03/01 1 2012/03/01
Truncate your table and insert the following statement and results should now be correct:
If someone has encountered this problem before, could you please let me know, I don't see what I make a mistake because the selection results are correct, they should not be different from what is being inserted.INSERT INTO result_data SELECT id, TRUNC(count_date, 'MM') FROM source_data GROUP BY id, TRUNC(count_date, 'MM') ORDER BY 1, 2;
Published by: user11285442 on May 13, 2013 05:16
Published by: user11285442 on May 13, 2013 06:15Most likely a bug in 11.2.0.3. I can reproduce on Red Hat Linux and AIX.
You can perform a search on MOS to see if this is a known bug (very likely), if not then you have a pretty simple test box to open a SR with.
John
Maybe you are looking for
-
I went to tools, Options, attachments and there are associated programs that should be able to open files - Windows Live Photo gallery for the Microsoft Excel for excel files and JPG files. I actually download and save the files and then open them. I
-
percentages vertical positioning depends on the width of the block?
I seem to have found a problem when firefox is positioning of blocks based on the values of percentage margin offsets In short, look at this page: http://akos.maroy.hu/~akos/frontend/experiment/awake.html the desired size of the image section is 75%
-
Windows Movie Maker DVD will not play in my DVD of Emerson drive
Burned DVD won't play in my dvd player. I worked on it for three days. I burned a movie on a dvd + rw disc. The film will play on my computer but won't play in my dvd player. I get "Disk error" on the screen and the disc may not have playback functio
-
Could not open the film downloaded, Chrome tabs are not open and the computer does not turn off
I downloaded a movie from torrent and tried to open it, but it did not open, and now I'm still not able to close the downloads tab in chrome page.google does not open also. more my pc isn't even close. Please resolve these issues. It's very urgent! O
-
just upgraded to Windows 10. My lightroom (point 6.1.1) no longer respond (hangs) when I pass it draws to develop the module.(I also update to the latest version of LR)