Separator in CSV file analysis
Hey,.I use the HTMDB_TOOLS to analyze my csv files, it works exceptionally well with one exception,
Because we have users with systems with different regional settings sometimes only the csv separator can be; Instead of
I searched through the package body and found where we can change the separator, unfortunately my knowledge of writing scripts is not so great for the change: s
Can someone help me get the analysis to look at either. or, as separator?
Thanks in advance
Ozzy
create or replace PACKAGE BODY htmldb_tools
AS
TYPE varchar2_t IS TABLE OF VARCHAR2(32767) INDEX BY binary_integer;
-- Private functions --{{{
PROCEDURE delete_collection ( --{{{
-- Delete the collection if it exists
p_collection_name IN VARCHAR2
)
IS
BEGIN
IF (htmldb_collection.collection_exists(p_collection_name))
THEN
htmldb_collection.delete_collection(p_collection_name);
END IF;
END delete_collection; --}}}
PROCEDURE csv_to_array ( --{{{
-- Utility to take a CSV string, parse it into a PL/SQL table
-- Note that it takes care of some elements optionally enclosed
-- by double-quotes.
p_csv_string IN VARCHAR2,
p_array OUT wwv_flow_global.vc_arr2,
p_separator IN VARCHAR2 := ','
)
IS
l_start_separator PLS_INTEGER := 0;
l_stop_separator PLS_INTEGER := 0;
l_length PLS_INTEGER := 0;
l_idx BINARY_INTEGER := 0;
l_quote_enclosed BOOLEAN := FALSE;
l_offset PLS_INTEGER := 1;
BEGIN
l_length := NVL(LENGTH(p_csv_string),0);
IF (l_length <= 0)
THEN
RETURN;
END IF;
LOOP
l_idx := l_idx + 1;
l_quote_enclosed := FALSE;
IF SUBSTR(p_csv_string, l_start_separator + 1, 1) = '"'
THEN
l_quote_enclosed := TRUE;
l_offset := 2;
l_stop_separator := INSTR(p_csv_string, '"', l_start_separator + l_offset, 1);
ELSE
l_offset := 1;
l_stop_separator := INSTR(p_csv_string, p_separator, l_start_separator + l_offset, 1);
END IF;
IF l_stop_separator = 0
THEN
l_stop_separator := l_length + 1;
END IF;
p_array(l_idx) := (SUBSTR(p_csv_string, l_start_separator + l_offset,(l_stop_separator - l_start_separator - l_offset)));
EXIT WHEN l_stop_separator >= l_length;
IF l_quote_enclosed
THEN
l_stop_separator := l_stop_separator + 1;
END IF;
l_start_separator := l_stop_separator;
END LOOP;
END csv_to_array; --}}}
PROCEDURE get_records(p_blob IN blob,p_records OUT varchar2_t) --{{{
IS
l_record_separator VARCHAR2(2) := chr(13)||chr(10);
l_last INTEGER;
l_current INTEGER;
BEGIN
-- Sigh, stupid DOS/Unix newline stuff. If HTMLDB has generated the file,
-- it will be a Unix text file. If user has manually created the file, it
-- will have DOS newlines.
-- If the file has a DOS newline (cr+lf), use that
-- If the file does not have a DOS newline, use a Unix newline (lf)
IF (NVL(dbms_lob.instr(p_blob,utl_raw.cast_to_raw(l_record_separator),1,1),0)=0)
THEN
l_record_separator := chr(10);
END IF;
l_last := 1;
LOOP
l_current := dbms_lob.instr( p_blob, utl_raw.cast_to_raw(l_record_separator), l_last, 1 );
EXIT WHEN (nvl(l_current,0) = 0);
p_records(p_records.count+1) := utl_raw.cast_to_varchar2(dbms_lob.substr(p_blob,l_current-l_last,l_last));
l_last := l_current+length(l_record_separator);
END LOOP;
END get_records; --}}}
--}}}
-- Utility functions --{{{
PROCEDURE parse_textarea ( --{{{
p_textarea IN VARCHAR2,
p_collection_name IN VARCHAR2
)
IS
l_index INTEGER;
l_string VARCHAR2(32767) := TRANSLATE(p_textarea,chr(10)||chr(13)||' ,','@@@@');
l_element VARCHAR2(100);
BEGIN
l_string := l_string||'@';
htmldb_collection.create_or_truncate_collection(p_collection_name);
LOOP
l_index := instr(l_string,'@');
EXIT WHEN NVL(l_index,0)=0;
l_element := substr(l_string,1,l_index-1);
IF (trim(l_element) IS NOT NULL)
THEN
htmldb_collection.add_member(p_collection_name,l_element);
END IF;
l_string := substr(l_string,l_index+1);
END LOOP;
END parse_textarea; --}}}
PROCEDURE parse_file( --{{{
p_file_name IN VARCHAR2,
p_collection_name IN VARCHAR2,
p_headings_item IN VARCHAR2,
p_columns_item IN VARCHAR2,
p_ddl_item IN VARCHAR2,
p_table_name IN VARCHAR2 DEFAULT NULL
)
IS
l_blob blob;
l_records varchar2_t;
l_record wwv_flow_global.vc_arr2;
l_datatypes wwv_flow_global.vc_arr2;
l_headings VARCHAR2(4000);
l_columns VARCHAR2(4000);
l_seq_id NUMBER;
l_num_columns INTEGER;
l_ddl VARCHAR2(4000);
BEGIN
IF (p_table_name is not null)
THEN
BEGIN
execute immediate 'drop table '||p_table_name;
EXCEPTION
WHEN OTHERS THEN NULL;
END;
l_ddl := 'create table '||p_table_name||' '||v(p_ddl_item);
htmldb_util.set_session_state('P149_DEBUG',l_ddl);
execute immediate l_ddl;
l_ddl := 'insert into '||p_table_name||' '||
'select '||v(p_columns_item)||' '||
'from htmldb_collections '||
'where seq_id > 1 and collection_name='''||p_collection_name||'''';
htmldb_util.set_session_state('P149_DEBUG',v('P149_DEBUG')||'/'||l_ddl);
execute immediate l_ddl;
RETURN;
END IF;
BEGIN
select blob_content into l_blob from wwv_flow_files
where name=p_file_name;
EXCEPTION
WHEN NO_DATA_FOUND THEN
raise_application_error(-20000,'File not found, id='||p_file_name);
END;
get_records(l_blob,l_records);
IF (l_records.count < 2)
THEN
raise_application_error(-20000,'File must have at least 1 ROW, id='||p_file_name);
END IF;
-- Initialize collection
htmldb_collection.create_or_truncate_collection(p_collection_name);
-- Get column headings and datatypes
csv_to_array(l_records(1),l_record);
csv_to_array(l_records(2),l_datatypes);
l_num_columns := l_record.count;
if (l_num_columns > 50) then
raise_application_error(-20000,'Max. of 50 columns allowed, id='||p_file_name);
end if;
-- Get column headings and names
FOR i IN 1..l_record.count
LOOP
l_headings := l_headings||':'||l_record(i);
l_columns := l_columns||',c'||lpad(i,3,'0');
END LOOP;
l_headings := ltrim(l_headings,':');
l_columns := ltrim(l_columns,',');
htmldb_util.set_session_state(p_headings_item,l_headings);
htmldb_util.set_session_state(p_columns_item,l_columns);
-- Get datatypes
FOR i IN 1..l_record.count
LOOP
l_ddl := l_ddl||','||l_record(i)||' '||l_datatypes(i);
END LOOP;
l_ddl := '('||ltrim(l_ddl,',')||')';
htmldb_util.set_session_state(p_ddl_item,l_ddl);
-- Save data into specified collection
FOR i IN 2..l_records.count
LOOP
csv_to_array(l_records(i),l_record);
l_seq_id := htmldb_collection.add_member(p_collection_name,'dummy');
FOR i IN 1..l_record.count
LOOP
htmldb_collection.update_member_attribute(
p_collection_name=> p_collection_name,
p_seq => l_seq_id,
p_attr_number => i,
p_attr_value => l_record(i)
);
END LOOP;
END LOOP;
DELETE FROM wwv_flow_files WHERE name=p_file_name;
END;
BEGIN
NULL;
END;The order of the parameters for the parse_file in the specification and body must match. In your case, it stopped the p_separator parameter (before nom_table_p in spec, but otherway around body) which is the origin of the problem of compiling again.
Tags: Database
Similar Questions
-
Deploy the CSV file virtual computer
Hello world!
I want to deploy multiple VM to a .csv file. I know this is pretty basic, but I don't get to work... What I've done wrong?
Here's my scrypt:
$list = import-CSV C:\config1_new_vm.csvWrite-Output $list$vcenter_ip = "192.168.0.14.SE connect-VIServer-Server $vcenter_ip-user root - password passwordforeach ($line in $list){New-VM-name $line.name - host $line.host Datastore - $line.datastore - DiskMB $line.disk MemoryMB - $line.memory - NumCPU $line.cpu - ID rhel5_64Guest - CD - Description 'RH5 Linux '.}Here my .csv file:

The result is:
name host datastore. disc; memory; UC
-----------------------------------
VM1 h1e0mudag - a.dc.infra.com h1e0mudag-local-storage. 200; 512; 1
h1e0mudag - a.dc.infra.com; h1e0mudag-local-storage; 300; 513, VM2; 2
New-VM: could not validate argument on the parameter 'Name '. Argument is null or empty.
Because I'm French, the message is in French, but for those who do not understand French, it basically means:
Unable to validate the argument in the parameter 'Name '. The argument is Null or is empty.
I do not understand... I can select my csv file lines but could not get the colomns... Is New-VM-name $line.name not right?
Thanks for your replies.
Pozitim
Try changing the line
$list = import-CSV C:\config1_new_vm.csv
in
$list = import-CSV C:\config1_new_vm.csv - UseCulture
By default, PowerShell expects the separator in CSV files to be a comma.Your output, it seems as if your regional settings set the separator like semicolumn.With the UseCulture switch the cmdlet will use the locale to determine the separator. -
Construction of a CSV file with tabs-DELIMITED
Apex 3.1.2
Customer wishes to build a report of the Apex with CSV output, but have DELIMITED by tabs columns, not. Any ideas on how to insert a tab CHARACTER in the 'Separator' column CSV file?
Thank you
DwightHi, Dwight
If you open an editor, such as Microsoft Word and in a new document, press the tab key. If you copy and paste it into the CSV separator in the report attributes.
Concerning
Paul
-
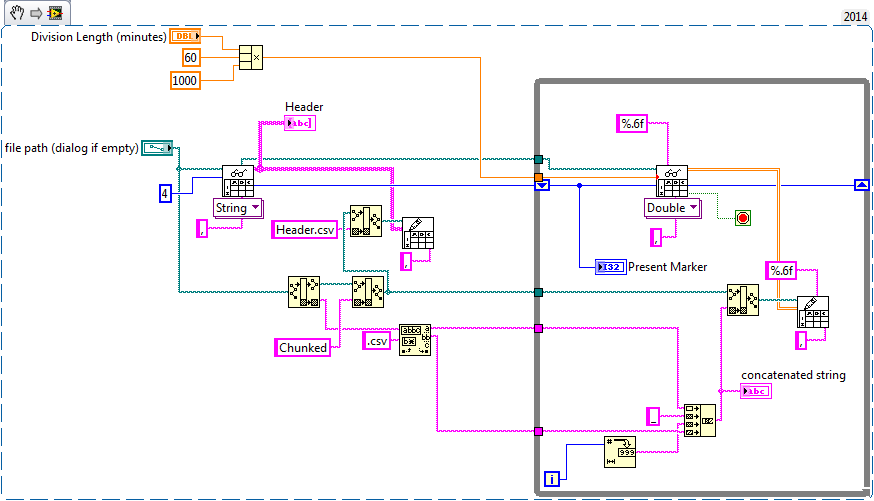
Segmentation of a huge CSV file for easier analysis
I have a CSV file that contains 3 columns: time, voltage and current. This data covers a period of 12 days with 1 ms between the samples and the size of the file is 53.4 GB!
I use LabVIEW to chunk this file into pieces easier to manage for analysis using spreadsheet File.vi reading and write a File.vi spreadsheet and my method works very well... to a point. Here's a snippet of what I do:
I use the "start offset reading" of entry to reading worksheet File.vi inch my way through the file, but since it is a type of data I32 it rolls more and VI out errors. I think I have to do, is remove pieces of the main file that I read and write in their respective smaller file, but the method to do this is me stumping. Y at - it suggestions on how I could pull this off while using the worksheet vi file (to avoid reinventing the wheel as much as possible)?
Some ideas: I'm playing:
1. of iteratively, delete data and reset to '0' marker in the file (reading data in order from the present to the future).
2. start at the END of the file (i.e. read data from future to present) and iterative set the smaller size, eliminating the data blocks that I will.
The simplest solution would probably be to modify the existing worksheet screws (or a copy you make of them) - you did, they use 32-bit values to track the location, but if you look inside the screw, you should see that the actual file functions use 64-bit values (the values of 32 bits in the functions are actually used for backward compatibility). I haven't looked closely, but my guess is that you can simply change this option to be 64 bit and that your code should then be able to go through the entire file.
-
Must be able to open the .csv file in Excel separated by two, and; -Windows 7 list separator
Original title: list separator Windows 7
Hi, I was wondering is it possible to add 2 values to list separator? I need to be able to open the .csv file in Excel separated by two, and; At the moment I can only do that if I continue to change the list separator value in the regional settings of Windows Alternatively, depending on which file I want to open. Is it possible to add both? I tried to add, and; separated by spaces, but it did not work. Any suggestions would be much appreciated! Thank you!
It may be one, sorry. But you can use an Excel template or Excel macro to analyze and open any kind of delimited file of reproducibly (even give you one-click button on the toolbar in Excel to do if you wish), and this is probably the best option.
-
Analysis 1 row into two lines from a CSV file
Hello
Im trying to read a csv of the external table data in a table target.
the problem is, I have a few lines, two names and names separated by spaces zwo (aspect ID2 and ID4)
the csv data have this format:
Source CSV file
ID1 | "" Max Miller ' | "Lyonerstr 99" | " "1000" | " "" Berlin "| "' The Germany.
ID2. «Hans Meyer Heidi Meyer «|» "Lyonerstr 100" | " "1000" | " "" Berlin "| "' The Germany.
ID3 | "" Stefan Tek | "Lyonerstr 200" | " "1000" | " "" Berlin "| "' The Germany.
ID4. ' José María Acero Acero ' |. ' "" Abcstr 111 | "2000" | " "" Hamburg ". "' The Germany.
Target table
ID1 | Max Miller | 99 Lyonerstr | 1000 | Berlin | Germany
ID2. Hans Meyer | Lyonerstr 100 | 1000 | Berlin | Germany
ID2. Heidi Meyer | Lyonerstr 100 | 1000 | Berlin | Germany
ID3 | Stefan Tek | Lyonerstr 200 | 1000 | Berlin | Germany
ID4. José Acero | Abcstr 111 | 2000. Hamburg | Germany
ID4. Maria Acero | Abcstr 111 | 2000 "|" Hamburg | Germany
Thank you very much.
with
external_table as
(select 'ID1' u_id, f_l_name 'Max Miller', ' Lyonerstr 'address, zip ' 1000' 99, "Berlin" city, country "Germany" in double union ")
Select 'ID2', 'Hans Meyer Heidi Meyer', ' Lyonerstr 100 ', ' 1000', 'Berlin', 'Germany' of the dual union all.
Select 'ID3', "Stefan Tek", "Lyonerstr 200 ', ' 1000', 'Berlin', 'Germany' of the dual union all.
Select "ID4", 'José Acero Acero Maria', ' Abcstr 111 ', ' 2000', 'Hamburg', 'Germany' from dual.
)
Select u_id, f_l_name, address, zip, city, country
from (select u_id,
-case when instr (f_l_name,' ') > 0
so to case when level = 1
then substr (f_l_name, 1, instr (f_l_name,' ')-1)
of another substr (f_l_name, instr (f_l_name,' ') + 2)
end
another case when level = 1
then f_l_name
end
end f_l_name
address, zip, city, country
of external_table
connect by level<=>
and prior u_id = u_id
and the previous address = address
zip and rar = prior
and prior city = city
and prior country = country
and prior sys_guid() is not null
)
where f_l_name is not null
U_ID F_L_NAME ADDRESS ZIP CITY COUNTRY ID1 Max Miller 99 Lyonerstr 1000 Berlin Germany ID2 Hans Meyer Lyonerstr 100 1000 Berlin Germany ID2 Heidi Meyer Lyonerstr 100 1000 Berlin Germany ID3 Stefan Tek Lyonerstr 200 1000 Berlin Germany ID4 José Acero Abcstr 111 2000 Hamburg Germany ID4 Maria Acero Abcstr 111 2000 Hamburg Germany Concerning
Etbin
-
Address book import of csv file gets empty address book
I have a .csv file from a Windows 'Contacts' window. It contains four hundred entries, each composed of a name and E-mail address. The first line of the file says .csv "name, Email '; the entries are separated by returns and the areas that fall within the comma.
When I import to intoThunderbird, I say to import an address book from the file and to import only the Email address and display name fields. When the import is executed, it is very fast and no errors are displayed. The new address book is displayed among the Thunderbird address books, but it is empty.
Thank you
Joe NelanTo import an address book, try the following steps:
Of the Treasury Board, click "Address book" (or 3-bar menu-> tools-> address book).
In the list in the left pane address books, click the one you want to import (or use the "personal address book").
On the menu bar, select Tools-> import. Opens a new window "import."
Click on "Address books" and "Next"
Select "Text file", click "Next".
Near the lower-right corner replace LDIF 'separated by commas.
Navigate to the folder where your CSV file. Left click on it once. Click on 'open '.
For CSV, there is no standard for the number or the order of the fields. The screen you see allows you to 'match' your entry with the fields of TB.
With respect to mapping of the fields, you have two columns: one of your CSV names and one of the CT. What you're trying to get first name, last name first name family name, etc.. If you are lucky, they will be already matched to the top. But if not, you can click on one and move it upwards or downwards in the list until it is opposite the name of the corresponding field. This will get names, email, phone, etc. in the right places. Make sure the fields are checked and the ones you don't want is unchecked.
Once you have everything set, click OK.Note 1: the file name of your CSV file becomes the name of the address book (for example AddrBook.csv will produce an address book named "AddrBook").
Note 2: when you first watch the imported address book, it can be empty. Click on another (for example, "personal address book"), and then return to that matter. -
Export to a CSV of tiara does not produce a CSV file!
Seems strange but exporting to a CSV of tiara does not a CSV file. Tiara produces a tab delimited file, which is obviously not a CSV file. Tiara aid said even the 'CSV' file is a tab-delimited. The software expects a comma as delimiter does not read the file properly created tiara. It is possible to specify the correct delimiter?
You can ask the decimal/separator, you need if you start exporting CSV from a script
Call DataFileSave ("
C:\temp\EXAMPLE.csv See also http://forums.ni.com/ni/board/message?board.id=60&message.id=8851&query.id=146775#M8851
-
Hello
I save my data from a Vision image analysis results to a CSV file. Works great! Now, I want to read the CSV file automatically by a server application. I need some tips or tricks to avoid access by the server or labview violations if the two programs want to read / write to the file at the same time.
What I want to do:
The server application read the output file every 30 seconds:
Read the data and delete thereafter - so no duplicate data should return.
LabVIEW writes the data to the file:
If the file does not exist: (deleted) create a new
If the file is in use: try it next time again (to lose one or two sets of data is not important)
I want to use the function "write to the spreadsheet", but maybe someone can give me a tip on how to use this or that to do a better job!

Best regards
Paul
Hi Paul,.
couldn't you just try it (see attachment):
5 error the file is already open.
Is this OK for you?
Best regards
Christoph
-
Problem loading of a large number of csv files
Hi all
I have a problem loading of a large number of csv files in my LabVIEW program. I have attached a png image of the code simplified for only loading sequence.
What I want to do is load the data of 5000 laser beam profiles, so 5000 files csv (68 x 68 elements), and then proceed to an analysis of data. However, the program will only ever 2117 files, and I get no error message. I also, tried at the beginning of loading a single file, selecting an area of cultures - say 30 x 30 items - and then to load the rest of the files cropped to these dimensions, but I always get only 2117 files.
Any thoughts would be appreciated,
Kevin
-
Hello
I know this question has been asked several times, but I did write read the. CSV file in labview. Although I read only first coloum and also it does not read the exact value. It is rounded to almost integer. I checked all the settings in the representation of the data, but have no luck. Someone can help me.
Your 'CSV' file contains a semicolon as field separator.
Your VI uses the separator by default when reading the file. The default value is a character from
. You also index the column even twice. See attachment to see how to load the file you provided...
-
How to scan more than 100 items of csv file in labwindows/CVI
Hello
I need little help related to playback of content from. CSV file.
My code is as follows:
FP = OpenFile ("FileName.csv", VAL_READ_ONLY, VAL_OPEN_AS_IS, VAL_ASCII);
ReadLine (FP, Line,-1);
I use the Scan() function to store all these values in the separate variable.
But I am getting error near following Scan() format string.
Please help me in this regard.
Thank you
Herald
Hi Ruben,.
the method simpler and faster to scan more than 100 arguments from a line is probably to use the keyword "rep" in the format string, as you can see in the onluen documentation and in following example taken from the ICB help: "String with separated by commas of the ASCII values in real table" search in the linked page. After reading return values, you can decide how to divide your table of values in important variables in your.
Another option would be to read online and then manually manage in a loop using strtok () function of line in single values.
-
How to create a header in csv file
I m still beginner in Labview, I'm just learning it this week...
I want to do a data conversion for temperature probe...
I m having trouble creating a header in the csv file, can anyone help me?
I am also attaching my csv file, what I wanted to do like this:
DT (ms) channel 0 channel 1 Channel 2 0.1 1 2 3 0.2 4 5 6 0.3 7 8 9 0.4 10 11 12 I also want to know how to make time to count 0 not real time...
Citras wrote:
I have to solve the problem, it s quite confusing, I have to use; instead of \t in the separator.
What is so confusing to this topic? You have chosen to use the semicolon, so you must explicitly specify the VI to use instead of the default of a tab.
When I start the program, can I do the dt (ms) count of 0? What I can do is to use the Date/Time Format string, I want Don t the time based on real time count
You can subtract the current time of the time at the beginning of the program. Use the time to get based on seconds outside of the loop let you time initially and then use it inside to get the current time. Subtract. Note that your loop is clocked by the software, so you won't get the same amount of delta.
Also: do not hard code paths in the code. What do you think will happen if someone tried to run your VI on a XP machine? This will not work because of the path of the file. Use a control with a default value defined for it.
-
I need a program installed that will open csv files.
I am trying to copy and print my DYMO addresses, but I don't have an imstalled program on my computer that will open csv files.
Values of comma-separated (CSV) files can be opened with any editor text like Word or Notepad or with any spreadsheet such as Excel or Lotus 1-2-3 program.
John
-
Unwittingly, I asked for a way to watch the CSV files.
I was sent to a program that is downloaded into my computer. With Vista, how can I quickly find this program and delete it. I have done nothing else in the computer, but write to you guru. Thank you very much.
Hello DaveF1953,
Thank you for your message. The. The extension is CSV refers to "Comma Separated Values". Usually (not always), it is a format that can be used for the transfer of personal and other address books. As stated Michael Murphy, we would need to know more information before we can give you sound advice. If you need to view the information contained in the .csv file, try to open the file with Excel if you have Office on your computer.We can't wait to hear back on your part.See you soonEngineer Jason Microsoft Support answers visit our Microsoft answers feedback Forum and let us know what you think.

Maybe you are looking for
-
I use Windows 7 with firefox as my default browser. When I download a program using firefox, I wonder if I want to save the file, and then must go to the download folder to start the download. When I download using internet explorer, I gives me the a
-
Portege Z30 - smart card reader does not work
Hi, I just got my new Portege Z30 a few days ago.I try to use the card reader chip for my Spanish ID (DNIe) and seems to not work.When I insert the card as stated in the users manual, nothing happens.I have to player of SC "actuvate" somehow? (DNIe n
-
How do I transfer photos from Picasa to WLPG?
I want to transfer pictures and some videos of Picasa3 to WLPG how?
-
Email of Smartphones blackBerry after software update issues
First of all, I want to express my displeasure of RIM or AT & T to not notify me that all my settings, emails and messages text would be handed over to zero/erased with the software update. I am more than now, but I still have an annoying problem.
-
Program compatibility - reinstall an old American Greetings crafts #2 program
This old program will not reinstall on a new version of the Windows 7 computer. Broderbund is the title company that shut down to American Greetings with a copyright of 1999. Licensed by the learning company. It was made for Windows 95/98 & Windows N