Simple XML - generation
Hi all
I would like to generate an XML file as follows in the Fig.

I can able to generate all the elements except which is marked in red and attachment vi for Ref. (there is a node called invoke insert XML but I am not able to succeed with that). Please can someone help with this problem.
Thanks in advance...
I can't open the vi posted since I'm still uisng LV2009, so it can duplicate what has already been posted. As has been specified that the State is an attribute of the real node.
Ben64
Tags: NI Software
Similar Questions
-
Switch from a simple Xml call to an rpc-Http call...
Hello
I need to go through a simple call from Xml:
<mx:XML id="urlsGeneral" source="http://www.mySite.com//.../AFS.xml"/>
for an rpc-Http call which updates the display if Xml is changed at any time.
I forgot to mention the most important and yet very simple point: I need it only to display in a title, etc. and NOT a datagrid or good example below.
title = "{urlsGeneral.urlGeneral. (()_@name==0).age}
I tried a lot today, but just can't get it right like id = "urlsGeneral" is always the problem.
Any help would be appreciated! Thanks in advance. cordially aktell2007
< urlsGeneral >
< urlGeneral >
< name > Jim < / name >
< 32 > < / age >
< / urlGeneral >
< urlGeneral >
< name > Jim < / name >
< 32 > < / age >
< / urlGeneral >
< / urlsGeneral >
Another call:
< mx:Script > <! [CDATA] Import mx.collections.ArrayCollection; Import mx.rpc.events.ResultEvent; public var myData:ArrayCollection; protected function myHttpService_resultHandler(event:ResultEvent):void {} myData = event.result.urlsGeneral.urlGeneral; } []] > < / mx:Script > < mx:HTTPService ID = "myHttpService". url = » http://www.mysite.com//.../AFS.XML " result = "myHttpService_resultHandler (Event)" / > Best I wanted something like this works:
< mx:Script > <! [CDATA] Import mx.rpc.events.FaultEvent; Import mx.managers.CursorManager; Import mx.controls.Alert; Import mx.rpc.events.ResultEvent; Import mx.rpc.xml.SimpleXMLDecoder; Do not here it is already used in .swc! / * import mx.rpc.http.HTTPService; */ private var myHTTP:HTTPService; private function initConfigCall (): void {} myHTTP = new HTTPService(); myHTTP.url = "com/assets/data/changesAppAIRPIOne001.xml"; myHTTP.send (); myHTTP.resultFormat = "xml"; myHTTP.addEventListener (ResultEvent.RESULT, resultHandler); myHTTP.addEventListener (FaultEvent.FAULT, faultHandler); CursorManager.setBusyCursor (); } private void resultHandler(evt:ResultEvent):void {} var xmlStr:String = evt.result.toString (); var xmlDoc:XMLDocument = new XMLDocument (xmlStr); var decoder: SimpleXMLDecoder = new SimpleXMLDecoder (true); var resultObj:Object = decoder.decodeXML (xmlDoc); Removed [0] on single node! appUpdateAvl.text = resultObj.application.configApp.appNewUpDate; appLastChanged.text = resultObj.application.configApp.appLastChanged; appChangedSections.text = resultObj.application.configApp.appChangedSections; CursorManager.removeBusyCursor (); myHTTP.disconnect (); } private void faultHandler (event:mx.rpc.events.FaultEvent): void {} var faultInfo:String = "details of the fault:"+ event.fault.faultDetail+"\n\n"; " "faultInfo += ' Fault faultString: '+ event.fault.faultString+"\n\n; mx.controls.Alert.show (faultInfo, "lack of information"); var eventInfo:String = "event target:"+ event.target+"\n\n"; " ' type of event eventInfo += ":"+ event.type+"\n\n; mx.controls.Alert.show (eventInfo, "Event information"); CursorManager.removeBusyCursor (); myHTTP.disconnect (); } []] > < / mx:Script > Hi again,
These days there are more questions than answers on a forum, and very rarely someone sharing the answer if they luck out so here is my answer to the above question is
Switch from a simple Xml call to an rpc-Http call...
I got it all along as a commend noted: / / deleted [0] single knot!
Then, instead of title = "{urlsGeneral.urlGeneral. (()_@name==0).age} it would be now title = "{resultObj. }" {urlsGeneral.urlGeneral. [0] .age} and now it works perfectly well. I hope one or the other of you can use the code and the answer! best regards aktell2007
-
How to query a simple XML - no matter what example?
People, I have a coaster XML stored in the table, the column type XMLTYPE.
I would like to extract all the data by using a simple query + later insert rows returned in other fake tables.
This should be an easy task for someone who's using XML on daily basis.
XML is stored in the column of table TEST_XML donnees_xml:<env:Envelope xmlns:env='http://schemas.xmlsoap.org/soap/envelope/'> <env:Header></env:Header> <env:Body> <ns1:getVehiclesResponse xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ns1="http://wirelesscar.com/dynafleet/api/types"> <result> <vehicleInfos> <displayName>TRUCK 1</displayName> <vehicleId> <id>15631444</id> </vehicleId> </vehicleInfos> <vehicleInfos> <displayName>TRUCK 2</displayName> <vehicleId> <id>1564652</id> </vehicleId> </vehicleInfos> <vehicleInfos> <displayName>TRUCK 3</displayName> <vehicleId> <id>15634543</id> </vehicleId> </vehicleInfos> </result> </ns1:getVehiclesResponse> </env:Body> </env:Envelope>
I would like to extract all nodes of < result > from a query.select ... extract(dr.response_env, '//result/vehicleInfos/displayName/text()').getStringVal() from TEST_XML
Kind regards
Tomasselect x.displayName, x.vehicleId from TEST_XML dr ,XMLTABLE('//result/vehicleInfos' PASSING dr.XML_DATA COLUMNS displayName varchar2(100) PATH 'displayName', vehicleId varchar2(100) PATH 'vehicleId/id') x ;SY.
-
Cannot open a simple XML file.
Hello
This has probably been answered, but the search bar in the forum seems to be broken, so I couldn't get him.
I tried to open a file xml with a simple application:
<? XML version = "1.0" encoding = "utf-8"? >
" < = xmlns:fx s:Application ' http://ns.Adobe.com/MXML/2009 "
xmlns:s = "library://ns.adobe.com/flex/spark".
xmlns:MX = "library://ns.adobe.com/flex/mx" minWidth = "955" = "600" minHeight >
< fx:Script >
<! [CDATA]
Import mx.rpc.events.FaultEvent;
Import mx.rpc.events.InvokeEvent;
Import mx.rpc.events.ResultEvent;protected function srv_resultHandler(event:ResultEvent):void
{trace ("result") ;}protected function srv_invokeHandler(event:InvokeEvent):void
{trace ("invoke") ;}protected function srv_faultHandler(event:FaultEvent):void
{trace ("fault") ;}protected function button1_clickHandler(event:MouseEvent):void
{trace ("breakpoint"); }[]] >
< / fx:Script >
< fx:Declarations >
< s:HTTPService id = "srv" url = "data.xml"
result = "srv_resultHandler (Event)" "
Invoke = "srv_invokeHandler (Event)" "
Fault = "srv_faultHandler (Event)" / >
< / fx:Declarations >
< s:Button click = "button1_clickHandler (event)" / >
< / s:Application >The HTTPService gives me nothing; any error, no cases of success, no invoke. When I freeze the program and look at the "srv", it does not seem to contain any thing useful, like whether to take data from.
The "Data.xml" is both in the src folder and parent his folder, and it looks like this:
<? XML version = "1.0" encoding = "utf-8"? >
< root >
< chart >
< Game >
< x >/< x > 1
< a > 1 / < y >
< / set >
< Game >
< x > 2 / < x >
< y > 4 / < y >
< / set >
< / chart >
< / root >Why does this work?
Hello
I can't see in your code you are using srv.send ().
Try calling srv.send () on the creation complete event handler to load the xml file.
-
Hi, I am using the following code:
dibujos_XML = new XML (_loader.data);
var _dibujos:XMLList = dibujos_XML.children ();
var _dibujo_id:Number;
for each {(var _dibujo:XML in _dibujos)
//
If (_dibujo.localName ()! = "dibujo")
throw new Error ("nodo XML no es UN dibujo");
If (_dibujo.hasOwnProperty ("id") is false)
throw new Error ("nodo XML no foreigners contains");
//
_dibujo_id = Number (_dibujo.id);
trace (_dibujo_id) / /. ToXmlString());
}
on the following file:
< p >
< dibujo id = "1" > a < / dibujo >
< dibujo id = "2" > as < / dibujo >
< dibujo id = "34" > asd < / dibujo >
< dibujo id '54' = > 123 < / dibujo >
< /p >If she was doing which, in my view, it should do so, it must take each node "dibujo", check that it was a "dibujo" (that part works well so far), then check each "dibujo" had a property ID this part is a failure. It seems to be thrown an exception with the following sentence:
If (_dibujo.hasOwnProperty ("id") is false)
throw new Error ("nodo XML no foreigners contains");
If I comment on this sentence, there is no error but the patterns print all 0s. If I have understood correctly, he must check the current node stored in "_dibujo" has a property called 'id', who all and set the value of this property of some other var, which didn't seem to do. pointers?
TNX
ID is an attribute, you must use:
_dibujo.hasOwnProperty ("@ID")
-
Hi dear flash community!
I want to create an XML file dynamically in flash and store it on your hard drive.
for example, it should look like this:<song> <title>titlename</title> <artist>artistname</artist> </song>
first of all, I tried this code:
var my_xml = new XML(); var node = my_xml.createElement("song"); my_xml.appendChild(node); node = my_xml.createElement("title"); my_xml.firstChild.appendChild(node); node = my_xml.createTextNode("titlename"); my_xml.firstChild.firstChild.firstChild.appendChild( node); node = my_xml.createElement("artist"); my_xml.firstChild.appendChild(node); node = my_xml.createTextNode("artistname"); my_xml.firstChild.firstChild.firstChild.appendChild( node);but then I get this:
"the < title > song > < titlenameartistname < / title > < artist / > < / song >.
of course, that is not correct.2)
then I tried this onevar my_xml = new XML("<song><title></title><artist></artist></song>"); my_xml.firstChild.firstChild.firstChild.nodeValue = "TEXT"; trace (my_xml);result of trace: <song><title /><artist /></song>
so I try to change the nodeValue then to the 'TEXT', which is not possible.
I would like to be able to define the overall structure (only the elements but no text inside the tags) and insert the text inside the tags (and add items) later dynamically.
I hope someone can help me.
welcome PeterTry:
var my_xml = new XML();
var node = my_xml.createElement ("song");
my_xml. AppendChild (Node);node = my_xml.createElement ("title");
my_xml.FirstChild.appendChild (Node);node = my_xml.createTextNode ("titlename");
my_xml.FirstChild.FirstChild.appendChild (Node);node = my_xml.createElement ("artist").
my_xml.FirstChild.appendChild (Node);node = my_xml.createTextNode ("artistname");
my_xml.FirstChild.FirstChild.NextSibling.appendChild (Node); -
The analysis of a simple XML file
Hello
In the XML code shown below, I want to get the value of the ID element that is nested in the item BOX.
The ColdFusion code that I have in my example outputs the xmltext of the RICHTEXT item.
What a change I would make to the value of the ID (e.g. text 1) followed by the exit of the RICHTEXT element?
I wish it were something like
Text 1: sweet
Text 2: Frédérique Joe vineyard
I really don't need to worry about the other elements or attributes. Those are the only ones I need. Any suggestions?
Best regards
KevinThe following seems to do what you want.
-
Simple XML problem. Help, please.
Hello
It's my RSS project. All I want is to show all titles in the upper window. Any idea?
private var cnnNS:Namespace = new Namespace (" http://rss.cnn.com/rss/cnn_world.rss");
-
Generation of XML with an INTO clause
I have a simple Xml DDE.
example query
I want to generate xml like this... I don't know how to use XMLELEMENT when there is an into clause...select * into variable1, variable 2 from table_1;
Thank you<row> <vraiable1>xxx</vraiable1> <vraiable2>yyy</vraiable2> </row>It depends on what you want to do with the variable.
Function XMLElement() returns an XMLType instance, so the target variable must be of type XMLType, for example:
DECLARE v_xmlrow XMLType; BEGIN select xmlelement("row" , xmlelement("var1", col1) , xmlelement("var2", col2) ) into v_xmlrow from table_1 where; END; / You can also return a serialized (text) representation of the XML document that is obtained as a CLOB or VARCHAR2, using methods. getClobVal() or. getStringVal() in 10 g and 11 g XMLSerialize() function.
-
Right now I work with a very simple .xml file that retrieves data ultimately resulting in the generation of run-time components. Here is a simplified version:
< data >
< article type = "Button" x = "50" y = "100" label = "Button 1" / >
< article type = "Button" x = "50" y = "300" label = "Button 2" / >
< / data >
I figured out how to remove an attribute, such as the "label" with this:
If (. name(). attributes() [i] myXML.item [0] == "label" "")
{
delete myXML.build.item [0]. attributes() [i];
i-- ;
}
Now, the question is how can I add another attribute - like the "height"? Any help would be greatly appreciated. Thank you.Okay, I just stumbbled on the solution:
x 1. @["name"] = "test 2"; "
This seems to do. I don't know if the reverse works just not or if I did it all just bad. Thanks for your help.
-
The 'answer' is perhaps that "XML is not intended for this purpose... "but here is the situation:
I'm parsing of a directory tree and creating a table of clusters, one for each folder in the tree. To save it to the 'user-friendly' on the disc format, I chose XML, in part because "it's here", because it is a 'standard', and part because he "embarked" in the file enough data LabVIEW structure it is easy, in principle, to recover the data in the same shape as I initially wrote (i.e. in the form of clusters with a specified TypeDef table).
I did my routine to a directory with about 2700 folders tree. It took 14 seconds to analyze the tree, about 0.1 second to write to the file (1.7 MB) XML, but over a minute and a half to read it back in and recover the original data. Incidentally, I made a comparison between the "written data" and "read data", and all the 25 000 elements (the cluster had 9 elements) are the same, so at least to read and write XML "works."
I'm always surprised at the 800-fold difference between reading and writing. I suspect that this shift is not linear with the "size of the problem", since in the beginning, I tried to do this with a larger painting of 4900 what took 0.25 seconds to write, but I "gave up" after what seemed to be too long to wait (sorry, it's so no scientist, but I think it was 3-4 minutes at least). However, now that I see that there is a difference of 800-fold for my previous example, I'll wait at least five minutes (800 * 0.25 sec = 200 s, 5 min = 300 sec)... (time goes away...)
Patience rewarded - it took 322 seconds, which is about 1200 times slower (not to criticize my calculations - I'm rounding when I report time, but use the millisecond values when I calculate ratios...). So the more you do it, it gets the slower.
Hmm - we are going to prove by doing a small folder. How about one with only 85 files? Which takes 21 msec to write and 102 msec to read, a factor of 5 only! Wow, this is certainly not a linear growth.
What happens here? Is there a problem with the analysis of large XML files? [I must point out that I use a simple XML File reading (array) for the table (of which will prove be cluster), and then in a for loop do a "Unflatten from XML' to recover the cluster.] I'm guessing that the loop is to behave linearly, as all clusters are (with the exception of their content) identical, then the part "polynomial time" should be "reading of XML File (array).
Not sure why this should be the case. It would seem, to me, that since LabVIEW tables are always "identical elements", read a file with 1000 'elements' and turn it into an array of 1000 elements should take approximately 10 times longer than that for an array of 100 elements, unless there is something that is extremely inefficient. Is this something that can withstand being examined and possibly optimized?
Bob Schor
PS - was curious enough to do more tests. I started with a 'Master Data Set' of 4906 records, then dealt with 'nested subsets' (which is a subset of the master, a subset of the subset, etc.) to try to compare of"apples with apples" (on a PC, of course). My samples were 20, 210, 2736 and 4906 records. The write speed of files has been between 10 K and 24K Records/sec on this beach, which is about nearly linearly with size. However, a similar measure for the reading of records varies between 3K (for all 20 items) and 15 (for all), reducing the size has increased. I traced a field of logarithmic data and got a slope of 0.1 for writing (a slope of 0 means speed is linear with the number of cases), but a slope of-0,95 for playback)
-
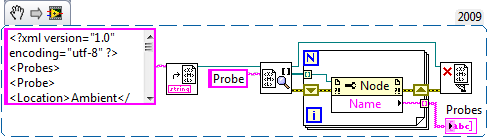
Just starting to learn more about XML.
I have a simple XML I created which is
Ambient panel1 panel2 panel3 Using the XML property - child results node table of nodes in a table of 9 elements:
#text Probe #text Probe #text Probe #text Probe #text
My question is what are all the #text that are there? Should the child nodes be not just the probes?
It seems to me you may be heading down a dark path. Instead of using the "table of nodes child" and fighting through the unnecessary complications and text nodes, let me suggest you look at XPath and using "get all matched Nodes.vi ' or 'Get first match Node.vi' to get the items. XPath allows parsing XML child's play.
For example:
Of course, I hope that you use XP does not mean you use LV8.6 or earlier since the XPath screws are new to LV9.
If you use LV8.6 or earlier, I suggest looking in the .NET functions to implement XPath. Once you get the hang of it, it still beats the attempt to parse XML the old-fashioned way.
As for the editor, I generate very few XML files by hand, for the most part I bring other programs and analyse them in LV again, XPath adjusts the rough edges.
-
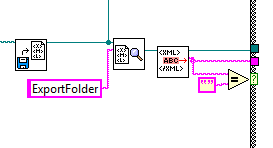
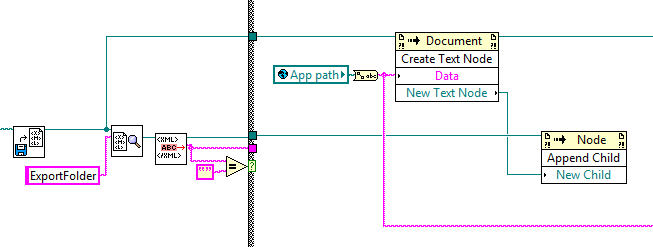
Hi all
I need to use XML to store program data. In the attached example, I save a path to an XML file, so that my program remember last used folder for export.
This simple XML file format is as follows:
-
C:\Users\AJ\Desktop At another time in my main program, an exception occurs when you try to update the XML file with the new path and I end up with the current XML:
-
I am trying to try to detect if the ExportFolder text node is empty, then add a default path:
The if statement works, but I can't find a way to update the XML file and analyze a next under ExportFolder element node.
Any help will be greatly appreciated.
Best regards
AJ
Found a solution for this. for those who may have a similar problem, it worked for me:
-
Read the nodes that have the same value as the subnodes - XML
It is more of a general JAVA / XML problem, but given that it is going into my BlackBerry app I thought I'd see if anyone knows.
Consider a simple XML document:
Whatever 1 Whatever 2 Whatever 3 Using the standard org.w3c.dom, I can get the nodes in X by the practice...
NodeList fullnodelist = doc.getElementsByTagName ("x");
But if I want to go to the next set of 'e', I try to use something like...
Element element = (Element) fullnodelist.item(0);NodeList nodes = pelement.getElementsByTagName("e");EXPECTED back '3' nodes (because there are 3 series of 'e'), but it returns '9' - because it gets all entries including the 'e' apperently.
It would be nice in the above case, because I could probably go through and find what I'm looking for. The problem I have is that when the XML file looks like the following:
whatever Something Else whatever Something Else When I ask 'e' value, it returns 4, instead of (what I want) 2.
I am simply not understand how DOM parsing works? Generally, in the past I used my own XML documents so I name never articles like this, but unfortunately this isn't my XML file and I don't have the choice to work like this.
What I thought I would do, it is write a loop knots "drills down" so that I can combine each node...
public static NodeList getNodeList(Element pelement, String find) { String[] nodesfind = Utilities.Split(find, "/"); NodeList nodeList = null; for (int i = 0 ; i <= nodesfind.length - 1; i++ ) { nodeList = pelement.getElementsByTagName( nodesfind[i] ); pelement = (Element)nodeList.item(i); } // value of the nod we are looking for return nodeList; }.. While if adopted you ' s/e' in the service, he would return the 2 nodes I'm looking (or elements, perhaps I'm using the wrong terminology?). on the contrary, it returns all the 'e' nodes in this node.
Anyway, if anyone is still with me and has a suggestion, it would be appreciated.
Well, there is no doubt that there is a learning curve robust for XML programming. You can take an hour or two and go through one of the tutorials that are circulating on the net. (Like that of w3schools.com.)
Basically, almost everything in XML is a node, the Document that returns the parser. The API for node tells you that you can test the node type you have by calling getNodeType, which returns one of the constants of type node (Node.ELEMENT_NODE, Node.TEXT_NODE, etc..) If necessary, you can then convert the variable to the corresponding interface (element, text, etc.).
Similarly, the API documentation say you for any node, calling getChildNodes (or for an element node or Document getElementsByTagName) will give you a NodeList (a little non-types of nodes in the XML API), while calling getFirstChild and getNextSibling to any node will give you another node (or null
 ).
).Once you learn the API, writing logic of course is not all that hard. For example, if the only 'e' interest tags are those directly under the element root of the document (as shown in your example) you can simply go to them directly:
Vector getTopENodes(Document doc) { Vector vec = new Vector(); NodeList nodes = doc.getDocumentElement().getChildNodes(); int n = nodes.getLength(); for (int i = 0; i < n; ++i) { Node node = nodes.item(i); if (node.getNodeType() == Node.ELEMENT_NODE && "e".equals(node.getNodeName())) { vec.addElement(node); } } return vec;}Note that this example does not assume that all children are nodes of element 'e '. the document could have comments, white space or something else that makes it into the DOM as comment, text or any other type of node.
On the other hand, if you want to capture every "e" tag which is directly under the ' tag, no matter the level, then you need to do something a little more complicated (it's on the top of my head - no guarantee):
static class NodeListImp implements NodeList { private Vector nodes = new Vector(); public int getLength() { return nodes.size(); } public Node item(int index) { return (Node) nodes.elementAt(index); } public add(Node node) { nodes.addElement(node); }} NodeList getTargetNodes(Document doc) { NodeListImp list = new NodeListImp(); getTargetnodes(list, doc.getDocumentElement(), false); return list;} void getTargetNodes(NodeListImp list, Node node, boolean parentIsS) { if (node.getNodeType() == Node.ELEMENT_NODE) { // node name is tag name for element nodes String name = node.getNodeName(); if (parentIsS && "e".equals(name)) { list.add(node); } parentIsS = "s".equals(name); for (Node child = node.getFirstChild(); child != null; child = child.getNextSibling()) { getTargetNodes(list, child, parentIsS); } }}I hope that it gets the idea across.
-
Hi, I have a simple xml file:
but I can't not only to what is in the first line, I mean: the values A, B, C, D and e. by this code:
_fileConnection = (FileConnection) Connector.open("file:///store/home/user/"+_fileName, Connector.READ); _documentBuilderFactory = DocumentBuilderFactory.newInstance(); _documentBuilder = _documentBuilderFactory.newDocumentBuilder(); _is = _fileConnection.openInputStream(); _document = _documentBuilder.parse(_is); _rootElement = _document.getDocumentElement(); _rootElement.normalize(); vector.addElement(_rootElement.getAttribute("A")); //and so onbut then, when I want to access to the:
I can't. I do something like this:
_nodeList = _rootElement.getChildNodes ();
for (_i int = 0; _i<_nodeList.getLength();>
System.out.println ("type" + _nodeList.item (_i) .getNodeValue ());
}
and what I get is:
type
value of type null
type
value of type null
and so on...
What's wrong? How can I get these items?
concerning
OK, I got it solved:
for( int _i = 0; _i < _nodeList.getLength(); _i++ ){ _node = _nodeList.item(_i); if( _node.getNodeName().equals("item") ){ System.out.println.("value "+_node.getAttributes().getNamedItem("max_ammount")); } }//end of forJava docs are very useful. but when you don't know how to start and are not even getting the general idea - you ask on the forum
best regards and thx for the help!
Maybe you are looking for
-
After the transition to Windows 7, there was a problem with Firefox. To work with the text to the award by the cursor of the large fragment of page it is necessary to change all the time down, 'against the judgment", but the page automatically does n
-
My old Tecra M1 running Windows XP gives very poor performance and I would be happy to empty it completely and reinstall the OS... but I can't find my recovery disc - I'm sure I created a! I tried a utility create this - without success. I also tried
-
HP envy: support from 110 to 220 volts
I bought a hp envy phoneix 810 pc in the United States and must contribute to Europe. Pls answer the following questions: 1. feeding sense auto tension? 2 pc usable on 110 volts or 220 volts? 3 supports 220V / 50 Hz Thank you D
-
OfficeJet 6100: What color is empty
I have recently upgraded to windows 10. Now the ink cartridges is empty but I con ' t find a way to say that one. I know that they are all empty. When I had windows 8 the out of ink message told me what color was empty. Now I don't see that. I though
-
When I install IE9, my printer Canon wireless stop working and more shows on my network
When I install IE9, my printer Canon wireless stop working and more shows on my network, accordingly. I am reluctant to reinstall IE9... of ideas? I use Windows Vista