Slow reads as follows: my data is meaningful to use with Berkeley DB?
HelloMy speed of insertion is wonderful, but I feel slow bed. It may be the way I use the sliders.
My key is a double. My data looks like this: (int X, int dontcare, int dontcare1, dontcare2 byte [8]).
I'm trying to do a 'select' statement that uses a slider to look through a RANGE of keys. In this range, the cursor looks like inside the data to find specific records which have a particular value of X (int). I ask if my data is logical to use with Berkeley DB because to find records in the beach is fast (VERY fast), but to iterate through all the records in the range, open the data and then analyze int X to see if X == someparticularvalue seems to be very slow. Because I go INTO the data to find particular values of X, this prevents me from using the getSearchBothRange() method.
PSEUDOCODE:
COUNTER = 0
Open a cursor
getSearchKeyRange to find the key value closest to you at the beginning of my range of keys
WHILE the value of getnextnodup is still in the range I'm looking for & & COUNTER < LIMIT_NUM_OF_RECORDS
get data
IF data.x is particularValue
memorize the current folder
counter ++
END IF
END WHILE
(because Berkeley DB forces the user to manage low level to research, I fear that I use one) not correctly b) do not effectively research the sliders. I could remove the "counter < limit_num_of_records" and put it in my IF statement and break when the condition is met, but I don't think it really makes a huge difference over time.
Help would be greatly appreciated.
Thank you
Julian
Julian,
I hope that I don't mislead you. This only works if the values of k1 are sequential and known in advance.
int k2 = ...
for (double k1 = start; k1 <= end; k1 += 1) {
// make a key {k1, k2}
// call Database.get or Cursor.getSearchKey
}
If this is not possible, you will need to return to an analysis of the values of k1 and select by k2. Sorry if I'm wrong you.
There is nothing magical about the queries I. The only mechanism underlying query is key or key range. You can add secondary keys for additional requests, but only if you have a unique primary key.
The same is true for all databases in general. If you were using a language such as SQL query, the query would likely be implemented internally by scanning of a range of key for k1 and selecting by k2.
-mark
Tags: Database
Similar Questions
-
I had these extensions installed since February 2015, when I bought my new computer. They always worked very well, but this morning I noticed that each say, «McAfee WebAdvisor/Skype Click-to-Call/Yahoo Toolbar could not be verified for use in Firefox.» Proceed with caution. All of these extensions have been download from their respective Web sites. Should I worry about this?
In the future, Firefox refuses to run unsigned extensions. However, the first step being taken in Firefox 40 is to warn you that you have a little so you can check the updates and/or inform the Publisher of this impending problem.
I'm sure that these three companies are aware of this change. What they need to do, is to submit their Add-ons for Mozilla for review and signature sometime before Firefox 41 is available and no doubt they will be.
If they are not, please complain to them!
-
How can I hide status ' Reading/waiting/transfer of data...' » ?
Firefox 34.0.5 Windows 7
I want to hide the status of "Reading/waiting/transfer of data..." "which shows at the bottom left of the browser window
I found a solution in this archived thread, https://support.mozilla.org/en-US/questions/942499and I applied it, but it doesn't seem to workThanks much el - cor
I used the code you posted on 969955 page
[ https://support.mozilla.org/en-US/questions/969955 ]Strangely enough I need to disable/enable Adblock Plus after, but it works
@namespace url("http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul"); /* only needed once */
.statuspanel-label {background:#FF9!important;color:black!important;font-family:"DejaVu Sans Mono"}
statuspanel {display:none!important}
statuspanel {max-width:90%!important}
statuspanel[type="overLink"] .statuspanel-label
statuspanel[type="status"] .statuspanel-label[value^="Looking"]
statuspanel[type="status"] .statuspanel-label[value^="Connect"]
statuspanel[type="status"] .statuspanel-label[value^="Waiting"]
statuspanel[type="status"] .statuspanel-label[value^="Transfer"]
-
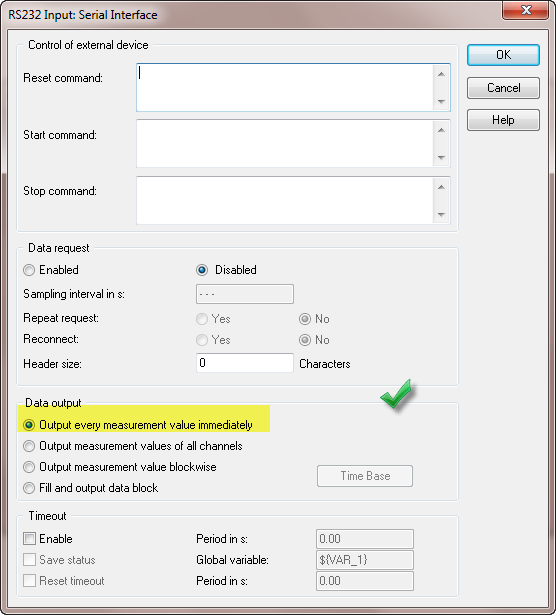
I can collect data from a hygrometer in a text file using the RS232 port with the following T75.2F:H17.0% format, these data are collected using a data logger software. I was wondering if I can collect this data for later analysis using Dasylab. Any help is appreciated.
The setting below causes the error. Change for the second selection, output values of all channels.
-
How to read the Serial Arduino data using labview VISA?
Hi =). Im a beginner work reading data series from an arduino but im facing... Lets do it step by step
I built a voltage divider circuit which gives from output
from 0 to 5V. The output of this circuit is sent to a 0 analog input pin
of a Committee of Arduino Duemilanove.(1) Firstly, I connected the cable to connect to my laptop USB the Arduino.
(2) I went to start-> control
Control Panel-> system-> hardware-> Device Manager. Check the Ports (COM
& LPT). In my laptop I can see USB Serial Port (COM4). Now I know only in
LabVIEW that I must read the data series COM 4.(3) to the side of the arduino, here's the code to read changes in voltage
entered to analog pin 0. The last line of 'delay' determines the sampling
Rate of how we want to taste the output of the voltage divider:int potPin = 0; Select the input pin for the output of the voltage divider
int val = 0; variable to store the value from the probevoid setup()
{
Serial.begin(9600) (9600); Opens the serial port, establishes the rate of 9600 bps data
}void loop() {}
Val = analogRead (potPin); read the value of the voltage divider
Serial.println (Val);
Delay (10);
}I slightly modified the basis series reading writing VI... I have
attached the block schema used with comments. Basically, I tried to read
data series, divide by 1023 and multiply by 5 to graphic voltage
variations of the voltage divider circuit. But Im not getting
the correct voltage output values. The value of the tension just keeps go
0 and coming again, as shown in the photo.Could you guys please guide me on what went wrong?
Thank you!
-you read the data, even if there is no data on the port. If 0 bytes are read => «»
-in the case of false, you resources VISA wired for the output of channel tunnel?
-There is no close VISA at the end of the VI resources
-you're not a loop this VI reading bytes
I added an addaption of your VI that you should give a try maybe

-
Use creation to read alternating channels and data
I have a csv file that I am trying to create a use. The help file says that if I specify a line in the form of data, then all subsequent lines must also be given.
The first line of my file is a header parameter names of test. I would like these are the names of channel for the actual data (parameter values) that follow on the next line.
Then I have a blank line, then a line with my main data channel names. The following lines are then the main actual data.
I'm sure I need a VBScript to do this, but am a little to get something that works based on examples that I found on the shelf.
I want to bring in the header data in the data portal so that I can put some of them together with graphs in my reports.
I have attached a sample data file. Also, I would generally ignore some of the columns of data (in this case, columns 3 to 10)
Thanks for your suggestions!
Hi Greg_Gran-
I have attached a personalized use which will be structured according to your posted example files and will ignore the third to the tenth data channels.
To use the use, simply unzip the cover record attached to your hard drive. Double-click the *.uri file that is included to register for use with your computer. Once you get the registration successful dialog box, you will be able to load your data files. Because CSV is a format of generic file with many variations, you may need to push the priority of this particular use for the *. "" "Extension CSV through DIAdem NAVIGATOR" settings "My DataFinder ' configure ' menu File Extensions so that this use is always used instead of the other *. DataPlugins CSV.
I didn't know if you wanted to ignore the third to the tenth of all columns of data or from time to time, so I built a small hook in the use that will allow you to adjust the 'package' of ignored channels (e.g.: 3-10, 1-5, 21-30). To change the range of the use know when loading:
- Select the NAVIGATOR tiara.
- "" "Select Settings ' Options ' Extensions ' DataPlugins.
- Right-click the use of Greg_Gran_CSV, and then select Edit the Script.
- In line 5 of the use, the variable "Ignore" is defined as a one-dimensional two values (3 and 10) table. These are the upper and lower values defining the range of the data channels to ignore. To load all the data, change the value (or both) - 1.
- Save the use.
As I had only a single file to test with, I can't guarantee that there will be problems with your other files - let me know if you encounter any problems or if you have any other questions.
-
read and medium n data from text file
I acquire [a waveform of reading] oscilloscope digital data that is stored in a column in a text file.
I need to read selectable amount of data at average/parcel them points.
So basically I want to have a text file with millions of data points, but I want to draw not to say that all 1000. data point. I tried a lot of things I found here on the forum, but as I'm new to LabView, none of them really worked.
Does anyone have a suggestion.
Thank you.
-
Unable to read the security descriptors data stream
Whenever I start my computer runs CHKDSK - it says checking file system on E: and then he said that it should be checked for consistency. It works until stage 3 when he says 'impossible to read the security descriptors data stream' how to fix this?
I tried chkdsk e:/r and it runs before step 3 when I get the "unable to read the security descriptors data stream" and it goes no further.
I also tried fsutil dirty query e:- but it says something about a parameter incorrect and not if the volume is dirty or clean.
Then I tried chkdsk e:/f/x - that always gives me the same mistake about it being an incorrect setting.
As far as I know there is absolutely nothing on E:, I didn't even know that there was an additional drive. Right now I have it turned off so that I can use my computer. It seems to work fine without it. I read an article that said that if I can't fix e: with chkdsk which I have to do a low-level format of the reader? What's my next step? And I can do without the XP disc?
The syntax
fsutil dirty query e:
is correct (except, of course, you try to use from the Recovery Console, where the fsutil command is not available). Are you logged on as a user with administrative rights when you use fsutil?
Similarly, the switches /f and/x are not available for chkdsk in the Recovery Console.
See Recovery Console controls.
Click on desktop then right-click on E: drive icon and select Properties. What is indicated for:
- File system
- Space used
- Free space
- Capacity
Now double click the icon for E: are shown files? If not, click Tools > Folder Options > view and select the radio button "Show hidden files and folders" and uncheck "Hide protected files (recommended) operating system. Now that you see all the files?
Everything you read 'low level of shaped' is nonsense. Any modern PC drive cannot be low level formatted by end users. You can read this, but there is really no necessary even to "zero fill" your drive E: http://seagate.custkb.com/seagate/crm/selfservice/search.jsp?DocId=203931 (I have not checked to see if the WD tools rescuer has similar characteristics to SeaTools for DOS).
If you are convinced that there is nothing of value on E (for example, installation of backup or restore), you can either format by right-clicking on the drive icon in my computer and selecting "format" or you can start disk management as described previously and use either in electronic format or delete the partition completely. If you delete the partition, space becomes "unallocated".
Because I guess C is your system drive (where Windows is), you may be able to use the diskpart tool to extend the partition F to use the unallocated space left if you decide to remove E well it's much easier (and safer) to do with disk management third-party tools such as Easeus Partition Manager free : http://www.partition-tool.com/personal.htm
-
Error message reads as follows:
A box keeps popping up on my screen and it reads as follows:
C\:ProgramData\Optus Mobile Broadband\OnlineUpDate\LiveUpd.exe
This program doesn't have a program associated with it for performing this action. Install a program or, if such is already installed, create an association in the default programs control panel.
I used Optus, but have now moved to Vodafone. Fairly new to the CPU, I don't know what to do. Thank you
Hi JIMOA,
Welcome to the Microsoft community. According to the description, you get C\:ProgramData\Optus Mobile Broadband\OnlineUpDate\LiveUpd.exe error message.
· Where do you get this error message?
I'll help you with this problem. I suggest you follow these methods.
Method 1: Follow these steps:
Step 1: Start the computer in safe mode with network and check if the problem persists.
Startup options (including safe mode)
Step 2: If the problem does not persist in safe mode with networking, perform a clean boot to see if there is a software conflict as the clean boot helps eliminate software conflicts.
Note: After completing the steps in the clean boot troubleshooting, follow the link How to reset the computer to start as usual after a clean boot troubleshooting to start the computer to a Normal startupmode.
Method 2: Follow the steps in the article.
Windows wireless and wired network connection problems
I hope this helps. Let us know if you need help with Windows related issues. We will be happy to help you.
-
Read file, reformat the data, write new file
Oracle 11g PL/SQL.
I have a need to read an existing file, reformat the drive and write to a new file format.
My solution has been to read the file using utl_file and store it in an array of procedure1. There is a column of data to hold 1000 bytes of data for each line of the file.
Then in procedure2, read the data through a cursor column, with a certain logic and fill in the fields of a record type object by using the function substr on the data column. The type of record object has about 80 columns, all TANK types. The OUT of procedure2 parameter would be the type of record object.
Then in procedure3, record object would be the parameter, and this recording would be used to write the new line of the file. The problem I see now is that I can't convert the object record type a TANK in order to write the file. So that would mean that I have to reference each of the 80 columns once again in procedure 3 and concatenate each for the parameter buffer utl_file.put_file.
I don't want to assign values for columns of 80 exit more than once because that makes the code very long and detailed, so I thought that I assign values to the time in the record object, then pass the record object to the write file procedure.
I'm looking for suggestions on a better design, or have I missed some very basic code design?
Thank you.
Thanks for all the great suggestions.
The original file is from a COBOL program. What I ended up doing was reference and readability, I have defined/filled all fields of provision of COBOL in my program and then concatenated fields during the construction of the output string. It's a bit verbose, since the 80s fields appear twice, but the code is clear and easy to understand for support purposes.
Thanks again for all the thoughtful suggestions.
-
Update Adobe CC reaches 5% installation point and error reads as follows: "try to connect to the server...". »
Thank you in advance for your response guys.
Hi yusney,
Please check the help below document:
https://helpx.Adobe.com/creative-cloud/KB/Error_Code_2_failed_update.html
Kind regards
Sheena
-
Defining the new path for the data files for restoring using the VALUE of NEWNAME FOR DATABASE
Version: 11.2.0.3 Linux
Today, I had to do a restore RMAN to a new server and I came across the post following RTO on the VALUE of NEWNAME FOR DATABASE
ALTER database open resetlogs upgraded; error to throw
So, I thought to use it to indicate the new location of the data files to restore.
That's what I did
===================
Restore the control file and catalog items to backup using the command of CATALOGUE START WITH. Then I started the restoration
Don't know how it worked for Levi without %f or %U. So, I added %f$ rman target / cmdfile=restore.txt Recovery Manager: Release 11.2.0.3.0 - Production on Thu Jul 26 04:40:41 2012 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: SPIKEY (DBID=2576163333, not open) RMAN> run 2> { 3> SET NEWNAME FOR DATABASE TO '/fnup/hwrc/oradata/spikey'; 4> restore database ; 5> } 6> 7> 8> executing command: SET NEWNAME RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of set command at 07/26/2012 04:40:43 RMAN-06970: NEWNAME '/fnup/hwrc/oradata/spikey' for database must include %f or %U format Recovery Manager complete.
As you can see, RMAN restore data files to the desired location. But the data file names ended up as$ vi restore.txt $ cat restore.txt run { SET NEWNAME FOR DATABASE TO '/fnup/hwrc/oradata/spikey/%f'; restore database ; } $ rman target / cmdfile=restore.txt Recovery Manager: Release 11.2.0.3.0 - Production on Thu Jul 26 04:45:45 2012 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: SPIKEY (DBID=2576163333, not open) RMAN> run 2> { 3> SET NEWNAME FOR DATABASE TO '/fnup/hwrc/oradata/spikey/%f'; 4> restore database ; 5> } 6> 7> 8> executing command: SET NEWNAME Starting restore at 26-JUL-12 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=19 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00001 to /fnup/hwrc/oradata/spikey/1 channel ORA_DISK_1: restoring datafile 00002 to /fnup/hwrc/oradata/spikey/2 channel ORA_DISK_1: restoring datafile 00003 to /fnup/hwrc/oradata/spikey/3 channel ORA_DISK_1: restoring datafile 00004 to /fnup/hwrc/oradata/spikey/4 channel ORA_DISK_1: restoring datafile 00005 to /fnup/hwrc/oradata/spikey/5 channel ORA_DISK_1: restoring datafile 00006 to /fnup/hwrc/oradata/spikey/6 channel ORA_DISK_1: restoring datafile 00007 to /fnup/hwrc/oradata/spikey/7 channel ORA_DISK_1: restoring datafile 00008 to /fnup/hwrc/oradata/spikey/8 channel ORA_DISK_1: restoring datafile 00009 to /fnup/hwrc/oradata/spikey/9 channel ORA_DISK_1: reading from backup piece /u07/bkpfolder/SPIKEY_full_01nh0028_1_1_20120725.rmbk channel ORA_DISK_1: errors found reading piece handle=/u07/bkpfolder/SPIKEY_full_01nh0028_1_1_20120725.rmbk channel ORA_DISK_1: failover to piece handle=/u07/dump/bkpfolder/SPIKEY_full_01nh0028_1_1_20120725.rmbk tag=SPIKEY_FULL channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:01:56 Finished restore at 26-JUL-12 Recovery Manager complete.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! -----------| Holy Cow |-----------------------------1 2 3 . . . 9
So I had to rename each file as below
I would have been better in execution of the order for each data below file$ mv 1 /fnup/hwrc/oradata/spikey/system01.dbf $ mv 2 /fnup/hwrc/oradata/spikey/sysaux01.dbf $ mv 3 /fnup/hwrc/oradata/spikey/undotbs01.dbf
Now, I think, there is no advantage in using NEWNAME SET of DATABASE to. Only the disadvantages. I did anything wrong above?SET NEWNAME FOR DATAFILEMartin;
On the issue of the VALUE of NEWNAME FOR DATABASE, you must specify at least one of the first three of the following substitution variables to avoid collisions of names: %b f % U. see semantic entry for TO 'filename' for a description of the possible substitution variables.
You use %f
%b Specifies the filename without the fully qualified directory path. For example, the datafile name /oradata/prod/financial.dbf is transformed to financial.dbf. This variable enables you to preserve the names of the datafiles while you move them to different directory. During backup, it can be used for the creation of image copies. The variable cannot be used for OMF datafiles or backup sets. %f Specifies the absolute file number of the datafile for which the new name is generated. For example, if datafile 2 is duplicated, then %f generates the value 2. %U Specifies a system-generated unique filename. The name is in the following format: data-D-%d_id-%I_TS-%N_FNO-%f. The %d variable specifies the database name. For example, a possible name might be data-D-prod_id-22398754_TS-users_FNO-7.Source - E10643-01
Backup and recovery reference
http://docs.Oracle.com/CD/E14072_01/backup.112/e10643/rcmsynta2014.htm
I see CKPT and I agree on that!
Best regards
mseberg
-
Cipher.exe to overwrite the data deleted in Windows works with Windows Vista?
Cipher.exe to overwrite the data deleted in Windows works with Windows Vista? He worked under Windows 2000, but not sure about Vista! Otherwise Vista contains a command to clean free space HDD?
Hello
you need 3 of third party programs to clean free hard drive space
For your question:
always check the compatibility of vista programs on the link below
http://www.Microsoft.com/Windows/compatibility/Windows-Vista/default.aspx
If a program is compatible with vista you can try right click on the setup.exe, and then selecting run as administrator
It is not compatible with vista, you can try running it in a previous operating system mode
This does not work for all programs
read the information below
http://www.howtogeek.com/HOWTO/Windows-Vista/using-Windows-Vista-compatibility-mode/
-
SQL Loader loading data into two Tables using a single CSV file
Dear all,
I have a requirement where in I need to load the data into 2 tables using a simple csv file.
So I wrote the following control file. But it loads only the first table and also there nothing in the debug log file.
Please suggest how to achieve this.
Examples of data
Source_system_code,Record_type,Source_System_Vendor_number,$vendor_name,Vendor_site_code,Address_line1,Address_line2,Address_line3
Victor, New, Ven001, Vinay, Vin001, abc, def, xyz
Control file script
================
OPTIONS (errors = 0, skip = 1)
load data
replace
in the table1 table:
fields ended by ',' optionally surrounded "" "
(
Char Source_system_code (1) POSITION "ltrim (rtrim (:Source_system_code)),"
Record_type tank "ltrim (rtrim (:Record_type)),"
Source_System_Vendor_number tank "ltrim (rtrim (:Source_System_Vendor_number)),"
$vendor_name tank "ltrim (rtrim (:Vendor_name)),"
)
in the Table2 table
1 = 1
fields ended by ',' optionally surrounded "" "
(
$vendor_name tank "ltrim (rtrim (:Vendor_name)),"
Vendor_site_code tank "ltrim (rtrim (:Vendor_site_code)),"
Address_line1 tank "ltrim (rtrim (:Address_line1)),"
Address_line2 tank "ltrim (rtrim (:Address_line2)),"
Address_line3 tank "ltrim (rtrim (:Address_line3)).
)the problem here is loading into a table, only the first. (Table 1)
Please guide me.
Thank you
Kumar
When you do not provide a starting position for the first field in table2, it starts with the following after a last referenced in table1 field, then it starts with vendor_site_code, instead of $vendor_name. So what you need to do instead, is specify position (1) to the first field in table2 and use the fields to fill. In addition, he dislikes when 1 = 1, and he didn't need anyway. See the example including the corrected below control file.
Scott@orcl12c > test.dat TYPE of HOST
Source_system_code, Record_type, Source_System_Vendor_number, $vendor_name, Vendor_site_code, Address_line1, Address_line2, Address_line3
Victor, New, Ven001, Vinay, Vin001, abc, def, xyz
Scott@orcl12c > test.ctl TYPE of HOST
OPTIONS (errors = 0, skip = 1)
load data
replace
in the table1 table:
fields ended by ',' optionally surrounded "" "
(
Char Source_system_code (1) POSITION "ltrim (rtrim (:Source_system_code)),"
Record_type tank "ltrim (rtrim (:Record_type)),"
Source_System_Vendor_number tank "ltrim (rtrim (:Source_System_Vendor_number)),"
$vendor_name tank "ltrim (rtrim (:Vendor_name)).
)
in the Table2 table
fields ended by ',' optionally surrounded "" "
(
source_system_code FILL (1) POSITION.
record_type FILLING,
source_system_vendor_number FILLING,
$vendor_name tank "ltrim (rtrim (:Vendor_name)),"
Vendor_site_code tank "ltrim (rtrim (:Vendor_site_code)),"
Address_line1 tank "ltrim (rtrim (:Address_line1)),"
Address_line2 tank "ltrim (rtrim (:Address_line2)),"
Address_line3 tank "ltrim (rtrim (:Address_line3)).
)
Scott@orcl12c > CREATE TABLE table1:
2 (Source_system_code VARCHAR2 (13),)
3 Record_type VARCHAR2 (11),
4 Source_System_Vendor_number VARCHAR2 (27),
5 $vendor_name VARCHAR2 (11))
6.
Table created.
Scott@orcl12c > CREATE TABLE table2
2 ($vendor_name VARCHAR2 (11),)
3 Vendor_site_code VARCHAR2 (16).
4 Address_line1 VARCHAR2 (13),
5 Address_line2 VARCHAR2 (13),
Address_line3 6 VARCHAR2 (13))
7.
Table created.
Scott@orcl12c > HOST SQLLDR scott/tiger CONTROL = test.ctl DATA = test.dat LOG = test.log
SQL * Loader: release 12.1.0.1.0 - Production on Thu Mar 26 01:43:30 2015
Copyright (c) 1982, 2013, Oracle and/or its affiliates. All rights reserved.
Path used: classics
Commit the point reached - the number of logical records 1
TABLE1 table:
1 row loaded successfully.
Table TABLE2:
1 row loaded successfully.
Check the log file:
test.log
For more information on the charge.
Scott@orcl12c > SELECT * FROM table1
2.
RECORD_TYPE SOURCE_SYSTEM_VENDOR_NUMBER $VENDOR_NAME SOURCE_SYSTEM
------------- ----------- --------------------------- -----------
Victor Ven001 new Vinay
1 selected line.
Scott@orcl12c > SELECT * FROM table2
2.
$VENDOR_NAME VENDOR_SITE_CODE ADDRESS_LINE1 ADDRESS_LINE2 ADDRESS_LINE3
----------- ---------------- ------------- ------------- -------------
Vinay Vin001 abc def xyz
1 selected line.
Scott@orcl12c >
-
Since the update to the most recent v11.0.10 of Adobe Reader, getting a Safe_mode Adobe Reader: Adobe Reader cannot open protected mode due make an incompatibility with your system configuration. Want to open Adobe Reader with protected Mode off?
The solution I was looking for was to launch Adobe Reader protected mode.
I couldn't identify issues preventing start Protected Mode. What ended up working, was complete, followed by a reinstall uninstall. Now we can load drive in Protected Mode.
Maybe you are looking for
-
How the message to your Favorites
How to set my watch to be able to text my favorites more quickly
-
iPhone Apps in iTunes greyed-out, no synchronization
Today, I downloaded a new iPhone App in iTunes [12.4.3.1] on a Macbook Pro [10.11.6] who has several granted previously iPhone Apps, all updated and everything already works on my iPhone 5 [9.3.5] (Firmware 10.01.00). Recently, via USB, attempts to s
-
What year the first USB3 was introduced for the MBP?
-
Satellite A350: How to change the size of the partitions on the HARD drive?
Hello I have a Satalite A350 with a 250 G, but for some reason hard drive any, that it has been partitioned with 114 for the C drive and a huge 114 for drive E g which is simply the recovery disc. I'm now at 20 g on the C, but still have a Virgin 100
-
Name of the table (Bug or feature)?
Hello I have a table named containers. I would like to increase the abscissa, if the name does not appear in the table. To do this, I use PropertyObject members. This works well if you use strings without 2 or more "------" (backslash). So what is th