SQL count (*) with Group of
HelloI need help to fix this SQL.
Fields in the table are like that.
ID(PK)
user_id
user_name
login_time(timestamp)select distinct user_id , user_name, login_date from USER_LOGIN
where login_date in (select max(login_date) from USER_LOGIN group by user_id) select distinct user_id , user_name, login_date, count(*) from USER_LOGIN
where login_date in (select max(login_date) from USER_LOGIN group by user_id) group by user_id can you help me to get the number of records by user_id group.
Thank you
SK
Hello
Looks like you want something like this:
SELECT user_id
, user_name
, MAX (login_time) AS last_login_time
, COUNT (*) AS total_rows
FROM user_login
GROUP BY user_id
, user_name
;
This assumes that user_login is off standard (like him are often seen), such that every row of the same user_id will also have the same user_name.
I hope that this answers your question.
If not, post a small example of data (CREATE TABLE and INSERT statements) and the results desired from these data.
Tags: Database
Similar Questions
-
Using the function count with grouped records
Hi all
This seems like it should be very easy, but I still have to find a simple way to do it.
Suppose I want to count the possibilities which are grouped by Sales Rep at run time I filter this list with a parameter for sales stage and created date.
I've simplified this greatly, but here's what my setup looks like now:
Sales representative*-Count* _
<? for-each-group: opportunity [SalesStage = param1 and creation > param2]; /SalesRep? >
<? SalesRep? >-<? count (current - group (available))? >
<? end for each group -? >
_ Total
The only solution I have to get my grand total so far is to create a variable and permanently keep a total that I will then display in the Total column. It all works, it seems that there should be an easier way, want to do a simple count (Id) for a total general. But given that the Total amount will appear after the end of each group-, I lose the filter that has been applied to the group so that the count is not valid.
Ideas of the experts?
Thank you!To get the total general
useparam2]/Id)?>Since you have not mentioned the complete xml code, I assumed, as the root.
If this isn't the case, put the full path from the root.If you give some xml examples and explain the output you want, we can fix it immediately.
go through these too... something can be drawn from here.
http://winrichman.blogspot.com/search/label/summation%20In%20BIP
http://winrichman.blogspot.com/search/label/BIP%20Vertical%20sum -
Max, Min, and Count with Group By
Hello
I want the max, min and the meter of a table that is grouped by a column
I need a combination of these two selects:
select max(COUNTRY_S) MAXVALUE, min(COUNTRY_S) MINVALUE from tab_Country
select count(*) from (select COUNTRY_TXT from tab_Country group by COUNTRY_TXT) ;
The result should be a line with the maximum and minimum of the table value and the County grouped by table, not the max and min of each group! -J' hope you understand my question?
Is this possible in a SQL-select?
Thank you very much
Best regards
Heidi
Hi, Heidi,.
HeidiWeber wrote:
Hello
I want the max, min and the meter of a table that is grouped by a column
I need a combination of these two selects:
- Select
- MAXVALUE, Max (COUNTRY_S),
- min (COUNTRY_S) MINVALUE
- Of
- tab_Country
- Select
- Count (*)
- Of
- (select the COUNTRY_TXT of the COUNTRY_TXT tab_Country group);
The result should be a line with the maximum and minimum of the table value and the County grouped by table, not the max and min of each group! -J' hope you understand my question?
Is this possible in a SQL-select?
Thank you very much
Best regards
Heidi
It is not clear what you want. Maybe
SELECT MAX (country_s) AS max_country_s
MIN (country_s) AS min_country_s
COUNT (DISTINCT country_txt) AS count_country_txt
OF tab_country
;
I hope that answers your question.
If not, post a small example of data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and the results desired from these data.
Explain, using specific examples, how you get these results from these data.
Always say what version of Oracle you are using (for example, 11.2.0.2.0).See the FAQ forum: https://forums.oracle.com/message/9362002
-
Count (*) with Group of and a join
I have the tables below:
Tables:
-----EMPLOYEE EMP_ID LNAME FNAME 1000 SLITT JOHN 1001 SLITHER STEVE 1002 JACOB MARLYN 1003 STUFFEY NOSE 1004 SLIPPY MOUTH
-----ACCESS_TYPE ACCESS_TYPE_ID ACCESS_DESCRIPTION 1 EMPLOYEE 2 EMPLOYEE_ADMIN 3 CONTRACTOR
-----EMPLOYEE_ACCESS ACCESS_ID ACCESS_TYPE_ID EMP_ID ACCESS_EFF_DATE 1 1 1000 01-JAN-13 2 1 1001 10-FEB-13 3 1 1002 18-FEB-13 4 2 1003 10-OCT-12 5 3 1004 10-MAR-08
I'm trying to appear on the behalf of the Group of employees by their type and whose name does not begin with SL
I wrote the following query and I get a missing Expression 00936. What I am doing wrong? Thank you
SELECT EA. COUNT (*), ACCESS_TYPE_ID
OF EMPLOYEE_ACCESS EA, USED E
WHERE ACCESS_EFF_DATE > = 31 December 12 ' AND E.LNAME NOT LIKE '% SL.
ACCESS_TYPE_ID GROUP;
Published by: parsar on March 25, 2013 15:54>
FAM COUNT (*)
>
You have a column named "COUNT" in your table? NOT! You probably intend to use the COUNT function: ditch the prefix aliases, functions use a prefix.
>
WHERE ACCESS_EFF_DATE > = 31 DECEMBER 12 '
>
Don't use strings to DATE values. Use the dates and the TO_DATE function if you need to convert a string to a date literal.This Cartesian join between the tables is unlikely to be what you want to do.
-
bad value COUNT with GROUP OF ROLLUP
Hi all
I'm using GROUP BY ROLLUP for the result in the below format. However the sum obtained by the query in my totals at the end lines is not the correct value. It should be 124. I am not able to understand what could be the reason for this. Help, please.
Result:Query: SELECT decode(grouping(ACCTNUM),'1','Totals', ACCTNUM) "Client",COUNT(DISTINCT Rpt.UserId) "Total Users Logged In" FROM VW_XXX_SUMMARYREPORTDATA Rpt WHERE Rpt.LoginDate BETWEEN TO_DATE('01-AUG-2011') and TO_DATE('31-AUG-2011') GROUP BY ROLLUP (Rpt.ACCTNUM) HAVING (Rpt.ACCTNUM IS NULL OR Rpt.ACCTNUM = 'Totals') OR Rpt.ACCTNUM IS NOT NULL ;1XXX013000 1 1XXX018000 1 1XXX015800 1 9XXX000600 1 9XXX000700 23 9XXX004400 1 9XXX004900 1 9XXX012700 1 9XXX016400 1 9XXX019800 1 9XXX020000 2 9XXX029300 5 9XXX000100 2 9XXX000100 1 9XXX003200 1 9XXX000100 1 9XXX000200 3 9XXX001000 11 9XXX001900 50 9XXX002600 1 9XXX000800 3 9XXX001000 1 9XXX000100 11 Totals 122Consider this:
SQL> select 2 e.deptno, e.job, e.ename 3 from scott.emp e 4 order by 5 e.deptno, e.job, e.ename 6 ; DEPTNO JOB ENAME ---------- --------- ---------- 10 CLERK MILLER 10 MANAGER CLARK 10 PRESIDENT KING 20 ANALYST FORD 20 ANALYST SCOTT 20 CLERK ADAMS 20 CLERK SMITH 20 MANAGER JONES 30 CLERK JAMES 30 MANAGER BLAKE 30 SALESMAN ALLEN 30 SALESMAN MARTIN 30 SALESMAN TURNER 30 SALESMAN WARD 14 rows selected. SQL> select 2 decode(grouping(e.deptno),1,'Total',e.deptno) dept, 3 count(distinct e.job) cnt 4 from scott.emp e 5 group by rollup( 6 e.deptno 7 ) 8 order by 9 grouping(e.deptno), 10 e.deptno 11 ; DEPT CNT ---------------------------------------- ---------- 10 3 20 3 30 3 Total 5There are three different names in each of the departments. But in total, there are only 5 different.
You can get the total that you want using analytical functions:
SQL> select 2 e.deptno, 3 count(distinct e.job) cnt, 4 sum(count(distinct e.job)) over () totalcnt 5 from scott.emp e 6 group by 7 e.deptno 8 order by 9 e.deptno 10 ; DEPTNO CNT TOTALCNT ---------- ---------- ---------- 10 3 9 20 3 9 30 3 9But this gives you the total in a column, not a line.
If you need as a line, you might be able to do something like this:SQL> select 2 decode(grouping(s.deptno),1,'Total',s.deptno) dept, 3 sum(s.cnt) cnt 4 from ( 5 select 6 e.deptno, 7 count(distinct e.job) cnt 8 from scott.emp e 9 group by 10 e.deptno 11 ) s 12 group by rollup( 13 s.deptno 14 ) 15 order by 16 grouping(s.deptno), 17 s.deptno 18 ; DEPT CNT ---------------------------------------- ---------- 10 3 20 3 30 3 Total 9In the Interior, you select count (distinct but without rollup. Then an external selection where you do a sum for rollup your meter internal.
Maybe an idea for you - maybe your solution two columns would work OK ;-)
-
How Oracle performs with 'COUNT' when to go with "GROUP BY"?
Hello
I am aware that count return 0 there is still no data found a 'WHERE' clause
However, when he goes with "GROUP BY", he goes to the "EXCEPTION block".
declare
a number: = 0;
Start
Select COUNT (1) in the doubles where 1 = 2
Group 1;
dbms_output.put_line ('a =' | a);
exception
While OTHERS then
dbms_output.put_line ('Exception =' |) SQLERRM);
end;
/
output:
Exception = ORA-01403: no data found
Why is Oracle jumps in the 'EXCEPTION' block when "GROUP BY" is added?
Why may not behave in the same way as it did without "GROUP BY"?
Please help me understand.
Hello
11fdb98c-D100-4baa-8eee-c00c9f7303bc wrote:
Hello
I am aware that count return 0 there is still no data found a 'WHERE' clause
...
This is not true. A query using COUNTY won't necessarily produce anything. The query you posted is an example:
Select COUNT (1) in DOUBLE where 1 = 2
Group 1;
does not 0; It produces nothing at all.
Why is Oracle jumps in the 'EXCEPTION' block when "GROUP BY" is added?
SELECT... INTO will trigger an error ("no data found" or "too many rows"), except if the query produces exactly 1 row.
Why may not behave in the same way as it did without "GROUP BY"?
GROUP BY means that the query will produce 1 row of output for each group (after the WHERE clause has been applied).
A query using an aggregate (such as COUNT) without a GROUP BY clause function will always produce exactly 1 row. (If you have a HAVING clause, then it can remove this row from the result set.)
What you trying to do?
Why do you use a GROUP BY clause in this case? If you want a query which behaves as if it doesn't have a GROUP BY clause, then do not add a GROUP BY clause.
-
Need help with query SQL Inline views + Group
Hello gurus,
I would really appreciate your time and effort on this application. I have the following data set.
Reference_No---Check_Number---Check_Date---description---Invoice_Number---Invoice_Type---Paid_Amount---Vendor_Number
1234567 11223 - 05/07/2008 -paid for cleaning- 44345563-I-* 20.00 *---19
1234567 11223 - 05/07/2008 - 44345563 -a--10,00---19 ofbad quality adjustment
7654321 11223 - 05/07/2008 - setting the last billing cycle - 23543556 - A - 50.00 - 19
4653456 11223 - 05/07/2008 - paid for cleaning - 35654765 - I - 30, 00-19
Please ignore '-' added for clarity
I'm writing a paid_amount based on Reference_No, Check_Number, Payment_Date, Invoice_Number, aggregate query Invoice_Type, Vendor_Number and display description with Invoice_type 'I' when there are multiple records with the same Reference_No, Check_Number, Payment_Date, Invoice_Type, Invoice_Number, Vendor_Number. When there are no more records I want to display the respective Description.
The query should return the following data set
Reference_No---Check_Number---Check_Date---description---Invoice_Number---Invoice_Type---Paid_Amount---Vendor_Number
1234567 11223 - 05/07/2008 -paid for cleaning- 44345563-I-* 10.00 *---19
7654321 11223 - 05/07/2008 - setting the last billing cycle - 23543556 - A - 50.00 - 19
4653456 11223 - 05/07/2008 - paid for cleaning - 35654765 - I - 30, 00-19
Here's my query. I'm a little lost.
Select b., A.sequence_id, A.check_date, A.check_number, A.invoice_number, A.amount, A.vendor_number
de)
Select sequence_id, check_number, check_date, invoice_number, sum (paid_amount) sum, vendor_number
of the INVOICE
Sequence_id group check_date, check_number, invoice_number, vendor_number
) A, B OF INVOICE
where A.sequence_id = B.sequence_id
Thank you
NickIt seems that this is a duplicate thread - correct me if I am wrong in this case->
Need help with query SQL Inline views + Group
Kind regards.
LOULOU.
-
Several SQL statements with zero executions in the region of SQL
Hello
one of my databases has a large number of statements in the SQL box with zero executions. Some of them analyzed several times without a single run. Why the database stores these statements and how to avoid or reduce them?
My problem is that the only time or zero time sql statements take the largest part of the area of sql:
-sql statement and only once and without executing sql statements
Select
Count (1) num_sql_total,.
sum (decode (executions, 1, 1, 0)) num_one_use_sql,.
sum (decode (executions, 0, 1, 0)) num_no_use_sql,.
Sum (RUNTIME_MEM) / 1024/1024 mb_used,.
sum (decode (executions, sharable_mem, 1, 0)) / 1024/1024 mb_for_one_use_sql,.
sum (decode (executions, 0, sharable_mem, 0)) / 1024/1024 mb_for_no_use_sql
Of
GV$ sqlarea
where
RUNTIME_MEM > 0;
NUM_SQL_TOTAL NUM_ONE_USE_SQL NUM_NO_USE_SQL MB_USED MB_FOR_ONE_USE_SQL MB_FOR_NO_USE_SQL 23318
8739
8027
1420,95619106293
381,41183757782
530,999855041504
Concerning
Thomas
This is not unusual. Another app could analyze for example hard the most often used SQLs in upstairs app - making benefit of further processing (in theory) of sweet analysis when you use these SQLs.
In fact, I remember reading something to this effect as a performance for some factor or another Oracle document or note?
So unless you have serious questions of shared pool, why bother with these sliders? What would be the problem?
-
PL/SQL: Cursor with list filling can do IF EXISTS on Table
Here's my problem. The DB I work with is a database of events (network events). I have a task to take a list of nodes of 2600 and see whether these nodes exist in a set of events that would be with a certain WHERE clause. On my first pass, I did WHERE AND NŒUD clause in (list of 2600 nodes). Well you can put only 1,000 items in a list so I've divided into 3 reports and served while a UNION all between them. This used 15% of the resources of the db and ran for hours and the Group dba like me to find a better way. They would prefer that I use PL/SQL.
I am new to pl/sql (but not programming or SQL). So the first thing I've done is just figure out how to get my list in a Varray, which I then went to a table because I couldn't find examples, after hours and hours of searching the Web,.
referencing a Varray with SQL syntax.
START CODE sample 1 *.
DECLARE
DECLARE
TYPE NodeList IS TABLE OF VARCHAR2 (255);
Node NodeList: = NodeList ('node1', node2', [.. .list of 2597 nodes..], 'node2600')
BEGIN
dbms_output. Enable (1000000);
FOR i IN Nodes.FIRST... Nodes.LAST
LOOP
DBMS_OUTPUT. Put_line (' relevant points: ' |) Nodes (i));
END LOOP;
END
END CODE Sample 1 *.
The pseudo-code I'm envisioning goes something like this:
IF one of these nodes (nodes of 2600 list),
There are in the nodes for this WHERE clause (which is taken from the event db table).
then print the records (of the events in the event db table) that contains the nodes (ie the list nodes).
I think I found an example with 2 sliders, but I can't find this example once again. And anyway, I can't figure out how to get my list in a cursor. I have many examples of how to complete a cursor on a select statement against a database.
I tried this but it did not work:
START the CODE sample 2 *.
DECLARE
DECLARE
TYPE NodeList IS TABLE OF VARCHAR2 (255);
Node NodeList: = NodeList ('node1', node2', [.. .list of 2597 nodes..], 'node2600')
CURSOR MOM_OVO_NODES IS
SELECT the node
OF NodeList
ORDER BY node;
BEGIN
dbms_output. Enable (1000000);
FOR nodelist_rec IN MOM_OVO_NODES
LOOP
dbms_output.put_line (' relevant nodes: ' | nodelist_rec.) Node);
END LOOP;
END
END CODE sample 2 *.
Is there a way to get this list in a slider? Or I think about this correctly?
BradBrad Bueche wrote:
Here's my problem. The DB I work with is a database of events (network events). I have a task to take a list of nodes of 2600 and see whether these nodes exist in a set of events that would be with a certain WHERE clause. On my first pass, I did WHERE AND NŒUD clause in (list of 2600 nodes). Well you can put only 1,000 items in a list so I've divided into 3 reports and served while a UNION all between them. This used 15% of the resources of the db and ran for hours and the Group dba like me to find a better way. They would prefer that I use PL/SQL.PL/SQL is probably going to be a slower solution, then SQL. It's almost always.
Your best bet would be to maintain a table of nodes. You can then use a single SQL query with an IN WHERE clause as:
WHERE node in (SELECT node FROM node_table)Or you can use a join (the method preferred honestly, gives Oracle more optimization options).
If you don't want to maintain a table of node, you can always create a global temporary Table or the external Table that could be loaded prior to running your report.
If you have tried these methods, and it is still too low or high intensity of resources, then we should look at the SQL and chorus only. See the PL/SQL FAQ's for more information on setting the SQL statements.
-
Report of update SQL query with line selector. Update process.
I have a report of update SQL query with the selectors in line.
How to identify line selector in a process update on the page.
I want to update some columns with a value of an area of selection on the page.
With the help of the base:
UPDATE table_name
SET Column1 = value
WHERE some_column = some_value
I would need to do:
UPDATE table_name
SET column1 =: P1_select
WHERE [line selector] =?
Now sure how to identify [line selector] and/or validate it is checked.
Thank you
BobIdentify the name of the checkbox of the source of the page element, it should be of the fxx format (f01, f02... f50).
Suppose that we f01.for i in 1 .. apex_application.g_f01.count loop UPDATE CONTRACTS SET SIP_LOAD_FLAG = :P16_STATUS where= apex_application.g_f01(i); --i'th checked record' primary key end loop; -
Count (*) with the nested query
Hello
I have a question about the count (*) with the nested query.
I have a table T1 with these columns:
Number of C1
Number of C2
Number of C3
Number of C4
Number of C5
(The type of each column is not relevant for example).
This query:
Select C1, C2, C3, C4
from T1
Group C1, C2
It is not correct becausa C3 and C4 are the columns specified in the GROUP BY expression.
If you run this query:
Select count (*)
(select C1, C2, C3, C4
from T1
Group C1, C2)
I don't have an error message (properly, the result is the number of records).
Why?
Thank you.
Best regards
Lucabecause the optimizer rewrites as
SELECT COUNT(*) FROM T1 GROUP BY C1, C2G.
Edited by: g. March 1, 2011 09:19
-
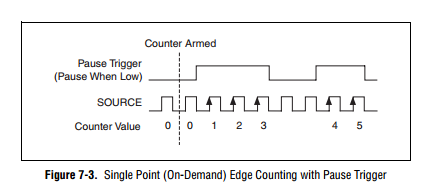
How to generate a single Point (On-Demand) edge counting with relaxing break
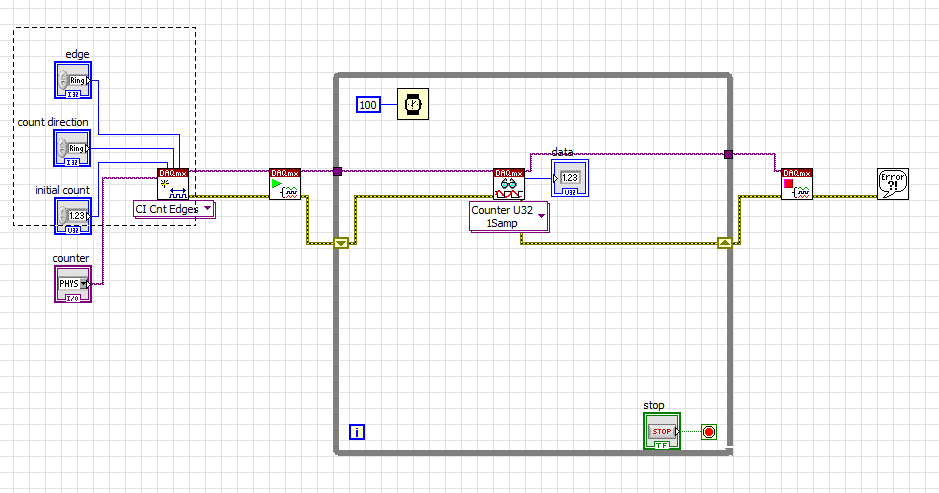
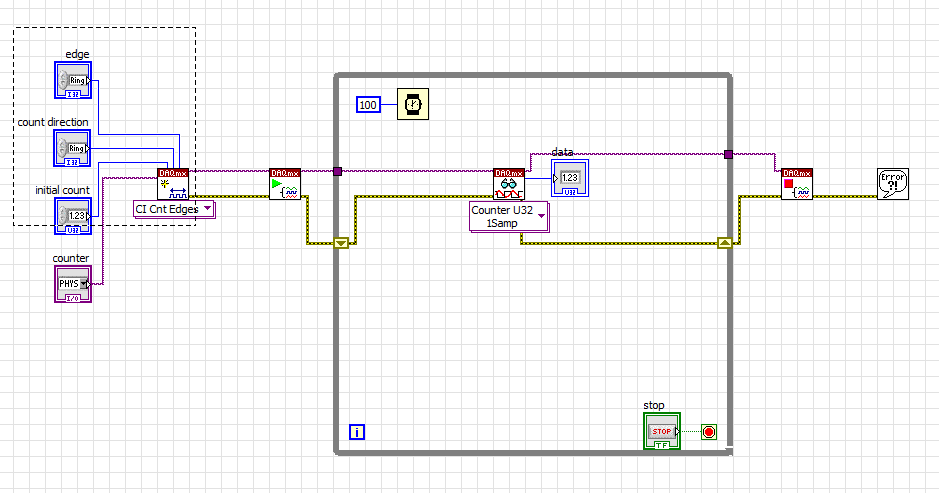
I have problem when creating a Labview program to generate a single Point (On-Demand) edge counting with relaxing break illustrated in FIGURE 1 below. I only know how to build counter edge without relaxing break and my program is illustrated in FIG. 2 and gaskets also. Should what changes I make on my program? The DAQ card that I use is 6259 PCI/USB.
FIG1. Single edge counting with break Point (on request)
Fig.2 my program to generate the edge without relaxing break
It is resolved
-
Using a counter with FiniteSamps and one with ContSamps
I am using 2 counters on the NI USB-6229 (or USB-6259), case where a counter is implemented for FiniteSamps and another for ContSamps. I have the following MeasurementStudio code:
ErrChk DAQmxCreateCOPulseChanTicks(hCnt0, "Dev1/ctr0", "", "20MHzTimebase", DAQmx_Val_Low, 0, 400, 400);
ErrChk DAQmxCfgImplicitTiming(hCnt0, DAQmx_Val_FiniteSamps, 100);ErrChk DAQmxStartTask (hCnt0);
ErrChk DAQmxCreateCOPulseChanTicks(hCnt1, "Dev1/ctr1", "", "20MHzTimebase", DAQmx_Val_Low, 0, 400, 400);
ErrChk DAQmxCfgImplicitTiming(hCnt1, DAQmx_Val_ContSamps, 2);
ErrChk DAQmxStartTask (hCnt1);
When I run it, I get an error-50103 "the resource specified is reserved". If I change the FiniteSamps to ContSamps on the first counter, everything works fine.
If I use only one counter with FiniteSamps, everything works very well.
Is this a bug in DAQmx or the use of double counter on M Series devices is limited to ContSamps?
VIC
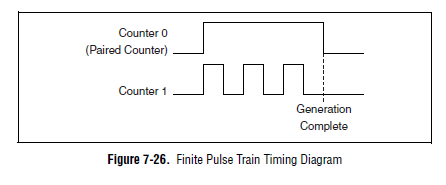
Hey Vic,
It is actually planned on a device of the M series. Here's a time diagram of the M Series user manual which might make this a little clearer:
The device uses actually one counter for the other door so the result is a generation of finite pulse. If you can provide the door from another source, you can configure a generation of continuous pulses on two counters and their door (DAQmx calls it a "relaxing break") of this external signal.
You can also look at the use of the digital I/o correlated to generate impulses over multiple (up to 32 lines on your 6229 and 6259). You could use one of the counters to generate a time base for digital lines and build the waveform as a result.
One thing to note is that our new X series cards can generate a generation of impulses finished on a "single" counter (it was actually a paired internal counter that allows this). There are four accessible counters by the user on the X series devices, which means you could generate four pulse trains finished.
Best regards
John
-
How to build a single Point (On-Demand) edge counting with relaxing break
Hi, I am building a clock as shown below. It is also called 'Single Point (On-Demand) Edge Counting with relaxing break'.
"
I have problem to find the code example. So far, I can only build a counter edge without a controller trigger like below. Could someone help me?
-
Internet Explorer 8 XP configuration with group policy
I'm trying to update the zone information of IE8 via the group policy on the xp computers. I don't get any errors, but the parameters are not get applied to the computers in the ORGANIZATIONAL unit. I created a test organizational unit placed a few inside computers and created a group policy I linked to the test OU. I blocked the legacy on the OU. Gpresult displays that it is the only political hitting the computer. Some Internet Explorer settings are updated while others are not? I imported the inetres.adm file in the new policy. I use a server of w2k8 Windows with Group Policy Management to update the policy and run gpresult.
For customers it does not implement try to use the GPupdate command in these machines. Also, you try to apply a restart on these machines and may also attempt to refrech domain and Active Directory.
Maybe you are looking for
-
For some reason, Mozilla or don't let me download from any site, including your own. This was not always a problem. He just started a while back. Maybe after an update? I'm not sure.Hope you can help solve this problem.Thank youNancy
-
Satellite Pro P100 - WinDVD stutters during playback
Satellite toshiba windvd Pro100 stutters during playback of dvd movies - worse yet, when you use windows Vista media player - can help you solve?
-
Can I put the Satellite L505-144 with a SSD?
Hello Anyone know if the Toshiba Satellite L505-144 can be improved with a SSD? Thank you Chris
-
XP starts the sequence but stops at a black screen before the end of startup.
When I start my PC's of tracks through the boot sequence but evaporate hangs on a white, black screen. Then I plant sequence and re-boot into Safe Mode. I tried to restore to a previous point, but have always had the same problem. The company I bough
-
Windows Media Player does not play videos
When I try to run a .wmv file say an attachment in an email the blue donut fair bit turns. I have to click the STOP button to stop smoking. The same tihing occurs when I try to run a library .wmv file. Any help would be appreiciated. I am running