SQL help (line column... a little)
I'm a little weird to write query. I want to turn rows into columns, but they must be grouped by line # as well. They will have to be group by tracking #...The other issue is, the system can have 5 minimum options and a maximum of 7. Here are the options...
So, in reality, he will be taking a set of lines (misc 5-7) and returning to the side to make the columns. But, the new column headers are always defined like this max 7 and 2 can be cancelled on if not available...
Confusing even explain... insert statement for example 2 below... we have 6, 7 criteria we met...
----------------------------------------------------------
Sector of activity
Type
Did you review the user guide?
Application
Enter your Message
Have you reviewed the FAQs?
Tracking number of EIS
-----------------------------------------------------------
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323646, 'application', "DRI INT");
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323646, 'Enter your Message', 'test');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323646, 'have you seen the FAQ document?', 'No');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323646, 'have you reviewed the user's guide?', 'No');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323646, "line of Business", "AUTO");
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323646, 'Type', 'Suggestion');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323647, 'application', 'BEST');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323647, 'Enter your Message', 'test');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323647, 'have you seen the FAQ document?', 'No');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323647, 'have you reviewed the user's guide?', 'Yes');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323647, 'Number of EIS path', 'none');
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323647, "line of Business", "MAPS");
Insert into the TABLE
(FIELDVALUES CAN ONLY BE TRACKINGNUMBER, NM_PARM)
Values
(323647, 'Type', 'Question');
COMMIT;
with "TABLE" as
(
(select 323646 TRACKINGNUMBER, 'Application' NM_PARM, 'DRI INT' FIELDVALUES from dual)
union all
(select 323646 , 'Enter Your Message', 'test' from dual)
union all
(select 323646 , 'Have you reviewed the FAQ document ?', 'No' from dual)
union all
(select 323646 , 'Have you reviewed the User guide ?', 'No' from dual)
union all
(select 323646 , 'Line Of Business', 'AUTO' from dual)
union all
(select 323646 , 'Type', 'Suggestion' from dual)
union all
(select 323647 , 'Application', 'BEST' from dual)
union all
(select 323647 , 'Enter Your Message', 'test' from dual)
union all
(select 323647 , 'Have you reviewed the FAQ document ?', 'No' from dual)
union all
(select 323647 , 'Have you reviewed the User guide ?', 'Yes' from dual)
union all
(select 323647 , 'ISW Tracking Number', 'none' from dual)
union all
(select 323647 , 'Line Of Business', 'CARDS' from dual)
union all
(select 323647 , 'Type', 'Question' from dual)
)
, t as
(
select distinct TRACKINGNUMBER tn from "TABLE"
)
select
(select FIELDVALUES from "TABLE" where NM_PARM = 'Application' and TRACKINGNUMBER = t.tn) "Application"
,(select FIELDVALUES from "TABLE" where NM_PARM = 'Enter Your Message' and TRACKINGNUMBER = t.tn) "Enter Your Message"
,(select FIELDVALUES from "TABLE" where NM_PARM = 'Have you reviewed the FAQ document ?' and TRACKINGNUMBER = t.tn) "Have you reviewed FAQ?"
,(select FIELDVALUES from "TABLE" where NM_PARM = 'Have you reviewed the User guide ?' and TRACKINGNUMBER = t.tn) "Have you reviewed User gui?"
,(select FIELDVALUES from "TABLE" where NM_PARM = 'ISW Tracking Number' and TRACKINGNUMBER = t.tn) "ISW Tracking Number"
,(select FIELDVALUES from "TABLE" where NM_PARM = 'Line Of Business' and TRACKINGNUMBER = t.tn) "Line Of Business"
,(select FIELDVALUES from "TABLE" where NM_PARM = 'Type' and TRACKINGNUMBER = t.tn) "Type"
from t
Application Enter Your Message Have you reviewed FAQ? Have you reviewed User gui? ISW Tracking Number Line Of Business Type
----------- ------------------ ---------------------- --------------------------- ------------------- ---------------- ----------
DRI INT test No No AUTO Suggestion
BEST test No Yes none CARDS Question
Tags: Database
Similar Questions
-
SQL help - lines, view by grouping...
Greetings!
Is this possible in Oracle 10 g using the SQL statement.
EMP table - EMPLID, DEPTID fields.
Data: E01, D01
E02, D01
E03, D01
E11, D11
E12, D11
I'm looking for output as follows using a SQL statement...
DeptID, EmplID
D01 E01
E02
E03
D11, E11
E12
Thanks in advance.Try this:
WITH emp AS (SELECT 'E01' emplid, 'D01' deptid FROM dual UNION ALL SELECT 'E02' emplid, 'D01' deptid FROM dual UNION ALL SELECT 'E03' emplid, 'D01' deptid FROM dual UNION ALL SELECT 'E11' emplid, 'D11' deptid FROM dual UNION ALL SELECT 'E12' emplid, 'D11' deptid FROM dual) SELECT CASE ROW_NUMBER () OVER (PARTITION BY deptid ORDER BY deptid) WHEN 1 THEN deptid||','||emplid ELSE emplid END dept_emp FROM emp ORDER BY deptid, emplid -
Database trigger - PL/SQL: ORA-00984: column not allowed here
I am trying to create a trigger that will update a table of audit used when a row is changed. Using a sequence number to assign an identifier unique to each line as it is created. Need to capture the user ID, date modified and action (update), the image of the front line.
CREATE SEQUENCE emp_audit_seq START WITH 10;Create table emp ( empno NUMBER(4) Primary Key, ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(2));CREATE TABLE emp_audit ( audit_uid NUMBER(15) Primary Key, change_date DATE, change_user VARCHAR2(30), action CHAR(1), empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(2));
Can someone help to help me find what I'm doing wrong with the trigger?CREATE OR REPLACE TRIGGER trig_emp_audit BEFORE UPDATE ON emp FOR EACH ROW BEGIN INSERT INTO emp_audit VALUES(emp_audit_seq.nextval, change_date, change_user, action, :old.empno, :old.ename, :old.job, :old.mgr, :old.hiredate, :old.sal, :old.comm, deptno); END; / Warning: Trigger created with compilation errors. SQL> show errors Errors for TRIGGER TRIG_EMP_AUDIT: LINE/COL ERROR -------- ----------------------------------------------- 2/3 PL/SQL: SQL Statement ignored 3/149 PL/SQL: ORA-00984: column not allowed here
Published by: LostNoob on August 25, 2012 14:24First of all, when you write an INSERT statement, it is always good for the columns that you insert in the list. Which makes the code easier to follow - you do not have separately pull toward the top of the table definition to know what order of columns is inserted. And it makes the code easier to manage because the declaration become invalid if you add a new column to the table in the future.
Second, CHANGE_DATE, CHANGE_USER and ACTION are not (probably) functions and are not local variables so it is not supposed to use them in an INSERT statement. You need to write code or to take advantage of the existing functions to fill in these columns. I suppose, for example, that you want to use SYSDATE to fill the CHANGE_DATE and the USER to fill the column CHANGE_USER. My guess is that ACTION must always be a 'U' for UPDATE.
Thirdly, it seems that you left the: old man on the DEPTNO column.
Put them all together, you would have something like
CREATE OR REPLACE TRIGGER trig_emp_audit BEFORE UPDATE ON emp FOR EACH ROW BEGIN INSERT INTO emp_audit( audit_uid, change_date, change_user, action, enpno, ename, job, mgr, hiredate, sal, comm, deptno ) VALUES( emp_audit_seq.nextval, sysdate, user, 'U', :old.empno, :old.ename, :old.job, :old.mgr, :old.hiredate, :old.sal, :old.comm, :old.deptno); END; /Justin
-
PL/SQL: ORA-00984: column not allowed here
Sorry, it's probably easy and I forgot something simple, but it's driving me crazy :-)
Error: PL/SQL: ORA-00984: column not allowed here on g_deduction_amountVARIABLE g_fk_deduction VARCHAR2(30) VARIABLE g_fk_empno NUMBER VARIABLE g_before_or_after_flag CHAR(1) VARIABLE g_deduction_amount NUMBER BEGIN :g_fk_deduction := '401K'; :g_fk_empno := 7369; :g_before_or_after_flag := 'B'; :g_deduction_amount := 150.00; END; / BEGIN INSERT INTO emp_deductions (fk_deduction, fk_empno, before_or_after_flag, deduction_amount) VALUES (g_fk_deduction, g_fk_empno, g_before_or_after_flag, g_deduction_amount); COMMIT; END; /
in the value clause.
Any help would be appreciated.
Table is below:
Published by: LostNoob on August 23, 2012 19:06CREATE TABLE emp_deductions ( fk_deduction VARCHAR2(30), fk_empno NUMBER(4), before_or_after_flag CHAR(1), deduction_amount NUMBER(6,2));rp0428 wrote:
>
: g_fk_deduction: = "401k".
: g_fk_empno: = 7369;
: g_before_or_after_flag: = 'B ';.
: g_deduction_amount: = 150.00;
>
Why did you put a colon here? Get rid of them.They are necessary, since they are declared SQL * more variable.
The problem for the OP, is that in the clause values in the insert the colon are missing.
Published by: Mark Williams on August 23, 2012 22:31
Here is your example requested:
SQL> create table test (c number); Table created. SQL> variable v_c number SQL> begin 2 :v_c := 46; 3 end; 4 / PL/SQL procedure successfully completed. SQL> begin 2 insert into test values (:v_c); 3 end; 4 / PL/SQL procedure successfully completed. SQL> commit; Commit complete. SQL> select * from test; C ---------- 46 1 row selected. SQL> -
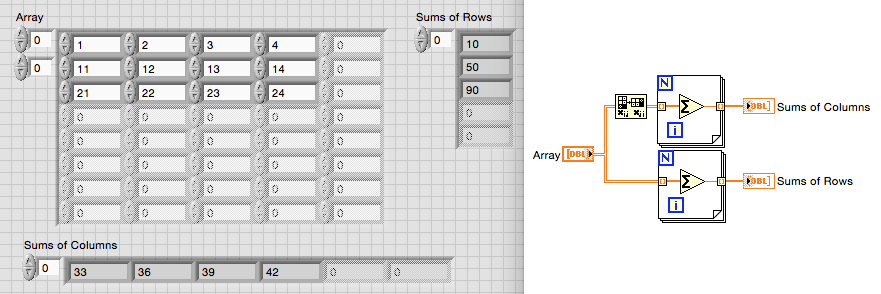
Add the elements of a single line/column of a matrix
Hi all
What is the best way to add all the elements of a single row or column of a given matrix the matrix and the number of this line/column on LabVIEW? The output should be a number for each row or column.
ARIJ,
You always said not if you use a table or a matrix.
The transposition has to be out of the loop.
This will give you the sum of all rows and all columns.
These are functions and LabVIEW base constructions. If you do not understand the concepts, please visit the online tutorials.
Lynn
-
Added line/column in the analysis document Web
Dear,
I am a beginner in Web Analytics. Is it possible to add a line/column of text/formula in a document?
I use version 11.1.2.3
Kind regards
Ahmad.
Hello
To insert a row or a column in a grid of free-form, with the right button of the freeform grid, and then select Insert a line or insert a column
HTH
Kind regards
Zohra.
-
Try to install CS4 Design Premium - disabled since the old computer, new computer does not accept my serial number. Just wasted 2 hours on Adobe help line.
I sent you a private message that will help you (I hope).
because scammers can continue to check this thread, I don't want to enter here information that could help them and this is the reason why I deleted your last post and sent you a private message.
-
I just downloaded the new DC Acrobat, and I'm having a lot of problems with it. It's very, very slow. He has opening, saving, closing, do anything. Is there something that can be done to help him run a little more, well, normally?
I fixed it! I used the string analyze function waiting in the Task Manager while opening a PDF file and have to wait 12 seconds... and it showed that the wait chain has been blocked by the Speech SDK. So I went to my Plugins of PDF from Adobe folder, which in my case is C:\Program Files (x 86) \Adobe\Acrobat DC\Acrobat\plug_ins and delete the plugin ReadOutLoud.api. (I had to close all instances of Acrobat DC first, and I had to also click the UAC Popup Windows application approval raised to remove the plugin) Now... instant Adobe Acrobat DC charge!
-
SQL monitor help with column of chronology

In the report attached to sql, in the timeline column means the whole last 3 began simultaneously and hash join is the first exploited who started?
my understanding is 'index range scan' should start first and give the data to "Single Partition range". Only once this step completed, he should 'TABLE ACCESS Full'. Isn't this correct?
Thanks for your time!
Your description is correct - and I think that you just have to allow some defects in the rounded, graphic display of errors and inconsistencies in what is "the order of execution.
If it is still possible, you can watch dbms_sqltune.report_sql_monitor output text () as numbers COULD clarify the sequence - on the other hand, the granularity of the timer is not very fine.
You may find that the chronology of hash join begins before the access times two table - which highlights the problem of "means to launch an operation." The subroutine "do a hash join" must begin before the two tablescans, on the other hand the mechanism 'return rowsource to parent' cannot start until after the second table access began to return the hash join lines.
Another sign of the available seeds, of course, is that the select statement does not seem to have started until a few seconds after the hash join has started!
Concerning
Jonathan Lewis
-
SQL Help: convert values in two rows in a line
Hello
I am using Oracle 11.2, I want to get the values in different rows in the Tb_a table and insert them into the TB_b table as suite:
create a Tb_a (number (5) id, init_dt date, upd_dt date, addr varchar2 (32));
create a Tb_b (number (5) id, date upd_dt, addr varchar2 (32), dated hist_dt);
insert into Tb_a values (101, to_date('ddmmyyyy','21/08/1990'), to_date('ddmmyyyy','22/08/1990'), "address1");
insert into Tb_a values (101, to_date ('ddmmyyyy', 21 August 1991 '), to_date ('ddmmyyyy', 22 August 1991 '), "address2");
insert into Tb_a values (101, to_date('ddmmyyyy','21/08/1992'), to_date('ddmmyyyy','22/08/1992'), "address3");
insert into Tb_a values (102, to_date('ddmmyyyy','24/08/1990'), to_date('ddmmyyyy','25/08/1990'), 'address_address');
I would like to have data in TB_b as follows.
101, 22 August 1990 ","address1", August 21, 1991"
101, August 22, 1991 ","address2", August 21, 1992 '"
101, August 22, 1992 ', 'address3', null
102, 25 August 1990 ', 'address_address', null
Suggest on the SQL to perform the conversion of Tb_a to Tb_b?
Thank you939569 wrote:
I wish that each line of TB_b has the same value to the ID of the column, upd_dt and addr as Tb_a and the next value in the crt_dt of the Tb_a column.Or table has a column called crt_dt. Do you mean init_dt?
This rule applies to the same ID only. How can I use LEAD on different ID, not the whole picture?
Inlcude
PARTITION BY idin the analytical clause, like this:
INSERT INTO tb_b ( id , upd_dt , addr , hist_dt ) SELECT id , init_dt , addr , LEAD (init_dt) OVER ( PARTITION BY id ORDER BY init_dt ) FROM tb_a; -
SQL Help: Derive from 'News' columns based on condition
Hi all
Can someone help me with this please? I am trying to achieve in a SQL (no), if this can be done in two different stages, even that is fine too...
Thanks in advance,
Chavigny
For a "batch - id", there are several Transactions that are denoted by (cr_crncy_cd, dr_crncy_cd, recvr_cntry_cd), and the "NEW_BTCH_NM" column is basically a concatenation of 'BTCH_NM' + above 3 columns (with a ~)SELECT * FROM ( SELECT 2765 BTCH_ID,'payroll' BTCH_NM,'payroll~EUR~EUR~DE'NEW_BTCH_NM,'1234'TMPLT_ID FROM DUAL UNION SELECT 2765,'payroll','payroll~USD~USD~US','1235' FROM DUAL UNION SELECT 2765,'payroll','payroll~USD~USD~US','1236' FROM DUAL UNION SELECT 2765,'payroll','payroll~GBP~GBP~GB','1237' FROM DUAL UNION SELECT 2766,'SALARY','SALARY~USD~USD~US','1238' FROM DUAL UNION SELECT 2766,'SALARY','SALARY~USD~USD~US','1239' FROM DUAL ) T_BATCH;
I'm trying to derive two new columns "SEQ" & "Output_Batch_name".
The SEQ column:
Output_BTCH_NM:For every batch_id, the first row will be assigned by sequence.nextval. For all transactions within BTCH_ID, all the rows with same NEW_BTCH_NM, share the same sequence number if different, then SEQ.nextval for all distinct rows
EXPECTED RESULTSfor a given batch_id, if the NEW_BTCH_NM is the same for all transactions ( batch_id 2766 in the below example) , then Output_BTCH_NM = BTCH_NM should be marked for All transactions which belong to this Batch_id, Else Output_BTCH_NM = New_BTCH_NM END if
Published by: user10711957 on 25 Sep, 2010 16:37*BTCH_ID BTCH_NM NEW_BTCH_NM TMPLT_ID SEQ Output_BTCH_NM* 2765 payroll payroll~EUR~EUR~DE 1234 1 payroll~EUR~EUR~DE 2765 payroll payroll~GBP~GBP~GB 1237 2 payroll~GBP~GBP~GB 2765 payroll payroll~USD~USD~US 1235 3 payroll~USD~USD~US 2765 payroll payroll~USD~USD~US 1236 3 payroll~USD~USD~US 2766 SALARY SALARY~USD~USD~US 1238 4 SALARY 2766 SALARY SALARY~USD~USD~US 1239 4 SALARYAn extension of the solution of the (slightly modified) jiq
function my_sequence(whichval in varchar2) return number is begin if whichval = 'currval' then return your_sequence.currval; else return your_sequence.nextval; end if; end my_sequence; WITH t AS ( SELECT 2765 BTCH_ID,'payroll' BTCH_NM,'payroll~EUR~EUR~DE'NEW_BTCH_NM,'1234'TMPLT_ID FROM DUAL UNION SELECT 2765,'payroll','payroll~USD~USD~US','1235' FROM DUAL UNION SELECT 2765,'payroll','payroll~USD~USD~US','1236' FROM DUAL UNION SELECT 2765,'payroll','payroll~GBP~GBP~GB','1237' FROM DUAL UNION SELECT 2766,'SALARY','SALARY~USD~USD~US','1238' FROM DUAL UNION SELECT 2766,'SALARY','SALARY~USD~USD~US','1239' FROM DUAL ) select btch_id,btch_nm,new_btch_nm,tmplt_id, case when lag(seq,1) over (order by tmplt_id) = seq then my_sequence('currval') else my_sequence('nextval') end seq, out_btch_nm select btch_id,btch_nm,new_btch_nm,tmplt_id, dense_rank() over(partition by btch_id order by new_btch_nm) seq case when count(distinct new_btch_nm) over (partition by btch_id) = 1 then btch_nm else new_btch_nm end out_btch_nm from tConcerning
Etbin
Posted before you see the following
the sequence # must be continuous, must avoid any shortfall or gaps with the numbering.
the foregoing must be the only user of its own sequence somehow and maybe...
Search for "sequence free gap"... http://asktom.oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:4343369880986
Edited by: Etbin on 26.9.2010 08:21 -
SQL puzzler: Line rankings according to the columns
We have a table that looks like the following:
COL_1_RANK COL_1_VALUE COL_2_RANK COL_2_VALUE 1 AAA 3 HHH 2 BBB 2 GGG 3 CCC 5 JJJ 4 DDD 1 FFF 5 EEE 4 III We want to extract a *single* rank for each case where COL_1_RANK and COL_2_RANK are equivalent. Then we want the values corresponding to this mutual rank to be contained in the same line. Thus, the desired output is as follows:
MUTUAL_RANK COL_1_VALUE COL_2_VALUE 1 AAA FFF 2 BBB GGG 3 CCC HHH 4 DDD III 5 EEE JJJ The other condition is that we want to do this in a *table single pass*. So we are aware of the solutions using two different CLAUSES and by joining in the ranks. It's not what we're looking for here.
We are suspecting that some analytic function can be used here, but can't seem to find, he. Basically, for each line, take the value of COL_1_RANK and, then, on the set of all values of COL_2_RANK , locate the line where COL_2_RANK = s COL_1_RANK. Pull the COL_2_VALUE of this line.
No matter what SQL Smarties out there who have a solution for this?
Thank you
-Joe
SELECT col_1_rank,
col_1_value,
REGEXP_SUBSTR (listagg (col_2_value, ",") THE Group (ORDER BY col_2_rank) (),
'[^,]+',
1,
col_1_rank)
col_2_value
T
order by 1;
-
SQL help, how to group in column A and then get a higher frequency in column B?
Assuming that the following table, operation represents each type of operation of transaction
Employee table operation another column c
' < ' id1
' < ' id1
' < ' id2
' *' id3
id1 ' / '.
question, for each operation, which employee do the most? which employee do the 2nd most?
I thought I need to group by operation first, then get the frequency of the employee and get top 1, or at the top of page 2 of higher frequency.
But I'm struct and don't know how to write sql code.998408 wrote:
Assuming that the following table, operation represents each type of operation of transaction
Employee table operation another column c
'<'>
'<'>
'<'>
' *' id3
id1 ' / '.question, for each operation, which employee do the most? which employee do the 2nd most?
I thought I need to group by operation first, then get the frequency of the employee and get top 1, or at the top of page 2 of higher frequency.
But I'm struct and don't know how to write sql code.Welcome to OTN. OPS! Posted in the wrong forum. Just after in {forum: id = 75}. Before posting it close this thread as answered marking.
If someone answer is useful or appropriate, please mark accordingly. *
-
SQL help - Need help to rotate the columns to rows
I have a HughesNet to divide the columns into multiple lines. For example:
EMP_DEPT
ROWID empid1 ename1 empid2 ename2 empid2 ename2 empid4 ename4 dept4 dep3 dep2 dept1
100001 1 'SCOTT' 10 2 'DAVE' 20 3 10 4 20 SMITH "MILLER"
100002 1 'SCOTT' 10 2 'DAVE' 20 3 'MILLER' 20
Note: EMP_DEPT do not always have information about the 4 employees settled for example in info only 3 employees rank 2 are there
I need to convert and insert it into the EMPLOYEE table as follows:
EMPLOYEE
EmpID ename dept
1 SCOTT 10
2 20 DAVE
3 MILLER 10
4 SMITH 20
1 SCOTT 10
2 20 DAVE
3 MILLER 20
Thank you
KeVHey Kevin,
Here's one way:
WITH t AS ( SELECT level i FROM dual CONNECT BY level <= 4 ) SELECT enty_type, enty_name, enty_id FROM ( SELECT case when mod(t.i,2) = 0 then 'DEPARTMENT' else 'EMPLOYEE' end as enty_type , case t.i when 1 then emp_name1 when 2 then dept_name1 when 3 then emp_name2 when 4 then dept_name2 end as enty_name , case t.i when 1 then emp_id1 when 2 then dept_id1 when 3 then emp_id2 when 4 then dept_id2 end as enty_id FROM emp CROSS JOIN t ) WHERE enty_id IS NOT NULL ;Another using the MODEL clause:
SELECT * FROM ( SELECT enty_id, enty_name, enty_type FROM emp MODEL RETURN UPDATED ROWS PARTITION BY (pk) DIMENSION BY (0 i) MEASURES( emp_id1, emp_name1 , emp_id2, emp_name2 , dept_id1, dept_name1 , dept_id2, dept_name2 , cast(null as number(10)) enty_id , cast(null as varchar2(200)) enty_name , cast(null as varchar2(30)) enty_type ) RULES ( enty_type[1] = 'EMPLOYEE' , enty_id[1] = emp_id1[0], enty_name[1] = emp_name1[0] , enty_type[2] = 'EMPLOYEE' , enty_id[2] = emp_id2[0], enty_name[2] = emp_name2[0] , enty_type[3] = 'DEPARTMENT' , enty_id[3] = dept_id1[0], enty_name[3] = dept_name1[0] , enty_type[4] = 'DEPARTMENT' , enty_id[4] = dept_id2[0], enty_name[4] = dept_name2[0] ) ) WHERE enty_id IS NOT NULL ;Published by: odie_63 on 8 Dec. 2010 21:00
-
With the help of functions/sql in the columns of the report
Hello
New to CRM OD then faced with reports...
So the problem is:
Have a record of account and an account of 'Parent' with her (Type: account)
Now, the report should show the name of the account, the Parent Account(if any), the ID of the Parent account.
Don't know how to implement the 3rd colonel IE parent account ID. It always shows the ID of the main account itself.
Any suggestions will be greatly useful.
Thank you!!!Perhaps this is an option to add a (hidden) field on the account that has the Id of the Parent account. You must fill in this field with a default value and a workflow, in the case where the parent gets later added or changed. This case, the parent Id account will be storen on registration account itself allowing you to report on this subject. It's a little workaround, but I think it works. Let me know if you need help on getting the right syntax.
Best regards, Tim

Maybe you are looking for
-
USB3 undetected on Satellite L870 - 18 X
Hellonow the right side of the Satellite L870-18 X USB3 ports is no longer recognized as non-existent in the device driver. Best regards
-
My scanner stop working, can you help me please?
-
When I start my office in the morning I get a popup saying a Revo is not connected, and I should connect and sign in. Is there a way to stop this? (I don't know really what is a Revo.) Thank you Tom
-
SOME URGENT NEED HELP PLEASE blackBerry smartphones
HEY! How to block a number or a number private call me again? I can delete all the call connect together, not one by one? Thank you!
-
Hi all I have just set up an IPSec tunnel, except use debug crypto ipsec / isakmp how can I check IPSec works? When I configure the encryption card, can I use ip of the tunnel as the peer address. Thanks in advance. Banlan