Status of clustering and failover rises as warning - NO IP Hash offset
Hi all
In my lab at the House, I created a distributed switch and activated the health check. I checked and found that the grouping and health status was as unknown. Screen attached.

After 3 minutes, I had an alert in the VI client to the host stating vds teaming situation of incompatibility. Attached snapshot.
![]()
As I turned off the alarm that teaming and health goes unknown status to the warning. NO IP Hash mismatch. Attached snapshot.

I checked all the port groups and I'm not under IP Hash on any group of ports. I rebooted services.sh but no go. I did check the vmkernel.log file, but did not find something informative. I'm under esxi 5.5 U1 and VC 5.5
I'm running my VMware Workstation 11 environment
Any suggestion how to solve the NO IP Hash mismatch error.
Thank you
Vaibhav
Thank you for your question on my blog, sorry for the late reply. Health check is sometimes a little weird. VMware recommends to use to identify the problem and not constantly. Health check is not supported with virtual load on any type of network interface cards on the platform, see:
This includes FlexFab HP or UCS. I assume that the virtual network adapter in my computer can also be throwing it for a loop. I consider the following options:
-Check your political grouping switch
-Check to each political grouping port group
-Ensure that none are set to the hash of the IP (for mac source based laboratory at home is your best bet or charge based on grouping)
-If everything's not hash IP then I would turn off and on again you might find new results
-At the end of the day the fact that you are using workstation can be the cause of the problem because ESXi hosts see a virtual network card.
Notes on the screenshots:
-First shot is normal, that's the message while it is still testing
-Second and third are related to a real incompatibility or the grant in the above KB
It's my best guess... the truth is that I've seen all kinds of crazy what with virtual cards. I saw a situation where the health check was running a CAM table off entries (500,000) with health check the UCS... it's really bad on UCS do not use.
It will be useful.
Thank you
Joseph
blog.jgriffiths.org
Tags: VMware
Similar Questions
-
Clustering of JMS vs distributed Destinations / persistent stores and failover
Hi again,
I got a bit confused while working my way through the WebLogic documentation and hoped that someone could delete a few things for me.
Is there a difference between the "JMS Clustering' and"Distributed destinations"? As far I knew "JMS Clustering" simply uses "Distributed of Destinations" to spread the JMS load through the complete cluster more using Affinity server configuration options and load balancing. Or is there something beyond that?
I was also wondering is, what happens in persistent stores of "Distributed Destinations" in the case of a server failure. Future message will not be sent to this destination, but rather to other destinations defined in the "distributed" Destination But what happens in the persistent store that is associated with the destination and messages persisted in it? It seems to me that they are lost, unless the server failed or a replacement instance is reduced upward migration of the server migrates the entire instance to another machine, in which case the destination must always be available and functioning correctly. Is this correct? Or are there other ways to retrieve stored messages? Or several destinations share the same persistent, as store using the same data source configuration?
Thank you
ChrisYou are basically correct. JMS clustering is implemented by distributed Destinations.
When a managed server goes down, messages JMS if stored locally will be put on hold until you raise your server again. If you want to implement server or the migration of service shops of persistence must be on some type of SAN, so messages will be consumed once the migration is complete.
Hi again,
I got a bit confused while working my way through the WebLogic documentation and hoped that someone could delete a few things for me.
Is there a difference between the "JMS Clustering' and"Distributed destinations"? As far I knew "JMS Clustering" simply uses "Distributed of Destinations" to spread the JMS load through the complete cluster more using Affinity server configuration options and load balancing. Or is there something beyond that?
I was also wondering is, what happens in persistent stores of "Distributed Destinations" in the case of a server failure. Future message will not be sent to this destination, but rather to other destinations defined in the "distributed" Destination But what happens in the persistent store that is associated with the destination and messages persisted in it? It seems to me that they are lost, unless the server failed or a replacement instance is reduced upward migration of the server migrates the entire instance to another machine, in which case the destination must always be available and functioning correctly. Is this correct? Or are there other ways to retrieve stored messages? Or several destinations share the same persistent, as store using the same data source configuration?
-
I've upgraded to Firefox 4. There is no status bar. And the buttons next and previous have no menus (it moves only a rear screen) or forward. Is - is this normal? Should I use the history button for the course back and forth? And on the status bar, how do you know how the site is to the opening line motionless black?
The status bar has been replaced by the bar of the add-on in Firefox 4.
To get the history of a tab on the previous/next button, you can do one of the following:
- Right-click on the previous/next button
- Press and HOLD left click on the front/back button until the list
- Install this add-on to get the arrow of the menu drop-down:
-
I usually 30 tabs open, and memory rises in an unexpected way, so that when it reaches 1.2 GB, firefox crashes. Also if, for example firefox consumes 700 MB of memory (with lots of tabs open), and if I close the tabs and let just 2 or 3 open, the memory usage does not go down and left to the 700 MB. Thank you for your attention. Cordially, Ricardo
ID of the Crash
BP-765e3c37-0edc-4ED6-a4e9-7ed612100526
See http://kb.mozillazine.org/Firefox_crashes and Firefox plant - troubleshoot and prevent assistance fixing crashes
-
Did someone use RIS to deploy XP on a S100? Our default image does not recognize the SCSI RAID hard drive is connected to the - so can not image for her. I can't seem to find any inregards to this information on the web - ay ideas would be appreciated!
Hello
Please check the advanced search option and use RIS as search terms. You will find several interesting topics.
Unfortunately, I have no much experience with it.
Good bye
-
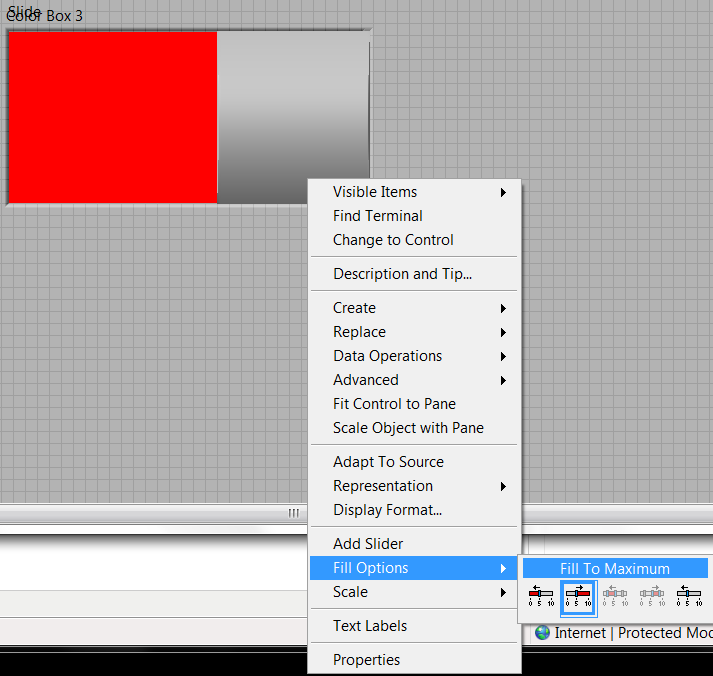
Table of clusters and the cluster is a bar counter, how can I change the color individually?
Table of clusters and the cluster is a bar counter, how do I change the color of the bar individual meter for each element of the array? I just realized that you cannot change the properties of an element of the array without changing everything. For scale, I had to make digital for each graduation of the scale indicators so that each measure meter in the table in the cluster has individual scales. I also had to do some calculations for each barmeter to display the correct proportions of 0 to 100% on the scale. Now, I'm stumped on the color of the bar counter. Basically, if the value exceeds a set value, the meter bar should turn red. It must be in a table to be infinitely scalable.
Thank you
Matt
And yet anothr approach...
Right click on the bar of > Options to fill > maximum fill.
The fill color of the same color as the background color, then make the background color transparent.
Drop a box of color BEHIND the bar and the size correctly.
He has this strange background 3D with flat bar, but what the Hey, his relatives. If its important a custom color box.
Ben
-
Aster Disk:S.M.A.R.T PRI hard status BAD, Backup and Replace
My dear, please help me
When I start my computer the msg show on screen
Aster Disk:S.M.A.R.T PRI hard status BAD, Backup and ReplacePress F2 to RESUME
[transferred from viruses and malware to the Windows/Hardware forum space]
This indicates that your hard drive is bad or is going to fail fast. There is nothing regarding viruses or malicious software. See this link:
-
When I return in a project recently recorded on windows movie maker, all executives went black and have a yellow warning marker, the sound also went but the name of the track is always above executives
Hi steveXB,
1. did you of recent changes on the computer?
2. this happens with all registered projects?
3. you have any program installed on the computer for photo editing?
I suggest that you disable video filters windows make of film and change, if that can help.
Change the video filter settings
http://Windows.Microsoft.com/en-us/Windows-XP/help/MovieMaker/change-video-filter-settings
Windows Movie Maker: Frequently asked questions
http://Windows.Microsoft.com/en-us/Windows-XP/help/Movie-Maker/FAQ
-
PowerCLI script for datacenter clusters and is, ANDS vm guests in a CSV file.
HI -.
I need help to write a script powercli that collect information vcenter such as the list of each Datacenter and its clusters, hosts and vm in a CSV file.
Thanks in advance!
-Philippe.
You can do something like this.
But be aware that it will not report VMHost, Clusters and data centers that do not have any virtual computer in them.
{foreach ($dc in Get-Data Center)
foreach ($cluster Get-cluster-location $dc) {}
foreach ($esx in Get-VMHost-location $cluster) {}
Get-VM-location $esx |
Select @{N = 'Center'; E = {$dc. Name}},
@{N = "Cluster"; E = {$cluster. Name}},
@{N = "$vmhost"; E = {$esx. Name}}, name
}
}
}
-
Consolidation and failover for the uplink on the Distributed switch port group
Hello
I have a problem with the implementation of a distributed switch, and I don't know I'm missing something!
I have a few guests with 4 of each physical cards. On the host eash I configured 2 virtual switches (say A and B), with 2 physical network by vSwitch using etherchannel adapter. Everything works fine for etherchannel and route based on the hash of the IP for the latter.
Recently, I decided to create two distributed switches and move the respective physical ports of virtual switches to this distributed switches. Once again, I want to configure etherchannel and route based on the hash of the IP. But when I open the settings for the uplink port group, aggregation and failover policies are grayed out and cannot be changed. Apparently they inherit configuration also but I don't know where!
Chantal says:
Once again, I want to configure etherchannel and route based on the hash of the IP. But when I open the settings for the uplink port group, aggregation and failover policies are grayed out and cannot be changed. Apparently they inherit configuration also but I don't know where!
You must set the card NIC teaming policy on trade in reality and not on the uplink group more expected.
-
Question: Are there risks or considerations when you rename clusters and data centers?
Question: Are there risks or considerations when you rename clusters and data centers?
We have the intention to rename our data centers and groups today to more meaningful names naming conventions. We intend to do so without problem and during production hours.
Comments, warnings, or known reserves?
All points will be awarded.
Thank you
If you have any scripts or tools that analyze currently based on the name of the Cluster, it could be affected.
-
Hello
Can you please tell what is the difference between the clusters and partitioning?
What is the average of hash partitioning? I know it's done by the hash value. How we will obtain the hash value?
Little confusion to self-study. It would be great if someone explains me.
Thank youHello
Clusters are two or more tables that are physically stored together to take advantage of the similar columns between tables. If two tables have identical column and you frequently need to join the two tables, for example, it is advantageous to store the common column values in the same data
block. The goal is to reduce the disk i/o and thus increase the speed of access when you join related tables.
However, the clusters will reduce the performance of your INSERT queries because several blocks are required to store data from several tables.Oracle partitions addresses the key issue of supporting very large tables and indexes allow you to break it down into smaller, more manageable pieces called partitions.
Once the partitions are defined, SQL statements can access and manipulate the partitions rather than entire tables or indexes.
The partitions are especially useful in applications of data warehouse, that generally, store and analyze large amounts of historical dataHash partitioning is a partitioning technique where a hash key is used to distribute the lines evenly between the different partitions (sub-tables). This is generally used where the beaches are not suitable, i.e. the employee number, productID, etc..
See this link
http://download.Oracle.com/docs/CD/B19306_01/server.102/b14231/General.htm#i1006095:)
-
Recovery of MRI, clustering and high availability
Is there a documentation or best practices out there on the MRI and recovery after disaster, clustering and high availability? I see nothing in the document in this regard.
Thanks a ton!I just wrote an article on this topic, take a look.
http://blogs.Oracle.com/IRM/2009/06/setting_up_an_oracle_irm_serve.html
Concerning
Simon Thorpe
http://blogs.Oracle.com/IRM/ -
Hello
Starting on the route from VCP 4. Read a lot of discussions here with shiny things; Thanks to all who contribute.
Is something I can't work on my own how this file: http://www.VMware.com/PDF/vSphere4/R40/vsp_40_mscs.PDF
Is part of the roadmap of documentation: http://www.VMware.com/PDF/vSphere4/R40/vsp_40_esx_roadmap.PDF
Should I just consider that last?
Thank you
It has to do with availability solutions.
You can protect aid comments clustering or using the solution services that protect the virtual machine (such as VMware HA and VMware FT).
André
-
Is it possible to have redundancy - say HSRP - within a VPN infrastructure? In other words - the peer IP address could be one HSRP or VRRP VIP? If no - one you wanted a redundancy of both VPN routers what mechanism would be used for a failover? Thank you.
I have in fact recently been looking into this myself and there are a few options of derivation according to your platforms and design.
VPN statefull failover 7200's and 3600's head. This allows failover statefull of the IPSEC Tunnels between a primary router secondary school.
http://www.Cisco.com/en/us/products/SW/iosswrel/ps5207/products_feature_guide09186a00802d03f2.html
Failover IPSEC using the injection of road HSRP and reverse. Stateless IOS base tunnel of failover. Closer to what you want if your using IOS VPN.
http://www.Cisco.com/en/us/Partner/Tech/tk583/TK372/technologies_tech_note09186a00800942f7.shtml
As I use ASA at the head end and IOS on the remote database, I'm currently looking for the use of static virtual tunnel interfaces on remote sites with HSRP followed these VTI interfaces with failover based on the status of the tunnel. Not quite sure that HSRP to track interfaces VTI but I guess he can.
http://www.Cisco.com/en/us/products/SW/iosswrel/ps5207/products_feature_guide09186a008041faef.html
The only other issues that leaves me with, is how the ASA handle routing where it as several tunnels of two different endpoints. Anyone know?
Maybe you are looking for
-
An application that I frequently used since last year, Logoist 2, crashed all of a sudden when I was in the middle of using it and will never re-opened. I always get the error "quit unexpectedly". I've tried several things with the developer: diagnos
-
iMac continues to be frozen as claimed by other users
I saw that many users have the same problem with my friends, the computer crashes randomly and the only thing that works is the arrow on the pointer on the screen, but I'm not able to do nothing to restart the system. In the past, it was a victim, fo
-
I imported the photos directly from my camera via a slot card on my computer HP using Windows Live Photo Gallery. Then I separated pictures in files by physical location in my images. I then started to change each locale file and save it. At least
-
HelloI use Microsoft SQL Server 2014 (SP1 - CU4) (KB3106660) Enterprise Edition (64-bit) on Windows NT 6.1 (Build 7601: Service Pack 1) SELECT DISTINCT A.PI_LOOKUP_CATEGORY_ID,REPLACE (REPLACE (UPPER (A.LOOKUP_CATEGORY_NAME), ' ', '_'), '-', '_') AS
-
I learned to download iCloud I need to go through an Adobe partner in the UNITED Arab Emirates. I am based in Dubai, and I was sent a link to a list of all their partners in this area. Can anyone recommend a good? Also why should I go through a partn