Stumped on a regular expression
I'm having problems with a hook of validation after SVN to populate a problem tracking system.Sorry for the bunch of a sample code, but I know that can be a bear help with regexes, and I hope that it will be easy for others see where I am going wrong. The default test is 'handleMultilineComments '. When I change the regex as shown, that passes test, but then the line 87 fails:
assertThat(firstCommentFrom("GEM:PROJID-2 Foo").text, is("Foo")); // expected "Foo", was "F"package com.yawmark;
import static org.junit.Assert.*;
import static org.hamcrest.CoreMatchers.*;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.junit.Test;
public class RegexTest {
static class Comment {
int id;
String text;
}
static class Comments {
static final String REGEX =
"^" // start of the line
+ "GEM:" // the issue number prefix
+ ".*?" // the project ID, if it exists
+ "(\\d+)" // the digits of the issue number
+ "\\s+" // any whitespace
+ "(\\w.*)"; // any comment text up to the next issue number
// + "(\\w.*?)(?:GEM:)?"; // <-- tried this, but failed on "Foo." (only captured F)
static final Pattern PATTERN = Pattern.compile(REGEX, Pattern.MULTILINE | Pattern.DOTALL);
static List<Comment> from(String message) {
List<Comment> comments = new ArrayList<Comment>();
if (isEmpty(message)) { return comments; }
Matcher matcher = PATTERN.matcher(message);
while (matcher.find()) {
comments.add(buildCommentFrom(matcher));
}
return comments;
}
private static Comment buildCommentFrom(Matcher matcher) {
Comment comment = new Comment();
comment.id = Integer.parseInt(matcher.group(1));
comment.text = matcher.group(2);
return comment;
}
static boolean isEmpty(String message) {
return message == null || message.length() == 0;
}
}
private Comment firstCommentFrom(String message) {
return Comments.from(message).get(0);
}
@Test
public void shouldParseGoodIssueNumber() {
assertThat(firstCommentFrom("GEM:PROJID-1\nX").id, is(1));
assertThat(firstCommentFrom("GEM:PROJID-2\nX").id, is(2));
}
@Test
public void shouldHandleDashesInProjectName() {
assertThat(firstCommentFrom("GEM:PROJ-ID-42\nX").id, is(42));
}
@Test
public void shouldHandleSpaceBetweenPrefixAndIssueId() {
assertThat(firstCommentFrom("GEM: PROJID-137\nX").id, is(137));
}
@Test
public void shouldHandleMissingProjectId() {
assertThat(firstCommentFrom("GEM:1234\nX").id, is(1234));
assertThat(firstCommentFrom("GEM: 5678\nX").id, is(5678));
}
@Test
public void shouldHandleTrailingWhiteSpace() {
assertThat(firstCommentFrom("GEM:PROJ-ID-1\nX").id, is(1));
assertThat(firstCommentFrom("GEM:PROJ-ID-2 X").id, is(2));
}
@Test
public void whiteSpaceAfterIssueNumberSignifiesCommentText() {
assertThat(firstCommentFrom("GEM:PROJID-1\nX").text, is("X"));
assertThat(firstCommentFrom("GEM:PROJID-2 Foo").text, is("Foo"));
assertThat(firstCommentFrom("GEM:PROJID-2\tBar").text, is("Bar"));
}
@Test
public void shouldHaveOnlyOneIssue() {
assertThat(Comments.from("GEM:PROJID-42\nX").size(), is(1));
}
@Test
public void shouldHandleMultilineComments() {
assertThat(firstCommentFrom("GEM:PROJ-42\nX\nY").text, is("X\nY"));
assertThat(firstCommentFrom("GEM:PROJ-42\nX\nY\nZ").text, is("X\nY\nZ"));
}
@Test
public void handleMultipleComments() {
assertThat(Comments.from("GEM:1\nX\nGEM:2\nY").size(), is(2));
}
}Thank you!
+ "(\\w.*?)(?=GEM:|\\z)"; // any comment text up to the next issue number or end of input
Tags: Java
Similar Questions
-
AFExactMatch and regular Expressions
Hello
I'm working on something similar to this .
My first shot at it. Found it useful messages of try67 and George. I'm almost there and now, I'm stumped.
My Custom Format Script is the following:
Custom Format script for the text field
If (event.value) event.value += '% ';
My typing a custom Script is the following:
Custom keystroke script
DigOnlyKS();
My custom calculation script is the following:
If (event.value == "") event.value = 0;
My Javascript Document is:
function DigOnlyKS() {}
Get everything that is currently in the field
var val = AFMergeChange (event);
Refuse entry if other thing that the figures
Event.RC = AFExactMatch (/ \d* /, val);
Event.RC = AFExactMatch (/^100\.0| [1-9] {1,2}\.\d{1}|0\.\d{1}$/, val);
}
Valid entries must be: 100.0, 1.0 to 99.9, and 0.1 to 0.9.
The regular Expression seems to work on the Regex testers online.
However, I can't enter anything in the field with the foregoing.
If replace my Regex with the link above - ^ \d+\. ? \d{0,2}$ - I can enter data in the field.
However, if I remove the? the - ^\d+\.\d{0,2}$ - regex to require (I think) the decimal places, I can't enter anything in the field.
Clearly, Miss something.
Thank you.
Regular expression is not appropriate for a typo script until the value has been committed, and even in this case, it may be too restrictive (for example, does not allow for ".") 9 »).
The way I would be inclined to implement would be to put the strike and Validate Format (not calculate) scripts to call the following functions, respectively.
// Custom Keystroke script calls this function percent_ks() { AFNumber_Keystroke(1, 1, 0, 0, "", false); } // Custom Format script call this function percent_fmt() { AFNumber_Format(1, 1, 0, 0, "", false); if (event.value) event.value += "%"; } // Custom Validate script calls this function percent_val() { if (event.value === "") event.value = 0; // Only allow numbers from 0 to 100 if (+event.value >= 0 && +event.value <= 100) { // round to nearest tenth event.value = util.printf("%.1f", event.value); } else { event.rc = false; app.alert("Your error message goes here.", 3); } }It lets you enter values outside the valid range, but the validation script takes care of it. It also allows more than one digit to the right of the decimal, but the validation script it rounds up to the tenth closest. Make sense?
Edit: correction of fault
-
When a string of characters, I'm interested, is buried in an e-mail, I would find these emails. It seems that as the code needed to find an email is already in place, it would take very little effort/code/support added to extend the search capabilities of more effectively, as it is available in spreadsheets.
This particular forum has these capabilities, suggesting that users find useful installation.
Are there reasons preventing these facilities being added to T/B? I find that the ability would frequently help me in search of my email.
FiltaQuilla both Expression search/GmailUI provide functionality, specifically the regular expressions.
FiltaQuilla aims to improve the message filters and has a useful side effect in improving the CTRL + SHIFT + f find. Research of expression increases the QuickFilter bar. Or rather weird global research assistance, but I work around this by using a Saved Search folder, where you use a dialog similar to the message filters and can make use of the enhancements offered by one of these modules.
-
The z570 has not a regular Express card slot (only a mini one)?
The z570 has not a regular Express card slot (only a mini one)?
Hi KiteEye and welcome to the community,
It doesn't have an Express card slot.
The small slot located is a memory card reader.
Dave
-
According to the link below, TS supports regular expressions. Can anyone provide an example where to write regular expressions?
I might be easier to do via a plug-in of .net, but TS permitting, I might go with it.
http://zone.NI.com/reference/en-XX/help/370052N-01/tsref/infotopics/find_regular_expressions/
Hello
Yes, there is a member of the PropertyObject.Search, but the result is search results, so I wonder how to use in the execution sequence?
What a simple solution using only 4 lines in Exression statement to realize this split and trim?
Concerning
Jürgen
-
Problem on regular expressions
Hi all
I'm working on a project that require me to separate the following examples:
+ 0, + 0.0000 E1, - 4.33 + E1, - 4.222 + E1, - 6.33 + E2, - 6.55 + E2
What I need is the final four results separately:
-4.33 + E1.
-4.222 + E1,
-6.33_E2,
-6.55 + E2.
I'm totally cool regular expression. Any help is appreciated!
Thank you
+ Kunsheng
Hi, Kunsheng
Good evening exercise to learn regular expressions...
For example, quick and dirty:

I have the strong feeling that something's wrong here (I guess in ([0-9] + [1-9] +)), but in any case the above code is just starting point for you.
Andrey.
-
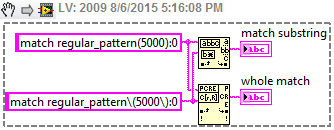
Use matching of regular expressions to search for parentheses
Hi all
I am currently looking for a particular pattern in a string, I can't display the exact string, but say its something like that. corresponds to regular_pattern (5000): 0
I'm also looking for the a different model at the same time, so I have to use the corresponding regular expression and the | function. I can't understand how to match this model because the regular expression function allows parentheses unless I put them in the legs, and that does not help me for this.
Any advice?
Thank you
Matt
Have you tried to escape the bracket?
-
Regular expression matching receives only two digit in brackets
Hello
I use the regular expression of the correspondence with the following expression. It is only able to get all the numbers that are not mere numbers. I want to retrieve all the values which lie between >< in="" the="" string="" and="" create="" an="">
Then
182 2 would be output
182
2
Any help would be appreciated. I've attached what I have so far. Right now I still have the >< and="" it="" can="" only="" grab="" numbers="" that="" are="" not="" single="">
Use (>.) [ ^(<>)]*)< *="" instead="" of="">
-
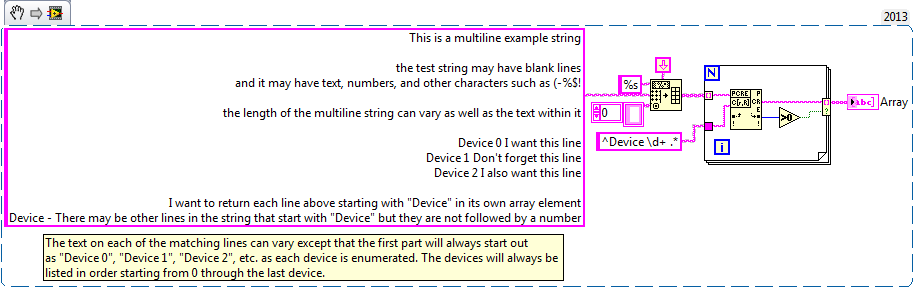
Multiline - Regular Expression Match string
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
regular expression for something that does not have a fixed sequence
Hello
Just having a little trouble with a regular expression. I have an input string and I want to find something that is not this string, so
Input = Hello
Match = Hello
Football game? = False
Entry = Hello1
Match = Hello
Football game? = False
Input = Hello
Match = goodbye
Football game? = True
As I thought that I understood it, to enter as a regular expression in the regular Expression.vi of Match would be ~ (Hello).
If I understand as well, I can't do this by using the match pattern.
Maybe you good people can correct me. Thank you!
-
Complex regular expressions without multiple passes
Does anyone know of a tool that can handle more complex regular expressions without chaining of multiple copies of the VI regular expressions?
For example, if I have a XML string as
Power supply error has occurred.
Sorensen SGA166/188 and I am interested in the tag method to retry only, I could write a regular expression something like
.*
.* to parse the string inside the tag.
kc64 wrote:
For example, if I have a string like
My email address is [email protected]. Please no spamming not me.
and I am interested in the domain name of the email only address, I could write a regular expression something like
@(\w)*\. (com: net | org)
to parse the string 'gmail '.
Forgive me if I am away from base, but I'm flying blind at the moment (not LV to test what I say). You can add to the power of a regular expression using submatches or capture groups. The regular expression you wrote will grab (I think) @gmail.com for the entire game. Let's say you want to get 'gmail' without a second function call. You can do the first group of a little dishonest selection by moving the * inside the parentheses. Then, on the BD pull down on the bottom of the function of regular expression matching to expose a variable number of submatches (both should be in this case). The first should be 'gmail '. The second one should be "com."
In summary, @(\w*)\.) (com: net | org) should give you gmail in the first submatch. Of course, my Perl is a little rusty and LV cannot apply in the same way.
-
What would be the regular expression to extract the "LEDsOnFront" of the string "FELIX-TestModules-LEDsOnFront - VIT.vit" (price not included)?
Looking for whatever text is between FELIX-TestModules - and - VIT.vit? If so, try using the Scan of string with a 'PUME-TestModules-%[^-]-VIT.vit' format specifier
-
regular expression or string (nevermind) format
Resolved,
I can use the string to a fractional number!
Hello
I have an array of strings in a multicolumn list box 2D, and I want to check if each value is a valid number, numbers can be one and can have negative values. Anyone know what regular expression, I need to check it out, or there at - it a still better way?
Best regards
Thijs
solved!
-
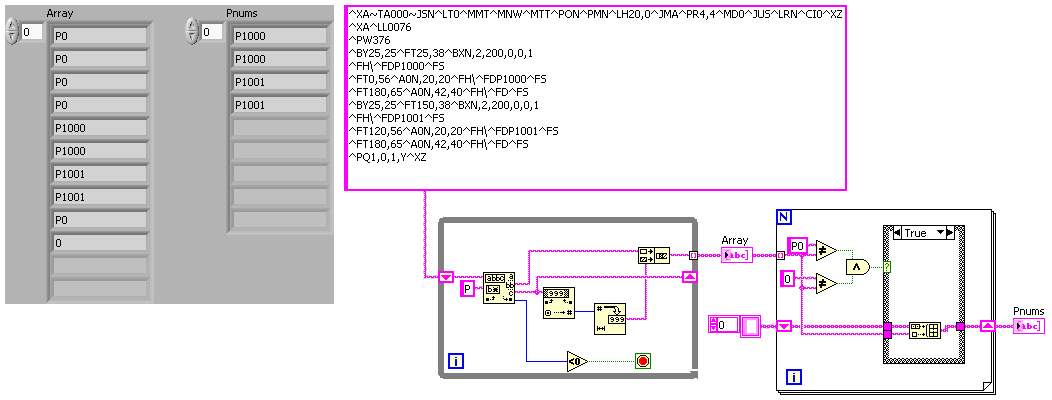
Hello
I have a string I want to use a regular expression to avoid a cascade of matching patterns, but I can't seem to make it work.
The string:
^ XA ~ TA000 ~ JSN ^ LT0 ^ TEM ^ MNW ^ MTT ^ PON ^ PMN ^ LH20, 0 ^ JMA ^ PR4, 4 ^ MD0 ^ JUICE ^ LRN ^ CI0 ^ XZ
^ XA ^ LL0076
^ PW376
^ 25, 25 ^ FT25, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1000 ^ FS
↑ FT0, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1000 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
^ 25, 25 ^ FT150, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1001 ^ FS
↑ FT120, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1001 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
↑ PQ1, 0, 1, O ^ XZI want to get out there is one instance of:
P1000
P1001
In this example. The numbered part will be different for the other channels, like P4567, PA34554, etc. He will never vary from P or PA. The section number can be 4 or 5 digits.
Each of these appear twice in the chain.
The regular expression, I tried to use is:
\^FD*\^FS
and then I was going to eliminate duplicates.
And now my brain doesn't give up.

Tay
This vi retrieves all P followed by numeric characters. You need to change to include AP
-
Search for a string using "Game Plan" or "Regular Expression to Match."
Hello
I would use the 'game plan' or the vi "Expression regular game" simply because the products that provide these vi. The result that interests me is the substring 'after '. I want to be able to specify a "substring" and get everything after the substring of the input string. However, I'm getting all confused and/or watered upward when it comes to "regular expressions". Is there a way to create a "regular expression" which acts as a 'substring' to find within the input string?
The substring is a path of partial directory that contains a colon, backslashes, etc. which are part of a directory path. If some how the "regular expression" entry must ingnore all special characters and simply to understand if the substring in the string entry and give me 'all things' after the substring in the output of 'after the string.
Use Regular Expression Match instead of match pattern; It's better.

Maybe you are looking for
-
Is there anyway to move my toolbar bookmarks above my navigation toolbar in Firefox 8?
I want to move the toolbar bookmarks above the navigation toolbar. In descending order, I want this interface:-Bookmarks Toolbar-Navigation bar-Tabs Firefox and Chrome seem to fail me to provide this functionality.
-
What is the best the SSD 1 TB with and external storage or fuser 3 TB
I ordered a new iMac 27 "with 4.0 GHz 32 GB 1867 MHz DDR3 SDRAM M395X R9 AMD with 4 GB of video memory I chose the 1 TB SSD from the merger of 3 TB vrs My current computer is a Mac Book Pro with 500 GB SSD + another standard 1 TB drive and I use the
-
Windows cannot find other networks
Hi all I have a problem that happened to me for the first time as follows my Intel WIFI 5100 network card works normally and turned on... but I can't seem to find wireless networks in range... im only 3 feet away from the router and in general I get
-
Hello
-
It's the navto: or goto: hyperlinks to the page to subscribe? Paywall page?
I would like to trigger this function with a button.