regular expression help
Hello
I have a string I want to use a regular expression to avoid a cascade of matching patterns, but I can't seem to make it work.
The string:
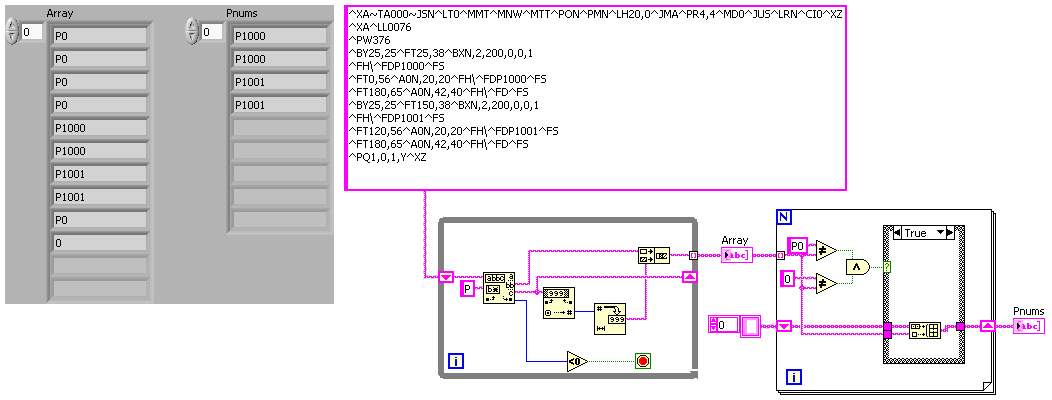
^ XA ~ TA000 ~ JSN ^ LT0 ^ TEM ^ MNW ^ MTT ^ PON ^ PMN ^ LH20, 0 ^ JMA ^ PR4, 4 ^ MD0 ^ JUICE ^ LRN ^ CI0 ^ XZ
^ XA ^ LL0076
^ PW376
^ 25, 25 ^ FT25, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1000 ^ FS
↑ FT0, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1000 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
^ 25, 25 ^ FT150, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1001 ^ FS
↑ FT120, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1001 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
↑ PQ1, 0, 1, O ^ XZ
I want to get out there is one instance of:
P1000
P1001
In this example. The numbered part will be different for the other channels, like P4567, PA34554, etc. He will never vary from P or PA. The section number can be 4 or 5 digits.
Each of these appear twice in the chain.
The regular expression, I tried to use is:
\^FD*\^FS
and then I was going to eliminate duplicates.
And now my brain doesn't give up.
Tay
This vi retrieves all P followed by numeric characters. You need to change to include AP
Tags: NI Software
Similar Questions
-
Regular expression help please. (extraction of a subset of the string between two markers)
I haven't used regular expressions before, and I can't find a regular expression to extract a subset of the string between two markers.
The chain;
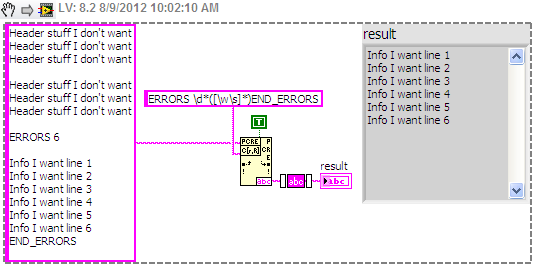
Stuff of header I want
Stuff of header I want
Stuff of header I wantStuff of header I want
Stuff of header I want
Stuff of header I want6 ERRORS
Info I want to line 1
Info I want line 2
Info I want line 3
Info I want to line 4
Info I want to line 5
Info I want line 6
END_ERRORSFrom the string above (it is read from a text file), I try to extract the subset of string between ERRORS 6 and END_ERRORS. The number of errors (6 in this case) can be any number from 1 to 32, and the number of lines I want to extract will correspond with this number. I can provide this number of a caller VI if necessary.
My current solution, which works, but is not very elegant;
(1) using Match Regular Expression for the return of the string after you have synchronized the 6 ERRORS
(2) uses the Regular Expression matches to return all characters before game END_ERRORS of the string returned by (1)
Is there a way this can be accomplished using 1 Regular Expression Match? If so someone could suggest how, as well as an explanation of the work of the given regular expression.
Thank you very much
Alan
I used a character class to catch any word or whitespace characters. This put inside parentheses a substring matching the criteria that you can get by developing the node for regular expression matching. The \d matches the numbers and the two * s repetition of the previous term. So, \d* will find the '6', as well as "123456".
-
Regular expression help numbers
Hello
I want an exact match of 9 digits or 12 digits, my query should give "No Match found" because the input value is actually 10 digits
Select case when regexp_like (regexp_replace (' 123 4567 890 ',' '), ' ^ ([0-9] {9}) |) () [0-9] {12}) $')
then Match "found."
another "No Match Found"
end test
Double;
Need help, I have to do something about something very basic, bad.
Kind regards
AshRemove the 2 brackets:
SQL> select case when regexp_like(regexp_replace( ' 123 4567 890', ' ' ), '^([0-9]{9}|[0-9]{12})$') 2 then 'Match Found' 3 else 'No Match Found' 4 end as test 5 from dual; TEST -------------- No Match Found SQL> select case when regexp_like(regexp_replace( ' 123 4567 89', ' ' ), '^([0-9]{9}|[0-9]{12})$') 2 then 'Match Found' 3 else 'No Match Found' 4 end as test 5 from dual; TEST -------------- Match Found SQL> -
Need help with a regular expression
I have a Zebra printer string that I want to analyze some information, but I can't get a single regex to do.
The string is like the following:
↑ FT342, 695 ^ A0N, 83, 81 ^ FH\ ^ FDS/N: [[WIDGET]] ^ FS
^ FT793, 1170 ^ A0N, 67, 67 ^ FH\ ^ ea FD1. Widget #00123 ^ FS
^ FT793, 1170 ^ A0N, 67, 80 ^ FH\ ^ ea FD2. #00456 Widget Deluxe ^ FS
^ FT793, 1170 ^ A0N, 67, 90 ^ FH\ ^ FD #0789 ^ FS
I want what is in red. It will vary from one label to the label. I will use the results to show to the user what label it is printing. Who is blue only varies, if that helps anything.
Thanks for any help!
Here would be a way using regular expressions. Again, you have to ignore the first entry and this version will add a blank entry in the last position of the table. Wil you have more entries if your label contains more than what you have posted...
-
Help in regular Expression for the beaches of limitation
Hi, I'm working on the provision of a text field is limited to dates, it's just a part of the code. I already have the validation of the dates, but I am now limiting what the user enters using a regular expression. This code works a little however, it does not limit me for example I can enter more than 2 digits, but then he limits based on the total amount allowable so for example 8 digits are allowed if I just type. I need to stop after 2 digits then have a - then 2 other numbers then one - and then followed by 4 digits. I tried to limit each section and grouping as well. Any help would be greatly appreciated. Thank you.
It is in the format code and I am the appellant in the key sequence.
function DateKS () {}
var value = AFMergeChange (event);
If (! event.willCommit) {}
Allow only characters that match the regular expression
Event.RC = /^([0]{0,1}[1-9]{0,1}|[_1]{0,1}[012]{0,1}) ([-] {0,1}) ([0] {0,1} [1-9] {0,1} |) [12] {0,1} [0-9] {0,1} | ([3] {0,1} [01] {0,1}) ([-] {0,1}) ([0-9] {0,4}) $/ .test (value);
}
}
I decided that control for 100 and 400 was not necessary because this event does occur that all 400 years. But I'm working on it further and changed even more. Here is my code to work.
function isLeapYear (year) {}
year return % 4 = 0;
}function checkDaysInMonth (day, month, year) {}
daysInMonth var = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31];If (month = 2) {}
If (isLeapYear (year)) {}
daysInMonth [1] += 1;
}
}return daysInMonth [month - 1] > = day;
}function checkDateFormat (dateStr) {}
var errorMsg = ",
maxYear = (new Date()) .getFullYear (),
minYear = maxYear - 1,.
match = dateStr.match(/^(\d{2})-(\d{2})-(\d{4})$/),
months,
day,
year;If {(matches)
month = parseInt (matches [1], 10);
day = parseInt (matches [2], 10);
year = parseInt (matches [3], 10);If (month < 1="" ||="" month=""> 12) {}
errorMsg = "invalid value for the month: ' + matches [1];"
} ElseIf (day = 0) {}
errorMsg = "invalid value for the day:" + match [2];
} else if (! checkDaysInMonth (day, month, year)) {}
errorMsg = "number of days for invalid month: ' + match [2];"
} ElseIf (year < minyear="" ||="" year=""> maxYear) {}
errorMsg = "invalid value for the year:" + match [3] + "-must be between" + minYear + "and" + maxYear;
}
} else {}
errorMsg = "invalid date format: ' + dateStr + ' \r\nPlease use format: dd-mm-yyyy ';"
}return errorMsg;
}function checkReceivedDate() {}
var value = AFMergeChange (event),
errorMsg = ";
ignore control if the value is blank, because this field is not mandatory
If (! value) {}
return;
}If {(event.willCommit)
errorMsg = checkDateFormat (value);If (errorMsg) {}
App.Alert (errorMsg, 0, 0, "error");
Event.value = ";Returns false;
}
} else {}
Allow only characters that match the regular expression
Event.RC = /^(?:0) [1-9]? 1 [012]?) ? -? ( ? : 0 [1-9] ? | [12] [0-9]? 3 [01]?) ? - ? 2? 0? [0-9] {0,2} $/ .test (value);
Event.RC = / ^ \d{0,2}-?\d{0,2}-?\d{0,4}$/.test(value);
}Returns true;
} -
Regular Expression search and replace question - please help!
I was wondering if someone could help me I have a lot of paper with notes like this: [1], but I need them to look like in this [1].
I don't know what to put in the section find [[\d]*] , but I need help with what to put in the field replace to make < sup > numbers]
In fact, your regular expression is false. What you need is the following:
(\[\d+\])
The field replace must contain this:
$1
-
Need help with regular Expression (RegEx)
Try to wrap your head around a regular Expression for the following format example: 0022-C-4452 OR 0022-C-4452-C
* The 4 digits are always numbers
* The last 5 digits are alpha numeric
* Last (if used) digit is always 'C' (in reference to the second structure)
Hold the dashes for "auto fill" if possible? This would be in the Custom Format? Sequence of keys? Or Validation? I appreciate any help!
I still think that you did not correctly describe your problem.
1 figures of 4 characters.
Optional separator.
Then 6 alphanumeric characters and ' - '.
OR
1 figures of 4 characters.
Optional separator.
Then 6 alphanumeric characters and ' - '.
Optional separator.
Character 'C '.
Note that the "-" is not a number and not an alphabetic character. It is a white space character.
Try:
function {MyRe (cString)
var cFormatted = "";
var RE_MyCode0 = /^(\d{4})[-.]) {0,1} ([A-Za-a0 - 9-] {6}) $/;
var RE_MyCode1 = /^(\d{4})[-.]) {0,1} ([A-Za-a0 - 9-] {6}) [-.] {0,1} ([C]) $/;
If (RE_MyCode0.test (CString) == true) {}
cFormatted = RegExp. $1 + '-' + RegExp. $2;
}
If (RE_MyCode1.test (CString) == true) {}
cFormatted = RegExp. $1 + '-' + RegExp. $2 + '-' + RegExp. $3;
}
Return cFormatted;
} / / end of MyRe function;some tests;
var MyString = "0022-C-4452; good channel;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString));var MyString = "0022-C-4452-C; string of Goo;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString));var MyString = "A022-C-4452" / / bad string;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString));var MyString = '0022-4452-CZ' / / bad string;
Console.println ("Input:" + MyString);
Console.println ("result:" + MyRe (MyString)); -
I need help you rename a file using regular expressions in Bridge.
Hello
I work at a University, and we are working through files for our theses and Dissertations. We were renamed to make them more coherent. I wonder if there is a regular expression that could help in this process?
Examples come from current file names;
- THESIS H343G 1981
- Thesis of 1981 g996e
- THESIS-1981-A543G
I just need to change the actual file names. how they are formatted.
Where appropriate on the thesis.
Hyphens (-) in all white space.
First letter, last letter is lower case on appeal no (H343g)
If the list above should look like;
- Thesis-1981-H343g
- Thesis-1981-G996e
- Thesis-1981-A543g
I've seen people do some pretty cool things with regular expressions! Any help would be greatly appreciated. Thank you!
You would be better to use a script to do this as an example because I don't think it would be possible in the new name of bridge.
Using ExtendScript Toolkit or a text editor to copy the code in any event and save it to sub Filename.jsx
This must be recorded in the appropriate folder. It is located by going to preferences in Bridge, select Startup Scripts, this will open the folder where the script should be saved.
Once this is done close and restart Bridge.
Usage: Goto the Tools Menu and select Rename PDF files
Be sure to only test the code with some files copied to a separate first folder to make sure it's what you want.
The script will make all PDF files in the selected folder.
#target bridge if( BridgeTalk.appName == "bridge" ) { renamePDFs = MenuElement.create("command", "Rename PDFs", "at the end of Tools"); } renamePDFs.onSelect = function () { app.document.deselectAll(); var thumbs = app.document.getSelection("pdf"); for( var z in thumbs){ var Name = decodeURI(thumbs[z].spec.name); var parts = Name.toLowerCase().replace(/\s/g,'-').match(/(.*)(-)(.*)(-)(.*)(\.pdf)/); var NewName = parts[1].replace(/^[a-z]/, function(s){ return s.toUpperCase() }); NewName += parts[2]+parts[3]+parts[4]+parts[5].toUpperCase().replace(/[A-Z]$/, function(s){ return s.toLowerCase() }); NewName += parts[6]; thumbs[z].spec.rename(NewName); } }; -
Helps the understanding of regular Expressions
Hello people,
I need help to understand Regular Expressions.
Can someone help me understand why second query not returning ", CA, '?-- This returns the Expected string from the Source String. ", Redwood Shores," SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa', ',[^,]+,', 1, 1) "REGEXPR_SUBSTR" FROM DUAL; REGEXPR_SUBSTR ------------------------------- , Redwood Shores, However, when the query is changed to find the Second Occurrence of the Pattern, it does not match any. IMV, it should return ", CA," SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa', ',[^,]+,', 1, *2*) "REGEXPR_SUBSTR" FROM DUAL; REGEXPR_SUBSTR ------------------------------- NULL
I did research on this forum and found the link on the thread "https://forums.oracle.com/forums/thread.jspa?threadID=2400143" for the basic tutorials.
Kind regards
P.The reason is that the comma between 'Redwood Shores' and 'CA' already represents the first occurrence.
So it can not match the second occurrence at the same time.You can replace to (remove the trailing ',' in the regex):
SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',',[^,]+', 1, 1) REGEXPR_SUBSTR FROM DUAL; SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',',[^,]+', 1, 2) REGEXPR_SUBSTR FROM DUAL;Published by: hm on 14.06.2012 00:52
When you remove also the leading comma you get to the BlueShadows solution.
-
Need help with regular expressions
Hi all
I need your help, because I have no ideas more...
I have the following problem: in the column of the database table, I have the string with the names of files already uploaded to the database. For example: + File1_V01.txt +, + File1_v02.txt +, + File1_01_v01.txt +, etc. The string _vxx * + or _Vxx * + (non-case sensitive) represents the version of the file.
Now the problem: I'll upload the file with the name + File1_v02.txt + (already exists in the table).
If the file name already exists in the table the pl/sql function should get the name of the file with the following version number. In my case it takes + File1_v03.txt +.
Is it possible to do this using SELECT with regular expressions?
Best regards and thanks!with t as ( select 'File_V05.txt' fn from dual union all select 'File_V04.txt' fn from dual union all select 'File2_v03.doc' fn from dual union all select 'File2_v115.doc' fn from dual union all select 'File2_v15.doc' fn from dual union all select 'File1_v03.doc' fn from dual union all select 'File1_v115.doc' fn from dual union all select 'File1_v999.doc' fn from dual union all select 'File2.doc' fn from dual union all select 'File2_v05.doc' fn from dual union all select 'File1_v01.txt' fn from dual union all select 'File1_v02.txt' fn from dual union all select 'File1_v1.txt' fn from dual union all select 'File1_v1.doc' fn from dual union all select 'File1_v2.txt' fn from dual union all select 'File2_v01.doc' fn from dual union all select 'File2_v02.doc' fn from dual union all select 'File1_ABC_v01_DEF.docx' fn from dual union all select 'File1_ABC_V02_ABC.docx' fn from dual union all select 'File1_ABC_v01_12_04_17.docx' fn from dual union all select 'ABC_V1_QWERT.pdf' fn from dual ) select fn, case when fn!=fn_new then last_value(fn_new) over(partition by regexp_replace(upper(fn),'V[[:digit:]]+','') --(.*?V0*)([1-9]+)(\..*?)$ order by nv rows between unbounded preceding and unbounded following ) else fn end fn_new from ( select case when v-1 <= 0 then fn else regexp_replace (fn, '(_v|_V)(\d*)', case when length(substr(fn,v+1,p-v-1)+1) > (p-v-1) then '\1'||to_char(substr(fn,v+1,p-v-1)+1) else '\1'||lpad(substr(fn,v+1,p-v-1)+1,p- v-1,0) end ) end fn_new ,fn ,case when v-1 <= 0 then -1 else substr(fn,v+1,p- v-1)+1 end nv from ( select fn, regexp_instr(upper(fn),'_V[[:digit:]]+',1,1,1) p, instr(upper(fn),'_V')+1 v from t ) ) order by fn FN FN_NEW ABC_V1_QWERT.pdf ABC_V2_QWERT.pdf File_V04.txt File_V06.txt File_V05.txt File_V06.txt File1_ABC_v01_DEF.docx File1_ABC_v02_DEF.docx File1_ABC_v01_12_04_17.docx File1_ABC_v02_12_04_17.docx File1_ABC_V02_ABC.docx File1_ABC_V03_ABC.docx File1_v01.txt File1_v3.txt File1_v02.txt File1_v3.txt File1_v03.doc File1_v1000.doc File1_v1.doc File1_v1000.doc File1_v1.txt File1_v3.txt File1_v115.doc File1_v1000.doc File1_v2.txt File1_v3.txt File1_v999.doc File1_v1000.doc File2.doc File2.doc File2_v01.doc File2_v116.doc File2_v02.doc File2_v116.doc File2_v03.doc File2_v116.doc File2_v05.doc File2_v116.doc File2_v115.doc File2_v116.doc File2_v15.doc File2_v116.doc -
Help... Regular expression for characters [special] /: ^ & * () @# $
Regular expression to parse the string in square brackets:
I am trying to parse a string in square brackets, but as [] are special characters used in regular expressions to start a character class, I want to remove its special meaning. This regular expression **_user=[a-zA-Z]*@[a-zA-Z]{2}+.abc.com_** works for the analysis of [email protected]* but I want to analyze _user = [[email protected]] _ *, I use the term regular *user=\[[a-zA-Z]*@[a-zA-Z]{2}+.abc.com\]*_* but is in error because it makes special sense of character class. I tried to use \ backslash before *------[]] * but it not working giving error * "INVALID ESCAPE SEQUENCE."
[JAVA CODE: user = "user=\[[a-zA-Z]*@[a-zA-Z]{2}+.abc.com\"];
Pat pattern is Pattern.compile (user);.
Carpet to match = pat.matcher ("2011-03-11 02:08:44, 653: User = [[email protected]], Doing report: account.server.regprocmemunix.daily");
If (mat.find ()) {}
User1 = mat.group ();
}
This room code gives error _ _ "SEQUENCE EXHAUST" INVALID and throw a PatternSyntaxException*.
Please help me parse the string within large brackets [].You realize that, although ' [' is a special character in a regular expression, ' \' is a special character in Java, right?] You also need to escape to the ' \'.
So, if you want to use ' [' in your regular expression, you must use something in the sense of]
\\[Published by: almightywiz on April 25, 2011 14:05
DOH... too slow...
-
Form validation helps with the regular Expression [a-zA-Z]
I'm trying to use the regular expression [a-zA-Z] to allow only upper or lowercase WITHOUT SPACES. With the help of [a-zA-Z] allows space and numbers.
Could someone give me a point in the right direction?
Thank you!
RGNelson wrote:
I'm trying to use the regular expression [a-zA-Z] to allow only upper or lowercase WITHOUT SPACES. With the help of [a-zA-Z] allows space and numbers.
Could someone give me a point in the right direction?
Please try with the following regular expression, which should work for text entry fields 'a line' well standard.
^ [A-Za-z] + $
See you soon,.
Günter
-
Find and replace - regular expression to help?
How can I find ' <!-* PAGE footer AREA *-> "and replace it and evething after with my new coding of footer on all my pages.
The problem is:
The code in my existing page footer area is not the same on all pages.
I want to replace it with a new one on all pages
I watch the operators of regular expressions, not found patern that works...
Thanks in advence for your help
The following regular expression is the and everything up, but not including the closing tag:
[\s\S]+(?=<\/body>)
Use it in the search field and put the comment and the code to the footer in the field replace. Select use regular expression.
Always make a backup before using a regular expression on many pages.
-
The clob data analysis - helps in the regular Expression
Hello
Need to analyze a clob and and get its value.
with the temp as
(select '-dn=cn=9245fe4a-d402-451c-b9ed-9c1a04247482,ou=people,dc=idauth-userstore,dc=standardlife,dc=com' as double val)
Select * Temp;
"Analysis to include only the characters after ' dn = cn =" and ending with a comma, so I need to value the O/P as feadcbedca
How to achieve this using regular expressions.
Also is it a useful site to learn Oracle regular expressions for beginners like me.
If yes give me the link, it will be useful.
Thanks in advance
SQL> with temp 2 as 3 ( 4 select '- dn=cn=9245fe4a-d402-451c-b9ed-9c1a04247482,ou=people,dc=idauth-userstore,dc=standardlife,dc=com' as val from dual 5 ) 6 select regexp_replace(ltrim(regexp_substr(val, 'dn=cn=[^,]+'), 'dn=cn='), '[^[:alpha:]]') val 7 from temp; VAL ---------- feadcbedca SQL>
-
Need help with a simple regular expression replacement
Hello everyone,
He comes to the table that I have to work with.
My select statement isCREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (129,'Kirby Hotel','25A Aitken Street Wellington','Wellington','04 918 8513','[email protected]','Deahdoow Maharg','A',null,null,'LEAN',to_date('14/02/13','DD/MM/RR'),'027 356 4333'); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (167,'Avenue ee','10 Wellington Street Wellington','Wellington','4444444','[email protected]','James','A',null,null,'LEAN',to_date('21/02/13','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (185,'Quadrant Hotel','10 Waterloo Quadrant, Auckland','Auckland','9555555','[email protected]','Quentin QQ','A',null,null,'LEAN',to_date('04/03/13','DD/MM/RR'),null);
I have to use the function replace twice. One is to replace the Chr (13) a comma is second band a comma where there are two commas.SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_ID
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.
Thanks in advance
AnnHi, Ann.
Ann586341 wrote:
Hello everyone,He comes to the table that I have to work with.
CREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); ...Thanks for posting the sample data. You post the results, but the validation of the existing query which I suppose, produced good results. I can't run this query, because it requires the ijs_seminar table and a connection variable that also has no post, but I can just comment on the join and the WHERE clause.
Is this really the best set of sample data for this question? This problem involves Chr (13) and repeated commas, but I don't see any s CHR (13) or repeated commas in the sample data. In addition, it seems that there are a lot of columns that play no role in this issue and just to make things difficult to read.
My select statement is
SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_IDI have to use the function replace twice. We need to replace the Chr (13) by a comma,.
As posted, inside REPLACE replaces Chr (13) with a comma and a space which could be important if you then pick up consecutive commas.
second is the band a comma where there are two commas.
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.Assuming you want to replace Chr (13) with just a comma, then an equivalent would be:
SELECT acc.hotel_name || '(' || REGEXP_REPLACE ( acc.address , '[,' || CHR (13) || ']{1,2}' , ',' ) || ')' AS h FROM tbl_accommodation acc INNER JOIN ijs_seminar s ON acc.accommodation_id = s.accommodation_id WHERE s.seminar_id = :P27_SEMINAR_ID ;In the argument to REGEXP_REPLACE 2nd
[xy]{1,2}medium 1 to 2 characters of set of x and y. This could be
x or
there or it could be 2 characters
XY or the other way
YX or it could be the same characters 2
XX or
YYREGEXP_REPLACE is slower that REPLACE. Even if your original expression is longer, it may be more effective. (Performance may be not a problem in this case.)
Maybe you are looking for
-
Add/customize buttons do not work
Since the upgrade to FF29.0.1 today, I can't access the option "Customize...". "through the Burger, button bar, or by right clicking on one of the toolbars. Also, I get no answer if I try to click on the Add-ons button in the Burger menu. Everything
-
I am unable to prevent iTunes from running. Well, it is not actually run. It crashed and I used alt-cmd-esc to stop it, but it will not disappear in the list programs. I killed all iTunes process in activity monitor, but iTunes refuses to stop. I hav
-
mail download messages but nothing appears
Greetings, Mail again me this is download the messages, but nothing ever happens. I checked the spam, junk, smart folders, rules of nowhere - but I don't know what is happening. I have multiple email - some IMAP, some POP3 accounts, but none are exc
-
"Wait until done" does not stop even if data generation is already waiting.
Hi all I have a code as well for production and data acquisition with rates of around 50 kHz samples. I've predetermined length of the data, so I use finite-sample-generation. I use also wait until done to make sure that my work is done correctly. Wh
-
BlackBerry 9360 Smartphones will not connect to the pc
Its so frustrating, my device a heating and drained baterry of 90% - 0% in less than an hour, I downloaded the Desktop Manager to update my device software in the oder, the DM wanted to update after I plugged it into the handset, so I updated the DM,