tables of performance vs resxtop
Is there an advantage to using resxtop on performance dashboards?
Is there a knowledge base for the counters?
Thank you
Rudi
I prefer to use resxtop/esxtop because it allows you to quickly search multiple metrics and browse screens see near real-time statistics. Both work fine, it's just a matter of preference I suppose, but I find that the more detailed information you are looking for the faster you will use esxtop/resxtop.
Duncan (VCDX)
Available now on Amazon: vSphere 4.1 HA and DRS technical deepdive
Tags: VMware
Similar Questions
-
Cannot display tables of performance of ESXi 4.1 data store
Using Vcenter, I select the tab performance on each host ESXI4.1. I can view a chart for reading of data store and the latency of writing in real time. However, if I select any period other than in real time, the array is empty.
Others for example CPU performance measures work well in real time and measures 24 hours a day.
I have to be able to measure the reading of the data and store latency of writing on at least a 24-hour period. Someone had this problem?
Examples shown in attachemnt.
Hello
Try to change the statistical level in 3:
go to Administration - vCenter Server Settings - statistics and change the statistical level to 3
wait for a while and check the historical performance, don't forget, change it back when you did with analysis
-
The tables of performance of update 4 cannot install config statsreport.war
Hi, we went just to vcenter update 4 2.5...
I then, on the vcenter server tried to load the new array of performance (plugin)? ...
I followed the KB article
and use a vcenter user account, account of local server with the admin rights and a domain account AD for the installation batch file... (on the command-line).
I get the same error,
«2 configure the statsreport.war...»
"jar" is not recognized as internal or external, command an executable program or batch file.
Setup ended because the statsreport.war file could not be configured.
Press a key to continue. »...
and it pours out on to the command prompt orginal... with no graphic plugin of performance...
We are equipped with a remote r2sp2 win2003 with a sql back-end system...
is the windows server must be restarted for the variables take effect?
The 'pot' is not recognized error is what you get if the path is not correctly point to your JDK installation. I check the value of the PATH environment variable in a shell for example echo %PATH% and search your directory "bin" of JDK being listed. Even better to run
javac-version
from the command shell, he must produce something like
C:\ & gt; javac-version
javac 1.6.0_11
I don't see the new path of java, I added when I have c: & gt; echo %path%
reset?
The message:
'< executable >' is not recognized as builtin or external, an executable program or batch file.
is a standard for MS Windows when < executable > is not found in the current folder or path environment.
In this case 'pot' is not found. Make sure you have correctly location PATH environment variable of installation by putting it in the same command prompt window right before starting the install.bat script as described in the KB article.
Hope this will help.
-
Inconsistent performance table
Hi all
Ive a problem recently with the tables of performance to the virtual Center and I was wondering if anyone has seen this and know how to solve this problem?
I was looking at the CPU usage and the ready time cpu on a couple of virtual methods after a ticket was born low yield. When looking at the hand of GPU real-time was about 100 ms with a tip on a less time 1000ms. when looking back at the last graphic day he showed up to 1000000ms cpu ready.
thought to what is a little weird and has continued to monitor the real time of the majority of the day knowing that was sitting on about 100 ms for most of the day. I watched the day after and for the few hours that I had been followed, he showed around 5000ms where I know it's about 100 MS for the majority of it. I ran esxtop and it seams to be on par with the graph in real time. I checked a hand full of other virtual methods and seems to suffer the same inconsistencies.
any ideas why this is?
running for all my hosts and vsphere esx 4 u1 vc.
See you soon
The day is a roll of 5 minutes. Check out this link for some good information about the performance monitoring, http://communities.vmware.com/docs/DOC-5230.
If you have found this device or any other useful post please consider the use of buttons useful/correct to award points
-
Say I have a table of 500 items and want to perform analysis on every 10 items, such as performing an analysis of the elements 0-9, then 10-19, 20-29 etc etc then what would be the best way to do this.
I thought to split the table in a number of the subarray, but table 1 d decimate function does not maintain the order of the elements in the original array. There is another function that can be used to achieve this?
I understand that I might use a loop of some sort to navigate the table and perform analysis every 10 items, but the table can be big enough and I want to do it as efficiently as possible.
Any ideas?
Stroke
Amd1480 wrote:
Check this
I have the feeling that the constant resizing of the table within the shift register could cause more memory allocation you would like.
I would recommend a simple "reshape array' or"subset of table", as it has already been suggested. Here are the two alternatives.
If the array of size not divisible by the size of subeset, this example will ignore the incomplete tail. (It would be a negligible change in order to treat it instead).

-
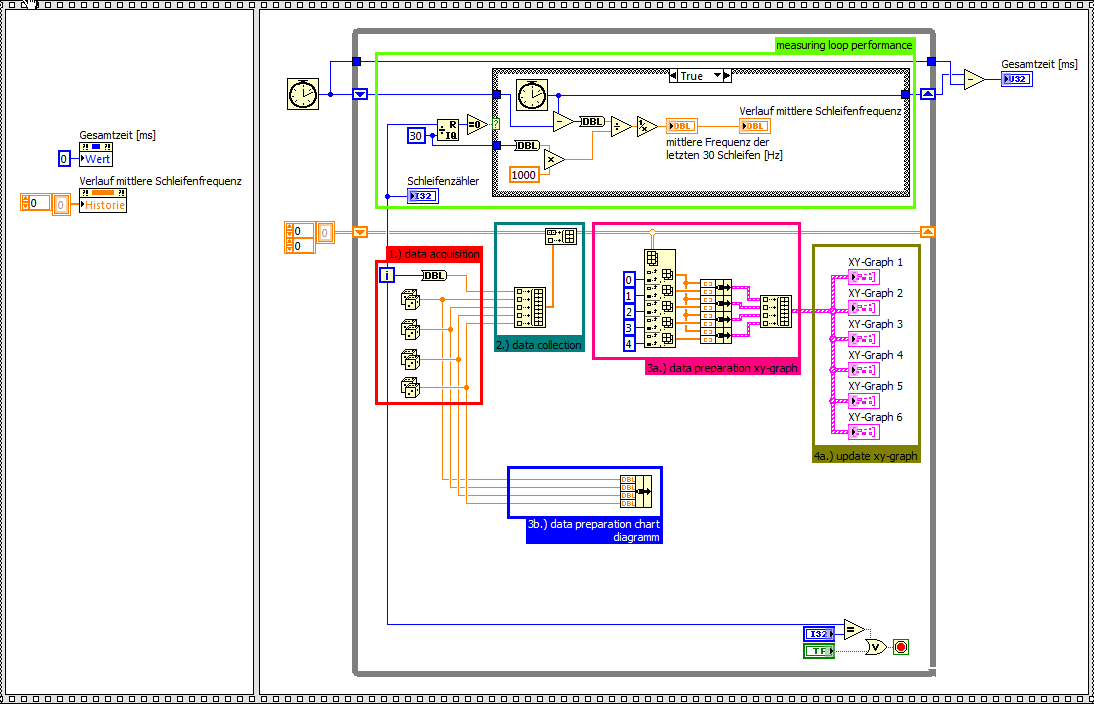
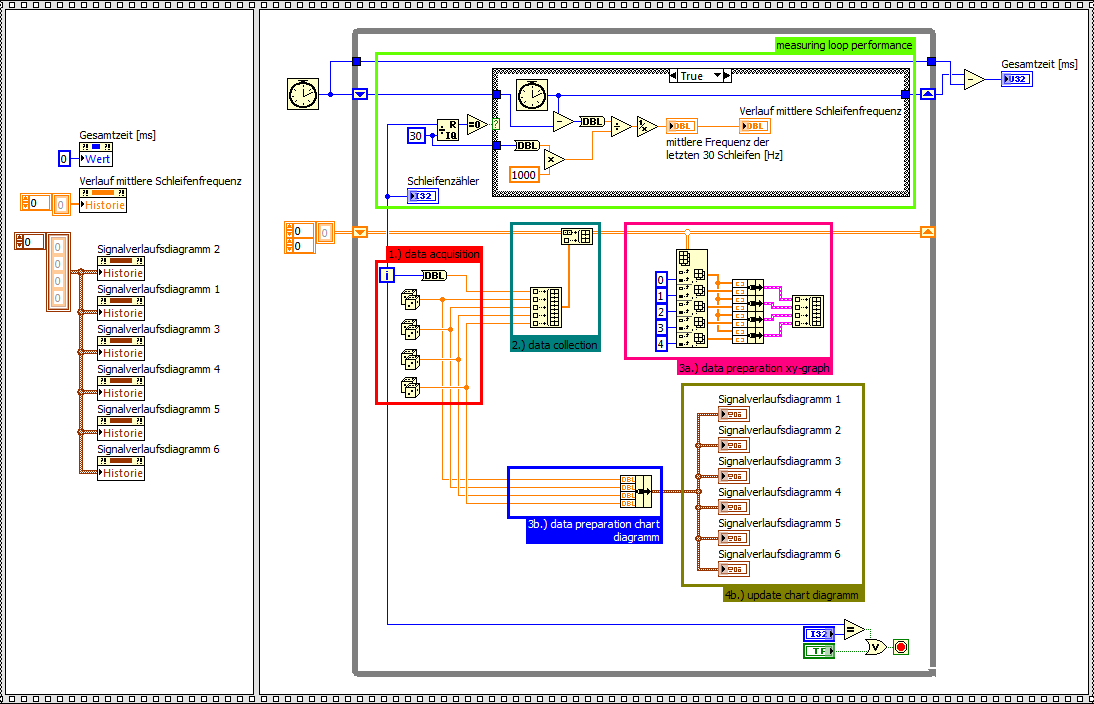
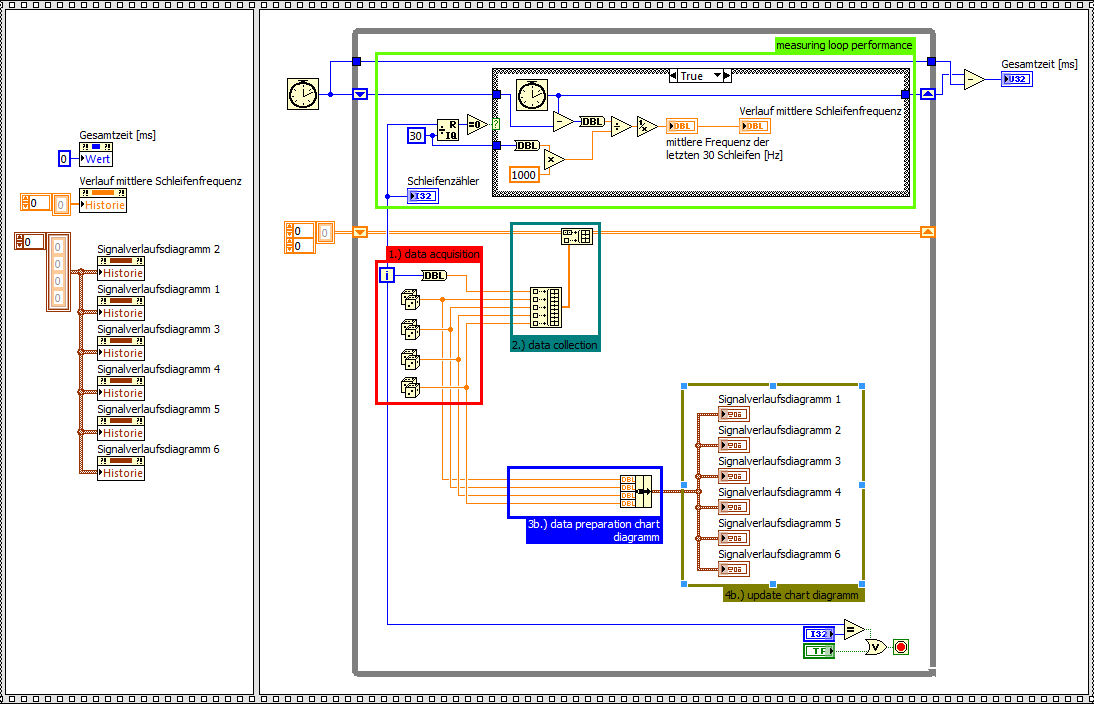
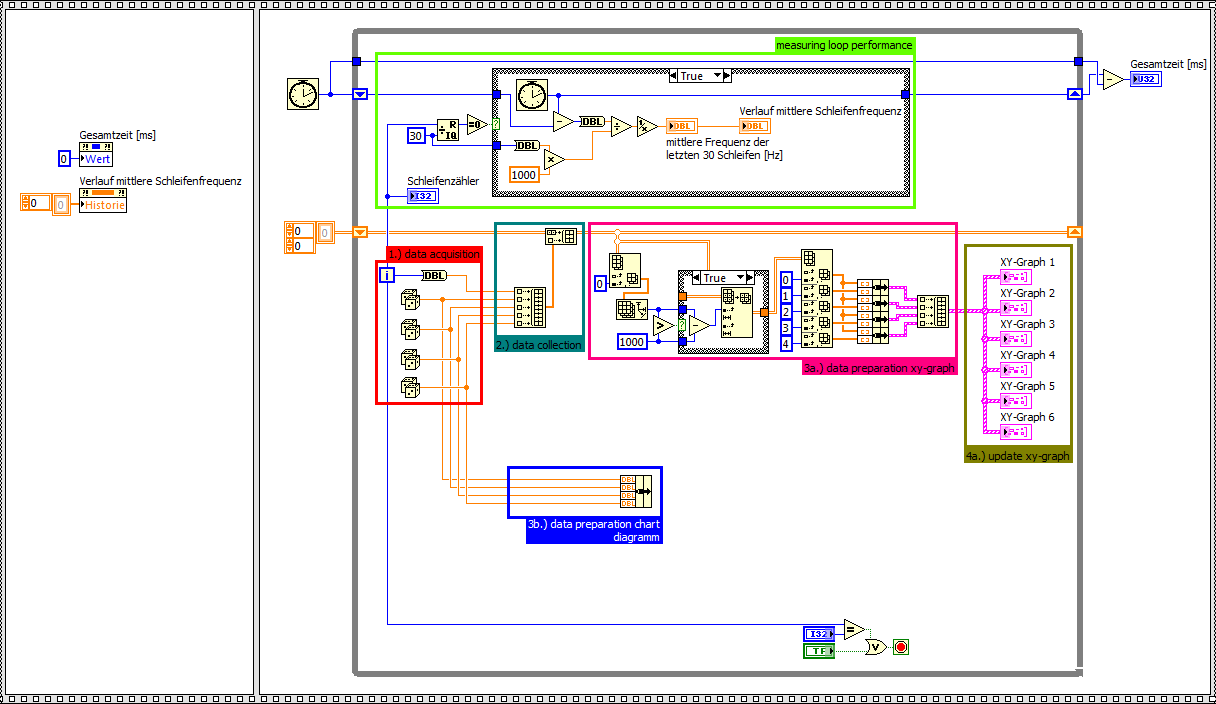
How to increase the performance of xy-graph
Hello
I'm running a continuous collection of data with a NI PCI 6133 (4 x channel HAVE @ 2, 5MS/s each) on a WIN 7 PC (LabView FDS 2012). Inside a while loop I'm able to acquire 2000 samples per loop for each channel with a stable performance loop of about 1, 25 kHz. Out of these data, I'm 24 calculation values that will be shown on 6 xy-graphs (4 values on each chart). Data acquisition runs up to 2 minutes.
Preparation of data and setting xy-graphs updated seems to be a big bottleneck. For this I wrote a simple point of interest, by comparing the xy-graph and table diagram performance clearify. For the same amount of data, the chart table is about 3 times faster, according to the ability to draw only the last value again. The xy-graph must update the whole plot of each iteration.
If I also remove the preparation of complex data of the xy-chart, the chart diagram is up to 6 times faster.
Landmark xy-graph
Diagram graph of reference (including the preparation of data for chart xy)
Benchmark graph diagram (without preparation of data for chart xy)
Questions
-Are there a way to optimize the data part of preparation of the xy-graph?
-Is it possible to draw only the last value again in a xy chart as a graphic diagram?
Why can I not use a graphic diagram?
-Because the time base is not constant.
My ideas:
(1.) during measurement, I use a graphical diagram. I know that there will be some failure according to the variable time base. After the acquisition of the acquired data will be shown in xy-graphs (as an only necessary update) with the good time base.
2.), I show all the data in a xy chart. Maybe just values the last 1000 would be sufficient.
XY-graph with simply display the last 1000 values of reference
Are there other ideas how to speed up xy-graphs?
Thank you very much and best regards,
Michael
MichaGue_01 wrote:
Why can I not use a graphic diagram?
-Because the time base is not constant.
This does not mean that you cannot use a chart. You should read my injurywaveform charts nugget. As long as you acquire your DAQmx device signals, you can wire all your signals directly in the table and it will load the time base.
-
GLPURGE, Archives of GL and purging what tables remove?
I need to know how the process of 'GL Archive and Purge' works when the purge of the records in the GL tables. Also delete the data permanently deleted the GL tables, does perform any other action on the tables or the data?
I don't think so, apart from the logic to delete the data in tables, it could also be updated for the other columns that will miss us, if we use explicitly remove commands. In addition Oracle does not directly support update or delete data from base tables, you can check raising a SR.
-
I'm running 4.2.1 apex and move an application from one computer to another, since I couldn't find a way to export with all necessary tabels for this, I create sql scripts each.
Check the results in the workshop-> tabels-> sql Object Explorer I get these results:
CREATE TABLE "SAMPLE"
( "ID" NUMBER,
"NAME" VARCHAR2(255),
"SAMP_ID" NUMBER NOT NULL ENABLE,
"SAMP_FRONT_IMAGE" BLOB,
"SAMP_BACKWARD_IMAGE" BLOB,
PRIMARY KEY ("ID") ENABLE
)
/
ALTER TABLE "SAMPLE" ADD CONSTRAINT "SAMPLE_CON" FOREIGN KEY ("SAMPLE_ID")
REFERENCES "SAMP" ("ID") ENABLE
/CREATE UNIQUE INDEX "SYS_IL0000031445C00004$$" ON "SAMPLE" (
/CREATE UNIQUE INDEX "SYS_IL0000031445C00005$$" ON "SAMPLE" (
/CREATE OR REPLACE TRIGGER "SAMPLE_T1"
BEFORE
insert on "SAMPLE"
for each row
begin
if :NEW.id is null then
select SAMPLE_SEQ.nextval into :NEW.id from dual;
end if;
end;
/
ALTER TRIGGER "SAMPLE_T1" ENABLE
/Notice the line "CREATE a UNIQUE INDEX ' SYS_IL0000031445C00005$ $' ON 'CARD_TYPE'", which not only duplicates but shouldn't be there at all.
So, how to edit them? Also, can anyone suggest why they are there in the first place, that I take all the code of the original project and it doesn't have these lines?
Hello
First of all, if you want the tables on the new computer, then you will need to export the schema database (not only the apex application) on which your application is analyzed. To export the database schema use the utility "expdp" of oracle database. This will create the dumpfile that must be imported on the new computer (or I would say that the data base). A DBA can help you do it if you don't know about it.
Unique indexes might appear due to BLOB fields in your table. I'm guessing that oracle db creates a unique index for each BLOB and, possibly, fields in a CLOB table. Since your table contains 2 BLOB fields, two unique indexes are appearing. I see too many these type sql indexes in my tables with BLOB fields. We don't need to create them. The Oracle Apex sql gives also to these indices is actually incomplete.
My suggestion to export the tables is perform a dump of the schema of the application using "expdp' analysis and import it using"impdp"on the new database. It is not only import tables but also triggers, packages, procedures, functions and all other objects in the schema of your db.
Contributes to hope
Concerning
Marie Laure
-
Hi people. IM new here. Need to accelerate a clarification on the table!
We have a scheme of production with 200 ~ tables in my body and I feel the performance of important queries in reports can be increased up to with the approach below.
Current settings - movement of the line is disabled for all tables.
What I can,
(1) to activate the movement of the line with "change the movement line of table_name enable;" ~ This allows the rows in the table to move dynamically remove the unused blocks.
(2) remove the unused blocks with "alter table table_name retractable space;"
(3) turn off the movement of the line with "modify the movement table table_name disable;"line ~ this will stop allowing the lines in the table move dynamically.
If I do, I get free unused blocks or removed making the table to perform at least a little more fast?
Will there be an impact elsewhere?
PS - It was never tried before by someone else in our scheme of production.
See you soon,.
Rachida.
India.
Use the Segment space Advisor to see what are the tables could benefit from a SHRINK
Hemant K Collette
-
vCenter Web Client 6.0 U1B - users cannot see VM performance data.
Our 6.0.0 U1b vCenter server and a Windows Server 2012.
My problem is, the VM admins have access to their virtual machines, but when they go to look at the tables of performance they get the message...
"Authorization to perform this operation was denied.
"You do not privilege" system > read "on the server vcenter-name folder.
They have the ability to turn their VM and they appear in their list.
Any ideas?
Thank you
It seems that the solution is yet to grant that the world of reading only the vCenter server access...
VMware KB: Cannot display the advanced performance of VMware vCenter Server 6.0 data tables
Runt...
We did not have this problem in the thick Client!
-
What is the best way to clear a table? (performance and resources)
Array.Length = 0;
array = [];array.splice(0);Array.Length = 0;
-
Performance tests: bind variables
When you write a SQL for the application, I want to do some performance testing of SQL before providing to JAVA developers. I understand that I need to test using bind variables, can someone guide me how do? What are the best tools out there to achieve? Please provide some guidance. Thank you!Rinne says:
I read more about bind variable and I can test the use of bind variables. I understand that testing SQL using bind variables is a closer representation of the real world. Even when queries have large tables, the performance would be similar if I run the query using literals twice (to avoid hard analysis) compared to tests with bind variables? I am trying to understand more thoroughly the need for tests with bind variables. Why we take more time than the other? Thank you!The main thing is that the opimizer will / can do if bind variables different optimization techniques are used or not.
There are two contradictory effects its regarding the binding settings.Effect 1: Reuse of cursor
If the same is done again and again and again. Maybe different sessions. Then using binding settings is essential. Why? Because the same cursor can be reused, which saves a lot of time for analysis. This occurs mainly in OLTP systems. The idea behind this is that to do the same action, just for a different ID (ID in order for example) will result in an identical implementation plan.The result: Faster analysis time and less consumption of memory, because the same cursor can be resused between different sessions.
Effect 2: Correct assumptions
According to a filter expression, some using the value of the OBC will make an assumption based on statistical data the number of rows is returned because of this expression and the value.
Speculation between a literal value and a bound value may be different. In many cases exist technical opimization (bind peeking etc.) to the same literal conjecture binded proposal.But there are exceptions, for example a condition such as the following will result in different estimates
column between 10 and 20column between :P1 and :P2There are as well other effects.
Result: The CBO can make assumptions better if literals. But most of the cases the proposal is identical.
Conclusion: Literal values are useful if you do large queries where the output size depends strongly on the parameters provided, and where you run that very few of these (OLAP) queries.
Binding settings are usfull when the same execution (OLTP) need a grand plan number of queries. -
What kind of difference in performance cuda and image first?
I'm torn between spending $1. 5 k and 2 k $ on a new macbook because the 15 inches we have a 650 m and i7, but is more expencive. Currently, I run a Bestial system and want something for a mobile platform for more casual projects. How much of a performance gain I actually would get with cuda and a quad core vs dual core i5?
Many discussions like this in the Sub-forum of material http://forums.adobe.com/community/premiere/hardware_forum?view=discussions
Lots of good links, with a few tables of performance at http://ppbm7.com/index.php/tweakers-page
Bottom line... fast CPU and Cuda MAKE make a difference, as well as 2 or more hard drives (or SSD + HDD 7200 RPM) especially for the edition of HiDef
-
divide the table based on the number of lines
Hello
I am trying to split a table based on the number of lines and then treat.
Say I have a TEST_XXX table that contains 50 lines, what I would do is.
to access multiple lines of 10. How can we achieve this?
What I thought is, once the table is created and the line are filled.
Add a new column to the table and perform a procedure that inserts of 1 to 10 first lines
and 2 to 10 lines and 3 to 10 next ranks... etc. Based on this, that we can treat
the first set of lines then play next or etc...
is there a better way to do it?
Code to create the table:
Code to add lines:CREATE TABLE TEST_XXX ( A_ID VARCHAR2(10), B_ID NUMBER, c_ID VARCHAR2(10), D_ID NUMBER )
The original problem is, I have a huge table, and I write a sql query to process,DECLARE BEGIN FOR I IN 1..50 LOOP INSERT INTO TEST_XXX VALUES('ABCDE',123,'ZYXWV',321); END LOOP; COMMIT; END;
When I treat him by selecting all the values in the table, it is very slow.
But when I have treat small Coulon (say 100 rows), it works very well.
That's how I got the approach described above in mind.You can use NTILE.
See:
http://download.Oracle.com/docs/CD/B19306_01/server.102/b14200/functions101.htm#SQLRF00680
http://asktom.Oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:47910227585839 -
How to insert values into a table
Hello Experts,
I would like to know if its possible to fill data in one table by performing a loop.
I have the following table:
Draw)
NUMBER OF NUM,
START_DATE DATE NOT NULL,
END_DATE DATE NOT NULL,
CHAR DEFAULT ACTIVE (1 BYTE) 'Y')
Now my table must contain the foll:
NUM start_date end_date active
1 2010-01-23 21:00 30/01/2010 19:00 Y
2 2010-01-30 21:00 02/06/2010 19:00 Y
I have an initial date and the end_date is always (start_date + 7) and the beginning of the next by the previous end_date but time varies from 19:00 to 21:00.
This is what I have at the moment, but I'm stuck out of
but I'm kind of stuck a bit for the dateCREATE SEQUENCE num_seq MINVALUE 1 START WITH 1 INCREMENT BY 1 CACHE 10 CREATE OR REPLACE procedure draw_date IS begin INSERT INTO draws (num, start_date , end_date, active ) VALUES (num_seq.nextval, ?, ?+7 days, Y); COMMIT; end;
Thank youHello
You can try something like:
INSERT INTO draws (num, start_date, end_date, active) with last_date as (select trunc(max(end_date)) dt from draws) select num_seq.nextval, last_date.dt + 21/24, last_date.dt +7 +19/24, 'Y' from last_date; COMMIT;Untested code because I don't have the create table and insert orders... and I'm feeling lazy today.
;)
Maybe you are looking for
-
Two updates of Boot Camp several times offered in Apple Software Update (ASU)
On the Mac Pro 2013, did someone else repeatedly offered the (1) "graphics Driver Update for Boot Camp" (version 6.0) - 339 MB and then the (2) "Apple Boot Camp Update" (also v6.0) - 265 MB? It's a Mac of 2013 Pro Win 10 worm. 1511 running with an AM
-
Slow Mac after installation of El Capitan
After installing the OS El Capitan 10.11.13 my computer is very slow, I hear a noise hard drive and get the Bowl from the beach and several programs (mail, number, pages, etc. stop responding and I have to force quit them) I just use Time machine to
-
Help someone? I'm looking for a screen for my Pavilion DV8000 (Dv8336ea). In my view, the screen is it a brilliant WXGA + screen ultrabright view 2 lamps 1440 x 900 17 inch widecreen. They are available on Ebay etc, but not with 2 lamps. I rang HP pa
-
HP officejet 6600: Officejet 6600 how to re - attach the scanner cover
the plastic pins came out the slots and the elastic metal hinge is born that way, how can I re - join them?
-
Windows Easy Transfer, 32-bit to 64-bit
I plan on using Windows Easy Transfer 7 to keep my files when I upgrade to 7. I think also the upgrade to 64-bit (I checked and my computer is capable). My question is, on the Page about the program, he said that the files can be moved from 64 bit to