the date of consolidation extends using analytic functions
I am trying to establish how long a person was in a situation the data looks like thisperson Locator recorded_date
--------------------------------------------------------
01/01/2012 10:10 LOC_A PERSON_X
03/01/2012 PERSON_X LOC_A 15:10
04/01/2012 PERSON_X LOC_B 02:00
05/01/2012 PERSON_X LOC_B 11:10
06/01/2012 PERSON_X LOC_A 03:10
What I want in the output. I want to divide it into 3 bays. What do I get with min and rank is a grouping of the last loc_a with the first that goes on the average time they were in a different location.
Start anyone to date date stop
-----------------------------------------------------------------------------------
01/01/2012 10:10 01/04/2012 PERSON_X LOC_A 02:00
04/01/2012 02:00 06/01/2012 PERSON_X LOC_B 03:10
06/01/2012 PERSON_X LOC_A 03:10
Hello
DanU says:
Thanks Frank! This was extremely helpful. I probably get the final stages. The only piece I am missing is having the end defined by the following date recorded date. So I might try your query with the lead function.
Sorry, I don't have the sense of end_date.
You're right; all you need is the analytical function of LEAD to get:
WITH got_grp AS
(
SELECT recorded_date, cqm_category, pat_acct_num
, ROW_NUMBER () OVER ( PARTITION BY pat_acct_num
ORDER BY recorded_date
)
- ROW_NUMBER () OVER ( PARTITION BY pat_acct_num
, cqm_category
ORDER BY recorded_date
) AS grp
FROM export_table
)
SELECT MIN (recorded_date) AS start_date
, LEAD (MIN (recorded_date)) OVER ( PARTITION BY pat_acct_num
ORDER BY MIN (recorded_date)
) AS stop_date
, cqm_category
, pat_acct_num
FROM got_grp
GROUP BY pat_acct_num, cqm_category, grp
ORDER BY pat_acct_num, start_date
;
It's almost the same query as what I posted before.
Apart from substituting your new table and column names, the only change I made was how stop_date is defined in the main query.
Tags: Database
Similar Questions
-
date ranges - possible to use analytical functions?
The following datastructure must be converted into a daterange datastructure.
Working solution:START_DATE END_DATE AMMOUNT ---------- ---------- ---------- 01-01-2010 28-02-2010 10 01-02-2010 31-03-2010 20 01-03-2010 31-05-2010 30 01-09-2010 31-12-2010 40
Output:with date_ranges as ( select to_date('01-01-2010','dd-mm-yyyy') start_date , to_date('28-02-2010','dd-mm-yyyy') end_date , 10 ammount from dual union all select to_date('01-02-2010','dd-mm-yyyy') start_date , to_date('31-03-2010','dd-mm-yyyy') end_date , 20 ammount from dual union all select to_date('01-03-2010','dd-mm-yyyy') start_date , to_date('31-05-2010','dd-mm-yyyy') end_date , 30 ammount from dual union all select to_date('01-09-2010','dd-mm-yyyy') start_date , to_date('31-12-2010','dd-mm-yyyy') end_date , 40 ammount from dual ) select rne.start_date , lead (rne.start_date-1,1) over (order by rne.start_date) end_date , ( select sum(dre2.ammount) from date_ranges dre2 where rne.start_date >= dre2.start_date and rne.start_date <= dre2.end_date ) range_ammount from ( select dre.start_date from date_ranges dre union -- implicit distinct select dre.end_date + 1 from date_ranges dre ) rne order by rne.start_date /
However, I would like to use an analytical function to calculate the range_ammount. Is this possible?START_DATE END_DATE RANGE_AMMOUNT ---------- ---------- ------------- 01-01-2010 31-01-2010 10 01-02-2010 28-02-2010 30 01-03-2010 31-03-2010 50 01-04-2010 31-05-2010 30 01-06-2010 31-08-2010 01-09-2010 31-12-2010 40 01-01-2011 7 rows selected.
Published by: user5909557 on July 29, 2010 06:19Hello
Welcome to the forum!
Yes, you can replace the scalar sub-queriy with a SUMMARY, like this:
WITH change_data AS ( SELECT start_date AS change_date , ammount AS net_amount FROM date_ranges -- UNION -- SELECT end_date + 1 AS change_date , -ammount AS net_amount FROM date_ranges ) , got_range_amount AS ( SELECT change_date AS start_date , LEAD (change_date) OVER (ORDER BY change_date) - 1 AS end_date , SUM (net_amount) OVER (ORDER BY change_date) AS range_amount FROM change_data ) , got_grp AS ( SELECT start_date , end_date , range_amount , ROW_NUMBER () OVER ( ORDER BY start_date, end_date) - ROW_NUMBER () OVER ( PARTITION BY range_amount ORDER BY start_date, end_date ) AS grp FROM got_range_amount ) SELECT MIN (start_date) AS start_date , MAX (end_date) AS end_date , range_amount FROM got_grp GROUP BY grp , range_amount ORDER BY grp ;This should be much more effective.
The code is longer than what you posted. It is largely because it includes consecutive groups with the same amount.
For example, if you add this line the sample data:-- union all select to_date('02-01-2010','dd-mm-yyyy') start_date , to_date('30-12-2010','dd-mm-yyyy') end_date , 0 ammount from dualThe query that you posted the product:
START_DAT END_DATE RANGE_AMMOUNT --------- --------- ------------- 01-JAN-10 01-JAN-10 10 02-JAN-10 31-JAN-10 10 01-FEB-10 28-FEB-10 30 01-MAR-10 31-MAR-10 50 01-APR-10 31-MAY-10 30 01-JUN-10 31-AUG-10 0 01-SEP-10 30-DEC-10 40 31-DEC-10 31-DEC-10 40 01-JAN-11I suppose you want only a new production line where the changes of range_amount., it is:
START_DAT END_DATE RANGE_AMOUNT --------- --------- ------------ 01-JAN-10 31-JAN-10 10 01-FEB-10 28-FEB-10 30 01-MAR-10 31-MAR-10 50 01-APR-10 31-MAY-10 30 01-JUN-10 31-AUG-10 0 01-SEP-10 31-DEC-10 40 01-JAN-11 0Of course, you can change the original query so that it did, but it would eventually just as complex as the above query, but less effective.
Conversely, if you prefer the longer output, then you need not got_grp Tahina-query in the above query.Thanks for posting the CREATE TABLE and INSERT statements; It is very useful.
There are people who use this forum for years and have yet to be begged to do. -
Cannot use analytical functions such as lag/lead in odi components 12 c except in the expression
Hi I am a beginner of ODI 12 c
I'm trying to get the last two comments made on the product for a given product id. and load them into a target.
I have a source table something like
Product SR_NO comments LAST_UPDATED_TS
1 good car 2015/05/15 08:30:25
1 car average 2015/05/15 10:30:25
Jeep 2 super 2015/05/15 11:30:25
1 car bad 2015/05/15 11:30:25
Jeep 2 horrible 2015/05/15 09:30:25
Jeep 2 excellent 2015/05/15 12:30:25
I want a target table based on their last timestamp updated as (last two comments)
SR_NO Comment1 Comment2
1 bad average
2 super excellent
I used the logic below to get records in SQL Developer but in ODI 12 c, I'm not able to do this by mapping a source to the target table by applying analytical functions to the columns in the target table. Can someone help me solve this problem
SELECT * FROM)
SELECT SR_NO Comment1, LAG(Comment1,1,) ON Comment2 (SR_NO ORDER BY LAST_UPDATED_TS ASC PARTITION),
ROW_NUMBER() ON RN (SCORE FROM SR_NO ORDER BY LAST_UPDATED_TS DESC)
FROM Source_table
) M
WHERE RN = 1
;
UM, I'm afraid that ODI puts the filter too early in the request, if it generates:
SELECT * FROM)
SELECT SR_NO Comment1, LAG(Comment1,1,) ON Comment2 (SR_NO ORDER BY LAST_UPDATED_TS ASC PARTITION),
ROW_NUMBER() ON RN (SCORE FROM SR_NO ORDER BY LAST_UPDATED_TS DESC)
FROM Source_table
WHERE RN = 1
) M
;
Instead of:
SELECT * FROM)
SELECT SR_NO Comment1, LAG(Comment1,1,) ON Comment2 (SR_NO ORDER BY LAST_UPDATED_TS ASC PARTITION),
ROW_NUMBER() ON RN (SCORE FROM SR_NO ORDER BY LAST_UPDATED_TS DESC)
FROM Source_table
) M
WHERE RN = 1
;
Even by changing the 'run on Hint"of your component of the expression to get there on the source, the request will stay the same.
I think the easiest solution for you is to put everything before the filter in a reusable mapping with a signature of output. Then drag this reusable in your mapping as the new source and check the box "subselect enabled."
Your final mapping should look like this:

It will be useful.
Kind regards
JeromeFr
-
Need help to resolve the query by using analytic functions
Hello
I need help to solve this problem, I tried an analytical function but could not solve the problem.
I have three table as illustrated below the table is filled with a flat file. The records are arranged sequentailly based on the name of the file.
The first record of the game based on EIN goes to TAB_RCE
the following records then goes to TAB_RCW
and last save of the game based on EIN goes to the RCT table
How can I make groups and
assign a
EIN * 12345 * line number * 02, 03, 04 * in the table TAB_RCW and * 05 * in the table TAB_RCT
EIN * 67890 * line number * 07, 08, 09,10 * in the table TAB_RCW and * 11 * in the table TAB_RCT
and so on...
Thank you
Rajesh
TAB RCE_--------------------------------------------------------------
LineNumber EIN FILENAME TYPE
-----
01 12345 ABC NCE. TXT
06 67890 ABC NCE. TXT
12 76777 ABC NCE. TXT
-----
TAB_RCW
-----
LineNumber TYPE SSN FILENAME
-----
02 22222 ABC RCW. TXT
03 33333 ABC RCW. TXT
04 44444 ABC RCW. TXT
07 55555 ABC RCW. TXT
08 66666 ABC RCW. TXT
09 77777 ABC RCW. TXT
10 88888 ABC RCW. TXT
13 99998 ABC RCW. TXT
14 99999 ABC RCW. TXT
-----
TAB_RCT
-----
NAME OF THE FILE OF TYPE LINENUMBER
-----
RCT 05 ABC. TXT
RCT 11 ABC. TXT
RCT 15 ABC. TXT
-----SQL> with TAB_RCE as ( 2 select 'RCE' rtype,'01' linenumber, '12345' EIN,'ABC.TXT' FILENAME from dual union all 3 select 'RCE','06','67890','ABC.TXT' from dual union all 4 select 'RCE','12','76777','ABC.TXT' from dual 5 ), 6 TAB_RCW as ( 7 select 'RCW' rtype,'02' linenumber,'22222' ssn,'ABC.TXT' FILENAME from dual union all 8 select 'RCW','03','33333','ABC.TXT' from dual union all 9 select 'RCW','04','44444','ABC.TXT' from dual union all 10 select 'RCW','07','55555','ABC.TXT' from dual union all 11 select 'RCW','08','66666','ABC.TXT' from dual union all 12 select 'RCW','09','77777','ABC.TXT' from dual union all 13 select 'RCW','10','88888','ABC.TXT' from dual union all 14 select 'RCW','13','99998','ABC.TXT' from dual union all 15 select 'RCW','14','99999','ABC.TXT' from dual 16 ), 17 TAB_RCT as ( 18 select 'RCT' rtype,'05' linenumber,'ABC.TXT' FILENAME from dual union all 19 select 'RCT','11','ABC.TXT' from dual union all 20 select 'RCT','15','ABC.TXT' from dual 21 ) 22 select rtype, 23 last_value(ein ignore nulls) over(partition by filename order by linenumber) ein, 24 linenumber, 25 ssn 26 from ( 27 select rtype, 28 linenumber, 29 ein, 30 to_char(null) ssn, 31 filename 32 from TAB_RCE 33 union all 34 select rtype, 35 linenumber, 36 to_char(null) ein, 37 ssn, 38 filename 39 from TAB_RCW 40 union all 41 select rtype, 42 linenumber, 43 to_char(null) ein, 44 to_char(null) ssn, 45 filename 46 from TAB_RCt 47 ) 48 order by linenumber 49 / RTY EIN LI SSN --- ----- -- ----- RCE 12345 01 RCW 12345 02 22222 RCW 12345 03 33333 RCW 12345 04 44444 RCT 12345 05 RCE 67890 06 RCW 67890 07 55555 RCW 67890 08 66666 RCW 67890 09 77777 RCW 67890 10 88888 RCT 67890 11 RTY EIN LI SSN --- ----- -- ----- RCE 76777 12 RCW 76777 13 99998 RCW 76777 14 99999 RCT 76777 15 15 rows selected. SQL>SY.
-
Change the way the date is displayed by using a formula
I have a standard date field in the format: dd/mm/yyyy
What I want to do is to use a formula to display "dd", is there an easy way to do this?
Thank you.You can use DAYOFMONTH (
>) function -
Merge no SQL using analytical functions
Hi, the Sql tuning specialists:
I have a question about the merger of view inline.
I have a simple vision with the analytical functions inside. When questioning him, he does not index.
VIEW to CREATE or REPLACE ttt
AS
SELECT EmpNo, deptno,
ROW_NUMBER() over (PARTITION BY deptno ORDER BY deptno desc NULLS last) part_seq
EMP AAA
-That will do full table for emp scan
Select * from TT
WHERE empno = 7369
-If I do not view use, I use the query directly, the index is used
SELECT EmpNo, deptno,
ROW_NUMBER() over (PARTITION BY deptno ORDER BY deptno desc NULLS last) part_seq
EMP aaa
WHERE empno = 7369
question is: How can I force the first query to use indexes?
Thank youMScallion wrote:
What happens if you use the push_pred flag:Nothing will happen. And it would be a bug if he would.
select * from ttt WHERE empno=7369and
SELECT empno,deptno, row_number() OVER (PARTITION BY deptno ORDER BY deptno desc NULLS last) part_seq FROM emp aaa WHERE empno=7369are two logically different queries. Analytical functions are applied after + * resultset is common. So first select query all rows in the emp table then assign ROW_NUMBER() to recovered lines and only then select a line with empno = 7369 her. Second query will select the table emp with empno = 7369 line and only then apply ROW_NUMBER() - so since emp.empno is unique ROW_NUMBER returned by second query will always be equal to 1:
SQL> select * from ttt 2 WHERE empno=7369 3 / EMPNO DEPTNO PART_SEQ ---------- ---------- ---------- 7369 20 4 SQL> SELECT empno,deptno, 2 row_number() OVER (PARTITION BY deptno ORDER BY deptno desc NULLS last) part_seq 3 FROM emp aaa 4 WHERE empno=7369 5 / EMPNO DEPTNO PART_SEQ ---------- ---------- ---------- 7369 20 1 SQL>SY.
-
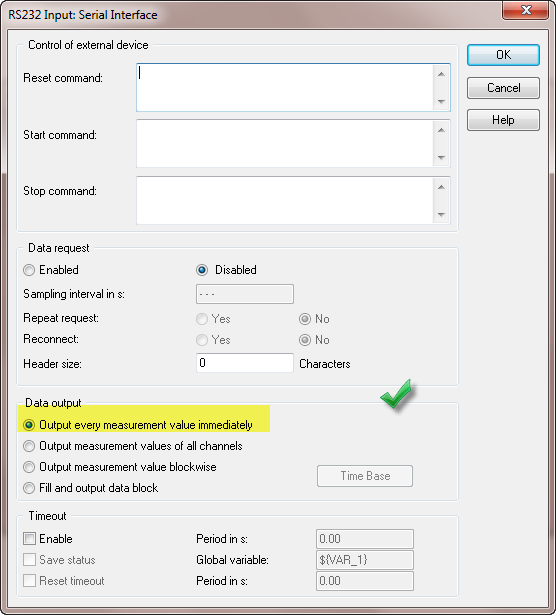
I can collect data from a hygrometer in a text file using the RS232 port with the following T75.2F:H17.0% format, these data are collected using a data logger software. I was wondering if I can collect this data for later analysis using Dasylab. Any help is appreciated.
The setting below causes the error. Change for the second selection, output values of all channels.
-
How can I get the Date of birth, I used on my Email
I need to know how to find the Date of birth, which I used on my WLID
Hello
Go here and scroll down to and click on connect to Account Services - then connect and you will see the
setting including your Date of birth.Windows Live ID
https://accountservices.passport.NET/ppnetworkhome.SRF?VV=1200&mkt=en-us&LC=1033For more help with Windows Live please use their support and the forums.
Windows Live Solution Center - accounts and passwords - Windows Live ID
http://www.windowslivehelp.com/I hope this helps and happy holidays!
Rob Brown - Microsoft MVP<- profile="" -="" windows="" expert="" -="" consumer="" :="" bicycle=""><- mark="" twain="" said="" it="">
-
Why I see my data in the data pane when you use a newly created schema?
I am trying to learn Oracle DB at home. I installed Oracle DB Express 11.2 and Developer SQL 4.0.3. I can connect to the database, the communication between SQL and Oracle DB Express Developer works well.
It is probably a problem with Oracle database, but since I see it in SQL Developer, I'll ask it anyway.
If I log in the HR demo schema (in line with the developer of 2 days) and create a new table called OFFICERS with some fictional characters for the data and populate it with the data through the data for HR pane. AGENTS, I can see in the table of retail Developer SQL tab of the component data. I see the column headings for the columns I've created on the top, then the line numbers for each line that I created and the data in each row.
Now I have created my own personal schema, for example MYNAME and then connected to this schema and tried to repeat the above process. I can create the table with the columns by using the new table Wizard. But once the table exists, and I go to the tab of the Panel data on the detail of the Table, I see nothing. No column header. When I hit the insert a row button in the tab of the component data, I see a marker + 1 appear, but I have nothing to click to enter data as I did with HR. OFFICERS.
Now, if I go to the SQL worksheet for embarrassing MYNAME schema and make some INSERTs, COMMIT and a query, for example
INSERT INTO VALUES OFFICERS ('Captain', 'Smith', 'Samuel');
INSERT INTO VALUES OFFICERS ("Corvette", "Jones", "Robert");
COMMIT WORK;
SELECT * FROM PERSONS;In the query result window, I get:
RANK NAME
-------------------- ----- ------
The Captain Smith Samuel
Lieutenant-Commander Robert JonesBut if I go to the Details tab of the Table to MYNAME. OFFICERS and look at the component data, all I see is two numbers 1 and 2. No column header and no data. Just the number of rows.
Why I see data in the pane the HR data. Table tab detail OFFICERS, but I do not see the headers of column or data in the USERNAME data pane. AGENTS? I can see fine columns in the columns pane, but not data in the data pane.
I looked at all the privileges that I know look, and MYNAME has at least the same privileges as HR. Any thoughts?
Thank you in advance.
Periods are used to separate components of object names so that they are not valid in the names.
for example
Schema.table
table. Column
Schema.table.Column
Package.PROCEDURE
Syntax rules for identifiers are in the http://docs.oracle.com/cd/E11882_01/server.112/e41084/sql_elements008.htm#SQLRF00223 SQL language reference manual
-
Defining the new path for the data files for restoring using the VALUE of NEWNAME FOR DATABASE
Version: 11.2.0.3 Linux
Today, I had to do a restore RMAN to a new server and I came across the post following RTO on the VALUE of NEWNAME FOR DATABASE
ALTER database open resetlogs upgraded; error to throw
So, I thought to use it to indicate the new location of the data files to restore.
That's what I did
===================
Restore the control file and catalog items to backup using the command of CATALOGUE START WITH. Then I started the restoration
Don't know how it worked for Levi without %f or %U. So, I added %f$ rman target / cmdfile=restore.txt Recovery Manager: Release 11.2.0.3.0 - Production on Thu Jul 26 04:40:41 2012 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: SPIKEY (DBID=2576163333, not open) RMAN> run 2> { 3> SET NEWNAME FOR DATABASE TO '/fnup/hwrc/oradata/spikey'; 4> restore database ; 5> } 6> 7> 8> executing command: SET NEWNAME RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of set command at 07/26/2012 04:40:43 RMAN-06970: NEWNAME '/fnup/hwrc/oradata/spikey' for database must include %f or %U format Recovery Manager complete.
As you can see, RMAN restore data files to the desired location. But the data file names ended up as$ vi restore.txt $ cat restore.txt run { SET NEWNAME FOR DATABASE TO '/fnup/hwrc/oradata/spikey/%f'; restore database ; } $ rman target / cmdfile=restore.txt Recovery Manager: Release 11.2.0.3.0 - Production on Thu Jul 26 04:45:45 2012 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: SPIKEY (DBID=2576163333, not open) RMAN> run 2> { 3> SET NEWNAME FOR DATABASE TO '/fnup/hwrc/oradata/spikey/%f'; 4> restore database ; 5> } 6> 7> 8> executing command: SET NEWNAME Starting restore at 26-JUL-12 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=19 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00001 to /fnup/hwrc/oradata/spikey/1 channel ORA_DISK_1: restoring datafile 00002 to /fnup/hwrc/oradata/spikey/2 channel ORA_DISK_1: restoring datafile 00003 to /fnup/hwrc/oradata/spikey/3 channel ORA_DISK_1: restoring datafile 00004 to /fnup/hwrc/oradata/spikey/4 channel ORA_DISK_1: restoring datafile 00005 to /fnup/hwrc/oradata/spikey/5 channel ORA_DISK_1: restoring datafile 00006 to /fnup/hwrc/oradata/spikey/6 channel ORA_DISK_1: restoring datafile 00007 to /fnup/hwrc/oradata/spikey/7 channel ORA_DISK_1: restoring datafile 00008 to /fnup/hwrc/oradata/spikey/8 channel ORA_DISK_1: restoring datafile 00009 to /fnup/hwrc/oradata/spikey/9 channel ORA_DISK_1: reading from backup piece /u07/bkpfolder/SPIKEY_full_01nh0028_1_1_20120725.rmbk channel ORA_DISK_1: errors found reading piece handle=/u07/bkpfolder/SPIKEY_full_01nh0028_1_1_20120725.rmbk channel ORA_DISK_1: failover to piece handle=/u07/dump/bkpfolder/SPIKEY_full_01nh0028_1_1_20120725.rmbk tag=SPIKEY_FULL channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:01:56 Finished restore at 26-JUL-12 Recovery Manager complete.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! -----------| Holy Cow |-----------------------------1 2 3 . . . 9
So I had to rename each file as below
I would have been better in execution of the order for each data below file$ mv 1 /fnup/hwrc/oradata/spikey/system01.dbf $ mv 2 /fnup/hwrc/oradata/spikey/sysaux01.dbf $ mv 3 /fnup/hwrc/oradata/spikey/undotbs01.dbf
Now, I think, there is no advantage in using NEWNAME SET of DATABASE to. Only the disadvantages. I did anything wrong above?SET NEWNAME FOR DATAFILEMartin;
On the issue of the VALUE of NEWNAME FOR DATABASE, you must specify at least one of the first three of the following substitution variables to avoid collisions of names: %b f % U. see semantic entry for TO 'filename' for a description of the possible substitution variables.
You use %f
%b Specifies the filename without the fully qualified directory path. For example, the datafile name /oradata/prod/financial.dbf is transformed to financial.dbf. This variable enables you to preserve the names of the datafiles while you move them to different directory. During backup, it can be used for the creation of image copies. The variable cannot be used for OMF datafiles or backup sets. %f Specifies the absolute file number of the datafile for which the new name is generated. For example, if datafile 2 is duplicated, then %f generates the value 2. %U Specifies a system-generated unique filename. The name is in the following format: data-D-%d_id-%I_TS-%N_FNO-%f. The %d variable specifies the database name. For example, a possible name might be data-D-prod_id-22398754_TS-users_FNO-7.Source - E10643-01
Backup and recovery reference
http://docs.Oracle.com/CD/E14072_01/backup.112/e10643/rcmsynta2014.htm
I see CKPT and I agree on that!
Best regards
mseberg
-
Date field to update using a function table
Hello
Have not been able to find something like that to give me an example where I'm wrong here.
(1) I have a table with a date field (table.created_date).
(2) I want to recover the date field of the table when it corresponds to a field of load_week. I created a function for this.
CREATE OR REPLACE FUNCTION ODUMGR. "" F_ODS_ET_HIST ".
(v_load_week varchar2)
DATE OF RETURN
AS
date of T_DATE;
BEGIN
Select trunc (max (load_date))
in T_DATE
of odu_course_enroll_all
where load_week = v_load_week
Load_week group;
RETURN T_DATE;
EXCEPTION
WHILE OTHERS
THEN RETURN ' ';
END F_ODS_ET_HIST;
/
(3) I have a field in another table, in that I want to put the date that I just received. The reception table has a field of type date.
If I try to do:
receiving_table update
Set receiving_table.date_field = ODUMGR. F_ODS_ET_HIST ("R08");
When this R08 is the load_week, I get the following error:
ORA-01847: day of the month must be between 1 and the last day of the month
ORA-06512: AT ODUMGR. Line 15 of the F_ODS_ET_HIST
ORA-01013: user has requested the cancellation of the current operation
I don't know why I'd get that, given that I put a date field Oracle in an another date field in an Oracle table.
Any ideas?
Thank you
VICThis works if you actually run the code in youe doc here :-)
/export/home/oracle> cat t.sh str='Hello World' sqlplus -s / <./t.sh Hello World Goodbye! PL/SQL procedure successfully completed. It takes a slash (/) on a line by itself after and before the release.
John
-
To access the data of a schema using the ftp adapter
Hi all
Here is an example of the data I receive from my ftp adapter, I read the entire file in my diagram:
< header >
< batch_filler1 > * LOT < / batch_filler1 >
< batch_number > 08110 < / batch_number >
< batch_date > 20090417 < / batch_date >
< batch_extra > KW1310 < / batch_extra >
< / header >
-< detail >
< cost_centre_comment > 1310 < / cost_centre_comment >
< cost_centre_code_comment > 01310 < / cost_centre_code_comment >
< amount > - 3000.00 < / amount >
< filler1 / >
< payment_method > T < / payment_method >
< description > TSHWANE MULTI SKILLS FEATURE ENTREPRENEURS < / description >
< receipt_number > 338516 < / receipt_number >
< date_comment > 20090417 < / date_comment >
< bill_to_cust_id > 11748885 < / bill_to_cust_id >
< ref_value > 999999 < / ref_value >
< detail_extra / >
* < / detail > *.
-< detail >
< cost_centre_comment > 1310 < / cost_centre_comment >
< cost_centre_code_comment > 01310 < / cost_centre_code_comment >
< amount > - 1870.00 < / amount >
< filler1 / >
< payment_method > T < / payment_method >
< description > UNIVERSITY OF SOUTH UNIVERSITY SOOUTH AF < / description >
< receipt_number > 338517 < / receipt_number >
< date_comment > 20090417 < / date_comment >
< bill_to_cust_id > 10414916 < / bill_to_cust_id >
< ref_value > 048630 < / ref_value >
< detail_extra / >
* < / detail > *.
-< detail >
< cost_centre_comment > 1310 < / cost_centre_comment >
< cost_centre_code_comment > 01310 < / cost_centre_code_comment >
< amount > - 300.00 < / amount >
< filler1 / >
< payment_method > T < / payment_method >
< description > VET & AGRIC CONSULTA RB JACKSON < / description >
< receipt_number > 338549 < / receipt_number >
< date_comment > 20090417 < / date_comment >
< bill_to_cust_id > 11462639 < / bill_to_cust_id >
< ref_value > 048893 < / ref_value >
< detail_extra / >
* < / detail > *.
-trailer >
< cost_centre > W801408014 < / cost_centre >
< amount > 18467.13 < / amount >
< trailer_extra > GROOTTOTAAL VIR W8014/8014 OP 20090417 BLONDEL 08110 08110 20090417 < / trailer_extra >
< / trailer >
As you can see I have several detaildata, I have to loop through my diagram for detail and values and pass it on. How do reference you a particular detail in bpel?
An example would be if I want the 2nd amount of detail which is - 300.00, I reference him with one [1] as in the tables?
Thank youIt depends on what you want to do. Usually what people do is the card to a partner link, for example another service. In most situations, the same structure is required for the target.
The processing activity is the best way to many nodes multi. You must choose it / if the conditions that allow to test conditions, if they match then you execute the plan.
One thing that draws people out is the use of the for each, if it is not specified that one line is mapped.
http://download-UK.Oracle.com/docs/CD/B31017_01/integrate.1013/b28987/Phase6.htm#sthref405
see you soon
James -
delay in reading the data when you are using multiple loops clocked on target RT
Hello
I have five loops clocked on a target of RT and I communicate to and from the host vi. All the loops of the value of the different priorities however when all running at the same time I found windows vi take up to 1 minute before reading the data. Four disabling loops to fix the problem. It is possible to start the app right after start windows vi?
Kind regards
Solved the problem by disabling variable autodeploy
Thank you
-
How to prioritize the query result using analytic functions
Hello
Published by: prakash on May 20, 2013 01:42Use ROW_NUMBER
SQL> select PRVDR_LCTN_X_SPCLTY_SID,PRVDR_LCTN_IID,PRVDR_TYPE_X_SPCLTY_SID,STATUS_CID 2 from 3 ( 4 select t.*, 5 row_number() over(partition by PRVDR_TYPE_X_SPCLTY_SID 6 order by STATUS_CID) rn 7 from your_table t 8 ) 9 where rn = 1; PRVDR_LCTN_X_SPCLTY_SID PRVDR_LCTN_IID PRVDR_TYPE_X_SPCLTY_SID STATUS_CID ----------------------- -------------- ----------------------- ---------- 75292110 10153920 75004770 1 75291888 10153920 75004884 2 75292112 10153920 75004916 1 75292117 10153920 75004974 1 -
The data of blackBerry Smartphones used per month
Does anyone know if there's a newspaper somewhere in the amount of data has been used and downloaded on the network? I have an 'unlimited' plan Orange in the United Kingdom but the implication says that this is limited to 250 MB per month. I wanted to check how much I use so I'm not on it.
For example in Verizon USA
You would call * 3282 or * DATA
However, it is dependent on the service provider. It's only for Verizon in the United States. If you do this on other networks, he'll probably tell that the call cannot be completed as compound or something similar.
You will need to call your provider and see if they offer something similar. Also check if there is a way, you can view it online.There is a third application of the part called Mini Moni
Web site: Mini Moni - Traffic monitor for BlackBerry
Download (office) http://www.ehnert.net/MiniMoni/MiniMoni.zip
Download (OTA) http://www.ehnert.NET/Minimoni/Minimoni.jad

Maybe you are looking for
-
How do computer viruses work?
-
My black cartridge will not print. I tried to change them. I can only print in color.
I have a HP Photosmart C6380 All In One and my black cartridges won't work (I tried changing them). I've done a clean print head but when I tried to align print heads, I get a message of failure align.
-
I would like to know if my power supply is supposed to become a real hot
whenever I charge my laptop my PSU becomes hot almost enough to where I can fry an egg on it, is supposed to get hot
-
I worked on it for about 3 days now. It's driving me crazy. I tried everything I could find to try to solve this problem. When installing iTunes it stops and a box will then appear to me said "there is a problem with this Windows Installer package. A
-
BlackBerry Z30 unlocked Blackberry Z30 in BB online store has 1700/2100 Mhz frequencies?
Hi friends: Fact unlocked Blackberry Z30 (GSM) in the BB online store has 1700/2100 Mhz frequencies? Thank you Ouyang Johnson