The FRA diskgroup separate for each prod database?
Hello
Env: Oracle 11 g 2 EE (11.2.0.3), 6.2 RHEL 64 bit
Storage: file system
Databses: ten databases on the PROD and 20 on the DEV
I have two existing servers with above configuration - a DEV and a single PROD. I have to move all of the databases from two servers to new servers.
I have two options. Configure the servers again exactly the same way (same software oracle, same mounts-points, directory structures, etc.) and move/copy the databases above. The other option is to use ASM for storage instead of file system.
Customer asks a diskgroup FRA separate for each DBA database. His reason is that if the FRA gets filled by archivelogs because of some process in the databases, all databases stops responding.
- It's a legitimate concern and what is the best way to deal with this kind of situation?
- Should I create a diskgroup FRA separate for each database?
The archivelogs are backed up every 20 minutes for each PROD database.
Please advise!
Best regards
You can limit FRA for each database with the parameter DB_RECOVERY_FILE_DEST_SIZE.
Tags: Database
Similar Questions
-
I have copy of old tbird and seamonkey e-mail files with the files and emails for each. I need to add to new tbird install. can not find a way to do it. HELP PLEASE. previous e-mail files are under mail then mail.earthlink* .net and each of the five mail .net is an email address I have. I can't find a way to identify each file by email to the specific email address (IE mail.my E-mail name.net) so I can copy the files and emails from the past to the email addresses now under tbird. previous installed e-mail identities may not be the current configuration of e-mail files in tbird. I think that I must be sure that mail.name.net matches the previous mail.name.net to be able to copy and paste the old to the new. is there a way to find the file name correct the old email and correspond to the new? all my emails very important information are mostly in the old mail electronic id and must be available in the identification of email again (but same) how can I do this?
http://KB.mozillazine.org/Importing_folders
Use this module.
https://addons.Mozilla.org/en-us/Thunderbird/addon/ImportExportTools/
-
Need to find the version number referring to the last name change for each emplid.
emplID Name age Version --- ----- --- -------- 1 ABC 25 2 1 ABC 26 5 1 def 27 9 1 def 28 15 1 def 29 18 2 JKL 15 5 2 MNO 16 8 2 MNO 17 11 2 PQR 18 20 Need to find the version number referring to the last name change for each emplid.
As indicated by the version number change when there is change in age as well, but I need a query that gives the version number referring to the last name change for each emplid.
with
DATA_TABLE (EmplId, Name, Age, version) as
(select 1, 'abc', 25, 2 double Union all
Select 1, 'abc', 26, 5 Union double all the
Select 1, 'def', 27, 9 double Union all
Select 1, 'def', 28, 15 double Union all
Select 1, 'def', 29, 18 double Union all
Select 2, 'jkl', 15 5 Union double all the
Select 2, 'mno', 16, 8 double Union all
Select 2, 'mno', 17, 11 double Union all
Select 2, 'pqr', 18, 20 double
)
Select emplid,
Max (Name) name of Dungeon (dense_rank last order by version).
Max (Age) age of Dungeon (dense_rank last order by version).
version Max (version)
from (select emplid, name, version,)
-case where name! = lag(name,1,name) on (emplid version order partition)
then "renamed".
end change
of data_table
)
where the change is not null
Emplid group
EMPLID NAME AGE VERSION 1 def 27 9 2 PQR 18 20 Concerning
Etbin
-
How to assign the ID of group for each group in the SQL query.
Hi all
I want to assign the ID of group for each group (group ID of series). I tried with the row_number function but did not work for my requiredment. Here is my sample data and my requirement.
Col1 A A A A A B C D D D D E E E F G G G I want to get number of each column with ID group assign to it value. Here is my example output
Col1 County Group ID A 5 1 A 5 1 A 5 1 A 5 1 A 5 1 B 1 2 C 1 3 D 4 4 D 4 4 D 4 4 D 4 4 E 3 5 E 3 5 E 3 5 F 1 6 G 3 7 G 3 7 G 3 7 Select col1, count (1) NTC (col1 partition).
ROW_NUMBER() over (partition by col1 by col1 order) tbl_test grp_id.
Please help me solve this problem.
SELECT
COL1,
COUNT (*) ON MYCOUNT (COL1 PARTITION).
DENSE_RANK () OVER (ORDER BY COL1) GROUPID
Of
T1;
-
WHY THE PGA IS REQUIRED FOR EACH USER?
Hello everyone;
I have a question about PGA.
WHY THE PGA IS REQUIRED FOR EACH USER?
What I got from google...
Even if information analysis of SQL or PL/SQL is already available in the library of shared pool cache,
the value that the user want to execute the statement select or update cannot be shared.
I can't realize that someone can show an example of clear, if possible?
DB version is 10.2.0.4.0
OS: oracle linux 5.5
Thanks in advance...
PGA is memory private belonging to a specific user. This private memory contains of these pieces that is not supposed to be shared with others. For example, when you sort a part of the data, that does not mean all he wants too. If Oracle retains the sorted data requested by you in your own PGA. Similarly, if you want to query a table with a value of 10, it does not mean that all want the same thing. If these structures are stored in the PGA. For a more detailed description, read the link given by Hoek.
HTH
Aman...
-
Is it possible to create a tag that lists the individual labels [keywords] for each position? The current {tag_blogtaglist} creates an endless list of tags.
If you can get hands on with the ID of blog post that you can list the tags assigned to this post particularly blog using module_data. It would be only possible with the new BC. Active following rendering engine. Here are some resources to point you in the right direction: how to activate the BC. Next - http://docs.businesscatalyst.com/developers/liquid/introduction-to-liquid#enable how to use module_data - odule_data http://docs.businesscatalyst.com/developers/liquid/consuming-apis-in-the-front-end-using-m install app BC API discovered to get you started on the syntax - http://docs.businesscatalyst.com/developers/apps/bc-api-discovery module data that lists the tags assigned to a blog post looks like this: {module_data = 'blogposts' version = "v3" field resource = subresource 'tag' = "tags" resourceId = collection "303870" = "myData"} resourceId is the blog ID to render tags for. Hope this helps, Mihai
-
How to find the first max value for each item
Hello
I have the me_result of the table as below,
SELECT * FROM me_result;
ID ||| ELITE ||||||||||| FREQ_ITEM | COMBINED_STR | SUP
1 ||; 1; 10; 2; 3; 4; 5; 7; 8. 1 ||||||||||||||; 1; 10; 2; 3; 4; 5; 7; 8 ||| 2
2 ||; 1; 10; 2; 3; 4; 5; 7; 8. 2 ||||||||||||||; 1; 10; 2; 3; 4; 5; 7; 8 ||| 2
3 ||; 1; 10; 2; 3; 4; 5; 7; 8. 3 ||||||||||||||; 1; 10; 2; 3; 4; 5; 7; 8 ||| 2
4 ||; 1; 10; 2; 3; 4; 5; 7; 8. 4 ||||||||||||||; 1; 10; 2; 3; 4; 5; 7; 8 ||| 2
5 ||; 1; 10; 2; 3; 4; 5; 7; 8. 5 ||||||||||||||; 1; 10; 2; 3; 4; 5; 7; 8 ||| 2
6 ||; 10; 2; 3; 4; 5; 8; 9. 1 ||||||||||||||; 10; 2; 3; 4; 5; 8; 9; 1 ||| 1
7 ||; 10; 2; 3; 4; 5; 8; 9. 2 ||||||||||||||; 10; 2; 3; 4; 5; 8; 9 ||| 2
8 ||; 10; 2; 3; 4; 5; 8; 9. 3 ||||||||||||||; 10; 2; 3; 4; 5; 8; 9 ||| 2
9 ||; 10; 2; 3; 4; 5; 8; 9. 4 ||||||||||||||; 10; 2; 3; 4; 5; 8; 9 ||| 2
10 ||; 10; 2; 3; 4; 5; 8; 9. 5 ||||||||||||||; 10; 2; 3; 4; 5; 8; 9 ||| 2
I need to find the first COMBINED_STR max for each element of the ELITE,
I mean, max value is the max REGEXP_COUNT (combined_str,' ;')))
really, I try to write down, but I had a lot of values for each ELITE and I need only the first, that
SELECT * from me_result
WHERE (ELITE, REGEXP_COUNT (combined_str,' ;')))) IN
(SELECT ELITE, MAX (REGEXP_COUNT (combined_str,' ;'))))) ME_RESULT ELITE GROUP);
I need the result to be as below.
1; 1; 10; 2; 3; 4; 5; 7; 8-1; 1; 10; 2; 3; 4; 5; 7; : p
6; 10; 2; 3; 4; 5; 8; 9 1; 10; 2; 3; 4; 5; 8; 9; 1 1
any help please,.
Published by: user11309581 on July 10, 2011 22:03Can be
with t as (select 1 ID, ';1;10;2;3;4;5;7;8' ELITE, 1 FREQ_ITEM, ';1;10;2;3;4;5;7;8' COMBINED_STR, 2 SUP from dual union all select 2 ,';1;10;2;3;4;5;7;8' ,2 ,';1;10;2;3;4;5;7;8' ,2 from dual union all select 3 ,';1;10;2;3;4;5;7;8' ,3 ,';1;10;2;3;4;5;7;8' ,2 from dual union all select 4 ,';1;10;2;3;4;5;7;8' ,4 ,';1;10;2;3;4;5;7;8' ,2 from dual union all select 5 ,';1;10;2;3;4;5;7;8' ,5 ,';1;10;2;3;4;5;7;8' ,2 from dual union all select 6 ,';10;2;3;4;5;8;9' ,1 ,';10;2;3;4;5;8;9;1' ,1 from dual union all select 7 ,';10;2;3;4;5;8;9' ,2 ,';10;2;3;4;5;8;9' ,2 from dual union all select 8 ,';10;2;3;4;5;8;9' ,3 ,';10;2;3;4;5;8;9' ,2 from dual union all select 9 ,';10;2;3;4;5;8;9' ,4 ,';10;2;3;4;5;8;9' ,2 from dual union all select 10 ,';10;2;3;4;5;8;9' ,5 ,';10;2;3;4;5;8;9' ,2 from dual ) select ID,ELITE,FREQ_ITEM,COMBINED_STR,SUP from ( SELECT ID,ELITE,FREQ_ITEM,COMBINED_STR,SUP, ROW_NUMBER() over (PARTITION BY ELITE order by id) RN FROM t WHERE (ELITE,REGEXP_COUNT(combined_str,';')) IN (SELECT ELITE,MAX(REGEXP_COUNT(combined_str,';')) FROM t GROUP BY ELITE) ) where RN=1 order by id ID ELITE FREQ_ITEM COMBINED_STR SUP ---------------------- ----------------- ---------------------- ----------------- ---------------------- 1 ;1;10;2;3;4;5;7;8 1 ;1;10;2;3;4;5;7;8 2 6 ;10;2;3;4;5;8;9 1 ;10;2;3;4;5;8;9;1 1 -
How we happen to know that the number of presents for this user database
How we happen to know that the number of presents for this user database.
Both those who are connected and not connected yet.
Thanks in advance
Concerning
SUBJ.using v$ session...
-
I need a query that selects the amount of records for each day of a table.
I need a query that selects the amount of records for each day of a table.
For example, the result would be:
1 14 date
Date 2-3
etc.
Any ideas?Sort:
SELECT count ([IDCommentaire]), convert (varchar, dateAdded, 112)
OF COMMENTSgroup by convert (varchar, dateAdded, 112)
-
Separate for each App menu bars?
I have a Mac Pro with OS X Yosemite 10.10.5
I've seen images screen Mac where the menu bar for each application was separate and along the top of the individual application window.
Is it possible to go from the Menu bar single at the top of the screen, to separate menu bars for each app?
Thanks for all your help.
N °
-
A Palm Desktop allows to load/update a Palm V and Tungsten T2 (separate for each software/data)?
I have a T2 tungsten used for business (in sync with your desktop XP and laptop XP). I recently got a Palm V I intend to use for personal applications / hobby (a controller requiring a serial connection). 2 devices may not be synchronized - in fact, they need their files and separate applications. The current installed desktop application comes from the T2 Setup disk (V 4.1.4).
I need to load an older version of Palm Desktop for Palm V of load/install programs?
How can I load applications Palm v and keep the Palm V files to take charge of the T2 (and now the files synchronization T2 Palm v)?
DRM for all the advice!
Hello and welcome to the Community Forums of Palm.
As long as you keep a separate Hotsync ID for each of the two devices, you should be able to sync the V of the same installation of office. Create a separate Hotsync ID will also create a folder of device separated on the desk, at which all the separate data and third-party applications will be synchronized.
Palm knowledge base Article explains how Hotsync two devices on the same office, but also a device on two different workstations:
http://tinyurl.com/kq4c5Message relates to: None
-
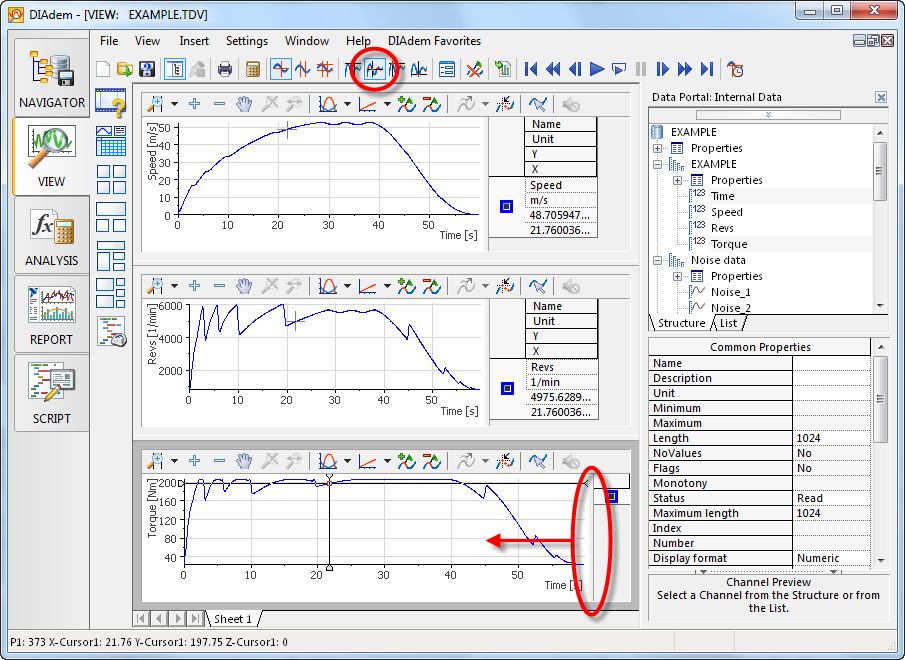
If DIADEM will bother to follow the cursor on all pages in a journal, I think that there is a NON-SCRIPT way to view the values of Y for all.
My graphics are aligned to the x-axis (couple), 4 - poster (1 for each rpm, HP, power and efficiency), and 2D 10 parcels on each of 4 screens in DIADEM 2010.
Shows that the box show the active screen coordinates and others are grayed out. I played a bit with the "cursor settings", but which generates the same although I add appears in the dialog box "coordinated". I guess it may have something to do with making it automatic, but I see no way to change this and how I assign it to a channel?
On another note, I want to be able to synchronize all 4 graphs to be on the same plot (legend) track above and read the same data. So if parcel 1 is selected in the display of RPM, then the other, three will also be on field 1. I guess it had to be done programmatically, but if not, I'm all ears.
Hi Tweedy-
No, you cannot use the .NET code directly in tiara. I don't know what is the point in suggesting it, because it would require a significant change to be able to use a similar code in DIAdem.
Have you tried to use the legends of the VIEW? Expand the legend for each graph, and then double-click the legend, how you can configure what information is displayed on each curve. By default, the legend displays the name of curve, curve units, X-Position (the cursor) and (the slider) Y-Position. Do not hesitate to complete or the contract depending on your preference.
After having developed each legend, switch to slider Curve and you should be able to see the Y Position of each curve, fully synchronized.
-
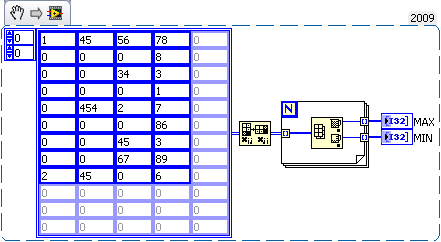
How to find the Maxima and Minima for each column of a 2D array?
Hello
I have a 2D chart and I would find the maxima and minima of each column of the 2-D table. Even though I know how to get maxima and minima for the whole picture but don't know how columnwise? Any ideas please?
Thank you
Rohit
Hello
@Smercurio-What you said is true, I should have shown using automatic indexing enabled which is really excellent choice. I just tried to show in a very simple way.

Anyway, here's the best way
-
How to assign the different VTEP subnet for each grid of a group pool?
The design guide NSX to use L3 access design, it is recommended to use the same number VLAN per rack, but with the other subnet
10.66. < id rack >.0
10.77. < id rack >.0
10.88 < id rack >.0
10.99 < id rack >.0
If the client compute cluster spread on grids, then we will have a different subnet for each rack VTEP, something like (assuming that vlan 77 is for VTEP0
< rack 1 > 10.77.1.1, 10.77.1.2, 10.77.1.3...
< rack 2 > 10.77.2.1, 10.77.2.2, 10.77.2.3...
During the preparation of the host, GUI invites you to assign VTEP for Pool DHCP/IP, looks like most of the cases we use Pool of IP, then for the compute cluster, how can assign us VTEP IP in a different subnet in a single group?
Thank you
Clarisse
You have two options:
(1) DHCP using support on every TOR address suggest you. This is the recommended approach
(2) DHCP then changing manually the VMkernel interface IP address on each ESXi host to match the required subnet - this is not recommended because it is not automatic, but is still supported
-
Calendar of the apex; limit values for each day/cell
Apex 4.2
I'm working on a calendar widget to my page. The calendar will be specific sectors (using the abbreviation of sector space maximze) for each day. When you use the calendar, I noticed the sectors more you have, the cell for this day will begin to stretch down / vertically. I tried to change this so that a specific day / cell would show only a number of areas. For example, maybe one day 20 sectors are attributed to him, however, I only want to show 5 of them and then a text saying 'See more'. The text 'see more' will eventually be a link, but it's far from being the problem.
Initially, the request for this was along the lines of:
select the_id, the_date, the_sector, the sector_abbrev from Table where this = that
It would show all sectors for all the days on the calendar. Yet once, I wanted to limit the output every day as some days would indicate all 20 sectors (their abbreviations), and some would be 3 or four in function. So to say that there are 30 sectors (10 1st), 4 of the 15, 12 on 20-4 on November 29. I want to allow only five abbreviations of sector which must appear in a cell until the link "see more" appears. I came up with the following query:
Select the_sector_abbrev, the_id, the_date, the sector from Table where rownum <= 5 and (this = that) union all Select 'View More', null, null, null from dual
I found that it would be limiting my calendar for showing that four areas throughout the month of November and not for each day / cell on the calendar. I am to discover that 'rownum' is perhaps not the way to go. I don't know how to specify for each of the calendar days rownum. I don't know how to capture every day / the Calendar cell. Maybe I need a more complicated or a subquery where clause. But overall, from my example above, the 1st show four of the sectors and then the link "See more", the 15th would show the four sectors and thats all, the 20th century would show four sectors and her "see more" link and so on.
Any help on this would be greatly appreciated. Thanks in advance.
NewApexCoder wrote:
I had no idea of the possible application of solution would be too complex.
It is not the case:
with calendar_data as ( select ins.sector_abbrev_name , sch.hwe_inspection_scheduling_id , sch.inspection_date , sch.instructions , sch.inspection_sector_id , sch.high_water_event_id , ins.inspection_sector_name , hwe.event_name , row_number() over ( partition by sch.inspection_date order by sch.inspection_date, ins.inspection_sector_name) day_sector_rn from hwe_inspection_scheduling sch left join inspection_sectors ins on sch.inspection_sector_id = ins.inspection_sector_id left join high_water_events hwe on sch.high_water_event_id = hwe.high_water_event_id where ( sch.high_water_event_id = :p0_high_water_event_id or :p0_high_water_event_id is null)) select inspection_sector_id , inspection_date , inspection_sector_name , sector_abbrev_name , ... , null -- Generate URL for sector links here from calendar_data where day_sector_rn <= 5 union all select null , trunc(the_date) + 1 - interval '1' second , null , 'View More…' , ... , null -- Generate URL for "View More..." links here from calendar_data group by the_date having count(*) > 5
Maybe you are looking for
-
How do the initialization of the new hard drive in the macbook pro 2012 model
I can't the initialization of a new WD hard drive in my macbook pro 2012. I installed the new drive and restarted with disk Warrior and followed the instructions to press option, command-R. When I followed the Protocol to download a new OS, disk util
-
HP Pavilion G 42 458 YOU: brightness button does not
My laptop HP Model No.. HP Pavilion G 42 458 UT. Laptop key Board have buttons f2 and f3, which I've used to control the brightness of my screen earlier. I got windows 7 ultimate OS that I had uninstalled and installed Windows 7 Home Basic Edition.
-
disable the touchpad as enter key for windows 7
I have a problem with windows 7. MS had to connect to my laptop to fix. In the process of a lot of things updated. Since then the touchpad acts as the Enter key, what bothers me. I want to disable the touchpad as the Enter key. Is this fixed with a d
-
Ladies and gentlemen, One of my clients recently installed NX3300. NX3300 use Windows Storage Server R2 2012 as an operating system, And the material is based on server r.620 EP. But I can not find NX3300 to the matrix of Support of OME. (NX3100, NX3
-
I have my printer connected to my router via a usb cable. I also have my (Vista) computer connected to the router by ethernet cable. How can I set the computer to print to my printer via the router?