The implementation of data mining
I have installed Oracle EBS R12. (Inventory and purchase module)I want to know how to incorporate techniques of exploration data in it?
Hi Naeem,
Data mining is fully integrated to the db.
So you can extend applications easily using pl/sql and sql operations (see the Documentation of the API Data Mining).
http://www.Oracle.com/technetwork/database/options/ODM/ODM-documentation-170506.html
Data mining has been integrated into some existing Oracle Applications as part of the base product.
For example, take a look at the Application of Capital Management human Oracle:
http://www.Oracle.com/us/products/applications/fusion/HCM/index.html
You just need to review guidelines on how what form of client extensions are allowed for a given Application to Oracle.
I suggest you contact the Oracle Support.
Thank you, Mark
Tags: Business Intelligence
Similar Questions
-
Cost associated with the implementation of Data Guard
Hello
What are the implications of cost migration to oracle Standard edition to Enterprise edition (I think data hold is not available with standard edition)?
I just need a rough estimate to make a presentation. Also is there any additional cost to implement Data Guard? Finally, it is reasonable to assume that the average cost of a server of the p series (4 processors with 16 / 32G of RAM) is around £2000 ($3500).
ConcerningYou can get the list of prices of http://www.oracle.com/corporate/pricing
However, actual prices depends on corporate discount - which vary according to the customer.
See also the Software Investment Guide of the same URL avaiable.
-
The deployment of Data Mining Project
Hello
I am new to the DataMining. I have finished a tutorial on the right customers when they buy new offers or not a video tutorial but it is very similar to this
Prediction (classification). I understood it completely. After connecting the models of classification to view output or a table I want results. and I got the table named Prediction_view in my diagram
I want to ask some questions.
- How can I register these predictions on visitors just be inserted?
- Whenever I need predictions, should I work on the project again and do view applied fees or a table?
- After deployment using (right click on the table or the data output view), I had all of the .sql files in my directory. Are only as files used for the fresh prediction algorithms?
- is it possible to refresh this view before making predictions?
In fact, I have same scenario in my application. customer quote management and sales. After sending the quote of sale to the customer, I want to apply the weather customer Classification will respond to that quote or not?
Thank you.
Please see this white paper on the deployment of workflow using generated sql scripts
http://www.Oracle.com/technetwork/database/options/advanced-analytics/companion-2042207.zip
I will use the workflow in the white paper for example to answer your questions.
1. How can I apply these predictions on visitors just be inserted?
In the workflow of demo, the INSUR_CUST_LTV_SAMPLE will APPLY node contains new data to be applied (Apply node) to the (node class Build) model for predictions. In your case, you have a Data Source node that contains customer data has to be inserted.
2. whenever I need predictions, should I work on the project again and do view applied fees or a table?
In the workflow of demo, the node SCORED_CUSTOMERS captures the predictions. Note that the node creates the output as a VIEW (SCORED_CUSTOMERS_V), this point of view always reflect predictions for new data. There is no need to run any of these nodes again for new data, the SCORED_CUSTOMERS_V view always grabs the latest data based estimates. Had created the output as a TABLE instead of that node, you must run the node to persist the new predictions.
3. once deployment using (right click on the table or the data output view), I had all of the .sql files in my directory. Are only as files used for the fresh prediction algorithms?
Please see the white paper for the use of script files.
4. is it possible to refresh this view before making predictions?
See above responses.
Thank you
Denny
-
Suggestion for Oracle data mining product team
Team of Oracle products,
Here's a suggestion Data mining product marketing and development.
For a specialist in data mining or data scientist, he does well synchronize when they see the name of the product as "SQL Developer" who has the ability to data mining, unless Oracle is intentionally marketing and sale to its existing base Oracle client, which I hope not.
Continue to have capabilities to extract data as part of the developer sql and make it as a stand-alone product. This will put Oracle in a much better position to compete with manufacturers as fast Miner, etc. and also it gels with many statisticains and scientific data.
Bottom line, start to use "SQL" less and more 'algorithms, libraries, APIs' data mining market product to customer non-Oracle base and make them buy product so DB. It seems to me that you sell products critical to Oracle DB clients now, but you should also have a good salesforce that can sell capabilites Data Mining product to customers not Oracle DB and make them buy Oracle DB as well.
I like SQL and is the way to go for most data extraction, but go with the wind and SQL and other non-SQL conditions to get a foot in the door of the market. Oracle has an amazing technology outside the Oracle database... just need to market it better. (I say this with 22 years of experience of the Oracle)
I'm curious to see what other people love Oracle and use SQL Developer - Data Mining capabilities say about it. Please post your comments. THX
D21,
You make a very good point. This isn't a comment which went unnoticed or that we ignored. Unfortunately, Oracle cannot make statements about the 'future '. Thank you very much for the comments. Keep it coming!
Charlie
-
Time series by using Oracle Data Mining? Is there any equivalent of ARIMA in the MDGS?
Hello
I followed the extraction of data from Oracle Press book. I applied regression models to predict continuous variables.
My use case is to predict the market price of stocks based on historical data.
I see there R packages to do. Some popular methods that are widely used are ARIMA (Autoregressive integrated mobile average).
Is there such an offer out-of-the-box in the MDGS?
Pointers / whitepapers, or do we use component regression?
Thank you
Chrystelle
Hey Lulu,
MDG does not have an implementation of time series which is precisely part of the SQL in the algorithms of db.
But AAO (Oracle Advanced Analtyics, ODM is a part of) has an implementation of time-series Oracle which may be useful for you:
See ore.esm model, documented with examples here: https://docs.oracle.com/cd/E57012_01/doc.141/e56973/procs.htm#BEIEGCDG
We also have the preparation of data for time series capabilities, listed here: https://docs.oracle.com/cd/E57012_01/doc.141/e56973/procs.htm#BEIJHHCG
May also be interested to Marcos Campos blog on time series using the current characteristics of ODM/DB: Oracle Data Mining and Analytics: time series Revisited
Hope it will be useful.
THX, mark
-
How to implement the reading of data from a matte file on a cRIO?
Hi all!
I'm still not sure, it is plausible, but I'll ask rather before you begin complicating. So far, I found no useful information on reading in the data to a device of RT from a file (type of a simulation test - data is simulated).
I have the MatLab plugin that allows the storage of data read a MAT file, which has a number of columns that represent the different signals and lines representing the samples at a time (depending on the time of the sample - sample every time has its own line of signal data).
I have no idea how to implement this at cRIO.
The idea is:
I have some algorithms running on the controller of RIO in a timed loop. As the entries of these algorithms I need to access each of the values of columns in the row, which is the time of the sample (sort of a time series - without written actual times).
I am fairly new to RT and LV development, so any help would be appreciated.
Thank you
Luka
Dear Luka!
I think the reading of all the samples in a single channel is exactly what you need here, because reading the files may take some time and is not deterministic, so it is best to read all the data in memory (or if this is not feasible due to problems of size, fairly large pieces may be sufficient). The table read can be provided and then in the loop simulating outings, something like this:
I used here separate channels so it's more graphic, but you can build all the channels in a 2D array and array index corresponding to the samples fom 1 who. You can also use for loops with indexing as tunnels are setup and then you won't need the index functions and the number of iterations is also set automatically, but you have to take care of synchronization settings.
Best regards:
Andrew Valko
National Instruments
-
new to labview :-) and I have a problem when I want to change the value of a string in bunches, and I want to implement this using the node value of property instead of writing directly to the stream or by using the variable, enclosed is the picture. No matter, I have change in cluster (control) or value of Popery out (indicator) cluster, the value (sensor 7) dataflow keeps unchanged even I gave the new value by value of property node. Thank you to give me some advice about this.
Hi GerdW
Thanks a lot for your answer. The reason I'm stubbornly tring to break the flow of DATA is: we have a test system that have about 100 screws, they have a few connected flow, some of them will be unbundling a cluster dataflow chain to check the value in order to make the different cases. Now I want to insert user event by changing the control and influential cases during run time.
As I initially uses a global variable (to control cases) instead of unbundle string data flow, it works well. But then, I found there are a lot of screws that are using the string unbundle. One of the 'lazy' means, I tried is to change the value via the property node (because that way, I did not need to find all the places where using the unbundle string and replace them with the global variable), then I noticed a problem with "dataflow", the value in the stream of cluster in fact will not be changed by changing the value of the property node.
I did a test with VI simple (like the picture in last post), and after reading your advice, I tell myself that I need to understand the concept of "DATAFLOW" in labview, it seems that my "lazy" way can not work in this scenario.
I have attached the criterion VI here, have you furthur suggestions on what I can do in this case?
Mant thanks!
Minyi
-
Data mining - error on the insertion of the TREE_TERM_MINPCT_MODE value in the parameter array
Hello
In Data mining when I tried to insert some values into the parameter array. I get the error by trying to introduce TREE_TERM_MINPCT_MODE in the table.
The model who was on trial for create was decision tree.
BEGIN
INSERT INTO DT_CA_SETTINGS_TEST (SETTING_NAME, SETTING_VALUE) VALUES
(dbms_data_mining. TREE_TERM_MINPCT_MODE, to_char (1));
END;
Error report:
ORA-06550: line 3, column 22:
PLS-00302: component 'TREE_TERM_MINPCT_MODE' must be declared.
ORA-06550: line 3, column 22:
PL/SQL: ORA-00984: column not allowed here
ORA-06550: line 2, column 4:
PL/SQL: SQL statement ignored
06550 00000 - "line %s, column % s:\n%s".
* Cause: Usually a PL/SQL compilation error.
* Action:
Thank you
Srikanth.Hello
BEGIN
INSERT INTO DT_CA_SETTINGS_TEST (SETTING_NAME, SETTING_VALUE) VALUES
(dbms_data_mining. TREE_TERM_MINPCT_NŒUD,to_char (1));
END;
This isn't 'Mode' his 'NŒUD '.
Run now.
See you soon...
-
How to implement security at the level of data
How to implement security at the level of data in BI Publihser? I use Obiee enterprise edition and publihser bi. My requirement is to show the data based on the user relation ship - region.
He belongs to the eastern region
B - the user belongs to the region of the South
so if the user has opened a session it must see only the region Eastern report. If user B is connected it should see only the southern region. I use direct sql to my database of oralce as data source.
I appriciate your helpHello
You can use *: xdo_user_name * in your query.
concerning
Rainer -
implementation of the table with the scroll bar. (data scrolling)
Hello
I want to show the web service data in the table with scroll bar using java script or html or css .actuall I want only a part of the screen is not whole screen scrollable. can you suggest how it is possible.any suggestion? I used phone gap technology. I used iscroll but it does not work in blackberry data are not displayed in the Simulator... Help, please
Thank you
ravi1989 wrote:
Hello
I want to show the web service data in the table with scroll bar using java script or html or css .actuall I want only a part of the screen is not whole screen scrollable. can you suggest how it is possible.any suggestion? I used phone gap technology. I used iscroll but it does not work in blackberry data are not displayed in the Simulator... Help, please
According to devices/operating systems that you want to support, you could give bbUI.js a change. It works really well in most of the cases, and I think there are a lot of things you don't need to worry more because bbUI.js is just for you.
Look more at the scrollPanel example that does exactly what it takes, a part only of the entire screen of scrolling you can configure a height in the HTML source code directly.
-
Hello
I was really intrigued with a capacity of DIAdem data mining and I was wondering if anyone has reference in which information is about how data must be save access of multiple users.
Here's a quick example of how I see using DIAdem data mining capability.
I work with several engineers and we are all data conditioning similar test of a variety of tests. Usually each every engineer save its air-conditioned data wherever he chooses. What I consider, it is that all the technical staff to save test data in a centralized location. Save the data in a common location would allow me to use DIAdem to browse the data of similar test on the basis of test criteria.
I guess my question is I go about it the right way. How is it difficult to implement tiara to mine the data of multiple users, using a centralized network location?
I thought about it.
I just added Netwrked way, I wanted to index and it works.
Thanks for your help.
-
The amount of data is generated in continuous mode?
I'm trying to implement a measure of voltage using a card PCI-6071E. I looked at some of the samples (ContAcqVoltageSamples_IntClk_ToFile) that uses the AnalogMultiChannelReader to collect the data asynchronously and write to a file. My question is, if I do 2000 samples per second with 200 samples per channel, the amount of data will be generated? By using compression really will make a big difference in how much data I have to deal with that? I want to graph data 'real time' in certain circumstances, but usually save the file for post processing by another application. My tests can be run for several minutes. I looked at the things given compressed, and I didn't understand how I could read the data back and understand what data are intended to what channels and the amount of data belongs to each channel and each time slice. Thank you
How many channels are you reading from? Samples per second, is what will tell you the amount of data that you produce. Multiply this number by the number of channels and you will get the total number of samples per second of the generated data. (The samples per channel determines just the size of buffer in continuous acquisition, so it is not used to determine the total amount of data being generated.) Each sample will be 2 bytes, so the total amount of data will be 2 * 2000 * number of channels * number of seconds during which your test runs for. From your description, it sounds not compression is really necessary; just save your files regardless the other format your program can read (text delimited by tabs, or any other common format files) and do not worry about compression, unless the size of your files become prohibitive.
-Christina
-
The research of data points in a cluster
Hello.
I'm using LabVIEW 2013 to myRIO. IM facing a problem with the implementation of a few things with the clusters.
Problem statement: coordinated map recorded for a GPS on a map and the use of the cursor functionality to check the value of the various sensors on different parts of the track.
I was able to map the contact information stored on a card in LabVIEW. I create an array of the coordinates, to group and then move them to an XY Chart. Cursor has also been implemented. I click on the map and drag my mouse and it takes me to different coordinates.
What I can't do, is show other data senors for the coordinates x, Y.
My plan is to consolidate all the data from sensors in a cluster, and then try to find the cluster for the necessary points of X, Y.
How a search within a cluster by specifying only X, Y
for example: I give to X, Y and I get the value of all the sensors for this pair x, Y?
Thank you

-
component module (function) in the Toolbox of data base
Hi, I have been using the Toolbox of data a lot, but I've never used a function of my Access database before.
I have a function called "Work_Days" that takes two dates as Inparameters and calculate how many working days it is. This function is stored in the Modules section in Access.
I have a working query I can run with access which looks like this:
SELECT tblActiveCCU.ID, tblActiveCCU.DateReceived, tblActiveCCU.DateTransferred, Work_Days([DateReceived],[DateTransferred]) AS NetDays FROM tblActiveCCU WHERE (((tblActiveCCU.ID)=97));
The output looks like this:
ID DateReceived DateTransferred NetDays 97 3/16/2016 3/30/2016 11
Now to the question, how I implemented this request in LabView?
In my attached code, I got a "syntax error" FROM clause
-
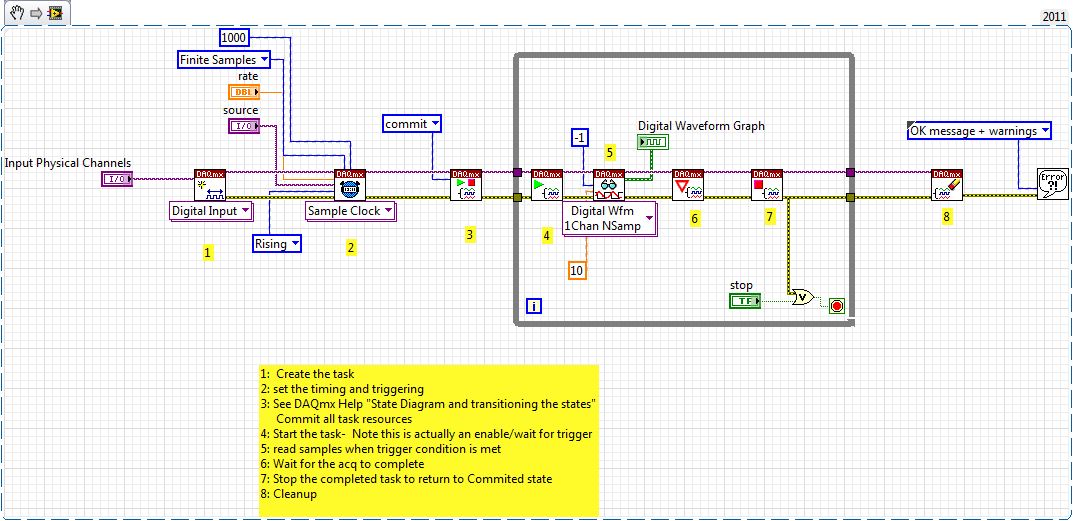
Restarting a task for the acquisition of data inside a For loop
Hello
I need iterate through my acquisition of data. Currently, I'm doing this through the creation, implementation and tasks for the acquisition of data inside a loop For which is iterated according to the needs of compensation. Unfortunately, the creation of these DAQ tasks slow down my code.
I would like to be able to create the tasks outside the loop, pass them in and revive the tasks at the beginning of each iteration. Is there an easy way to do this?
Otherwise, is there a way to make the standard DAQmx digital startup trigger trigger several times (so that it starts each pulse data acquisition in a long pulse rather than just the first pulse train)?
Thank you!
-Evan
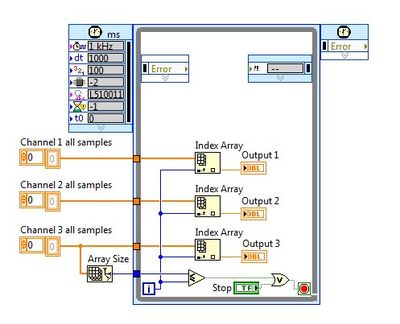
I whent before and created this example for you (and many others.)
Maybe you are looking for
-
I heard this term recently. I think it's a certain amp DAC or something of this nature? I know that the 10th HTC and ZTE Axon 7 is supposed to have. I read a review saying that it was not hi-fi... Although I'm sure that it does not matter with a good
-
Hello I'm tracing a FFT of find a different frequency of the signals non-periodic signal. kindly help to plot the frequency and Amplitude. attachment have given amplitude time Vs
-
Windows security alerts. The small red sign in the lower right corner of my monitor tells me that my computer is not protected against viruses. The only way to make it work again is to restart my computer, but this time even that did not work. Window
-
I just started using my HP Photosmart 6510, how do I scan multiple pages to my computer documents so that they find themselves in a single file?
-
file broken after moved in bridge
HelloI moved some big pdf files in bridge (cs6) via drag & drop of a folder to a subfolder, then, some have been broken, cannot open more...; (which is a great catastrophe...