Tips on optimizing the performance of table.
Hello
I read several article on optimizing the performance for the table. Finally, I settle on a strategy to implement, but I have a few questions.
Let's say we want to display a wide range of data in a table. The number of lines displayed on the screen is n = 25.
For each VO displayed in table form: Open model project->->->-> Data Model Instances to View object Data Model Module of Application -> select your view object-> press the modify... button-> Tuning
- For best performance Oracle ADF Performance Tuning Documentation indicates that in lots of field must be set to n + 3
- The scope of the queryoptimizer indicator should be the value + 3, so if n = 25, FIRST_ROWS_28 FIRST_ROWS_n
- By default, access is set to Scrollable, which is OK as long as you aren't iteration in a large data set, but if you are, then you must change the Access Mode to the Range Paging
- Set the size of the beach to n + 3
Q1: What is the reasonable maximum for a set size? Client wants to display huge table as 200 lines that is not really usable, but it's what they want. I was wondering if the definition of the size of the beach at 203 is a reasonable value, or if it is too high.
Q2: I have really not understand the purpose of the indicator of QueryOptimizer even after reading the documentation. Is it okay to put it at FIRST_ROWS_203 if your batch size is 203?
Thank you
JDev 11.1.2.4
What version of jdev we are talking about?
Is the table in paging mode (+ 11.1.1.7)?
Q1 Yes), the tip is still standing, then set-203. The reason is that the table will display 200 lines that you need to load them in any case. In this case, it is best to load them into a round trip. a smaller rangesize then the number of visible rows in the table means more then 1 trip on the server and the db.
Q2) the query optimizer indicator is just passed to the db which then decides to use it or not. The indicator shows the db to deliver the first n lines of results as soon as possible. If you have large result sets the db can provide the result set when it comes always collection more data FRO the game results in the background. This will display the fastest page to the user.
Timo
Tags: Java
Similar Questions
-
Tips on improving the performance
Hello
I have a table that contains data for the last 5 min, maximum (500 lines), this table is in NOLOGGING mode.
I have another process that get these data every 5 minutes and then remove each row in this table.
As my table is in NOLOGGING mode I was questioning myself if this better to TRUNCATE the table or DELETE all ranks.
I did a trace to see the result, but I'm not sure of the conclusion:
truncate table
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 0.00 1.40 12 3 238 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 2 0.01 1.40 12 3 238 0
Chess in the library during parsing cache: 1
Optimizer mode: ALL_ROWS
The analysis of the user id: SYS
Elapsed time are waiting on the following events:
Event waited on times max wait for the Total WHEREAS
---------------------------------------- Waited ---------- ------------
DB file sequential read 12 0.00 0.00
ENQ: RO - fast object reuse 3 0.26 0.42
local writing wait 7 0.50 0.24
reliable message 1 0.00 0.00
Journal of synchronization of file 1 0.04 0.04
SQL * Net message to client 1 0.00 0.00
SQL * Net client message 1 0.00 0.00
delete
call the query of disc elapsed to cpu count current lines
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Run 1 0.00 129 263 566 134 0.12
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Total 2 0.00 0.12 129 263 566 134
Chess in the library during parsing cache: 1
Optimizer mode: ALL_ROWS
The analysis of the user id: SYS
Caught plan statistics number: 1
Ranks (1) operation of line Source lines (avg) lines (max)
---------- ---------- ---------- ---------------------------------------------------
0 0 0 ASH_DATA DELETE (cr = 263 pr = 129 pw = time 0 = 125014 en)
134 134 134 TABLE ACCESS FULL ASH_DATA (cr = 263 pr = 129 pw = time 0 = 2738 US cost = 37243 size = card 6420 = 321)
Elapsed time are waiting on the following events:
Event waited on times max wait for the Total WHEREAS
---------------------------------------- Waited ---------- ------------
db file scattered read 17 0.11 0.11
SQL * Net message to client 1 0.00 0.00
SQL * Net client message 1 0.00 0.00
Thank you
Cyrille
@rp0428 I have no control over this, if you have a suggestion, I'm very open minded
, Thanks for the STORAGEclause of RE-USE, I'll have a look.
The button Delete and truncate made with about 130 lines each, at the exit, it seems that the truncation is longer but consumes less resources.
Ask yourself that question 'control transaction' is a more important than potential problem on.
I followed the basic rule is: if it ain't broke, don't fix it.
You have not posted ANY reason to believe that you still have a problem.
Until you really have a problem to choose a solution and move.
As it has already menntioned AND TRONQUER LOADING/RELOADING operations
1. is evolutionary movement
2 are performing travel as the amount of data increases
3. use fewer resources (undo, redo, memory) as the amount of data increases
The above is particularly true for the use case that can benefit from the RE-USE of STORAGE clause such as batch jobs which tend to use about the same amount of tablespace.
-
Help/tips to set the performance preference. FOR large files.
Hello
I work with large files for prints of fashion.
I did some research several sites and manuals, tried various settings, but it did not help.
Average sizes are 100x100cm with 300 dpi.
+ Think it takes to save and it takes a lot to apply filters. E.g. liquefy.
What is the best setting to improve performance ?
Memory usage . I leave in 70% (I have 10 GB)
History States: 20
Cache Levels: used in 1 and moved to 8, which is the best option? my files are large and with some 20 layers.
Cache Tile Size: Used with 128 and 1024, don't know which one is better??
Scratch Disk: Use the primary and secondary? Also the external?
Chart Processor: use in basic or advanced mode?
My files are on average with 1.5 GB to 700 MB
It is best of save in PSD or PSB?
Thank you!
My system :
Photoshop CS6
Windows 7 64bits
10Go of Memory ram
NVIDIA video card, 2 GB
HD Master : 100 GB free
Secondary HD: 30 GB free
External hard drive : Samsung 300 GB free
Use a flash drive with 6 GB of readyboost.
After many attempts.
tested for 30 days.
Configuration which had better results.
Memory: 70%
History States: 20 (I prefer a large number)
Cache levels: 4 or 6
Tile cache size: 128 k
Cratch disc
1st master (where is windows and my files)
2nd external hard drive USB
Chart peak: Advanced
activate the chart use...
Enable Anti-aliasing...
Clear the bit 30...
Now I have "purge all" every 15 minutes.
-
Optimizing the performance of Flash
I evaluate VMware View, and it's feeling like I get not quite multimedia delivery just RDP to my Win7 VMs vSphere. Is there a list of best practices for this type of optimization? Everything I've done so far is to change the settings of the Pool to use high-quality Flash and play with giving the VM more vCPUs or vRAM.
I tried different configurations, and here's what it seems good to bad:
VMware View 4.6 Mac = Mac RDP client > PC VMware view 4.6 Client = Win7 RDP > Suse Linux Enterprise VMware View 4.5 Wyse > Wyse ThinOS RDP. This corresponds pretty well to the power of the machine that I use a Mac 8 - core, a PC 2 drivers, a R50LE and a C10LE.
At best, I always get a frame torn here and there, and the sound is a fraction of a second behind. At worst (devices from Wyse), the video is choppy and the sound is consisitently 1-2 seconds behind, even if the sound is solid and doesn't break the flow.
I'd be able to do better than that? Does take to the Wyse TCX? Anyone have good experiences here? Elsewhere?
I'm running a vCenter with two hosts, 8-12cpus, DAS with much ability: for the host on which the test VM is sitting on I'm generally 5-8% cpu, memory 40% and 40% storage. I think that there are a lot of lats, running on even underused GB Ethernet network.
Thank you!
As the above poster said, you must use PCoIP if you want to enjoy the benefits of a protocol designed for VDI. RDP is not go just cut, although supposed to be native is doing stuff with RDP to improve it with Blaze.
To improve even more, I suggest to use Clients zero jointly with PCoIP for a total experience.
-
New user - need tips to improve the performance and graphics ability
Hello
I am a new user. I loaded Windows 7 64-bit today, and it seems to work fine. (I used only Explorer.) I downloaded by Reallusion CrazyTalk and software is lagging terribly, and the image is blurry. The Forum of CrazyTalk, they recommend updating graphics drivers to fix blurry images. On the NVIDIA site, when I asked her to automatically detect the driver update, it says none is available for my computer (my Mac).
Question: They have updates driver for Windows... When I am running Windows via Fusion, should I different graphics drivers than those on my Mac? If so, means that I need another graphics card? * Of course I'm not super technical. **
I have attached a screenshot of my info/display of charts:

In addition, molten, I increased the RAM to 3 GB (3000 MB), but it has not improved the situation.
CrazyTalk allows the user to make a photo 'talk '... It is lively and contains the audio. I usually save files as uncompressed reviews that are about 4 GB in size (when I worked directly on a PC) but today to test it's obviously "too much" for this system. (It would have probably been about 2 GB). So I recorded a MP4 (3.7 MB), which has always been a time loooooooong to save - 30 minutes.
Other info:
Model name: iMac
Model ID: iMac9, 1
Processor name: Intel Core 2 Duo
Processor speed: 3.06 GHz
Number of processors: 1
Total number of cores: 2
L2 Cache: 6 MB
Memory: 4 GB
Bus speed: 1.07 GHz
Boot ROM version: IM91.008D.B08
Version of the SCM (System): 1.37f3
I would appreciate advice and links to information that will help me.
Thank you
Dora
TatianaTheDog wrote:
I am a new user. I loaded Windows 7 64-bit today, and it seems to work fine. (I used only Explorer.) I downloaded by Reallusion CrazyTalk and software is lagging terribly, and the image is blurry. The Forum of CrazyTalk, they recommend updating graphics drivers to fix blurry images. On the NVIDIA site, when I asked her to automatically detect the driver update, it says none is available for my computer (my Mac).
Welcome to the Fusion community.
Question: They have updates driver for Windows... When I am running Windows via Fusion, should I different graphics drivers than those on my Mac? If so, means that I need another graphics card?
Your don't need another graphics card. By necessity, VMware can pass through native graphics of your iMac to any guest including Windows operating system. VMware provides its own graphic adapter of substitute (WDDM 3D) or VMware SVA II, with its own pilots. Apple takes care to provide you with the latest drivers for OS X, you will never have to download all the drivers directly from the graphics vendors. Details about the virtual hardware and its differences of capacity are covered in the FAQs on VMware Fusion
Regarding the VMware graphics drivers who are in the VMware tools and are supported if you have installed Windows 7 using Windows Easy install feature in the new computer Wizard. If you do not use Windows Easy Install (or don't remember), the icon of blue squares of VMware in the system tray is a Visual indicator, they are installed. But you can confirm the video adapter by using the Control Panel, search for display > change display settings > advanced settings to look at your graphics card. For Win7, the default value is VMware SVGA 3D.
Whenever you want to refresh the VMware drivers you can select Virtual Machine > install VMware Tools to install or run the option repair after the Welcome screen.
In addition, molten, I increased the RAM to 3 GB (3000 MB), but it has not improved the situation.
Based on the requirements of CrazyTalk6 system I could find, you do not need to allocate as much RAM (3 GB). Depending on your other needs Windows 7, 1 GB to 2 GB would be better, based on your host, the RAM size.
Pentium IV 2 GHz or higher recommended
512 MB of RAM or more recommended
1 GB space drive or higher recommended
Duplex Sound Card/VGA Card/keyboard/mouse/Microphone/Speaker
Display resolution: 1024 x 768 or higher
Video memory: 128 MB RAM or higher recommended
Windows 7 / Vista / XP SP2
Internet Explorer 6 or higher, Firefox 2 or higher
DirectX 9 and WMEncoder 9 are required to export WMV
Recommended hardware:
CPU dual core or higher recommended
1 GB of RAM or more recommended
Hard drive 2 GB or more recommended
Video memory: 256 MB RAM or higher recommended
Things to try:
The 3D Aero interface may impose the virtual graphic adapter, then you could try to disable that by getting the properties of the desktop background, choose Customize and change the theme of Windows 7 Basic.
More radically, you can stop the virtual machine and disable 3D graphics in the VM > settings > display > uncheck "Accelerate 3D graphics." This will cause Windows 7 use the legacy VMware SVGA II adapter. The oldest non - 3D adapter looks like it meets the system requirements but requiring DirectX 9 encoding for WMV exporting. If you save without video compression, that may be OK. If the non - 3D adapter does not meet requirements, I am sure that the program will display.
-
Tips to improve the converted machines
Hello
I began to convert the Windows Machines and they are a bit slower after the P2V process. Already, I removed all the old material and the VMware Tools installed.
I would like you to hear some tips to improve the performance of virtual machines converted.
Thank you!
Cristiano Botelho
http://communities.VMware.com/thread/25121
Wait for this theme on the cleaning of the VM after the P2V conversion.
StarWind Software R & D
-
Rewrite the query to improve the performance and the optimized below cost.
Oracle 10g.
----------------------
Query
UPDATE FACETS_CUSTOM. MMR_DTL
SET
CAPITN_PRCS_IND = 2,
FIL_RUN_DT = Current_fil_run_dt,
ROW_UPDT_DT = dta_cltn_end_dttm
WHERE CAPITN_PRCS_IND = 5
AND HSPC_IND = 'Y '.
AND EXISTS (SELECT 1
OF FACETS_STAGE. CRME_FUND_DTL_STG STG_CRME
WHERE STG_CRME. MBR_CK = MMR_DTL. MBRSHP_CK
AND MMR_DTL. PMT_MSA_STRT_DT BETWEEN STG_CRME. ERN_FROM_DT AND STG_CRME. ERN_THRU_DT
AND STG_CRME. FUND_ID IN ('AAB1', '1AA2', '1BA2', 'AAB2', '1AA3', '1BA3', ' 1 B 80 ', ' 1 HAS 80 '))
AND EXISTS (SELECT 1
OF FACETS_CUSTOM. FCTS_TMS_MBRID_XWLK XWLK
WHERE XWLK. MBR_CK = MMR_DTL. MBRSHP_CK
AND MMR_DTL. PMT_MSA_STRT_DT BETWEEN XWLK. HSPC_EVNT_EFF_DT AND XWLK. HSPC_EVNT_TERM_DT);
Explain the plan of the query
-----------------------------------------------
Hash value of plan: 3109991485
-------------------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
-------------------------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT. | 1. 148. 12431 (2) | 00:02:30 |
| 1. UPDATE | MMR_DTL | | | | |
| 2. SEMI NESTED LOOPS. | 1. 148. 12431 (2) | 00:02:30 |
|* 3 | HASH JOIN RIGHT SEMI | | 49. 5488. 12375 (2) | 00:02:29 |
| 4. TABLE ACCESS FULL | FCTS_TMS_MBRID_XWLK | 6494 | 64940 | 24 (0) | 00:00:01 |
|* 5 | TABLE ACCESS FULL | MMR_DTL | 304K | 29 M | 12347 (2) | 00:02:29 |
|* 6 | TABLE ACCESS BY INDEX ROWID | CRME_FUND_DTL_STG | 1. 36. 5 (0) | 00:00:01 |
|* 7 | INDEX RANGE SCAN | IE1_CRME_FUND_DTL_STG | 8. | 1 (0) | 00:00:01 |
-------------------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
3 - access("XWLK".") MBR_CK "=" MMR_DTL. " ("' MBRSHP_CK")
filter ("XWLK". "HSPC_EVNT_EFF_DT" < = INTERNAL_FUNCTION ("MMR_DTL". " PMT_MSA_STRT_DT') AND
'XWLK '. "" HSPC_EVNT_TERM_DT "> = INTERNAL_FUNCTION ("MMR_DTL". "PMT_MSA_STRT_DT")) "
5 - filter("CAPITN_PRCS_IND"=5 AND "HSPC_IND"='Y')
6 filter (("STG_CRME". "FUND_ID" = "1 HAS 80 ' OR 'STG_CRME'." " FUND_ID "="1AA2"OR"
'STG_CRME '. "FUND_ID"= '1AA3' OR 'STG_CRME'. "FUND_ID" = "1 B 80 ' OR 'STG_CRME'. '. "FUND_ID" = "1BA2" OR "
'STG_CRME '. "FUND_ID"= "1BA3" OR "STG_CRME". "FUND_ID"= "AAB1" OR "STG_CRME". ("FUND_ID"="AAB2") AND
'STG_CRME '. "" ERN_FROM_DT "< = INTERNAL_FUNCTION ("MMR_DTL". "PMT_MSA_STRT_DT") AND "
'STG_CRME '. "" ERN_THRU_DT "> = INTERNAL_FUNCTION ("MMR_DTL". "PMT_MSA_STRT_DT")) "
7 - access("STG_CRME".") MBR_CK "=" MMR_DTL. " ("' MBRSHP_CK")
I could not optimize this query for best performance and optimized the cost... Can someone guide me on this.
Thank you
DS
You think you're going to lines updates 85K, Oracle think it will update a line.
At the time where the existence of the first test runs that oracle think already up to 49 lines, which is probably why he uses the loop join nested for the second test. (In your version of Oracle, the subquery introduced existence a very bad assumption (small) on the amount of data will survive).
It is possible that you will get better performance if you hint Oracle using a hash join for testing the existence - and you might want to think what test will eliminate most of the data and that we can first force.
Having said that, however, note that MMR_DTL research is a considerable fraction of the cost of the query - and an analysis is an easy thing for Oracle cost properly - if, despite your comments on update a column with a clue to this topic, you will find that the query can be more effective if you use an index. This is more likely to be the case if data ' WHERE CAPITN_PRCS_IND = 5 AND HSPC_IND = 'Y' "is well grouped (perhaps the latest data added to the table).". " You could then reduce the cost of maintaining this index by creating an index based on a feature that indexes only the lines where the predicate are both true so that the 2 update deletes the index entries and allows the index remain as thin as possible.
Concerning
Jonathan Lewis
-
Hello
I have a loop 'for' which can take different number of iterations according to the number of measures that the user wants to do.
Inside this loop, I'm auto-indexation four different 1 d arrays. This means that the size of the tables will be different in the different phases of the execution of the program (the size will equal the number of measures).
My question is: the auto-indexation of the tables with different sizes will affect the performance of the program? I think it slows down my Vi...
Thank you very much.
My first thought is that the compiler to the LabVIEW actually removes the Matlab node because the outputs are not used. Once you son upward, LabVIEW must then call Matlab and wait for it to run. I know from experience, the call of Matlab to run the script is SLOW. I also recommend to do the math in native LabVIEW.
-
Remove the performance of a large table or several small tables.
I have a table with 30 million lines, that is used in a statistic application developed in home treatment.
In the process, there is an application that will scan old records and then remove them from the database.
I'm looking for a way to improve it, and I am currently faced with alternatives:
Option #1
Separate the old records into several smaller tables, and then run several copies of the application, a single instance of the application by the smaller table.
Option #2
Use additional criteria to when choosing the rows of the table (which would be indexed on), an execution mulltiple of copies of the application based on the criteria.
From a logistical point of view, I'd prefer Option #2, my only concern with him is what's performance comparrison between:
50 processes Delete form 50 small individual tables with 100,000 rows in each
vs
50 to a table with more than 30 million lines removal process
Anyone has any experience on a preview?
We use an instance of Oracle 9i, no partitioning.
Unfortunately I don't have a lot of control in the application or make major changes to Oracle.940507 wrote:
It redundant seams, one of the reasons why I prefer Option 2, using additional criteria...I just need to make sure that when 20 process attempts to remove it from the same table with 30 + million lines, the contetion on the updating of the table, index... will not introduce a point of suffocation.
This can vary widely based on the distribution of data and model of data access. Oracle accesses data in blocks, so if someone updates an another line of the block while you delete, you could get a transaction wait. For playback from your deletion, Oracle is good, not blocking, but compromise can be a lot of waiting. If your data in the table such as two of your processes to remove from the same block, you could come back here crying on the performance and have people laugh design.
Rather than the mud things with more java spawning process, you may need to perform these deletions by a single stored procedure with very specific criteria. Then, rather that dealing with the issues of contention, you serialize everything to go as soon as possible and reduce to a minimum the block copy and cancel demand to keep multiuser. Oracle is biased in favor of adding data instead of delete, add will always be potentially more fast-able.
Think about this: http://jonathanlewis.wordpress.com/2011/04/19/more-cr/
-
Need some tips to merge the two table-manipulation functions
Hi guys!
Thanks to Johnsold, Helmut O'Brian and Jcarmody, who helped me through a string function complicated (for me, the noob of LV), I got away with my project and I'm very close to its end.
As I've described it here I wanted to explore an array of words combined with-, i.e. C1 - C10. Help, when I arrived, I was able to do. I also learned a few things and was able to do the following:
Original array: new table:
R1 R1
R2 R2
C1-C3 C1
K1 C2
C3
K1
I have this:
Original array: new table:
R1 R1
R2,R4,R7 R2
C1 R4
K1 R7
C1
K1
I was also able to combine these two functions

Now, back to my problem.
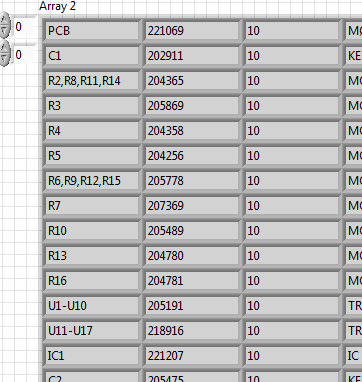
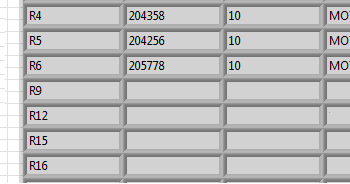
Until now, it was just a 1 d array that I worked with. In fact, it's a 2D array, I read a. CSV file:
As you can see there are a few places where things is combined with either - or by commas. I need to widen the first column as described above and as resolved in the thread I mentioned. Fact! No problem. I extracted the first column in table 1 d. Then expand it. Now, I need to replace in the original array and also expand all.
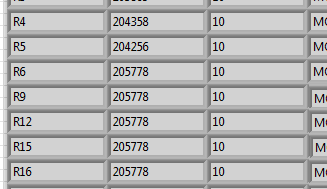
It should then look like this:
Then I only need to copy the position of the R6 line and paste it in the empty fields:
I enclose below two screws. Start by opening the main.vi. Then copy.vi. I tried to describe the problem here too. You can see what I've accomplished and what is missing.
Tasks:
1. replace the column expanded in the original array and expand all.
2 copy the needed lines.
In the main.vi, I do the 1 d expansion, but I have the problem with the expansion of table 2D. In copy.vi, I managed to copy the lines. If this part is done.
Basically, I need some advice on enlargement that I do and how do I get the 2D table also expanded. Because I have not much experience, I feel more comfortable working with 1 d arrays. But I can't seem to get any further with this 1 d-> expansion 2D.
I also really can't seem to find a smart way to implement my function of copy-line-in the main.vi.
P.S the joint screws are manufactured in LV2010.
Fortunately, I can attend some courses of basic home OR here in Norway, but so far, I'm still learning and I think that sometimes, I try to do things that are way out of my League

I don't know what I did but it works now
Thanks for the help, same!
You are even welcome!
Have attached the file if anyone wants to see what I did.
-
Views of repository for the performance table
Hi all
I found this page
[http://docs.oracle.com/cd/B19306_01/em.102/b16246/views.htm | http://docs.oracle.com/cd/B19306_01/em.102/b16246/views.htm]
on Oracle® Enterprise Manager extensibility
but I can't seem to find what I want.
Can someone tell me one I can find the information that powers the graphics on the performance tab? As "medium-sized active sessions?
I would like to create a graph of multiple target.
Thank you.
ARO
João Pinela.
Published by: Pinela on July 2, 2012 11:19I wasn't a link to monitoring views section. Specifically, you do not want to watch the following views:
MGMT$ METRIC_CURRENT
MGMT$ METRIC_HOURLY
MGMT$ METRIC_DAILY -
Performance overview tables appears no not after the upgrade...
After the upgrade to vcenter, the overview of the performance does not appear?
see this KB
-
ORA-29874: caution in the performance of routine ODCIINDEXALTER
Hello
I'm on Oracle 11.2.0.3
[code]
drop table test;
create table test of xmltype.
Insert in the test
values (')
< employee
" xmlns: xsi =" http://www.w3.org/2001/XMLSchema-instance "xsi: noNamespaceSchemaLocation =" "> ".
< location >
< joiningDate id = "on site" >
2012 06-18 of < hireDate > < / hireDate >
< / joiningDate >
< joiningDate id = "offshore" >
2011 07-8 < hireDate > < / hireDate >
< / joiningDate >
< / location >
(< / employee > ');
commit;
exec ('myprop') DBMS_XMLINDEX.dropParameter;
CREATE INDEX test_xml_index ON test (OBJECT_VALUE)
INDEXTYPE IS XDB. PARAMETERS XMLIndex ("test_dates_tab WAY of TABLE");
BEGIN
() DBMS_XMLINDEX.registerParameter
"myprop",.
' ADD_GROUP GROUP test_dates
XMLTable test_dates_tab "/ employee"
XMLNAMESPACES ("http://www.w3.org/2001/XMLSchema-instance" AS "xsi")
COLUMNS on the spot date PATH ".//*[@id="onsite"]/hiredate/text ()"
');
END;
/
ALTER INDEX SETTINGS ('myprop PARAM') test_xml_index;
[/ code]
When I run the alter index below I get the error.
I'm following the documentation to the Indexation of the XMLType data example 6-20
[code]
SQL > test_xml_index ALTER INDEX SETTINGS ('myprop PARAM');
ALTER INDEX SETTINGS ('myprop PARAM') test_xml_index
*
ERROR on line 1:
ORA-29874: caution in the performance of routine ODCIINDEXALTER
[/ code]
ORA-29960: line 1, ORA-02000: lack of keyword
Hello
The example you're referring to creates an index informal first, and then add a structured component.
Unless it's really what you want to do, simply create a structured index directly:
CREATE INDEX test_xml_index ON test (OBJECT_VALUE)
INDEXTYPE IS XDB. XMLIndex SETTINGS (q'~)
Test_dates_tab XMLTable ' / employees '
COLUMNS on the spot date PATH 'location/joiningDate[@id="onsite"]/hireDate '.
~'
);
If you want to use two components, and then specify a different XMLTABLE name of the path table.
See my response here for more tips:
-
Increase the performance of pl/sql delete
version: 10g
Hi all
Help me please by increasing the performance of the code below,
The code below takes about 10 min for deletion in 80 tables he recovered. Each table it does not remove more than 50,000 thousands
Is there another way I can increase the performance of the below.
I thought to delete forall, but I don't think its useful in this context.
DECLARE
v_num_2 PLS_INTEGER: = 50000;
BEGIN
THE C1
(SELECT master: '.) ' || table_name table_name
From all_tables owner WHERE = 'ARCHIVE' AND num_rows > 0 ORDER BY table_name
)
LOOP
BEGIN
EXECUTE IMMEDIATE 'remove'. C1.table_name |
"where arch_ts < (sysdate-530) and rownum < =' | ' v_num_2;
END LOOP;
END;
Thanks in advance
Without asking what purpose your code is used:
You can enable parallel DML and add a hint of parallel to your delete statement.
Something like (not tested, but you'll get the idea):
Start
immediate 'alter session enable dml parallel. "
--
C1 in (select master: '.) ' || table_name table_name
from all_tables
where owner = "ARCHIVE".
and num_rows > 0
-order of table_name<-- not="" really="" needed,="" is="">
)
loop
Start
run immediately "remove / * + parallel (t 4) * / ' |"
'from' | C1.table_name | |' t ' |
"where arch_ts".< (sysdate-530)="">
'and rownum '.<= 50000="">
end loop;
--
immediate "alter session disable dml" parallel execution
end;
/
You can test with different values for the declaration of principles (degree of parallelism), 4 in the index and find the optimal value.
-
How to speed up the performance of Tecra A4
How can I speed up my Tecra A4 performance. I don't want the usual diskfrag and the cleaning disc. Is there an I can change to improve the performance of specific parameters?
Hello
I put t know how you are familiar with computers, but the best way to optimase performance is to disable unnecessary applications at startup in MSCONFIG. Tecra A4 is beautiful unit. I put t know how much RAM is there, but if you want better performance I recommend you update maximum (2 GB). Upgrading, you can use compatible RAM module:
512 MB DDR2-400/533 (PA3412U - 1 M 51) and
1 GB OF DDR2 400/533 (PA3411U-1M1G).By the way: If you start the computer under Services management you will find a large number of settings and options. Check them and Google all over the place. Maybe you will find some tips how to disable someyou don t need.
One last thing: in Device Manager, you can disable all devices, you need t (modem, PCMCIA, or something similar). All these materials cannot be detected at startup.

Maybe you are looking for
-
Why iMessage is ask old Apple ID password
I have an iPhone 6 and just made the last update, IOS 9.3.3. Since that time, I had trouble with iMessage. I tried to send some pictures to someone a bit there and he said that he would not send without me turning on iMessage. He was already on, but
-
Safari slow after update to the last El Capitan
Hello! After the last update El Capitan (April 16), Safari has been slow. For example, goes from one URL to another usually take one or two seconds and takes up to 15 seconds. First of all, I thought that my cable provider was the culprit but then I
-
STOR. E ALU 2 s - detected as CD-ROM as opposed to USB HARD drive
I connected my HDD STOR. E ALU 2 s to my computer with Windows 8.1 and it does not recognize as a USB key, but as a CD. I can't open files because I did not have access to them; the computer tells me that the HARD drive is a CD and not a USB key, so
-
Programmatically, returned the error code 31
Hello I use NI PCI-5640R and NI PXI-5600 with Labview 2009. When I compile my FPGA VI, I get the following error message: "At AU!ERROR: Xflow - returned programmatically code 31 error. Aborting the workflow execution... " Could someone guide me what
-
I am having problems with getting my Outlook Express 6 to hang with my hotmail account.
I get an error Ox8OOcccOD code, hotmail server is not found. I had windows mail and had problems with my computer and my son uninstalled and reinstalled everything on my computer, and Outlook Express 6 has been installed. Can someone give me a help