VCSA - on a cluster? Or a way to Hyper-V import?
Hello
I have 4 ESXi servers. In some network a windows with HyperV server. Now I have vCenter directly under Windows. In the future, I would use VCSA. But I can't find some Hyper-V device.
Then?
1 / it is safe, when I VCSA on cluster with ESXi 4? But what will for example live motion in HA when the host with VCSA fails? Difficulty, cela not vCenter but must be online, right?
2 / it is hyper-v device somewhere?
Thank you very much!!!
Pavel
1 / it is safe, when I VCSA on cluster with ESXi 4? But what will for example live motion in HA when the host with VCSA fails? Difficulty, cela not vCenter but must be online, right?
Your assumption that the vCenter/VCSA must be online for HA to function is incorrect. You only need a connection for the initial setup of the HA agents on your hosts.
If the host running the VM VCSA/vCenter fails, HA will save the day as usual by restarting on another host, just like any other virtual computer. The HA restart process has nothing to do with the Webcam live migration/vMotion either (which would require vcenter).
So, if you have the choice between a stand-alone host with some hypervisor and a fully redundant cluster with HA and live migration, which is the best choice for the VM VCSA of accommodation should be fairly obvious.
2 / it is hyper-v device somewhere?
No, there is no device VCSA Hyper-V.
Tags: VMware
Similar Questions
-
Is there an easy way to convert graphics (imported from the common library) Composite path?
Hi all
This is my problem:
I had sex with any common library grapch, and I would like to convert to a Composite path. I had been using a manual method (double click on the image and copy the compound path, and then stick it on my main layer).
question:
Is there an easy way to convert graphics (imported from the common library) Composite path? as a shortcut, or other?
Image:

Thank you before and waiting for your responses
With the object selected, choose Modify > symbol > Break Apart. Then click Modify > ungroup.
-
Using a cluster, the best way to do it...
I wonder is there is a better way to group the controls to the right of the vi (see table). So that when you click on an arrow all the box copy this action.
Chaz
You're wrong matching data types. You must place the cluster within a table.
Range of table matrix Cluster-> table control
Drag and drop your cluster within the table.
Or right-click on the tunnel exit in your loop and select Create-> indicator
-
Y at - it an easy way to create or import tables in muse
I am trying to create a Web site that uses tables for things like rankings and results, but I need an easy way to put them in the muse.
I got a discount to create tables in dreamweaver and import the HTML resulting, and I created tables in Indesign and imported as JPEG files, but this of course so does not allow me to change on the fly.
If anyone can help.
It has developed before on the other forum many times, and still there is no way to import editable tables directly in Muse.
-
any way to cut bookmark import html name .url?
just inside bookmark.html IE and note that all bookmark see as XXXXX.url?
Why? Bookmark.html Checked in IE, not .url here.sort of cut ".url"?
Please notify.
Thank you. I thought he did something wrong.
Detective Conan. -
I want to import pictures from my iphone / ipad to lightroom, but only the collections of synchronization on the ipad. My iphone is 'space challenged' so I do not want to synchronize collections on my iphone, but need to synchronize collections to my ipad to share with clients. Is it possible or are collections sync'd with all mobile devices in the cloud?
No, but really, what takes place when you set the edition offline. So activate it on the iPad, leave it disabled on the phone.
-
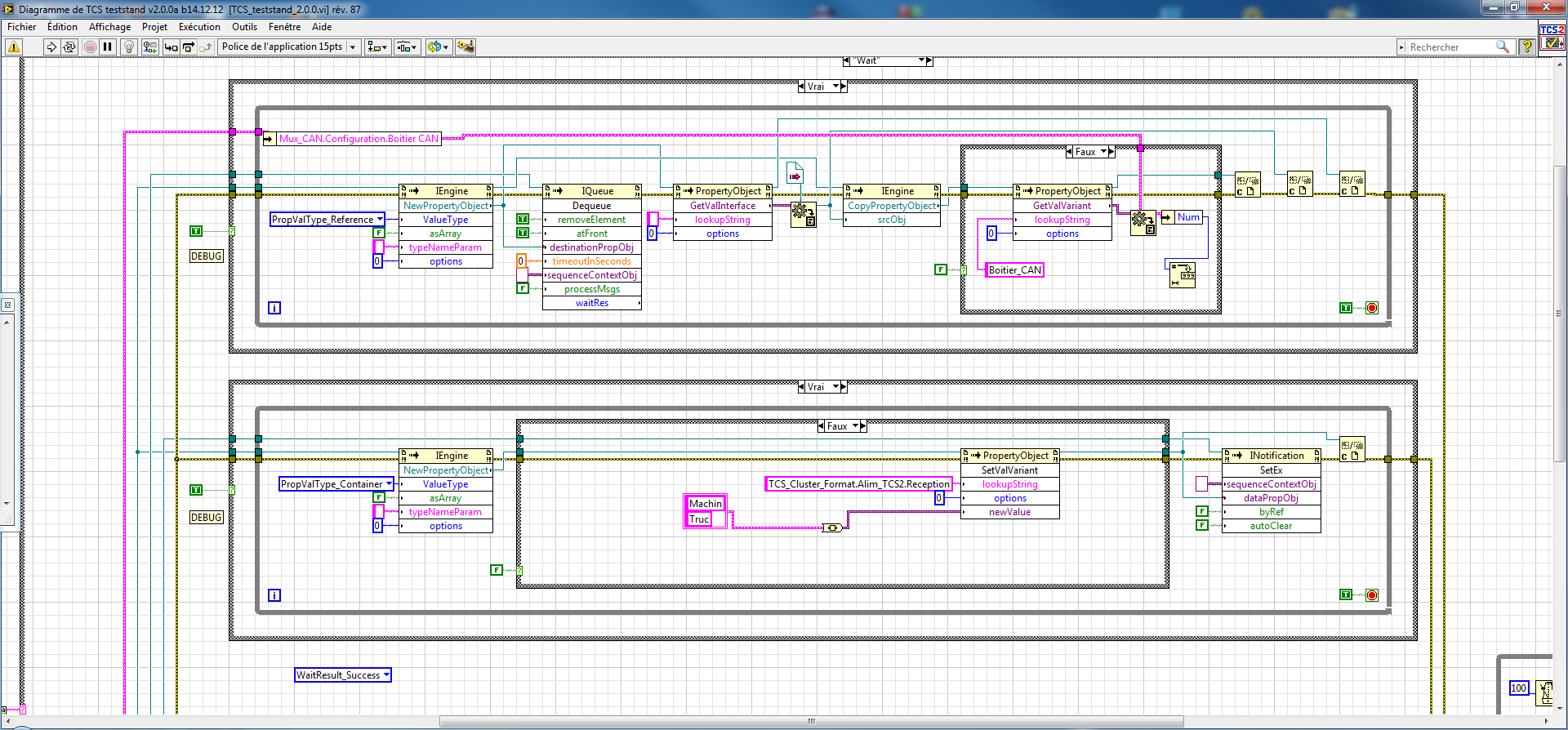
Enqueue cluster for Labview Teststand, return a cluster by notification
Hi all
I get very very frustrated that I can't find a way to spend
an asynchronous VI with a cluster of Teststand reflecting a LV
cluster using a queue.
This works if wire you the cluster Teststand for the VI is there
an order appropriate to link to. Yet, the VI has no
Connector, he expects that a cluster in queue, read of the
PropertyObject by 'GetValVariant', do some magic
and is supposed to return another cluster using Teststand
a notification
I can read singular elements of the cluster in queue, but cannot
Run in a cluster of LV with, say, the good old 'VariantToData '.
which indeed works great inside LV
Same thing happens when I try to regain a Teststand cluster
using 'SetValVariant' even if both the Teststand cluster
and the cluster of LabView are the same format and structure.
The 'Wait' Teststand notifier action is linked to the right cluster
property, but Labview fails at the "SetValVariant", because not of
the right type, even if I have sunk the variant data.
I wonder if I do wrong or Teststand and Labview
are simply not designed to work together seamlessly.
Here's the example I'm putting in place, but the reading of the
cluster fails, while the alternative 'False' works (123.00)
Defining the notifier cluster fails too, but its definition the
elements indivualy also fails because Labview is
What are 'Compliance' and 'Comments' in
the 'True' alternative, although I tried all
hierarchy tree.
You might have figured out, but I really really need to
get this working, and I can't understand where the
default is (next between the Chair and the keyboard) because
the principle works in LabView.
David Koch
Okay guys, I give up all hope, that I had to do this work.
This is a WIP Teststand container/Labview cluster motor relay.
TestStand 2013-> TCS_main_2.0.4.seq (run TCS_teststand_2.0.0.vi)
LabVIEW 2013-> TCS_teststand_2.0.0.vi (run TCS_instruments_2.0.0.vi)
LabVIEW 2013-> TCS_instruments_2.0.0.vi (interface instruments)The main idea was to catch Teststand queued of containers,
convert a Variant, to analyze their structure and
to match with their counterpart of cluster of Labview.The engine is initialized to 'learn' the Labview
data structures, storing the data type and the names of the clusters
different elements, as well as the cluster hierarchy.A format of target data type and an associated action are also
stored for each identified cluster/container.Then the engine is waiting for incoming Teststand queue
containers, convert them to a Variant, to analyze their
structure and * TRY * to match with the stored
having been analyzed Labview homologous groups.This is what I call the "footprints".

The three main problems were... are:
1 - different naming convention (TCS_string_teststand_name_convert_2.0.0.vi)
2 - format of different data type (TCS_variant_tree_convert_2.0.0.vi)
3 - different (TCS_propertyobject_tree_parse_2.0.0.vi) data structureI think I was very close to resolving these issues, but I'm
short on time. As an entrepreneur, I've spent
more than a month of work on this value. Who is
too many given my dead line.I'm quite sad to be leaving this unfinished, he would have
was great to get the motor relay pole upward and
running, having just to place a container Teststand
to get something done automatically at the other end
and just wait for a notification sent for analysis.What's left to do is the following, as an exercise
left for the reader:To "explode" the data structure to correspond to of Teststand "
still more verbose simpler data formatThis means for example that a Labview wave have to
be transformed into a cluster of 3 datas. You can read the
suite of document, but it is not very clear on how
The LabVIEW data type formats are converted to their
corresponding Teststand counterpart:http://zone.NI.com/reference/en-XX/help/370052N-01/tsref/infotopics/labview_data_types/
Beware, this involves a lot of trial and error, as
creating a large Labview cluster with all data
type of support, import it in Teststand and create
a custom, data type and then compare each converteda data type.
B point A would improve the adequacy between Teststand
containers and clusters of Labview.With a longer data structure mirrored, it will indeed
help 'TCS_fingerprint_search_2.0.0.vi' to compare
the structure of the Teststand container with the correspondent
LabVIEW cluster structure, the elements names
Always different Convention.Conversion of data format C - needs to be done, place holders
are ready to be filled.There are still a lot of work to do in 'TCS_variant_tree_convert_2.0.0.vi '.
Remember that the type of data "FileGlobals.tcscluster".
mirrors (wise Teststand) the 'TCS_instruments_2.0.0.ctl '.
type definition.This means that a string has not transformed a waveform.
Data format should be very close to each other. That's why
There is no need to focus too much on these "exotic" data
format conversions.Thanks again to all the people who have invested some time
in trying to help me solve this issue.Thanks to nathand for its cluster monitor not recursive.
David Koch
-
Cluster Hyper-V CSV allocation unit size
Hello. Is there any recommendation Dell when it comes to the size of the allocation unit of the NTFS volumes that serve as CSVs (Cluster shared Volumes) in a Hyper-V cluster?
Using EQL LUN in the background apparently.
Where should we go with the default using Windows (based on the size of the volume/LUN) or should I use something different to optimize performance, for example 64 k?
CSV store virtual machines with different workloads, nothing specific, such as SQL pure or web servers, etc..
Thanks in advance.
Hello
Cluster size when you format a volume must always be 64K. Which corresponds to the size on the spreadsheet. Writing in complete stripes is the most effective way, it reduces the overhead of RAID.
Kind regards
Don
-
vCenter 5.5 cluster using Fibre Channel & MSCS (Win 2003)
Hi all
I need to create a Cluster of 2003 of Windows (MSCS) as well as storage Fibre Channel shared on vCenter Server 5.5. I need to work so that if a server crashes, the second server goes into action and support.
I have a two-node Windows 2003 R2 64 bit running on the same host. Virtual machines are created with an operating system installed. I use for Fibre Channel storage and I have created and attached 6 discs in thick eager set to zero. I also created and configured two NICs (Public and private) on each node. The shared SCSI Bus is set to "Virtual" on both nodes. I managed to get the two nodes to market and both can see the 6 disks. The disk configuration is identical between nodes. All drive letters to even the SCSI virtual peripheral nodes (1:X).
I have not yet created the Windows cluster. The problem is that, in node 1 when I create a folder in one of the attached disks, I don't see this folder in the same drive in node 2. Is it a problem, a bad configuration or is this a normal behavior?
Are there any other setup that I should consider to make this work?
It's the doc that I follow:
Thanks much for any help!
Since you not yet configured the cluster, this is normal behavior. Go ahead and configure the cluster, then the software cluster will manage the discs... do what you try can cause data corruption.
And after the configuration of the cluster, take in mind that the drive will be online to a single node by time, as the Microsoft cluster is an active/passive cluster, in this way you will be able to see the disc and online with the letter assigned only on the active node.
-
Disassembly of cluster 5.1 ESXi
Hi all
I have a problem. I have cluster HA (without DRS) of two nodes, now I want to spend these two nodes to different vCenter (new) and to build a new three-node HA cluster there.
Can I disassemble my current HA cluster, remove nodes old vCenter, connect hosts to the new vCenter and build without disturbing HA cluster virtual servers hosted on these nodes vm?
concerning
I guess that you have a HA cluster with 2 ESXi host & guests have some virtual machines running on them. Now you have a different vCenter & don't want to create a new cluster with 2 ESXi host to vCenter old + you want to add a new ESXi host.
Here is the recommended method to do the same thing:
1. walk old vCenter HA cluster > right click > change settings > disable HA
2. Once you disable HA on the old vCenter, HA agent will be out installed as well.
3 tell - the old cluster host or connect immediately to remove the cluster.
4. create the new cluster > add all 3 hosts (2 removed from the old cluster + 1 new host) in the new cluster.
5. activate HA on the new cluster > This will install HA agent on all hosts 3.
6 configure the cluster HA the way that suits you (admission control strategies, datastore pulses etc.)
Note: Your virtual machines always work on hosts that have been removed/disconnected from the old cluster. Please note that until you add to the new Vcenter cluster, there is chance that host disconnected can go down for some reason any & your virtual machines can cope in time to stop. That is why, first follow the new vCenter, create the cluster in advance > configure HA & then remove old cluster.
-
An easy way to re-import massive media after a hard disk crash if the library files are intact?
Hello
I'm running 10.2.3 on OS X 10.11.3 FCPX. My external hard drive just crashed, and while I was able to save most everything else (including library files, proxy support, etc.), Miss me about 90% of the media about 2 000 "original" files. Because the library files have been saved, it seems that my projects seem to be intact, including the cuts and changes. Since FCPX knows what files and parts of files were previously imported, import should be easy... except for the fact that there are about 1 800 distributed clips on dozens of camera archives.
Is there a way to 'massive re-import' office where he knows the clips came, without having to wade through thousands of clips in dozens of archives and manually by clicking on each of them? Because there is also the fact that, due to several archives of the camera used, different are multiple "Clip #1", "Clip #2", etc. that FCP is solved by adding a number at the end (for example, "Clip #1 (fcp1)" and "Clip #1 (fcp2)"). " I'm afraid that if I import everything in disorder (maybe I not initially import a clip, but returned later and get it), I'll have to sift through to find a needle in a haystack and rename the files manually.
Even if I have to specify the locations of these archives of tens of couple, it would be so much easier than having to go into each of them and click 1 800 files manually... Any suggestions?
Please and thank you!
Too bad. I had assumed the import > reimportation of the camera wasn't working, but apparently because I had saved the AVCHD archives on my hard drive via the Finder instead of 'Create the Archives' of in Final Cut, he just didn't see them. Creating new archives of these same AVCHD files (or rather the folders 'PRIVATE' which originally housed them on the SD card) did the trick and I was able to reimport. Alternatively, I could have re-recorded these SD cards PRIVATE folders and it would have identified those as the original 'camera' once again, too and I could have reimported it... but who would be tedious.
-
import a class: how many ways are there? CFC, import, extend the base class
How many ways is there to import a class and am I confused
1 screen/public class extends MovieClip
This inherits all the properties and methods of the MovieClip class so WHY again do we use: import flash.display.MovieClip;
Import something else or just made the job twice
2 import flash.display.MovieClip - so no need to extend (repeat me once again - see 1)
3 CFCS: connect to a CFC
4. stir in a SWF with a meta tag
5. in the properties panel menu - add a class as a base class
OMG - a bit confusing
You can only "extend" another class if the compiler knows where he is.
The import statement is only by the compiler to find the class on your hard drive.
It is not "import" of the entire class in the sense that you import a BMP in Photoshop.
-
What is the best way to import and export images from the 5 d Mark II?
Hello
I have just finished what I plan my first masterpiece of shooting film. Shot on the Canon 5 d (1080 p, 24 fps), and the film looks amazing. Now, I'm ready to start editing and now use creating lately, but I still have to figure out the proper conduct. I want to know the best way to keep the resolution before I dive into this project.
My questions:
(1) what is the best way to start a new project and import the images without having to make while editing, in order to keep all the resolution and the originality of the source footage?
(2) what is the best way / codec / format to export these images even once done editing to maintain than crisp 1080 p for which the 5 d is therefore counted?
(3) what is the best way / codec / format for import and export / rendering between the first and after effects? I speak especially of Visual effects and color correction. I also a few sequences of 30 images per second that I intend to slow down in AE and then import into first.
I know that it's wide enough, but as a solo Director I really need advice from someone. Rarely, I finished my films with the same look crispy as images. I need help of pipeline and really appreciate it!
> used first lately
A list of tutorial in the #3 http://forums.adobe.com/message/2276578 message
1 - Please NOTE that the PPro CS6 screen may be a little different (I use CS5)
For CS5 and later versions, the easy way to ensure that your video and your project
See 2nd post for the photo of a NEW ELEMENT of process http://forums.adobe.com/thread/872666
- and a FAQ on setting http://forums.adobe.com/message/3804341 sequence
2 - BluRay... but I'm not sure if 1080 p is supported (I don't use of BluRay)
1080 p http://forums.adobe.com/thread/995191 some work, some are not
In addition, for upcoming posts, information FAQ http://forums.adobe.com/message/4200840
In addition, read the metadata contained in the file http://forums.adobe.com/thread/1015001?tstart=0
And finally, read Bill Hunt on http://forums.adobe.com/thread/919388?tstart=0 installation project
-
Reference DELL VRTX Shared Storage for cluster
Dell administrator and specialist out there, I need help!
I have a VRTX and 2 nodes of Cluster of Windows Server 2012 Hyper-V running. I want to migrate to Windows Server 2012 Hyper - V R2 cluster (using another 2 blades) but will use existing storage. Seems that I can't use the existing storage again, I assigned the virtual disk of the CMC. In Failover Cluster Manager > disc, I got error "the requested resource is in use. Cluster event log, I got:
1069-
Cluster resource ' Cluster disk 1' type "Physical disk" in the role of cluster '9c5e9411-cddd-4496-8 ch. 57-9be758e788a1' failed. "
1038 - ownership of cluster disk 'disk 1' Cluster unexpectedly lost by this node.
I'm currently stuck here. Cannot make the 2012 R2 to access the existing cluster disk. Can someone tell me what is my mistake, and if there is no action to be performed on the CMC or Windows?
Thanks in advance for your help...
Found the answer. See the CSV property. During migration, the cluster to copy can be used to migrate the roles of clusters. But the disc may not be online on two clusters as a cluster have the property. So the steps, you must run the cluster to copy first, then turn off your VM on the old cluster and make the CSV file in offline mode. Then do the WB Online on the other node, run your VM on your new node with the new cluster. This solved my issue.
-
Error 0xBFF62133 with NI-CAN on NOR-XNET
My C application was written with the NI-CAN Channel API and works very well on the old cards PCI - CAN. Now he runs on a PCI-8512 OR XNET 1.3.0 with the NI-CAN 2.7.2 compatibility library and falsely, it gives this error: "NI-CAN: (Hex 0xBFF62133) you set an attribute that is not supported when Virtual Bus Timing is off." Refer to the section of frame channel Conversion of the NI-CAN manual for a list of the attributes that return an error when Virtual Bus Timing is false. Solutions: 1) Set Virtual Bus Timing true (or leave as default). "(2)"do not set the attribute not supported."
My application does not frame channel Conversion or the virtual Bus to use directly, it turns to speak directly on the bus hardware CAN0 via the channel API. Use the compatibility library the virtual Bus?
How can I avoid this error?
Thank you.
So the actual error you see is 0xBFF63133, not 0xBFF62133 (starting with 0xBFF63 - error codes are errors OR XNET). This is due to a bug in the way the database is imported (several threads all try to create a cluster with the same name, where the error "name of the cluster in double").
While the bug will be fixed in the future, in the meantime, you need to make calls to sequential nctInitStart. I recommend a small function that catches a global mutex and then calls nctInitStart. Sorry for the inconvenience.

Maybe you are looking for
-
404 not found error was encountered while trying to use an ErrorDocument directive to manage demand
When I try to go to my site, I get a blank screen and this message: Method not implemented GET to / not supported. Additionally, a 404 not found error was encountered while trying to use an ErrorDocument directive to manage demand. Can someone help m
-
Flow iPod to the laptop using toshiba a2dp
Hi, ive tried to use my computer toshiba laptop as speakers for my iPod. It's an iPod touch 2g with OS 3.0 and I tried with a BT headset, so I don't know for sure it can broadcast some audio a2dp. As I understand it the ability to profile a2dp-sink i
-
Satellite A100 series - Express media player does not turn off!
I had to restart my laptop after completing the update of windows, and after rebooting, it does not start in Windows, but for Express Media Player instead. The drive will turn off little matter what I do so I press on and press and hold the power but
-
My HP photosmart 6510e all-in-one scan only black and white.
How do I change this color scans? Just bought. And I can't scan document in color. Only when I use the scan for the photo. But then the scan is very low. When you have the answer thank you in advance. Kind regards Jeroen The Netherlands
-
Transportation jams, always on the left side, always 3/4 this page
Printer HP all-in-one HP Envy 110 Jams of transport, always on the left side, always about 3/4 per page