XML data convert the data of the item only
Hello everyone,I create a form that uses the web service. My exit came in the form of xml as...
< NewDataSet >
< table >
< PRIVATE_MARKA_BATCH_NO > 0622 < / PRIVATE_MARKA_BATCH_NO >
< /table >
< table >
CABINET < PRIVATE_MARKA_BATCH_NO > < / PRIVATE_MARKA_BATCH_NO >
< /table >
< / NewDataSet >
I want to only data element as 0622, WARDROBE. Is it possible to delete the titled XML? Help, please...
Forms [32 bit] Version 10.1.2.0.2 (Production)
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
also
SQL> select * from v$version where rownum=1;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod
SQL>
SQL> select trim(column_value)
2 from (select xmltype('
3
4 0622
5
6
7 DOOR CABINET
8
9 ') xml
10 from dual) t,
11 xmltable('string-join((for $i in /NewDataSet/Table/PRIVATE_MARKA_BATCH_NO return $i), ",")'
12 passing t.xml) x
13 /
TRIM(COLUMN_VALUE)
--------------------------------------------------------------------------------
0622,DOOR CABINET
SQL>
Tags: Oracle Development
Similar Questions
-
Listing of the items only from a specific range
Hello
I have a list of about 100 pages, each of them using date_create variable to the date, they were entered in the database; These entries are the years 2005 to 2008. I need the list of those of the last only six months, but without Hardcoding specific values, then it automatically displays the correct list. Could someone edit me the code for this?
The code I am using right now is:
< name cfquery = "disp_news_arti_curr" datasource = "" #Request.MainDSN # "CACHEDWITHIN =" #CreateTimeSpan (1,0,0,0) #">"
SELECT
URL, name_pub, date_create, author_pub, id_news_arti, title
Of
data_news_arti
WHERE
"status = 1 AND date_create > = ' 01 Sep 2005.
ORDER BY
date_create DESC
< / cfquery >
Thank you
[email protected]
Thank you for all your help. I inherited this web site focused on CF and have very little knowledge of this technology.
I was able to apply some of your comments to change the code. Here's the final copy:
SELECT the url, name_pub, date_create, author_pub, id_news_arti, title
OF data_news_arti
Situation WHERE = 1 AND date_create > = #last_six_months #.
ORDER BY DESC date_create
Thank you very much.
jstama -
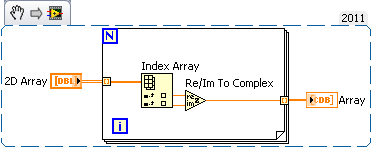
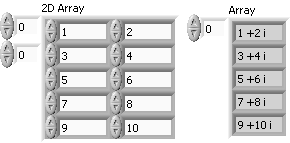
convert the items in table re / im values?
I 2Darray and want to convert its components to re / im values
want to be
26 + 49i
81 + 93J
and you want that all values are not specific, we (myself cant input values) wants to ground for general caseYes you can do this by using the function given by rolfk
-
Show the item only after the process ran
Hello
I have 3 questions:
-: P1_ENTERED_VALUE (text field)
-: P1_DEFAULT_VALUE (display text)
-: P1_DIFF_VALUE (display text)
Users enter a value in: P1_ENTERED_VALUE and trigger a process with a button.
The process compares the number of: P1_ENTERED_VALUE with: P1_DEFAULT_VALUE and fills: P1_DIFF_VALUE. So far, it's working.
What I want is: P1_DEFAULT_VALUE and: P1_DIFF_VALUE are not displayed until the key was pressed.
What I tried: because: P1_DIFF_VALUE is null until the process, I put a condition to element: P1_DEFAULT_VALUE:
-Condition Type: "value of element in the Expression 1 is NOT NULL"
-1 expression: P1_DIFF_VALUE
If the colon (: P1_DEFAULT_VALUE and: P1_DIFF_VALUE) would show only after that the process is running.
The problem is that: P1_DIFF_VALUE now always shows 0 and no difference, because the element with the condition (: P1_DEFAULT_VALUE) obviously to not just hidden before the process, but too inactive.
How can I solve this problem?
Thanks in advance,
RogerRoger:
The calculation of P1_DIFF_VALUE should be done using the element hidden in which you retieved "by default".
The hidden element should not be subordinated.
Are these two statements true for your page?CITY
-
Validate the value of the item only with the alphabets and hyphen
Hi Experts,
I have a text field element, I want to create a posting as
It must contain a hyphen as a separator
example: -.
valid entry
A B
AA-BB-CC
Invalid entry
-A, A-,AA-AB-,-BC-CC-etc.
I tried certain regular expressions but found no solution,
Please suggest me a solution
Kind regards
Jitendra
declare v_check_string varchar2(4000); v_error_message varchar2(32767); begin v_check_string := trim(:p1_text_field); if ( v_check_string is null or ( translate( v_check_string, '#ABCDEFGHIJKLMNOPQRSTUVWXYZ-', '#' ) is null -- only alfabetic and - and substr( v_check_string, 1, 1 ) != '-' -- first character not - and substr( v_check_string, -1 ) != '-' -- last character not - and instr( v_check_string, '--' ) = 0 -- not two ore more repeating - ) ) then null; -- valid string else v_error_message := 'String: "' || v_check_string || '" is not valid'; end if; return v_error_message; end; -
Insert a link on the xml report. The link must open a document (PDFS).
Is it possible to insert a link in the report? The value would come from a sql query. The link when clicked on would open the pdf or doc.
This is done through a href or by inserting a hyper dynamic link.
Version 5.6.2 Release documentation reference how to insert a hyperlink. Not sure if this will work for me.
I tried, but in literature, he States:
>
If your input XML data includes an item that contains a hyperlink, or a part of
one, you can create dynamic hyperlinks when running. In the Type of file or Web page
domain name of the dialog box insert hyperlink, enter the following syntax:
{URL_LINK}
where URL_LINK is the name of incoming data item.
>
However the dialog I get when I inserted the hyperlink does not have a place to enter the item name. In other words, there is no "TYPE of file or Web page" area that I see.Hi ashalon,
I made this way in MS Word.
1. create the placeholder for the value
2. put highlight and make a hyperlink
3. Enter the url in the address barSo if you have a complete hyperlink in the URL_LINK xml element you just enter {URL_LINK} in the address line. If you have only a part of the link, IE only a product name, you can enter 'http://www.oracle.com?product= {PRODUCT_NAME} ".
I hope this helps.
Concerning
Chrissy -
The analysis of the external Web service XML data IS
Hi all
I'm looking to analyze the data returned by the Scopus API with Apex webservice.
First of all, I tried parsing the JSON, however, it seems that the apex_json.parse function does not produce a result when the string contains a ':' character. (It looks a lot like the webservice returns returns a JSON XML version below, namespace and all).
I moved from the attempt to analyze the XML code that is less a model to:
<?xml version="1.0" encoding="UTF-8"?> <search-results xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/" xmlns:prism="http://prismstandard.org/namespaces/basic/2.0/" xmlns:atom="http://www.w3.org/2005/Atom" xmlns="http://www.w3.org/2005/Atom"> <opensearch:totalResults>2</opensearch:totalResults> <opensearch:startIndex>0</opensearch:startIndex> <opensearch:itemsPerPage>2</opensearch:itemsPerPage> <opensearch:Query role="request" startPage="0" searchTerms="authlast%28ryan%29+and+af-id%2860017837%29"/> <link type="application/xml" href="http://api.elsevier.com:80/content/search/author?start=0&count=25&query=authlast%28ryan%29+and+af-id %2860017837%29" ref="self"/> <link type="application/xml" href="http://api.elsevier.com:80/content/search/author?start=0&count=25&query=authlast%28ryan%29+and+af-id %2860017837%29" ref="first"/> <entry> <link href="http://api.elsevier.com/content/author/author_id/7402922277" ref="self"/> <link href="http://api.elsevier.com/content/search/author?query=au-id%287402922277%29" ref="search"/> <link href="http://www.sco pus.com/author/citedby.url?partnerID=HzOxMe3b&citedAuthorId=7402922277&origin=inward" ref="scopus- citedby"/> <link href="http://www.scopus.com/authid/detail.url?partnerID=HzOxMe3b&authorId=7402922277&origin=inward" ref="scopus-author"/> <prism:url>http://api.elsevier.com/content/author/author_id/7402922277</prism:url> <dc:identifier>AUTHOR_ID:7402922277</dc:identifier> <eid>9-s2.0-7402922277</eid> <preferred-name> <surname>Ryan</surname> <given-name>Philip J.</given-name> <initials>P.J.</initials> </preferred-name> <name-variant> <surname>Ryan</surname> <initials>P.J.</initials> </name-variant> <name-variant> <surname>Ryan</surname> <given-name>P. J.</given-name> <initials>P.</initials> </name-variant> <name-variant> <surname>Ryan</surname> <given-name>Phil</given-name> <initials>P.J.</initials> </name-variant> <document-count>28</document-count> <subject-area frequency="47" abbrev="AGRI">Agricultural and Biological Sciences (all)</subject-area> <subject-area frequency="24" abbrev="EART">Earth and Planetary Sciences (all)</subject-area> <subject-area frequency="15" abbrev="ENVI">Environmental Science (all)</subject-area> <affiliation-current> <affiliation-url>http://api.elsevier.com/content/affiliation/affiliation_id/60006905</affiliation-url> <affiliation-id>60006905</affiliation-id> <affiliation-name>CSIRO Forestry and Forest Products</affiliation-name> <affiliation-city>Kingston</affiliation-city> <affiliation-country>Australia</affiliation-country> </affiliation-current> </entry> <entry> <link href="http://api.elsevier.com/content/author/author_id/56970474800" ref="self"/> <link href="http://api.elsevier.com/content/search/author?query=au-id%2856970474800%29" ref="search"/> <link href="http://www.s copus.com/author/citedby.url?partnerID=HzOxMe3b&citedAuthorId=56970474800&origin=inward" ref="scopus- citedby"/> <link href="http://www.scopus.com/authid/detail.url?partnerID=HzOxMe3b&authorId=56970474800&origin=inward" ref="scopus-author"/> <prism:url>http://api.elsevier.com/content/author/author_id/56970474800</prism:url> <dc:identifier>AUTHOR_ID:56970474800</dc:identifier> <eid>9-s2.0-56970474800</eid> <preferred-name> <surname>Ryan</surname> <given-name>Peta</given-name> <initials>P.</initials> </preferred-name> <document-count>1</document-count> <subject-area frequency="2" abbrev="NURS">Nursing (all)</subject-area> <affiliation-current> <affiliation-url>http://api.elsevier.com/content/affiliation/affiliation_id/60017837</affiliation-url> <affiliation-id>60017837</affiliation-id> <affiliation-name>University of New England Australia</affiliation-name> <affiliation-city>Armidale</affiliation-city> <affiliation-country>Australia</affiliation-country> </affiliation-current> </entry> </search-results>
So far, the best I could do is to extract the total results by XMLTable:
SELECT results.totalResults INTO numResults FROM XMLTable( XMLNamespaces( default 'http://www.w3.org/2005/Atom', 'http://prismstandard.org/namespaces/basic/2.0/' as "prism", 'http://a9.com/-/spec/opensearch/1.1/' as "opensearch", 'http://purl.org/dc/elements/1.1/' as "dc"), '/search-results' PASSING xmlResult COLUMNS totalResults NUMBER PATH '//opensearch:totalResults') results;
I'm not convinced that using XMLTable is the best solution, but that's what I've learned to work. Take it further proves to be more problematic.
Ideally, what I want to do is get the Subproperty, favorite-name/given-name, favorite-name/initials, favorite-name and affiliation-affiliation/current-name in a collection, as well as the entrance of <>... < / input >. The user can then select the correct author, and we can use the full set of data to process.
I'm sure that my problem comes down to manage multiple with XPath, although namespaces that putting my XPath through Validator online gives the desired result, it does not work for me in my PL/SQL.
If someone could provide some tips and suggestions, I would be very grateful.
Thank you very much
Andrew Rochdale-MearesAndrew Rochdale-Meares wrote:
I'm looking to analyze the data returned by the Scopus API with Apex webservice.
I moved from the attempt to analyze the XML code that is less a model to:
So far, the best I could do is to extract the total results by XMLTable:
- SELECT results.totalResults INTO numResults OF
- XMLTable)
- XMLNamespaces)
- default "http://www.w3.org/2005/Atom",.
- "http://prismstandard.org/namespaces/basic/2.0/" as "Prism,"
- "http://a9.com/-/spec/opensearch/1.1/" as "opensearch".
- ("http://purl.org/dc/elements/1.1/" as "dc").
- ' / search result PASSING xmlResult
- COLUMNS
- totalResults NUMBER PATH ' / / ' opensearch:totalResults) results;
I'm not convinced that using XMLTable is the best solution, but that's what I've learned to work. Take it further proves to be more problematic.
Ideally, what I want to do is to get the Subproperty, favorite-name/given-name, favorite-name/initials, favorite-name and affiliation-current/affiliation-name in a collection, as well as of the
. . The user can then select the correct author, and we can use the full set of data to process.The results using XMLTable of shredding is the best way to get results in a collection.
I'm sure that my problem comes down to manage multiple with XPath, although namespaces that putting my XPath through Validator online gives the desired result, it does not work for me in my PL/SQL.
It is not clear where you encountered problems because no details of the attempts to obtain the required information has been provided. Is not clear from the description exactly what "...". along with the
... " means, so I assumed that you want to store this item as an XML fragment in the collection. It is therefore necessary to use a loop withapex_collection.add_memberas the most effectivecreate_collection_from_queryb2method doesn't have support to complete the collection XML column:... /* Assuming the xmlResult variable is set somewhere previously... */ apex_collection.create_or_truncate_collection('SCOPUS_RESULTS'); for scopus_entry in ( select se.* from xmltable( xmlnamespaces( default 'http://www.w3.org/2005/Atom' , 'http://prismstandard.org/namespaces/basic/2.0/' as "prism" , 'http://a9.com/-/spec/opensearch/1.1/' as "opensearch" , 'http://purl.org/dc/elements/1.1/' as "dc") , '/search-results/entry' passing xmlResult columns dc_identifier varchar2(64 char) path 'dc:identifier' , given_name varchar2(64 char) path 'preferred-name/given-name' , initials varchar2(64 char) path 'preferred-name/initials' , surname varchar2(64 char) path 'preferred-name/surname' , affiliation_name varchar2(256 char) path 'affiliation-current/affiliation-name' , entry_xml xmltype path '.') se) loop apex_collection.add_member( p_collection_name => 'SCOPUS_RESULTS' , p_c001 => scopus_entry.dc_identifier , p_c002 => scopus_entry.given_name , p_c003 => scopus_entry.initials , p_c004 => scopus_entry.surname , p_c005 => scopus_entry.affiliation_name , p_xmltype001 => scopus_entry.entry_xml); end loop; ... -
XML data in the table using sql/plsql
Hi experts,
Could you please help with the following requirement. I have the tags xml (.xml on a server file) below. I need to access this file and read the XML and insert into the db table using sql and plsql. Is it possible with the cdata below? And there is a nested this table.
Could someone please guide me if you have a sample code file and xml.
<? XML version = "1.0" encoding = "UTF-8"? >
< generation_date > <! [CDATA [17/11/2015]] > < / generation_date >
< generated_by > <! [CDATA [Admin Admin]] > < / generated_by >
< year > <! [CDATA [2015]] > < / year >
< month > <! [CDATA [01]] > < / month >
< author >
< author > <! [CDATA [user author]] > < / author > < author_initial > <! [CDATA [user]] > < / author_firstname > < author_country > <! [CDATA [author]] > < / author_lastname >
< author_email > <! [CDATA [[email protected]]] > < / author_email >
< author_data_01 > <! [CDATA []] > < / author_data_01 >
< author_data_02 > <! [CDATA []] > < / author_data_02 >
< items >
< article_item >
< article_id > <! [CDATA [123456]] > < / article_id >
< publication > <! [CDATA [Al Bayan]] > < / publication >
< section > <! [CDATA [Local]] > < / section >
< issue_date > <! [CDATA [11/11/2015]] > < / issue_date >
< page > <! [CDATA [2]] > < / print this page >
< article_title > <! [CDATA [title.]] > < / article_title > < number_of_words > <! [CDATA [165]] > < / number_of_words >
< original_price > <! [CDATA [200]] > < / original_price >
< original_price_currency > <! [CDATA [DEA]] > < / original_price_currency >
< price > <! [CDATA [250]] > < / price >
< price_currency > <! [CDATA [DEA]] > < / price_currency >
< / article_item >
< / articles >
< total_amount > <! [CDATA [250]] > < / total_amount >
< total_amount_currency > <! [CDATA [DEA]] > < / total_amount_currency >
< / author >
< / xml >
Thanks in advance,
Suman
XMLTABLE using...
SQL > ed
A written file afiedt.buf1 with t (xml) as (select xmltype ('))
2
3
4
5
6
7
8
9
10
11
[[12[email protected]]] >
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34-
35 end of sample data
36-
37 - assumptions:
(38 - a) XML may have several tags
(39 - b) eachmay contain more
40-
41 select x.gen_by, x.gen_date, x.mn, x.yr
42, y.author, y.auth_fn, y.auth_ln, y.auth_cnt, y.auth_em, y.auth_d1, y.auth_d2
43, z.id, z.pub, z.sec, z.iss_dt, z.pg, z.art_ttl, z.num_wrds, z.oprice, z.ocurr, z.price, z.curr
44 t
45, xmltable ('/ authxml')
from $ 46 t.xml
path of 47 columns gen_date varchar2 (10) '. / generation_date'
48, path of varchar2 (15) of gen_by '. / generated_by'
49, path of varchar2 (4) year '. "/ year"
50 varchar2 (2) mn road '. "/ month"
51, path of xmltype authors '.'
52 ) x
53, xmltable ('/ authxml/authors ')
from $ 54 x.authors
author of 55 path of varchar2 columns (15) '. / author'
56, path of varchar2 (10) of auth_fn '. / author_firstname'
57, path of varchar2 (10) of auth_ln '. / author_lastname'
58 road of VARCHAR2 (3) auth_cnt '. / author_country'
59 road of varchar2 (20) of auth_em '. / author_email'
60 road of varchar2 (5) of auth_d1 '. / author_data_01'
61, path of varchar2 (5) of auth_d2 '. / author_data_02'
62, path of xmltype articles '. / Articles'
63 ) y
64, xmltable ('/ Articles/article_item ')
from $ 65 y.articles
path id 66 number columns '. / article_id'
67, path of varchar2 (10) pub '. ' / publication.
68 road of varchar2 (10) dry '. / section'
69, path of varchar2 (10) of iss_dt '. / issue_date'
70 road of VARCHAR2 (3) pg '. "/ print this page"
71, path of varchar2 (20) of art_ttl '. / article_title'
72, path of varchar2 (5) of num_wrds '. / number_of_words'
73, path of varchar2 (5) of oprice '. / original_price'
74 road to VARCHAR2 (3) ocurr '. / original_price_currency'
75, path of varchar2 (5) price '. "/ price"
76, path of VARCHAR2 (3) curr '. / price_currency'
77* ) z
SQL > /.GEN_DATE GEN_BY YEAR MN AUTHOR AUTH_FN AUTH_LN AUT AUTH_EM AUTH_ AUTH_ ID PUB DRY ISS_DT PG ART_TTL NUM_W OPRIC HEARTS PRICE OCU
---------- --------------- ---- -- --------------- ---------- ---------- --- -------------------- ----- ----- ---------- ---------- ---------- ---------- --- -------------------- ----- ----- --- ----- ---
17/11/2015 Admin Admin 2015 01 user author user author [email protected] 123456 UAE Al Bayan Local 11/11/2015 2 is the title. 165 200 AED AED 250Of course, you'll want to change the types of data, etc. as needed.
I assumed that the XML can contain several "
" sections and that each section can contain several entries. Thus the XMLTABLE aliasing as 'x' gives information of XML, and supplies the data associated with the XMLTABLE with alias 'y' which gets the multiple authors, which itself
section of the XMLTABLE with alias 'z' for each of the article_item. CDATA stuff are handled automatically by SQLX (XML functionality integrated into Oracle's SQL)
-
convert the data-> layer mask vertex position position
I have 2 videos (A; (B) whose corresponding value of markers, I need to distort the video so the position of the markers would correspond to the position of the corresponding markers in video B.
The markers are easy to spot, but I can only request data followed the anchor layer,
while I can use for the distortion (Reshape, revision deform or Morph) the tools work with masks.
I need a way to convert the caterpillars position data to control individual mask points.
Someone knows or can write this script?
much help appreciated
Yes, as David said, with local Tracker2Mask mode, you can move individual points mask with track points of the tracker item AE.
See this tutorial:

Tracker2Mask - advanced functions and local change mask | mamoworld
My MaskTrackerPlus not help not in this particular case, since he cannot move together masks, but individual vertices not independently.
-
Load the XML data to the UNIX server directly to Tables of database relational
Is there a way I can load some data from an XML file in the Oracle Tables, without going through the input file XML in a directory of the Oracle server. My XML file resides on the UNIX application server. And I need to load the data directly into database tables. Without load them into the database directory.
Also, I'm looking for a solution that would not load my database much and affect other processes running. Can be done using SQL Loader?
Oracle database version: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64 bit Production
Thanks for the companions of answers!
There I helped to learn a lot of options.
But the easiest using UNIX server that worked for me was to use an XSLT transformation to convert the XML file to a delimited file. (Load the unix server, save the Oracle resources).
UNIX 'xsltproc' feature was not a bad option.
Then use SQL Loader to load into tables.
Bravo!
Rahul
-
Dear Sir
The current ver is 10gXe
I trf suite data through two table the Pl/sql procedure in table sales, filed (col) narr varchar2 (200)
How can I select all in xml?
is it possible to convert given below even even in Formate of xml
> < 1 INVOICE NUMBER < / INVOICE NUMBER >
< DATE 14/09/2011 invoice - > < / DATE of INVOICE >
< BILLING - >
Pipe of the first < DESCRIPTION OF PRODUCTS > carbon steel seamless < / PRODUCT >
CETSH < NUMBER > 73049000 < / CETSH-NUMBER >
QUANTITY < CODE > KG < / QUANTITY-CODE >
< QUANTITY > 40 < / QUANTITY >
< AMOUNT-OF-DUTY-set GAME > 3699 < / QUANTITY-OF-DUTY-INCURRED >
< / BILLING >
< / INVOICE-INSTRUCTIONS >You must use the getClobVal() method to convert the XMLType to a character data type:
... ).extract('/*').getclobval() as yourXML from demo_orders o; -
How to check the first < TAG > (* i.e. 1 node) of some XML data
Hi all
I have a Flash program (* in Actionscript 3) where I get XML data using XMLSocket.
I know how to access the different values with the knots and stuff like that, but I'm checking what the very 1st is < TAG >.
For example, I send to the program of the XML data. The XML data is 90% of the time a way and then after a while it will receive
Differently formatted XML data.
Here's what it looks like 90% of the time:
< FRAME >
< VAR MESSAGE =«...» " TEXT =«...» » / >
< VAR MESSAGE =«...» " TEXT =«...» » / >
< VAR MESSAGE =«...» " TEXT =«...» » / >
<... etc... / >
< / FRAMEWORK >
#########################################################
#########################################################
And the rest looks like at:
< TICKER >
< VAR="...." TEXT="...." />
< VAR="...." TEXT="...." />
< VAR="...." TEXT="...." />
<... etc... / >< / TICKER >
So what I try to do, is when I get the XML data, I want to check the 'node' very 1st data (* what is in bold above < SETTING > - and - < TICKER >).
I know how to get the specific/children items and their values, but I couldn't understand this.
So for, the node element/3rd of 1 such that I would have:
function dataHandler(e:_DataEvent):void
{
var XML = XML (e.data);
It would give me the 3rd node of the < FRAME > data XML...
var nodeThree:String is xml. MESSAGE[2].@TEXT;
}
I read on the property of 'parentNode' of the XMLNode class, but I could not understand if that's what I had to use...
Anyone know how I can check if FIRST data node is < TICKER > or < FRAME >... ??
Any thoughts would be much appreciated!
Thanks in advance,
Matt
You can use the methods of strings:
function dataHandler(e:_DataEvent):void
{
var XML = XML (e.data);
var s:String = xml.toString ();
{if (s.substr (0, s.IndexOf(">")).)} {(IndexOf ("frame") >-1)}
No matter what
} else {}
else to do
}
}
-
How the filter E4x Xml data in a tile list?
Hello!
I am trying to use a search box for some xml data that I have in a tile list. Can someone point me in the right direction?
Here is the list of tile:
< mx:HTTPService id = "GetXmlService".
resultFormat = "e4x".
Fault = "getXMLFault (Event); »
result = "getXMLResult (Event); »
showBusyCursor = "true" / >
< mx:TileList id = 'tileList '.
dataProvider = "{GetXmlService.lastResult.image}" "
itemRenderer = "CustomItemRenderer."
columnCount = "4".
columnWidth = "125".
number of lines = '2 '.
rowHeight = '150 '.
themeColor = "haloSilver".
verticalScrollPolicy = "on".
itemClick = "tileList_itemClick (event); "backgroundAlpha ="0"height ="487"borderStyle ="none"="30"right ="10"left ="10"/ >
And here is the XML data:
<? XML version = "1.0"? >
< Gallery >
< user name image = "People1' rating ="5"="yes"/ >
< / Gallery >
Hello
protected function searchFunc(item:Object):Boolean
{
var username:String = .@username (XML topic);
var insession: String = .@insession (XML topic);
username = (username.substr(0,ti.text.length)) .toUpperCase ();
var chkUser:String = (ti.text) .toUpperCase ();
If (username == chkUser & insession.toUpperCase () == "YES")
Returns true
on the other
Returns false;
}
I changed the variable names to make it a little clearer. Now whenever you perform a search it will only show according to Yes (Yes). You can have nested If more more complex application but remember there is always need to be a return to true or false for each record (item).David. -
XML data in the question text field
LC ARE 8.2.1.3
I have a web service that returns XML data and designer calls the Web service and the XML data meet a text field. It works very well.
My problem is getting the data out of the text field to fill in the various fields in my form. I have done a lot of research and have tried many different things but still can't get out the data. I did that my form is dynamic xml.
This is the last thing I tried:
-Begin Code-
Place in testData: initialize and the connectionSet is placed in Page1:Initialize.
var myXML = XMLData.parse (xmlData.rawValue, false);
var subNames = XMLData.applyXPath (myXML, "//Subordinates/Subordinate/full_name");
If (subNames == null) {}
No data
} Else if (subNames.length == null) {}
No picture, just a single value
topmostSubform.Page2.testData.addItem (subName.value);
} else {}
for (var i = 0; i < subNames.length; i ++) {}
topmostSubform.Page2.testData.addItem (subName.item (i) .value);
}
}-Code of end-
I worked on it for 3 days and still can not make it work. The closest I came is out in my testData field that says "Object23485968".
Thanks in advance for your help
John
I forgot the file ACL
Paul
-
Error specifying the spry xml data source?
I have been using Spry in Dreamweaver XML data sets without any problem until I added the YUI calendar widget. After that, I get a message error "no entity expected to name reference (65: 23). Also, there is no evidence in the bindings panel. I have a Mac OS X, which I find very frustrating after being on a PC for 15 years. I can never find anything that I am looking help section.
Here's what I tried to present this has not worked.
1 removed the YUI extension
2. remove the * file *.dat in the folder of configuration in the user library folder
3 Rename the configuration folder in the user library folder
4 copy the folder of my laptop configuration library works
5. uninstalled and reinstalled Dreamweaver CS4
I can code everything by hand, but it of a lot of your time and makes the software a virtual paper weight.
I would be recognizing an advisor who may be offered.
Preference for programs files Mac is in your user folder/Library/Preferences account. The files that DW and other applications create end in .plist. These files are created by Mac OS for many applications. If you delete one, the operating system will be re - create another preferences file the next time the application opened.
Also other files DW records during a re - install are saved only if you go through the uninstall process and enable this option. It's the same for the Windows version. Sometimes if there are strange errors you can contact Adobe support for more information.
If not and you need to do a reinstall, I would recommend disabling everything first. Then, by running the adobe CS # own tool. Just type this phrase into Google and you'll find the best result for CS3 or CS4.
Adobe - Adobe CS4 clean Script
Those more that simply remove the program. They will remove all the items in the applications folder and shared in the user's library and the library of the system. It is the only true way to make a re-install AFAIK. But you will need to disable the function before doing so because it will erase all files and all the serial numbers of all the Adobe programs with this tool.
Maybe you are looking for
-
Equium L40-10 x PSL41E: no media card
Hello This maybe a stupid question but here again; I am a stupid boy Equium all have the locations of media as our looking card doesn't have the manual one where it should be ours is L40 - 10 x model psl41e. Thank you
-
Pavilion dv6-2115aa: Pavilion dv6-2115sa BIOS corruption failure
My laptop does not start and flashes the caps locks and MOM sighted twice, which according to locking elsewhere on the forum, is a BIOS corruption failure. However, I can't find a BIOS version anywhere on the HP support site to re-install it, especia
-
My laptop computer and printer do not communicate with each other.
I went to "printers and devices in the control panel and my laptop has an icon of troubleshooting beside him. I tried to search for updates/drivers solve the problem and nothing works. It says ' unknown device is not a driver. My fax, copier and sca
-
Article ID: 308402 - need to fix Q308402
I have problems copy my OS on a hard drive (more) replacement. I am trying to use the Recovery Console to help solve the problem but get an error about an incorrect password (it is not). Apparently, I need the Q308402 hotfix. How to do it?
-
Icons remain in place when I shut down or restart
My icons move and expand on the restart or shut down my computer. I tried so many ways to address this issue and nothing that I do work!I want that my icons organized and light them as I wish. It's so awkward knowing that everytime I restart or shutd