Advice needed on the way to store large amounts of data
Hi guys,.
Im not sure what the best way is to put at the disposal of my android application of large amounts of data on the local device.
For example records of food ingredients, in the 100?
I have read and managed to create .db using this tutorial.
http://help.Adobe.com/en_US/air/1.5/devappsflex/WS5b3ccc516d4fbf351e63e3d118666ade46-7d49. HTML
However, to complete the database, I use flash? If this kind of defeated the purpose of it. No point in me from a massive range of data from flash to a sql database, when I could access the as3 table data live?
Then maybe I could create the .db with an external program? but then how do I include this .db in the apk file and deploy it for android users device.
Or maybe I create a class as3 with a xml object initialization and use it as a way to store data?
Any advice would be appreciated
You can use any way you want to fill your SQLite database, including using external programs, (temporarily) incorporation of a text file with SQL, executing some statements code SQL from code AS3 etc etc.
Once you have filled in your db, deploy with your project:
Cheers, - Jon-
Tags: Adobe AIR
Similar Questions
-
Smart way to save large amounts of data using the circular buffer
Hello everyone,
I am currently enter LabView that I develop a measurement of five-channel system. Each "channel" will provide up to two digital inputs, up to three analog inputs of CSR (sampling frequency will be around 4 k to 10 k each channel) and up to five analog inputs for thermocouple (sampling frequency will be lower than 100 s/s). According to the determined user events (such as sudden speed fall) the system should save a file of PDM that contains one row for each data channel, store values n seconds before the impact that happened and with a specified user (for example 10 seconds before the fall of rotation speed, then with a length of 10 minutes).
My question is how to manage these rather huge amounts of data in an intelligent way and how to get the case of error on the hard disk without loss of samples and dumping of huge amounts of data on the disc when recording the signals when there is no impact. I thought about the following:
-use a single producer to only acquire the constant and high speed data and write data in the queues
-use consumers loop to process packets of signals when they become available and to identify impacts and save data on impact is triggered
-use the third loop with the structure of the event to give the possibility to control the VI without having to interrogate the front panel controls each time
-use some kind of memory circular buffer in the loop of consumer to store a certain number of data that can be written to the hard disk.
I hope this is the right way to do it so far.
Now, I thought about three ways to design the circular data buffer:
-l' use of RAM as a buffer (files or waiting tables with a limited number of registrations), what is written on disk in one step when you are finished while the rest of the program and DAQ should always be active
-broadcast directly to hard disk using the advanced features of PDM, and re-setting the Position to write of PDM markers go back to the first entry when a specific amount of data entry was written.
-disseminate all data on hard drive using PDM streaming, file sharing at a certain time and deleting files TDMS containing no abnormalities later when running directly.
Regarding the first possibility, I fear that there will be problems with a Crescent quickly the tables/queues, and especially when it comes to backup data from RAM to disk, my program would be stuck for once writes data only on the disk and thus losing the samples in the DAQ loop which I want to continue without interruption.
Regarding the latter, I meet lot with PDM, data gets easily damaged and I certainly don't know if the PDM Set write next Position is adapted to my needs (I need to adjust the positions for (3analog + 2ctr + 5thermo) * 5channels = line of 50 data more timestamp in the worst case!). I'm afraid also the hard drive won't be able to write fast enough to stream all the data at the same time in the worst case... ?
Regarding the third option, I fear that classify PDM and open a new TDMS file to continue recording will be fast enough to not lose data packets.
What are your thoughts here? Is there anyone who has already dealt with similar tasks? Does anyone know some raw criteria on the amount of data may be tempted to spread at an average speed of disk at the same time?
Thank you very much
OK, I'm reaching back four years when I've implemented this system, so patient with me.
We will look at has a trigger and wanting to capture samples before the trigger N and M samples after the outbreak. The scheme is somewhat complicated, because the goal is not to "Miss" samples. We came up with this several years ago and it seems to work - there may be an easier way to do it, but never mind.
We have created two queues - one samples of "Pre-event" line of fixed length N and a queue for event of unlimited size. We use a design of producer/consumer, with State Machines running each loop. Without worrying about naming the States, let me describe how each of the works.
The producer begins in its state of "Pre Trigger", using Lossy Enqueue to place data in the prior event queue. If the trigger does not occur during this State, we're staying for the following example. There are a few details I am forget how do ensure us that the prior event queue is full, but skip that for now. At some point, relaxation tilt us the State. p - event. Here we queue in the queue for event, count the number of items we enqueue. When we get to M, we switch of States in the State of pre-event.
On the consumer side we start in one State 'pending', where we just ignore the two queues. At some point, the trigger occurs, and we pass the consumer as a pre-event. It is responsible for the queue (and dealing with) N elements in the queue of pre-event, then manipulate the M the following in the event queue for. [Hmm - I don't remember how we knew what had finished the event queue for - we count m, or did you we wait until the queue was empty and the producer was again in the State of pre-event?].
There are a few 'holes' in this simple explanation, that which some, I think we filled. For example, what happens when the triggers are too close together? A way to handle this is to not allow a relaxation to be processed as long as the prior event queue is full.
Bob Schor
-
Assemble the different tables with large amounts of data
Hello
I need to collect different types of tables:
Example "table1", with columns: DATE, IP, TYPEN, X 1, X 2, X 3
For "table0" with the DATE, IP, REFERENCE columns.
TYPEN in table1 to be inserted in REFERENCE in table0, but by a function that transforms it to another value.
There are several other tables like 'table1', but with slightly different columns, which must be inserted into the same table ("table0").
The amount of data in each table is pretty huge, so the procedure must be made into small pieces and effectively.
If / could I use data pump for this?
Thank you!user13036557 wrote:
How can I continue with this then?Should I delete the columns I don't need and transform the data in the first table, and then use data pump.
or should I just do a procedure traversing all ranks (into small pieces) "table1", then threading "table0"?
You have two options... Please test both of them, calculate the time to complete and to implement the best.
Concerning
Rajesh -
Advice needed on scanning and organization of large amounts of family photos
I have about 4000 photos, I need to digitize and organize, and would appreciate information on the experiences of people with similar projects - specifically what scanners and software editing/organization work well (or not) and why. I am interested in scanning experience, naming, entering in the metadata tags / and storage on an external drive (or drive possible cloud) as effective as possible. I have a MacBook Pro towards 2012, running OS X El Capitan 10.11.6, processor 2.9 GHz Intel Core i7 with 8 GB 1600 Mhz DDr2 memory
I waited for someone to answer, but no luck so far.
I think that, maybe, the question is too broad, but you hit on a lot of issues that I tried to respond in support of my own digitization projects. These are essentially old photos and family concert tickets, I've gathered that I want to geocode instead and add an event date to sort the pictures correctly in my reader, I now use pictures all to also store the main images in the form of files in folders.
One of the first things that you need to consider what is my final use, how will be I be display these carelessly or what their final destination, that is to say: the screen or print. Next, you will need to examine and decide what are your basic quality standards. Is it an archiving project where you might want to get the maximum resolution to capture your images or you are looking for very high resolution - pixel specific pick - and go deep with it. What types of files you save; jpg or RAW or another.
Don't forget the file type is like a box and the picture is in the box, you can have the same image quality in each type of file and each has positive points and negatives, jpgs are the most common, can display high-quality, but at the root with loss.
It is to you and how you want to store, manage and share. You could take a sweeping super high ground - better as your scanner may take - and a large jpg copy for sharing, etc.
Depending on how you answer the above, in terms of desired scan quality, will affect what kind of scanner that you buy. I used several descent average range flat scanners, a versatile case and a wand at a crossing through of dock that I just got.
I decided quite a while that I'm not in the business of archive I'm in enjoy it there and share business. IF they look good in an email or on Facebook or on my big screen as screensaver, even for the large TV. Then, I have what I need. It is for me. Others feel differently. For me in the end, it's the time it took to take a sweeping super high quality in order to get an image, which overwhelms my screen and has a huge file size. You have to play and see what works for you.
I just got this scanner wand 1200 dpi with a dock charger and it quickly arranged a pile of concert tickets at its highest quality of scanning. I was happy with the initial results and I can't wait to make some pictures.
There are a lot of details, you can enter each of these topics, but here you say basically software that controls the scanner. On a flat bed I hope you can scan several small images at once by selecting them in the program. You select the output resolution, file type, and can perform a variety of other adjustments to the image, which some will be dictated by the source. As the digitization of old photos 'black and white' in color.
You will need to consider certain issues of workflow here, the scanner software will generally look to create file names to sequential access to what you are scanning. If it's a large image at a time, you can name each or there may wish to work through a lot of dimensions and similar features and then mess with the baptism and the meta data later. You will find what works best for you as enter you.
You have now all these files. For me, it was ticket_1 - 90.jpg who had to have their date, time and locations adjusted. I've been messing around with photos of geocoding for years and so far my favorite geogocder and meta-data tool is called photolinker http://www.earlyinnovations.com/photolinker/ that I started using it because I was using a geo - stay with my regular camera and I wanted to match the Geo-trail of the recorder for pictures and this tool does that very well , with tools for helpsync the time of the image and geolog times. or you can give it an address or a city or a block and he will score as many images you select. It will give them a geocode latitude and longitude (altitude in some cases) as well as the metadata for the region city of the State, etc.
It also gives you quick access to metadata, including tiles, descriptions, keywords, etc. and I do as well of this titration and marking here as I can. as well as the geocoding. Dates are a very special case that I will come back soon.
So analysis stuff you give a whole bunch of files and you need to decide how you want to sort and store them. My family photos I usually sort in events and it is pretty easy because the images were of particular type of event and then something holidays. So I in my folder of photos folders called things like:
1909 - Granma baby pictures
1931_12_25-moms first Christmas.
1952_07_21-dad comes from the service.
etc with this kind of naming structure. months of the year and day, if I know that it and the event.
The photos then if there are few have specific names for files. If it is more like '1986_07-Florida_ #1-72' and let the meter. If I can be precise date in each event, I try to do, since we are talking about scans and no pictures of digital cameras, if the clock is set right and phones that capture this info.
The deal with dates, as I mentioned earlier, can be a mess and I have found no real primer on how best to define and manage the dates on scanned images, but here is a part from what I understand. First of all remember that the dates of creation and modification in your finder associated with the file that contains the image, but not necessarily the image itself. Each image also has various sets of metadata that is stored with the images, called EXIFdata, this is where you find the geocoded and other data type keyword, you may be added, such as discussed above.
As I said I have use pictures formerly iPhoto to see my images now and it does not always play nice with dates, but I think I understood now that it uses a date edit EXIF, to place images in the long scenario.
Other non-traditional software I use for batch file renamed and full playback and editing of EXIF data are GraphicConverter 10 adata-and-more-on-your-mac/ https://www.lemkesoft.de/en/image-editing-slideshow-browser-batch-conversion-met
This should be a lot of things to get started, I've always wanted to write that down and happy to now have at hand. Many men of straw - for people to start to sting to, assisting us on the tools and means better or different. I hope. I also hope that this help find you your first steps. Good luck.
-
With the help of the network location and mapped a drive to the server FTP off site; during the transfer of very large amounts of the login information is always lost. Computer power settings are configured to not to do no matter what, I'm assuming that the ftp server can publish a scenerio timeout but is there a way for my computer and windows to restart the file transfer?
Hello
Thanks for posting your question in the Microsoft Community forums.I see from the description of the problem, you have a problem with networking on the FTP server.The question you posted would be better suited in the Technet Forums. I would post the query in the link below.http://social.technet.Microsoft.com/forums/en/w7itpronetworking/threads
Hope this information helps you. If you need additional help or information on Windows, I'll be happy to help you. We, at tender Microsoft to excellence. -
Looking for ideas on how to get large amounts of data to the line in via APEX
Hi all
I am building a form that will be used to provide large amounts of data in row. Only 1 or 2 columns per line, but potentially dozens or hundreds of lines.
I was initially looking at using a tabular subform, but this feels like a method heavy since more than an insignificant number of lines.
So now I'm wondering what are the solutions others have used?
Theoretically, I could just provide a text box and get the user to paste in a list delimited by lines and use the background to interpret code on submit.
Another method that I've been thinking is to get the user to save and download a CSV file that gets automatically imported by the form.
Is there something else? If not, can someone give me any indication of which of the above would be easier to implement?
Thank you very much
PT
Hi PT,.
I would say that you need a loading data wizard to transfer your data with a CSV file. 17.13 Creating Applications with loading capacity of data
It is available for apex 4.0 and distributions, later.
Kind regards
Vincent
-
Memory management by displaying the large amount of data
Hello
I have a requirement to display the large amount of data on the front in table 2 & 7 graphic during the time period 100hrs for 3 channels, data read from strings must be written in the binary file, and then converted and displayed in front of the Panel for 3 channels respectively.
If I get 36 samples after conversion for all hours, up to 83 h 2388 samples displayed in table and graphical data are thin and samples correspond exactly.
After that 90 hours 45 minutes late is observed after theoretical calculation of samples, what could be the problem
I have controller dual-core PXI8108 with 1 GB of ram
As DFGray,
says there is no problem with the RAM or display, problem with conversion (timming issue) if I am data conversion of large amount it takes even, compared to the conversion less amount of data. So I modifed so that each data point Sec 1 is convereted at once, problem solved
Thanks for your replies
-
How can I find a large amount of data from a stored procedure?
How can I find a large amount of data to a stored procedure in an effective way?
For example do not use a cursor to go through all the lines and then assign values to variables.
Thanks in advance!>
How can I find a large amount of data to a stored procedure in an effective way?For example do not use a cursor to go through all the lines and then assign values to variables.
>
Leave the query to create the object back to you.Declare a cursor in a package specification than the result set gives you desired. And to declare a TYPE in the package specification which returns a table composed of % rowtype to this cursor.
Then use this type as the function's return type. Here is the code example that shows how easy it is.
create or replace package pkg4 as CURSOR emp_cur is (SELECT empno, ename, job, mgr, deptno FROM emp); type pkg_emp_table_type is table of emp_cur%rowtype; function get_emp( p_deptno number ) return pkg_emp_table_type pipelined; end; / create or replace package body pkg4 as function get_emp( p_deptno number ) return pkg_emp_table_type pipelined is v_emp_rec emp_cur%rowtype; begin open emp_cur; loop fetch emp_cur into v_emp_rec; exit when emp_cur%notfound; pipe row(v_emp_rec); end loop; end; end; / select * from table(pkg4.get_emp(20)); EMPNO ENAME JOB MGR DEPTNO ---------- ---------- --------- ---------- ---------- 7369 DALLAS CLERK2 7902 20 7566 DALLAS MANAGER 7839 20 7788 DALLAS ANALYST 7566 20 7876 DALLAS CLERK 7788 20 7902 DALLAS ANALYST 7566 20If you return a line an actual table (all columns of the table) so you don't need to create a cursor with the query a copy you can just declare the type like this % rowtype tables table.
create or replace package pkg3 as type emp_table_type is table of emp%rowtype; function get_emp( p_deptno number ) return emp_table_type pipelined; end; / create or replace package body pkg3 as function get_emp( p_deptno number ) return emp_table_type pipelined is begin for v_rec in (select * from emp where deptno = p_deptno) loop pipe row(v_rec); end loop; end; end; / -
Transport of large amounts of data from a schema of one database to another
Hello
We have large amount of data to a 10.2.0.4 database schema from database to another 11.2.0.3.
Am currently using datapump but quite slow again - to have done in chunks.
Also files datapump big enough in order to have to compress and move on the network.
Is there a quick way to better/more?
Habe haerd on tablespaces transportable but never used and do not know for speed - if more rapid thana datapump.
tablespace names in the two databases.
Also source database on the system of solaris on Sun box opertaing
target database on aix on the power box series of ibm.
Any ideas would be great.
Thank you
Published by: user5716448 on 08-Sep-2012 03:30
Published by: user5716448 on 2012-Sep-08 03:31>
Habe haerd on tablespaces transportable but never used and do not know for speed - if more rapid thana datapump.
>
Speed? Just copy the data files themselves at the level of the BONE. Of course, you use always EXPDP to export the "metadata" for the tablespace but that takes just seconds.See and try the example from Oracle-Base
http://www.Oracle-base.com/articles/Misc/transportable-tablespaces.phpYou can also use the first two steps listed on your actual DB to see if it is eligible for transport and to see what there could be violations.
>
DBMS_TTS EXEC. TRANSPORT_SET_CHECK (ts_list-online 'TEST_DATA', => of incl_constraints, TRUE);PL/SQL procedure successfully completed.
SQL > TRANSPORT_SET_VIOLATIONS The view is used to check violations.
SELECT * FROM transport_set_violations;
no selected line
SQL >
-
Not sure if this should be in performance/maintenance or hardware/drivers.
Hello. I was wondering about the usb2, eSATA and a bit on the usb3. I have usb2 and eSATA on my systems.
Someone I work with told me that there may be corrupted data if you transfer a large amoutns of data via Usb2. It is best to break your files to move, copy, etc., he said. My colleague told me earlier that anything more than 30 or 40 GB start to be transferred correctly from external factors or for some reason any.
These issues apply to eSATA or Usb3? I guess not, since these other methods are designed to transfer large amounts of data.
Is this true? Is this due to material limitations? What is the recommended size of transfer? It's Windows XP, Vista or 7 limits?
Any info or links are appriciated.
Thank you.
I have never heard of something like this before and have done some fairly large data movements in the past. I would recommend using the program Robocopy in Windows Vista/Windows 7 (and available for Windows XP as a download add-on) to drag the move instead of type / move, given that Robocopy includes a number of features and security provisions that are not present in the case.
'Brian V V' wrote in the new message: * e-mail address is removed from the privacy... *
Not sure if this should be in performance/maintenance or hardware/drivers.
Hello. I was wondering about the usb2, eSATA and a bit on the usb3. I have usb2 and eSATA on my systems.
Someone I work with told me that there may be corrupted data if you transfer a large amoutns of data via Usb2. It is best to break your files to move, copy, etc., he said. My colleague told me earlier that anything more than 30 or 40 GB start to be transferred correctly from external factors or for some reason any.
These issues apply to eSATA or Usb3? I guess not, since these other methods are designed to transfer large amounts of data.
Is this true? Is this due to material limitations? What is the recommended size of transfer? It's Windows XP, Vista or 7 limits?
Any info or links are appriciated.
Thank you.
-
Impossible to transfer large amounts of data more than 10 GB
Original title: the maximum data transfer size?
I recently installed an eSata controller card in location faster PCIex-1 of my computer to benefit from a transfer of data to and from my Fantom drives GreenDrive, of 2 TB external HARD drive. When I started to copy the files from that drive to a new drive HARD internal, I recently installed I could not transfer large amounts of data more than 10 GB. The pop-up message indicating files preparing to copy, then nothing would pass. When I copy or cut smaller amounts of data all works fine. Perplexed...
I think I got the question. It seems that some of the files I transfer were problematic. When I transferred in small amounts, I was then invited for what I wanted to do about these files. Thanks for the reply!
-
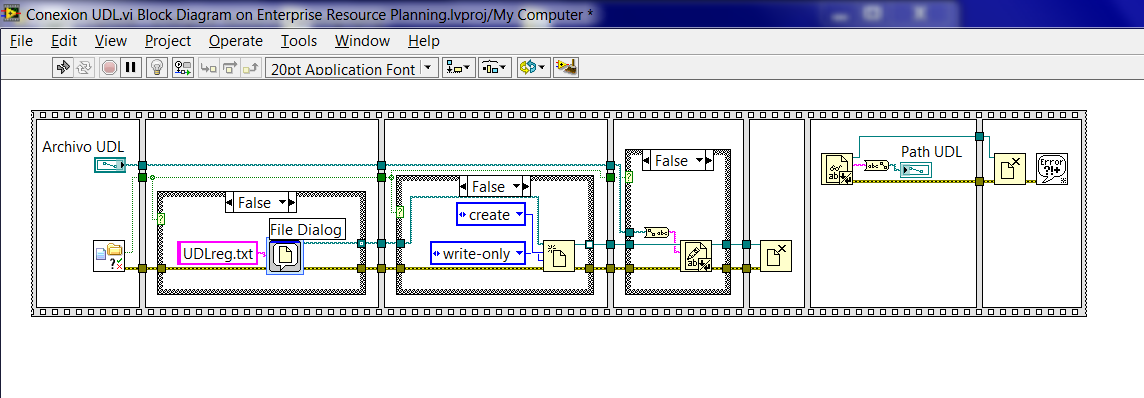
How keep the paths with LV, I am looking for the way to store paths?
I'm looking for ways to store paths, so that when I run a VI requiring this way, I don't have to set it.
What I want is to establish once > store it > open a VI who select automatically.
I have an example, but it gives a bad result.
One thing to think creates a configuration file that contains constant file paths that you need. I think it's a bad idea to have hard coded paths in your code.
-
I need help my program read in limited amounts of data at a time
I have attached my schema. I have problems are the following
I need to read the data from a .txt (alternately .lvm) entered file 250 at a time. The problem with the construction, I have now, is that the dynamics of the table buffer destroyed point type of segment data because it reads in both. In addition, I need a way to read and write this data so that I do not use the express VI. Semblance of my data file is say C:\data.txt and it is a single column of entries in values about 5 m long.
In addition, I have set up the while loop to stop once it has been processed, I need to put in place such as the while loop stops when all data have been read in.
Thanks for the help.
-
Hi all
I did an applet that receives the data, signs and returns the signed data. When the amount of data is too big, I break into blocks of 255 bytes and use the Signature.update method.
OK, it works fine, but perfomarnce is poor due to the large amount of blocks. Is it possible to increase the size of the blocks?
Thank you.Hello
You cannot change the size of the block, but you can change what you send.
You can get better performance by sending multiple of your block size of hash function that the card will not do an internal buffering.
You could also do as much of the work in your host as possible application and then simply send the data you need to work on with the private key. Generate the hash of the message does not require a private so key can be made in your host application. You then send the result of the hash to the card is encrypted with the private key. This will be the fastest method.
See you soon,.
Shane -
Timeout values receive vo large amount of data
Hello
I have an application works, but if I go more than 3 MB of data (large text), I have a time-out error.
Can someone help me please?
Thank you.
I recall there is no way to automatically partition the data in php.
So if you have memory limits, you must check the number of rows and returns all the data to the client with number of all lines. And on the client if the number of lines is not equal to the total number of lines request additional data.
There is no feature implemented for this.
Maybe you are looking for
-
Why the audio quality of Apple TV 4 film is so bad?
I have my Apple TV (4th generation) hooked up to my receiver Pioneer Elite and the audio quality is very, very bad on all HD, its horrible movies. Everything is fine with my HDMI cable, receiver, or Apple TV. The volume is so low compared to the play
-
Need to reinstall windows 7 home neremium
Re: HP Pavilion P2-110 (432730) bought at Staples, Petaluma CA 05/17/12. I have all the documents, including the Product ID and the key #.) My Windows operating system was wiped out by a nasty virus (Incredibar). Unfortunately, I got no backup copie
-
Re-reconfigure a GPIB-USB-HS in NI-VISA 4.3
I have a GPIB-USB-HS that I use to interface my transmissions TDS2014 oscilloscope. I did something very stupid this afternoon and used NI-VISA Wizard program to configure the GPIB-USB-HS as a raw USB. The GPIB-USB-HS still works, but I can't make it
-
Integrating Active Directory and UCS Manager
I'm looking to create an LDAP authentication provider in the UCS Manager that will authenticate users in Active Directory. I see the configuration guide UCS that a schema change is required to add a new attribute for user accounts and the guide detai
-
Hi guys,.I can't find the integration of EchoSign in Sugarcrm v7... Have you any idea where I can find the Extension?Thank you!See you soonMika