Approach for the removal of the physical dimension table
Hello
We have a situation to decommission a physical dimension table (table 1) and we will have new values.
The table is a source for a consistent size with 2 facts in the business model.
Can you please let me know steps to transform the existing for the future model and changes to these model reports.
However, I do not have the documentation of data lineage of these reports, how do I know the reports that would be affected by this change in the repository?
Receive your answer.
Thank you
Shravan
Hello
In tools > utilities you have a tool called 'Replace logical column or Table Source Table', use this tool to keep your business model and simply replace the existing physical sources with a new one.
Once you're done to make sure your physical objects are not used more (right click > queries about objects) and then just delete.
Always run the overall consistency checks after each important step to ensure that your SPR is always very good.
This can be a way to do it, another way may be to add new items to the existing MDB and then gradually remove the old or even add a new dimension of MDB and map to the same objects of presentation layer.
Ultimately it is to you to know if the new source for your dimension will correspond to each column, so you can just replace the physical source to the columns in the Sun or it will take further work (such as a snowflake and things like that).
Tags: Business Intelligence
Similar Questions
-
Increase the physical dimensions of the image in high resolution?
I have an image I want to use in a video, if it is not physically large enough to fill the dimensions of 1920 x 1080 video, she has a resolution of 300ppi and video needs only 72 dpi. How to take advantage of the fact that it's an image high definition and increase the physical dimensions of the image? Is there a way to do this?
Thank you.
If you are told that you should print at 4 inches by 6 inches at 300 dpi, follow these steps:
- Choose Image - Image size.
- Check the box resampling .
- In the resolution box, type 300 .
- Put 4 to 6 inches in the height and Width boxes (or vice versa if it's a bitmap portrait).
You will find yourself with an image 1200 x 1800 pixels that will be printed at 4 by 6 inches, your goal of printing at 300 ppi.
Printing will be probably not as sharp and detailed as if you had printed at 4 by 6 inches without downsampling at 300 ppi.
You will do well to try to begin to understand how the images are expressed in pixels, and why the above is true, while in the future, you will know when the issue of the requirements. This thread you might also like:
http://forums.Adobe.com/thread/975142?TSTART=30
-Christmas
-
How can I write the trigger for the global temporary Table
Hi Grus,
How can I write the trigger for the global temporary Table.
I created the TWG with trigger using the script below.
CREATE A GLOBAL_TEMP GLOBAL TEMPORARY TABLE
(
EMP_C_NAME VARCHAR2 (20 BYTE)
)
ON COMMIT PRESERVE ROWS;
CREATE OR REPLACE TRIGGER TRI_GLOBAL_TEMP
BEFORE DELETE, UPDATE OR INSERT
ON GLOBAL_TEMP
REFERRING AGAIN AS NINE OLD AND OLD
FOR EACH LINE
BEGIN
INSERT INTO VALUES EMPNAME (: OLD.) EMP_C_NAME);
END;
/
trigger was created successfully, but her would not insert EMPNAME Table...
Please guide if mistaken or not? If not wanting to give a correct syntax with example
Thanks in advance,
Arun M MBEGIN INSERT INTO EMPNAME VALUES (:OLD.EMP_C_NAME); END;you are referencing old value in insert stmt. BEGIN INSERT INTO EMPNAME VALUES (:new.EMP_C_NAME); END;then run your app, it works very well...
CREATE GLOBAL TEMPORARY TABLE GLOBAL_TEMP ( EMP_C_NAME VARCHAR2(20 BYTE) ) ON COMMIT PRESERVE ROWS; CREATE OR REPLACE TRIGGER TRI_GLOBAL_TEMP BEFORE DELETE OR UPDATE OR INSERT ON GLOBAL_TEMP REFERENCING NEW AS NEW OLD AS OLD FOR EACH ROW BEGIN dbms_output.put_line(:OLD.EMP_C_NAME||'yahoo'); INSERT INTO EMPNAME VALUES (:new.EMP_C_NAME); dbms_output.put_line(:OLD.EMP_C_NAME); END; / create table EMPNAME as select * from GLOBAL_TEMP where 1=2 insert into GLOBAL_TEMP values('fgfdgd'); commit; select * from GLOBAL_TEMP; select * from EMPNAME; output: 1 rows inserted commit succeeded. EMP_C_NAME -------------------- fgfdgd 1 rows selected EMP_C_NAME -------------------- fgfdgd 1 rows selectedHe got Arun
Published by: OraclePLSQL on December 28, 2010 18:07
-
Why the following does it
but just add the clause "for update" allows to make the point?create table division (code varchar2(2) primary key, div_desc varchar2(20)); insert into division values ('01', 'Ninja assassins'); insert into division values ('02', 'Working for the man'); create table employees (tk number, first_name varchar2(10), last_name varchar2(10), code varchar2(2) references division(code)); insert into employees values (1, 'Chuck', 'Smith', '01'); insert into employees values (2, 'John', 'Smith', '02'); DECLARE CURSOR my_csr IS Select e.tk, e.first_name, e.last_name From employees e, division d Where e.code = d.code and e.code = '01' and e.last_name = 'Smith' For update; cnt_updated NUMBER; BEGIN cnt_updated := 0; FOR my_row IN my_csr LOOP Update employees Set last_name = 'Forbes' Where current of my_csr; cnt_updated := cnt_updated + SQL%ROWCOUNT; dbms_output.put_line('You updated '||cnt_updated||' records'); END LOOP; END;
We discovered this recently, and fellow developers are wondering "why?" Is there a reason documented, or is - just how it is?DECLARE CURSOR my_csr IS Select e.tk, e.first_name, e.last_name From employees e, division d Where e.code = d.code and e.code = '01' and e.last_name = 'Smith' For update *of e.tk*;
Thank you
-= Chuckof 'of the user to the database PL/SQL Oracle® reference Guide. "
"10g Release 2 (10.2):
"During the interrogation of several tables, you can use the FOR UPDATE clause to limit the line blocking to specific tables. Rows in a table are locked unless done FOR UPDATE OF clause refers to a column in the table. For example, the following query locks the rows in the employees table, but not in the departments table:DECLARE
CURSOR c1 IS SELECT last_name, department_name FROM employees, departments
WHERE employees.department_id = departments.department_id
AND job_id = "SA_MAN."
FOR the UPDATE OF treatment; »a little demo:
SQL> select * from v$version; BANNER ------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production PL/SQL Release 11.1.0.6.0 - Production CORE 11.1.0.6.0 Production TNS for 32-bit Windows: Version 11.1.0.6.0 - Production NLSRTL Version 11.1.0.6.0 - Production 1 DECLARE 2 CURSOR my_csr IS 3 Select e.tk, e.first_name, e.last_name, e.rowid 4 From employees_t e, division d 5 Where e.code = d.code 6 and e.code = '01' 7 and e.last_name = 'Smith' 8 For update of e.tk; 9 cnt_updated NUMBER; 10 BEGIN 11 cnt_updated := 0; 12 FOR my_row IN my_csr 13 LOOP 14 Update employees_t 15 Set last_name = 'Forbes' 16 Where current of my_csr; 17 cnt_updated := cnt_updated + SQL%ROWCOUNT; 18 dbms_output.put_line('You updated '||cnt_updated||' records'); 19 END LOOP; 20* END; SQL> / You updated 1 records PL/SQL procedure successfully completed. SQL> ed Wrote file afiedt.buf 1 DECLARE 2 CURSOR my_csr IS 3 Select e.tk, e.first_name, e.last_name, e.rowid 4 From employees_t e, division d 5 Where e.code = d.code 6 and e.code = '01' 7 and e.last_name = 'Smith' 8 For update;-- of e.tk; 9 cnt_updated NUMBER; 10 BEGIN 11 cnt_updated := 0; 12 FOR my_row IN my_csr 13 LOOP 14 Update employees_t 15 Set last_name = 'Forbes' 16 Where current of my_csr; 17 cnt_updated := cnt_updated + SQL%ROWCOUNT; 18 dbms_output.put_line('You updated '||cnt_updated||' records'); 19 END LOOP; 20* END; SQL> / PL/SQL procedure successfully completed.Amiel
-
Problem creating hierarchy based on 2 physical dimension tables
I'm having a problem create 1 dimension logic with a hierarchy of exploration, based on two separate physical dimension tables. The errors I get when navigating in the exploring hierarchy is:
"Cannot find coverage source logical table to the columns of the logical" &
"Missing join between the logical tables.
I use OBIEE 10.1.3.4
Here are the details of what I have set up as:
Physical layer:
Table DIM_ORG with the dimension columns:
-dimension_key
-org_total_code
-org_total_description
-org_detail_code
-org_detail_description
Dimension table DIM_DEPT with columns:
-dimension_key
-dept_total_code
-dept_total_description
-dept_detail_code
-dept_detail_description
FACT_SALES table with columns of facts:
-fk_org
-fk_dept
-sum_sales
Physical joins:
FACT_SALES.fk_org = DIM_ORG_dimension_key
FACT_SALES.fl_dept = DIM_DEPT.dimension_key
Business model and the mapping of layer:
I created a logical dimension ORG_DEPT. It contains two sources of logic table (DIM_ORG & DIM_DEPT) and the following logical columns:
-All departments (mapped to dept_total_code)
-Organization (mapped to org_detail_description)
-Organisation number (mapped to org_detail_code)
-Department (mapped to dept_detail_description)
-Department Code (mapped to dept_detail_code)
The logical key of the company is based on the combination of number of organization & Department Code
The hierarchy, I need is: all departments-> organization-> Department so I created the following hierarchy for ORG_DEPT:
-Total level containing: all departments
-Organization level containing: company (defined as logical level key) number & Organisation (als defined the key level drill)
/ Department detail level containing: Department (defined as logical level key) Code and the Department (defined as key level drill).
In the LTS of the ORG_DEPT dimension, I've set levels of content for sources:
DIM_ORG: Level of organization
DIM_DEPT: Level of detail Department
The LTS non - joins inner - came against the associated physical tables.
I created a logical fact table (based on the physical fact table) SALES and joined him on the ORG_DEPT logical dimension table.
In the LTS, level of content for ORG_DEPT is part of the level of retail service. Non - joins inner were aded against related physical tables.
When I create a report in response to test the hierarchy and select only "all departments' I get the value of the returned correct size. When I try to break through to the next level, I get the following ODBC error:
"Could not find coverage source logical table for logical columns: [all of them]." "Please check more detailed level keys are correctly mapped.
When I create a report in responses and select "Every department" and "Sales", I get the correct result. When I try to break through to the next level, I get a different ODBC error:
"Lack of join between the logical tables DIM_DEPT and DIM_DEPT: there must be at least a physical link to join between the underlying physical tables.
All suggestions are welcome!
Thank you!You have no relationship defined between the Department and org.
You can either:
a. create a table of physical dimension with a composite key of org_id & dept_id if there is a relationship defined somewhere, then to obiee model as you have already done, but in the physical layer on the composite key join
b. model your exisitng as two-dimensional and two hierarchies tables and set up a path of forest favorite between them according to your needs.Kind regards
Robert
-
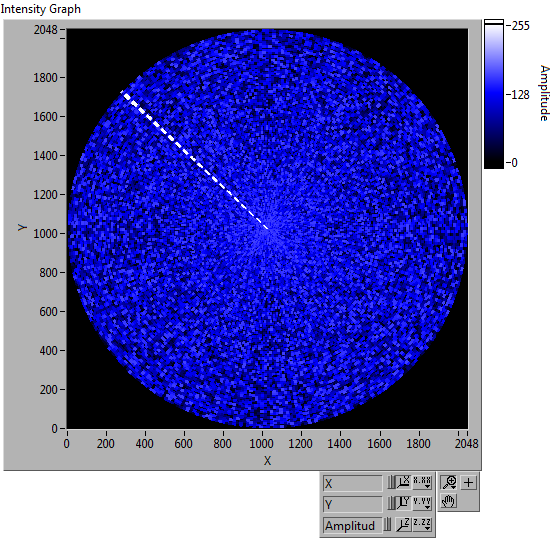
Best approach for the design of the Radial Image - sector scanning Sonar
This is not a problem, but you are asked to think about the best approach.
I need a sector sonar image data. This device runs on 360 (degree sub-segments) and generates a set of data from the origin - radially outwards at an angle of no - to an endpoint. Therefore, for each 'ping' sonar I need data points in the center of a circle graph, a radial angle on the outside.
I don't know if I should use LabView vi for the drawing tools, or go to ActiveX or?
Anyone has a suggestion on the best approach to this?
Thank you
PeterPeter,
You can use a chart of the LabVIEW intensities for this kind of display.
Maybe not the best way, but it is possible.
As an attachment, I did an example with your specifications.
datapoints 1024 by degree
See example image:
Basic principle:
-Create the matrix of 2048 x 2048 points database
-For each 'line of angle' calculate which pixel to replace each data point in the line
-Because "datapoints" becoming bigger, far from the Center, repeat the action for several "sup angles. for example, to 85 deg also Calc. 84.6, 84.8, 85, 85.2 85.4
It gives you an idea of the possibilities, but performance may be necessary.
-Only external Calc x pixels more degrees
-Do some kind of anti-aliasing to avoid the pixelated lines.
See attached example. (LV 8.6)
-
How to get the MAC address for the physical NETWORK adapter of the HOST ESX (vmnic0/vmnic1)
I can recover physical NIC details for the server HOST ESX, but MAC is empty... How can I get?
Thank you/HKS
$net = get-VMHostNetwork - VMHost myServer.domain.net
$net | FC
class VMHostNetworkInfoImpl
{
VMKernelGateway = 166.12.113.1
ConsoleGateway = 166.12.113.1
ConsoleGatewayDevice = vswif0
DnsAddress =
[
169.40.0.2
169.40.0.1
]
DnsFromDhcp = False
DnsDhcpDevice =
DomainName = domaine.net
Host name = hostname1
SearchDomain =
[
EU.hedani.NET
]
PhysicalNic =
[
class PhysicalNicImpl
{
BitRatePerSec = 1000
FullDuplex = True
WakeOnLanSupported =
ID = key - vim.host.PhysicalNic - vmnic0
DeviceName = vmnic0
Mac =
DhcpEnabled = False
IP =
SubnetMask =
}
class PhysicalNicImpl
{
BitRatePerSec = 0
FullDuplex = False
WakeOnLanSupported =
ID = key - vim.host.PhysicalNic - vmnic1
DeviceName = vmnic1
Mac =
DhcpEnabled = False
IP =
SubnetMask =
}
]
VirtualSwitch =
[
class VirtualSwitchImpl
{
Key = key - vim.host.VirtualSwitch - vSwitch0
Name = vSwitch0
NumPorts = 128
NumPortsAvailable = 105
NIC =
[
vmnic1
vmnic0
]
MTU =
}
class VirtualSwitchImpl
{
Key = key - vim.host.VirtualSwitch - vSwitch1
Name = vSwitch1
NumPorts = 64
NumPortsAvailable = 56
NIC =
MTU =
}
class VirtualSwitchImpl
{
Key = key - vim.host.VirtualSwitch - vSwitch2
Name = vSwitch2
NumPorts = 64
NumPortsAvailable = 64
NIC =
MTU =
}
]
ConsoleNic =
[
class HostConsoleVirtualNicImpl
{
PortGroupName = Service_Console_VLAN1
ID = key - vim.host.VirtualNic - vswif0
DeviceName = vswif0
Mac = 00:50:56:4 c: 1 d: 3B
DhcpEnabled = False
IP = 111.11.111.11
Subnet mask = 255.255.255.0
}
class HostConsoleVirtualNicImpl
{
PortGroupName = Service_Console_ISOL
ID = key - vim.host.VirtualNic - vswif1
DeviceName = vswif1
Mac = 00:50:56:4 d: 88:87
DhcpEnabled = False
IP = 10.0.0.241
Subnet mask = 255.255.255.0
}
]
VirtualNic =
[
class HostVMKernelVirtualNicImpl
{
VMotionEnabled = True
PortGroupName = Vmotion_VLAN1
ID = key - vim.host.VirtualNic - portgroup3
DeviceName = portgroup3
Mac = 00:50:56:65:04:56
DhcpEnabled = False
IP = 166.12.113.72
Subnet mask = 255.255.255.0
}
]
}
get-vmhost | % {(get-view $_.id).config.network.pnic} | select Device, Mac -
Search for the nearest value table
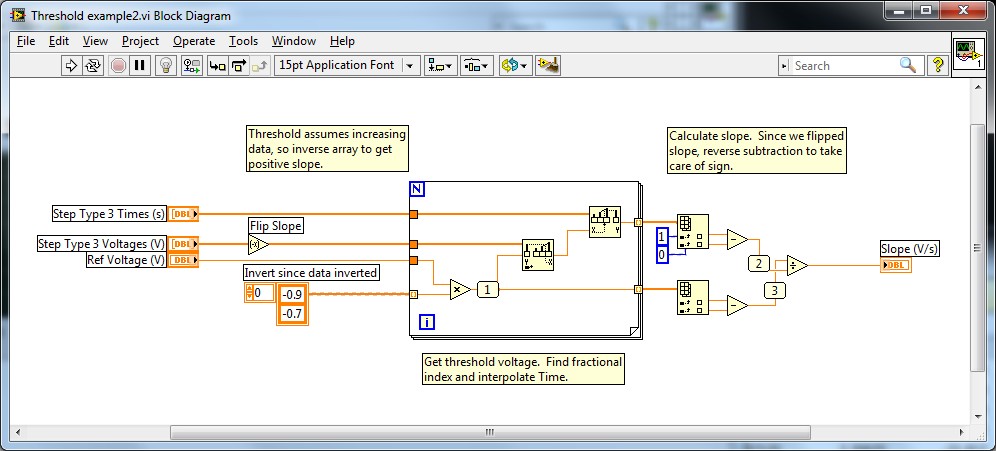
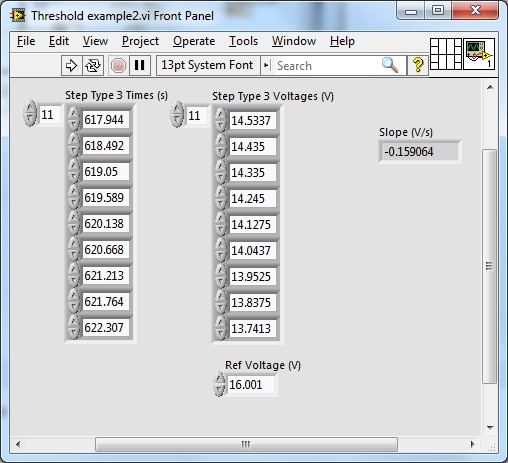
IM wondering if its possible to find a 1 d table worth, if it is not found, then find the nearest match. IM using the 'double' data type and I need at least an accuracy of 4 decimal point in the research.
For now, im rounding decimal values to the nearest integers from you, but it is not effective at all. Im getting a lot of unwanted split in the plot. I need to be able to search for the decimal points. I found this function "About Equals.VI" starting from a previous thread. Even that uses the concept of the rounding.
I enclose 3 screws "0.8 & 0.4.VI" are that I created, rounding decimals nearest digit.
The "approximately equal" is the one I found online.
The 3rd is I try to mess with what I can find as close a match.
Y at - it a trick to work around this problem?
Thank you
Eureka
This VI uses the first type of step 3 in your data. Since you said that you can get the data, you can drop the in VI.
At the end where I calculate the slope, you can use a linear adjustment if you have full or professional LabVIEW.
-
Help for the reconciliation of table. Average cost
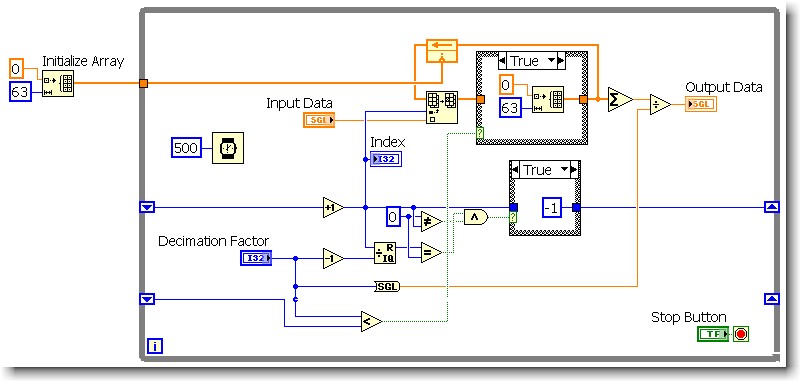
So this is my attempt to imitate a function block that we use in our standard converter software - "Decimation filter" which is nothing more than a running average / mobile. The sample size is adjustable to execution of 2 to 64 samples (decimation factor). I saw many topics on this and used to average around 4 large samples shift registers - but I wanted to be able to change the sample size without recompiling. I'm new to LV, there is likely a lot of better ways to do this.
I would like to have answered is linked to clear the table, if the decimation factor is set to a lower number than the last time that the loop executed. (The uppercase - false statement is wired directly by)
The math in the shift register: creates an array index that cycles from 0 to (decimation Factor-1). The index is then used to fill elements in the table (the rest being zeros). When the decimation factor decreases, I need zero external element in (former decimation factor - 1) (new decimation Factor-1) positions. So I tried various things, but the only thing that seems to work, it's the re - initialize the array. I think it's less than optimal.
I tried:
(1) leaving the tunnel of continuous wire output for the real deal and selecting the option 'use default if unwired' - thinking I'd get a table of 64 elements, of zeros. Doesn't seem to work.
(2) a constant matrix cable tunnel exit if this value is true. When I followed him, after a decline in decimation factor - the probe seems to indicate an array of elements, not 64 No. And I do not see how to specify the size of the array of constant matrix.
If I use this in my application it will run on a target of cRIO.
Any help much appreciated.
You already have your initialized table, why not use it? Wire your table initialized via if this value is TRUE. Or better yet, use Select? function.

-
Solution for the mutation of table of error when using triggers
Hello
Could you please give the solution for the error table mutation during the use of triggers. I'll give you the simple scenario here,
I created a trigger on the employees table, whenever all DML operations takes place in the employees table, it must run the trigger body. I intentionally used also of the employees in the body of the trigger table. Please give me the solution.
Triggering factor:
create or replace trigger test_trigger
before you insert or update or delete employees
for each line
declare
an employees.first_name%type;
Start
Select first_name from people where job_id = "AD_PRES";
end;
DML statement:
Update employees set salary = 20000 where job_id = "AD_PRES" (I run this query)
Error message:
ORA-04091: table HR. Is the transfer of EMPLOYEES, the function of triggering/can not see
ORA-06512: at "HR. TEST_TRIGGER', line 4
ORA-04088: error during execution of trigger ' HR. TEST_TRIGGER'
Can anyone tell, in what other scenarios, we get this error or recursive table mutation?
Thanks in advance
Hello
When you create a trigger on a table, you cannot edit/query this table the trigger is not completed.
You can use
(1) transaction of Pragma autonomous
(2) instead of row-level trigger, you have statement-level trigger
(3) to 11 g, try with COMPOSITE trigger
Try below to avoid it (a solution):
create or replace trigger test_trigger
before you insert or update or delete employees
for each line
declare
PRAGMA AUTONOMOUS_TRANSACTION;
an employees.first_name%type;
Start
Select first_name from people where job_id = "AD_PRES";
COMMIT;
end;
-
Format mask for the size of table cells
Hi all
I'm working on a catalog with a lot of products, and each product has a table for its specifications.
The catalogue is ready for printing, but now the customer asks me to enlarge certain parts of the text in the table.
This means that I have to give some cells more space. The cells have different sizes, and that's the problem:
Is there a way to define the new cell widths and heights as a sort of "master format" so that I can change the tables
for the design of new without marking of each column and adjusting by hand?Unfortunately, the layout is too complex to have tables on a master page, as they are not on a particular coordinate
throughout the catalog.
I hope I described my problem quite clearly I'm no native speaker
I thank very you much in advance!
Max
The script linked in the post one of this thread will allow you to adjust automatically to match - table column widths it allows to save the widths of a table in the style of the table and then apply them to other tables of this style. I don't know about heights, but if all the heights will be the same within a given table, you can select all the lines and enter the exact height of the cell.
-
ESX host with local storage recommended for the host partition table?
Hi all
I know that the best practical partition table should look like this:
Mount Point
Partition
Size
Description
/ dev/sda (primary)
/ Boot
ext3
250 MB
Change of extra space for upgrades
N/A
SWAP
1 600 MB
Change the maximum size of Exchange service console
/
ext3
5120 MB
Change of extra space in the root
/ dev/sda (Extended)
/ var
ext3
4096 MB
Create partition to avoid an overflow of root with log files
/ tmp
ext3
1024 MB
Create partition to avoid an overflow of root with temporary files
/ opt
ext3
2048 MB
Create partition to avoid overfilling root with the log files of VMware HA
/ Home
ext3
1024 MB
Create partition to avoid an overflow of root with agent / user files
vmkcore
100 MB
Pre-configured
However with a system with local storage would you set it up the same way, and whatever it is must be amended to change to get ESX to write log files to the different partitions? I would like to configure it for future expansion for when the enterprise package is configured.
Yes, I would set up the same way with an ESX with local storage server and nothing needs to be changed for the vmekernel right at the partition/var - unless of course you want to write to a log server that you need to change a configuration file to point to the server logs. If you talk to the ESX Enterprise license you willnot have to change partiition table-
Also on something else if you don't have a SAN/NAS storage you will also need to create a VMFS partition on the local data store to host your virtual machines
If you find this or any other answer useful please consider awarding points marking the answer correct or useful
-
Could not import a custom in the physical layer table
Background
**********
We are implementing the OBI Applications
The RPD is OBI (analytical) applications, a. We created custom tables and are now building the logic layer.
Problem
*******
Created a new custom table in the physical OBAW using the username of the OBI (analytical objects owner)
Connected to the BI-Admin offline using the user/pwd administrator name
Utility of used import, the appropriate custom table table (you can see in the dialog box), taken from the warehouse. It brings up the dialog box, and it looks like it is to import the table (by displaying the file flying over).
Updating of the RPD. Even tried to connect and again.
When you check the physical layer you do not see the custom table. Y at - it a cache that needs to be eliminated?have you checked if it creates a new connection pool and the table under this new connection pool?
-
SELECT... FOR the vs LOCK TABLE of UPDATE... MODE OF LINE SHARING IN
Hello
In practice, what is the difference between the two versions of line locking methods...?
In my case, I need to block only the lines that will be extracted by a cursor... but because the select stmt using the sum aggregate function... I can't use the format:cursor c1
So, the only alternative I have (I think) is the "LOCK TABLE d PART of the LINE in MODE.
is
select x , y ,sum(a)
from d
group by x,y
for update;
Is the above correct... to obtain row locks the same as the "select" for the update?
Note: I use Db10g v.2
Thank you
SIMWhen you draw a select... Updated, it's immediately another session in standby mode until you release the lock.
TABLE LOCK is a bit different, the other session will run in standby mode after an UPDATE statement. If the other session, run an UPDATE statement before your own session, you will wait for the release lock.
So, it's different behaviors. Conclusion: they are not same.Nicolas.
-
Performance problem with SQL for recovering data in FACT and Dimension Table
Hello
We have a query that performs very slow when extracting data in FACT and the DIMENSION Table.
SQL and Plan are in the attachment.
Please suggest how this can be improved.
The version of DB is 11.2.0.4
Kind regards
VN
Slow is a very relative term, for about 1 hour is slow for some 1s is slow. So please always quantify your settings.
The first thing caught my eye is done 4 times ia_oasis_tot_prov_cur_d access. Try to isolate which and change it like this and see if it returns the same result.
select case when a.clm_capitn_ia_bil_prov_edw_sk = b.prov_edw_sk then b.prov_id end ben_billing_prov , case when a.clm_capitn_attnd_prov_edw_sk = b.prov_edw_sk then b.prov_id end ben_attending_prov , case when a.clm_capitn_ia_pcp_edw_sk = b.prov_edw_sk then b.prov_id end ben_pcp_number , case when a.clm_capitn_ia_ipa_prov_edw_sk = b.prov_edw_sk then b.prov_id end ben_ipa_number from edw.clm_capitn_f partition (jan2015) a left join edw.ia_oasis_tot_prov_cur_d b on ( a.clm_capitn_ia_bil_prov_edw_sk = b.prov_edw_sk or a.clm_capitn_attnd_prov_edw_sk = b.prov_edw_sk or a.clm_capitn_ia_pcp_edw_sk = b.prov_edw_sk or a.clm_capitn_ia_ipa_prov_edw_sk = b.prov_edw_sk )If it works this means allows you to reduce certain I/O.
Maybe you are looking for
-
How to disable the toolbar to search related
Visiting a few results from web sites in the appearance of a toolbar on the left, called "related searches." How to disable the toolbar?
-
Satellite A200-27R does not start
I got my Satellite A200-27R for 2 years and 8 months and 2 weeks ago he crashed and died. At the time, I was watching on the internet and had probably opened pages 3 or 4 when it froze and I got a blue screen with white writing telling me that someth
-
How to use UInt64 in a time limited digital. TS said "should find number {UInt64}." If I change the digital format for the UInt limits, my limit values are changed. I can't select UInt64 in digital format. My data source format is UInt64. BR Nikolaj
-
get the label from a selection of radio in a box of radio buttons
I use a control of radio buttons, with four selections of radio in there. I understand that this is an enumerated type, so the value is a 'number '. When wire you this control to a statement button, the case is automatically generated with the sele
-
Windows Update fails with Error 0x80072F76 on Windows 2003 server number
I try to run windows update on my windows 2003 server. The update fails with number 0x80072F76 Errow. The Windows Firewall/Internet service Connection Sharing (ICS) is stopped and the security settings on IE is set by default. IE version is 8. The Wi