CBO promotes the basic function of the index (descending)
Location:Table 1 million records, 1 GB in size
Multiple indexes, including an index on three columns, one of these DESC
A particular query uses this index and made coherent 40,000 gets to return 1635 records.
The plan
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 75 | 1275 | 3 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN DESCENDING| IHISTOJOUR | 75 | 1275 | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------------------When forcing this index with a hint, the uniform becomes fall to as little as 16 for the same set of results
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 75 | 1275 | 4 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IHISTOJOUR2 | 75 | 1275 | 4 (0)| 00:00:01 |
------------------------------------------------------------------------------------Version Oracle 11.2.0.1
I can't understand why Oracle choose the order of the function based on the normal index, however.
Any thoughts?
This is one of those cases where through a 10053 is probably appropriate.
In my 10053 trace, I found this line:
Using prorated density: 0.000000 of col #4 as selectvity of
out-of-range/non-existent value pred
COL #4 corresponding to the virtual column for the descending column in the index.
There are a couple of notes on metalink about 'sub-optimal index is used when the index column is in descending order' and a number of bug - 11072246 - confirmed as affecting > = 10.2.0.5 and<=>
In the notes for this bug, this seems relevant:
"Selectivity of the Index has been calculated is not properly considering the DESC property.
By the way, another possible oddity was that, even if I've calculated the statistics with the size of the sample of 100% and it checked with sample_size in dba_tab_col_statistics, the LO_VAL of DAT and the virtual column never matched.
Convert the raw, DAT was a lo_val of 2 January 2001 and a hi_val 27-SEP-2003.
While the virtual columns had 8 January 2001 and 27-SEP-2003. difference of 6 days. Weird, right?
Published by: Dom Brooks on November 10, 2011 17:18
Tags: Database
Similar Questions
-
Invalidation of the index based on a function because the recompilation
Hello
one of our customers has two indices according to the functions that fall under the State "off" in some situations. After looking more closely at the situation, there are some things that my opinion are different from what I expected of a function-based index. Because I am unable to find anything about either on metalink (or I'm not asking the right question) I would appreciate a second opinion of you.
To keep things simple, I gave an example to illustrate the behavior. I use Oracle 12.1.0.2, although it can also be reproduced on versions 10.2 and 11.2.
It's my environment and three parameters that I find relevant to the discussion:
SQL> select banner from v$version; BANNER ---------------------------------------------------------------------------- Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production PL/SQL Release 12.1.0.2.0 - Production CORE 12.1.0.2.0 Production TNS for Linux: Version 12.1.0.2.0 - Production NLSRTL Version 12.1.0.2.0 - Production SQL> show parameter remote_dependencies NAME TYPE VALUE ------------------------------------ ----------- ---------- remote_dependencies_mode string TIMESTAMP SQL> show parameter query_rewrite NAME TYPE VALUE ------------------------------------ ----------- ------------- query_rewrite_enabled string TRUE query_rewrite_integrity string enforced
Test case:
SQL> CREATE OR REPLACE FUNCTION f1 (p_string IN VARCHAR2) 2 RETURN VARCHAR2 3 DETERMINISTIC 4 IS 5 BEGIN 6 RETURN lower(p_string); 7 END f1; 8 / Function created. SQL> CREATE TABLE tmp_t1 (a_string VARCHAR2(10)); Table created. SQL> INSERT INTO tmp_t1 VALUES ('a'); 1 row created. SQL> COMMIT; Commit complete. SQL> CREATE INDEX x1_tmp_t1 ON tmp_t1(f1(a_string)); Index created. SQL> set linesize 80; SQL> column index_name format a10; SQL> SELECT index_name, index_type, status, funcidx_status 2 FROM user_indexes; INDEX_NAME INDEX_TYPE STATUS FUNCIDX_ ---------- --------------------------- -------- -------- X1_TMP_T1 FUNCTION-BASED NORMAL VALID ENABLEDWe have our table and our based on an index function which basically converts the values to lowercase. From here on things, download a little weird. What happens with the index based on a function if the underlying function is recompiled? I always thought (and which is also stated in the Concepts and the use of function index (Doc ID 66277.1)) that the index would change its status to "disabled". Here is an excerpt of the said Doc ID:
The index depends on the State of the PL/SQL function. The index can be
struck down or rendered useless by changes to the function. The index is marked
People with DISABILITIES, if he is brought to the function or function is re-created.
The timestamp of the function is used to validate the index.
To allow the index after it is created, the function if the signature of the
the function is identical to the front:
ALTER INDEX ENABLE;
If the signature of functions is changed, to make the changes effective
in the index, the index must be renewed to make it valid.
ALTER INDEX REBUILD.
It seems that this is not the case, as the index remains valid and activate.
SQL> alter function f1 compile; Function altered. SQL> SELECT index_name, index_type, status, funcidx_status 2 FROM user_indexes; INDEX_NAME INDEX_TYPE STATUS FUNCIDX_ ---------- --------------------------- -------- -------- X1_TMP_T1 FUNCTION-BASED NORMAL VALID ENABLED
OK, explicitly recompiling function F1 single timestamp changed. What if we replace the function completely and we change the output of the function - for example we will switch from a LOWER function to SUPERIOR function in the body of the F1. Again, it is change that I thought would be not only to disable the index based on a function, but also force its reconstruction. At least that is my understanding of the explanation in Doc ID).
SQL> CREATE OR REPLACE FUNCTION f1 (p_string IN VARCHAR2) 2 RETURN VARCHAR2 3 DETERMINISTIC 4 IS 5 BEGIN 6 RETURN UPPER(p_string); 7 END f1; 8 / Function created. SQL> SELECT index_name, index_type, status, funcidx_status 2 FROM user_indexes; INDEX_NAME INDEX_TYPE STATUS FUNCIDX_ ---------- --------------------------- -------- -------- X1_TMP_T1 FUNCTION-BASED NORMAL VALID ENABLED
Should not be. Because of the function "create or replace" F1 never go through a "invalid" phase which may be necessary for index becomes unusable? What about queries on the TMP_T1 table? Does optimizer always uses access index or not? What about the results?
SQL> EXPLAIN PLAN SET statement_id='s1' FOR 2 SELECT a_string, f1(a_string) as f1_a_string, f1('a') as f1_literal 3 FROM tmp_t1 4 WHERE f1(a_string) = 'a'; Explained. SQL> SELECT * from table(dbms_xplan.display(statement_id=>'s1')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------ Plan hash value: 3133804460 ------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2024 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TMP_T1 | 1 | 2024 | 2 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | X1_TMP_T1 | 1 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------------------The index is used by the optimizer, see the results.
SQL> column f1_a_string format a15; SQL> column f1_literal format a15; SQL> SELECT a_string, f1(a_string) as f1_a_string, f1('a') as f1_literal 2 FROM tmp_t1 3 WHERE f1(a_string) = 'a'; A_STRING F1_A_STRING F1_LITERAL ---------- --------------- --------------- a a AA_STRING = value in the table
F1_A_STRING = value of f1 (a_string) but the value is not evaluated because it comes from an index, so tiny value (remember, at the time index created the function returned small values)
F1_LITERAL = value of the function f1 newly evaluated, using literal instead of the value in the table.
Predicate f1 (a_string) = 'a' should return no rows because no character uppercase is equivalent to "a". Query with f1 (a_string) = 'A' should return a line, but it doesn't.
SQL> SELECT a_string, f1(a_string) as f1_a_string, f1('a') as f1_literal 2 FROM tmp_t1 3 WHERE f1(a_string) = 'A'; no rows selectedAnyone know if this is an expected behavior? And, is it possible to disable the index based on a function whenever the underlying function signature is changed? The parameter query_rewrite_integrity = applied from
DOC-ID 66277.1 does not seem to do the trick:
(c) session variables
~~~~~~~~~~~~~~~~~~~~
QUERY_REWRITE_ENABLED (true, false),
QUERY_REWRITE_INTEGRITY (confidence, forced, stale_tolerated)
determines the optimizer to use index based on a function with
expressions using SQL, user defined functions functions.
TRUST: Oracle allows rewrites using relationships that have
was declared.
APPLIED: Oracle ensures and guarantees consistency and integrity.
STALE_TOLERATED: Oracle allows rewrites using vessels of the relationship not applied.
Used in the case of materialized views.
Set session variable cost function optimizer to choose the
a function-based index
Kind regards
SAMO
From the Manual 11.2 ( https://docs.oracle.com/cd/E11882_01/appdev.112/e41502/adfns_indexes.htm#ADFNS254 )
"If you change the semantics of a
DETERMINISTICrun and recompile, then you must manually rebuild all addicts depending on index and materialized views." Otherwise, they report results for the previous version of the function. »This note is not that I made my initial comment well - which was based on an incorrect memory the relationship between function-oriented and autonomous pl/sql functions, so I won't try to explain it. In fact, I went back to Oracle 8i practice to see if something had changed between yesterday and today and found that I had described exactly the behavior that the OP has been seeing. It's the way it is supposed to be.
Concerning
Jonathan Lewis
-
With the help of the index function based! =
Hello
Is it possible to create an index of basic function that is used when the! = operator is used?
I have a question with the following in the where clause
WHERE (SYMBOL = 1 AND LOGICAL_STATUS! = '8')
Thank you
Carl
Published by: Carl Holmes on November 5, 2009 10:18But you can create a FBI such as the following which will be a NULL entry when the condition is not put in correspondence:
CREATE INDEX .... ON TABLE .... (CASE WHEN SYMBOL=1 AND LOGICAL_STATUS !='8' THEN 1 ELSE NULL END);Then you might change your SQL to match the FBI:
WHERE CASE WHEN SYMBOL=1 AND LOGICAL_STATUS !='8' THEN 1 ELSE NULL END = 1 -
Digital output frequency seems to be twice the frequency generated by the basic function generator
Hi Labview forum,
I wrote a program (attached) Labview to generate 3 PWM, square wave, signals that has the same frequency and phase delay right (so that when a signal is off, the other signal is lit. Then the next signal). Everything seems to work fine except that the frequency of the PWM signals generated seems twice as the frequency given to the basic function generator. Anyone have any idea why this is happening? Anyhelp would be greatly appreciated.
Thank you!
Totally agree with the advice of all GerdW than the hardware timing of your hardware DAQ will be much more reliable. That said, part of what you are probably hitting is a little quirk of the primitive delay msec. Requests for 1 msec have long been particularly little reliable (although they * seem * to have improved in recent years, probably due to the better OS support in Win 7 or something).
I did minimal mods to your code with comments from you switch to a timed loop. My quick test showed he is good enough to hit the 1 length of loop of target msec.
-Kevin P
-
I have some functions will be pointers as parameter and CVI 2012 SP1, they work as before without problems but with CVI 2013 SP1 they are now incorrect.
Here the description of what is happening - I found a cure, but a duty adopt the old code and I think it's clear that nobody don't "captures" all lines in a 'big old code' which are affected (maybe):
I have functions
'function_XYZ(int *p_paraArr) '.
with 'p_paraArr' as pointers on a table (int).
Suppose I have another function
"fct_TOP (void)".
where is a local array variable which is inizialized by
"int TheArray [25] = {0};
and inside of this "TOP"-function-body I call a function ".
"function_XYZ (TheArray).
There are no complains of the compiler (CVI 2012 or 2013) and the code works (but the CVI 2013 only once!).
But if I put 'fct_TOP' loop I have a lag in the "TheArray' -memory. (The loop surrounds the function "TOP"! "")
This means that the result "TheArray" obtained from "function_XYZ (TheArray)" starts at index '1' not on the index '0' - as the first time that the function "function_XYZ (TheArray)" was performed. ".
The solution is:
I only replaced
"function_XYZ (TheArray)" (<1>)
by
"function_XYZ (&(TheArray[0]))" (<2>)
overall the program now works every time (in the whole loop)-the first time (in the loop).
In the second version (<2>) everything is necessary to "work well":
The '&' and parentheses "(...)", which contains the element that may be designated by the '& '.
And I hope that you believe me: I've tested several times, it was only "little" change that solved the problem.
So it seems that the ICB 2013 (SP1) is a kind of internal offset index by a repeated execution of the
"function_XYZ (TheArray).
but I don't know how or why but I see in debug mode by observing the expected against the values in the table received!
At the first time the (implicit) internal index of 'TheArray' is '0', but the following times (during the execution of the loop) the internal index passes to '1' (seen in the debugger because that all the expected values were shiftet like that!).
So there's an explicit index in the table ("function_XYZ (&(TheArray[0]))") necessary to make the first time of this clear code execution.
There are some good improvements in 2013 CVI (SP1) and I like this environment more than the 2012 version - but:
There are other "changes" also, in the compiler (or linker...?) that are more rigid than "in ancient times.
The problem of this kind of error is always the 'old code '!
It is expected of such behavior.
The compiler/linker do not complain (a complaint would be good!) writing but he made this mistake (in a loop).
By the way: my 'compilation Options' are set to 'Extended' (without change in the "..." ("- button - Options) and that all of the boxes, except the" OpenMP_support "-box are checked!"» So I think that I put the very rigid compiler - maybe there are some «...» ' - button - settings to get rid of this problem, but I have not found them/it.
My request:
-Check the stiffer compiler by the need of an explicit index
- or switch to the 'old' behavior with "function_XYZ (TheArray)" always refers to implicit index '0' of the element "TheArray". "."
Thank you for your messages, comments and suggestions.
-As I wrote before - maybe it's the style of programming or error"self made"... maybe...
.. But if I replace 'function_XYZ (TheArray)' by "function_XYZ (&(TheArray[0]))" and
then it works... Why so and not, if bothe the same? ...But as long as I do not post sample code, nobody is going to accept - I accept it. So consider this post more as an allusion to the fact that of the LW/CVI 2012-2013 LW/CVI more changed than just the LW - GUI or certain features: the compiler changed its 'way to'... or almost.
For this problem, I think that I will use the solution 'use no implicit and explicit pointers'.
Who should be a good idea taking into account
http://forums.NI.com/T5/LabWindows-CVI/fatal-run-time-error-dereference-of-out-of-bounds-pointer/TD-...mybe also only caused by wrong code... who knows... but for me it is a sufficient reason to act as I suggest above.
Best regards,
F. -
Continuity of the functions of the basic function generator
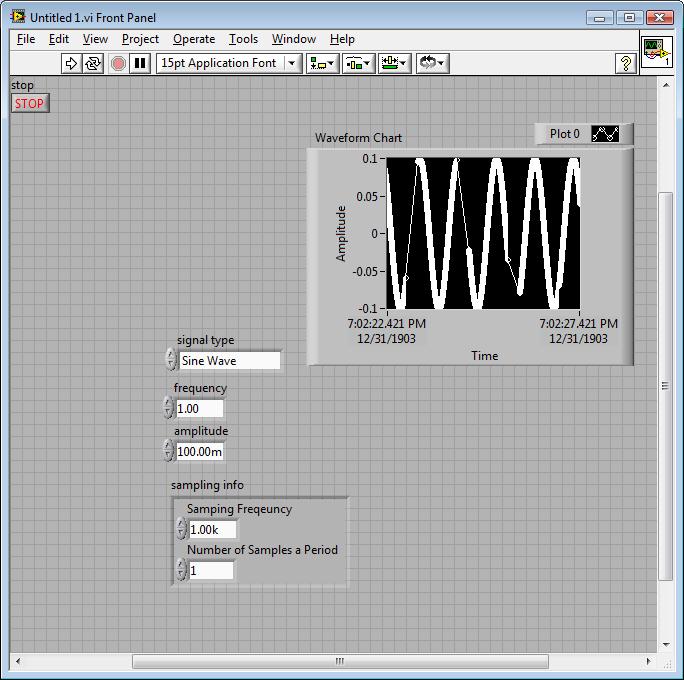
I would use the basic function generator to create a continuous waveform.
im not sure if Im not run or use the function generator correctly.
for each iternation of the while loop, I would like to only one point of the exit sinusoid.
Then the next iternation would produce the next point in the sinwave.
It seems to keep missing a few points
I'm not sure why - this.
It's hard to notice that if the plot is made only show few places for each sampling point.
I'm fairly certain that that VI uses the current timestamp as the value of x, so whenever your computer receives a bit busy (I'm off / 0, etc.) it is likely to be a small problem. You can always use the simple sinus with the number of the iteration (optimized for the desired period).
-
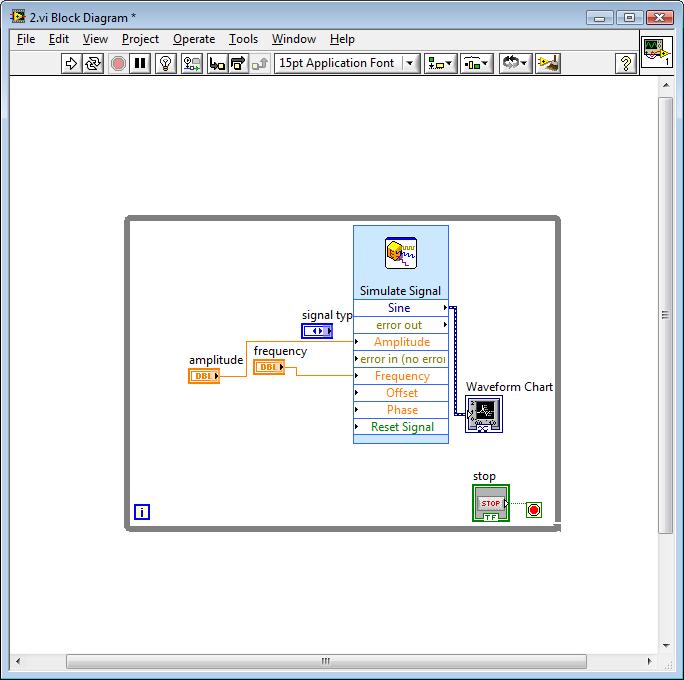
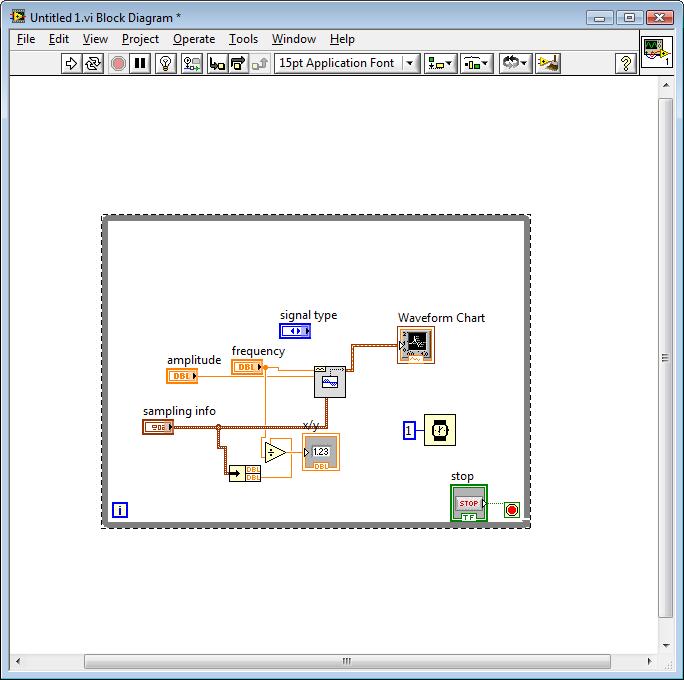
Continuity of the functions of the basic function generator and the right time
I need to create a sine wave, point by point, which will be forwarded to the MIP and finally to a channel of analog output on a PCI-6014
Ive tried a few different ways to do it, but everyone has some problems with her slider.
with the 'generator.vi of the base feature.
and also the "sine waveform.vi.
There seems to be problems with this lack of points.
someone helpfully pointed, its very likely windows interrupts the origin of the problem
Here is a schematic representation of the panels front and rear
the back panel
the façade has a few points that are missing
Another way to do that seems to work better known that the signal "simulate" express vi.
It's great because it's actually a way of sine 1htz occur at 1htz.
There are also all the points.
The problem is that as soon as I put in my request, she grinds to stop.
Program speed about changes 10khtz less than 1htz when the basic function generator is replaced with this express vi.
A third idea or concept that has been proposed is to put a programmer to slow the timetable.
It is once again, works fine, no more points are missed in the plot.
Yet, he kills again the speed of execution of the program as everything can wait 1ms (or the recripocal of sampling points interval time).
Someone at - it an idea on how I can get a sine wave in PID, then, in the analog waveform without a huge amount of the efficiency of the program. Im sure this is simple.
Nevermind
accedanta do the 2nd option from the top.
go just to increase the number of samples for now leave the rest of the fastest of the program
-
Hello
can you please explain the below topic?
That could leave gaps in the index, but the built-in function
NEXTallows you to iterate over any series of clues. -> this line- Arrays have a fixed upper bound, but the nested tables are unlimited (see Figure 5-1). Thus, the size of a nested table can increase dynamically.
Table in figure 5-1 against the nested Table
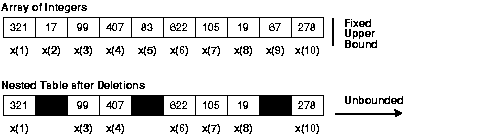
Description of the illustration pls81016_array_versus_nested_table.gif- Tables should be dense (have consecutive indices). So, you can delete individual items from a table. Initially, the nested tables are dense, but they can become sparse (have non-consecutive indexes). So, you can remove items from a table nested by using the integrated procedure
DELETE. That could leave gaps in the index, but the built-in functionNEXTallows you to iterate over any series of indexes.
Hello
Look at the second half of the Figure 5-1, the 'Nested Table after destruction". X (9), x.5 and x (2) elements have been removed, so the index values are 1, 3, 4, 6, 7, 8 and 10. There is a gap between 1 and 3, another gap between 4 and 6 and another gap between 8 and 10.
You could not use a simple FOR loop:
FOR j IN 1... 10
LOOP
...
END LOOP;
to iterate over a collection of rare as this, but you can use a loop where you get with the FOLLOWING indices:
j: = x.FIRST;
Then j IS NOT NULL
LOOP
...
j: = (j) x.NEXT;
END LOOP;
-
Question: I'm new to LR and did install you on a Mac desktop computer and laptop. On the laptop, the basic function under develop simply disappeared. I'm lost. Help.
This is a common problem. The basic Panel is simply hidden.
Billboards / of masking is actually a function of Lightroom, but it is intuitive--not many people know that there are - for the most newcomers are thrown when a Panel is somehow hidden.
Right-click anywhere in the area of the Panel on the right hand side and a context menu will appear.
Click on the basic option to re - appear the basic Panel.
-
TIP, GOLD and the INDEX FUNCTION-ORIENTED
RDBMS: 10.1.0.5.0
I'm trying to force an index based on a function in a query with a condition OR .
It seems that INDEX INDICATOR does not work if the query has an OR condition.
I created a test case to describe the problem:
The plan of the explain for a simple query command is:create table tab1 (col1 VARCHAR2(300)) ....load the table....... CREATE INDEX col1_IX ON tab1 ( my_FUNCTION(col1) ) TABLESPACE USERS ;
If the simple query has a CONDITION or:select * from tab1 where my_FUNCTION(col1) = '+23452081' Plan hash value: 2179519467 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 871 | 512K| 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| TAB1 | 871 | 512K| 2 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | COL1_IX | 348 | | 1 (0)| 00:00:01 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("my_FUNCTION"("COL1")='+23452081') Note ----- - dynamic sampling used for this statement
I tried to force the index using the trick without success:select * from tab1 where ( MY_FUNCTION(col1) = '+23452081' or col1 <> '') Plan hash value: 2211052296 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5183 | 3047K| 59 (31)| 00:00:01 | |* 1 | TABLE ACCESS FULL| TAB1 | 5183 | 3047K| 59 (31)| 00:00:01 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("COL1"<>'' OR "MY_FUNCTION"("COL1")='+23452081') Note ----- - dynamic sampling used for this statement
Can you help me?select /*+ index(tab1 col1_IX) */ * from tab1 where ( MY_FUNCTION(col1) = '+23452081' or col1 <> '') Plan hash value: 2211052296 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5183 | 3047K| 59 (31)| 00:00:01 | |* 1 | TABLE ACCESS FULL| TAB1 | 5183 | 3047K| 59 (31)| 00:00:01 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("COL1"<>'' OR "MY_FUNCTION"("COL1")='+23452081') Note ----- - dynamic sampling used for this statementPublished by: Dom Brooks on January 28, 2011 11:26
Sorry too hasty.
If you have an index on COL1 and your predicate can use this index, then you might get a BITMAP CONVERSION.
If you do not have an index on COL1 or you cannot use it, then you will do a FTS.
Useful relevant info:
Based on an index function are not used in the expansion of GOLD in 10gR 1 (or beyond - restriction still documented in 11 GR 2)
See here:
http://download.Oracle.com/docs/CD/B14117_01/AppDev.101/b10795/adfns_in.htm#1006464Dion Cho spoke here:
http://dioncho.WordPress.com/2009/07/31/function-based-index-and-or-expansion/ -
If the INSTR function will not use the INDEX o?
Hi all
I have a querry as
Is simple index on column Col1. If we use the index will be used or full table scan will happen in this scenario?Select * from Tab1 Where Instr(Tab1.Col1,'XX') >0 ;
Please give me explanatory answer because I have doubts
DhabasHello
You must use the index function if you want to avoid the full table scan. Check this box
SQL> create table tab1(col1 varchar(20)) 2 / Table created. SQL> insert into tab1 values ('XXAB') 2 / 1 row created. SQL> create index col1_idx on tab1(col1); Index created. SQL> explain plan for Select * from Tab1 Where Instr(Tab1.Col1,'XX') >0; Explained. SQL> set autotrace on SQL> Select * from Tab1 Where Instr(Tab1.Col1,'XX') >0; XXAB Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=5 Card=1 Bytes=12) 1 0 TABLE ACCESS (FULL) OF 'TAB1' (TABLE) (Cost=5 Card=1 Bytes =12) Statistics ---------------------------------------------------------- 4 recursive calls 0 db block gets 32 consistent gets 0 physical reads 0 redo size 234 bytes sent via SQL*Net to client 280 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> create index col1_idx2 on tab1(Instr(Col1,'XX')); Index created. SQL> Select * from Tab1 Where Instr(Tab1.Col1,'XX') >0; XXAB Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=2 Card=1 Bytes=12) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TAB1' (TABLE) (Cost=2 Ca rd=1 Bytes=12) 2 1 INDEX (RANGE SCAN) OF 'COL1_IDX2' (INDEX) (Cost=1 Card=1 ) Statistics ---------------------------------------------------------- 28 recursive calls 0 db block gets 22 consistent gets 0 physical reads 0 redo size 234 bytes sent via SQL*Net to client 280 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL>Thank you
AJ -
Index on two columns becomes the index of function?
Hello, I create a unique index with two columns, a number (9) and a date.
It becomes an index of feature based with the number column and a column sys hidden (date).
When I do queries that use this index the autotrace tells me it does things like this:
sys_nc00001$ > SYS_OP_DESCEND (datevalue)
sys_nc00001$ IS NOT NULL
How is he did not have a normal index?Use of ESCR does this.
Of http://download.oracle.com/docs/cd/B19306_01/server.102/b14200/statements_5010.htm
Oracle database processes Index descending as if they were focused on the index function.
-
OpenScript / functional HTTP / what is the index?
Hello
I'm designing functional tests of http and I found that the read failed because the index number has changed (I think)
Action, click:
I used (button properties)
[/ web:window[@index='1' or @title = "Export']/web:document[@index='0 information" or @name = "avye2ck58_16"] / web: a [@href ='{{db.] URL. URL}} / Mednext/faces/ADF. Task-Flow? [ADF.tfDoc=%2Fpages%2Fclmres%2Ftask-flows%2FCLMClaimInfoReportTaskFlow.xml & adf.tfId = CLMClaimInfoReportTaskFlow & inIsFromMain = true #' or @index = "6"]
now, I have:
[/ web:window[@index='1' or @title = "Export']/web:document[@index='0 information" or @name = "109lhcxnuz_11"] / web: a [@href ='{{db.] URL. URL}} / Mednext/faces/ADF. Task-Flow? [ADF.tfDoc=%2Fpages%2Fclmres%2Ftask-flows%2FCLMClaimInfoReportTaskFlow.xml & adf.tfId = CLMClaimInfoReportTaskFlow & inIsFromMain = true & _afrLoop = 947316640529847 & _afrWindowMode = 0 & _afrWindowId = null #' or @index = "7"]
Please what is this index = "7"? because even looking in the html code, I can't find such index.
Why is he changing of 6 to 7?
Thank you.
Michael.Michael
The index is just a number to find an object with, so if you are looking for a link with index 3, which would be the third link on the page, note that we use a statement or when looking for attributes, so it will search for a NAME or ID or the HREF attribute and if she is not one of them, it will search the index.
Usually, I tend to recommend people to remove the index of the path that the pages are today very dynamic and that can cause all sorts of unpredictable behavior, if we cannot find an object using its HTML attributes chances are that's not there, if its there attributes are dynamic you can use wildcards or regular expressions to generate a string of research better.
Concerning
Alex
-
Control values defined by the Index function only works for a running VI?
I've never used set of control values based on the Index before so I decided to compare it against two other ways to set the controls on the front panel, by using the invoke Ctrl.Val.Set node and nodes for the value property. But if the VI which I am trying to set the controls does not work I get error 1000 say "The VI isn't in a State compatible with this operation." When I run the VI which I am trying to set the controls, I get an error. This is VI really only work if the VI is running? I can't set the values before calling the VI to run dynamically?
I wonder why you do so in the first place.
a bit of history. This feature was added to the problem write to items in front by reference is about 1000 times slower than writing to the Terminal. I think that this feature works by writing directly to the transfer buffer. It always ends up by being slower than writing to the Terminal, but only about 10 times slower.
My company made use of this new feature. We needed it because we have updated thousands of values of frontage on the same VI by reference and labview couldn't keep it up (Yes, probably could have worked around him in a different way, but there is more detail than this...). If your ' e does not update thousands of articles, probably you should not use this feature. Performance savings is not worth the additional development effort it takes.
It does not work probably because the transfer buffer does not exist when the vi is not running
-
Using the index function in where clause of Exchange.
Hello friends,
I need your help with a problem.
I have a query that uses two table Say T1 and T2, where C1 is common column with which both are joined.
C1 is the primary key in T1, but no index available in Q2 for the C1. T1C2 is the column that we want to select.
(Note that table may be a Master table)
Now let's see the query:
Select T1C2
From T1, T2
where T2. C1 = T1. C1
Here where the clause may have other conditions and From clause can have other tables as needed.
I want to know that if I have change the query as continuation of leave my query to use the index available of T1. C1.
Select T1C2
from T1, T2
where T1. C1 = T2.C1
Then, the query uses the index available of T1. and I get better performance. Even a small improvement of performance help me much because this type of query is used in a loop where clause (so it will be run several times).
Please advise on this...
Kind regards
Lifexisxnotxsoxbeautiful...Hello
18:43:17 rel15_real_p>create table t1(c1 number primary key, c2 number); Table created. 18:43:26 rel15_real_p>create table t2(c1 number, c2 number); 18:45:08 rel15_real_p> 18:45:09 rel15_real_p>begin 18:45:09 2 for i in 1..100 18:45:09 3 loop 18:45:09 4 insert into t1(c1,c2) values (i,i+100); 18:45:09 5 end loop; 18:45:09 6 commit; 18:45:09 7 end; 18:45:09 8 / PL/SQL procedure successfully completed. 18:45:09 rel15_real_p> 18:45:09 rel15_real_p> 18:45:09 rel15_real_p>begin 18:45:09 2 for i in 1..100 18:45:09 3 loop 18:45:09 4 insert into t2(c1,c2) values (i,i+200); 18:45:09 5 end loop; 18:45:09 6 commit; 18:45:09 7 end; 18:45:09 8 / 18:45:23 rel15_real_p>select count(*) from t1; COUNT(*) ---------- 100 18:45:30 rel15_real_p>select count(*) from t2; COUNT(*) ---------- 100 18:45:49 rel15_real_p>select index_name,index_type from user_indexes where table _name='T1'; INDEX_NAME INDEX_TYPE ------------------------------ --------------------------- SYS_C0013059 NORMAL 18:48:21 rel15_real_p>set autotrace on 18:52:25 rel15_real_p>Select T1.C2 18:52:29 2 From T1, T2 18:52:29 3 where T2.C1 = T1.C1 18:52:29 4 / C2 ---------- 101 102 103 104 105 ..... ...... C2 ---------- 200 100 rows selected. Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=7 Card=100 Bytes= 900) 1 0 HASH JOIN (Cost=7 Card=100 Bytes=3900) 2 1 TABLE ACCESS (FULL) OF 'T1' (TABLE) (Cost=3 Card=100 By es=2600) 3 1 TABLE ACCESS (FULL) OF 'T2' (TABLE) (Cost=3 Card=100 By es=1300) Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 21 consistent gets 0 physical reads 0 redo size 1393 bytes sent via SQL*Net to client 562 bytes received via SQL*Net from client 8 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 100 rows processed 18:52:31 rel15_real_p>analyze table t1 compute statistics; Table analyzed. 18:55:35 rel15_real_p>analyze table t2 compute statistics; 18:55:38 rel15_real_p>set autotrace on 18:55:42 rel15_real_p>Select T1.C2 18:55:43 2 From T1, T2 18:55:45 3 where T2.C1 = T1.C1 18:55:46 4 / C2 ---------- 101 102 103 104 105 ..... ...... C2 ---------- 200 100 rows selected. Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=6 Card=100 Bytes=7 00) 1 0 MERGE JOIN (Cost=6 Card=100 Bytes=700) 2 1 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (TABLE) (Cost=2 Ca rd=100 Bytes=500) 3 2 INDEX (FULL SCAN) OF 'SYS_C0013059' (INDEX (UNIQUE)) ( Cost=1 Card=100) 4 1 SORT (JOIN) (Cost=4 Card=100 Bytes=200) 5 4 TABLE ACCESS (FULL) OF 'T2' (TABLE) (Cost=3 Card=100 B ytes=200) Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 23 consistent gets 0 physical reads 0 redo size 1393 bytes sent via SQL*Net to client 562 bytes received via SQL*Net from client 8 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 100 rows processed 18:56:56 rel15_real_p>Select T1.C2 18:56:56 2 From T1, T2 18:56:56 3 where T1.C1 = T2.C1 18:56:58 4 / C2 ---------- 101 102 103 104 105 ..... ...... C2 ---------- 200 100 rows selected. Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=6 Card=100 Bytes=7 00) 1 0 MERGE JOIN (Cost=6 Card=100 Bytes=700) 2 1 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (TABLE) (Cost=2 Ca rd=100 Bytes=500) 3 2 INDEX (FULL SCAN) OF 'SYS_C0013059' (INDEX (UNIQUE)) ( Cost=1 Card=100) 4 1 SORT (JOIN) (Cost=4 Card=100 Bytes=200) 5 4 TABLE ACCESS (FULL) OF 'T2' (TABLE) (Cost=3 Card=100 B ytes=200) Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 23 consistent gets 0 physical reads 0 redo size 1393 bytes sent via SQL*Net to client 562 bytes received via SQL*Net from client 8 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 100 rows processed-Pavan Kumar N
Maybe you are looking for
-
copy and paste volume too low noon
Hello I am a new user to Logic Pro X I recorded audio and midi in a song tracks, when I copied the first verse and stuck on the second verse, the volume of the second stanza is lower than the original one. How to fix this? Thank you!
-
The book that I use to learn selenium is based on firefox version 17.0.1. I know this is an old version, but I want to be consistent with the book. I installed this earlier version of firefox and now need to install a compatible version of firebug. T
-
How much space for Time Machine backups
Hello Is there a rule for how much space you may want to allow for Time Machine backups? I would like to partition the drive to have a room reserved for Time Machine back ups only. I realize that it is a personal preference. Each individual backup o
-
Satellite Pro M70: Question on the port on the left hand side
Another question regarding the Pro M70 PSM75E, next to the hard drive (left side) there is a port which you can take off. I took it of and it looks like a chip grafx or something: s someone with the M70 not what it is. Thanks again
-
how take off Windows Vista and put windows xp on? I get an error message.
I tried Vista windows on my computer but discovered that it is slow. I already tried to reinstall xp but I get an error message that says that I can't put it because the version of windows I have now is newer than the one I am trying to install. Help