Computed in a Create table columns
It's my create table statement:CREATE TABLE DTPartInv
(partinv_partnbr VARCHAR2 (10) NOT NULL,)
partinv_prodname VARCHAR2 (25).
partinv_desc VARCHAR2 (25).
partinv_manufact VARCHAR2 (25).
partinv_instock INTEGER NOT NULL,
partinv_category VARCHAR2 (20).
partinv_purchdate DATE,
partinv_loc VARCHAR2 (15).
partinv_price NUMBER (6.2),
partinv_vendor VARCHAR2 (20).
partinv_reorder INTEGER NOT NULL,
partinv_serial VARCHAR2 (20).
partinv_flag as (case when partinv_instock < partinv_reorder then 'X' else 'o' end), calculated column
CONSTRAINT DTPartInv_partinv_partnbr_pk
PRIMARY KEY (partinv_partnbr)
);
and here's my Insert into table instructions:
INSERT INTO DTPartInv VALUES ('XT40010E', 'TMC Inc', 2, Null, 'Exhaust' 'pipes', TO_DATE (11 April 10 ',' DD-MON-RR'), Null, 45.95, 'Oracle Auto Parts', 1, Null);
INSERT INTO DTPartInv VALUES ('CH9260', Null, 'oil filter', 'Mechanical parts', 5, 'Fuild filters', TO_DATE (15 January 10 ',' DD-MON-RR'), Null, 20.00, "wells auto P", 2, Null);
INSERT INTO DTPartInv VALUES ('15W40', Null, ' oil ',' sink the oil ', 20, 'Auto Fuilds', TO_DATE (February 10, 11 ',' DD-MON-RR'), Null, 10.00, "Oracle Auto Parts", 5, Null,);
INSERT INTO DTPartInv VALUES ('C9262', Null, 'fuel filter', 'Mechanical parts', 2, 'Fuild filters', TO_DATE (October 20, 10 ',' DD-MON-RR'), Null, 35.95, 'sink Auto Parts', 1, Null);
INSERT INTO DTPartInv VALUES ('PS7716', Null, ' Fuel/water separator', 'Parts', 4, 'Fuild filters', TO_DATE (December 9, 10 ',' DD-MON-RR'), Null, 50.00, 'sink Auto Parts', 1, Null);
INSERT INTO DTPartInv VALUES ('800142', Null, 'Valve PPI', 'Beink pipes Inc.', 10, 'Valves', TO_DATE (June 1, 11 ',' DD-MON-RR'), Null, 20.00, 'Oracle Auto Parts', 2, Null);
INSERT INTO DTPartInv VALUES ('TTS400', 'Clip Butt', Null, 'Beink pipes Inc.', 10, 'Valves', TO_DATE (October 31, 11 ',' DD-MON-RR'), Null, 15.95, 'Oracle Auto Parts', 2, Null);
INSERT INTO DTPartInv VALUES ('TBA400', 'Clamp Lap', Null, 'Beink pipes Inc.', 10, 'Valves', TO_DATE (November 10, 11 ',' DD-MON-RR'), Null, 30.00, 'Oracle Auto Parts', 2, Null);
INSERT INTO DTPartInv VALUES (Null, mechanical parts "Brake pads',"Mechanical CostVB", 5,", 'SC16650', TO_DATE (May 15, 11 ',' DD-MON-RR'), Null, 60.00, 'Adosql Auto Parts', 1, Null);
INSERT INTO DTPartInv VALUES ('OB46613', Null, 'emergency door latch", 'Mechanical CostVB', 3, 'Mechanical parts', TO_DATE ('01 - sept.-11 ',' DD-MON-RR'), Null, 45.95, 'Adosql Auto Parts', 1, Null);
And this is a sample of the error, I can test:
INSERT INTO DTPartInv VALUES ('XT40010E', 'TMC Inc', 2, Null, 'Exhaust' 'pipes', TO_DATE (11 April 10 ',' DD-MON-RR'), Null, 45.95, 'Oracle Auto Parts', 1, Null)
ERROR on line 1:
ORA-00947: not enough values
I need to understand what it is that I'm missing here. partinv_flag is supposed to be calculated according to partinv_instock and partinv_reorder.
Hello
Review the syntax for virtual columns in the manual of the SQL language:
http://download.Oracle.com/docs/CD/E11882_01/server.112/e26088/statements_7002.htm#sthref5146
You want something like this (showing only the relevant columns):
CREATE TABLE DTPartInv
(
partinv_instock INTEGER NOT NULL
, partinv_reorder INTEGER NOT NULL
, partinv_flag VARCHAR2 (1) AS ( CASE
WHEN partinv_instock < partinv_reorder
THEN 'X'
ELSE 'O'
END
)
);
INSERT INTO DTPartInv (partinv_instock, partinv_reorder) VALUES (100, 100);
Announcing the column names until the VALUES of Word key is a good idea in any case, and it is needed when you have virtual columns.
Tags: Database
Similar Questions
-
Create table column position questions?
Hi all
I'm just confused the saying that the positioning of column in tables is not serious for the relational database?
Do you agree or disagree.
For me, I do not share. Why?
If it isn't serious.SQL> create table a (a char(10),b number); Table created. SQL> create table b (b number, a char(10)); Table created. SQL> insert into a values ('a',1); 1 row created. SQL> commit; Commit complete. SQL> insert into b select * from a; insert into b select * from a * ERROR at line 1: ORA-01722: invalid number
Thank youKinsaKaUy? wrote:
OK maybe I interpreted in the wrong sense :))Can you help with this problem.
I have an EMP table with more than 10,000 rows and 500 columns.
The developer was asked to edit a column ATTRIBUTE1 of VARCHAR2 (10) number;
It is said that the column must be empty to change the data type, so I created a backup:
CREATE TABLE EMP_BAK AS SELECT * FROM EMP;
TRUNCATE TABLE EMP;
ALTER TABLE EMP MODIFY (ATTRIBUTE1 NUMBER);How can I insert it using the... INSERT INTO EMP SELECT * FROM EMP_BAK;
To aggraviate the situation the designer wants to move the position of the column in the 100th place in 10th place.
Assuming that you can't reason with out them, how to make this task easier?Thank you
Rather than create a new table and your complications mentioned above, you can follow the Sub method I guess.
ALTER TABLE DUMMY_ATTRIBUTE1 ADD EMP NUMBER;
UPDATE EMP
ATTRIBUTE1 SET = DUMMY_ATTRIBUTE1
WHERE 1 = 1;COMMIT;
UPDATE EMP
ATTRIBUTE1 SET = NULL
WHERE 1 = 1;COMMIT;
ALTER TABLE EMP CHANGE ATTRIBUTE1 NUMBER;
UPDATE EMP
SET DUMMY_ATTRIBUTE1 = ATTRIBUTE1
WHERE 1 = 1;COMMIT;
ALTER TABLE DROP COLUMN DUMMY_ATTRIBUTE1 EMP;
-
Create a column of table on RPD
Hello
I'm modeling a SPR file.
Is it possible to create a column in a table based on another column?
Kind regards
Hello
You can add additional columns in the layer of logic (Business Model).
See you soon.
Daan Bakboord
-
Create table with overlapping parallel dates in individual columns
I try to combine data from two different tables into a single table.
The data in table 1 contains locations of patients in a hospital where each record represents a single location. Patients can be transferred several times between the different beds resulting from multiple records for a single visit.
The data in table 2 contains the operative activity of the patient to the Hospital where each record represents either the GOLD of the suspension of the recovery room. A patient may have multiple operations in a single visit.
I would like to join/merge/mashup data in a single table that contains the data parallel to each other. In other words, dates of the appliance on one side of the table and the activity of GOLD on the other. The difficulty is that the two sets of overlapping of dates of arrival and departure. I wish that the final table to divide the originals in new records when the overlaps do not coincide.
Example:
Original in both events (one per table)
> Unit event has - from 14:00 to 18:00
> OR event B - from 16:00 to 17:00
Results in 3 documents (in the final)
> Event 1 - unit from 14:00 to 16:00, null dates GOLD
> Event 2 - unit from 16:00 to 17:00 OR 16:00 to 17:00
> Event 3 - unit from 17:00 to 18:00, null dates GOLD
Of course overlap can be more complex than the example above and adding code to indicate the 'ghosts' transfers to as well.
In the code below, the first visit of the GOLD occurs during the first mention of the unit.
Jason
Oracle 10g
[code]
create the table delme_Unit_dates
(id varchar2 (20))
, unit_rcd_id varchar2 (20)
, Unit_desc varchar2 (20)
Unit_in_code char (1)
Date of Unit_in_dttm
Date of Unit_out_dttm
Unit_out_code char(1));
create the table delme_or_dates
(id varchar2 (20))
, OR_rcd_id varchar2 (20)
, OR_desc varchar2 (20)
OR_in_code char (1)
Date of OR_in_dttm
Date of OR_out_dttm
OR_out_code char(1));
create the table delme_all_dates
(id varchar2 (20))
, Unit_OR_id varchar2 (40)
, Unit_rcd_id varchar2 (20)
, Unit_desc varchar2 (20)
Unit_in_code char (1)
Date of Unit_in_dttm
Date of Unit_out_dttm
Unit_out_code char (1)
, OR_rcd_id varchar2 (20)
, OR_Desc varchar2 (20)
OR_in_code char (1)
Date of OR_in_dttm
Date of OR_out_dttm
OR_out_code char (1));
insert into delme_unit_dates values ('123456', 'U1111', 'Unit A', 'A', to_date('2013-04-29 5:02:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-09 1:06:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 'B');
insert into delme_unit_dates values ('123456', 'U1112', 'Unit A', 'B', to_date('2013-05-09 1:06:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-09 4:53:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 'B');
insert into delme_unit_dates values ('123456', 'U1113', 'Unit A', 'B', to_date('2013-05-09 4:53:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-10 10:52:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 't');
insert into delme_unit_dates values ('123456', 'U1114', ' unity, 't', to_date('2013-05-10 10:52:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-11 11:30:00 AM', 'yyyy-mm-dd hh:mi:ss am'), 'B' ");
insert into delme_unit_dates values ('123456', 'U1115', ' unity, ' B', to_date('2013-05-11 11:30:00 AM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-12 4:00:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 'B');
insert into delme_unit_dates values ('123456', 'U1116', ' unity, ' B ', to_date('2013-05-12 4:00:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-16 2:14:00 PM', 'yyyy-mm-dd hh:mi:ss am'),' t ');
insert into delme_unit_dates values ('123456', 'U1117', 'Unit Z', ', to_date('2013-05-16 2:14:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-17 2:26:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 'B');
insert into delme_unit_dates values ('123456 ', 'U1118', 'Unit Z', 'B', to_date('2013-05-17 2:26:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-20 11:30:00 AM', 'yyyy-mm-dd hh:mi:ss am'),');
insert into delme_or_dates values ('123456', 'OR2221', 'or 1', 'O', to_date('2013-05-09 7:35:00 AM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-09 10:56:00 AM', 'yyyy-mm-dd hh:mi:ss am'), 'R');
insert into delme_or_dates values ('123456', 'OR2222', ' 5', 'R', to_date('2013-05-09 10:56:00 AM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-09 3:20:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 'U');
insert into delme_or_dates values ('123456', 'OR3331', 'or 2', 'O', to_date('2013-05-16 7:59:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-16 10:43:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 'R');
insert into delme_or_dates values ('123456', 'OR3332', ' 8', 'R', to_date('2013-05-16 10:43:00 PM', 'yyyy-mm-dd hh:mi:ss am'), to_date('2013-05-17 11:20:00 PM', 'yyyy-mm-dd hh:mi:ss am'), 'U');
commit;
-Is far from what we
Select
U.*
, o.*
Of
delme_Unit_dates U
delme_OR_dates O
where
U.ID = o.id
and U.UNIT_IN_DTTM < = O.OR_IN_DTTM
and U.UNIT_OUT_DTTM > = O.OR_IN_DTTM
order of U.UNIT_IN_DTTM, O.OR_IN_DTTM
;
[/ code]
Post edited by: Jason_S (changed a single date ' 2013 - 05 - 16 15:20 ' to ' 2013 - 05 - 09 15:20 ')
Hi, Jason.
Jason_S wrote:
I edited one of the dates in the original post.
Also although the inpatient unit and OR events are contiguous for a given patient (no overlap and without gaps - after that data are cleaned).
...
The sample data you posted a of gaps in the data of the GOLD. It is correct that the solution below works or not there are gaps in the two tables.
WITH got_dttm AS
(
SELECT unit_in_dttm AS DTMC
OF delme_unit_dates
UNION
SELECT unit_out_dttm AS DTMC
OF delme_unit_dates
UNION
SELECT or_in_dttm AS DTMC
OF delme_or_dates
UNION
SELECT or_out_dttm AS DTMC
OF delme_or_dates
)
all_periods AS
(
SELECT DTMC AS in_dttm
, (DTMC) ahead OF (ORDER BY DTMC) AS out_dttm
OF got_dttm
)
SELECT NVL (u.id, o.id) as id
u.unit_rcd_id
u.unit_desc
u.unit_in_code
p.in_dttm
p.out_dttm
o.or_rcd_id
o.or_desc
Of all_periods p
LEFT OUTER JOIN delme_unit_dates u WE u.unit_in_dttm<=>
AND u.unit_out_dttm > = p.out_dttm
LEFT OUTER JOIN delme_or_dates o WE o.or_in_dttm<=>
AND o.or_out_dttm > = p.out_dttm
WHERE p.out_dttm IS NOT NULL
ORDER BY p.in_dttm
;
You can use the query above to CREATE or a CREATE TABLE... AS command.
If you have as much data as you say, a table or materialized view would be maybe faster to use.
You will notice that I do understand not all columns; I would like to know if you have a problem, including them.
I don't know what id role plays in this problem. It is difficult to say when all rows have the same value.
-
ORA-14030: partitioning column does not exist in the CREATE TABLE statement
Hi all
We are trying to create a partition materialized view and get an error below.
ORA-14030: partitioning column does not exist in the CREATE TABLE statement
Our GL_BALANCES21 and GL_CODE_COMBINATIONS21 base tables is already divided by interval of the range on Code_combination_id.
In the same way that we try to partition the view materialized
We get the error.
ORA-14030: partitioning column does not exist in the CREATE TABLE statement
Where the clause there are 4 tables gl_balances21, gl_code_combinations21, gl_periods and gl_set_of_books.
CREATE MATERIALIZED VIEW apps. BAL_PART
PARTITION BY RANGE ("CODE_COMBINATION_ID")
(SCORE LOWER (80000) VALUES,
PARTITION OF LOWER VALUES (160000),
PARTITION OF LOWER VALUES (240000),
PARTITION OF LOWER VALUES (320000),
PARTITION OF LOWER VALUES (400000),
PARTITION OF LOWER VALUES (480000),
PARTITION OF LOWER VALUES (560000),
PARTITION OF LOWER VALUES (640000),
PARTITION OF LOWER VALUES (720000),
PARTITION OF VALUES LESS THAN (800000),
PARTITION OF LOWER VALUES (880000),
PARTITION OF LOWER VALUES (960000),
PARTITION OF VALUES LESS THAN (10400000),
PARTITION OF LOWER VALUES (11200000),
PARTITION OF LOWER VALUES (12000000),
PARTITION OF LOWER VALUES (12800000),
PARTITION OF VALUES LESS THAN (13600000),
PARTITION OF LOWER VALUES (14400000),
PARTITION OF VALUES LESS THAN (15200000),
PARTITION OF LOWER VALUES (16000000),
PARTITION OF VALUES LESS THAN (16800000),
PARTITION OF VALUES LESS THAN (17600000),
PARTITION OF VALUES LESS THAN (18400000),
PARTITION OF VALUES LESS THAN (19200000),
PARTITION OF LOWER VALUES (20000000),
PARTITION OF VALUES LESS THAN (20800000),
PARTITION OF VALUES LESS THAN (21600000),
PARTITION OF VALUES LESS THAN (22400000),
PARTITION OF VALUES LESS THAN (23200000),
PARTITION OF LOWER VALUES (24000000),
PARTITION OF VALUES LESS THAN (24800000),
PARTITION OF VALUES LESS THAN (25600000),
PARTITION OF VALUES LESS THAN (26400000),
PARTITION OF LOWER VALUES (27200000),
PARTITION OF LOWER VALUES (28000000),
PARTITION OF VALUES LESS THAN (28800000),
PARTITION OF VALUES LESS THAN (29600000),
PARTITION OF VALUES LESS THAN (30400000),
PARTITION VALUES LESS THAN (MAXVALUE))
QUICKLY REFRESH ON DEMAND
SELECT the QUERY REWRITE as
SELECT GL.GL_CODE_COMBINATIONS21. ROWID C1,
GL.GL_BALANCES21. ROWID C2,
"GL". "" GL_BALANCES21 ". "" ACTUAL_FLAG, "
"GL". "" GL_BALANCES21 ". "" CURRENCY_CODE "
"GL". "" GL_BALANCES21 ". "" PERIOD_NUM, "
"GL". "" GL_BALANCES21 ". "" PERIOD_YEAR ".
"GL". "" GL_BALANCES21 ". "" SET_OF_BOOKS_ID ""SOB_ID"
"GL". "" GL_CODE_COMBINATIONS21 ". "" CODE_COMBINATION_ID ""CCID.
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT1 ",.
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT10, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" DIRECTION11, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT12, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT13, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT14, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT2 ",.
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT3. "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT4, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT5, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT6, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT7. "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT8, "
"GL". "" GL_CODE_COMBINATIONS21 ". "" SEGMENT9, "
"GL". "" "" GL_PERIODS '. "" PERIOD_NAME,"
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_CR', 0) Open_Bal_Cr,
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_CR', 0) +.
NVL ("GL". "GL_BALANCES21" "." " (PERIOD_NET_CR', 0) Close_Bal_Cr,
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_DR', 0) Open_Bal_Dr,
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_DR', 0) +.
NVL ("GL". "GL_BALANCES21" "." " (PERIOD_NET_DR', 0) Close_Bal_Dr,
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_DR', 0).
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_CR', 0) Open_Bal,
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_DR', 0).
NVL ("GL". "GL_BALANCES21" "." " (BEGIN_BALANCE_CR', 0) +.
NVL ("GL". "GL_BALANCES21" "." " (PERIOD_NET_DR', 0).
NVL ("GL". "GL_BALANCES21" "." " (PERIOD_NET_CR', 0) Close_Bal,
NVL ("GL". "GL_BALANCES21" "." " (PERIOD_NET_CR', 0) Period_Cr,
NVL ("GL". "GL_BALANCES21" "." " (PERIOD_NET_DR', 0) Period_Dr
OF GL.GL_CODE_COMBINATIONS21.
GL.GL_BALANCES21,
GL.GL_SETS_OF_BOOKS,
GL.GL_PERIODS
WHERE GL.GL_BALANCES21. CODE_COMBINATION_ID = GL.GL_CODE_COMBINATIONS21. CODE_COMBINATION_ID
AND GL.GL_SETS_OF_BOOKS. SET_OF_BOOKS_ID = GL.GL_BALANCES21. SET_OF_BOOKS_ID
AND GL.GL_PERIODS. PERIOD_NUM = GL.GL_BALANCES21. PERIOD_NUM
AND GL.GL_PERIODS. PERIOD_YEAR = GL.GL_BALANCES21. PERIOD_YEAR
AND GL.GL_PERIODS. PERIOD_TYPE = GL.GL_BALANCES21. PERIOD_TYPE
AND GL.GL_PERIODS. PERIOD_NAME = GL.GL_BALANCES21. PERIOD_NAME
AND GL.GL_PERIODS. PERIOD_SET_NAME = GL.GL_SETS_OF_BOOKS. PERIOD_SET_NAME
and gl.GL_CODE_COMBINATIONS21.summary_flag! = « Y »
ERROR on line 54:
ORA-01013: user has requested the cancellation of the current operation
I checked the metalink note saying that ensure that all columns in a partitioning column list are columns of
the table being created.
Partition is already there, on the column of code_combination_id of gl_balances21 and gl_code_combinations21.
Please suggest.
Thank youIt's your mistake:
PARTITION BY RANGE ("CODE_COMBINATION_ID")but in your projection of column list, you have an alias he:
"GL"."GL_CODE_COMBINATIONS21"."CODE_COMBINATION_ID" "CCID",You must use the alias as a partition key, not the name fom the secondary table column.
--
John Watson
Oracle Certified Master s/n
http://skillbuilders.com -
Create table with data in the column
Create a new table, just want to know if there is a way to add a new column to the table with a value in all areas of this column when new rows are added to that this column will always be the same value
As...
name | address | zip | assets
Active will always be Yes.
I do a trigger?Use the default...
create table (test)
name varchar2 (20).
address varchar2 (40),
zip number (7).
Active VARCHAR2 (3) DEFAULT NULL NOT 'yes'); -
create table as a table with nested column type
On my Oracle DB (11.1), I have a table with a nested as a column type (and it is a partitioned table).
Now I need to copy partitions in a second table, and I use swap partition for it (with a table that is not partitioned as a table in step).
But there is a problem, because as the ordinary as sql ddl:
does not work when there is a table nested within a column type.create table table1_stage as select * from table1 where 1=2;
Is it possible easy to copy its structure (and to create the table that is not partitioned, so I suppose that no dbms_metadata package would help)?
Kind regards...>
does not work when there is a table nested within a column type.
>Will work indeed.
Read this
SQL> CREATE TYPE typtst IS TABLE OF VARCHAR2 (100); 2 3 / Type created. SQL> CREATE TABLE test1 2 ( 3 col1 VARCHAR2 (100), 4 col2 typtst 5 ) 6 NESTED TABLE col2 7 STORE AS list1; Table created. SQL> CREATE TABLE test2 2 NESTED TABLE col2 3 STORE AS list2 4 AS 5 SELECT * FROM test1; Table created. SQL>G.
-
Create table works, create materialized view only - long column names?
Hello.
I have no probs creating a table as well: -.
CREATE TABLE blah
(
DEVICE_ID
)
in select
"Device_ID" AS DEVICE_ID
"of"sum" Device"@ed_link_3
where "Device_ID" < 5;
But when I try to create a materialized view:
Blah1 CREATE MATERIALIZED VIEW
(
DEVICE_ID
)
< various materialized view parms >
in select
"Device_ID" AS DEVICE_ID
"of"sum" Device"@ed_link_3
where "Device_ID" < 5;
It fails with errors: -.
ORA-04052: error occurred when searching to the top of the remote object Aggregate.Device@ED_LINK_3
ORA-01948: length of the name of the identifier (31) exceeds maximum (30)
Is there a way to get around this?
Is the problem with the columns of the remote table of device, which I do NOT need to import to have column names that are longer than 30 characters?
For now, I want only the Device_ID column which is a simple 9 characters long.
Oh, and the remote database is MySQL.
I'm uncomfortable with the < parms of materialized view > as they work fine when I choose a different remote table with only short column names.
Thank you.To my knowledge, you have the option
(a) create view (with shortened column names or only with desired columns if they are already less than 30 char limit) side of mysql
(b) use dbms_passthrough to force the analysis to be done on mysql (as in the example provided by SY here use dbms_passthrough to create a view )
However, I prefer to stick to one), because with dbms_passtrhough, you retrieve row by row.Best regards
Maxim
-
ORA-00904 on CREATE TABLE with a virtual column based on the XMLTYPE content
Hello
This is another one for the gurus of the syntax...
Try the following, fails with ORA-00904: "MESSAGE". "' GETROOTELEMENT": invalid identifier
While it succeedsCREATE TABLE XML_TEST_VIRT ( MSG_TYPE GENERATED ALWAYS AS (MESSAGE.GETROOTELEMENT()) VIRTUAL, MESSAGE XMLTYPE NOT NULL, IE906 XMLTYPE DEFAULT NULL ) XMLTYPE COLUMN MESSAGE STORE AS SECUREFILE BINARY XML XMLTYPE COLUMN IE906 STORE AS SECUREFILE BINARY XML /
The GETROOTELEMENT from SYS member function. XMLTYPE is stated as "PARALLEL_ENABLE DETERMINISTIC" the method called is not the problem, as evidenced by the 2nd case.CREATE TABLE XML_TEST_VIRT ( MSG_TYPE GENERATED ALWAYS AS (EXTRACT(MESSAGE, '/*').GETROOTELEMENT()) VIRTUAL, MESSAGE XMLTYPE NOT NULL, IE906 XMLTYPE DEFAULT NULL ) XMLTYPE COLUMN MESSAGE STORE AS SECUREFILE BINARY XML XMLTYPE COLUMN IE906 STORE AS SECUREFILE BINARY XML /
Using the MESSAGE column that is of type XMLTYPE directly seems to be the problem. But the question is "why." The result of the EXTRACT function is of type XMLTYPE and call his works of members, the column is also of type XMLTYPE still call its members fails...
Thanks in advance for any ideas on that.
Best regards
PhilippeGoing on the means to go far, far back.
-
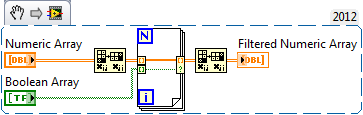
Create table 2d by pulling larger 2d table columns, as indivated by an array of Boolean
Hello
I have a 2d chart with 16 columns that contain data from different input channels. I also have a 1 d array of Boolean (length 16) corresponding to these columns. In the table of Boolean 1 d, if a value is true, I want this column in table 2d to stay. If the value in the table of Boolean 1 d is wrong, I want to delete the corresponding column.
Thus, for example, if the table of Boolean 1 d looks like this:
[T T T T F F T T T F T T F F T F]
the new 2d array would be 10 columns, which correspond to the columns of the old 16-column of table 1, 2, 3, 4, 7, 8, 9, 11, 12 and 15.
I am very new to labview (programming just started yesterday). Can someone help a newbie to do something that is probably simple? In my view, that there will be an iteration back through the deletion of rows and 16 columns table columns as they come if the value of the Boolean vector is false, or iterate forward through the 16 columns and add columns to a table if the value of the Boolean vector is true... but I don't know how to do this.
Thank you
Matt
If you have 2012 you could just do this:
-Ryan S.
-
Add default column have Boolean when creating table
Hello
I am trying to create a table with the default value for boolean data, as shown below:
CREATE TABLE test_users)
user_id number (11) NOT NULL PRIMARY KEY,
first name varchar2 (50).
VARCHAR2 (50) last_name,.
e-mail varchar2 (100),
user_password varchar2 (100),
Zip_code varchar2 (50).
title varchar2 (100),
Description varchar2 (2000).
PICTURE_PATH varchar2 (2000).
one_time_activation number (1) value default null check (one_time_activation in (0,1)).
one_time_activation_code varchar2 (100),
is_active number (1) value default null check (is_active in (0,1)).
security_question_id number (11),
security_answer varchar2 (100),
inserted_date DateTime,
DateTime MODIFIED_DATE,
check the number IS_DELETED (1) default 0 (is_deleted in (0,1)).
last_login_date DateTime,
no_of_views number (20) default 0,.
is_redirect_to_edit_profile number (1) 1 check default (is_redirect_to_edit_profile in (0,1)).
present_login_date DateTime,
check the is_interested_ab_membership number (1) default 0 (is_interested_ab_membership in (0,1)).
joined_date DateTime,
removed_date DateTime,
is_admin_deleted number (1) default check 0 (is_admin_deleted in (0,1)).
moderated_by number (11),
is_subscribe_newsletter number (1) default check 0 (is_subscribe_newsletter in (0,1)).
user_pagination number (3) 15 by DEFAULT
);
but I'm getting
Error on line 1
ORA-00902: invalid data type
Thank youWhatever your question has to do with sql developer?
You don't even tell what database you want to use.
Oracle does not support a data type 'datetime' so your create table statement will not work in Oracle.
If you replace "datetime" 'date' the table creates very well.
-
Put a % sign in a label (Table column)
Hi all
I created a very basic dashboard of the percentages of availability for the service display. The default (medium) label appears as availability average reference (%):


I changed it has something a little more meaning to our customer:

However, it would be good to put in something like percentage of availability of Service (target 99%), but I can't get the % symbol to display. I tried to use the backslash % (-%) to comment out a special meaning, but it does not work and the default label is displayed instead. Does anyone know how to display a "%" symbol in a table/column label? I also tried a double backslash, double percentage, single and double quotes, brackets...
Thank you
Brian
I took an additional screen shots. It is the foglight 5.6.7 version. Note the label for the column.


-
Hello
I am train to write a procedure where I would spend the table as a parameter name and then the code would determine it is column names, and then he would insert records in each column depending on the data type. could someone help me with this.
Thank you
SM
Hello
Perhaps you need to dummy data just for the table.
Here is my exercise
create or replace procedure generate_rows(p_table_name varchar2, p_count number) is -- function insert_statement(p_table_name varchar2) return clob is l_columns clob; l_expressions clob; l_sql clob default 'insert into p_table_name (l_columns) select l_expressions from dual connect by level <= :p_count'; begin select -- l_columns listagg(lower(column_name), ',') within group (order by column_id), -- l_expressions listagg( case when data_type = 'DATE' then 'sysdate' when data_type like 'TIMESTAMP%' then 'systimestamp' when data_type = 'NUMBER' then replace('dbms_random.value(1,max)', 'max', nvl(data_precision - data_scale, data_length) ) when data_type = 'VARCHAR2' then replace(q'|dbms_random.string('a',data_length)|', 'data_length', data_length ) else 'NULL' end, ',') within group (order by column_id) into l_columns, l_expressions from user_tab_columns where table_name = upper(p_table_name); -- l_sql := replace(replace(replace(l_sql, 'p_table_name', p_table_name), 'l_columns', l_columns), 'l_expressions', l_expressions); -- debug dbms_output.put_line(l_sql); -- return l_sql; end; begin execute immediate insert_statement(p_table_name) using p_count; end; / -- test create table mytable( id number(4,0), txt varchar2(10), tstz timestamp with time zone, dt date, xml clob ) ; set serveroutput on exec generate_rows('mytable', 10); select id, txt from mytable ; drop procedure generate_rows ; drop table mytable purge ; Procedure GENERATE_ROWS compiled Table MYTABLE created. PL/SQL procedure successfully completed. insert into mytable (id,txt,tstz,dt,xml) select dbms_random.value(1,4),dbms_random.string('a',10),systimestamp,sysdate,NULL from dual connect by level <= :p_count ID TXT ---------- ---------- 3 WnSbyiZRkC 2 UddzkhktLf 1 zwfWigHxUp 2 VlUMPHHotN 3 adGCKDeokj 3 CKAHGfuHAY 2 pqsHrVeHwF 3 FypZMVshxs 3 WtbsJPHMDC 3 TlxYoKbuWp 10 rows selected Procedure GENERATE_ROWS dropped. Table MYTABLE dropped.and here is the vision of Tom Kyte for the same https://asktom.oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:2151576678914
Edit: to improve my code, it must use p_count as bind as Tom.
-
epengs.dB (ENG) + error CREATE TABLE PS_1099C_CUST_DATA
PT 8.54.10FSCM 9.2 (picture 13)
SQL Server 2008 (64-bit)
We get below error when we are in the stages of the creation of the DB via DM scripts.
Started the: Tue Nov 17 02:10:54 2015
Release of Data Mover: 8.54.10
Database: FSDMO92 (ENG)
Input file: E:\FSDMO92\data\epengs.db (ENG)
Import 1099C_CUST_DATA
Create Table 1099C_CUST_DATA
-SQL error. Position of the error: 0 return: 8601 -.
[Microsoft] [SQL Server Native Client 10.0] [SQL Server] Column, parameter, or variable #4: could not find the PSDATE data type.
[Microsoft] [SQL Server Native Client 10.0] [SQL Server] Instructions could not be prepared. (SQLSTATE 37000) 8180
CREATE TABLE PS_1099C_CUST_DATA (CUST_ID varchar (15) NOT NULL, TIN varchar (20) NOT NULL, TAXPAYER_ID varchar (14) is NOT NULL, ASOF_DATE PSDATE NULL, decimal ENTRY_AMT (26, 3) NOT NULL, decimal INTEREST_EXPENSE (26, 3) NOT NULL, Name1 varchar (40) NOT NULL, NAME2 varchar (40) NOT NULL, NOT NULL of the varchar (55), of ADDR_LN1 ADDR_LN2 varchar (55) NOT NULL) , ADDR_LN3 varchar (55) NOT NULL, ADDR_LN4 varchar (55) NOT NULL, CITY varchar (30) NOT NULL, NOT NULL of the varchar (6) State, POSTAL varchar (12) NOT NULL, TEL varchar (24) is NOT NULL, NAME varchar (50) NOT NULL, Name3 varchar (40) NOT NULL, name4 varchar (40) NOT NULL, CITY3 varchar (30) NOT NULL, Address1 varchar (55) NOT NULL , State3 varchar (6) NOT NULL, POSTAL...
Error: Unable to process create statement for 1099C_CUST_DATA
Ending: Tue Nov 17 02:10:56 2015
Unsuccessful endCannot find the data type PSDATE comes here. Looks like one of the required scripts has not been executed. It has been long since I am on a site of SQL Server, but I understand the substance of this issue. PeopleSoft creates a customized in SQL Server PSDATE data type which is an extension of the date format.
Rather than to point you to the script, I suggest you go back and find where this prerequisite is necessary and make sure that you are not lacking in any other required component.
-
Value separated by commas in a table column to get each field separtely?
Hello
I have the table that a column has values separated by commas in it. This table is populated using SQL LOADER, which is staging table.
I need to retrieve the records of these values separated by commas.
format of. CSV file is as -
A separate file of pipes.
DHCP-1-1-1. WNLB-CMTS-01-1,WNLB-CMTS-02-2|
DHCP-1-1-2. WNLB-CMTS-03-3,WNLB-CMTS-04-4,WNLB-CMTS-05-5|
DHCP-1-1-3. WNLB-CMTS-01-1.
DHCP-1-1-4. WNLB-CMTS-05-8,WNLB-CMTS-05-6,WNLB-CMTS-05-0,WNLB-CMTS-03-3|
DHCP-1-1-5 | WNLB-CMTS-02-2,WNLB-CMTS-04-4,WNLB-CMTS-05-7|
CREATE TABLE link_data (dhcp_token VARCHAR2 (30), cmts_to_add VARCHAR2 (200), cmts_to_remove VARCHAR2 (200));
insert into link_data values ('dhcp-1-1-1','wnlb-cmts-01-1,wnlb-cmts-02-2',null);
insert into link_data values ('dhcp-1-1-2','wnlb-cmts-03-3,wnlb-cmts-04-4,wnlb-cmts-05-5',null);
insert into link_data values ('dhcp-1-1-3','wnlb-cmts-01-1',null);
insert into link_data values ('dhcp-1-1-4','wnlb-cmts-05-8,wnlb-cmts-05-6,wnlb-cmts-05-0,wnlb-cmts-03-3',null);
insert into link_data values ('dhcp-1-1-5','wnlb-cmts-02-2,wnlb-cmts-04-4,wnlb-cmts-05-7',null);
Here the cmts_to_add column has comma separted
I need values such as -.
> for wnlb-cmts-01-1,wnlb-cmts-02-2 > > wnlb-CMTS-01-1
> > wnlb-CMTS-02-2
> for wnlb-cmts-03-3,wnlb-cmts-04-4,wnlb-cmts-05-5 > > wnlb-CMTS-03-3
> > wnlb-CMTS-04-4
> > wnlb-CMTS-05-5
And so on...
I do this because it's the staging table and I load data into the main tables using this table.
This second field contain different values as the simple comma-delimited string.
I need to write a PLSQL block to insert into the main table after checking as if dhcp-1-1-1 and wnlb-CMTS-01-1 is present in the main table so not to introduce other insert a new record.
To meet this requirement, I need to get the distinct value of the cmts_to_add column to insert into DB.
the value will be inserted as dhcp-1-1-1_TO_wnlb-cmts-01-1 and dhcp-1-1-1_TO_wnlb-cmts-02-2 for the first row of the array of link_data.
The process will also be same for the rest of the lines.
I use the function substrt and instr for this problem, but its does not work.
declare
cursor c_link is select * from link_data.
l_rec_link link_data % rowtype;
l_dhcp varchar2 (30);
l_cmts varchar2 (20000);
l_cmts_1 varchar2 (32000);
Start
Open c_link;
loop
extract the c_link in l_rec_link;
l_cmts: = l_rec_link.cmts_to_add;
loop
l_cmts_1: = substr (l_cmts, 1, instr(l_cmts,',')-1);
dbms_output.put_line (l_cmts_1);
end loop;
dbms_output.put_line(l_dhcp||) e '|| l_cmts);
When the output c_link % notfound;
end loop;
exception
while others then
Dbms_output.put_line ('ERROR' |) SQLERRM);
end;
Its a peusdo code I write, but it also gives me the wrong answer it gives me error ORA-20000: ORU-10027: buffer overflow, limit of 20000 bytes
I am using-
Oracle Database 11 g Enterprise Edition Release 11.2.0.1.0 - 64 bit Production
Please tell me if my problem isn't clear!
Hello
little 'trick': Add a comma at the end of the chain... So it's easier to deal with the fact that there are zero, one, or N components...
CREATE TABLE link_data (dhcp_token VARCHAR2 (30), cmts_to_add VARCHAR2 (200), cmts_to_remove VARCHAR2 (200));
insert into link_data values ('dhcp-1-1-1','wnlb-cmts-01-1,wnlb-cmts-02-2',null);
insert into link_data values ('dhcp-1-1-2','wnlb-cmts-03-3,wnlb-cmts-04-4,wnlb-cmts-05-5',null);
insert into link_data values ('dhcp-1-1-3','wnlb-cmts-01-1',null);
insert into link_data values ('dhcp-1-1-4','wnlb-cmts-05-8,wnlb-cmts-05-6,wnlb-cmts-05-0,wnlb-cmts-03-3',null);
insert into link_data values ('dhcp-1-1-5','wnlb-cmts-02-2,wnlb-cmts-04-4,wnlb-cmts-05-7',null);
COMMIT;SET SERVEROUT ON
DECLARE
l_cmts VARCHAR2 (200 CHAR);
l_cmts_1 VARCHAR2 (200 CHAR);
BEGIN
FOR r IN (SELECT dhcp_token, cmts_to_add |) ',' cmts
OF link_data
)
LOOP
l_cmts: = r.cmts;
l_cmts_1: = SUBSTR (l_cmts, 1, INSTR (l_cmts, ",") - 1);
While l_cmts_1 IS NOT NULL
LOOP
DBMS_OUTPUT. Put_line (r.dhcp_token |) '|' || l_cmts_1);
l_cmts: = SUBSTR (l_cmts, INSTR (l_cmts, ",") + 1);
l_cmts_1: = SUBSTR (l_cmts, 1, INSTR (l_cmts, ",") - 1);
END LOOP;
END LOOP;
END;
/
DHCP-1-1-1. WNLB-CMTS-01-1
DHCP-1-1-1. WNLB-CMTS-02-2
DHCP-1-1-2. WNLB-CMTS-03-3
DHCP-1-1-2. WNLB-CMTS-04-4
DHCP-1-1-2. WNLB-CMTS-05-5
DHCP-1-1-3. WNLB-CMTS-01-1
DHCP-1-1-4. WNLB-CMTS-05-8
DHCP-1-1-4. WNLB-CMTS-05-6
DHCP-1-1-4. WNLB-CMTS-05-0
DHCP-1-1-4. WNLB-CMTS-03-3
DHCP-1-1-5 | WNLB-CMTS-02-2
DHCP-1-1-5 | WNLB-CMTS-04-4
DHCP-1-1-5 | WNLB-CMTS-05-7Best regards
Bruno Vroman.
Maybe you are looking for
-
0x000000C2 after connection XP SP2 BSOD error - cannot find the drivers for model
HelloWindows XP from. Once the connection with password, it immediately crashes with the following error:0x000000C2 (0 x 00000043, 0xD76A2000, 0, 0) Try using ERD - but it does not find the system of windows XP - made notrecognizes hard drive - need
-
Jitter of RT! Can multiple readings to a variable / cluster cause a deadlock condition?
Howdy do. While gradually develop and test an application on a crio9068 (RT linux) I started to see 'finished later?' in my main timed loop indicator flicker. Start pulling my hair out trying to figure out how to prevent this. I did a 'max hold' vi a
-
I brought the new tab omini. After the update and insert memory card tab showed ocons inadmissible start button. Now after trying several times it don't be startedany more.
-
People, There are printers HP laserjet capable of 2 sides print A6? Thanks in advance James
-
IOS router with several groups of VPN
Similar to a discussion, I read with a PIX firewall, I need to set up multiple VPN groups on IOS-based router to support different levels of security. For example, a VPN "GUESTS" group would only have access to 1 server, while the VPN "ADMIN" group w