concatenation of lines having the same value of the column
Hi allI was struck with a situation, please find the example in the following table
create table test (varchar2 (20) Column1, Column2 varchar2 (20), Column3 varchar2 (20))
Insert test values ('A1', 'x 1', 's1');
Insert test values ('A1', 'x 1', 's2');
Insert test values ('A1', 'x 1', 's4');
Insert test values ('A1', 'x 2', 's1');
Insert test values ('A1', 'x 2', 's2');
Insert test values ('A1', 'x 2', 's3');
so finally the teable looks like this
Column1 - Column2 - Column3
A1-----------------------x1------------------------s1
A1-----------------------x1------------------------s2
A1-----------------------x1------------------------s4
A1-----------------------x2------------------------s1
A1-----------------------x2------------------------s2
A1-----------------------x2------------------------s3
so now I want the o/p, based on common values for i.e Column2 Column3
Column1 - Column2 - Column3
A1-----------------------x1,x2-------------------s1,s2
A1-----------------------x1------------------------s4
A1-----------------------x2------------------------s3
How this could be achieved, any help would be appreciated
Thank you
Simi
You can use wm_concat... but are not documented in 10g
SELECT column1,
column2 ,
wm_concat(column3)
FROM
(SELECT column1 ,
wm_concat(column2) column2,
MAX(column3) column3
FROM test
GROUP BY column1,
column3
)
GROUP BY column1,
column2;
Ravi Kumar
Tags: Database
Similar Questions
-
lines to the column and summation
Hi everyone, I am using oracle 10g consider the following data:
WITH the data as {}
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 123.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 111.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 666.23 amount OF the dual UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 888.23 amount OF the double UNION
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 333.23 amount OF the dual UNION ALL
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 222.23 amount OF double UNION ALL
SELECT mntrid "XTR3", "CCC" ctid, ' hi tech 3 ' description, code 'PC', 777.23 amount OF double
}
I would like secret lines at column and add the amounts. my output should be like this
MNTRID CTID DESCRIPTION MAIN PC PAYROLL
XTR AAA hi tech 234,46 1554.46
XTR2 BBB Hi tech2 555.46
CCC XTR3 Hi Tech 3 777.23
what I do is converting lines to the column and the display of the sum. for example, for mntrid = XTR I get the sum of all MAIN lines and the lines all PAY and PC.
Since there is no line of PC for XTR I display null.
can someone help me write a query that displays the output in oracle 10g above?
Hello
elmasduro wrote:
It's great Frank. Thank you very much.
I have a request. What happens if I want to add total main grad, wages, the pc? How would I do that.
output
Total general AFFID CTID DESCRIPTION MAIN PAY PC
XTR AAA hi tech 234.46 1554,46 1788.92
XTR2 BBB Hi tech2 555,46 555.46
CCC XTR3 Hi Tech 3 777,23 777.23
It's just plain old garden-variety SUM:
SELECT Mntrid
ctid
Description
, SUM (CASE WHEN code = "MAIN" THEN rise END) AS main
, SUM (CASE code WHEN = "SALARY" THEN rise END) AS pay
, SUM (CASE WHEN code = 'PC', THEN rise END) AS pc
, The SUM of (amount) AS grand_total-* NEW *.
FROM the data
GROUP BY mntrid
ctid
Description
;
-
lines to the column for large number of files
my version of the database is 10 gr 2
I want to transfer the lines to the column... .i have seen examples of small no records, but how can it be done if there are more the 1,000 records in a table...?
Here is the example of data I'd like to change to column
SQL> / NE RAISED CLEARED RTTS_NO RING --------------- ------------------------------ ------------------------------ -------------- ----------------------------------------------------------------------------------- 10100000-1LU 22-FEB-2011 22:01:04/28-FEB-20 22-FEB-2011 22:12:27/28-FEB-20 SR-10/ ER-16/ CR-25/ CR-29/ CR-26/ RIDM-1/ NER5/ CR-31/ RiC600-1 11 01:25:22/ 11 02:40:06/ 10100000-2LU 01-FEB-2011 12:15:58/06-FEB-20 05-FEB-2011 10:05:48/06-FEB-20 RIMESH/ RiC342-1/ 101/10R#10/ RiC558-1/ RiC608-1 11 07:00:53/18-FEB-2011 22:04: 11 10:49:18/18-FEB-2011 22:15: 56/19-FEB-2011 10:36:12/19-FEB 17/19-FEB-2011 10:41:35/19-FEB -2011 11:03:13/19-FEB-2011 11: -2011 11:08:18/19-FEB-2011 11: 16:14/28-FEB-2011 01:25:22/ 21:35/28-FEB-2011 02:40:13/ 10100000-3LU 19-FEB-2011 20:18:31/22-FEB-20 19-FEB-2011 20:19:32/22-FEB-20 INR-1/ ISR-1 11 21:37:32/22-FEB-2011 22:01: 11 21:48:06/22-FEB-2011 22:12: 35/22-FEB-2011 22:20:03/28-FEB 05/22-FEB-2011 22:25:14/28-FEB -2011 01:25:23/ -2011 02:40:20/ 10100000/10MU 06-FEB-2011 07:00:23/19-FEB-20 06-FEB-2011 10:47:13/19-FEB-20 101/IR#10 11 11:01:50/19-FEB-2011 11:17: 11 11:07:33/19-FEB-2011 11:21: 58/28-FEB-2011 02:39:11/01-FEB 30/28-FEB-2011 04:10:56/05-FEB -2011 12:16:21/18-FEB-2011 22: -2011 10:06:10/18-FEB-2011 22: 03:27/ 13:50/ 10100000/11MU 01-FEB-2011 08:48:45/22-FEB-20 02-FEB-2011 13:15:17/22-FEB-20 1456129/ 101IR11 RIMESH 11 21:59:28/22-FEB-2011 22:21: 11 22:08:49/22-FEB-2011 22:24: 52/01-FEB-2011 08:35:46/ 27/01-FEB-2011 08:38:42/ 10100000/12MU 22-FEB-2011 21:35:34/22-FEB-20 22-FEB-2011 21:45:00/22-FEB-20 101IR12 KuSMW4-1 11 22:00:04/22-FEB-2011 22:21: 11 22:08:21/22-FEB-2011 22:22: 23/28-FEB-2011 02:39:53/ 26/28-FEB-2011 02:41:07/ 10100000/13MU 22-FEB-2011 21:35:54/22-FEB-20 22-FEB-2011 21:42:58/22-FEB-20 LD MESH 11 22:21:55/22-FEB-2011 22:00: 11 22:24:52/22-FEB-2011 22:10:could you do something like that?
with t as (select '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised , '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared from dual union select '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' from dual ) select * from( select NE, regexp_substr( raised,'[^/]+',1,1) raised, regexp_substr( cleared,'[^/]+',1,1) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,2) , regexp_substr( cleared,'[^/]+',1,2) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,3) , regexp_substr( cleared,'[^/]+',1,3) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,4) , regexp_substr( cleared,'[^/]+',1,4) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,5) , regexp_substr( cleared,'[^/]+',1,5) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,6) , regexp_substr( cleared,'[^/]+',1,6) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,7) , regexp_substr( cleared,'[^/]+',1,7) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,8) , regexp_substr( cleared,'[^/]+',1,8) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,9) , regexp_substr( cleared,'[^/]+',1,9) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,10) , regexp_substr( cleared,'[^/]+',1,10) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,11) , regexp_substr( cleared,'[^/]+',1,11) cleared from t ) where nvl(raised,cleared) is not null order by neNE RAISED CLEARED 10100000-1LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:06 10100000-1LU 22-FEB-2011 22:01:04 22-FEB-2011 22:12:27 10100000-2LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:13 10100000-2LU 19-FEB-2011 10:36:12 19-FEB-2011 10:41:35 10100000-2LU 19-FEB-2011 11:03:13 19-FEB-2011 11:08:18 10100000-2LU 19-FEB-2011 11:16:14 19-FEB-2011 11:21:35 10100000-2LU 06-FEB-2011 07:00:53 06-FEB-2011 10:49:18 10100000-2LU 01-FEB-2011 12:15:58 05-FEB-2011 10:05:48 10100000-2LU 18-FEB-2011 22:04:56 18-FEB-2011 22:15:17You should be able to do without all these unions using a connection by but I can't quite make it work
the following does not work, but perhaps someone can answer.select NE, regexp_substr( raised,'[^/]+',1,level) raised, regexp_substr( cleared,'[^/]+',1,level) cleared from t connect by prior NE = NE and regexp_substr( raised,'[^/]+',1,level) = prior regexp_substr( raised,'[^/]+',1,level + 1)Published by: pollywog on March 29, 2011 09:38
Here it is with the type clause that gets rid of all unions.
WITH t AS (SELECT '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised, '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared FROM DUAL UNION SELECT '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' FROM DUAL) SELECT * FROM (SELECT NE, raised, cleared FROM t MODEL RETURN UPDATED ROWS PARTITION BY (NE) DIMENSION BY (0 d) MEASURES (raised, cleared) RULES ITERATE (1000) UNTIL raised[ITERATION_NUMBER] IS NULL (raised [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (raised[0], '[^/]+', 1, ITERATION_NUMBER + 1), cleared [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (cleared[0], '[^/]+', 1, ITERATION_NUMBER + 1))) WHERE raised IS NOT NULL ORDER BY NEPublished by: pollywog on March 29, 2011 10:34
-
How to query start a new line in the column?
How to query start a new line in the column?
Exam
SELECT ID, username | host name, details of xxx;
on the 2 column, I need result below:
Username ID | hostname in detail
1 user1 xxxxxx
host1
2 user2 xxxxxx
host2
Kind regards
SuradechSomething like that?
SQL> WITH tbl AS (SELECT 1 id,'user1' uname,'xxx' dtl,'host1' hname FROM DUAL UNION ALL 2 SELECT 2 id,'user2' uname,'yyy' dtl,'host2' hname FROM DUAL UNION ALL 3 SELECT 3 id,'user3' uname,'zzz' dtl,'host3' hname FROM DUAL 4 ) 5 SELECT id,uname||dtl||chr(10)||hname FROM tbl; ID UNAME||DTL||CH ---------- -------------- 1 user1xxx host1 2 user2yyy host2 3 user3zzz host3 -
APEX do not allow to change the lines of the columns that are the primary key?
I have pictures:
http://img508.imageshack.us/my.php?image=21269582oe8.jpg
Book (id_book - 'Primary key', title, year); book_author (id_author id_book - 'Primary key', - 'Primary key'); author (id_author - "Primary key", name)
I created a new page-> Form-> form of 'author' table because I want to add new authors, modification and deletion. During the creation of this page, I have chosen column 'id_author' as '1 primary key column' and everything is OK (I can't edit the 'id_author' column - this column is autoincrement and I can change the 'name' column).
BUT I also created a new page-> Form-> table for table "book_author" because I like to write numbers like id_book and id_author, change and remove them (so add relations between tables: book, book_author and author). During the creation of this page, I have chosen column 'id_book' as '1 primary key column' and 'id_author' as 'column primary key 2'. And on the Web site, I can't edit these fields. And I can not add also new line because I see in each new line: (null).
http://img444.imageshack.us/my.php?image=11324615yk9.jpg
APEX do not allow to change the lines of the columns that are the primary key? It's stupid... What can I do?
Edited by: user10731158 2008-12-20 11:40Column unique and not meaningful if you ever want to update. In the case of your example, you need to add an ID column in the intersection of book_author table. Honestly, I was so blown away (and pleasantly surprised) by the absence of rebuttal and the "thx" I advanced and set up an example of how I would define the book_author table:
create table book_author (id varchar2(32), book_id varchar2(32), author_id varchar2(32), modified_on date, modified_by varchar2(255), constraint book_author_pk primary key (id), constraint book_auth_book_fk foreign key (book_id) references books(id), constraint book_auth_author_fk foreign key (author_id) references authors(id) ) / create unique index book_author_uq on book_author (book_id,author_id) / create or replace trigger biu_book_author before insert or update on book_author for each row begin if inserting then :new.id := sys_guid(); end if; modified_on := sysdate; modified_by := nvl(v('APP_USER'),user); end; /Good luck
Tyler -
Find the same value in different columns
Hello
I'm trying to figure out how I would get the same value in the same row but in different columns. For example, in the table sometimes report the name is the same as the description. I would like to find all the lines where this is the case.
Thank you
Name of the report Description Date Time Report 1 Report 1 Delalande TTTT Report 2 Billing report Delalande TTTT Report 3 Report 3 Delalande TTTT Hello
Is that what you want?
SELECT *- or whatever the columns that you want to
FROM table_x
WHERE description = report_name
;
If not, post a small example data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and also publish outcomes from these data.
Explain, using specific examples, how you get these results from these data.
Always say what version of Oracle you are using (for example, 11.2.0.2.0).See the FAQ forum: https://forums.oracle.com/message/9362002
-
ADF: how to insert the character of new line in the column of VO?
Hello world
IM using Jdev 11 G.
I have a VO with 5 columns appear on the page of the ADF. (VO a total 8 columns)
column 1 is the combination of 3 columns. I concatenated 3 columns and add the new line character after each column Chr (13).
VO query works very well as a toad. the columnn displays each column value concatenated after a newline character, but the same query does not work in the ADF.
The column that is the concatenation of the 3 columns and should display with the new line character does not display the new line character its just concatenation of the 3 values and display on the page.
Wat could be the solution for this in the ADF?
Thank you.Column does not have the property to escape. It is part of the output text.
Something like
Arun-
-
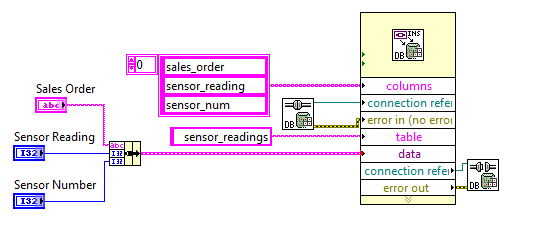
Update line in the column-based database
Hello
I am trying to find a way to update a row that has a SQL database based on two columns. If the command and the match number sensor order number and sales sensor that already exists in the database, I want to update the column of reading of the sensor. If not exists then I want that it creates a new line. How would I go to do this?
Thank you
Chris
You can use the tools of DB Query.vi Execute. Here is an example of a MS Access 2010 database where a column value is updated in all rows satisfying the WHERE conditions.
Ben64
-
Hi all, I have two tables with data as described below.
what I want to do is to join these two tables and get the values of the table Details
and fill in the data table in the columns that are null. Data table must remain with one
line.
WITH the data AS
(
SELECT "a34" id, "pat smith" name, 234 compid, NULL returned, NULL, NULL prod FROM dual UNION all
SELECT "a35" id name "case jon", dual 543 compid, NULL, NULL, NULL FROM prod revenue business
)
Details such AS
(
SELECT "a34' id code 'craft', 123 idvalue FROM double UNION all
SELECT "a34' id, 'rev' code, 456 idvalue FROM double UNION all
SELECT "a34' id, 'product' code, 789 idvalue FROM dual UNION all
SELECT "a35' id code 'craft', 294 idvalue FROM double UNION all
SELECT "a35' id, 'rev' code, 546 idvalue FROM double UNION all
SELECT "a35' id, 'product' code, 654 double idvalue
)
the output of this query should be
ID name compid prod turnover
A34 pat smith 234 123 456 789
A35 case jon 543 294 546 654
can someone help write a query that gives me not the above result? Thank youThis gives a shot:
WITH data AS ( SELECT 'a34' id, 'pat smith' name, 234 compid, NULL business, NULL revenue, NULL prod FROM dual UNION all SELECT 'a35' id, 'jon case' name, 543 compid, NULL business, NULL revenue, NULL prod FROM dual ), details AS ( SELECT 'a34' id, 'business' code, 123 idvalue FROM dual UNION all SELECT 'a34' id, 'rev' code, 456 idvalue FROM dual UNION all SELECT 'a34' id, 'product' code, 789 idvalue FROM dual UNION all SELECT 'a35' id, 'business' code, 294 idvalue FROM dual UNION all SELECT 'a35' id, 'rev' code, 546 idvalue FROM dual UNION all SELECT 'a35' id, 'product' code, 654 idvalue FROM dual ), unpivot_details AS ( SELECT ID , MAX(DECODE(CODE,'business',IDVALUE)) AS BUSINESS , MAX(DECODE(CODE,'rev',IDVALUE)) AS REVENUE , MAX(DECODE(CODE,'product',IDVALUE)) AS PROD FROM DETAILS GROUP BY ID ) SELECT DATA.ID , NAME , COMPID , NVL(DATA.BUSINESS,UD.BUSINESS) AS BUSINESS , NVL(DATA.REVENUE,UD.REVENUE) AS REVENUE , NVL(DATA.PROD,UD.PROD) AS PROD FROM DATA JOIN unpivot_details UD ON DATA.ID = UD.IDI did take your DETAILS and UNPIVOT table data turning rows of columns. I used this result to join the DATA table. Once the tables were joined, I used the function NVL will only display the DETAILS table data if the data in the DATA table is NULL.
If you have more values of 'code', you will need to add them manually to the UNPIVOT_DETAILS view.
HTH!
-
RESULT DATE1 POINT
-------------------------------------------
XYZ F 1 JUNE 07
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
XYZ F 1 JUNE 07
ABC F 1 JUNE 07
ABC F 1 JUNE 07
F 1 JULY 07 ABC
F 1 JULY 07 ABC
P 1 JULY 07 ABC
P 1 JULY 07 ABC
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
the above lines must be transposed to the columns as below table from the above. That takes the number total of RESULTS, County of 'F', 'P' County, based on the month and the product.
DATE1 POINT TOTALCOUNT COUNT_OF_F COUNT_OF_P
---------------------------------------------------------------------------------------------------------------------------------------------------
1ST JUNE 07 XYZ 2 2 0
1 JULY 07 XYZ 3 3 0
1ST JUNE 07 5 2 3 ABC
1 JULY 07 4 2 2 ABC
Thank youuser9370033 wrote:
RESULT DATE1 ITEM ------------------------------------------- F 01-JUN-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUN-07 XYZ F 01-JUN-07 ABC F 01-JUN-07 ABC F 01-JUL-07 ABC F 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC the above rows has to be transposed to columns like below table from the above one. Which takes the total count of RESULT, count of "F" , count of "P" based on month and Product. DATE1 ITEM TOTALCOUNT COUNT_OF_F COUNT_OF_P --------------------------------------------------------------------------------------------------------------------------------------------------- 01-JUN-07 XYZ 2 2 0 01-JUL-07 XYZ 3 3 0 01-JUN-07 ABC 5 2 3 01-JUL-07 ABC 4 2 2Thank you
You can do like this
select date1, item, count(*) totalcount, count(decode(result,'F',1,null)) count_of_f, count(decode(result, 'P',1, null)) count_of_p fromgroup by date1, item
can someone help me how to get previous lines having the same provider
My question is:
I have a table
CREATE TABLE insert_table
(
NUMBER OF ACCTNUM,
DATE TIMESTAMP (3),
CODE VARCHAR2 (35 BYTE),
PROVIDER VARCHAR2 (35 BYTE)
)
I INSERTED SOME DATA IN IT:
1 1/22 / 2011 V1 BSO
1 1/23 / 2011 V1 BSOF
1 1/24 / 2011 BSOF V2
1 1/25 / 2011 V1 BSOF
IN THE SCENARIO ABOVE, I NEED TO GET RESULT AS:
1 1/22 / 2011 V1 BSO NO.
1 1/23 / 2011 V1 BSOF YES
1 1/24 / 2011 V2 BSOF NO.
1 1/25 / 2011 V1 BSOF YES
iAM the WAY GET THE RESULT in A COMPLEX:
SELECT ACCTnum, provider, date,
CASE
WHERE code = 'bsof.
THEN (CASE
WHEN COUNT(DISTINCT code) OVER (PARTITION BY ACCTnum, vendor) > 1 THEN
(CASE
WHEN LAG (code, 1, 0)
COURSES (PARTITION BY ACCTnum, provider
ORDER BY vendor, date) <>' 0'
THEN
(CASE
WHAT RANK)
COURSES (PARTITION BY ACCTnum, vendor ORDER BY 0) = 1
THEN '' Yes. ''
ON THE OTHER
'no' END)
ON THE OTHER
'no' END)
End ELSE ' no')
ON THE OTHER
'no' END
result
OF INSERT_TABLE
WHERE l_workcode IN ('iso', 'bsofu') and ACCTnum = 1
ORDER BY ACCTnum, date;
CAN SOMEONE HELP OUT ME IN A SIMPLE WAY
NOTE: FOR EACH ACCTNUM WE ONLY BSO FOR A PROVIDER AND SUPPLIERS HAVE CODE (BSOF).
PLEASE HELP ME URGENTYour query can be rewritten as follows,
SELECT acctnum,l_date, CASE WHEN code = 'bsof' AND COUNT (DISTINCT code) OVER (PARTITION BY acctnum, vendor) > 1 AND row_number () OVER (PARTITION BY acctnum, vendor ORDER BY vendor, l_date) != 1 THEN 'yes' ELSE 'no' END result FROM TEMP_TABLE WHERE code IN ('bso', 'bsof') AND acctnum=1 ORDER BY acctnum ,l_date;G.
- Hi all
I have a requirement where I need to convert rows to columns and vice versa in 10 g.
Pivot is not supported in 10g.
Actual query looks like this
THXchange_name primary_key_id ASSET 1501 COLLATERAL 1501 ASSET 1502 COLLATERAL 1510 ASSET 1503 COLLATERAL 1515 Required Output: change_table_name Asset Collateral Primary_key_id 1501 1501 Primary_key_id2 1502 Primary_key_id3 1510 Primary_key_id4 1503 Primary_key_id5 1515
Rod.
Published by: SamFisher May 16, 2012 19:48Hello
SamFisher wrote:
Hi allI have a requirement where I need to convert rows to columns and vice versa in 10 g.
Pivot is not supported in 10g.Pivot can be done in any version of Oracle.
The PIVOT of the Select keyword is not supported in Oracle 10. It is the only way to rotate.Actual query looks like this
change_name primary_key_id ASSET 1501 COLLATERAL 1501 ASSET 1502 COLLATERAL 1510 ASSET 1503 COLLATERAL 1515 Required Output: change_table_name Asset Collateral Primary_key_id 1501 1501 Primary_key_id2 1502 Primary_key_id3 1510 Primary_key_id4 1503 Primary_key_id5 1515I think you want something like this:
SELECT 'Primary_key_id || TO_CHAR ( NULLIF ( ROW_NUMBER () OVER (ORDER BY NVL ( a.primary_key_id , c.primary_key_id ) ) , 1 ) ) AS change_table_name , a.primary_key_id AS asset , c.primary_key_id AS collateral FROM table_x a FULL OUTER JOIN table_x c ON a.primary_key_id = c.primary_key_id -- Next 4 lines added after Ankit, below AND a.change_name = 'ASSET' AND c.change_name = 'COLLATERAL' WHERE a.change_name = 'ASSET' OR c.change_name = 'COLLATERAL' ;If you would care to post CREATE TABLE and INSERT statements for your sample data, then I could test it.
This operation generates a unique change_table_name for each line. I don't see how you get the values you said you want associated with the other columns. In other words, I have the same question as Justin:
Justin cave wrote:
... How do you know that 1502 goes hand in hand with primary_key_id2 and not primary_key_id3 or 4 or 1?Maybe you didn't really what change_table_name is given to each line, just as long as they are unique and numbered with consecutive integers (except 1). If you really need exactly what you have posted, explain how to get it. You should probably just change the analytical ORDER BY clause.
Published by: Frank Kulash, May 17, 2012 06:56
Query has been correctedHow to merge values into a line, based on distinct values in another column
I have a table like
updatedby updateddate text
Approval John 1st May 2009 1 added file
Approval of John 1 May 2009 2 added file
May 2, 2009 1 deleted David approval form
I need the text column values to be concatenated and displayed for unique (updatedby updateddate) records. The output is something like
updatedby updateddate text
Approval of May 1, 2009 John save further approval 1 sheet, 2 added
May 2, 2009 1 deleted David approval form
I had planned to do it using PLSQL. Is there a way to achieve this in SQl...? Please suggestSQL> ed Wrote file afiedt.buf 1 with t as (select 'John' as updatedby, to_date('01-May-2009','DD-MON-YYYY') as updateddate, 'Approval record 1 added' as text from dual union all 2 select 'John', to_date('01-May-2009','DD-MON-YYYY'), 'Approval record 2 added' from dual union all 3 select 'David', to_date('02-May-2009','DD-MON-YYYY'), 'Approval record 1 removed' from dual) 4 -- END OF SAMPLE DATA 5 -- 6 select updatedby, updateddate, ltrim(sys_connect_by_path(text,','),',') as text 7 from ( 8 select updatedby, updateddate, text, row_number() over (partition by updatedby, updateddate order by text) as rn 9 from t 10 ) 11 where connect_by_isleaf = 1 12 connect by rn = prior rn+1 and updatedby = prior updatedby and updateddate = prior updateddate 13 start with rn = 1 14* order by 2 SQL> / UPDAT UPDATEDDA TEXT ----- --------- ---------------------------------------------------------------------------------------------------- John 01-MAY-09 Approval record 1 added,Approval record 2 added David 02-MAY-09 Approval record 1 removed SQL>Edited by: BluShadow May 21, 2009 12:37
Argh! hair to the pole by SYConcatenation of two records based on values in a column
Hello
I have the table and values as below.
create the table export_table
(TEXT varchar (255),)
Number cust_id,
PROD_SHOP varchar (100)
);
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 410,"Digital Sportsbook");
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 753,"Payments");
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 753, 'TBT');
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 753,"Digital Sportsbook");
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 999,"Digital Sportsbook");
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 999, 'TBT');
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 1593, 'TBT');
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 1593,"Digital Sportsbook");
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 1624,"Digital Sportsbook");
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 1769, 'TBT');
Insert into EXPORT_TABLE (TEXT, CUST_ID, PROD_SHOP) values (' predominant product 12 months ", 1769,"Digital Sportsbook");
commit;
Now showing current records are like
Product last 12 months 410 Digital sportsbook Product last 12 months 753 Payments Product last 12 months 753 OTC Product last 12 months 753 Digital sportsbook Product last 12 months 999 Digital sportsbook Product last 12 months 999 OTC Product last 12 months 1593 OTC Product last 12 months 1593 Digital sportsbook Product last 12 months 1624 Digital sportsbook Product last 12 months 1769 OTC Product last 12 months 1769 Digital sportsbook
But I want the result form
Product last 12 months 410 Digital sportsbook Product last 12 months 753 Payments, TBT, digital Sportsbook Product last 12 months 999 Digital Sportsbook, OTC Product last 12 months 1593 CTA digital Sportsbook Product last 12 months 1624 Digital sportsbook Product last 12 months 1769 CTA digital Sportsbook How can I achieve this by using the query.
Thank you and best regards,
Mahesh
Use under request
[code]
Select text, cust_id, listagg (prod_shop, ',') WITHIN GROUP (ORDER BY prod_shop) FOR prod_shop
of export_table
Group by text, cust_id.
[/ code]
Concerning
Arun
Help - lines of the columns in the query
I have table-
CREATE TABLE group_device
(group_id NUMBER (8) NON NULL
member_id NUMBER (4) NOT NULL
device_id NUMBER (10) NOT NULL
, install_date DATE NOT NULL
remove_date DATE
);
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 1, 123, TO_DATE (May 23, 2012 "," mm/dd/yyyy"), TO_DATE (May 28, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 1, 456, TO_DATE (May 28, 2012 "," mm/dd/yyyy"), TO_DATE (June 1, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 1, 789, TO_DATE (June 1, 2012 "," mm/dd/yyyy"), null);
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 2, 999, TO_DATE (May 4, 2012 "," mm/dd/yyyy"), TO_DATE (May 17, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 4, 1123, TO_DATE (January 22, 2012 "," mm/dd/yyyy"), TO_DATE (January 27, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 4, 1456, TO_DATE (January 27, 2012 "," mm/dd/yyyy"), TO_DATE (January 28, 2012","mm/dd/yyyy"));
commit;
Select * from group_device;
Current output does look like in below
10 1 123 23 MAY 12 28 MAY 12
10 1 456 28 MAY 12 1ST JUNE 12
10 1 789 1 JUNE 12
10 2 999 4 MAY 12 MAY 17, 12
10 4 1123 22 JANUARY 12 JANUARY 27, 12
10 4 1456 27 JANUARY 12 28 JANUARY 12
Device_id - Replaced_device_id - remove_date: for group_id = 10
for example, if member_id = 1, device_id = 123A replaced by device_id = 456 on 28 May 12
DEVICE_ID = 456 was replaced by device_id = 789 on June 1, 12
If the output should look like this
10 123 456 28 May 12 - replaced
10 456 789 1 June 12 - replaced
10 789 - active
Similarly there are many groups, so it should list group_id based on
Thank youThat match your desired output?
select a.group_id, a.device_id, a.rep_device_id, a.rep_date, decode(NVL(a.rep_device_id, -1), -1, 'ACTIVE', 'REPLACED') rep_active from ( select group_id, device_id, lead(device_id) over (partition by member_id order by install_date) rep_device_id, lead(install_date) over (partition by member_id order by install_date) rep_date from group_device ) a; GROUP_ID DEVICE_ID REP_DEVICE_ID REP_DATE REP_ACTIVE -------- ---------- ------------- --------- ---------- 10 123 456 28-MAY-12 REPLACED 10 456 789 01-JUN-12 REPLACED 10 789 ACTIVE 10 999 ACTIVE 10 1123 1456 27-JAN-12 REPLACED 10 1456 ACTIVE 6 rows selectedOracle 11g is not a version. Therefore, please do not forget to post the output of
select * from v$version;Maybe you are looking for
-
Is it possible to pop the button of the remote control on the EarPods in place, if I take it off? I want to clean the inside, but I don't want to destroy it if I can't put it back. If I remove it, is it possible to pop/lock (attach) the remote contro
-
Why the GeForce Go 7600 is not supported by any driver Nvidia?
Why this video card is not supported by any driver on the web of the nvidia drivers?
-
How do I downgrade to iOS to iOS 9.2.1 7 or 8
I would like my mini iPad (wifi) to iOS Downgrader 7 or 8 as iOS 9 have the features or set out as I'd like. Can you help me my downgrade?
-
I reinstalled the drivers for the Nvidia card and now I can't see the icon in 'hidden' icons on the bar, which showed the programs that use this card. Is it possible to bring him back?
-
Aspire unlike the model S7-392
Can someone tell me the difference between these two models? Aspire S7-392-7863 (NX. MBKAA.029)Aspire S7-392-9439 (NX. MBKAA.015) There is the only difference in the specs is supported memory card, they say "Secure Digital (SD) card" and the other "S