Transpose lines to the column
RESULT DATE1 POINT-------------------------------------------
XYZ F 1 JUNE 07
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
XYZ F 1 JUNE 07
ABC F 1 JUNE 07
ABC F 1 JUNE 07
F 1 JULY 07 ABC
F 1 JULY 07 ABC
P 1 JULY 07 ABC
P 1 JULY 07 ABC
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
the above lines must be transposed to the columns as below table from the above. That takes the number total of RESULTS, County of 'F', 'P' County, based on the month and the product.
DATE1 POINT TOTALCOUNT COUNT_OF_F COUNT_OF_P
---------------------------------------------------------------------------------------------------------------------------------------------------
1ST JUNE 07 XYZ 2 2 0
1 JULY 07 XYZ 3 3 0
1ST JUNE 07 5 2 3 ABC
1 JULY 07 4 2 2 ABC
Thank you
user9370033 wrote:
RESULT DATE1 ITEM ------------------------------------------- F 01-JUN-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUN-07 XYZ F 01-JUN-07 ABC F 01-JUN-07 ABC F 01-JUL-07 ABC F 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC the above rows has to be transposed to columns like below table from the above one. Which takes the total count of RESULT, count of "F" , count of "P" based on month and Product. DATE1 ITEM TOTALCOUNT COUNT_OF_F COUNT_OF_P --------------------------------------------------------------------------------------------------------------------------------------------------- 01-JUN-07 XYZ 2 2 0 01-JUL-07 XYZ 3 3 0 01-JUN-07 ABC 5 2 3 01-JUL-07 ABC 4 2 2Thank you
You can do like this
select date1, item, count(*) totalcount, count(decode(result,'F',1,null)) count_of_f, count(decode(result, 'P',1, null)) count_of_p
from
group
by date1, item
Tags: Database
Similar Questions
-
lines to the column and summation
Hi everyone, I am using oracle 10g consider the following data:
WITH the data as {}
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 123.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 111.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 666.23 amount OF the dual UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 888.23 amount OF the double UNION
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 333.23 amount OF the dual UNION ALL
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 222.23 amount OF double UNION ALL
SELECT mntrid "XTR3", "CCC" ctid, ' hi tech 3 ' description, code 'PC', 777.23 amount OF double
}
I would like secret lines at column and add the amounts. my output should be like this
MNTRID CTID DESCRIPTION MAIN PC PAYROLL
XTR AAA hi tech 234,46 1554.46
XTR2 BBB Hi tech2 555.46
CCC XTR3 Hi Tech 3 777.23
what I do is converting lines to the column and the display of the sum. for example, for mntrid = XTR I get the sum of all MAIN lines and the lines all PAY and PC.
Since there is no line of PC for XTR I display null.
can someone help me write a query that displays the output in oracle 10g above?
Hello
elmasduro wrote:
It's great Frank. Thank you very much.
I have a request. What happens if I want to add total main grad, wages, the pc? How would I do that.
output
Total general AFFID CTID DESCRIPTION MAIN PAY PC
XTR AAA hi tech 234.46 1554,46 1788.92
XTR2 BBB Hi tech2 555,46 555.46
CCC XTR3 Hi Tech 3 777,23 777.23
It's just plain old garden-variety SUM:
SELECT Mntrid
ctid
Description
, SUM (CASE WHEN code = "MAIN" THEN rise END) AS main
, SUM (CASE code WHEN = "SALARY" THEN rise END) AS pay
, SUM (CASE WHEN code = 'PC', THEN rise END) AS pc
, The SUM of (amount) AS grand_total-* NEW *.
FROM the data
GROUP BY mntrid
ctid
Description
;
-
lines to the column for large number of files
my version of the database is 10 gr 2
I want to transfer the lines to the column... .i have seen examples of small no records, but how can it be done if there are more the 1,000 records in a table...?
Here is the example of data I'd like to change to column
SQL> /
NE RAISED CLEARED RTTS_NO RING
--------------- ------------------------------ ------------------------------ -------------- -----------------------------------------------------------------------------------
10100000-1LU 22-FEB-2011 22:01:04/28-FEB-20 22-FEB-2011 22:12:27/28-FEB-20 SR-10/ ER-16/ CR-25/ CR-29/ CR-26/ RIDM-1/ NER5/ CR-31/ RiC600-1
11 01:25:22/ 11 02:40:06/
10100000-2LU 01-FEB-2011 12:15:58/06-FEB-20 05-FEB-2011 10:05:48/06-FEB-20 RIMESH/ RiC342-1/ 101/10R#10/ RiC558-1/ RiC608-1
11 07:00:53/18-FEB-2011 22:04: 11 10:49:18/18-FEB-2011 22:15:
56/19-FEB-2011 10:36:12/19-FEB 17/19-FEB-2011 10:41:35/19-FEB
-2011 11:03:13/19-FEB-2011 11: -2011 11:08:18/19-FEB-2011 11:
16:14/28-FEB-2011 01:25:22/ 21:35/28-FEB-2011 02:40:13/
10100000-3LU 19-FEB-2011 20:18:31/22-FEB-20 19-FEB-2011 20:19:32/22-FEB-20 INR-1/ ISR-1
11 21:37:32/22-FEB-2011 22:01: 11 21:48:06/22-FEB-2011 22:12:
35/22-FEB-2011 22:20:03/28-FEB 05/22-FEB-2011 22:25:14/28-FEB
-2011 01:25:23/ -2011 02:40:20/
10100000/10MU 06-FEB-2011 07:00:23/19-FEB-20 06-FEB-2011 10:47:13/19-FEB-20 101/IR#10
11 11:01:50/19-FEB-2011 11:17: 11 11:07:33/19-FEB-2011 11:21:
58/28-FEB-2011 02:39:11/01-FEB 30/28-FEB-2011 04:10:56/05-FEB
-2011 12:16:21/18-FEB-2011 22: -2011 10:06:10/18-FEB-2011 22:
03:27/ 13:50/
10100000/11MU 01-FEB-2011 08:48:45/22-FEB-20 02-FEB-2011 13:15:17/22-FEB-20 1456129/ 101IR11 RIMESH
11 21:59:28/22-FEB-2011 22:21: 11 22:08:49/22-FEB-2011 22:24:
52/01-FEB-2011 08:35:46/ 27/01-FEB-2011 08:38:42/
10100000/12MU 22-FEB-2011 21:35:34/22-FEB-20 22-FEB-2011 21:45:00/22-FEB-20 101IR12 KuSMW4-1
11 22:00:04/22-FEB-2011 22:21: 11 22:08:21/22-FEB-2011 22:22:
23/28-FEB-2011 02:39:53/ 26/28-FEB-2011 02:41:07/
10100000/13MU 22-FEB-2011 21:35:54/22-FEB-20 22-FEB-2011 21:42:58/22-FEB-20 LD MESH
11 22:21:55/22-FEB-2011 22:00: 11 22:24:52/22-FEB-2011 22:10:
could you do something like that?
with t as (select '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised , '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared from dual union
select '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/',
'05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' from dual
)
select * from(
select NE, regexp_substr( raised,'[^/]+',1,1) raised, regexp_substr( cleared,'[^/]+',1,1) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,2) , regexp_substr( cleared,'[^/]+',1,2) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,3) , regexp_substr( cleared,'[^/]+',1,3) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,4) , regexp_substr( cleared,'[^/]+',1,4) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,5) , regexp_substr( cleared,'[^/]+',1,5) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,6) , regexp_substr( cleared,'[^/]+',1,6) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,7) , regexp_substr( cleared,'[^/]+',1,7) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,8) , regexp_substr( cleared,'[^/]+',1,8) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,9) , regexp_substr( cleared,'[^/]+',1,9) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,10) , regexp_substr( cleared,'[^/]+',1,10) cleared from t
union
select NE, regexp_substr( raised,'[^/]+',1,11) , regexp_substr( cleared,'[^/]+',1,11) cleared from t
)
where nvl(raised,cleared) is not null
order by ne
NE RAISED CLEARED
10100000-1LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:06
10100000-1LU 22-FEB-2011 22:01:04 22-FEB-2011 22:12:27
10100000-2LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:13
10100000-2LU 19-FEB-2011 10:36:12 19-FEB-2011 10:41:35
10100000-2LU 19-FEB-2011 11:03:13 19-FEB-2011 11:08:18
10100000-2LU 19-FEB-2011 11:16:14 19-FEB-2011 11:21:35
10100000-2LU 06-FEB-2011 07:00:53 06-FEB-2011 10:49:18
10100000-2LU 01-FEB-2011 12:15:58 05-FEB-2011 10:05:48
10100000-2LU 18-FEB-2011 22:04:56 18-FEB-2011 22:15:17
You should be able to do without all these unions using a connection by but I can't quite make it work
the following does not work, but perhaps someone can answer.
select NE, regexp_substr( raised,'[^/]+',1,level) raised, regexp_substr( cleared,'[^/]+',1,level) cleared from t
connect by prior NE = NE and regexp_substr( raised,'[^/]+',1,level) = prior regexp_substr( raised,'[^/]+',1,level + 1)
Published by: pollywog on March 29, 2011 09:38
Here it is with the type clause that gets rid of all unions.
WITH t
AS (SELECT '10100000-1LU' NE,
'22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised,
'22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared
FROM DUAL
UNION
SELECT '10100000-2LU',
'01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/',
'05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/'
FROM DUAL)
SELECT *
FROM (SELECT NE, raised, cleared
FROM t
MODEL RETURN UPDATED ROWS
PARTITION BY (NE)
DIMENSION BY (0 d)
MEASURES (raised, cleared)
RULES
ITERATE (1000) UNTIL raised[ITERATION_NUMBER] IS NULL
(raised [ITERATION_NUMBER + 1] =
REGEXP_SUBSTR (raised[0],
'[^/]+',
1,
ITERATION_NUMBER + 1),
cleared [ITERATION_NUMBER + 1] =
REGEXP_SUBSTR (cleared[0],
'[^/]+',
1,
ITERATION_NUMBER + 1)))
WHERE raised IS NOT NULL
ORDER BY NE
Published by: pollywog on March 29, 2011 10:34
-
How to query start a new line in the column?
How to query start a new line in the column?
Exam
SELECT ID, username | host name, details of xxx;
on the 2 column, I need result below:
Username ID | hostname in detail
1 user1 xxxxxx
host1
2 user2 xxxxxx
host2
Kind regards
Suradech Something like that?
SQL> WITH tbl AS (SELECT 1 id,'user1' uname,'xxx' dtl,'host1' hname FROM DUAL UNION ALL
2 SELECT 2 id,'user2' uname,'yyy' dtl,'host2' hname FROM DUAL UNION ALL
3 SELECT 3 id,'user3' uname,'zzz' dtl,'host3' hname FROM DUAL
4 )
5 SELECT id,uname||dtl||chr(10)||hname FROM tbl;
ID UNAME||DTL||CH
---------- --------------
1 user1xxx
host1
2 user2yyy
host2
3 user3zzz
host3
-
APEX do not allow to change the lines of the columns that are the primary key?
I have pictures:
http://img508.imageshack.us/my.php?image=21269582oe8.jpg
Book (id_book - 'Primary key', title, year); book_author (id_author id_book - 'Primary key', - 'Primary key'); author (id_author - "Primary key", name)
I created a new page-> Form-> form of 'author' table because I want to add new authors, modification and deletion. During the creation of this page, I have chosen column 'id_author' as '1 primary key column' and everything is OK (I can't edit the 'id_author' column - this column is autoincrement and I can change the 'name' column).
BUT I also created a new page-> Form-> table for table "book_author" because I like to write numbers like id_book and id_author, change and remove them (so add relations between tables: book, book_author and author). During the creation of this page, I have chosen column 'id_book' as '1 primary key column' and 'id_author' as 'column primary key 2'. And on the Web site, I can't edit these fields. And I can not add also new line because I see in each new line: (null).
http://img444.imageshack.us/my.php?image=11324615yk9.jpg
APEX do not allow to change the lines of the columns that are the primary key? It's stupid... What can I do?
Edited by: user10731158 2008-12-20 11:40 Column unique and not meaningful if you ever want to update. In the case of your example, you need to add an ID column in the intersection of book_author table. Honestly, I was so blown away (and pleasantly surprised) by the absence of rebuttal and the "thx" I advanced and set up an example of how I would define the book_author table:
create table book_author
(id varchar2(32),
book_id varchar2(32),
author_id varchar2(32),
modified_on date,
modified_by varchar2(255),
constraint book_author_pk primary key (id),
constraint book_auth_book_fk foreign key (book_id) references books(id),
constraint book_auth_author_fk foreign key (author_id) references authors(id)
)
/
create unique index book_author_uq on book_author (book_id,author_id)
/
create or replace trigger biu_book_author before insert or update on book_author
for each row
begin
if inserting then
:new.id := sys_guid();
end if;
modified_on := sysdate;
modified_by := nvl(v('APP_USER'),user);
end;
/
Good luck
Tyler
-
Update line in the column-based database
Hello
I am trying to find a way to update a row that has a SQL database based on two columns. If the command and the match number sensor order number and sales sensor that already exists in the database, I want to update the column of reading of the sensor. If not exists then I want that it creates a new line. How would I go to do this?
Thank you
Chris
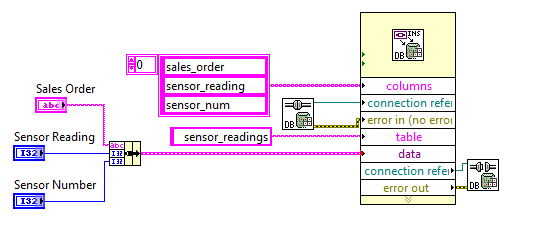
You can use the tools of DB Query.vi Execute. Here is an example of a MS Access 2010 database where a column value is updated in all rows satisfying the WHERE conditions.
Ben64
-
ADF: how to insert the character of new line in the column of VO?
Hello world
IM using Jdev 11 G.
I have a VO with 5 columns appear on the page of the ADF. (VO a total 8 columns)
column 1 is the combination of 3 columns. I concatenated 3 columns and add the new line character after each column Chr (13).
VO query works very well as a toad. the columnn displays each column value concatenated after a newline character, but the same query does not work in the ADF.
The column that is the concatenation of the 3 columns and should display with the new line character does not display the new line character its just concatenation of the 3 values and display on the page.
Wat could be the solution for this in the ADF?
Thank you. Column does not have the property to escape. It is part of the output text.
Something like
Arun-
-
Hi all, I have two tables with data as described below.
what I want to do is to join these two tables and get the values of the table Details
and fill in the data table in the columns that are null. Data table must remain with one
line.
WITH the data AS
(
SELECT "a34" id, "pat smith" name, 234 compid, NULL returned, NULL, NULL prod FROM dual UNION all
SELECT "a35" id name "case jon", dual 543 compid, NULL, NULL, NULL FROM prod revenue business
)
Details such AS
(
SELECT "a34' id code 'craft', 123 idvalue FROM double UNION all
SELECT "a34' id, 'rev' code, 456 idvalue FROM double UNION all
SELECT "a34' id, 'product' code, 789 idvalue FROM dual UNION all
SELECT "a35' id code 'craft', 294 idvalue FROM double UNION all
SELECT "a35' id, 'rev' code, 546 idvalue FROM double UNION all
SELECT "a35' id, 'product' code, 654 double idvalue
)
the output of this query should be
ID name compid prod turnover
A34 pat smith 234 123 456 789
A35 case jon 543 294 546 654
can someone help write a query that gives me not the above result? Thank you This gives a shot:
WITH data AS
(
SELECT 'a34' id, 'pat smith' name, 234 compid, NULL business, NULL revenue, NULL prod FROM dual UNION all
SELECT 'a35' id, 'jon case' name, 543 compid, NULL business, NULL revenue, NULL prod FROM dual
),
details AS
(
SELECT 'a34' id, 'business' code, 123 idvalue FROM dual UNION all
SELECT 'a34' id, 'rev' code, 456 idvalue FROM dual UNION all
SELECT 'a34' id, 'product' code, 789 idvalue FROM dual UNION all
SELECT 'a35' id, 'business' code, 294 idvalue FROM dual UNION all
SELECT 'a35' id, 'rev' code, 546 idvalue FROM dual UNION all
SELECT 'a35' id, 'product' code, 654 idvalue FROM dual
), unpivot_details AS
(
SELECT ID
, MAX(DECODE(CODE,'business',IDVALUE)) AS BUSINESS
, MAX(DECODE(CODE,'rev',IDVALUE)) AS REVENUE
, MAX(DECODE(CODE,'product',IDVALUE)) AS PROD
FROM DETAILS
GROUP BY ID
)
SELECT DATA.ID
, NAME
, COMPID
, NVL(DATA.BUSINESS,UD.BUSINESS) AS BUSINESS
, NVL(DATA.REVENUE,UD.REVENUE) AS REVENUE
, NVL(DATA.PROD,UD.PROD) AS PROD
FROM DATA
JOIN unpivot_details UD ON DATA.ID = UD.ID
I did take your DETAILS and UNPIVOT table data turning rows of columns. I used this result to join the DATA table. Once the tables were joined, I used the function NVL will only display the DETAILS table data if the data in the DATA table is NULL.
If you have more values of 'code', you will need to add them manually to the UNPIVOT_DETAILS view.
HTH!
-
Hi all
I have a requirement where I need to convert rows to columns and vice versa in 10 g.
Pivot is not supported in 10g.
Actual query looks like thischange_name primary_key_id
ASSET 1501
COLLATERAL 1501
ASSET 1502
COLLATERAL 1510
ASSET 1503
COLLATERAL 1515
Required Output:
change_table_name Asset Collateral
Primary_key_id 1501 1501
Primary_key_id2 1502
Primary_key_id3 1510
Primary_key_id4 1503
Primary_key_id5 1515
THX
Rod.
Published by: SamFisher May 16, 2012 19:48 Hello
SamFisher wrote:
Hi all
I have a requirement where I need to convert rows to columns and vice versa in 10 g.
Pivot is not supported in 10g.
Pivot can be done in any version of Oracle.
The PIVOT of the Select keyword is not supported in Oracle 10. It is the only way to rotate.
Actual query looks like this
change_name primary_key_id
ASSET 1501
COLLATERAL 1501
ASSET 1502
COLLATERAL 1510
ASSET 1503
COLLATERAL 1515
Required Output:
change_table_name Asset Collateral
Primary_key_id 1501 1501
Primary_key_id2 1502
Primary_key_id3 1510
Primary_key_id4 1503
Primary_key_id5 1515
I think you want something like this:
SELECT 'Primary_key_id
|| TO_CHAR ( NULLIF ( ROW_NUMBER () OVER (ORDER BY NVL ( a.primary_key_id
, c.primary_key_id
)
)
, 1
)
) AS change_table_name
, a.primary_key_id AS asset
, c.primary_key_id AS collateral
FROM table_x a
FULL OUTER JOIN table_x c ON a.primary_key_id = c.primary_key_id
-- Next 4 lines added after Ankit, below
AND a.change_name = 'ASSET'
AND c.change_name = 'COLLATERAL'
WHERE a.change_name = 'ASSET'
OR c.change_name = 'COLLATERAL'
;
If you would care to post CREATE TABLE and INSERT statements for your sample data, then I could test it.
This operation generates a unique change_table_name for each line. I don't see how you get the values you said you want associated with the other columns. In other words, I have the same question as Justin:
Justin cave wrote:
... How do you know that 1502 goes hand in hand with primary_key_id2 and not primary_key_id3 or 4 or 1?
Maybe you didn't really what change_table_name is given to each line, just as long as they are unique and numbered with consecutive integers (except 1). If you really need exactly what you have posted, explain how to get it. You should probably just change the analytical ORDER BY clause.
Published by: Frank Kulash, May 17, 2012 06:56
Query has been corrected
-
How to break lines in the column
Hello32-bit Windows: Version 11.2.0.1.0
When I use this, I get the o/p as shown:SQL> select hiredate from emp where hiredate between '01-FEB-81' and '30-SEP-81' order by hiredate;
HIREDATE
---------
20-FEB-81
22-FEB-81
02-APR-81
01-MAY-81
09-JUN-81
08-SEP-81
28-SEP-81
Now what I want, the o/p should be like:FEBRUARY MARCH APRIL MAY JUNE JULY AUGUST SEPTEMBER
--------- ----- --------- ---------- -------- ------ -------- -----------
20-FEB-81 02-APR-81 01-MAY-81 09-JUN-81 08-SEP-81
22-FEB-81 28-SEP-81
Means, for each month, there are new column.
How to do this? Like this
SQL> with t
2 as
3 (
4 select hiredate
5 , extract(month from hiredate) mth
6 , row_number() over(partition by extract(month from hiredate) order by hiredate) rno
7 from emp
8 where hiredate between '01-FEB-81' and '30-SEP-81'
9 order by hiredate
10 )
11 select max(decode(mth, 1, hiredate)) JAN
12 , max(decode(mth, 2, hiredate)) FEB
13 , max(decode(mth, 3, hiredate)) MAR
14 , max(decode(mth, 4, hiredate)) APR
15 , max(decode(mth, 5, hiredate)) MAY
16 , max(decode(mth, 6, hiredate)) JUN
17 , max(decode(mth, 7, hiredate)) JUL
18 , max(decode(mth, 8, hiredate)) AUG
19 , max(decode(mth, 9, hiredate)) SEP
20 , max(decode(mth,10, hiredate)) OCT
21 , max(decode(mth,11, hiredate)) NOV
22 , max(decode(mth,12, hiredate)) DEC
23 from t
24 group by rno
25 /
JAN FEB MAR APR MAY JUN JUL AUG SEP OCT NOV DEC
--------- --------- --------- --------- --------- --------- --------- --------- --------- --------- --------- ---------
20-FEB-81 02-APR-81 01-MAY-81 09-JUN-81 08-SEP-81
22-FEB-81 02-APR-81 28-SEP-81
-
examples of data-
ID COUNTTIME Sum
L 05/08/2011 12:00:02-7 days return 697
W 11/08/2011 12:00:01 AM - yesterday 712
W 12/08/2011 12:00:02 AM - today ' hui 693
U 05/08/2011 12:00:02 AM 813
U 11/08/2011 12:00:01 AM 834
U 12/08/2011 12:00:02 AM 828
T 05/08/2011 12:00:02 AM 143
T 11/08/2011 12:00:01 AM 129
T 12/08/2011 12:00:02 AM 129
S 05/08/2011-12:00:02 AM 2
S 11/08/2011-12:00:01 AM 1
S 12/08/2011-12:00:02 AM 1
R 05/08/2011 12:00:02 AM 1548
R 11/08/2011 12:00:01 AM 1559
R 12/08/2011 12:00:02 AM 1522
P 08/05/2011 12:00:02 AM 211
P 11/08/2011 12:00:01 AM 213
P 12/08/2011 12:00:02 AM 207
I want data from today in a column, Yester day in a column data and the data for 7 days in a special identity column
ID today last 7 days back
W 693 712 697
U 828 834 813
T 129 129 143
S 1 1 2
1522 1559 1548 R
P 207 213 211
Help, please
Thank you
Praveen. Hello
Is this what you need?
with t as (
select 'W' id , to_date('8/5/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 697 c from dual union all
select 'W' id , to_date('8/11/2011 12:00:01 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 712 c from dual union all
select 'W' id , to_date('8/12/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 693 c from dual union all
select 'U' id , to_date('8/5/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 813 c from dual union all
select 'U' id , to_date('8/11/2011 12:00:01 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 834 c from dual union all
select 'U' id , to_date('8/12/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 828 c from dual union all
select 'T' id , to_date('8/5/2011 12:00:01 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 143 c from dual union all
select 'T' id , to_date('8/11/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 129 c from dual union all
select 'T' id , to_date('8/12/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 129 c from dual union all
select 'S' id , to_date('8/5/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 2 c from dual union all
select 'S' id , to_date('8/11/2011 12:00:01 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 1 c from dual union all
select 'S' id , to_date('8/12/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 1 c from dual union all
select 'R' id , to_date('8/5/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 1548 c from dual union all
select 'R' id , to_date('8/11/2011 12:00:01 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 1559 c from dual union all
select 'R' id , to_date('8/12/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 1522 c from dual union all
select 'P' id , to_date('8/5/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 211 c from dual union all
select 'P' id , to_date('8/11/2011 12:00:01 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 213 c from dual union all
select 'P' id , to_date('8/12/2011 12:00:02 AM','MM/DD/YYYY HH:MI:SS AM') counttime , 207 c from dual )
select id,
sum(today) today,
sum(yesterday) yesterday,
sum(seven_days) seven_days
from (
select id,
case when counttime > sysdate-1 then c else 0 end today,
case when counttime <= sysdate-1 and counttime>sysdate-7 then c else 0 end yesterday,
case when counttime <=sysdate-7 then c else 0 end seven_days
from t
)
group by id ;
ID TODAY YESTERDAY SEVEN_DAYS
----- ---------- ---------- ----------
W 693 712 697
U 828 834 813
R 1522 1559 1548
P 207 213 211
T 129 129 143
S 1 1 2
Kind regards
Sylvie
-
lines to the column in 11g as a single query
I would like to create single row with column name
as ISIN, CUSIP, SEDOL for each row which has desc IS, CU, SE
as below
SQL> select * from test;
CODE DESCR VALUE
---------- -------------------- ----------
10 IS 100
10 CU 200
10 SE 200
20 IS 100
20 CU 200
20 SE 200
The row should looks like below with column name ISIN, CUSIP, SEDOL
CODE ISIN CUSIP SEDOL
---- ----- ----- -----
10 100 200 200
20 100 200 200
CREATE TABLE TEST
(
CODE NUMBER(10),
DESCR VARCHAR2(20 BYTE),
VALUE NUMBER(10)
);
SET DEFINE OFF;
Insert into TEST
(CODE, DESCR, VALUE)
Values
(10, 'IS', 100);
Insert into TEST
(CODE, DESCR, VALUE)
Values
(10, 'CU', 200);
Insert into TEST
(CODE, DESCR, VALUE)
Values
(10, 'SE', 200);
Insert into TEST
(CODE, DESCR, VALUE)
Values
(20, 'IS', 100);
Insert into TEST
(CODE, DESCR, VALUE)
Values
(20, 'CU', 200);
Insert into TEST
(CODE, DESCR, VALUE)
Values
(20, 'SE', 200);
COMMIT;
Hello
Thanks for posting the CREATE TABLE and INSERT statements; It's very useful!
Using the PIVOT functionality introduced in Oracle 11:
SELECT *
FROM test
PIVOT ( SUM (value)
FOR descr
IN ( 'IS' AS isin
, 'CU' AS cusip
, 'SE' AS sedol
)
)
;
If the combination (code, descr) emerges, then it can onlly have one value (at most) in each group, so it doesn't matter if you use MIN, MAX or AVG instead of the above SUM.
-
pivot - data line to the columns to condition
create table t_a (identification number);
insert into t_a values (1);
insert into t_a values (2);
insert into t_a values (3);
insert into t_a values (4);
insert into t_a values (5);
create table t_b (identification number, name varchar2 (100), val varchar2 (100));
insert into t_b values (1, 'A', 'Yahoo');
insert into t_b values (1, 'B', 'BBB');
insert into t_b values (1, 'C', 'CCC');
insert into t_b values (1,'d ","DDDD"");
insert into t_b values (2, 'A', ' 2 Yahoo' ");
insert into t_b values (2, 'B', 'FD');
insert into t_b values (4, 'C', 'test');
insert into t_b values (5, 'A', 'Yahoo 5');
I could only get the list of IDS of t_a column and table name with the values 'A' and 'B' columns can
result must be-
ID | A | B
1. Yahoo | BBB
2. Yahoo 2 | FDS
3.
4.
5. Yahoo 5 |
Thanks in advance Hello
Of course, you can do it.
Outer-sign up for t_a, to ensure that all the 5s IDs appear:
SELECT t_a.id
, MAX (CASE WHEN t_b.name = 'A' THEN t_b.val END) AS a
, MAX (CASE WHEN t_b.name = 'B' THEN t_b.val END) AS b
FROM t_a
LEFT OUTER JOIN t_b ON t_a.id = t_b.id
GROUP BY t_a.id
ORDER BY t_a.id;
Thanks for posting the sample data: which helps a lot!
You may have noticed that this site compresses the spaces by default. When you want to post something where the spacing is important (like your results), and then type the 6 characters:
{code}
(small letters only, inside curly braces) before and after the section of text formatted to preserve spacing.
-
Help - lines of the columns in the query
I have table-
CREATE TABLE group_device
(group_id NUMBER (8) NON NULL
member_id NUMBER (4) NOT NULL
device_id NUMBER (10) NOT NULL
, install_date DATE NOT NULL
remove_date DATE
);
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 1, 123, TO_DATE (May 23, 2012 "," mm/dd/yyyy"), TO_DATE (May 28, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 1, 456, TO_DATE (May 28, 2012 "," mm/dd/yyyy"), TO_DATE (June 1, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 1, 789, TO_DATE (June 1, 2012 "," mm/dd/yyyy"), null);
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 2, 999, TO_DATE (May 4, 2012 "," mm/dd/yyyy"), TO_DATE (May 17, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 4, 1123, TO_DATE (January 22, 2012 "," mm/dd/yyyy"), TO_DATE (January 27, 2012","mm/dd/yyyy"));
INSERT INTO group_device (group_id, member_id, device_id, install_date, remove_date) VALUES (10, 4, 1456, TO_DATE (January 27, 2012 "," mm/dd/yyyy"), TO_DATE (January 28, 2012","mm/dd/yyyy"));
commit;
Select * from group_device;
Current output does look like in below
10 1 123 23 MAY 12 28 MAY 12
10 1 456 28 MAY 12 1ST JUNE 12
10 1 789 1 JUNE 12
10 2 999 4 MAY 12 MAY 17, 12
10 4 1123 22 JANUARY 12 JANUARY 27, 12
10 4 1456 27 JANUARY 12 28 JANUARY 12
Device_id - Replaced_device_id - remove_date: for group_id = 10
for example, if member_id = 1, device_id = 123A replaced by device_id = 456 on 28 May 12
DEVICE_ID = 456 was replaced by device_id = 789 on June 1, 12
If the output should look like this
10 123 456 28 May 12 - replaced
10 456 789 1 June 12 - replaced
10 789 - active
Similarly there are many groups, so it should list group_id based on
Thank you That match your desired output?
select a.group_id, a.device_id, a.rep_device_id, a.rep_date, decode(NVL(a.rep_device_id, -1), -1, 'ACTIVE', 'REPLACED') rep_active
from (
select group_id, device_id, lead(device_id) over (partition by member_id order by install_date) rep_device_id,
lead(install_date) over (partition by member_id order by install_date) rep_date
from group_device
) a;
GROUP_ID DEVICE_ID REP_DEVICE_ID REP_DATE REP_ACTIVE
-------- ---------- ------------- --------- ----------
10 123 456 28-MAY-12 REPLACED
10 456 789 01-JUN-12 REPLACED
10 789 ACTIVE
10 999 ACTIVE
10 1123 1456 27-JAN-12 REPLACED
10 1456 ACTIVE
6 rows selected
Oracle 11g is not a version. Therefore, please do not forget to post the output of
select * from v$version;
-

Open the dialogue window, the column width should expand. The new dialogue window size must be the same for subsequent exports. If you want to change the default column size, hold down the option key when you drag the small dividing line between the columns, (even if the new size apply to export and save the window).
Maybe you are looking for
-
NB200 - Recovery Media Creator and drive HARD USB
I just bought a white NB200 and noticed that it does not come with a DVD of Windows 7 in case I ever need to install.I was informed by the seller in the store I could save a copy on a USB key using a recovery disc writing.I assume that "Recovery Medi
-
Internet DEVICE level pnpRappelez - you - this is a public forum so never post private information such as email or phone numbers! Ideas: Problems with the programs Error messages Recent changes to your computer What you have already tried to solve t
-
Unable to download music from itunes
Original title: Itunes I have problems downloading my music I bought from the iTunes store. He said that I had to activate something. How can I do?
-
I was wondering how can I load Microsoft Office software on my new laptop HP Mini 210? I have the CD and the keys but what to do next?
-
T400 not re after waking from sleep - w7
I have a t400 with integrated f5307g wan device, which works very well, but after I wake the laptop from sleep, the wan card disappears in the menu fn + f5 and can not be turned on. I have to restart to reappear. IM using windows 7 with the latest dr

