Update line in the column-based database
Hello
I am trying to find a way to update a row that has a SQL database based on two columns. If the command and the match number sensor order number and sales sensor that already exists in the database, I want to update the column of reading of the sensor. If not exists then I want that it creates a new line. How would I go to do this?
Thank you
Chris
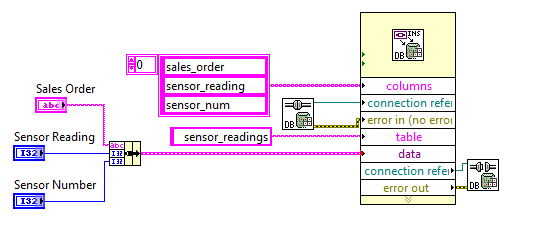
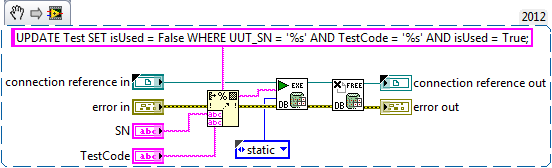
You can use the tools of DB Query.vi Execute. Here is an example of a MS Access 2010 database where a column value is updated in all rows satisfying the WHERE conditions.
Ben64
Tags: NI Software
Similar Questions
-
lines to the column for large number of files
my version of the database is 10 gr 2
I want to transfer the lines to the column... .i have seen examples of small no records, but how can it be done if there are more the 1,000 records in a table...?
Here is the example of data I'd like to change to column
SQL> / NE RAISED CLEARED RTTS_NO RING --------------- ------------------------------ ------------------------------ -------------- ----------------------------------------------------------------------------------- 10100000-1LU 22-FEB-2011 22:01:04/28-FEB-20 22-FEB-2011 22:12:27/28-FEB-20 SR-10/ ER-16/ CR-25/ CR-29/ CR-26/ RIDM-1/ NER5/ CR-31/ RiC600-1 11 01:25:22/ 11 02:40:06/ 10100000-2LU 01-FEB-2011 12:15:58/06-FEB-20 05-FEB-2011 10:05:48/06-FEB-20 RIMESH/ RiC342-1/ 101/10R#10/ RiC558-1/ RiC608-1 11 07:00:53/18-FEB-2011 22:04: 11 10:49:18/18-FEB-2011 22:15: 56/19-FEB-2011 10:36:12/19-FEB 17/19-FEB-2011 10:41:35/19-FEB -2011 11:03:13/19-FEB-2011 11: -2011 11:08:18/19-FEB-2011 11: 16:14/28-FEB-2011 01:25:22/ 21:35/28-FEB-2011 02:40:13/ 10100000-3LU 19-FEB-2011 20:18:31/22-FEB-20 19-FEB-2011 20:19:32/22-FEB-20 INR-1/ ISR-1 11 21:37:32/22-FEB-2011 22:01: 11 21:48:06/22-FEB-2011 22:12: 35/22-FEB-2011 22:20:03/28-FEB 05/22-FEB-2011 22:25:14/28-FEB -2011 01:25:23/ -2011 02:40:20/ 10100000/10MU 06-FEB-2011 07:00:23/19-FEB-20 06-FEB-2011 10:47:13/19-FEB-20 101/IR#10 11 11:01:50/19-FEB-2011 11:17: 11 11:07:33/19-FEB-2011 11:21: 58/28-FEB-2011 02:39:11/01-FEB 30/28-FEB-2011 04:10:56/05-FEB -2011 12:16:21/18-FEB-2011 22: -2011 10:06:10/18-FEB-2011 22: 03:27/ 13:50/ 10100000/11MU 01-FEB-2011 08:48:45/22-FEB-20 02-FEB-2011 13:15:17/22-FEB-20 1456129/ 101IR11 RIMESH 11 21:59:28/22-FEB-2011 22:21: 11 22:08:49/22-FEB-2011 22:24: 52/01-FEB-2011 08:35:46/ 27/01-FEB-2011 08:38:42/ 10100000/12MU 22-FEB-2011 21:35:34/22-FEB-20 22-FEB-2011 21:45:00/22-FEB-20 101IR12 KuSMW4-1 11 22:00:04/22-FEB-2011 22:21: 11 22:08:21/22-FEB-2011 22:22: 23/28-FEB-2011 02:39:53/ 26/28-FEB-2011 02:41:07/ 10100000/13MU 22-FEB-2011 21:35:54/22-FEB-20 22-FEB-2011 21:42:58/22-FEB-20 LD MESH 11 22:21:55/22-FEB-2011 22:00: 11 22:24:52/22-FEB-2011 22:10:could you do something like that?
with t as (select '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised , '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared from dual union select '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' from dual ) select * from( select NE, regexp_substr( raised,'[^/]+',1,1) raised, regexp_substr( cleared,'[^/]+',1,1) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,2) , regexp_substr( cleared,'[^/]+',1,2) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,3) , regexp_substr( cleared,'[^/]+',1,3) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,4) , regexp_substr( cleared,'[^/]+',1,4) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,5) , regexp_substr( cleared,'[^/]+',1,5) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,6) , regexp_substr( cleared,'[^/]+',1,6) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,7) , regexp_substr( cleared,'[^/]+',1,7) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,8) , regexp_substr( cleared,'[^/]+',1,8) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,9) , regexp_substr( cleared,'[^/]+',1,9) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,10) , regexp_substr( cleared,'[^/]+',1,10) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,11) , regexp_substr( cleared,'[^/]+',1,11) cleared from t ) where nvl(raised,cleared) is not null order by neNE RAISED CLEARED 10100000-1LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:06 10100000-1LU 22-FEB-2011 22:01:04 22-FEB-2011 22:12:27 10100000-2LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:13 10100000-2LU 19-FEB-2011 10:36:12 19-FEB-2011 10:41:35 10100000-2LU 19-FEB-2011 11:03:13 19-FEB-2011 11:08:18 10100000-2LU 19-FEB-2011 11:16:14 19-FEB-2011 11:21:35 10100000-2LU 06-FEB-2011 07:00:53 06-FEB-2011 10:49:18 10100000-2LU 01-FEB-2011 12:15:58 05-FEB-2011 10:05:48 10100000-2LU 18-FEB-2011 22:04:56 18-FEB-2011 22:15:17You should be able to do without all these unions using a connection by but I can't quite make it work
the following does not work, but perhaps someone can answer.select NE, regexp_substr( raised,'[^/]+',1,level) raised, regexp_substr( cleared,'[^/]+',1,level) cleared from t connect by prior NE = NE and regexp_substr( raised,'[^/]+',1,level) = prior regexp_substr( raised,'[^/]+',1,level + 1)Published by: pollywog on March 29, 2011 09:38
Here it is with the type clause that gets rid of all unions.
WITH t AS (SELECT '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised, '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared FROM DUAL UNION SELECT '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' FROM DUAL) SELECT * FROM (SELECT NE, raised, cleared FROM t MODEL RETURN UPDATED ROWS PARTITION BY (NE) DIMENSION BY (0 d) MEASURES (raised, cleared) RULES ITERATE (1000) UNTIL raised[ITERATION_NUMBER] IS NULL (raised [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (raised[0], '[^/]+', 1, ITERATION_NUMBER + 1), cleared [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (cleared[0], '[^/]+', 1, ITERATION_NUMBER + 1))) WHERE raised IS NOT NULL ORDER BY NEPublished by: pollywog on March 29, 2011 10:34
-
How to divide the data in the column based identifier
Hello
I use the oracle database.
I have data in this format in my column 1234 ~ 2345 ~ 3456 ~ 4567.
I need a motion to split the data in the column based on the identifier ' ~', so that I can choose the value after the second occurrence of the identifier.
Do I know who can do this.
Published by: 962987 on October 3, 2012 12:11Hello
Welcome to the forum!
Whenever you have any questions, please post CREATE TABLE and INSERT statements for some examples of data and the results desired from these data. For example, in view of these data
CREATE TABLE table_x ( my_column VARCHAR2 (40) ); INSERT INTO table_x (my_column) VALUES ('1234~2345~3456~4567'); INSERT INTO table_x (my_column) VALUES ('just~2 parts');I think you're asking for these results
PART_3 MY_COLUMN ---------- ---------------------------------------- 3456 1234~2345~3456~4567 just~2 partsI suppose that, if the string does not contain at least 2 ' ~ s, you want to return null. It's a good idea to explain what you want like that for special cases and include examples in your sample data and results.
Not all versions of Oracle are exactly the same. In fact, they are all different. If you want the best solution that works with your version, then say what version it is.
The following query will work in Oracle 10.1 and higher:SELECT REGEXP_SUBSTR ( my_column , '[^~]+' , 1 , 3 -- 3rd occurrence (after 2nd delimiter) ) AS part_3 , my_column -- if wanted FROM table_x ;See the FAQ forum {message identifier: = 9360002}
Published by: Frank Kulash, October 3, 2012 15:24
Adding sample data and results. -
APEX do not allow to change the lines of the columns that are the primary key?
I have pictures:
http://img508.imageshack.us/my.php?image=21269582oe8.jpg
Book (id_book - 'Primary key', title, year); book_author (id_author id_book - 'Primary key', - 'Primary key'); author (id_author - "Primary key", name)
I created a new page-> Form-> form of 'author' table because I want to add new authors, modification and deletion. During the creation of this page, I have chosen column 'id_author' as '1 primary key column' and everything is OK (I can't edit the 'id_author' column - this column is autoincrement and I can change the 'name' column).
BUT I also created a new page-> Form-> table for table "book_author" because I like to write numbers like id_book and id_author, change and remove them (so add relations between tables: book, book_author and author). During the creation of this page, I have chosen column 'id_book' as '1 primary key column' and 'id_author' as 'column primary key 2'. And on the Web site, I can't edit these fields. And I can not add also new line because I see in each new line: (null).
http://img444.imageshack.us/my.php?image=11324615yk9.jpg
APEX do not allow to change the lines of the columns that are the primary key? It's stupid... What can I do?
Edited by: user10731158 2008-12-20 11:40Column unique and not meaningful if you ever want to update. In the case of your example, you need to add an ID column in the intersection of book_author table. Honestly, I was so blown away (and pleasantly surprised) by the absence of rebuttal and the "thx" I advanced and set up an example of how I would define the book_author table:
create table book_author (id varchar2(32), book_id varchar2(32), author_id varchar2(32), modified_on date, modified_by varchar2(255), constraint book_author_pk primary key (id), constraint book_auth_book_fk foreign key (book_id) references books(id), constraint book_auth_author_fk foreign key (author_id) references authors(id) ) / create unique index book_author_uq on book_author (book_id,author_id) / create or replace trigger biu_book_author before insert or update on book_author for each row begin if inserting then :new.id := sys_guid(); end if; modified_on := sysdate; modified_by := nvl(v('APP_USER'),user); end; /Good luck
Tyler -
lines to the column and summation
Hi everyone, I am using oracle 10g consider the following data:
WITH the data as {}
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 123.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 111.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 666.23 amount OF the dual UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 888.23 amount OF the double UNION
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 333.23 amount OF the dual UNION ALL
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 222.23 amount OF double UNION ALL
SELECT mntrid "XTR3", "CCC" ctid, ' hi tech 3 ' description, code 'PC', 777.23 amount OF double
}
I would like secret lines at column and add the amounts. my output should be like this
MNTRID CTID DESCRIPTION MAIN PC PAYROLL
XTR AAA hi tech 234,46 1554.46
XTR2 BBB Hi tech2 555.46
CCC XTR3 Hi Tech 3 777.23
what I do is converting lines to the column and the display of the sum. for example, for mntrid = XTR I get the sum of all MAIN lines and the lines all PAY and PC.
Since there is no line of PC for XTR I display null.
can someone help me write a query that displays the output in oracle 10g above?
Hello
elmasduro wrote:
It's great Frank. Thank you very much.
I have a request. What happens if I want to add total main grad, wages, the pc? How would I do that.
output
Total general AFFID CTID DESCRIPTION MAIN PAY PC
XTR AAA hi tech 234.46 1554,46 1788.92
XTR2 BBB Hi tech2 555,46 555.46
CCC XTR3 Hi Tech 3 777,23 777.23
It's just plain old garden-variety SUM:
SELECT Mntrid
ctid
Description
, SUM (CASE WHEN code = "MAIN" THEN rise END) AS main
, SUM (CASE code WHEN = "SALARY" THEN rise END) AS pay
, SUM (CASE WHEN code = 'PC', THEN rise END) AS pc
, The SUM of (amount) AS grand_total-* NEW *.
FROM the data
GROUP BY mntrid
ctid
Description
;
-
upgrades of vcenter 5.0.1b to 5.0.2 (5.0 update 2) includes the schema of database update/upgrade?
upgrades of vcenter 5.0.1b to 5.0.2 (5.0 update 2) includes the schema of database update/upgrade?
Hello
I'd be surprised if there is one, but have you checked with the database audit tool?
http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2004286 - mentions not required for minor updates but still should be able to run it.
Many tx
-
How to query start a new line in the column?
How to query start a new line in the column?
Exam
SELECT ID, username | host name, details of xxx;
on the 2 column, I need result below:
Username ID | hostname in detail
1 user1 xxxxxx
host1
2 user2 xxxxxx
host2
Kind regards
SuradechSomething like that?
SQL> WITH tbl AS (SELECT 1 id,'user1' uname,'xxx' dtl,'host1' hname FROM DUAL UNION ALL 2 SELECT 2 id,'user2' uname,'yyy' dtl,'host2' hname FROM DUAL UNION ALL 3 SELECT 3 id,'user3' uname,'zzz' dtl,'host3' hname FROM DUAL 4 ) 5 SELECT id,uname||dtl||chr(10)||hname FROM tbl; ID UNAME||DTL||CH ---------- -------------- 1 user1xxx host1 2 user2yyy host2 3 user3zzz host3 -
Update the value of the column based on another value of the column to another table
Hi all
I have something very confused me and need your help.
Having two tables A and B.
Table A have 2 column (+ id + and desc1)
Table B have column 2 also (+ transnum + and desc2)
Now, I want to update the column desc2 of table B identical desc1 of table was where transnum of Table B same as the id of the table has.
I use this SQL
update of a2 set a2.desc2 = a1.desc1 of a2 on a2.transnum = a1.id inner join a1
but this error occurs
Error from line 5 in order:
update of a2 set a2.desc2 = a1.desc1 of a2 on a2.transnum = a1.id inner join a1
Error in the command line: 5 column: 35
Error report:
SQL error: ORA-00933: SQL not correctly completed command
* 00933. 00000 - "command not properly ended SQL."
* Question: *.
* Action. *
Hope someone can help me. TQ for help...SQL> create table a1 (id number(2),des varchar2(10)); Table created. SQL> create table b1 (transnum number(2),des varchar2(10)); Table created. SQL> insert into a1 values (1,'maran'); 1 row created. SQL> insert into b1 values (1,'ram'); 1 row created. SQL> commit; Commit complete. SQL> update b1 set des=(select des from a1 where b1.transnum=a1.id); 1 row updated. SQL> select * from b1; TRANSNUM DES ---------- ---------- 1 maran -
Conditionally display the values in the column based on another column
Hello
I'm sure this has been covered before, but I can't find anything appropriate based on the research I've done.
I have 2 attributes in VO.
I have a table that displays this VO.
I still want to display header for both attributes, but I only want to show the value of attribute 1 in a row, if value of Attibute2 = 'I '.
If Attibute2! = 'I', so I want just the column for Attribute1 to be empty space.
I've not yet done anything with conditional expressions, and I wonder if someone could provide a link or a thread which is similar to this issue.
Thank you
JoelYou can do according to the post above, but if you are not interested in changing the original Version and I want to just change the user interface page only, you can do as in the example below:
lines = ' #{bindings. " Employee.rangeSize}.
emptyText = "#{bindings." Employee.Viewable? "{'No data to display.': 'Access Denied.'}".
fetchSize = "#{bindings." Employee.rangeSize}.
rowBandingInterval = '0 '.
selectedRowKeys = ' #{bindings. " Employee.collectionModel.selectedRow}.
selectionListener = "#{bindings." Employee.collectionModel.makeCurrent}.
rowSelection = "single" id = "t1" >
headerText = "#{bindings." Employee.hints.Employeeid.label}.
ID = "c2" >
model = ' #{bindings. " Employee.hints.Employeeid.format}"/ >
headerText = "#{bindings." Employee.hints.Employeename.label}.
ID = 'c3' >
headerText = "#{bindings." Employee.hints.Salary.label}.
ID = "c1" >
*
ID = "ot2" >
model = ' #{bindings. " Employee.hints.Salary.format}"/ >
OutputText for the Attibute1, you can write the EL expression as:
*<>
* value = "#{rank." Attibute2 == "I"? "line. "{Attibute1:"}. "
* id = "ot2" > *.I hope this helps.
Thank you
Nini -
RESULT DATE1 POINT
-------------------------------------------
XYZ F 1 JUNE 07
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
XYZ F 1 JUNE 07
ABC F 1 JUNE 07
ABC F 1 JUNE 07
F 1 JULY 07 ABC
F 1 JULY 07 ABC
P 1 JULY 07 ABC
P 1 JULY 07 ABC
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
the above lines must be transposed to the columns as below table from the above. That takes the number total of RESULTS, County of 'F', 'P' County, based on the month and the product.
DATE1 POINT TOTALCOUNT COUNT_OF_F COUNT_OF_P
---------------------------------------------------------------------------------------------------------------------------------------------------
1ST JUNE 07 XYZ 2 2 0
1 JULY 07 XYZ 3 3 0
1ST JUNE 07 5 2 3 ABC
1 JULY 07 4 2 2 ABC
Thank youuser9370033 wrote:
RESULT DATE1 ITEM ------------------------------------------- F 01-JUN-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUN-07 XYZ F 01-JUN-07 ABC F 01-JUN-07 ABC F 01-JUL-07 ABC F 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC the above rows has to be transposed to columns like below table from the above one. Which takes the total count of RESULT, count of "F" , count of "P" based on month and Product. DATE1 ITEM TOTALCOUNT COUNT_OF_F COUNT_OF_P --------------------------------------------------------------------------------------------------------------------------------------------------- 01-JUN-07 XYZ 2 2 0 01-JUL-07 XYZ 3 3 0 01-JUN-07 ABC 5 2 3 01-JUL-07 ABC 4 2 2Thank you
You can do like this
select date1, item, count(*) totalcount, count(decode(result,'F',1,null)) count_of_f, count(decode(result, 'P',1, null)) count_of_p fromgroup by date1, item
Problem with insert/update statements on the MS Access database
Hi all
Before posting this question, I did a search and found this thread.
I have the same problem as pawel had (in this thread), i.e. cannot insert or update data in the Access database. However, the reason is not that I am using some keywords in my domain name - it has been several years using SQL, some things are 'unwritten' rules But this is the first time I try something in LV
However, after losing all day for work that I expect to do the same morning in 1 hour, try many different options and debugging until the level low in the Toolbox of data base screw (building or higher), I saw some weird SQL statement being trained in-house - so I tried what Troy has tried.
"password" is a reserved word in the Jet. I just looked at MOManagers_M, but by changing the field "password" to 'passworda', it does the job.
ADF: how to insert the character of new line in the column of VO?
Hello world
IM using Jdev 11 G.
I have a VO with 5 columns appear on the page of the ADF. (VO a total 8 columns)
column 1 is the combination of 3 columns. I concatenated 3 columns and add the new line character after each column Chr (13).
VO query works very well as a toad. the columnn displays each column value concatenated after a newline character, but the same query does not work in the ADF.
The column that is the concatenation of the 3 columns and should display with the new line character does not display the new line character its just concatenation of the 3 values and display on the page.
Wat could be the solution for this in the ADF?
Thank you.Column does not have the property to escape. It is part of the output text.
Something like
Arun-
Update lines with the info from the other rows in the same Table.
I'm trying to update the lines with the information of the same table. The table is loaded with information from a report that runs and there must be a new entry every month, but I would like to bring some of the info from the last month. This statement below works but updates all rows in the new load table and in my test case, I only did a few game only like 5 files need to get updates. It is an example of what I'm trying to do. If I add this (C2. COL_INVC_ID = C1. COL_INVC_ID) until the last "* where *" statement get an invalid identifier for 'C2 '. COL_INVC_ID ". So what I'm doing wrong here? How can I update only the lines where also in recent months run?
Thanks in advance for any help!
------------
Update OpenIssues OI1
Together (OI1. NUM, OI1. Status, OI1. Code, OI1. LastModifiedDate) =
(Select ios2. NUM, ios2. Status, ios2. Code, ios2. LastModifiedDate
Of OpenIssues ios2
Where OI2.num = OI1.num and ios2. TableLoadDate = TO_DATE (January 31, 2012 00:00:00 ',' ' the HH24: MI: SS DD/MM/YYYY)
)
Where and OI1. TableLoadDate = TO_DATE (February 29, 2012 00:00:00 ',' ' the HH24: MI: SS DD/MM/YYYY)
------------
SQLMeAs Frank suggested merger is much effective here, go...
create table temp as( select 1 eno, 1 amt , sysdate load_date from dual union all select 1 eno, 2 amt , add_months(sysdate,1) load_date from dual union all select 2 eno, 1 amt , sysdate load_date from dual union all select 2 eno, 2 amt , add_months(sysdate,1) load_date from dual ); merge into temp t using (select eno, amt, load_date from temp where trunc(Load_Date) = TO_DATE('05/30/2012', 'MM/DD/YYYY')) s on ((s.eno = t.eno) and trunc(t.Load_Date) = TO_DATE('06/30/2012', 'MM/DD/YYYY')) when matched then update set t.amt = s.amt; commit; select * from temp;- Hi all, I have two tables with data as described below.
what I want to do is to join these two tables and get the values of the table Details
and fill in the data table in the columns that are null. Data table must remain with one
line.
WITH the data AS
(
SELECT "a34" id, "pat smith" name, 234 compid, NULL returned, NULL, NULL prod FROM dual UNION all
SELECT "a35" id name "case jon", dual 543 compid, NULL, NULL, NULL FROM prod revenue business
)
Details such AS
(
SELECT "a34' id code 'craft', 123 idvalue FROM double UNION all
SELECT "a34' id, 'rev' code, 456 idvalue FROM double UNION all
SELECT "a34' id, 'product' code, 789 idvalue FROM dual UNION all
SELECT "a35' id code 'craft', 294 idvalue FROM double UNION all
SELECT "a35' id, 'rev' code, 546 idvalue FROM double UNION all
SELECT "a35' id, 'product' code, 654 double idvalue
)
the output of this query should be
ID name compid prod turnover
A34 pat smith 234 123 456 789
A35 case jon 543 294 546 654
can someone help write a query that gives me not the above result? Thank youThis gives a shot:
WITH data AS ( SELECT 'a34' id, 'pat smith' name, 234 compid, NULL business, NULL revenue, NULL prod FROM dual UNION all SELECT 'a35' id, 'jon case' name, 543 compid, NULL business, NULL revenue, NULL prod FROM dual ), details AS ( SELECT 'a34' id, 'business' code, 123 idvalue FROM dual UNION all SELECT 'a34' id, 'rev' code, 456 idvalue FROM dual UNION all SELECT 'a34' id, 'product' code, 789 idvalue FROM dual UNION all SELECT 'a35' id, 'business' code, 294 idvalue FROM dual UNION all SELECT 'a35' id, 'rev' code, 546 idvalue FROM dual UNION all SELECT 'a35' id, 'product' code, 654 idvalue FROM dual ), unpivot_details AS ( SELECT ID , MAX(DECODE(CODE,'business',IDVALUE)) AS BUSINESS , MAX(DECODE(CODE,'rev',IDVALUE)) AS REVENUE , MAX(DECODE(CODE,'product',IDVALUE)) AS PROD FROM DETAILS GROUP BY ID ) SELECT DATA.ID , NAME , COMPID , NVL(DATA.BUSINESS,UD.BUSINESS) AS BUSINESS , NVL(DATA.REVENUE,UD.REVENUE) AS REVENUE , NVL(DATA.PROD,UD.PROD) AS PROD FROM DATA JOIN unpivot_details UD ON DATA.ID = UD.IDI did take your DETAILS and UNPIVOT table data turning rows of columns. I used this result to join the DATA table. Once the tables were joined, I used the function NVL will only display the DETAILS table data if the data in the DATA table is NULL.
If you have more values of 'code', you will need to add them manually to the UNPIVOT_DETAILS view.
HTH!
How to set the width of the column based on the width of header?
I have a column that will contain only 1 character. It's good, but I want that column width to match the column header.
For example,.
Currently, I get:
Select * from table;
I NAME
- ---------
1 ROBERT
The problem is, I want the column heading set out (in this case, it's just the ID)
ID NAME
-- ---------
1 ROBERT
Better yet,.
If I did:
Select the ID "Identification NUMBER", "FIRST NAME" of table name;
I want to see:
ID NUMBER NAME
--------------- -----------------
1 ROBERT
(The ID in the column width of centering would be good too, but it's "sauce")
Any thoughts? I tried:
FORMAT ID COLUMN A10 (which obviously didn't work!)
Thank you
KSL.
Published by: leonhardtk on August 23, 2010 11:55Hello
You can check [SQL Reference | http://download.oracle.com/docs/cd/E11882_01/server.112/e10592/functions093.htm#SQLRF00663] for syntax.
SELECT LPAD('A', 10) FROM DUAL;Maybe you are looking for
-
I used the same setup file, but on 1 pc, the "Open new tab" button is available in the menu 'Customize toolbar' and can be dragged and drop on the navigation bar. On the other pc, the "Open new tab" button/icon is not yet available for drag / drop. I
-
Okay, so my problem is that Disk Defragmenter, disk checking and the system restore will not work.
I tried to go to the c drive and right on it and going click Tools then error checking, but it did not work. I tried dfrg.in and right click to install. I tried to use cmd fixes, I found on the net. I tried a lot of bugs, but nothing helped. Any idea
-
I have a question about running my application of profiling. I ran the following code: private function onMouseMove(event:MouseEvent):void { var mark:Number = getTimer(); trace ("time: ", getTimer()-mark, "ms"); } My trace shows never liked 20 MS (w
-
It's not my vixs puretv-u b 48-0 tv tuner works for windows 7 anyone can help me?
I had windows vista and my tv tuner worked perfectly and now I have installed on my windows 7 32-bit computer because is more reliable and faster but my tv tuner cant find all the channels now. the driver has been installed successfully but windows m
-
It is safe to delete the archivelogs FRA?
HelloI'm running an Oracle 12 c database and running a backup script every week:RMAN > BACKUP of DATA PLUS ARCHIVELOG;The archivelog should therefore be connected, no? Today I got an ora-00257. The current solution is to resize the area of 6 GB to 20