Concatenation of the name of the table in the Insert query
Greetings,
Oracle Version - Oracle9i Enterprise Edition Release 9.2.0.6.0 - 64 bit Production
I want to write a procedure in which we give the name of the table in the Insert at runtime through cursor
But the problem is
insert into tra_temp
Select * tra_smi23 of
in statement above 23 must be dynamic like tra_smi | 23
Here is my code, but something is not
Kindly help
create or replace procedure as
cursor c1 is
Select op_ID, operators OP_NAME where OP_NAME like '% TRA '.
and OP_ID <>9;
Start
run immediately 'truncate table tra_temp;
for rec in c1
loop
insert into tra_temp
Select * from tra_SMI | ' recomm. OP_ID';
commit;
When exit c1% notfound;
end;
Hello
Then you must change the insert statement for: run immediately ' insert into tra_temp select * from tra_SMI'| recomm. OP_ID;
Concerning
Mr. Mahir Quluzade
Tags: Database
Similar Questions
-
trigger for the insert statement
Hello.
I have a table, say, with 3 columns: ID, NAME, NAME_LENGTH.
I am trying to create a trigger that fires when a record is inserted in the table.
I send values for the ID and NAME columns per INSERT statement. and I need the trigger to write the LENGTH OF THE NAME INSERTED in the 3rd column
CREATE OR REPLACE TRIGGER schema_name. GENERATE_length
AFTER INSERT ON table_name
FOR EACH LINE
DECLARE
F NVARCHAR2 (200);
L NUMBER (5);
NL NUMBER (5);
NUMBER OF ID_LENGTH (5): = 5;
BEGIN
F: =:New.Name;
L: = LENGTH (F);
UPDATE HR_ORG_TREE
SET name_length = NL;
END;
but does not work. error occurres as...
ORA-04091: table schema_name.table_name is changing, the function of triggering/can not see
ORA-06512: at the 'schema_name '. GENERATE_length', line 13
ORA-04088: error during execution of trigger ' schema_name. GENERATE_length'
Thank you.
SaraCREATE OR REPLACE TRIGGER schema_name.GENERATE_length -- is "table_name" real name of your table? AFTER INSERT ON table_name FOR EACH ROW BEGIN -- this update will change all rows in HR_ORG_TREE table -- specify WHERE for this update UPDATE HR_ORG_TREE SET name_length = LENGTH(:NEW.name); END;Suppose your table_name is HR_ORG_TREE and you need to calculate the length of the name for just inserted row
After maybe the code will be useful (not tested)CREATE OR REPLACE TRIGGER schema_name.GENERATE_length BEFORE INSERT ON HR_ORG_TREE FOR EACH ROW BEGIN :new.name_length := LENGTH(:NEW.name); END;Good luck
-
RICs when MergeTable using with the names of multiple tables
Hello world!
I just saw, as v11 OWM MergeTable media with the names of multiple tables. As I couldn't find anything in the documentation, here's a question:
It also means, that RICs are automatically taken into account regarding the order of INSERTS/CHANGES/DELETES?
That would actually really great and simplify the merge of our application mechanism a lot.
Kind regards
Andreas
Hi Andreas,
This feature works the same MergeWorkspace, but with a smaller set of tables. Tables will always be merged into the order of the child table first, then the parent tables. However, foreign key constraints are not validated until all tables have been merged. This would prevent a mistake to be triggered when the child table merging before the parent merging table data in the parent workspace.
Kind regards
Ben
-
get the name of a directory file and insert it into a table
Hello
I have a requirement, I need to read the name of a Linux directory file and enter the file name in a variable,
After that, I need to insert this file name in a table.
EX: is it a file1.txt in Yearbook of the CBA, and I read that 'file name' in the v_file_name variable and I'm going to insert this file name in a table.Hello
I think you've got your request of replied by Chantal.
Shoul you have a kind of intelience in the name of the file itself so that ODI retrieves the correct file and insert into the table.Thank you
Fati -
How to find the same column name in different tables in the same schema
Hello
I find the 'ename' column name in different tables in the same schema.
Thank you
NrHello
Try this query
Select column_name, table_name from user_tab_columns where column_name = 'ENAME ';
Award points and end the debate, if your question is answered or mark if she was...
Kind regards
Lacouture.
-
AF:table with the search query present bindvariable name in the filter text field
I created a simple display with a criterion of the view object. The criteriy defines a group with 4 criteria. Each element of the criteria has a STARTSWITH operator and compare a column to a binding parameter. The binding variable is marked as optional.
Then I move the data control named on my page and selected criteria "Read - Only ADF filtered table"
When the page is displayed to the user, I had the table containing the search field in the header.
Unfortunately, the entry to the filter of the table fields are not empty, but containing the name of the connection variable.
text in a filter for GebeCode: VarGebeCode *.
text in a filter for NiedCode: VarNiedCode *.
...
When the user just wants to filter on a property, for example GebeCode, the user must
(1) type in the GebeCode
(2) delete the input for other filter box filter: NiedCode,...
Step 2 is heavy, but if the user does not specify an empty text in the filter, no lines are selected in the query.
1 question
How can I get the boxes of entry filter empty the first time the page is loaded?
2 question
As see you in the criteria listed below, I put the box "Ignoe box" (-> UpperColumns = '1') to make my case insensitive search.
How ever, it does not work: it is always case sensitive.
How can I get the framework to do things?
It is the resuling query where clause:
Code MitarbeiterViewRVOCriteria( ( ( UPPER(MITA_NAME_VORNAME_CODE) LIKE UPPER( :VarMitaNameVornameCode || '%') ) OR ( :VarMitaNameVornameCode IS NULL ) ) AND ( ( UPPER(MITA_CODE) LIKE UPPER( :VarMitaCode || '%') ) OR ( :VarMitaCode IS NULL ) ) AND ( ( UPPER(GEBE_CODE) LIKE UPPER( :VarGebeCode || '%') ) OR ( :VarGebeCode IS NULL ) ) AND ( ( UPPER(NIED_CODE) LIKE UPPER( :VarNiedCode || '%') ) OR ( :VarNiedCode IS NULL ) ) )
Edited by: Stefan1979 the 06.11.2009 20:45<ViewCriteria Name="MitarbeiterViewRVOCriteria" ViewObjectName="model.mitarbeiterDetails.view.MitarbeiterViewRVO" Conjunction="AND"> <Properties> <CustomProperties> <Property Name="displayOperators" Value="InAdvancedMode"/> <Property Name="autoExecute" Value="false"/> <Property Name="allowConjunctionOverride" Value="true"/> <Property Name="showInList" Value="true"/> <Property Name="mode" Value="Basic"/> </CustomProperties> </Properties> <ViewCriteriaRow Name="vcrow12" UpperColumns="1"> <ViewCriteriaItem Name="MitaNameVornameCode" ViewAttribute="MitaNameVornameCode" Operator="STARTSWITH" Conjunction="AND" Value=":VarMitaNameVornameCode" IsBindVarValue="true" Required="Optional" UpperColumns="1"/> <ViewCriteriaItem Name="MitarbeiterViewRVOCriteria_vcrow12_MitaCode" ViewAttribute="MitaCode" Operator="STARTSWITH" Conjunction="AND" Value=":VarMitaCode" IsBindVarValue="true" Required="Optional" UpperColumns="1"/> <ViewCriteriaItem Name="MitarbeiterViewRVOCriteria_vcrow12_GebeCode" ViewAttribute="GebeCode" Operator="STARTSWITH" Conjunction="AND" Value=":VarGebeCode" IsBindVarValue="true" Required="Optional" UpperColumns="1"/> <ViewCriteriaItem Name="NiedCode" ViewAttribute="NiedCode" Operator="STARTSWITH" Conjunction="AND" Value=":VarNiedCode" IsBindVarValue="true" Required="Optional" UpperColumns="1"/> </ViewCriteriaRow> </ViewCriteria>Hello
the case sensitive search is controlled by the 'filterFeatures' on the af: column. Due to a bug that is fixed in the next Patch set 1 of JDeveloper 11 g R1, that the search is always case-sensitive.
Frank
-
I have two tables (2) RESULT TAB (1)
CREATE TABLE TAB
(
NUMBER OF SNO
A NUMBER,
B THE NUMBER.
NUMBER OF THE SUM
);
CREATE AN ARRAY OF RESULT
(
NUMBER OF SNO
NUMBER OF THE SUM
)
my doubt is:
(1) I want to insert a table TAB, my question is how to insert a column to the SUM using the column A AND B... Here im adding two values of the column and store result in the AMOUNT column.
SNO A B SUM
1 100 150 250
2 300 100 400
I want to like this, it is possible with single insert query?
(2) at the time of the insertion TAB of values that SNO, and the values of table TAB $ insert in the table of RESULTS... is it possible these two inserts at the same time?
in fact, im using another this table.fro TAB and easy to understand I write like that, please solve this problem
First, you post in the wrong forum as this one is only for Oracle's SQL developer tool. So you might ask your question in the general forum of SQL.
Second, you might solve your problems with bind variable:
Insert tab
(sno, a, b, sum)
values
(: SNO,: A: B: A + B :))
You should not use sum as column name because it is a reserved word.
More you cannot insert into two different tables with a single SQL, but you can use PL/SQL to do this:
Start
insert into tab values (: SNO,: A: B: A + B :);)
insert into result values (: SNO,: A + B :);)
end;
If you meet sno from a sequence, you could do something like this:
Start
insert into values tab (seq_sno.nextval,:,: B,: A +: B) return sno in: SNO.
insert into result values (: SNO,: A + B :);)
end;
Hope that helps,
dhalek
-
FETCH ONE RECORD IN THE SECOND TABLE OF CORRELATED SUB QUERY
Hi all
I have provided the script below, I want to single fecth record in the second table in the join query,
based on the example below, I want to go get one record of the table emp2 what matches with the emp_id of table emp1, please note emp2 may contain more record for the emp_id emp1 which respects
all records can be selected in the table emp2.
DROP TABLE emp1.
CREATE TABLE emp1 (emp_id NUMBER);
INSERT INTO emp1 VALUES (1);
INSERT INTO emp1 VALUES (2);
COMMIT;
DROP TABLE emp2.
CREATE TABLE emp2 (emp_id NUMBER, emp_name VARCHAR2 (100));
INSERT INTO emp2 VALUES (1, 'Name1');
INSERT INTO emp2 VALUES (2, 'Name2');
INSERT INTO emp2 VALUES (1, 'Name3');
INSERT INTO emp2 VALUES (2, 'Conjoint4');
COMMIT;
SELECT * from emp1.
SELECT * from emp2.
SELECT T1. EMP_ID, MIN (T2. EMP_NAME)
FROM EMP1, EMP2 T2 T1
WHERE T1. EMP_ID = T2. EMP_ID
GROUP T1. EMP_ID;
My output should be the same as the result set of query above, but I don't want this logic, please provide the solution by using a different logic, thanks in advance.
2811876 wrote:
Thanks for your comments :-)
My business logic will change to 'Fetch N second timeline table', that's the reason why I asked for a different approach, if I use max, min to achieve this does not allow me to evolve dynamically.
Although logic has not been expressed at all in your original question, so good job I asked.
You could do something like:
SQL > ed
A written file afiedt.buf1 with emp1 (select 1 as the emp_id of union double all the)
2. Select 2 double
3 )
4, emp2 (select 1 as emp_id, 'name 1' as emp_name double union all
5. Select "name 2' Union double every 2
6 select 1, 'name' 3' from dual union all
7. Select 2, 'name 4' double union all.
8 select 1, 'name 5' from dual union all '.
9 select 2, 'name 6' from dual '.
10 )
11-
12. end of test data
13-
14 select emp_id, emp_name
15 of)
16 select t1.emp_id, t2.emp_name
17, row_number() over (partition by order of t2.emp_name t1.emp_id) rn
emp1 t1 18
19 join t2 emp2 (t1.emp_id = t2.emp_id)
20 )
21 * where rn<=>
SQL > /.Enter the value for rows_required: 1
21 Alumni: where rn<=>
21 news: where rn<=>EMP_ID EMP_NA
---------- ------
1 name 1
2 name 2SQL > /.
Enter the value for rows_required: 2
21 Alumni: where rn<=>
21 news: where rn<=>EMP_ID EMP_NA
---------- ------
1 name 1
1 name 3
2 name 2
2 name 4 -
Entries are concatenated in the same column in the excel file
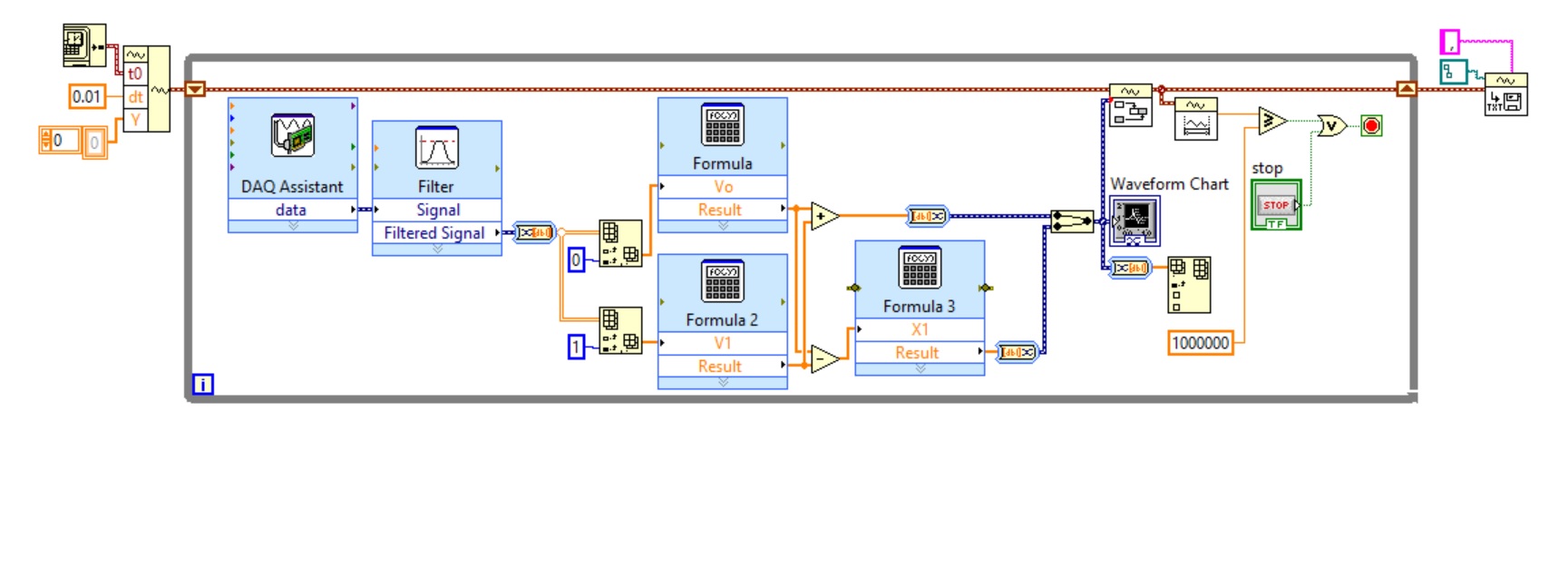
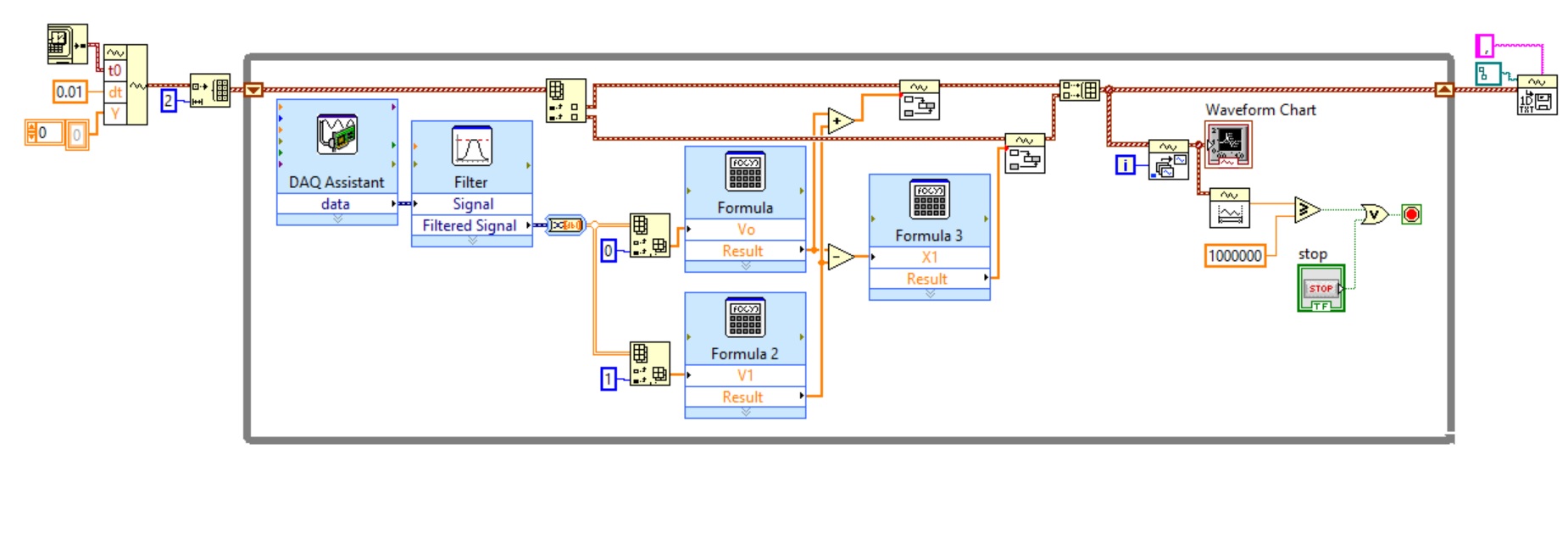
Hi, I really need help in this emergency. The problem is when I open the spreadsheet file after you run the program below, all the values that I believe are concatenated in the same column. However, there are 2 different analog inputs which I want in 2 different columns. I'm getting the 2 waveforms in the same graph, but when I open the excel file, it seems that the entries are concatenated in the same column. Someone knows how to fix this? Thank you very much.
Hi Ben 64,.
Thanks a lot again. I did as you said and I removed the dynamic data and logged files added directly to the results. I'm still checking if the program works as I can branch only when I return to work tomorrow. Tell me if you think it might be able to work this time. Thanks a lot again!
-
Table error ' can not analyze the SQL query!
Hi all
I created a view on my database called VIEW_MEMBER_PARTIC_PROJECTS
If I run a query showing the results of the view:
SELECT * FROM VIEW_MEMBER_PARTIC_PROJECTS
I get the following data
Projects Participants 1 31 S 2 41 3 19 4 3 5 3 6 1 7 2 Now, I wanted to represent this diagram in the APEX so I created a graphic region and entered the Source query generator and the manufacturer produces the following code
Select null, label projects, value1 Participant link
of "SCHEMANAME." "" VIEW_MEMBER_PARTIC_PROJECTS ".
With this code, I get an error:
Cannot parse the SQL query!
Select the link null, label projects, value1 "SCHEMANAME Participant." "" VIEW_MEMBER_PARTIC_PROJECTS ".
Some queries can be run when you run your application, if your query is syntactically correct, you can save your query without validation (see options below the source of the query).
The code looks OK, but I do not see to save options as the error code is mentioned.
No one knows how to fix this?
Thank you
JaReg wrote:
I finally found the problem.
I looked at the code for the view and changed the start of:
CREATE OR REPLACE FORCE EDITIONABLE VIEW "SCHEMANAME." "" VIEW_MEMBER_PARTIC_PROJECTS "("Participant","Projects")
AS
TO
CREATE OR REPLACE VIEW "SCHEMANAME." "" VIEW_REPEAT_PARATIC ".
AS
And that seemed to fix it. I'm not entirely sure why though.
The view was created using the quoted identifiers for column names. This makes them sensitive and means that they must always be referenced using double quotes. In the absence of quotation marks, Oracle is not case insensitive and automatically converts all uppercase identifiers. The application of graph:
Select the link null, label projects, value1 "SCHEMANAME Participant." "" VIEW_MEMBER_PARTIC_PROJECTS ".
has therefore been interpreted by Oracle:
SELECT THE LINK NULL, LABEL, VALUE1 "SCHEMANAME PARTICIPANT PROJECTS." "" VIEW_MEMBER_PARTIC_PROJECTS ".
and PROJECTS and PARTICIPANT columns were not recognized because the columns defined for the view have been 'Participant' and 'projects '. The graphic request should have been:
Select the link null, the label of "Projects", "Participant" value1 "SCHEMANAME." "" VIEW_MEMBER_PARTIC_PROJECTS ".
As you have now discovered, quoted identifiers are a source of nothing but obscure bugs and should never be used for database objects. He also pointed out the reason why you should always use a standardized, form tiny, coding style as it is faster to type, easy to read and less prone to errors.
-
How to use the slider in the insertion of data in table to another
Hi all
I am beginner in oracle and I have a question to deal with my table
I have 2 table lets say (c1) and (c2).
C1 contains the following columns (product_number, product_name, description)
C2 contains the following columns (product_code, product_id, description)
I need to build anonymous blocks including cursor, this extraction of cursor data c2 to insert in c1 in the following way:
product_code = product_number,
product_id = product_name,
description = description
a help can you please...?
Thanks for all,
Best regards.
Sorry to say that this is not "talking nonsense." the statement below, you wrote, updated the TABLE whenever a row is inserted:
Update products
Set service_code = 'VOIP', Charge_type = 'FIXED', PRODUCT_TYPE = 'SERVICE', super_product = 'n',
available = 'Y', default_bill_method = 'TIPS', default_prorate = 'Y', gl_code = '00000',.
service_type = "COMPLEMENTARY", partner_code is "oman", used_service_code = "VOIP."
I can't believe that's what you intend to update an entire table every time that a row is inserted.
The second problem I see is that you try to use v_x and you aren't anything to assign to this variable. Whence 'rownum '? ROWNUM is generated when choosing and assigned to the rows in a result set. Looking at a rewrite of your code that actually works now:
SQL > declare
2
3 v_sku TMP_TABLE. Type % SKU;
v_DESCRIPTION 4 tmp_table. DESCRIPTION of % type;
5 v_MSRP TMP_TABLE. Type of MSRP %;
6 v_BILLING_FREQUENCY TMP_TABLE. Type of BILLING_FREQUENCY %;
7 v_ALLOW_PRICE_CHANGE TMP_TABLE. Type of ALLOW_PRICE_CHANGE %;
8 v_status TMP_TABLE. % OF STATUS TYPE.
v_x 9 varchar2 (20);
10
11 tmp_product of CURSOR IS
12. SELECT "p" | status of prod_id, SKU, LTrim (to_char(rowNum,'0999999')), ALLOW_PRICE_CHANGE, BILLING_FREQUENCY, advised, DESCRIPTION retail price
13 FROM tmp_table
14 where sku is not null;
15
BEGIN 16
17
18 open tmp_product;
19
loop 20
21
22 extract tmp_product in v_x, v_SKU, v_status, v_DESCRIPTION, v_MSRP, v_BILLING_FREQUENCY, v_ALLOW_PRICE_CHANGE;
23 when the output tmp_product % notfound;
24
25 INSERT INTO PRODUCTS (product_code, product_name, description, available, DEFAULT_BILL_FREQ, APPLY_SPECIAL_RATES)
26 values (v_x, v_SKU, v_DESCRIPTION, v_status, v_BILLING_FREQUENCY, v_ALLOW_PRICE_CHANGE);
27
28 END LOOP;
29 close tmp_product;
30
31 products update
32 set service_code = 'VOIP', Charge_type = 'FIXED', PRODUCT_TYPE = 'SERVICE', super_product = 'n',
33 available = 'Y', default_bill_method = 'TIPS', default_prorate = 'Y', gl_code = '00000',.
34 service_type = 'SUPPLEMENTARY', partner_code = 'oman', used_service_code is "VOIP."
35
36 commit;
END 37;
38.PL/SQL procedure successfully completed.
SQL >
SQL > select *.
2 from products
3 where rownum<>PRODUCT_CODE PRODUCT_NAME DESCRIPTION AVAILABLE SERVER PRODUCT_TYPE CHARGE_T DEFAULT_BILL S DEFAULT_BILL D GL_CO PARTNER_ USED_SER APP SERVICE_TYPE
-------------------- ---------------------------------------- -------------------------------------------------------------------------------- ------------ ------------ -------- -------- ------------ - ------------ - ----- -------------------- -------- -------- ---
p0000095 Plerkle213 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000096 Plerkle214 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000097 Plerkle215 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000098 Plerkle216 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000099 Plerkle217 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000100 Plerkle218 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000101 Plerkle219 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000102 Plerkle220 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000103 Plerkle221 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES
p0000104 Plerkle222 Plerkle Best Ever! Y QUARTERLY VOIP FIXED SERVICE N TIPS Y 00000 ADDITIONAL oman VOIP YES10 selected lines.
The update has been moved out of the loop, the useless '<>null' condition has been changed to "is not null" and v_x is generated by the cursor query itself.
David Fitzjarrell
-
UPDATE on the same table in the sub query
DB version: 11.2
We have a table called SHP_GC_TRACK, which has about 8 million records with partitions. In the below UPDATE, it updates a column based on the SELECT on the same table in a subquery.
This UPDATE takes a long time to run and sometimes get hung up.UPDATE shp_gc_track a SET f_tran_proc = 'Y' WHERE last_update_date < (SELECT MAX (last_update_date) FROM shp_gc_track b WHERE a.shp_trx_rowid = b.shp_trx_rowid AND a.c_shp_inst = b.c_shp_inst AND a.f_tran_proc = b.f_tran_proc AND b.f_ltr_received = 'D' AND f_rec_code IN ('G', 'W') AND b.f_rec_status = 'B' AND b.c_shp_inst = :b1 ) AND a.c_shp_inst = :b1 AND a.f_ltr_received = 'D' -----------------> part of composite index AND a.f_tran_proc = 'N' -----------------> part of composite index AND a.f_rec_code IN ('G', 'W') --------------> part of composite index AND a.f_rec_status = 'B'; -----------------> part of composite index
We have a composite index on four columns f_ltr_received, f_rec_code, f_rec_status and f_tran_proc. Explain the plan shows that this composite index is used.
Any way to rewrite this query or suggestion?Steve_74 wrote:
DB version: 11.2We have a table called SHP_GC_TRACK, which has about 8 million records with partitions. In the below UPDATE, it updates a column based on the SELECT on the same table in a subquery.
UPDATE shp_gc_track a SET f_tran_proc = 'Y' WHERE last_update_date < (SELECT MAX (last_update_date) FROM shp_gc_track b WHERE a.shp_trx_rowid = b.shp_trx_rowid AND a.c_shp_inst = b.c_shp_inst AND a.f_tran_proc = b.f_tran_proc AND b.f_ltr_received = 'D' AND f_rec_code IN ('G', 'W') AND b.f_rec_status = 'B' AND b.c_shp_inst = :b1 ) AND a.c_shp_inst = :b1 AND a.f_ltr_received = 'D' -----------------> part of composite index AND a.f_tran_proc = 'N' -----------------> part of composite index AND a.f_rec_code IN ('G', 'W') --------------> part of composite index AND a.f_rec_status = 'B'; -----------------> part of composite indexThis UPDATE takes a long time to run and sometimes get hung up.
We have a composite index on four columns f_ltr_received, f_rec_code, f_rec_status and f_tran_proc. Explain the plan shows that this composite index is used.
Any way to rewrite this query or suggestion?
Setting updates with subqueries may be difficult: (.) Unfortunately my suggestions below are of the try-it-and-see-what-happens variety - nothing of certain
First of all, check the index. Is it bitmap or tree? If the tree to see if the more restrictive columns are listed first - this can help with effectiveness of b-tree indexes. Also if the tree a composite bitmap for columns with lots of repeat values instead could help
Its a correlated subquery so that you cannot run just the subquery first put the result in a scalar varaiable and using the variable in the SQL instead. You can try putting the keys w/join subuqery results in a TWG first to use TWG in SQL to see if I/O is reduced together during these two operations.
You have the license for the parallel query option? Using parallel DML (this must be activated manually) can help. Check the documentation of the ALTER SESSION command to do so. In addition, the PARALLEL_INDEX() indicator could help
Display the SQL execution plan
-
using the insert 1 million to create a table
Dear Expert;
Lets say someone sent you instructions insert about 2 million and you want to use to insert into a table or create a new table... How do you do...
because I tried just pointing out all the insert statement and executing them, but that has not worked in pl/sql developer, was crashing whenever I did
The other way may be to create a loop for them and insertion of about 10,000 at a time... but is there a faster way to do...
Any help is appreciated, it...SQL > @script.sql
(some time later...)
SQL > commit;
(This is not ideal but because of analysis. Either that or change the file into something that can be done in a single insert. Or maybe simpler, SQL Loader file or the external table.)
-
What is the syntax for creating a global temporary table using a select query
HII
I create a global temporary table using a select query... How to speak of "on commit preserve rows ' who?
create a table temporary global t1 select * from trn_ordbase on the lines of commit preserve;
but this is an invalid syntax, then how to talk on commit preserve rows in this? If I don't mention, by default its recital on the validation of deleted rows.
Please help me on this problem.create global temporary table t1 on commit preserve rows 2 as select * from dual; Table created. TUBBY_TUBBZ? -
Insert data into the table without using the insert or select the command
Hello
Is there anyway to insert data from one table to another table, without using insert, and then select the command in the same pattern.
Note: the two tables have the same structure.ALTER table... Swap partition...
Maybe you are looking for
-
Bootcamp for repair after the partition
Hello I've done research on how to repair the bootcamp partition, but it seems to be that everyone either has corrupted the partition is before El Capitan and the old disk utility or had more than 4 GPT. While on my own, I have 4 partitions and all m
-
Excel formula does not (ESTNUM, PRODUITMAT)
Hello, I used an excel file that contains formulas which does not work on the numbers and I'm trying to find a way to make it work. It's nice here: = IF (ISNUMBER (ROUND (MMULT (E1, G1), 2)), ROUND (MMULT (E1 + F1, G1), 2),"" ") some research I found
-
install windows 8 on computer hp laptop pavilion 14 ts
Hello When I want to install windows 8 on my computer, the windows process goes up to the section to choose the disk to install windows on. the message says: , we have found all the disks. For a storage driver, click on load a driver. What should I d
-
theres be a way to share our G on Thinkpad non - 3 G phone 3
because we have not rooted devices, it is not possible to activate the ad hoc support... but there's got to be an alternative to use capablity of our 3G phone on Thinkpad non - 3 G tablets Please keep this topic up. We were supposed to have a 'Busine
-
error1068 print spooler service does not I tried several times to restart it, but in vain.
Error 1068 print spooler service is not running.