Create a view of values separated from colon
HelloI have a field that contains the data separated by colons as such:
10:20:30:...
I want to create a view that displays vertical data:
10
20
30
..
Any suggestions?
Thanks in advance
Like this...
SQL> ed
Wrote file afiedt.buf
1 with t as (select 'aaaa:bbbb:cccc:dddd:eeee:ffff' as txt from dual)
2 -- end of sample data
3 select REGEXP_SUBSTR (txt, '[^:]+', 1, level)
4 from t
5* connect by level <= length(regexp_replace(txt,'[^:]*'))+1
SQL> /
REGEXP_SUBSTR(TXT,'[^:]+',1,L
-----------------------------
aaaa
bbbb
cccc
dddd
eeee
ffff
6 rows selected.
SQL>
Tags: Database
Similar Questions
-
Create the view with the dynamic from clause
Hi all
you might have some ideas to help me out of my problem I just "created myself" ;-)
I have an unknown quantity and not constant of the tables using the same structure of the table and I have a main table
that contains all the names of these table types. Now, I want to create a unique view that contains all the columns in each table
and an extra column name containing the name of the corresponding table.
I found a solution for this but only if I knew that all the table names while creating my view.
Here is what I currently have:
master_table:
TABLENAME ID
1 table_01
2 table_02
table_01:
ID NAME
1 eins
zwei 2
drei 3
table_02:
ID NAME
1 a
2 two
3 three
I think 'tab1tab2' on these 2 table looks like this:
ID NAME TABLENAME
1 table_01 eins
2 zwei table_01
3 drei table_01
1 a table_02
2 two table_02
3 three table_02
I have reached this point of view with:
CREATE OR REPLACE VIEW TAB1TAB2 ('ID', 'NAME', 'TABLENAME')
AS
SELECT id, name, 'table_01' AS table_01 FROM tablename
UNION
SELECT id, name, 'table_02' AS tablename FROM table_02;
Is it possible to create as many select statements and union that I entered (tablenames) into my master_table to achieve the same results as my opinion hard?
Thank you very much in advance for your help
Best regards
Majocreate or replace view v_alltables
Select * from v_all;These two statement contradict each other in some way, Don't they?
path ID number name 'id', varchar2 (20) 'name' of the path) x;
the column names are case sensitive - try
id number path 'ID' , name varchar2(20) path 'NAME' ) x;assuming that the names of the columns are named like that.
-
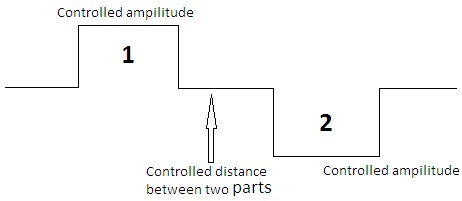
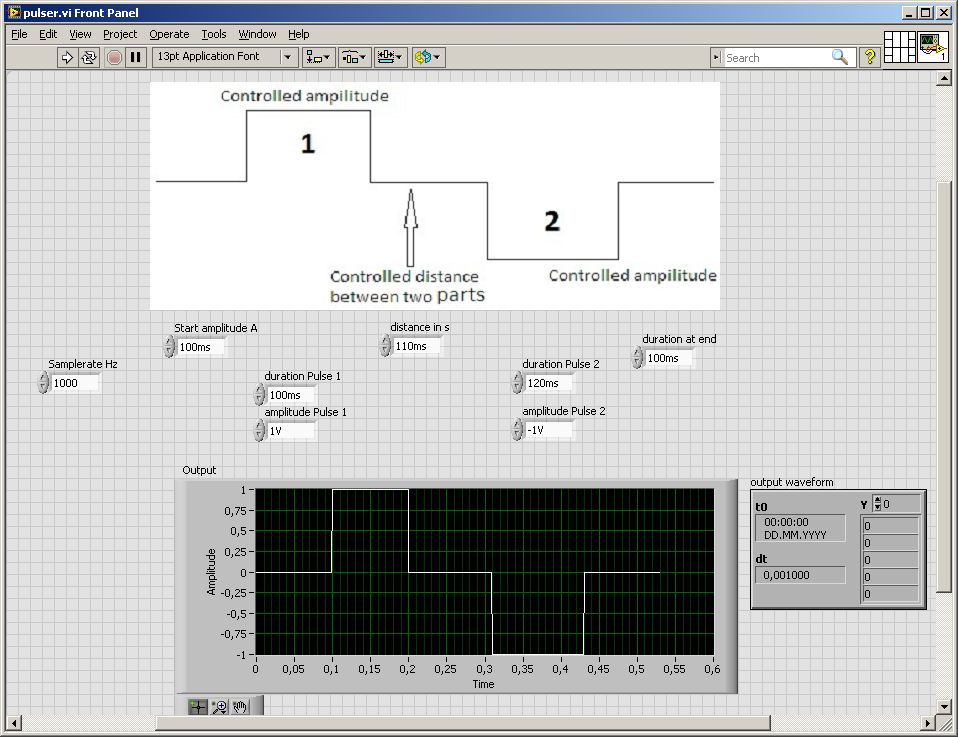
How can I design square wave which has a positive and negative values equal to the other and separated from each other by controlled time or distance, as indicated in the figure below. and enter this signal in a data acquisition.
At the time wherever you go for the beautiful diadram, you could have done the vi

Your DAQ would like a waveform (table of values and dt ak 1/sampling rate)
If you set the sampling rate you know the length of the array, create a matrix of zeros and set the values of the two amplitudes...
Because I don't want to connect other duties
here are some photosAnd it
does have a few drawbacksleaves to be desired in my solution, just think... rounding errors and what might happen if the tables are becoming more... -
Creating a view and replacing id with strings of text values
This can be a pretty basic question, but I'm a newbie so any advice is appreciated.
Here's my data:
create table user_attributes (id NUMBER, attr1 number, attr2 number, attr3 number, attr4 number, attr5 number); create table tag_values (tag_id number, tag varchar2(30)); insert into user_attributes (id, attr1, attr2, attr3, attr4, attr5) values (1, 101, 105, 102, null, null); insert into user_attributes (id, attr1, attr2, attr3, attr4, attr5) values (2, 105, null, 101, 105, null); insert into user_attributes (id, attr1, attr2, attr3, attr4, attr5) values (3, 102, null, null, 105, 103); insert into tag_values (tag_id, tag) values (101, 'blue'); insert into tag_values (tag_id, tag) values (102, 'red'); insert into tag_values (tag_id, tag) values (103, 'green'); insert into tag_values (tag_id, tag) values (104, 'orange'); insert into tag_values (tag_id, tag) values (105, 'black');
I want to create a view and the column id and the text of the tag instead of the ID.
That's what I use so far (just showing three columns of attribute for example):
SELECT a.id, b.tag ATTR1, c.tag ATTR2, d.tag ATTR3 FROM user_attributes a LEFT JOIN tag_values b ON a.attr1 = b.TAG_ID LEFT JOIN tag_values c ON a.attr2 = c.TAG_ID LEFT JOIN tag_values d ON a.attr3 = d.TAG_ID ORDER BY 1;
Result:
ID ATTR1 ATTR2 ATTR3 ---------- ------------------------------ ------------------------------ ------------------------------ 1 blue black red 2 black blue 3 red
That's what I want, but I have a lot of data and I want to just make sure that I do things properly. Is there a more efficient way to build this application?
Hello
It would be so much easier if you had only 1 column to search, not 5. We will therefore unpivot the table so there is only 1 column to search; then we can switch it to display as you wish:
WITH unpivoted_data AS
(
SELECT ua.id, ua.col, tv.tag
Of user_attributes
UNPIVOT (attr
FOR the collar (attr1, attr2, attr3, attr4, attr5)
) ua
JOIN tag_values tv ON tv.tag_id = ua.attr
)
SELECT *.
Of unpivoted_data
PIVOT (MIN (tag)
At THE neck ('ATTR1' AS attr1
'ATTR2' attr2 VALUE
'ATTR3' attr3 AS
'ATTR4' AS attr4
'ATTR5' AS attr5
)
)
ORDER BY id
;
Output:
ID ATTR1 ATTR2, ATTR3 ATTR4 ATTR5
--- ----- ----- ----- ----- -----
1 red blue black
2 black blue black
3 black red green
.
It is better to have the attributes in a dynamic no cross-form for this problem, it is perhaps better to have the attributes of the dynamic non cross-shape for most other uses, too. Consider to permanently store the attributes with only 1 attribute per line.
-
create a view, the default value of the columns are NULL
Windows XP / 10g 10.2.0.1.0
I have a table tab1 (test1, test2, test3)
And, I have to create a view as:
create or replace VW1 (test1, test2, viewtest1, viewtest2) as (select test1, test2, viewtest1, viewtest2 from tab1, double);
And need to viewtest1 and viewtest2 to be default null value column.
Thank you.You are looking for something like this?
create or replace VIEW VW1(test1, test2, viewtest1, viewtest2) as (select test1, test2, NULL, NULL from tab1); -
I have a column with two values, separated by a space, in each line. How do I create 2 new columns with the first value in one column and the second value in another column?
Add two new columns after than the original with space separated values column.

Select cell B1 and type (or copy and paste it here) the formula:
= IF (Len (a1) > 0, LEFT (A1, FIND ("", A1) −1), ' ')
shortcut for this is:
B1 = if (Len (a1) > 0, LEFT (A1, FIND ("", A1) −1), ' ')
C1 = if (Len (a1) > 0, Member SUBSTITUTE (A1, B1 & "", ""), "")
or
the formula of the C1 could also be:
= IF (Len (a1) > 0, RIGHT (A1, LEN (A1) −FIND ("", A1)), "")
Select cells B1 and C1, copy
Select cells B1 at the end of the C column, paste
-
How to create a view with columns from multiple lines
I posted this in the SQL/PSL forum, but I hope that experts from the database in this group can give me ideas also, the necessity is also BI reports.
I have a table, for example, project_milestones, that has these columns in order:
PROJ_ID, milestone_name, actual_end_date
with data:
PROJ_ID, milestone_name, actual_end_date
===== ================ ==============
1001, key approval, 2009-10-02
1001, final synopsis, 2009-10-07
1001, approved final Protocol, 2009-10-15
1001, FPFV, 2010-01-10
1001, LPFV, 2010-03-12
...
1002, key approval, 2008-12-02
1002, final synopsis, 2009-01-07
1002, approved final Protocol, 2009-01-12
1002, FPFV, 2009-03-30
1002, LPFV, 2009-10-04
...
There are about 10 steps in each project.
I need to create a view for dish these data at the project level, looks like this:
PROJ_ID, key_element_date, final_synopsis_date, final_protocol_approved_date, FPFV_date, LPFV_date, key_element_to_final_synopsis_days, final_synopsis_final_protocol_days...
How can I do this?
Thank youuser9175541 wrote:
I posted this in the SQL/PSL forum, but I hope that experts from the database in this group can give me ideas also, the necessity is also BI reports.I have a table, for example, project_milestones, that has these columns in order:
PROJ_ID, milestone_name, actual_end_date
with data:
PROJ_ID, milestone_name, actual_end_date
===== ================ ==============
1001, key approval, 2009-10-02
1001, final synopsis, 2009-10-07
1001, approved final Protocol, 2009-10-15
1001, FPFV, 2010-01-10
1001, LPFV, 2010-03-12
...
1002, key approval, 2008-12-02
1002, final synopsis, 2009-01-07
1002, approved final Protocol, 2009-01-12
1002, FPFV, 2009-03-30
1002, LPFV, 2009-10-04
...
There are about 10 steps in each project.
I need to create a view for dish these data at the project level, looks like this:PROJ_ID, key_element_date, final_synopsis_date, final_protocol_approved_date, FPFV_date, LPFV_date, key_element_to_final_synopsis_days, final_synopsis_final_protocol_days...
How can I do this?
Thank you
Create a PivotTable and put "milestone_name" in the columns, under the labels section.
Put 'actual_end_date' in the section of measures and to change the rule of the aggregation of 'Max '.
The rest of the attributes keep in the lines section. -
How to search for a particular text values separated by commas
Hello
I have a table for example. TB_Fruits.
In that I have a FruitsName (Varchar) column
In this column I store the string of values separated by commas.
Select FruitsName in the tb_fruits;
Result: orange, banana, Apple
Now the question is suppose that if I try inserting one of these fruits once again name, then it must not allow me to insert.
Suppose that now if I try to insert ('grapes, banana')
or
(Apple, grape")
the orange, banana, Apple may be in any position.
How to check if one of these names exist already or not in the fruitsname column?
I can't use INstr function here as or. because the position is not fixed chain even not.
Appreciate any help.Hmm, OK, the BASIC_LEXER in the documentation is specified is useful to "spaces separate languages". So not really a good suggestion from my side ;-)
Okay, so a few different choices, you can play with:
SQL> create table tb_fruits ( 2 fruitsname varchar2(60) 3 ) 4 / Table created. SQL> begin 2 insert into tb_fruits values ('BANANA,APPLE'); 3 insert into tb_fruits values ('YELLOW BANANA,ORANGE'); 4 insert into tb_fruits values ('GREEN APPLE,YELLOW ORANGE'); 5 insert into tb_fruits values ('APPLE,GREEN BANANA'); 6 commit; 7 end; 8 / PL/SQL procedure successfully completed.Option 1:
Make a outdated AS operator. It just won't be fast because it's more likely will be full table scan (or scan restricted index full).
SQL> select fruitsname 2 from tb_fruits 3 where ','||fruitsname||',' like '%,'||'APPLE'||',%' 4 / FRUITSNAME ------------------------------------------------------------ BANANA,APPLE APPLE,GREEN BANANA SQL> select fruitsname 2 from tb_fruits 3 where ','||fruitsname||',' like '%,'||'BANANA'||',%' 4 / FRUITSNAME ------------------------------------------------------------ BANANA,APPLE SQL> select fruitsname 2 from tb_fruits 3 where ','||fruitsname||',' like '%,'||'YELLOW BANANA'||',%' 4 / FRUITSNAME ------------------------------------------------------------ YELLOW BANANA,ORANGEOption 2:
Transform your data and replace the spaces with underscores. Which may or may not be a possibility for you. If your other data contains no underscores, you might fool your user interface using a view that replaces underscores with spaces when you select and a trigger before insert that replaces spaces with underscores to insert or update. Then, you can use the TEXT index.
SQL> create table tb_fruits2 as 2 select replace(fruitsname,' ','_') fruitsname 3 from tb_fruits 4 / Table created. SQL> begin 2 ctx_ddl.create_preference('mylex', 'BASIC_LEXER'); 3 ctx_ddl.set_attribute('mylex', 'printjoins', '_-'); 4 end; 5 / PL/SQL procedure successfully completed. SQL> create index fruitsname_idx on tb_fruits2 (fruitsname) 2 indextype is ctxsys.ctxcat 3 parameters ( 4 'stoplist ctxsys.empty_stoplist 5 LEXER mylex' 6 ) 7 / Index created. SQL> select fruitsname 2 from tb_fruits2 3 where catsearch(fruitsname,replace('YELLOW BANANA',' ','_'),null) > 0 4 / FRUITSNAME ------------------------------------------------------------ YELLOW_BANANA,ORANGE(I used CTXCAT rather then CONTEXT indexes to keep simple search syntax, avoid SYNCHRONIZATION problems and others. You can use CONTEXT or CTXCAT as desired.)
Option 3:
Transform your data in XML format instead of values separated by commas. Then create a XMLIndex.
SQL> create table tb_fruits3 as 2 select xmltype(''||replace(fruitsname,',',' ')||' YELLOW BANANA ORANGE (I used just 'l' for 'list of the words' and 'w' for 'word').
Option 4:
Create your own [url http://docs.oracle.com/cd/E11882_01/text.112/e24436/cdatadic.htm#i1008347] USER_LEXER instead of a variant of BASIC_LEXER. This would require allows you to create your own stored procedures for the index to be used, in which case you have complete control over what you set in the form of a token.
That's the different options I can think of right now ;-)
-
Value separated by commas in a table column to get each field separtely?
Hello
I have the table that a column has values separated by commas in it. This table is populated using SQL LOADER, which is staging table.
I need to retrieve the records of these values separated by commas.
format of. CSV file is as -
A separate file of pipes.
DHCP-1-1-1. WNLB-CMTS-01-1,WNLB-CMTS-02-2|
DHCP-1-1-2. WNLB-CMTS-03-3,WNLB-CMTS-04-4,WNLB-CMTS-05-5|
DHCP-1-1-3. WNLB-CMTS-01-1.
DHCP-1-1-4. WNLB-CMTS-05-8,WNLB-CMTS-05-6,WNLB-CMTS-05-0,WNLB-CMTS-03-3|
DHCP-1-1-5 | WNLB-CMTS-02-2,WNLB-CMTS-04-4,WNLB-CMTS-05-7|
CREATE TABLE link_data (dhcp_token VARCHAR2 (30), cmts_to_add VARCHAR2 (200), cmts_to_remove VARCHAR2 (200));
insert into link_data values ('dhcp-1-1-1','wnlb-cmts-01-1,wnlb-cmts-02-2',null);
insert into link_data values ('dhcp-1-1-2','wnlb-cmts-03-3,wnlb-cmts-04-4,wnlb-cmts-05-5',null);
insert into link_data values ('dhcp-1-1-3','wnlb-cmts-01-1',null);
insert into link_data values ('dhcp-1-1-4','wnlb-cmts-05-8,wnlb-cmts-05-6,wnlb-cmts-05-0,wnlb-cmts-03-3',null);
insert into link_data values ('dhcp-1-1-5','wnlb-cmts-02-2,wnlb-cmts-04-4,wnlb-cmts-05-7',null);
Here the cmts_to_add column has comma separted
I need values such as -.
> for wnlb-cmts-01-1,wnlb-cmts-02-2 > > wnlb-CMTS-01-1
> > wnlb-CMTS-02-2
> for wnlb-cmts-03-3,wnlb-cmts-04-4,wnlb-cmts-05-5 > > wnlb-CMTS-03-3
> > wnlb-CMTS-04-4
> > wnlb-CMTS-05-5
And so on...
I do this because it's the staging table and I load data into the main tables using this table.
This second field contain different values as the simple comma-delimited string.
I need to write a PLSQL block to insert into the main table after checking as if dhcp-1-1-1 and wnlb-CMTS-01-1 is present in the main table so not to introduce other insert a new record.
To meet this requirement, I need to get the distinct value of the cmts_to_add column to insert into DB.
the value will be inserted as dhcp-1-1-1_TO_wnlb-cmts-01-1 and dhcp-1-1-1_TO_wnlb-cmts-02-2 for the first row of the array of link_data.
The process will also be same for the rest of the lines.
I use the function substrt and instr for this problem, but its does not work.
declare
cursor c_link is select * from link_data.
l_rec_link link_data % rowtype;
l_dhcp varchar2 (30);
l_cmts varchar2 (20000);
l_cmts_1 varchar2 (32000);
Start
Open c_link;
loop
extract the c_link in l_rec_link;
l_cmts: = l_rec_link.cmts_to_add;
loop
l_cmts_1: = substr (l_cmts, 1, instr(l_cmts,',')-1);
dbms_output.put_line (l_cmts_1);
end loop;
dbms_output.put_line(l_dhcp||) e '|| l_cmts);
When the output c_link % notfound;
end loop;
exception
while others then
Dbms_output.put_line ('ERROR' |) SQLERRM);
end;
Its a peusdo code I write, but it also gives me the wrong answer it gives me error ORA-20000: ORU-10027: buffer overflow, limit of 20000 bytes
I am using-
Oracle Database 11 g Enterprise Edition Release 11.2.0.1.0 - 64 bit Production
Please tell me if my problem isn't clear!
Hello
little 'trick': Add a comma at the end of the chain... So it's easier to deal with the fact that there are zero, one, or N components...
CREATE TABLE link_data (dhcp_token VARCHAR2 (30), cmts_to_add VARCHAR2 (200), cmts_to_remove VARCHAR2 (200));
insert into link_data values ('dhcp-1-1-1','wnlb-cmts-01-1,wnlb-cmts-02-2',null);
insert into link_data values ('dhcp-1-1-2','wnlb-cmts-03-3,wnlb-cmts-04-4,wnlb-cmts-05-5',null);
insert into link_data values ('dhcp-1-1-3','wnlb-cmts-01-1',null);
insert into link_data values ('dhcp-1-1-4','wnlb-cmts-05-8,wnlb-cmts-05-6,wnlb-cmts-05-0,wnlb-cmts-03-3',null);
insert into link_data values ('dhcp-1-1-5','wnlb-cmts-02-2,wnlb-cmts-04-4,wnlb-cmts-05-7',null);
COMMIT;SET SERVEROUT ON
DECLARE
l_cmts VARCHAR2 (200 CHAR);
l_cmts_1 VARCHAR2 (200 CHAR);
BEGIN
FOR r IN (SELECT dhcp_token, cmts_to_add |) ',' cmts
OF link_data
)
LOOP
l_cmts: = r.cmts;
l_cmts_1: = SUBSTR (l_cmts, 1, INSTR (l_cmts, ",") - 1);
While l_cmts_1 IS NOT NULL
LOOP
DBMS_OUTPUT. Put_line (r.dhcp_token |) '|' || l_cmts_1);
l_cmts: = SUBSTR (l_cmts, INSTR (l_cmts, ",") + 1);
l_cmts_1: = SUBSTR (l_cmts, 1, INSTR (l_cmts, ",") - 1);
END LOOP;
END LOOP;
END;
/
DHCP-1-1-1. WNLB-CMTS-01-1
DHCP-1-1-1. WNLB-CMTS-02-2
DHCP-1-1-2. WNLB-CMTS-03-3
DHCP-1-1-2. WNLB-CMTS-04-4
DHCP-1-1-2. WNLB-CMTS-05-5
DHCP-1-1-3. WNLB-CMTS-01-1
DHCP-1-1-4. WNLB-CMTS-05-8
DHCP-1-1-4. WNLB-CMTS-05-6
DHCP-1-1-4. WNLB-CMTS-05-0
DHCP-1-1-4. WNLB-CMTS-03-3
DHCP-1-1-5 | WNLB-CMTS-02-2
DHCP-1-1-5 | WNLB-CMTS-04-4
DHCP-1-1-5 | WNLB-CMTS-05-7Best regards
Bruno Vroman.
-
Hello
I have 3 tables with the following structure.
create table a_os_lang_stls
(ID NUMBER )
SWB_NUMBER VARCHAR2 (30),
Pc_NUMBER VARCHAR2 (30),
PC_FLAG TANK (1),
INSTALLATION_ord NUMBER ,
SP_OR_LATER_VSN TANK (1),
Platform VARCHAR2 (4000),
OS VARCHAR2 (4000),
LANG VARCHAR2 (4000),
LOSS_OF_FUNC_REASON_TXT VARCHAR2 (4000),
CREATION_DATE DATE ,
MODIFIED_DATE DATE ,
CREATED_BY VARCHAR2 (100 BYTE),
MODIFIED_BY VARCHAR2 (100 BYTE)
);
Insert in a_os_lang_stls
values (1 'SWB1' 'SWB0','P',1 of ','11118,14,16,234,124' '12,26,17,24,35''34,28,45,67,123,95',USER, NULL, NULL, NULL, SYSDATE);
Insert in a_os_lang_stls
values (2,'SWB1' 'SWB2','P',2 of ','111,20,14,16,124''11,26,18,24,35''35,27,42,67,123,95', SYSDATE, NULL, NULL, NULL, USER);
insert into a_os_lang_stls
values (3,'SWB1','SWB3','C', 1,'','11118,14,16,234,124','12,26,17,24,35',' 35,27,42,67,123,95', SYSDATE, NULL, NULL, NULL, USER);
insert into a_os_lang_stls
values (4,'SWB1','SWB4','C', 2,'','111,20,14,16,124','11,26,18,24,35'' 34,28,45,67,123,95, SYSDATE, NULL, NULL, NULL, USER)
CREATE TABLE os_dtls
(
OSCODE VARCHAR2 (10 BYTE),
ID NUMBER DEFAULT NULL,
AG_OSCODE VARCHAR2 (250 BYTE),
);
insert into os_dtls
values ('HUX', 12, 'HP UNIX');
insert into os_dtls
values('SUX',26,'SOLARIS');
insert into os_dtls
values ('LUX', 17, 'LINUX');
CREATE TABLE lang_dtls
(
LANGCD TANK (2 BYTE),
LANGNAME VARCHAR2 (255 BYTE),
ID NUMBER DEFAULT 1 NOT NULL
);
insert into lang_dtls
values ('ENG', 'ENGLISH UK', 35);
insert into lang_dtls
values ('UEG', 'USA ENGLISH', 27);
insert into lang_dtls
values('FR','FRENCH',45);
Information on the database:
Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - 64 bit Production
PL/SQL version 11.1.0.7.0 - Production
Production base 11.1.0.7.0
AMT for Linux: Version 11.1.0.7.0 - Production
NLSRTL Version 11.1.0.7.0 - Production
I have to write a procedure like this
procedure os_lang_info (P_SB_NO IN varchar2, p_pcur sys_refcursor, p_ccur, sys_refcursor );
The requirement is to get the details for a given swb_no where pc_flag is P or C pass like 2 different sys_refcursor. But the value of column of bones and lang I need to map to the os_dtls and lang_dtls tables to get the ag_oscode and langname respectively for the corresponding id then through sys_refcursor.
So sys_refcursor structure will be
Open the p_pcur for
Select * from a_os_lang_stls
where swb_number = p_sb_no
and PC_FLAG = 'P' ;
so the output will resemble the following
1 , « SWB1 » , « SWB0 » , 'P' , 1 , 'S' , '11118,14,16,234,124' , «HP UNIX,SOLARIS,LINUX,... « , "UK ENGLISH,US ENGLISH,FRENCH,...» ', NULL, NULL, NULL, USER, SYSDATE
I must get the id separated by commas of column bone and lang and map to the corresponding table to get the names separated by commas of the bones and langs and pass it as a component of sys_refcursor.
Open the p_ccur for
Select * from a_os_lang_stls
where swb_number = p_sb_no
and PC_FLAG = 'C';
Could someone please help me how to convert the value separated by commas in a comma separated value new map to another table and pass it as part of the sys_refcursor.
Thanks in advance.
Kind regards
SB2011
Hello. Here are the queries for the two sys_refcursors.
(1) FOR THE FLAG = 'P '.
SELECT T1.ID,
T1. SWB_NUMBER,
T1. PC_NUMBER,
T1. PC_FLAG,
T1. INSTALLATION_ORD,
T1. SP_OR_LATER_VSN,
T1. PLATFORM,
T1. OS_CODE,
T2. LANG_CODE
DE)
SELECT T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
RTRIM (XMLAGG (XMLELEMENT(A,AG_OSCODE,',')). Extract ('//Text ()'), ',') OS_CODE
FROM (SELECT ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
(COLUMN_VALUE). GETNUMBERVAL() os_id
Of a_os_lang_stls t, xmltable (os) t1) T1.
OS_dtls T2
WHERE T2.ID = T1. OS_ID
GROUP OF T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
T1 PLATFORM),
(SELECT T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
RTRIM (XMLAGG (XMLELEMENT(A,LANGNAME,',')). Extract ('//Text ()'), ',') LANG_CODE
FROM (SELECT ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
(COLUMN_VALUE). GETNUMBERVAL() lang_id
Of a_os_lang_stls t, xmltable (lang) t1) T1.
lang_dtls T2
WHERE T2.ID = T1.lang_id
GROUP OF T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
T2 PLATFORM)
WHERE T1.ID = T2.ID
AND T1. SWB_NUMBER = T2. SWB_NUMBER
AND T1. PC_NUMBER = T2. PC_NUMBER
AND T1. INSTALLATION_ORD = T2. INSTALLATION_ORD
AND T1. PLATFORM = T2. PLATFORM
AND T1. PC_FLAG = "P";
(2) PC_FLAG FOR = 'C '.
SELECT T1.ID,
T1. SWB_NUMBER,
T1. PC_NUMBER,
T1. PC_FLAG,
T1. INSTALLATION_ORD,
T1. SP_OR_LATER_VSN,
T1. PLATFORM,
T1. OS_CODE,
T2. LANG_CODE
DE)
SELECT T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
RTRIM (XMLAGG (XMLELEMENT(A,AG_OSCODE,',')). Extract ('//Text ()'), ',') OS_CODE
FROM (SELECT ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
(COLUMN_VALUE). GETNUMBERVAL() os_id
Of a_os_lang_stls t, xmltable (os) t1) T1.
OS_dtls T2
WHERE T2.ID = T1. OS_ID
GROUP OF T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
T1 PLATFORM),
(SELECT T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
RTRIM (XMLAGG (XMLELEMENT(A,LANGNAME,',')). Extract ('//Text ()'), ',') LANG_CODE
FROM (SELECT ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
PLATFORM,
(COLUMN_VALUE). GETNUMBERVAL() lang_id
Of a_os_lang_stls t, xmltable (lang) t1) T1.
lang_dtls T2
WHERE T2.ID = T1.lang_id
GROUP OF T1.ID,
SWB_NUMBER,
PC_NUMBER,
PC_FLAG,
INSTALLATION_ORD,
SP_OR_LATER_VSN,
T2 PLATFORM)
WHERE T1.ID = T2.ID
AND T1. SWB_NUMBER = T2. SWB_NUMBER
AND T1. PC_NUMBER = T2. PC_NUMBER
AND T1. INSTALLATION_ORD = T2. INSTALLATION_ORD
AND T1. PLATFORM = T2. PLATFORM
AND T1. PC_FLAG = 'C ';
-
Creating a view using causes error ORA-00600
Hello ladies and gentlemen,
I tried to deploy a recursive query, as a point of view in Oracle XE and Standard Edition, nor a lot of success.
The query is in this issue here: http://stackoverflow.com/questions/17358109/how-to-retrieve-all-recursive-children-of-parent-row-in-oracle-sq
with recursion_view(base, parent_id, child_id, qty) as ( -- first step, get rows to start with select parent_id base, parent_id, child_id, qty from md_boms union all -- subsequent steps select -- retain base value from previous level previous_level.base, -- get information from current level current_level.parent_id, current_level.child_id, -- accumulate sum (previous_level.qty + current_level.qty) as qty from recursion_view previous_level, md_boms current_level where current_level.parent_id = previous_level.child_id ) select base, parent_id, child_id, qty from recursion_view order by base, parent_id, child_id
The query itself works and returns the results. However, when I try to create a view with this query, I get errors.
I posted two screenshots: http://www.williverstravels.com/JDev/Forums/StackOverflow/17358109/ViewError.jpg and http://www.williverstravels.com/JDev/Forums/StackOverflow/17358109/InternalError.jpg one with the! and * is when I am using JDeveloper 11g, using the navigation database, right-click on the view and select "New View". I get the error when I click on OK. I can indeed create the view through a sql script, but when I try to view the data, I get the error ORA_00600.
I tried it work on my machine the two premises for XE (version 11.2.0.2.0) and 11g Standard Edition (11.2.0.2.v6) via Amazon Web Services. The result is the same.
Does anyone know how to get around this problem?
Not 5 minutes after I have this post, I decide not to use the graphical editor of JDev and simply write
SELECT * FROM BOMS_VIEW;
And it works like a charm. I can not just use data tab to display records in the editor. Wish I'd known that there is 5 hours.
-
Hi all
11.2.0.1
I have tables EMP and DEP, and their structures are the ff:
DEP (depno, depname)
EMP (emp_id, depno)
I want to create a view EMP_VIEW (emp_id, status).
The status value is "Active" (if depno exists in DEP) or 'Inactive' (if depno is null or not depno corresponding to the DEP).
How to create this view?
Thank you very much
zxyCheck this box
SQL> insert into emp(empno,ename) values (1234,'test'); 1 row created. SQL> commit; Commit complete. SQL> create or replace view emp_view as select e.empno, nvl2( d.deptno,'Active','Inactive') Status from emp e left outer join dept d on e.deptno=d.deptno; View created. SQL> select * from emp_view; EMPNO STATUS ---------- -------- 7369 Active 7499 Active 7521 Active 7566 Active 7654 Active 7698 Active 7782 Active 7788 Active 7839 Active 7844 Active 7876 Active 7900 Active 7902 Active 7934 Active 1234 Inactive 15 rows selected. -
Associate data to create a view.
I am currently using a database of Oracle 10.2.0.4.0. I work for the Department of public safety and I am trying to create an Oracle Forms Application that will be used to track information of the mandate. I need to create a view that I can use in my form that will allow me to the warrants list who are associated with each other. In the forms I create these associations in a table by using primary keys for these records.
I created a few fictitious tables with data that you can use to help me create the SQL I can use in the creation of the view, that I need, I hope.
Once the tables are created, the table ORDER_INFO contains detailed information (in real life, it comes to the information related to a mandate). The ASSOCIATE_ORDER table contains the relationships between the records in the ORDER_INFO table. The ASSOCIATE_ORDER table is the one I want to use to create a view that I use in my Application Forms to list all of the warrants that are associated with each other.CREATE TABLE order_info (wp_id number(12) primary key, info varchar2(10), order_no number(12) not null, order_name varchar2(30) not null); insert into order_info (wp_id, info, order_no, order_name) values (1, 'AXE', 123456, 'DOE, JOHN P'); insert into order_info (wp_id, info, order_no, order_name) values (2, null, 245645, 'DOE, JOHN P'); insert into order_info (wp_id, info, order_no, order_name) values (3, 'SHOVEL', 354654, 'DOE, JOHN P'); insert into order_info (wp_id, info, order_no, order_name) values (4, 'PAIL', 432110, 'DOE, JONATHAN'); insert into order_info (wp_id, info, order_no, order_name) values (5, null, 514654, 'DOE, JOHN'); insert into order_info (wp_id, info, order_no, order_name) values (6, null, 687980, 'DOE, JONATHAN'); commit; CREATE TABLE associate_order (wp_id number(12) not null, associated_wp_id number(12) not null, constraint assoc_wp_ip_fk foreign key (associated_wp_id) references order_info(wp_id)); insert into associate_order (wp_id, associated_wp_id) values (2, 1); insert into associate_order (wp_id, associated_wp_id) values (3, 1); insert into associate_order (wp_id, associated_wp_id) values (5, 3); insert into associate_order (wp_id, associated_wp_id) values (6, 4); commit;
If you look at the data in the ASSOCIATE_ORDER table:
WP_ID 2 is associated with WP_ID 1WP_ID ASSOCIATED_WP_ID ----- ---------------- 2 1 3 1 5 3 6 4
WP_ID 3 is associated with WP_ID 1
WP_ID 5 is associated with WP_ID 3
6 WP_ID is associated with 4 WP_ID
I want to be able to do in the view that I have create is something like:
And he have all the primary keys for the warrants (orders in this case) come back to me:SELECT associated_wp_id FROM ORDER_VIEW WHERE WP_ID = 3;
The WP_ID of 1 is not included in the ASSOCIATE_ORDER table, because it is not associated with a previous mandate (order in this case), but because it is associated with WP_ID 2 and 3 I think.ASSOCIATED_WP_ID ---------------- 1 2 3 5
Here are all the commands associated together based on the data that is in the table. There may be 0 to many of these records in the ASSOCIATE_ORDER table, but if they reference a primary key (WP_ID) so I want to include in the view.
I really hope that makes sense. I tried to play a little with analytics, but I'm not even close to the selection of any of the data that I want, so I can't yet show you what I've tried because it probably doesn't even have sense.
Thanks in advance - mike
In order to clean your database if you filled with the scripts above, you can do the following:drop table associate_order; drop table order_info;Hello
I know right what you want the view to look like.
Given the example of data you posted, that's what you want to the content of the view?WP_ID INFO ORDER_NO ORDER_NAME WP_ID_GRP ----- ---------- ---------- --------------- ---------- 1 AXE 123456 DOE, JOHN P 1 2 245645 DOE, JOHN P 1 3 SHOVEL 354654 DOE, JOHN P 1 4 PAIL 432110 DOE, JONATHAN 4 5 514654 DOE, JOHN 1 6 687980 DOE, JONATHAN 4? You will notice that it is just order_info, with an additional column, wp_id_grp, added. Wp_id_grp is the lowest related wp_id. For example, wp_ids 1, 2, 3, and 5 are all related, so they all have wp_id_grp = 1.
Here's a way to do it:
CREATE OR REPLACE VIEW order_info_grp AS WITH got_pairs AS ( SELECT wp_id AS x_id , associated_wp_id AS y_id FROM associate_order UNION SELECT associated_wp_id AS x_id , wp_id AS y_id FROM associate_order ) , got_relatives AS ( SELECT CONNECT_BY_ROOT x_id AS wp_id , y_id FROM got_pairs CONNECT BY NOCYCLE y_id = PRIOR x_id ) , got_wp_id_grp AS ( SELECT wp_id , MIN (y_id) AS wp_id_grp FROM got_relatives GROUP BY wp_id ) SELECT o.* , g.wp_id_grp FROM order_info o JOIN got_wp_id_grp g ON o.wp_id = g.wp_id ;If you want a view which only has the columns wp_id and wp_id_grp, then everything just omit the main request; got_wp_id_grp, it's just what you want.
I guess that the associate_order relationship is reflexive. In other words, instead of:
insert into associate_order (wp_id, associated_wp_id) values (2, 1);you have it, could just as well, says:
insert into associate_order (wp_id, associated_wp_id) values (1, 2);In other words, all that matters is that 1 and 2 are linked. What number goes in which column is not relevant.
In table assoiciate_order, why is there a foreign key on associated_wp_id constraint, but not on wp_id?
CONNECT BY is never terribly effective, and NOCYCLE does only make it worse. Depending on your data, in particular how different wp_ids can be in a related group, this may not be practical. You might consider adding a column wp_id_grp in the associate_order table, rather than owning a view and containing a PL/SQL (which would be faster) procedure re - fill this column when associate_order is changed.
Published by: Frank Kulash on April 17, 2013 18:33
MLBrown wrote:
I think I left mouth stumped the Panel...Be patient! It's true that the median time for a first response on this forum is less than 10 minutes, but it's because the first response often only pointed out that we need more information. When you provide all the sample data, and a good explanation of the problem, as you did, then people can begin to solve the problem instead of complaining, complaining is so much faster than problems.
-
How to store the values separated by commas
Hi all
I have a table named discount, with discount_id (number data type) as one of the columns.
The user gives an entry as the value separated by commas, (ex: '123,27890,3543')
I use built-in proc that separates the values separated by commas.
Result set is stored in a table.DECLARE l_input VARCHAR2 (4000) := '123,27890,3543'; l_count BINARY_INTEGER; l_array DBMS_UTILITY.lname_array; BEGIN DBMS_UTILITY.comma_to_table ( list => REGEXP_REPLACE (l_input, '(^|,)', '\1x'), tablen => l_count, tab => l_array); DBMS_OUTPUT.put_line (l_count); FOR i IN 1 .. l_count LOOP DBMS_OUTPUT.put_line ( 'Element ' || TO_CHAR (i) || ' of array contains: ' || SUBSTR (l_array (i), 2)); END LOOP; END; Result: 3 Element 1 of array contains: 123 Element 2 of array contains: 27890 Element 3 of array contains: 3543
I would like to do a select on the table of discounts
Select * discount where discount_id (123, 27890 3543).
I am looking for options,
I need to create a new physical table as
Create table new_table (identification number) and bulk insert in this table.
Select * discount where discount_id in (select distinct id of new_table).
or
Is there a better way?
THX
Rod.Hello, SamFisher.
May be the recursive subquery factoring help you?WITH test(f1, n) AS (select '12, 15, 235', 1 from dual UNION all select f1, n + 1 from test where n < regexp_count('12, 15, 235', ',') + 1) SELECT regexp_substr(f1, '[^, ]+', 1, n) f FROM test -
Create the view using SQL DEVELOPER
I'm new to this forum :)
11 GR 2, WIN2008 R2
SQL Developer Version 3.2.09
I am creating the data below view (view existing)
Table: Dovmarker
I try to describe the table and my goal :),MARKERBOREHOLE UWI MARKERSURFACE Z WELLXXX 65372643AAAA Cw -982,985619574516 WELLXXX 65372643AAAA Cn -1891,47401803955 WELLXXX 65372643AAAA J -674,989528816517 WELLXXX 65372643AAAA K3 20,00165000429 WELLXXX 65372643AAAA Tr 125,000317308153 WELLXXX 65372643AAAA K1 -658,989731894024 WELLXXX 65372643AAAA Q 149,999999999549 WELLYYY 56618334AAAA Jkm -715,071442105268 WELLYYY 56618334AAAA K3 36,9013966413975 WELLYYY 56618334AAAA J2 -976,056079257549 WELLYYY 56618334AAAA Tr 106,900507694299
each line describes wells, uwi(uniqe identifier), z (deppth), high (surface marker)
I try to merge all lines with the same MARKERBOREHOLE/UWI and MARKERSURFACE contact coresponding Z (ascending) as MARKERSURFACE = Z.
If it is posibble to reduce the number of decimals to 2.
My idea to solve the problem:
example: ' | ' is the delimiter
or better (not enough knowledge ;))WELLXXX Q=149,999999999549 | Tr=125,000317308153 | K3=20,00165000429 | K1=-658,989731894024 | J =-674,989528816517 | Cw=-982,985619574516 | Cn=-1891,47401803955 WELLYYY Tr=106,900507694299 | K3=36,9013966413975 | Jkm=-715,071442105268 | J2=-976,056079257549
Number of markersurface is different for each wellWELLXXX Q=149,999999999549 Tr=125,000317308153 K3=20,00165000429 K1=-658,989731894024 J =-674,989528816517 Cw=-982,985619574516 Cn=-1891,47401803955 WELLYYY Tr=106,900507694299 K3=36,9013966413975 Jkm=-715,071442105268 J2=-976,056079257549
I try to do it by the listagg function, but I have failled
result:select markerborehole, listagg(z, ' | ') within group (order by z) as new1 from dovmarker group by markerborehole;
When I tried to create new view in sql developer I occurred error;WELLZZZ -2575,95869465411 | -1891,47401803955 | -982,985619574516 | -674,989528816517 | -658,989731894024 | WELLRRR -2376,96975480605 | -2376,96975480605 | -2308,97180590009 | -2308,97180590009 | -2206,47428534641 | -2206,47428534641 | -2163,97522524171
Can you help me with this?Error(s) parsing SQL: unexpected token near *!* in the following: select markerborehole, listagg(z, ' | ') within *!*group (order by z) as new1 unexpected token near *!* in the following: select markerborehole, listagg(z, ' | ') within group *!*(order by z) as new1 missing expression near *!* in the following: select markerborehole, listagg(z, ' | ') within group (*!*order by z) as new1
Concerning
Jaroslaw961148 wrote:
I missed xWell Yes, my apologies, I has not changed all that.
It's a simple way to format the Z value to 2 decimal places?
Yes. It depends on if you want to use rounded, floor, ceiling, truncate or if you like a string always have 2 decimal places etc.
Make your choice and customize according to your needs...SQL> ed Wrote file afiedt.buf 1 with t as (select 'WELLXXX' as MARKERBOREHOLE, '65372643AAAA' as UWI, 'Cw' as MARKERSURFACE, -982.985619574516 as Z from dual union all 2 select 'WELLXXX', '65372643AAAA', 'Cn', -1891.47401803955 from dual union all 3 select 'WELLXXX', '65372643AAAA', 'J', -674.989528816517 from dual union all 4 select 'WELLXXX', '65372643AAAA', 'K3', 20.00165000429 from dual union all 5 select 'WELLXXX', '65372643AAAA', 'Tr', 125.000317308153 from dual union all 6 select 'WELLXXX', '65372643AAAA', 'K1', -658.989731894024 from dual union all 7 select 'WELLXXX', '65372643AAAA', 'Q', 149.999999999549 from dual union all 8 select 'WELLYYY', '56618334AAAA', 'Jkm', -715.071442105268 from dual union all 9 select 'WELLYYY', '56618334AAAA', 'K3', 36.9013966413975 from dual union all 10 select 'WELLYYY', '56618334AAAA', 'J2', -976.056079257549 from dual union all 11 select 'WELLYYY', '56618334AAAA', 'Tr', 106.900507694299 from dual) 12 -- 13 -- END OF TEST DATA - IGNORE ABOVE WITH CLAUSE 14 -- 15 select z 16 ,round(z,2) as round_z_2 17 ,floor(z*100)/100 as floor_z_2 18 ,ceil(z*100)/100 as ceil_z_2 19 ,trunc(z,2) as trunc_z_2 20 ,to_char(round(z,2),'fm9990.00') as string_z_2 21* from t SQL> / Z ROUND_Z_2 FLOOR_Z_2 CEIL_Z_2 TRUNC_Z_2 STRING_Z ------------------- ---------- ---------- ---------- ---------- -------- -982.9856195745160 -982.99 -982.99 -982.98 -982.98 -982.99 -1891.4740180395500 -1891.47 -1891.48 -1891.47 -1891.47 -1891.47 -674.9895288165170 -674.99 -674.99 -674.98 -674.98 -674.99 20.0016500042900 20 20 20.01 20 20.00 125.0003173081530 125 125 125.01 125 125.00 -658.9897318940240 -658.99 -658.99 -658.98 -658.98 -658.99 149.9999999995490 150 149.99 150 149.99 150.00 -715.0714421052680 -715.07 -715.08 -715.07 -715.07 -715.07 36.9013966413975 36.9 36.9 36.91 36.9 36.90 -976.0560792575490 -976.06 -976.06 -976.05 -976.05 -976.06 106.9005076942990 106.9 106.9 106.91 106.9 106.90 11 rows selected.with above code I try to create a new view in SQL Developer, but I have error:
Error(s) parsing SQL: Unexpected token near *!* in the following: select markerborehole, listagg(z,chr(10)) within *!*group(order by rn) as z Unexpected token near *!* in the following: select markerborehole, listagg(z,chr(10)) within group*!*(order by rn) as z Missing expression near *!* in the following: select markerborehole, listagg(z,chr(10)) within group(*!*order by rn) as zWhat are all the {noformat}! * * {noformat} in the code? Delete them.
Edit: or maybe your version of SQL Developer is not up-to-date and does not know the new LISTAGG function in 11g?
Published by: BluShadow on 26-Sep-2012 09:41

{kind=link}
{kind=link}
Maybe you are looking for
-
Qosmio G30-137 (PQG30E) - how to use 2 monitors
Hello I would use this monitors 2 http://www.Preissuchmaschine.de/preisvergleich/Produkt.cgi?Suche=HP+2228&Image1.x=0&Image1.y=0 monitor inputs: DVI, HDMI, VGAthe laptop output: connector VGA and the D4 or D5 (d-terminal) now my questions: Is it poss
-
HP Photosmart B209a - lost wireless connection
I use the printer above and it worked perfectly on a BT Home Hub 2-57GM. I recently added a Time Capsule from Apple in the network and now use it as my default around the home wifi even if it is connected by a cable to the BT Home Hub. I operate two
-
restore data on lexar memory stick (I removed dangerously, it now reads empty - AGGG)
new lexar folding MemoryStick I removed w/out 'Remove' as it was in a computer that had been dead, and I couldn't get it to power upward. When I inserted in another computer Lexar now reads "empty" which means I lost? all the data? Someone knows how
-
Custom in the ALX files properties
Hello in fact I deploy my application OTA. I added some special parameters in the JAD file to configure the application before it is downloaded to the device. Using the CodeModuleGroupManager I can then read properties and use them in my application.
-
Cannot remove content on Oracle Content Marketing (collection)
HelloI have created a few articles and some material on Compendium projects. However, when I go to the products tab, then click on "Manage content", then browse and click on delete once I have selected the expected content, I get https://app.compendi