Date string between Dates
Hello. I came up with a method that seems to work fine. Just thought it might be a more effective way to determine if a date string (must be from a string) is located between 2 other dates (of string).
TimeZone clientZone = TimeZone.getDefault();
String dateToCompare="2012-10-03";
String dateBegin="2012-10-01";
String dateEnd="2012-10-07";
Date date1= new Date(HttpDateParser.parse(dateToCompare));
Date date2= new Date(HttpDateParser.parse(dateBegin));
Date date3= new Date(HttpDateParser.parse(dateEnd));
Calendar calToCompare = Calendar.getInstance(clientZone);
Calendar calBegin = Calendar.getInstance(clientZone);
Calendar calEnd = Calendar.getInstance(clientZone);
calToCompare.setTime(date1);
calBegin.setTime(date2);
calEnd.setTime(date3);
if(calToCompare.after(calBegin) && calToCompare.before(calEnd)) {
Dialog.alert("date is between");
}
else {
Dialog.alert("date is NOT between");
}
Is there a better way to do this? Thank you.
Date date1 = new Date (HttpDateParser.parse (dateToCompare));
Date2 = new Date (HttpDateParser.parse (dateBegin));
Date date3 = new Date (HttpDateParser.parse (dateEnd));
long compareDateLong = date1.getTime ();
long beginDateLong = date2.getTime ();
long endTimeLong = date3.getTime ();
If (beginDateLong < comparedatelong="" )="" &&="" (="" endtimelong=""> compareDateLong) {}
Dialog.Alert ("date is between");
}
else {}
Dialog.Alert ("date is NOT between the two");
}
Tags: BlackBerry Developers
Similar Questions
-
Regular expression help please. (extraction of a subset of the string between two markers)
I haven't used regular expressions before, and I can't find a regular expression to extract a subset of the string between two markers.
The chain;
Stuff of header I want
Stuff of header I want
Stuff of header I wantStuff of header I want
Stuff of header I want
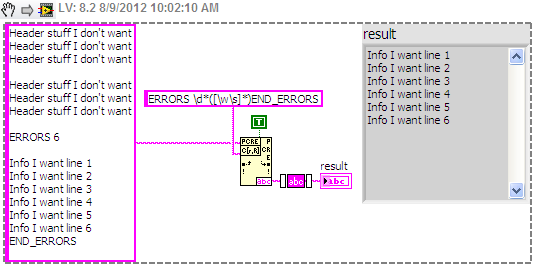
Stuff of header I want6 ERRORS
Info I want to line 1
Info I want line 2
Info I want line 3
Info I want to line 4
Info I want to line 5
Info I want line 6
END_ERRORSFrom the string above (it is read from a text file), I try to extract the subset of string between ERRORS 6 and END_ERRORS. The number of errors (6 in this case) can be any number from 1 to 32, and the number of lines I want to extract will correspond with this number. I can provide this number of a caller VI if necessary.
My current solution, which works, but is not very elegant;
(1) using Match Regular Expression for the return of the string after you have synchronized the 6 ERRORS
(2) uses the Regular Expression matches to return all characters before game END_ERRORS of the string returned by (1)
Is there a way this can be accomplished using 1 Regular Expression Match? If so someone could suggest how, as well as an explanation of the work of the given regular expression.
Thank you very much
Alan
I used a character class to catch any word or whitespace characters. This put inside parentheses a substring matching the criteria that you can get by developing the node for regular expression matching. The \d matches the numbers and the two * s repetition of the previous term. So, \d* will find the '6', as well as "123456".
-
Can anyone tell how to insert a string between the two another string...?
Can anyone tell how to insert a string between the two another string...?
For example: String1 = 'ABC '.
String2 = "XY".
I want that the chain of output like "AXYBC".If you have the Position where you want to place your chain, this might work:
SQL> r 1 declare 2 vStr1 varchar2(20) := '123456789'; 3 vStr2 varchar2(20) := 'aa'; 4 nInsertPos number := 3; 5 vResult varchar2(20); 6 begin 7 vResult := substr(vStr1, 0, nInsertPos) || vStr2 || substr(vStr1, nInsertPos+1); 8 dbms_output.put_line(vResult); 9* end; 123aa456789If you want to insert it after a special character, you can search for the position of your character with the help of instr
concerning
-
Avoid writing empty lines or remove the empty string between data lines
Hello
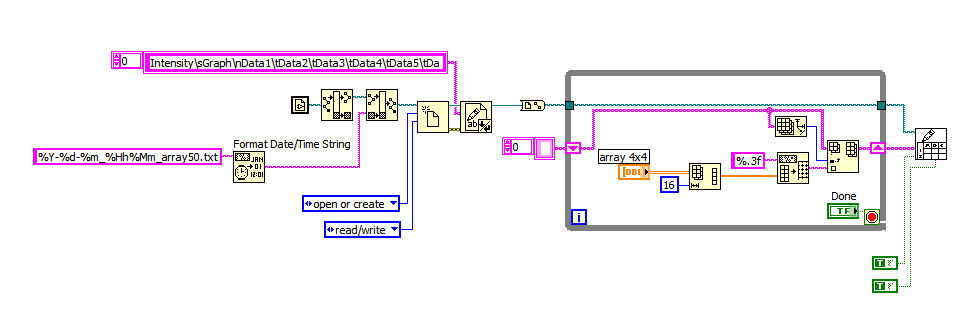
I have this problem... I write as a 4 x 4 witch table comes from a graph of intensity in a file. But when I write, regardless of the method that I use out it somehow unusable when I try to read more later.
Right now I got change for a 1 x 16 table witch I later convert back to 4 x 4 again shown in the graph of the intensity.
The problem is that I have empty lines between the data I want to remove to display correctly.
Maybe to be clear in my explanation I will post screenshots of how I write and how I like to read...
Can someone help me?
Thank you!
Antonio
Why do you use a loop to create a string to write to the file? In LabVIEW 8.x writing on a spreadsheet file is polymorphic, so you can select the instance of 'Double' and simply connect your table 2D directly to it, without a loop or anything like that. On playback, even select the instance 'Double' for your return values exactly as you wrote them.
-
IN the string I want to take all values between {and}.
This is the string.
({Location1} # tie # 12-< and > {Item1} # top # (8) < and > {Item2} # # (40) < and > {DOCDATE} "# # 10 January 2015" AND 10 January 2017 ' < and > {amount} # tie # 1).
Vinodh
Here's a way to do what you asked (which may or may not be what you need), using REGEXP_REPLACE to remove everything that is not between two brands of {}:
with t as
(select ' ({Location1} # equal (12) < and=""> {Item1} # more than # (8) < and=""> {Item2} # # (40) < and=""> {DOCDATE} # between # "January 10, 2015" AND 'January 10, 2017' < and=""> {amount} # equal # 1)' txt)
the double)
-end of test data-
Select regexp_replace (regexp_replace (regexp_replace(txt,'}[^}]*{','',1,0),'^ [^ {}] * {', ", 1,0}) {,'}. * $',", 1.0)
t
-
Get the string between two operators <>
Hello
I have a string that looks like this "text here < emplid > more text here '." Now, I want to choose the data between the < and >. These data is still a number. I tried the following query, but it does not give good results.
This will result in the number, including the < and > (which I'm not) and some characters more. I also need the rest of the chain to be available to insert in another field.select SUBSTRING(NAME,CHARINDEX('<',NAME),CHARINDEX('>',[NAME])) as col01 from databasename
Published by: wijnandgritter on 23 January 2012 0:03Hello
You should be able to
update tablename set field = regexp_replace(fieldname,'^.*<(\d+)>.*$','\1 this is an employee') where fieldname = '123'or something similar...
HtH
Johan -
Extract the given string a String between double quotes
Hey guys,.
I am doing a project open source to help lovers of ADS - B to store data on Oracle Database XE (11.2.0.2)
I need to retrieve a string, but I didn't know how, please can someone help me.
Chain: [{'id': 'PR - GIG', 'label': "PR-CONCERT - E47EB2 - BS Airlines - Boeing 737 - 73 S (29077)", "value": 'PR - GIG' "}]
KeyString: "label".
Output: ' PR-CONCERT - E47EB2 - BS Airlines - Boeing 737 - 73 S (29077) '
And if possible put this string in multiple strings
String1: PR-GIG
Channel 2: E47EB2
String3: BS Airlines
String4: Boeing 737 - 73 S
String5: 29077
Thanks for the help.
Select x.*
t,.
XMLTable)
"ora: tokenize($s,"-").
from regexp_substr (str,'"label": "([^"]+) "', 1,1,null, 1) as"s ".
) x
/
COLUMN_VALUE
-------------------------
PR - GIG
E47EB2
BS Airlines
Boeing 737 - 73S (29077)SQL >
SY.
-
Hello
I'm curious to know what I see using TestStand, LabWindows/2013 2013 with regard to initial in TestStand string values when you perform the steps in the process or an external instance of LabWindows/CVI.
I have a step (CVI) string value that is used to check an array of characters stored in an EEPROM to test. I pass on the Step.Result.String in the CVI by reference. I then read the table charater of the EEPROM in the chain (Step.Result.String). The string is then compared against the limit as specified in the test step breast.
When I run this test step to perform the steps in the process selected in the popup Configuration of the adapter of LabWindows/CVI, it seems that the memory allocated for the string is filled with null characters. Which is what I expected.
When I run this test step to execute the steps in an external instance of LabWindows/CVI iselected of the Configuration of the adapter of LabWindows/CVI popup, it seems that the memory allocated for the string is filled with something else. That is not what I expected. For example what I see in the memory, it's the first characher is one byte NULL but the remaining bytes are some other values, as shown below:
F0 00 AD BA 0D F0 AD BA 0D F0 AD BA 0D AD BA 0D AD BA 0D BA 0D AD F0 F0 F0
F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD 0D AD BA 0D AD BA 0D F0 F0 F0 BA...In my code I make sure to write a null character in the following location table charater I just write in the chain so I have no problem with the test is working properly. I have remove the writing from my code null character and was able to verity that the test passes when executing the steps in the process and fails during execution of the steps in an external instance of LabWindows/CVI.
The returned string contains what I wrote for her, and then the rest of the string is filled with the values that are in the memory allocated for the string.
Here's my Question: is this the expected behavior for the original string values in TestStand between both types of stage performances?
Thank you
Chris Young
In general teststand not Initializes the unused portion of the string buffer, so it is expected that the values of the memory after character no endpoint will be different, or even to each call. If you happen to be get zeros after the null terminator which was probably due to random character (i.e. the memory allocated just arrived already having zeros in there) or perhaps a debug setting you use perhaps in the Visual C runtime (if you are debugging the process in visual studio or modify visual C runtime heap parameter). TestStand is not initializaing memory after the null terminator character in both cases (I checked the code).
-Doug
-
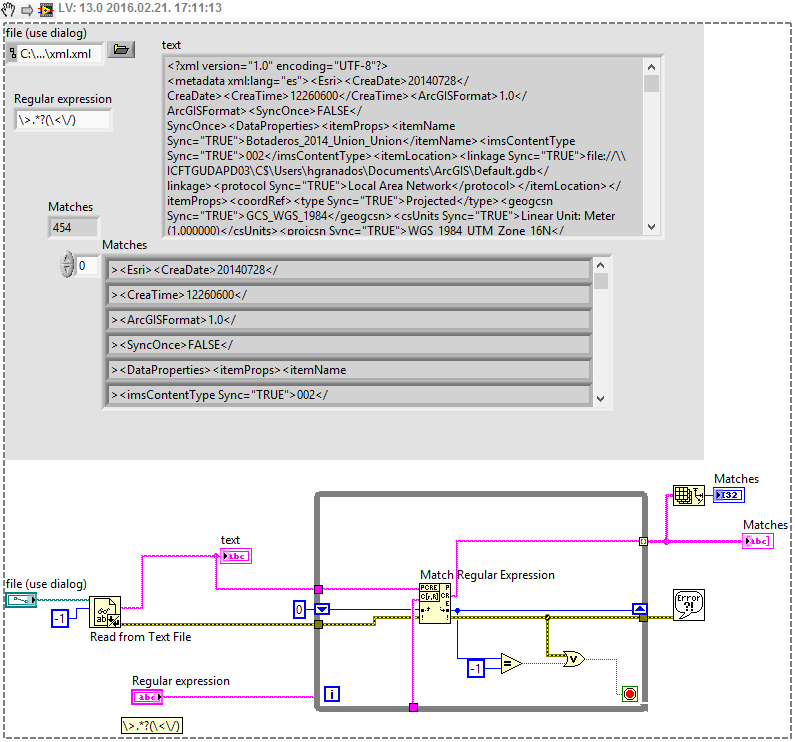
Read the string between two characters
I have an xml file that is saved to a text file, and the XML was not in Labview. I want to be able to read each line of the text file and display the text that is between ' > '.
I'll leave the text as an attachment file.
This could give you some tips, but you have to play with it to get properly what you want. I'm not really good at manipulating strings and not too familiar with regular expressions, I'm sorry...
-
Find a joint letter between two strings
Hello
I need help to find a common string between strings that results in a table. Here's an example scenario that you can consult to replicate and suggest.
create the table test_marine
(
P_ID varchar2 (50).
t_id varchar2 (50).
h_code varchar2 (40),
number of misc_type
);
insert into test_m values('1','100','ABC',1);
insert into test_m values('1','101','ABCD',1);
insert into test_m values('1','102','BC',1);
insert into test_m values('1','103','B',1);
COMMIT;
Data will look like below: -.

What I have to do here is - I want to take the all the h_code column values across both where p_id = 1 and browse all the values H_CODE one by one. Any other approach viable also who can help will be good.
Example - I choose ABC for 100, I check if A is common throughout 101,102,103, if so, save somewhere check then if B exists in all.
My Final result should be like this: -.

Where there is more than one match: -.

Where there is no match, the value may come as something as below: -.

Appreciate the help. Thank you
2615593 wrote:
Hello
Alone with AB.
In this case, you also want to...
insert into test_m values('3','100','ABC',1);
insert into test_m values('3','101','ABD',1);
insert into test_m values('3','102','ABE',1);
insert into test_m values('3','103','ABFG',1);
COMMIT;SQL > ed
A written file afiedt.buf1 with split as (select p_id
2, substr (h_code, level 1) as ch
3, count (distinct t_id) on (p_id partition) under the name of grp_cnt
4 of test_m
5 connect by p_id = prior p_id
6 and t_id = prior t_id
7 and level<=>
sys_guid() 8 and prior is not null
9 )
10, grp as (select p_id
11 ,ch
12, count (*) as ch_cnt
13, grp_cnt
14 split
Group 15 of p_id, ch, grp_cnt
16 )
17 select m.p_id
18, listagg (nvl (grp.ch, 'None')) within the Group (ch control) as ch
19 m (select distinct test_m p_id)
20 left outer join grp (grp.p_id = m.p_id and grp.ch_cnt = grp.grp_cnt)
21 * group by m.p_id
SQL > /.
P_ID CH
-------------------------------------------------- --------------------
1 B
2 None
3 AB3 selected lines.
-
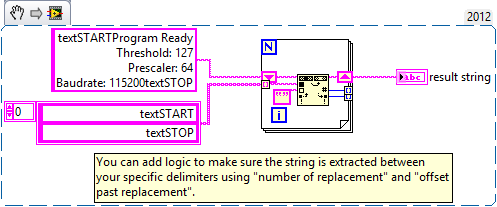
Regular expression for middle of string
Little background. I get the data (only the numbers) and text (can contain numbers) series. Since I don't know which I get and when it starts / ends, I do the sender send 'textSTART ###textSTOP' where ' # ' is what I want to extract. # can contain text, numbers, new line, carriage return or whatever.
The same for the data : "dataSTART ###dataSTOP", where # contains only numbers.
I think I should use the match pattern, but I don't know how to make my regular expression.
Any help is appreciated.
There are many solutions if you want to only extract the string between your specific delimiters. Here's a solution:
-
Apex 4: conditional display substitution strings
Hello
I have a replacement string defined in apex 4:
Substitution string: NOT_IN_EXCEL
Replacement value: instr (nvl(:REQUEST,'FOO'), 'FLOW_EXCEL') = 0
Now when I try to use this substitution string to a condition, for example on a column of the report, I get an error:
Condition type: PL/SQL Expression
Expression 1: & NOT_IN_EXCEL.
Error message:
ORA-06550: line 4, column 18: PLS-00103: encountered the symbol "&" when expecting one of the following numbers: (- + new case mod not null < an ID > < a between double quote delimited identifiers of > < a variable binding > continue avg current County are min max sql prior stddev sum variance execute forall time timestamp interval date fusion < a literal string with character set the context of > < a > <) a SQL string between single quotes > hose < a literal string between double quotes otherwise spec character set
With the help of a chain of substitution in this way in Apex 3.2.1 works without problem.
Thanks for the help in advance,
DirkHello
1. change the Item Page and scroll up to where you have the Condition
2. check do validate not (code analysis during execution only). checkbox, and then apply the changesSubstitution strings to continue to work as before in 4.x
Concerning
-
Parsing HTML in strings from to and input XML
I'm loading an XML file in a bunch of text (and other data) in text fields dynamic on my stage via a call XML.load. Here is an example of an entry in my XML file:
< stillDescriptions >
< text > Mack Trucks of North America came to us to help create marketing for their Diesel MP7 engine materials.
< / text >
< / stillDescriptions >
I would like to be able to create HTML links in these strings between tags < text > I have in my XML file so that a user can click on the link that is inserted into the dynamic text field.
I can't get this to work. If I place typical of HTML tags in my strings of XML - tag, it does not get analysis as HTML. As it, it does not - text string is truncated after hitting the first HTML tag. Logical as it can be expected from the XML tags instead of HTML tags?
< stillDescriptions >
< text > Mack Trucks of North America came to us to help create marketing < b > < a href = www.blah.blah > materials < /a > < /b > for their engine Diesel MP7.
< / text >
< / stillDescriptions >
Y at - it something to do, or is this not possible?
Any info would be most appreciated.
Thank you and good day,
-johnSCHwwwinnnng!
That's it - sort of... It restores to correctly in my field of dynamic text, in any case, but with two strange things:
(1) the focal point for the link is not only within the area occupied by the related underlined words, it seems that the length of the expression of a hypertext link, the larger the area below all the way to the lower limit of the dynamic text field.
(2) - I'll post this in a new thread - link works fine and dandy in a trial within Flash. but, as soon as it is embedded in HTML and read in a browser, the link does nothing. I can click forever, but, alas, my link does not open.
-john
-
An empty array to a worksheet string, delimiter
The string table worksheet function does not accept an empty delimiter, it uses the tab character in such a case.
The same is true for string array spreadsheet function (but of course this function can not work without a delimiter).
I would appreciate one of the following options:
- to allow a blank separator for the two functions (for string in array of spreadsheet that can easily obviously works for the worksheet to an array of strings, you might see a delimiter of empty string between each two adjacent characters similar to the function search and the string to replace with an empty search string);
- to document this behavior correctly;
I prefer the first espacially option for the string table worksheet function. What do you think?
aschipfl wrote:
The string table worksheet function does not accept an empty delimiter, it uses the tab character in such a case.
It is an old story covered in my idea here. (as of 2009!)
If there is more insight, it should be added as a comment to the idea of city.
Let's keep the discussion all in one place! Thank you.
-
I have a string that is I get when running. its length is variable. Suppose that its "NUMBER = ABC1004457844 | "It's the number you wanted." I want to get the string between '=' and ' | '. It can be variable, as I get it when the server running. This trend is the same in each response from the server.
Please help someone. Its urgency.
Hi you can use the indexof and substring in this case methods indexof method takes on the character and returns the index of the provided character, now give your characters required to indexof() alternately and get these indexes, now use the substring (startingIndex, endingIndex) for your required string.


Maybe you are looking for
-
waether app not working not
-
SSHD Toshiba MQ01ABD100H - Firmware / data recovery problem
Hello!I have the mission critical data on a MQ01ABD100H of Toshiba to SSHD which was in a Sony VAIO for less than one year who decided to stop working from one day to the next. All I care about is the data. A professional data recovery company appare
-
Reinstalling Windows XP edition family MCE on Equium A100-147
After a blue screen on this laptop, I ran chkdsk /r and when he pointed out several times there mistakes I replaced the ghost drive it. I did a repair reinstall and a large number of files could not be "copied". I reformatted the drive and ran verifi
-
My screen has been slain for 2 days on scanning and repair disk (C: 39% complete.) Does anyone know how to do it. I tried to restart.
-
???? Plese