delimiter
Hello!
This should not be a difficult question, but it took me a while anyway. I'm reading the text file (for example the one attached) in my VI, then read these data using a spreadsheet. It seems that the function readFromSpreadSheet has trouble recognizing the end of line delimiter. So far, I am only able to read the first line of data. Can someone help me with this problem? Thank you very much!
The delimiter is to specify which separates items on the same line - not what separates lines. Only, you have a single item by line and need not specify any delimiter. You get the 2D table or select transpose and get table 1 d.
Tags: NI Software
Similar Questions
-
String function tab delimiter table worksheet
Hi all, I am trying to use chain of worksheet to the array function to read on several lines of text and separate them in a 2D array. I have trouble using the delimiter. The default delimiter is tab, if I leave he unwired or use the Constant tab, it works, but if I use \t, it does not work. I'm using Labview 2013 and Windows 7 64-bit.
Anyone know what is happening? Also, if I want to use several delimiters, what should I do?
Thank you!
Right-click on your constant tab, select "code view"... you might find a surprise:
"you don't need to manually insert a tab because the function is set by default to it already, since you have... you'll find a back double return '."
-
I'm taking a picture of waveforms and the units of the scale accordingly. I have a picture of the sensitivities that the user can change and do this in my "EUs Scaling" under VI. I would use just of "LAS scale voltage to EU VI LabView", but the sensitivity of my sensors will vary depending on the way through. I can't much the back wave of construction. I think I'm scaling of values of y in my sub VI correctly. The sub VI is inside a loop of acquisition data and after reading MX DAQ. The sub VI is "Scaling had 32ch".
In addition, when you use DAQ MX create channel he wants to channel names to a string of nouns that are delimited by commas. How do I take a string array and comma delimit them into one string?
They are here in 2009.
-
view the file delimited by tabs on a table VI
Hi all
I have a delimited file tab I want to view help for the Table control.
I tried to use the tab settings and / n in a while loop to search for the file and display it on the table.
However, this will not work because the file is of variable size, i.e. some lines have columns others will have 2.
Is their a simple VI to import delimited by tabs of files does anyone know?
Thank you
Sean
Please try the primitive "worksheet of array of strings. It will be useful.
-
Is 'Spreadsheet.vi wire Delimited' identical 'write to worksheet File.vi?
I can't find the "write to the File.vi spreadsheet" in 2015 Labview. I used to have 2012, but now I can not find it! I see others with a similar icon so I thought 'Spreadsheet.vi delimited wire' is the same, but when I read the help, it seems not the same!
They are essentially the same thing. NEITHER changed the name because so many people thought you could read/write from/to excel. Adding the delimited Word makes it a little more specific.
What you see is the difference?
They must create the file even if the same inputs are used. Have you tried?
The new Vi includes the clusters of the error, because the old version of spreadsheet used error automatic handkling (yuck).
-
Text added in loop file adds the value of delimiter unwanted at the end of each iteration.
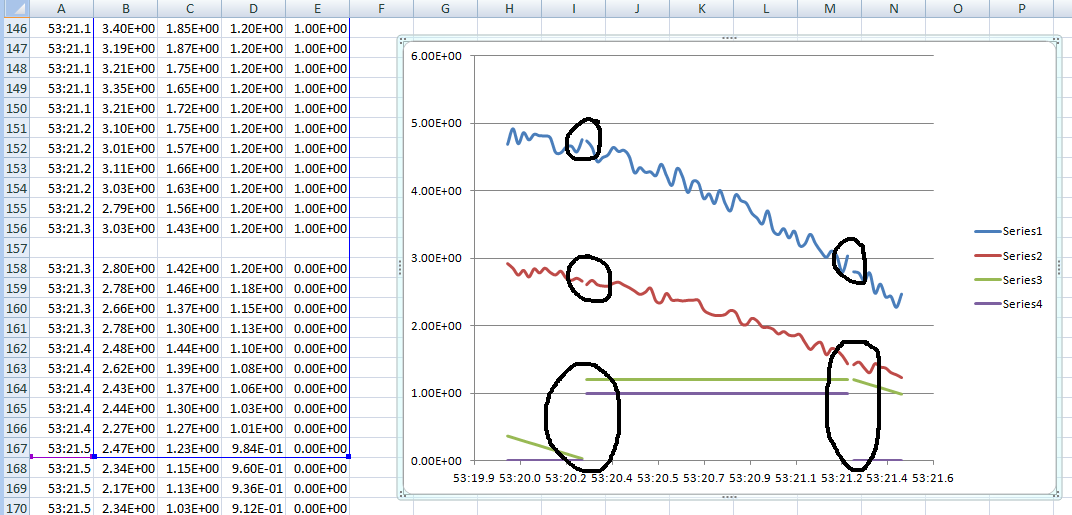
I use 'Export to Spreadsheet.vi' in a loop that records a text file and adds data to a waveform table 1 d for each iteration. My problem is that, at the end of each iteration of what an extra delimiter value is added to the file. When I then try to graph my data, I get the holes, as shown below (circled in black).
When I start to analyze the data, I'm sure it will be a nuisance. I can't find a solution to this problem. Any advice would be greatly appreciated.
Thank you.
Any wire TRUE here


-
An empty array to a worksheet string, delimiter
The string table worksheet function does not accept an empty delimiter, it uses the tab character in such a case.
The same is true for string array spreadsheet function (but of course this function can not work without a delimiter).
I would appreciate one of the following options:
- to allow a blank separator for the two functions (for string in array of spreadsheet that can easily obviously works for the worksheet to an array of strings, you might see a delimiter of empty string between each two adjacent characters similar to the function search and the string to replace with an empty search string);
- to document this behavior correctly;
I prefer the first espacially option for the string table worksheet function. What do you think?
aschipfl wrote:
The string table worksheet function does not accept an empty delimiter, it uses the tab character in such a case.
It is an old story covered in my idea here. (as of 2009!)
If there is more insight, it should be added as a comment to the idea of city.
Let's keep the discussion all in one place! Thank you.
-
I would like to how to convert commas to delimited by tabs?
Not so difficult

-
I developed an application based cross-platform LabVIEW. It will work on Mac OSX, Linux and Windows. It must reliably detect the operating system, it runs using delimiters of right for access roads (I generate filenames / files using other inputs on the front panel).
I have been using a craft of all kinds to do this. I use a server VI reference and use the node name property of the BONE, he wire in a search / replace string VI and count the number of times wherever a 'Windows' substring is replaced. If the number of replacements is greater than 0, it's Windows. Otherwise, I have test Linux. Do the same thing. Then if it is neither Windows nor Linux, I suppose it's Mac OS x.
This hack who has worked for the screws running on Mac OSX and Windows, doesn't seem to work for the application compiled on Windows LabVIEW PDS (the absence of a gcc cross-compiler style for LabVIEW is a kind of a topic thought for me right now since NEITHER forces developers to choose an operating system by creating unnecessary barriers for cross-platform compilation, but we won't go into that). There is no other point in my code which detect the right delimiter to use ("": "for Mac HFS," / "for Linux file systems and"------"to Windows FAT32 and NTFS).
I imagine that there are people here who have tried anything of the sort. Is there an operating system detects and find the good Delimiter.vi that someone can have and want to share?
Sometimes the use of strings is inevitable, in the relatively few cases, there are a few useful screws in vi.lib to help in cross-platform problems.
-
split a string using any delimiter and display a table
Hello
I'm trying to split a delimited string and an array of the output results.
I come from a background of .net and c# code I would use would be
Dim myString As String = "mystring\r\nto\r\nsplit";
String [] myString = mystring. Split (newchar [] {'\n', '\r'}, StringSplitOptions.RemoveEmptyEntries);
The code above have a line of muli on the input string (where the \r\n) and the output of a table with the following content
'mystring '.
« à »
'split '.
In addition, I would like to also support comma-delimited files.
I used the string function
"Spreadsheet String To Array" that works well enough for the lines of delimited by commas, but not when the delimiter is something funky like '\r\n '.
vi.llb in the advanced channel folder there are some goodies that do not surrender to the Kroatiens
-
Chips with 3 delimiter characters using regular expressions
Hello world
I have a function that is able to mark the input in a collection string using regular expressions.
In case the input string is a character such as the comma or semicolon delimiter,
We can just get the result we want like the example below.
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production PL/SQL Release 11.2.0.1.0 - Production CORE 11.2.0.1.0 Production TNS for 64-bit Windows: Version 11.2.0.1.0 - Production NLSRTL Version 11.2.0.1.0 - Production
SQL> with tab1 as ( 2 select 'abc,dfg,h,,1234' as col1 from dual 3 ) 4 select regexp_substr(col1, '([^,]*)(,|$)', 1, level, 'i', 1) as result 5 from tab1 6 connect by level <= regexp_count(col1, ',')+1; RESULT --------------- abc dfg h 1234
But in the case where the channel of entry has 2 types of delimiter and each delimiter consists of 3 characters as below
I wonder if it is possible to get the result as below.
The input string: 01| ^ | ABCD| ^ | 111| * | 02| ^ | efgh| ^ | 222
Separators: | * | is divided into lines, | ^ | is divided into columns
Expected result:
col1 col2 col3
Row1 - > 01 abcd 111
row2-> efgh 02 222
Simply put, take a next
The input string: 01| ^ | ABCD |^| 111 |*| 02 |^| efgh |^| 222
Separator: | * |
Result:
01. ^ | ABCD | ^ | 111
02. ^ | efgh | ^ | 222
How can I achieve this using regular expressions?
Kind regards
Euntaek
You need to know the number of the column from the outset:
with tab1 as)
Select ' 01 | ^ | ABCD | ^ | 111. * | 02. ^ | efgh | ^ | 222' as double col1
)
Select rownum,
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 1, null, 1) col1,.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 2, null, 1) col2.
regexp_substr (regexp_substr (col1 '(.*?) ((\|\*\|)| $) ', 1, level, null, 1),'(.*?) ((\|\^\|)| $) ', 1, 3, null, 1) col3
of tab1
connect by level<= regexp_count(col1,'\|\*\|')="" +="">
/
ROWNUM COL1 COL2 COL3
---------- ----- ----- -----
1 01 abcd 111
2 efgh 02 222
SQL >
SY.
-
manage the CLOB data delimited by tabs with the newline character
Hi all
I have a table with a column of type CLOB data where my data are delimited by tabs. For the new line I Chr (10) as the separator between the lines. Someone knows how to handle this character in order to select these data in separate lines.
Here is the example:
create table xx_test1(col1 clob); insert into xx_test1 values (TO_CLOB('1'||chr(9)||'5467'||chr(9)||'41773'||chr(9)||'5467'||chr(9)||'169407'||chr(9)||'GBP'||chr(9)||'08-Feb-2016'||chr(9)||'08-Feb-2016'||chr(9)||'UK Accrual Invoice'||chr(9)||'UK Accrual - import'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'RDWHMP.03.00025.IND'||chr(9)||''||chr(9)||'300'||chr(9)||'15'||chr(9)||'Each'||chr(9)||'ZZU'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'PL Imported Invoices'||chr(9)||'119'||chr(9)||'229'||chr(9)||'340'||chr(9)||'450'||chr(9)||'560'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'Franchise COGS'||chr(9)||'12'||chr(9)||'13'||chr(9)||'14'||chr(9)||'15'||chr(9)||'Y'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'10'||chr(9)||'0'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''|| chr(10) || '2'||chr(9)||'5467'||chr(9)||'41773'||chr(9)||'5467'||chr(9)||'169407'||chr(9)||'GBP'||chr(9)||'08-Feb-2016'||chr(9)||'08-Feb-2016'||chr(9)||'UK Accrual Invoice'||chr(9)||'UK Accrual - import'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'RDWHMP.03.00025.IND'||chr(9)||''||chr(9)||'10'||chr(9)||'15'||chr(9)||'Each'||chr(9)||'ZZU'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'PL Imported Invoices'||chr(9)||'120'||chr(9)||'230'||chr(9)||'341'||chr(9)||'451'||chr(9)||'561'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'Franchise COGS'||chr(9)||'12'||chr(9)||'13'||chr(9)||'14'||chr(9)||'15'||chr(9)||'Y'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||'10'||chr(9)||'0'||chr(9)||''||chr(9)||''||chr(9)||''||chr(9)||''));I'll try this one, but it does not work. The last column is not correct and it returns the value of the next line and also does not continue to the end (I presume it's due to the position of the character hardcoded in regexp_substr). Any ideas how to handle?
WITH c_file_imp_data AS (SELECT dbms_lob.substr(col1, 32767, 1) src FROM xx_test1) SELECT --regexp_subsr is finding the position of the x occcurrance of a tab delimitter to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 1), chr(9))), --RECORD_ID to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 2), chr(9))), --BILL_TO_CUSTOMER_NUMBER, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 3), chr(9))), -- BILL_TO_LOCATION, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 4), chr(9))), -- SHIP_TO_CUSTOMER_NUMBER, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 5), chr(9))), -- SHIP_TO_LOCATION, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 6), chr(9)), -- CURRENCY, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 7), chr(9)), 'DD-MON-YYYY'), -- GL_DATE, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 8), chr(9)), 'DD-MON-YYYY'), -- TRANSACTION_DATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 9), chr(9)), -- TRANSACTION_TYPE_NAME, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 10), chr(9)), -- TRANSACTION_SOURCE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 11), chr(9)), -- TERMS, to_date(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 12), chr(9)), 'DD-MON-YYYY'), -- DUE_DATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 13), chr(9)), -- PAYMENT_METHOD, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 14), chr(9))), -- SALESREP_NUMBER, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 15), chr(9)), -- ITEM, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 16), chr(9)), -- DESCRIPTION, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 17), chr(9))), -- QUANTITY, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 18), chr(9))), -- UNIT_SELLING_PRICE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 19), chr(9)), -- UNIT_OF_MEASURE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 20), chr(9)), -- WAREHOUSE, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 21), chr(9))), -- TAX_RATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 22), chr(9)), -- TAX_CODE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 23), chr(9)), -- GL_ACCOUNT_STRING, to_number(rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 24), chr(9))), -- CURRENCY_EXCHANGE_RATE, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 25), chr(9)), -- LINE_TRX_DFF_CONTEXT_VAL, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 26), chr(9)), -- LINE_TRANSACTION_FIELD1, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 27), chr(9)), -- LINE_TRANSACTION_FIELD2, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 28), chr(9)), -- LINE_TRANSACTION_FIELD3, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 29), chr(9)), -- LINE_TRANSACTION_FIELD4, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 30), chr(9)), -- LINE_TRANSACTION_FIELD5, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 31), chr(9)), -- LINE_TRANSACTION_FIELD6, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 32), chr(9)), -- LINE_TRANSACTION_FIELD7, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 33), chr(9)), -- LINE_TRANSACTION_FIELD8, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 34), chr(9)), -- LINE_TRANSACTION_FIELD9, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 35), chr(9)), -- LINE_TRANSACTION_FIELD10, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 36), chr(9)), -- LINE_TRANSACTION_FIELD11, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 37), chr(9)), -- LINE_TRANSACTION_FIELD12, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 38), chr(9)), -- LINE_TRANSACTION_FIELD13, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 39), chr(9)), -- LINE_TRANSACTION_FIELD14, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 40), chr(9)), -- LINE_TRANSACTION_FIELD15, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 41), chr(9)), -- INV_LINE_INFO_DFF_CONT_VAL, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 42), chr(9)), -- NO_ANIMALS, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 43), chr(9)), -- MX_WEIGHT, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 44), chr(9)), -- MX_SLAUGHTER, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 45), chr(9)), -- REBILLED, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 46), chr(9)), -- NON_STAT, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 47), chr(9)), -- ATTRIBUTE12, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 48), chr(9)), -- ATTRIBUTE13, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 49), chr(9)), -- ATTRIBUTE14, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 50), chr(9)), -- ATTRIBUTE15, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 51), chr(9)), -- ATTRIBUTE8, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 52), chr(9)), -- ATTRIBUTE11, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 53), chr(9)), -- ATTRIBUTE2, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 54), chr(9)), -- ATTRIBUTE3, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 55), chr(9)), -- ATTRIBUTE4, rtrim(regexp_substr(src, '[^' || chr(9) || ']*' || chr(9) || '', 1, 56), chr(9)) -- ATTRIBUTE9 FROM c_file_imp_data
Oracle DB version: 12 c
Thanks in advance,
Alex
with
xx_test1 as
(select TO_CLOB ('1' |)) Chr (9) | "5467' | Chr (9) | "41773' | Chr (9) | "5467' | Chr (9) | ' 169407' | Chr (9) | ' GBP'. Chr (9) | "February 8, 2016'. Chr (9) | "February 8, 2016'. Chr (9) | "Bill regularization UK' | Chr (9) | "Accumulation of UK - import '. Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' RDWHMP.03.00025.IND' | Chr (9): "| Chr (9) | ' 300'. Chr (9) | ' 15' | Chr (9) | ' Each ' | Chr (9) | ' ZZOU ' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "PL imported invoices | Chr (9) | ' 119' | Chr (9) | ' 229'. Chr (9) | ' 340' | Chr (9) | "450 | Chr (9) | ' 560' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "Franchise of the WORKINGS. Chr (9) | ' 12'. Chr (9) | ' 13'. Chr (9) | ' 14'. Chr (9) | ' 15' | Chr (9) | » Y'|| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' 10'. Chr (9) | » 0' || Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (10) | '2'|| Chr (9) | "5467' | Chr (9) | "41773' | Chr (9) | "5467' | Chr (9) | ' 169407' | Chr (9) | ' GBP'. Chr (9) | "February 8, 2016'. Chr (9) | "February 8, 2016'. Chr (9) | "Bill regularization UK' | Chr (9) | "Accumulation of UK - import '. Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' RDWHMP.03.00025.IND' | Chr (9): "| Chr (9) | ' 10'. Chr (9) | ' 15' | Chr (9) | ' Each ' | Chr (9) | ' ZZOU ' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "PL imported invoices | Chr (9) | ' 120'. Chr (9) | ' 230'. Chr (9) | ' 341'. Chr (9) | ' 451' | Chr (9) | "561' | Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | "Franchise of the WORKINGS. Chr (9) | ' 12'. Chr (9) | ' 13'. Chr (9) | ' 14'. Chr (9) | ' 15' | Chr (9) | » Y'|| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ' 10'. Chr (9) | » 0' || Chr (9): "| Chr (9): "| Chr (9): "| Chr (9) | ") the_clob
of the double
)
Select x.lne
of xx_test1 t.
XMLTable ('/ a/b ')
from xmltype ('' |) Replace (t.the_clob, Chr (10),''): '')
path of ESA varchar2 columns (4000) '.'
) x
ESA 1 5467 41773 5467 169407 GBP 8 February 2016 8 February 2016 regularization invoice accounting UK UK - import RDWHMP.03.00025.IND 15 300 each ZZU PL Imported bills 119 229 340 450 560 Franchise COGS 12 13 14 15 Y 10 0 2 5467 41773 5467 169407 GBP 8 February 2016 8 February 2016 regularization invoice accounting UK UK - import RDWHMP.03.00025.IND 10 15 imported bills each PL ZZU 120 230 341 451 561 Franchise COGS 12 13 14 15 Y 10 0 It seems that you know how to do the rest
Concerning
Etbin
-
Out of csv Sqlcl, and; delimiter
Hello
When I use the line tool SQLCL command, with defined option sqlformat csv or delimited, sqlformat the delimiter is ', '.
I want to change it to ';', but I can't do it.
I have seen that we can change with SQLDeveloper? I have not yet tested, but I wonder if it is possible with a within the tool sqlcl command line
Any help would be appreciated, thanks...
Is not possible today in SQLcl, but it's a natural suggestion and the progression of the function then I imagine it will happen at some point.
-
Hello
I'm still struggling with the multi assign delimiter. We have log files with values that can contain virtually any character. In this case: what multi assign delimiter should I use? Or what delimiter to assign multi do you use?
Thank you!
Marco
I usually put it in the workspace.prm and then reference it in the world.
ENDECA_SERVER_HOST = myhost.thebird.com
ENDECA_SERVER_PORT = 11001
ENDECA_SERVER_CONTEXT = server short
DATA_DOMAIN_NAME = test
MULTIASSIGN_DELIMITER = \u007F
As in a re-formatter...
$out.0.myDataField = "Value1" + "${MULTIASSIGN_DELIMITER}" + "Value2";
Or charger in bulk...

-
How to split a string into several substrings parent using a delimiter
Hello
I am forced to split a string into several substrings parent using a delimiter.
And insert these substrings in variuou of the columns of a table in a row.
For example. The sting is: ABC * DEF * GHI * JKH *.
where ' *' is the separator.
Desired output:
Col1 Col2 Col3 Col4 Col5
------- -------- -------- ------- ---------
JKH GHI ABC DEF (null)
Could you please guide me how can I achieve this.
Thank you
Bogoss
Hello Salim,
Leave the thread for reference... got this excerpt:
with t as
(
Select "c: its: hgfd:1:23" Str
)
Select
REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 1, null, 1) col1
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 2, null, 1) col2
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 3, null, 1) col3
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 4, null, 1) col4
, REGEXP_SUBSTR (str, ' ([^:] *)(:|$)', 1, 5, null, 1) col5
t;
This code snippet works well, but for the fixed columns. Here are 5 predefined columns.
But I need to have a logic that I can browse the string any No.. sometimes.
For example. If I get 3 secondary channels of the parent chain... I need to insert into 3 columns.
And if I get 6 strings under... I need to insert into 6 columns.
Could you please help me develop a logic like that.
I use Oracle database 10g.
And the data are currently being collected on external table... but I can store in a variable or a column of a database table.
Thank you
Bogoss



Maybe you are looking for
-
The output of the mode standby
After a recent update of Windows 10, I am unable to use the mouse or the keyboard to wake the computer from sleep. To resume the use of the computer, I now need to press the power button. Before the update (from the same Windows 10), I had no probl
-
It is Chinese or Japanese writing on my lock in ios 10 screen
I recently installed ios 10 and it works fine, but on the lock under the date screen, it shows the date in Chinese or Japanese. How can I fix?
-
I'm used to HD content to display wide meaning. Everything I have ever downloaded/purchased in HD has always been contained pan. Recently returned in the leap forward and I saw that iTunes has HD and SD versions. Was happy to see that there are episo
-
HP psc 1315 is compatible with Vista?
Hi, I have an old printer, HP PSC 1315, I used it with my XP OS. I just want to know if I could install it too with an OS like Vista. TIA.
-
Windows 7 Task Scheduler is not wake the portable computer at the scheduled time
Instead of stopping my laptop, I put it to sleep at night. Later, the laptop is expected to execute the sequence of tasks scheduled in my windows-7: 04:00, run a task "A". To perform this task, the laptop awakens from his sleep because "task" was to