Expected waiting time gives-1
Hello
I have an IPCC Express Premium operating system. In my script, I call the stage get statistical Reporting and request the value of wait times should. When I read the variable, it gives-1. My QSC seems to be set correctly. I have 2 agents for the moment, on a call or is not ready. If anyone has encountered this before?
Thank you
Mike
The estimated wait time will be-1 if CSQ talk time average or the total number of work resources is 0.
The reference step Guide...
The base system the calculation of planned downtime on the number of reserved, talk and statements of work for the CSQ, position of the call in the queue and the average duration of calls to this CSQ. Medium-term a CSQ is the average duration of calls officers spend in reserved States, Talking and working during the processing of an appeal by the CSQ.
Tags: Cisco Support
Similar Questions
-
How the expected wait time is scripted?
Hello
Can someone tell me what controls are needed and where they should be placed in a script and what variables I need to create if everything for a very basic should expect a time?
I looked at previous assignments and I'm not. The only control I see that would be necessary is to get statistical reporting, but I know not where to put it or how to play people in the queue the message of what the expected wait time is.
Please advise,
Thank you
Chuck
You can use the step get statistical Reporting to fetch the expected waiting time (in this step, the "line identifier" parameter is interested in the CSQ).
The expected wait time is in seconds, so you can convert this to minutes and then use a series of guests as well as a "create generated Prompt" to announce the waiting time.
Take a look at these messages in previous discussions:
Please note the useful messages!
-
IPCC Express estimated the waiting time in the queue
I have an ipcc express 4.0 and my client wants the number of callers to hear a prompt indicating the estimated waiting time in the queue.
Is this possible with this solution? Maybe to deal with scripts.
Any idea?
Jose
Jose,
You can do the process you like through the IPCC Express Scripts.
You must use the "Get Reporting" statistical step under 'IPCC Express' in the script editor and choose the statistics that you want, in your case, you have to select 'Report object'-> 'CSQ IPCC Express' and afte, select 'Area'-> "Expected wait time", store that value in a variable to create as a guest to read the value.
Hope this helps,
Juan Luis
-
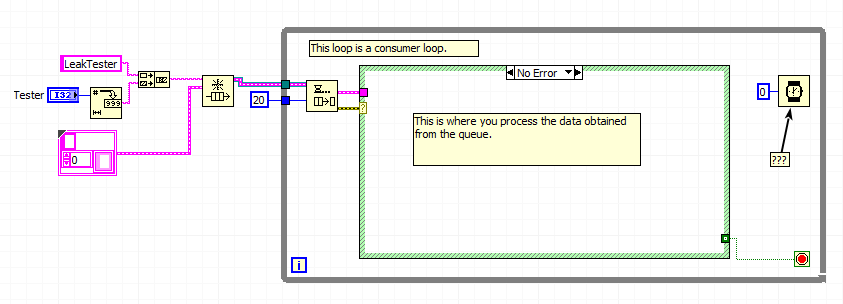
A wait timer is needed in a loop of consumer?
I have a leak of test engine and motor servo which is a loop of consumer being called via "Start Asynchronous Call" several times for each device. A contractor I work with said that I need to add a timer wait since the dequeue tie up the processor. Is this true?
I kind of logic that awaits the dequeue to treat something immediately, but I thought that the time-out would free the loop as a wait timer to zero. He says he doesn't because he is still waiting to remove something. What the experts think about it?
nonecure wrote:
So the dequeue will normally be on the CPU? Is this similar to an empty loop without a wait timer? Not a lot of treatment, but taking processor resources?
Lol if there is nothing in the queue, Dequeue item causes a 'sleep '. This is similar to the Structure of your event until the event. They use no CPU while you wait for a message.
Now if you have a lot of things in your queue, then your loop could run as fast as possible to play catch-up.
-
Can I use a variable in step of TS Message for field 'waiting time '?
Is it possible to use a variable (inhabitants, parameters, etc.) for the field "Wait time" in the stage of message TestStand?
TestStand 4.1
Thank you
Rafi
Go to the step settings > properties > Expressions > Expression Pre and enter something like:
Step.TimeToWait = Locals.MyTimeToWait
-
Server wait times 2012 - Win 7 - DNS Client
Background:
Single Server R2 of 2012:
Domain controller: * field (192.168.0.12)
Primary DNS Active Directory integrated, double cards configured network team
Clients Windows 7 Pro:
Quantity 15 (with an assigned static IP, no DHCP, all cables, wireless), defined primary DNS on 192.168.0.12
Cisco SmartSwitch SG200-26 - show NO error on one of the ports
Randomly the DNS server stops just in response to DNS queries.
Clients receive Error 1014: no DNS servers responded ORS
Wait times when Internet browsing and access to the local server
Computers lose all network connectivity, (as long as I use 192.168.0.x references I can access files on the network) just DNS resolution
Customers (when it works)
nslookup microsoft.com
Server: server2015.* *.
Address: 192.168.0.12
Non-authoritative answer:
Name: microsoft.com
Address: 23.100.122.175
When things do NOT work
nslookup microsoft.com
Server: unknown
Address 192.168.0.12
Unknown can't find microsoft.com: no response from Server
After a few minutes, I can retry the command NSlookup and return works.
All Windows updates have been installed on the server and the clients.
This server / configuration is only 2 months old. New server hardware and software. Replace Windows SBS 2003. Customers have been the same.
Tried to disable all anti-virus, disabling all services necessary, re-configured to use only one network card. The problem is more common that a new server has just arrived.
I have no idea where to go from here.
Thank you
The problem ended up being the on the DNS server. The local ISP changed the DNS server address and the forwarder was not set correctly on the DNS server.
Thanks for all the support.
-
How long can we keep in touch in a waiting time?
Hello
How long can we keep a contact in a waiting time?
Thank you
Hello
You can keep a contact in an unlimited number of step of waiting time.
Thank you
-
The waiting time for the activation of the subscription of creative cloud?
The waiting time for the activation of the subscription of creative cloud?
Hi Evgeny,
You can follow the article: solve common activation Adobe Creative Cloud (login) and questions (disconnect) disabling or error messages and errors in connection with Creative Suite and creative Cloud applications, activation and connection Solutions to resolve activation problems.
Let us know if this solves the problem for you or not.
Thank you
Yann Arora
-
Sometimes (but) my calculation script of waiting time of bombs with this error:
TypeError: Cannot find the function SetHours in object Tuesday, March 18, 2014 14:02:56 GMT - 0400 (EDT). (Workflow: Install SQL / calculate wait (work) (item11) #17)
Any ideas? (NextPool is used for a WaitTimer)
DEPARTURES:
NextPoll (Date)
SCRIPT:
/* */ var waitTime = 2; // Polling Interval workflowScheduleDate = new Date(); //this is now // If minutes is less than 59 if ((workflowScheduleDate.getMinutes() + waitTime) < 59) { // Then let's add a minute to that workflowScheduleDate.setMinutes(workflowScheduleDate.getMinutes() + waitTime); } else { // we're at 59 minutes already, add a minute (by rolling over to 60, e.g. 0) workflowScheduleDate.setMinutes(waitTime); // If hours is less than 23 if (workflowScheduleDate.getHours() < 23) { // Let's add an hour to that (because we rolled over minutes workflowScheduleDate.SetHours(workflowScheduleDate.getHours() +1); } else { // We need to roll over our day workflowScheduleDate.setHours(0); } } // Set the Next scheduled time NextPoll = workflowScheduleDate; /* */(And if anyone can tell me how to format the script in a pleasant way of this post, I'm all ears)
EDIT: I realize that's not quite do exactly what I need it to do (the reversal of the works a little, kind of isn't), you can ignore it for now.
Post edited by: pezhorEL
JavaScript is case-sensitive, so you must use with tiny setHours() of '. Something like
workflowScheduleDate.setHours(workflowScheduleDate.getHours() +1);
and is not
workflowScheduleDate.SetHours(workflowScheduleDate.getHours() +1);
For syntax highlighting of code, there is a 'Use advanced editor' link in the top right of the window to answer. Click on the link, then on the blue button "Insert", which looks at ' > '.
-
WAIT times extreme and vm slow performance
In a cluster of 3 host R710 ESXi 4.1 (3 x 16 logical processors) DRS 18 virtual machines running on a virtual machine performance is really bad.
Glancing once ready nothing strange does not show, but WAIT times seems extremely high (some vm of maxing out at 20000 millisecond for longer periods).
I see that most vm have 2 vCPU and about 6 even 4 vCPU. I guess that the problem could be with the vCPU but do not know (its use and ready once are really low). Which could explain the high WAIT times?
Concerning
The metric of WAITING % is not relevant because it includes idle time:
http://www.yellow-bricks.com/2012/07/17/why-is-wait-so-high/
% OF WAITING
The total percentage of the Resource Pool/world of time in a wait state. That is, the world awaits a VMKernel resource. Note that this percentage includes the percentage of time that the Resource Pool/world remained inactive.If you really think a CPU bottleneck, RDY and CSTP % are the main parameters to be monitored.
Looking at once ready nothing strange shows
So how big are they really? Do not forget to put ready graphic vCenter summation values in proportion to the data collection interval (20 seconds in the graphs in real time).
But since I doubt you really CPU issues with 'only' 48 vCPUs in a cluster of 3 guests with 24 son of carrots/48 total, less than most, if your VMS running at nearly 100 percent CPU usage.
-
Production Portal crashes with wait times
Hi all
Several times during the day, the Portal 10.1.4.0.0 crashes with wait times.
In order to recover, the portal must be restarted.
(The time-out period also took place during the time that they had a db corruption, but now that corruption has been resolved, the grip still occur.)
After you run the SVU in CLEANING mode, the problem persists.
Timeout has been defined in many more than the default value. Stall has increased also. Neither helped to solve the problem.
Java portlets come from a provider of OC4J, and they are all the pages under a group of pages.
These data (also the views of hollow) readings of portlets on portal schema to create the "style" and the css of the portals pages. All the instructions of database are selected, except for the rare insert on a table in their schema operation custom.
Responsibility of the user:
Access statistics indicate that about 800 users access this site in 1 hour.
1100 users had access of user higher in an hour.
Access by concurrent users are about 500.
Thanks for any help.
Published by: hmannila on May 11, 2010 23:50Hello Louis,.
In this particular case, the EPP time-out settings are set at very high values causing depletion of the discussions of the recovery tool in the recovery EPP tool thread pool:
page oracle.webdb.page.ParallelServlet requesttime 120 minTimeout 180 stall 200 This should be the course of action for you:
>
As you already pointed out, the portal seems to hang because Edison provider does not respond quickly enough to requests as part of the portal. Oracle Portal should be able to recover Thi in normal cases. Unfortunately, configuration in the portal settings have changed since the default values, making it almost impossible for the framework to recover from the error. To understand this, we will need to go through the theory:The Oracle Portal framework collects information from various sources and assemble these web pages which are then sent to the Web browser to end users. Suppliers are a source of information. To retrieve information from providers, Oracle Portal allocates a thread of so-called fetcher in OC4J_Portal. This fetcher thread will create a session with the provider (remote) and extract the content, similar to the way in which a web browser would contact a web server to retrieve an HTML page. It is important to note that Oracle Portal allocates a thread of the recovery tool for each portlet on a page. For a page containing five portlets, five threads of the recovery tool are allocated as the content is retrieved at the same time.
In a default configuration with one OC4J_Portal process, the number of threads in the recovery tool is limited to 25. With five portlets on a page, the portal will be able to serve up to five queries simultaneously until the Fetcher thread pool is exhausted. This normally isn't a problem because the recovery tool nets are normally allocated for a few seconds. Once they have received the response from the provider, they are returned to the pool and will again be available on the portal.
The problems start when the response from the provider becomes slow. The thread of the recovery tool is not returned to the pool immediately. Applications begin to queue until the system has more than the threads of the available recovery tool. Once there is no thread of the available recovery tool, the portal will wait for a new thread fetcher for a certain period of time (as specified by the queueTimeout). After expiry of that period of waiting for the queue, the portal will return an error on Oracle's HTTP server. This is when end users will start to encounter errors in the pages.
To keep the portal alive and in good health, administrators should be careful that the fetcher thread pool don't get exhausted. Obviously, the best way to do this is to ensure that all suppliers to respond in a reasonable amount of time. If there is no control on the response time of the suppliers, administrators can use timeouts in the framework to ensure that queries for long durations are killed by the framework to ensure that threading of the recovery tool is returned to the pool again. These settings are configured in the Web.XML from the portal application in the OC4J container called OC4J_Portal. Of course users will see errors of time-out specific portlets on some pages but the general framework will be available. In addition, directors may decide to increase the number of threads in the recovery tool by starting more than a process of OC4J_Portal. Each additional process will increase the amount of threads fetcher with 25. However, there is a penalty of memory that each process may consume between 256 to 512 MB of memory. Administrators should only increase the amount of process when they checked the system high portal has enough free memory available to hold account of these additional processes.
Action plan:
1 change the values of time-out for the framework of portal to the default values:
a. go to $ORACLE_HOME/j2ee/OC4J_Portal/applications/portal/Portal/WEB-INF
b. copy the web.xml file:web.xml Web.xml_23MAR2010% cp
c. edit the web.xml file:
For the RepositoryServlet and the PortalServlet, remove the timeout of STALL
For the page servlet, remove the requesttime, minTimeout, stall and queueTimeout settings2 increase the number of processes of OC4J_Portal from 1 to 4:
a. create a copy of the $ORACLE_HOME/opmn/conf/opmn.xml file:
% cp opmn.xml opmn.xml_23MAR2010
b. open the opmn.xml file
c. find the following section:
d. in the section for the OC4J_Portal process, change the following line:
TO
3 synchronize the repository, DCM:
% $ORACLE_HOME/dcm/bin/dcmctl updateconfig
4 restart the process high
% $ORACLE_HOME/opmn/bin/opmnctl stopall
% $ORACLE_HOME/opmn/bin/opmnctl startall4. make sure that the changes are in force:
a. number of OC4J_Portal process:
Run opmnctl status and count the number of OC4J_Portal process. You should see four of them.
b. time-out settings in OC4J_Portal
Open the $ORACLE_HOME/j2ee/OC4J_Portal/application-deployments/portal/OC4J_Portal_default_island_1/application.log file and locate the following line at the end of the file:
03/10/08 06:32:32 Portal: version PPE: 10.1.2.0.2 (29022008)
03/10/08 06:32:32 Portal: setting of the parameter values: poolSize (Fetchers) = 25 [default = 25]: minTimeout (MinTimeout) = 5 s [default = 5s]: requesttime (DefaultTimeout) = 15 seconds [default = 15 s]: stall (MaxTimeout) = 65 s [default = 65]:
queueTimeout (QueueTimeout) = 10 s [default = 10 sec] maxParallelPortlets = 20 [default = 20] maxParallelPagePortlets = 10 [default = 10] -
Need an example of script for the waiting time expected
Hello
Does anyone have an example script that they can send me that indicates how and where to use statistical control of get and how to generate a prompt to read a message to a caller who says what is the waiting period?
Thank you
Chuck
There is a position in the queue thing.
First you stor in the parameter value and then read it...
My modified script which should explain is attached. You can actually use, but must change that I deleted my customer info.
Please note so useful.
Thank you
Barnes.
-
The waiting time for the end of the FNDLIBR process?
This morning we have problems with our ICM. We found a process FNDLIBR running since yesterday and five PROD.dbc process, although we run a cold backup every night.
I read in (Doc ID 1317901.1() you expect that each FNDLIBR is finished after running script adstpall.sh. How long we have to wait? Do we not have to kill these processes after a certain time?
And if we kill these processes the MHI will start cleanln?
Thank you very much.
Silvina Leguero.
Hello
The concurrent Manager processes are usually less than 5 minutes to issue the shutdown command.
You have to wait for them, but if there are still active process after 10 minutes then you should check if there are applications running that wouldn't get fired.
I faced this question several times and I'm sure that happens with our customers during cold backup processes but in most cases simultaneous managers start up normally afterwards.
Kind regards
Bashar
-
Workflow fails on the wait Timer
I have a created workflow that generates a snapshot of a VM, notifies the user by e-mail that the snapshot was created, and then going into a timer waiting for a period of 2 weeks before checking if the snapshot still exists and to notify the user that they must remove the snapshot. So buckle up every day notify the user that the snapshot should be removed until the snapshot no longer exists.
For most of the time, the workflow works as expected, however, I find that one or two workflow running fails from time to time. The schema of the execution of workflow shows workflow failed on the timer standby (which I checked has a valid date/time value assigned to the input of energy). When I view the events for the workflow, it has 3 events, Workflow has started, workflow is suspended and Workflow failed. When you select the workflow does not event, the description is "Workflow has been issued by a task, the workflow runtime does not be resumed" (I guess that 'being' = 'summer' in the message). In addition, when the workflow fails, it never runs the exception workflow that is configured to send me an email notification with the information of errors/exceptions.
Does anyone have ideas, what could be causing this failure? I noticed that the failure occurs most often after that the Orchestrator function has been restarted.
Hello
In fact, the behavior you observe is not random and should somehow. Currently all the workflows that are opened by an i.e., scheduled task are not included on the reboot of the server. The centre of the spot is responsible. The reason is that it could happen that such a workflow can be started at the same time to resume from the point it was suspended and centre/Task Manager. So, if the workflow should he resume the server restarts.
Other hand the reboot of the server, the Task Manager will hold the following logic:
1.1 if it is a recurrent task task manager will calculate the next execution time and is scheduled to run.
1.2 If the task is not recurrent, i.e. it is a one time task there are two options:
1.2.1 the execution time is not spent - then the task is scheduled for execution.
1.2.2 the execution time already - spent, we will in two other options:
1.2.2.1 the task has been configured on "Start if scheduled in the past" and has not yet been completed - the task is scheduled to run once.
1.2.2.2 the task has been configured for "do not start if scheduled in the past ', or is already completed - the task ends with error and the workflow will not be executed.
I guess in your case, the workflow is scheduled (started from a task) and that's why he is unable to return to restart the server. If the workflow is not recurring to work around the problem, you can configure the task scheduled as "Start" If in the past You can do this with access from the client to the Scheduler->-> Edit (photo attached). This will lead to the execution of the workflow from the beginning on the reboot of the server if the workflow has already been launched but was not complete or suspended in the middle. 
Kind regards
Radostin -
Hello can anyone give solution to my problem.
my iPhone touch 5 works not when it is in locked mode and it's time all incoming call came the touch works do not. other times, the touch works normally wat is the problem. ?
If you disturb not activated. Settings > do not disturb.

Maybe you are looking for
-
Remove "blocklist.xml" impossible to find a new one?
I deleted firefox blocklist.xml to solve a problem, I expect Firefox to renew when I start the browser again, but I can not find
-
Satellite A-P70-11R - drive Blu - Ray from Toshiba does not work after windows 10
Hello Please can someone help with my Satellite P70-A-11R I have upgraded to Windows 10My Blu - Ray player would not work but the DVD worked,All drivers OK I tried to update and it said to remove old version first.I uninstalled it, then says cannot i
-
Strange problem with ports USB on my Satellite A300-243
Hello I have the following problem. So far, I have 4 USB ports, and only my USB key and key to my friend works there. All other USB keys (I tried mby 20 different ones) does not work: aks for, pilot research, etc... I spent many hours together in the
-
My brand new ipod touch will not even appear on itunes. It says I have to update the software, but it is already updated on itunes and the ipod. Help!
-
The number of activations of Windows 8 permit Dreamspark Premium
Hello I recently got Windows 8 of Dreamspark Premium and installed on my laptop. Unfortunately, the laptop is now dead, completely non-functional (unrelated to Windows, it's a hardware problem). I will soon receive a new laptop and I was wondering if