extract characters from a string
Hi gurus,I want to extract the first, third, fifth, seventh... characters in a string.
not to extract characters from a subset of characters in a select query in oracle 9i database.
for example (1):
Assume that a string like this "SUE" is that I am 'ACEGI"of the source string
and the source can be any valid string, I just give an example here.
Example (2) of "kalpataru' in klatau'
Please guide me for this
for 9i:
SQL> with t as (
select 'ABCDEFGHIJ' str from dual union
select 'kalpataru' from dual
)
--
--
select str,
trim(extract(xmlagg(xmlelement(e, substr(str,level,1)) order by level),'//text()')) str2 from t
where mod(level,2) = 1
connect by level <= length(str) and prior str = str and prior sys_guid() is not null
group by str
/
STR STR2
---------- --------------
ABCDEFGHIJ ACEGI
kalpataru klaau
Tags: Database
Similar Questions
-
Hello
i'numbers in the neck of string arrecnote
Please help me in this...
Published by: smile on October 7, 2010 05:33
Published by: smile on October 7, 2010 06:14Try this to extract the numbers from a string:
SQL> ed Wrote file afiedt.buf 1 with t as (select 'hello-cycle monthly settlement; 865.15 SDR 2
multilat net 218.15 (USD) USAWW-USACC-2007/10' col1 from dual) 3 SELECT * FROM 4 (SELECT REGEXP_SUBSTR(col1,'[0-9]+.[0-9]+',1,lvl) col1 FROM 5 (select col1,level lvl 6 from t 7 connect by level <= LENGTH(col1) - LENGTH(REPLACE(col1,' ')) + 1)) 8* WHERE col1 IS NOT NULL SQL> / COL1 -------------------------------------------------------------------------------- 865.15 218.15 2007/10 SQL> -- or if you just want the numbers with its decimal SQL> ed Wrote file afiedt.buf 1 with t as (select 'hello-cycle monthly settlement; 865.15 SDR 2
multilat net 218.15 124 (USD) USAWW-USACC-2007/10' col1 from dual) 3 SELECT * FROM 4 (SELECT REGEXP_SUBSTR(col1,'[0-9]+[.][0-9]+',1,lvl) col1 FROM 5 (select col1,level lvl 6 from t 7 connect by level <= LENGTH(col1) - LENGTH(REPLACE(col1,' ')) + 1)) 8* WHERE col1 IS NOT NULL SQL> / COL1 -------------------------------------------------------------------------------- 865.15 218.15 SQL>Published by: AP on October 7, 2010 05:43
-
Hi all
I am trying to remove special characters without the help of regular expressions.
translate (the column name or string,'!@#$ & * (* () _) * "" :} {?}) >? /, «, » ')
I want to eliminate this manual process to give all special characters using a chr() or ascii() function.
Please show me the way.
Thanks in advance
Similar to the solution of Michael...
SQL > ed
A written file afiedt.buf1 with t as (select "[it comes of the #] [more amazing!") Test @# "$* & $%) assuming chain cost $ 5 000' double Str)
2, i like (select level 1 c from dual connect by level<=>
3 less
4 Select + 32 (level-1) double connect by level<=>
5 less
6 select + 58 (level-1) double connect by level<=>
7 less
8 select + 91 (level-1) double connect by level<=>
9 less
10. Select 123 + (level-1) from dual connect by level<=>
11 less
12. Select 255 double
13 )
14, ts as (select level r, substr (str, level 1) c
15 t
16 connect by level<=>
17 )
18, tf as (select row_number() (order for r) r
19 ,ts.c
20 TS
21 I join on (i.c = ascii (ts.c))
22 )
23 select replace (sys_connect_by_path(c,'!'),'! ') Str
24 TF
25 where connect_by_isleaf = 1
26 connect r = prior r + 1
27 * start with r = 1
SQL > /.STR
-----------------------------------------------------------------------------------------------------------------------
Thisisthemostamazingtest¸astringcosting5000Or something as horrible as this...
SQL > ed
A written file afiedt.buf1 with t as (select "[it comes of the #] [more amazing!") Test @# "$* & $%) assuming chain cost $ 5 000' double Str)
2, I like (select replace (sys_connect_by_path (chr (c), 'A'), 'A') as tr)
3 of)
4 select c, rownum r
5 (select 32 + (level-1) as the double connection by level c<=>
6 union
7 select + 58 (level-1) double connect by level<=>
8 union
9 select + 91 (level-1) double connect by level<=>
10 the union
11. Select 123 + (level-1) from dual connect by level<=>
12 union
13. Select 255 double
14 tri 1
15 )
16 )
17 where connect_by_isleaf = 1
18 log r = prior r + 1
19 start with r = 1
20 )
21 select translate (str, 'A' |) TR, 'A') as str
22 * t, I
SQL > /.STR
--------------------------------------------------------------------
Thisisthemostamazingtest¸astringcosting5000 -
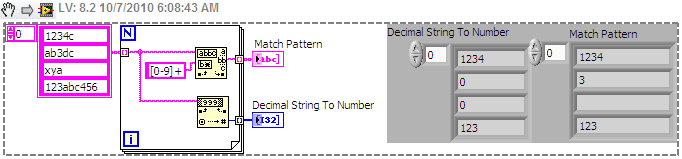
How to distinguish the figures and characters from a string
I am looking for a simple way to do this or any built-in subVIs that can do this.
I have 3 strings "1234c", "ab3dc". 'XYA', I want to identify those who have numbers and to reclaim all of the numbers. So an important step is to distinguish the character numeric and non-numeric characters. How can I do it in Labview with subVIs integrated?
Thank you

[0-9] is looking for a number, "+" makes the search for 1 or more of them (it is "greedy", so it will get as many as there are has). I added a rope in addition to your list to show that the Pattern Match will match only the first instance of a number. If there's a chance you have data as the last element that you need to run it in a loop. Decimal string number can also work if a figure is the first character that it finds.
-
How would extract everything before and after the LAST - (dash)?
Example: mt-st-marys-fl...
Everything preceding the latest scoreboard: mt-smarys
Everything that follows the latest scoreboard: fl
Before last dash: Replace(string, "-" & ListLast(string, "-"), "") After: ListLast(string, "-")
Mack
-
Remove characters from a string
I am currently developing a seqence for barcode analysis, then writes code-specific data bar to EA on the object to be measured. Here's my problem: a shot of uniqueness of the bar code contains several '-' brands. The raw data from bar codes are as follows "aaaa-bbbb-cccc-Davis-eeee." However, to write the data in EA, I need the shot in the following format: "aaaabbbbccccddddeeee". Is it possible to use Testand to revome the instance of "-" of the sting?
Thank you
Here's an option:
SearchAndReplace(Locals.InputString,"-","")
-
extract data from a string and compare it with sysdate
Hello
Since a few days I struggle to find a solution to my problem, maybe I have some luck here.
Data type:
11/23 ANA
Alex 19/11
1/11 tomorrow
03/12 FW1
Makes me tomorrow
Bo 11/12
Necessary data should be as MM/DD. I used substr and/or regexp_like, regexp_substr, but having a few problems.
Months can be like 1, 2.11, 12 or 01,02, 03... 11, 12.
I don't need the data in the format Month\Day.
Basically all of the above "/" should be a month.
And I need to get out all the foregoing, > 13.
And I need to compare the exp with sysdate.
Any ideas?
THX
something like:
FUNCTION to CREATE or REPLACE makeDate (in_string in VARCHAR2
in_format IN VARCHAR2: = ' MM/DD')
date of return
IS
BEGIN
To_date (in_string, in_format) return;
exception
When others then return null;
end;
/with sample_data as (choose 11/23 ANA' double str)
Union of all the
Select 19/11 Alex' double
Union of all the
Select 1/11 tomorrow "of the double
Union of all the
Select FW1 10/12 ' double
Union of all the
Select "Makes Me" tomorrow the double
Union of all the
Select ' Bo' 11/12 double
UNION ALL
SELECT 11/24 09:00 ' FROM dual
)
SELECT str
OF sample_data
WHERE REGEXP_LIKE (str, ' ^ [[: digit:]] {2} / [[: digit:]] {2}')
and makeDate (regexp_substr (str, ' ^ [[: digit:]]{2}/[[:digit:]]{2}'))]]))<>/
HTH
-
Hello
I need a SQL to meet the following requirements.
Table
Col1
A AND B
B C HAS
Output
Col1 Col2
A B AA B B
B C A B
B C C
C B A A
I can do via PLSQL. But I need it in a SQL.
Thank you
Hello
Here's one way:
SELECT col1
REGEXP_SUBSTR (col1,
, '[^ ]+'
1
LEVEL
) AS col2
FROM table_x
CONNECT BY LEVEL<= regexp_count="" (="">
, '[^ ]+'
)
AND PRIOR col1 = col1
AND PRIOR SYS_GUID () IS NOT NULL
;
Depending on your version, you may have to change the CONNECT BY clause.
-
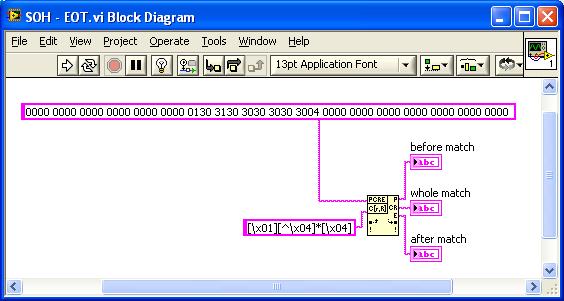
Remove the unused characters from string
Hi, I try to remove unused characters from a string, but I can't find a function for this.
The string like: 0000 0000 0000 0000 0000 0000 0130 3130 3030 3030 3004 0000 0000 0000 0000 0000 0000 0000, I need the characters from 01 to 04.
I need some advice.
If the characters between the SOH and EOT had a NULL value, then Match Regular Expression can be a choice:
Find \x01, find something else THAN \x04, then find \x04
-
How to remove the first 11 characters of a string
With the help of ' XML Publusher Desktop / generator model for Word / 5.6 Build 45'
I use XML Publisher. With the help of a RTF model, to generate purchase orders by email of the purchase of the Oracle.
The fields are drawn from the XML code generated by Oracle.
One of the fields is the place of delivery Description field.
Will appear in the report as follows:
* & lt;? SHIP_TO_LOCATION_NAME? & gt; *
When I attach a test XML file in Word and view the output, one of my test case returns a description of the site:
DON'T code USE County Hall of Global location
What I have to do is to remove the * DO NOT USE * according to the description of the location.
I could do is a Find / Replace, or a substring to ignore the first 11 characters from the string. But I don't know how to do it.
Any help would be much appreciated, because it is a production problem that is causing a bit of a small problem for us!
Thank you very much.Hello
Maybe you know this syntax :)Rahul
-
replace characters in the string
Hi all
Is it possible to index the characters in a string as if it were a table and remove them from the second position and now. I just want with the first letter or number so that I can later concatenate strings to it.
Thanks for any help!
-Michael
Hi Michael,
Yes. Use the function "Sring subset. At the beginning the value 0 (default value) and the length of 1.
This will give you the first character in the string.
Steve
-
How to extract the corresponding regex string
Hello
I am trying to extract text from a long string using QRegEx. Here's my regex:
Rx QRegExp ("^. *(192|210). * key =? *");
QString url = ""https://192.168.1.10/files/30/encrypt/key=s6h779bf " "
rx.setPatternSyntax (QRegExp::Wildcard);
rx.indexIn (str, 0);
qDebug()<>
qDebug()<>
However, it is does not match anything.
If I change the regular expression of "(192|210)." * key =? ' * ' can he match but I can't get the string after the = key
You use a regular expression capture if you want that the parameter "key."
QRegExp rx("^.*(192|210).*key=(.*)?"); qDebug() << rx.cap(1); // here's the first octet of your IP qDebug() << rx.cap(2); // key parameter (optional)Your regex could do with a lot of improvement in my humble opinion. You might want to consuder the class QUrl that does what you want already:
QUrl url("https://192.168.1.10/files/30/encrypt/key=s6h779bf"); qDebug() << url.queryItemValue("key");Tip: rubular is a handy Tester on the regex web which makes this kind of thing much easier to debug
-
Hello
I have a table that stores the ID as a varchar, but includes names alongside of the ID. I have a requirement to extract only the value inside the brackets as ID, see the sample data below:
create table test (id varchar2 (30),)
start_date date)
;insert into test values ("Joe Bloggs (HJUTJFDK)', September 11, 2009 '");
insert into test values ("Someone Else (GEORGE JGK)", September 11, 2009 ');
Insert test values ('AGHFJDKK', September 11, 2009 ');
Insert test values ('TRUTIRUT', September 11, 2009 ');Expected results:
ID
HJUTJFDK,
JULIEN OF EUREKA,
"AGHFJDKK,"
'TRUTIRUT '.
I tried the regexp_substr (ID,'[^ ()] * $'), but it returns the hook closed too)
Hello
sliderrules wrote:
Hello
I have a table that stores the ID as a varchar, but includes names alongside of the ID. I have a requirement to extract only the value inside the brackets as ID, see the sample data below:
create table test (id varchar2 (30),)
start_date date)
;insert into test values ("Joe Bloggs (HJUTJFDK)', September 11, 2009 '");
insert into test values ("Someone Else (GEORGE JGK)", September 11, 2009 ');
Insert test values ('AGHFJDKK', September 11, 2009 ');
Insert test values ('TRUTIRUT', September 11, 2009 ');Expected results:
ID
HJUTJFDK,
JULIEN OF EUREKA,
"AGHFJDKK,"
'TRUTIRUT '.
Here's one way:
SELECT id
REGEXP_REPLACE (id
, '.*\((.*)\).*'
, '\1'
) AS inside_parens
OF the test
ORDER BY id
;
What is the role of the start_date arguments in this problem?
Do not try to insert some VARCHAR2 values, such as September 11, 2009", in a DATE, as the start_date field. Use TO_DATE if you need to create a DATE from a string, or use DATE literals.
What happens if id contains 2 or more sets of parentheses? Can a set be nested insode another?
What happens if the parentheses are unbalanced, for example, if there is an uneven number of left "(d'et droit») of?"
If things like these issue, include examples in your sample data, the desired results and the explanation.
-
Bunch of Oracle on the special characters in a string - translate?
How to remove special characters in a string, it can contain. , (space), etc.
SELECT TRANSLATE('123.456 (90-90)', '', '') FROM DUALBasically I want to undress and to compare with the db value.
WHERE TRANSLATE(TABLE.NUMCODE, '', '') = TRANSLATE('123.456 (90-90)', '', '')Use TRANSLATE, since you're on 9i. For example:
TRANSLATE (your_string,'X,. #! % @$ ^ & * () _-+=', 'X')
Removes all the s characters in ', #! % @$ ^ & * () _-+=' of your_string.
SY.
-
Extract data from error HFM, float to Numeric?
Hi all
We extract data from HFM,.
HFM-> SQL-> FILE staging
Our mapping, flow, everything seems fine. When we run this out on the third market errors while extracting data with the following:
com.hyperion.odi.common.ODIHAppException: arithmetic overflow error conversion float type numeric data.
We researched and found to increase the logical length should solve this problem.
Our Source has a length of 16...
We have increased the logical length of target from 16 to 30, and he rest-error. We even tried 50, 100 for the logical length.
We are at Version 10.1.3.6.0.
Any suggestions on how to fix this?
Thank you!
Published by: user10678366 on May 22, 2013 13:28Have you tried changing the scale of all the columns float, right?
It can be a ridiculously large number coming from HFM. So, go to store for your data source in ODI and manually change the data type of column type VARCHAR of size like 100 or more. That would force the ODI to create the staging table with columns of characters for the field. Data will be retrieved anyway. Given that you write it in file, type of character should not matter. In addition, if writing to the file fails for any reason, you can do a max on the staging table and find the value problem in the table (while in HFM, you may not be able to do).
Maybe you are looking for
-
Re: Satellite L500D - how do I remove my sim card
HelloI saw the slot for sim card behind the battery and then to put a sim card, but now I have no idea how to get it.Can someone please?
-
I need drivers software and unlocked DNS server that works together
My messages are rejected by other networks and, and I get an error on a locked socket code. Code 10061 bed, acrobat reader doesn't let me access IE8. I can't set up roku because it cannot communicate with the server. I have 17 bad drivers. It's a mes
-
I get an error message 'Microsoft Shared Fax Driver' is not installed.
I was able to select 'Fax' from the list of printers and go through the Fax Wizard to send a document from my computer. Now, the document goes to the queue, but is not sent. The only message I get is that the Microsoft Shared Fax driver is not instal
-
Keyboard HP compaq nc 6220 enter button does not work
Cannot use enter to restart in safe mode, y does not work so I can't connect to windows
-
Deliver the WRE54G to computers windows XP
Hello I've configured my WRE54G. I had to update the firmware so I could use WPA. I am able to connect using a macbook pro or an iphone. It has really improved the scope, I can go to areas where they cannot even see the main router... So here all rig