Extract characters
Hello
I have a table that stores the ID as a varchar, but includes names alongside of the ID. I have a requirement to extract only the value inside the brackets as ID, see the sample data below:
create table test (id varchar2 (30),)
start_date date)
;
insert into test values ("Joe Bloggs (HJUTJFDK)', September 11, 2009 '");
insert into test values ("Someone Else (GEORGE JGK)", September 11, 2009 ');
Insert test values ('AGHFJDKK', September 11, 2009 ');
Insert test values ('TRUTIRUT', September 11, 2009 ');
Expected results:
ID
HJUTJFDK,
JULIEN OF EUREKA,
"AGHFJDKK,"
'TRUTIRUT '.
I tried the regexp_substr (ID,'[^ ()] * $'), but it returns the hook closed too)
Hello
sliderrules wrote:
Hello
I have a table that stores the ID as a varchar, but includes names alongside of the ID. I have a requirement to extract only the value inside the brackets as ID, see the sample data below:
create table test (id varchar2 (30),)
start_date date)
;insert into test values ("Joe Bloggs (HJUTJFDK)', September 11, 2009 '");
insert into test values ("Someone Else (GEORGE JGK)", September 11, 2009 ');
Insert test values ('AGHFJDKK', September 11, 2009 ');
Insert test values ('TRUTIRUT', September 11, 2009 ');Expected results:
ID
HJUTJFDK,
JULIEN OF EUREKA,
"AGHFJDKK,"
'TRUTIRUT '.
Here's one way:
SELECT id
REGEXP_REPLACE (id
, '.*\((.*)\).*'
, '\1'
) AS inside_parens
OF the test
ORDER BY id
;
What is the role of the start_date arguments in this problem?
Do not try to insert some VARCHAR2 values, such as September 11, 2009", in a DATE, as the start_date field. Use TO_DATE if you need to create a DATE from a string, or use DATE literals.
What happens if id contains 2 or more sets of parentheses? Can a set be nested insode another?
What happens if the parentheses are unbalanced, for example, if there is an uneven number of left "(d'et droit») of?"
If things like these issue, include examples in your sample data, the desired results and the explanation.
Tags: Database
Similar Questions
-
extract characters from a string
Hi gurus,
I want to extract the first, third, fifth, seventh... characters in a string.
not to extract characters from a subset of characters in a select query in oracle 9i database.
for example (1):
Assume that a string like this "SUE" is that I am 'ACEGI"of the source string
and the source can be any valid string, I just give an example here.
Example (2) of "kalpataru' in klatau'
Please guide me for thisfor 9i:
SQL> with t as ( select 'ABCDEFGHIJ' str from dual union select 'kalpataru' from dual ) -- -- select str, trim(extract(xmlagg(xmlelement(e, substr(str,level,1)) order by level),'//text()')) str2 from t where mod(level,2) = 1 connect by level <= length(str) and prior str = str and prior sys_guid() is not null group by str / STR STR2 ---------- -------------- ABCDEFGHIJ ACEGI kalpataru klaau -
I have a string ' CITY - NAME: NEW DELHI 12345'
I want characters like "CITYNAMENEWDELHI".Try
SELECT REGEXP_REPLACE ("CITY - NAME: NEW DELHI 12345', ' [^ A - Z]'," ") double;
or
SELECT REGEXP_REPLACE ("CITY - NAME: NEW DELHI 12345', '(*[^[:alpha:]])'," ") double;
-
How to display the three months by guest
Hello
I have a requirement in the dashboard,
There is a prompt of the month, if I select a month, it will show three months of data.
example, if I select '201108', it appears 201107,201108,201109.
If I use '+' or '-' in the calculation of the month, he has a problem, as in the whole of the year two, 201012,201101,201102.
So, how can I achieve this requirement?
Thank you!example, if I select '201108', it appears 201107,201108,201109.
If I use '+' or '-' in the calculation of the month, he has a problem, as in the whole of the year two, 201012,201101,201102.
I know that's not easy, but you have to think about it more logically. I know you got it to the point that you select month Jan or Dec as 201112 GOLD 201101.
FOR EXAMPLE: SUPPOSE I CHOSE 201112
Here you must create a report MID with 3 passes as CURR MTH, PRV MTH, NEXT MTH
In the COMING MONTHS apply a logic, such as:
-Convert "CURR MTH + 1' TANK '.
-2 EXTRACT CHARACTERS RIGHT
-EXTRACT IF = 13 THEN CONCAT (EXTRACT 4 TANKS LEFT - convert INT and add 1.) This will give you 2012 and concat with 01). New change to INT
Report: 201112, 201201, 201111FOR EXAMPLE: SUPPOSE I CHOSE 201101
PRV MTH apply logic as:
-Convert CHAR 'CURR MTH - 1'.
-2 EXTRACT CHARACTERS RIGHT
-EXTRACT IF = 00 THEN CONCAT (EXTRACT 4 TANKS LEFT - converted to INT and minus 1. This will give you 2010 and concat with 12). New change to INT
Report: 201101, 201102, 201012Just to play with String and cast OFF function make
The rest you know... Hope this helps
-
XMLType.extract cannot display French special characters in the select statement
Hello
E characters (acute e) get distorted when they are retrieved from the
XMLType column of an ordinary table.
How can we solve correctly get the characters e (acute e)?
We tried setting 'setenv NLS_LANG French_France.WE8ISO8859P1' and
"setenv NLS_LANG French_France.WE8DEC" before loading the table.
Database version:
The test sample case is as follows:SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - Production PL/SQL Release 11.2.0.2.0 - Production CORE 11.2.0.2.0 Production TNS for Linux: Version 11.2.0.2.0 - Production NLSRTL Version 11.2.0.2.0 - Production
Output is the following with setenv NLS_LANG French_France.WE8ISO8859P1--connect to any schema where you can store XMLType set long 2000; set pagesize 2000; set serveroutput on; --delete from test; drop table test; create table test (id number, xmldata XMLType); declare featureDescriptorXML CLOB; xml_type XMLType; new_xml_type XMLType; myName varchar2(100); myName2 varchar2(100); myName3 varchar2(100); stmt varchar2(4000); begin featureDescriptorXML := '<?xml version="1.0" encoding="UTF-8"?>' || '<abc:TheFeature xmlns:' || 'de' || '="' || 'http://abc.klmno.org/fghde' || '" xmlns:abc="http://www.ghijklmn.net/abc"' || ' xmlns:xyz="http://www.ghijklmn.net/xyz">' || '<abc:Name>de:MyGénérique</abc:Name>' || '</abc:TheFeature>'; xml_type := xmltype(featureDescriptorXML); myName := xml_type.extract('/abc:TheFeature/abc:Name/text()', 'xmlns:abc="http://www.ghijklmn.net/abc"').getStringVal(); dbms_output.put_line('abc:Name value stored in VARCHAR2 variable from XMLType variable is ' || myName); -- can show French chars insert into test(id, xmldata) values(20, xml_type); stmt := 'select t.xmldata.extract(''/abc:TheFeature/abc:Name/text()'', ''xmlns:abc="http://www.ghijklmn.net/abc"'').getStringVal() from test t'; execute immediate stmt into myName2; dbms_output.put_line('abc:Name value stored in VARCHAR2 variable from XMLType column in 2nd version is ' || myName2); -- cannot show French chars stmt := 'select t.xmldata from test t'; execute immediate stmt into new_xml_type; myName3 := new_xml_type.extract('/abc:TheFeature/abc:Name/text()', 'xmlns:abc="http://www.ghijklmn.net/abc"').getStringVal(); dbms_output.put_line('abc:Name value stored in VARCHAR2 variable from first XMLType column and then from XMLType variable in 3rd version is ' || myName3); -- cannot show French chars end; / select t.xmldata.extract('/abc:TheFeature/abc:Name/text()', 'xmlns:abc="http://www.ghijklmn.net/abc"').getStringVal() from test t; -- Cannot show French chars select t.xmldata.extract('/abc:TheFeature/abc:Name/text()', 'xmlns:abc="http://www.ghijklmn.net/abc"').getStringVal() "myname" from test t; -- Cannot show French chars select t.xmldata.getCLOBVal() from test t; -- Cannot show French chars select t.xmldata from test t; -- Can show French chars
and NLS_DATABASE_PARAMETERS are the following:SQL> select * from nls_database_parameters; PARAMETER VALUE ------------------------------ ---------------------------------------- NLS_LANGUAGE AMERICAN NLS_TERRITORY AMERICA NLS_CURRENCY $ NLS_ISO_CURRENCY AMERICA NLS_NUMERIC_CHARACTERS ., NLS_CHARACTERSET WE8DEC NLS_CALENDAR GREGORIAN NLS_DATE_FORMAT DD-MON-RR NLS_DATE_LANGUAGE AMERICAN NLS_SORT BINARY NLS_TIME_FORMAT HH.MI.SSXFF AM PARAMETER VALUE ------------------------------ ---------------------------------------- NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR NLS_DUAL_CURRENCY $ NLS_COMP BINARY NLS_LENGTH_SEMANTICS BYTE NLS_NCHAR_CONV_EXCP FALSE NLS_NCHAR_CHARACTERSET AL16UTF16 NLS_RDBMS_VERSION 11.2.0.2.0 20 ligne(s) sélectionnée(s).
We also tried affecting NLS_CHARACTERSET AL32UTF8Table creé. abc:Name value stored in VARCHAR2 variable from XMLType variable is de:MyGénérique abc:Name value stored in VARCHAR2 variable from XMLType column in 2nd version is de:MyGénérique abc:Name value stored in VARCHAR2 variable from first XMLType column and then from XMLType variable in 3rd version is de:MyGénérique Procdure PL/SQL terminée avec succès. T.XMLDATA.EXTRACT('/ABC:THEFEATURE/ABC:NAME/TEXT()','XMLNS:ABC="HTTP://WWW.GHIJK -------------------------------------------------------------------------------- de:MyGénérique myname -------------------------------------------------------------------------------- de:MyGénérique T.XMLDATA.GETCLOBVAL() -------------------------------------------------------------------------------- <?xml version="1.0" encoding="DEC-MCS"?> <abc:TheFeature xmlns:de="http://abc.klmno.org/fghde" xmlns:abc="http://www.ghij klmn.net/abc" xmlns:xyz="http://www.ghijklmn.net/xyz"> <abc:Name>de:MyGénérique</abc:Name> </abc:TheFeature> XMLDATA -------------------------------------------------------------------------------- <?xml version="1.0" encoding="ISO-8859-1"?> <abc:TheFeature xmlns:de="http://abc.klmno.org/fghde" xmlns:abc="http://www.ghij klmn.net/abc" xmlns:xyz="http://www.ghijklmn.net/xyz"> <abc:Name>de:MyGénérique</abc:Name> </abc:TheFeature>
by CHARACTER SET of ALTER DATABASE.
the database is closed and restarted.
But that did not help.
Thank youOk. Wasn't sure. Thank you for that clarification.
.. .but please make an attempt with XMLTABLE XMLQUERY, XMLCAST (or CAST) and other XML functions that support XQuery and not to use the engine of 'old '... I hope that these features will keep things as it should...
.. .If not... create an SR with support of Oracle on this issue. Changes, if you base your SR on these 'old' operators XML/SQL and functions that are her will not be able to help, mainly due to the fact that your last version and stuff like EXTRACT / getStringVal() etc. are announced officially discouraged in this 11.2.0.2.0 version. As far as I know the t.xmldata.extract, the xml_type.extract and the other syntaxes, outlaw count of 10.1 (although I know, he appealed to java / OO people kind).
Published by: Marco Gralike April 5, 2011 19:50
-
extract only some characters of a coloumn
the chain of value in coloumn ERROR_ROW (the field name is ERROR_ROW)
Salesperson code: RFD, product code: GLU 065405: BT, date of invoice: 16 March 09, the invoice No.: 41001418, quantity: 3, price: 13.49, amount: 40.47, distributor HIN: G74LA4Q00, HIN client: AHW6WQF00, Source: SS, REF ID from: 35950268, HIN warehouses: KE12PF500, Trans line no: 4436, Bill: 211907, ship to: AHW6WQF00, identifier of sales: 21, Zip: 45133
I have a thousand rows in this table
Using SQL
I want to extract the values of the XXXXXXX (abouve example 41001418)
in the example charactors between invoice No.: XXXXXXX, * amount *.
These characters between "Invoice number" and "Quantity" must be extracted from all lines
Note: the value of
vendor code
product code
UNIT OF MEASURE
Its value will vary
Thanks in advance
MAhNOT TESTED
substr(error_row, instr(error_row,'Invoice no:') + 12, instr(error_row,',',instr(error_row,'Invoice no:'),1) - instr(error_row,'Invoice no:') - 12) )Concerning
Etbin
Assume that "quantity:' does not always follow ' invoice No. :'-> looking for the first comma after" invoice No.:'
Edited by: Etbin on 26.6.2009 18:07
-
Extracting columns with non-English characters?
Hello
I have a query using SQL Developer on a table that contains several names of companies from different countries, and is one of the controls I should do to ensure consistency of data to find all the rows that the company name contains special or non-English characters (such as c, a, as example).
I don't know what can I use to do this. I tried to gather using NLS_SORT, but it did not work.
Is there a way to select only the lines that contain these special characters or non-English, excluding the results the lines containing only English characters? Please have in mind that we have a lot of languages in this table.
The area that I would like to make the conditions is VARCHAR2.
Please let me know if there is any additional information I should give you so that you can help me.
Thanks in advance for the help.
Kind regards
LuisJust list all characters that or not special for you, use something like
with test as ( select 'Behringer Harvard Eldridge Venture, LLC' txt from dual union select 'Behringer Harvard Redwood, LLC' from dual union select 'Behringer Harvard Lovers Lane Venture I, LLC' from dual union select 'Atlas Pipeline Mid-Continent KansOK, LLC' from dual union select 'AB JÄRNBJÖRNEN' from dual union select 'FRONTBILAR I GÖTEBORG AB' from dual union select 'ARANDA HERMANOS MUEBLERÍA, S.A. DE C.V.' from dual ) select * from test where translate( txt, chr(0) || 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789.,- ', chr(0) ) is not null -
How to: Extract the first three characters of a text field
Greetings-
What is the best method to extract the first three letters of a text field?
I need to extract the first three letters of a text field (surname in this case),
so I add other components to create an identification number for
a person.
This identification number which must be created consists of the
date of the person by birth, last 4 digits of social security number and
the first three letters of the person's first name.
Example:
== > Date of birth: 15/11/45
== > Last 4 SSN: 6654
== > Name: Smith
Identification number would be:
== > 1115456654SMI
Leonard B
That should do the trick:
I put your values in the variable, simply replace the names, according to the needs
This removes all the string of the / your birthday (if it's a string!) and puts it in the variable id:
It takes the 4 last letters/digits of your social security number string and adds it to the id:
It takes the first thre letters/numbers from your last name variable, capitalizes and adds to the identification string
It will be useful.
-
Extraction or decoding of characters
Hello
I need to extract a character, for example
0150 to 01h50m. To separate the hours of the minutes.
How can this be achieved?
Thank you!Assuming that it is a string (when it should be a DATE)
select substr (str, 1, 2)||'h'|| substr (str, -2)||'m' from xas in
SQL> with x as 2 (select '0150' str from dual) 3 select substr (str, 1, 2)||'h'|| 4 substr (str, -2)||'m' 5 from x 6 / SUBSTR ------ 01h50m -
How to extract the last 5 characters of the column CLOB001?
Hi all
I've set up an external WS in the APEX and now I want to create a report with the following query:
Select dbms_lob. Substr (CLOB001, 5, -5) 'Test '.
of APEX_collections
where collection_name = "P422_CHECKVAT_RESULTS";
What I want to do is to retrireve the last 5 characters in the CLOB, has anyone any ideea how I can do this?
Kind regards
Ana-MariaSELECT dbms_lob.Substr(CLOB001,dbms_lob.getlength(CLOB001),dbms_lob.getlength(CLOB001)-5 ) test FROM HTMLDB_COLLECTIONS WHERE COLLECTION_NAME ={code} Hope this helps... Tyson -
How to extract the characters of mixed string?
"I have a string like ' ORA123CLE * () ^ % ^ & NET + -* / WORK"
I need output like-> ORACLENETWORK
Hello Bharathoracle
SELECT REGEXP_REPLACE (' (ORA123CLE) * ^ % ^ & NET + -* / WORK ',' [^ [: alpha:]]', ") FROM DUAL;
Kind regards
David
-
I would use Yuanti SC police for my web development project. However, my developer is not able to use the file .ttc I extracted from the library of fonts, and .ttf, .otf .woff formats not available anywhere on the web. Please, let me know how can I use this font for my project.
Thank you
Anton
Unless the site you develop is for the Asian market, I don't know why you want to use that particular font. The Basic, standard and digital alphabet punctuation glyphs has sans serif, Roman characters, but the rest is thousands of Kanji characters. While you can use the font .ttf and .otf and web fonts, it would be very unusual to use one so great. Pages should load quickly and 78 MB, with a value of faces to download for those who have connections slow Internet is not fast.
I would take a different font without serifs. There are literally thousands who look identical or virtually identical to Yuanti.
131 free and high quality without font serif to choose here. I'm sure you can find a desired.
-
Separation of the characters in a string
I have a string in which all characters are separated by a space. I want to extract each of these characters to different substrings. Is there a way to do this?
For example: a string of parent : 1 g 3: 00 p
need =>
channel 1: 1
Channel 2: a
Channel 3: g
Channel 4:3
Channel 5: h
Sun 6: p
Thank you.
I would use the spreadsheet String to Array with a space defined on the delimiter.
-
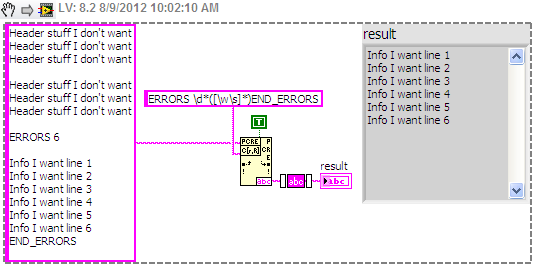
Regular expression help please. (extraction of a subset of the string between two markers)
I haven't used regular expressions before, and I can't find a regular expression to extract a subset of the string between two markers.
The chain;
Stuff of header I want
Stuff of header I want
Stuff of header I wantStuff of header I want
Stuff of header I want
Stuff of header I want6 ERRORS
Info I want to line 1
Info I want line 2
Info I want line 3
Info I want to line 4
Info I want to line 5
Info I want line 6
END_ERRORSFrom the string above (it is read from a text file), I try to extract the subset of string between ERRORS 6 and END_ERRORS. The number of errors (6 in this case) can be any number from 1 to 32, and the number of lines I want to extract will correspond with this number. I can provide this number of a caller VI if necessary.
My current solution, which works, but is not very elegant;
(1) using Match Regular Expression for the return of the string after you have synchronized the 6 ERRORS
(2) uses the Regular Expression matches to return all characters before game END_ERRORS of the string returned by (1)
Is there a way this can be accomplished using 1 Regular Expression Match? If so someone could suggest how, as well as an explanation of the work of the given regular expression.
Thank you very much
Alan
I used a character class to catch any word or whitespace characters. This put inside parentheses a substring matching the criteria that you can get by developing the node for regular expression matching. The \d matches the numbers and the two * s repetition of the previous term. So, \d* will find the '6', as well as "123456".
-
Extract ODBC data Long field names
I need to extract some data created by the 4 lookout data logging (files .thd). Is it possible to do so. I use a PC that does not have installed belvedere, I only database files
What I got so far is to export some fields whose names are less than 62 characters (using the program Logos 4.5 and driver ODBC database of 4 of Citadel by strict limitation of the field at 62 names). If I increase the limit to about 100 required to extract all the fields I can't export to Microsoft Query or any other software (which supports the import of ODBC database). I've tried several programs but usually they jump a message you can read that one point in time (or they do not see the fields or values at all)
Please, can you tell me a way I can extract the data?
The lifecycle of database is not applied in an aggressive manner. The database do not try and remove data simply because life has expired. On the contrary, the life expectancy is applied only when new data are currently recorded in the database and the log would need to increase the size of the database to store incoming data. The rate at which data are removed from the database may vary according to the rate at which new data are recorded in the database. If the frequency of recording is slow, it may take a long time for the data to be deleted.
J.D. Robertson
National Instruments
Maybe you are looking for
-
Why can't I get RoboForm appears on FireFox Version 7?
I am running Windows 7 Professional on my laptop. I've always had RoboForm works on my other previous versions of FireFox. I can't even RoboFom icon. I went to view then toolbars and still it has not shown in section toolbar. I even uninstalled FireF
-
The size of the library user & mobile Documents
Since his arrival in iCloud my library in my username is passed about 30 GB to 200 GB and I can see that the Documents Library Mobile is where the increase has disappeared. Why is it so? Do this? I'm doing something wrong? It caused my iMac almost do
-
LabVIEW VI error when executing DLL functions
Hello OR developers! I have driver for windows application created by Jungo WinDriver program for PCI-E card. Application works very well. I have edited and compiled the project as DLL manual suite. I can read successfully resource information of the
-
How to stop the mail sent to members of my list of contacts from my hotmail account
The mail is sent from my account to members of my list of contacts, how can I stop this
-
When electronic mail, I get a message that before I can send my messages, I need to open a new window and enter the numbers that appear. But when I go to this window, the box for the figures does not open.