Generate random data by using lookup tables
I have 2 tables. Student_subject table contains the list of the students and they are enrolled in subjects.Table Subjent_mark contains valid degrees, a student can have for a topic.
I want to generate data for all students with valid marks randomly.
Examples of data include:
with student_subject as
(select '111' student_id
'rea' subj_id
of the double
Union
Select '111' student_id
subj_id 'wri '.
of the double
UNION
Select '111' student_id
subj_id 'ss '.
of the double
Union
Select '111' student_id
"sci" subj_id
of the double
Union
Select '222' student_id
'rea' subj_id
of the double
Union
Select '222' student_id
subj_id 'wri '.
of the double
UNION
Select '222' student_id
subj_id 'ss '.
of the double
Union
Select '222' student_id
"sci" subj_id
of the double
Union
Select '333' student_id
'rea' subj_id
of the double
Union
Select '333' student_id
subj_id 'wri '.
of the double
UNION
Select '333' student_id
subj_id 'ss '.
of the double
Union
Select '333' student_id
'mus' subj_id
of the double
Union
Select '444' student_id
'rea' subj_id
of the double
Union
Select '444' student_id
subj_id 'wri '.
of the double
Union
Select '444' student_id
subj_id 'ss '.
of the double
Union
Select '444' student_id
'mus' subj_id
of the double
Union
Select '444' student_id
"sci" subj_id
the double)
subject_mark as
(
Select
'rea' subj_id,
' O '
of the double
Union
Select
'rea' subj_id,
THE OF '
of the double
Union
Select
'rea' subj_id,
« N »
of the double
Union
Select
'rea' subj_id,
« P »
of the double
Union
Select
subj_id "wri"
' O '
of the double
Union
Select
'rea' subj_id,
THE OF '
of the double
Union
Select
'rea' subj_id,
« N »
of the double
Union
Select
subj_id "ss."
« A »
of the double
Union
Select
subj_id "ss."
« B »
of the double
Union
Select
subj_id "ss."
« C »
of the double
Union
Select
subj_id "ss."
A '
of the double
Union
Select
subj_id "ss."
« E »
of the double
Union
Select
"sci" subj_id,
« A »
of the double
Union
Select
"sci" subj_id,
« B »
of the double
Union
Select
"sci" subj_id,
« C »
of the double
Union
Select
"sci" subj_id,
A '
of the double
Union
Select
"sci" subj_id,
« E »
of the double
Union
Select
'mus' subj_id,
« A »
of the double
Union
Select
'mus' subj_id,
« P »
of the double
Union
Select
'mus' subj_id,
"NA".
the double)
SELECT * FROM subject_mark has.
student_subject b
where
a.subj_id = b.subj_id
Something like that...?
SELECT student_id, SUBJ_ID, subj_mark
from (
SELECT b.student_id, b.SUBJ_ID, a.subj_mark
, row_number() over(partition by b.student_id, b.subj_id order by dbms_random.value) as mark_num
FROM subject_mark a, student_subject b
WHERE a.subj_id = b.subj_id
)
where mark_num = 1
order by student_id, subj_id
;
STUDENT_ID SUBJ_ID SUBJ_MARK
---------- ------- ---------
111 rea O
111 sci A
111 ss D
111 wri O
222 rea P
222 sci D
222 ss B
222 wri O
333 mus A
333 rea P
333 ss C
333 wri O
444 mus A
444 rea N
444 sci B
444 ss E
444 wri O
17 rows selected
... (assuming that you add subj_mark as an alias in your query of subject_mark)
Kind regards
Bob
Tags: Database
Similar Questions
-
Hello
Where we use lookup table?
Thank you
POOJA
Hi Pooja,
Look up table stores data. Look up table data is automatically updated with other data.
It is used in the "update rule". Look up table has two columns, one for the original values for the changed values.
Here is a link where you can get more help on implementing of lookup table:
"If this, then that"-a Guide to create Lookup Tables in Eloqua
The link "update rule:
How to run an update rule set with a Table of choice on a shared list
I hope this helps.
Kind regards
Eloqua Experts Edynamic
-
Use SQL statements to roll a calendar forward to a random date
Hello
Oracle 10.2.0.4 Linux
We have two tables largeish (10 ^ 5 rows each) who follow our planned workforce hours. The first table created generic programs that show the days, at that each must have Schedule 1-n lines in this document, one for every day of the cycle. The majority of our workforce is on a 8 day cycle. In the example below, I have two shifts
Sched_4d it is a cycle of four days from the day - the day pairs off.
Sched_3d cycle this is a full day off, half day, day off.
According the information below you can see that in 1990, the sched_4d went to a day of 8 hours to 9 hours a day. There is no guarantee that SCHED_4D will not win suddenly 2 additional days in this years union negotiations.
The second table is a simple assignment table when a person goes on a calendar.
To determine the schedule for the day a datum, you look at the table EMP_SHIFT to determine which calendar is 'in progress', then you look at the date at which the person has been assigned to the planning and guess that's SHIFT_ID 1, the next day is SHIFT_ID 2 until complete you the cycle and try again.
CREATE TABLE SCHED_DATA
(
SCHED_ID VARCHAR2 (8 CHAR) NOT NULL,
ASOFDATE DATE NOT NULL,
SHIFT_ID NUMBER (3) NOT NULL,
SCHED_HRS NUMBER (4,2) NOT NULL
)
;
CREATE UNIQUE INDEX SCHED_DATA on SCHED_DATA (SCHED_ID, ASOFDATE, SHIFT_ID)
;
CREATE TABLE EMP_SHIFT
(
EMPID VARCHAR2 (15 CHAR) NOT NULL,
ASOFDATE DATE NOT NULL,
SCHED_ID VARCHAR2 (8 CHAR) NOT NULL
)
;
CREATE UNIQUE INDEX EMP_SHIFT on EMP_SHIFT (EMPID, ASOFDATE, SCHED_ID)
;
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1980 ', 1, 8);
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1980 ', 2, 0);
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1980 ', 3, 8);
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1980 ', 4, 0);
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1990 ', 1, 9);
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1990 ', 2, 0);
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1990 ', 3, 9);
INSERT INTO SCHED_DATA VALUES ('SCHED_4D', 1 JANUARY 1990 ', 4, 0);
INSERT INTO SCHED_DATA VALUES ('SCHED_3D', 1 JANUARY 1990 ', 1, 8);
INSERT INTO SCHED_DATA VALUES ('SCHED_3D', 1 JANUARY 1990 ', 2, 4);
INSERT INTO SCHED_DATA VALUES ('SCHED_3D', 1 JANUARY 1990 ', 3, 0);
INSERT INTO EMP_SHIFT VALUES ('001', 20 DECEMBER 1989', 'SCHED_4D');
INSERT INTO EMP_SHIFT VALUES ('001', 1 JANUARY 1990', 'SCHED_4D');
INSERT INTO EMP_SHIFT VALUES ('001', 3 JANUARY 1990', 'SCHED_3D');
In view of the above, I need to write a select statement receives 2 dates (: of and: to) and for all employees of EMP_SHIFT returns one row for each day and the hours for that day.
Thus, the data above with one and from 21 December 1989 ': 5 January 1990 ' should return
EMPID, DATE, SCHED_HOURS
001, 21 - DEC, 0
001, 22 - DEC 8
001, 23 - DEC, 0
001, 24 - DEC 8
001, 25 - DEC, 0
001, 26 - DEC 8
001, 27 - DEC, 0
001, 28 - DEC 8
001, 29 - DEC, 0
001, 30 - DEC 8
001, 31 - DEC, 0
001, 01 - JAN 9
001, 02 - JAN, 0
001, 03 - JAN 8
001, 04 - JAN 4
001, 05 - JAN, 0
The employee began thir mission to sched_4d the 20 - DEC, then it would be SHIFT_ID 1. DEC 21 - Therefore SHIFT ID 2, which is 0 hours. Cycle until the next event which is 01 - JAN, when they are assigned to the new sched_4d who work 9 hours on day 1. 03 - JAN they pass to the new cycle and go to the 8:4:0 rotation.
I can see how I could
SELECT EMPID, DAY_OF_INTEREST, SCHED_ID
EMP_SHIFT a, (SELECT 1 January 1979 ' + rownum 'DAY_OF_INTEREST' from dual connect by level < = 10000)
WHERE A.ASOFDATE = (SELECT MAX (A1. ASOFDATE) OF A1 EMP_SHIFT WHERE A1. EMPID = A.EMPID AND A1. ASOFDATE < = DAY_OF_INTEREST)
AND DAY_OF_INTEREST BETWEEN: FROM_DT AND: TO_DT
And I guess I need to use some kind of MOD ((DAY_OF_INTEREST - EMP_SHIFT. ASOFDATE), (#number of days of shift)) which shift_id applies to a given Day_of_interest
But I'm struggling to do this in a way that could evolve to more than one employee,
The analytical functions achieve neatly?
Hello
There are several analytical functions that might help here. Two tables include only; departure dates we need to know the end dates of both employee assignments regarding schedules. I used the analytical functions MIN and LEAD to get these in the query below. In addition, the following query needs to know how many days is in each Annex. I used the analytical COUNT function for that.
WITH params AS
(
SELECT TO_DATE (December 21, 1989 ","DD_MON-YYYY"") AS start_date
, TO_DATE (5 January 1990 ', 'DD_MON-YYYY') AS end_date
OF the double
)
all_dates AS
(
SELECT the LEVEL - 1 AS a_date + start_date
OF params
CONNECT BY LEVEL<= (end_date="" +="" 1)="" -="">
)
sched_data_plus AS
(
SELECT sched_id, asofdate, shift_id, sched_hrs
NVL (MIN (asofdate) over (PARTITION BY sched_id
ORDER BY asofdate
RANGING FROM 1 TO MORE
AND UNBOUNDED FOLLOWING
) - 1
, TO_DATE (31-DEC-9999', 'DD-MON-YYYY')
) AS uptodate
, COUNT (*) OVER (PARTITION BY sched_id
asofdate
) AS days_in_sched
OF sched_data
)
emp_shift_plus AS
(
SELECT empid, asofdate, sched_id
NVL (in ADVANCE (asofdate) OVER (PARTITION BY empid
ORDER BY asofdate
) - 1
, TO_DATE (31-DEC-9999', 'DD-MON-YYYY')
) AS uptodate
Of emp_shift
)
SELECT e.empid
d.a_date
s.sched_hrs
Of all_dates d
JOIN the s sched_data_plus WE d.a_date BETWEEN s.asofdate
AND s.uptodate
JOIN e-emp_shift_plus WE d.a_date BETWEEN e.asofdate
AND e.uptodate
AND e.sched_id = s.sched_id
AND MOD (d.a_date - e.asofdate)
s.days_in_sched
) + 1 = s.shift_id
ORDER BY e.empid
d.a_date
;
This request is started by getting daily interest, that is, every day between the given - start and end dates. (When you said "random date", I assume you meant 'a date', data which may not involve any random element.)
Once we have a list of all the dates of interest, to get the results you want is just a matter of inner join to get the schedules were in effect on these dates, and which employees were assigned to these annexes to these dates.
If you are worried about having more than 1 employee, maybe you should post the sample data that has more than 1 employee.
How do you manage the endings of the employee? For example, what happens if the employee 001 had left on January 4, 1990? I guess that you would like the output for this employee stop January 4, rather than continue to the end of the period that interests us.
If you have dates of termination in an employee table not shown here, then you can use this date of termination instead of December 31, 9999 as the end date by default of the assignments. If you have a special schedule for endings (or leave, by the way) you'll probably want to include a WHERE clause in the main query does not display dates after the employee left (or when the employee was on leave).
-
Need help in generating XML data to a table in XML format
Hi all
I need help to generate an xml file using the data below.
The table name is T_Data have 4 columns as shown below with data.
Neighbourhood region Division
---------- ----------------------- ----------- -----------
Northwest Northern California San Jose SJStore1
Northwest Northern California San Jose SJStore2
Northwest North of California to the North of THE LAStore1
Northwest North of California to the North of THE LAStore2
Northwest North of California to the North of THE LAStore3
I want to generate an XML file using SQL/XML functions and the XML file should look like as below.
<>region
< name of region > Northwest < / name of the region >
< Division >
Northern California < division name > < / Division name >
District of <>
SanJose < district name > < / District name >
<>store
< store name > SJStore1 < / name >
< store name > SJStore2 < / name >
< / store >
< / district >
< / division >
< / region >
Very much appreciate your help here.
Thank you.I tried to group the lines, but they did not then provide a correct output.
To unflatten dataset, we can use nested GROUP-BY subqueries.
The following will produce a line by region.
If all regions must be grouped in a single root element (does not so appear according to the directives of the sample), we just add an another XMLAgg.SQL> with sample_data as 2 ( 3 select 'Northwest' reg, 'Northern California' div, 'San Jose' district, 'SJStore1' st from dual union all 4 select 'Northwest' reg, 'Northern California' div, 'San Jose' district, 'SJStore2' st from dual union all 5 select 'Northwest' reg, 'Northern California' div, 'North LA' district, 'LAStore1' st from dual union all 6 select 'Northwest' reg, 'Northern California' div, 'North LA' district, 'LAStore2' st from dual union all 7 select 'Northwest' reg, 'Northern California' div, 'North LA' district, 'LAStore3' st from dual 8 ) 9 select reg 10 , xmlserialize(document 11 xmlelement("Region" 12 , xmlelement("RegionName", reg) 13 , xmlagg( division_xml ) 14 ) 15 indent -- for display purpose 16 ) as region_xml 17 from ( 18 select reg 19 , xmlelement("Division" 20 , xmlelement("DivisionName", div) 21 , xmlagg( district_xml ) 22 ) as division_xml 23 from ( 24 select reg 25 , div 26 , xmlelement("District" 27 , xmlelement("DistrictName", district) 28 , xmlelement("Store" 29 , xmlagg( 30 xmlelement("StoreName", st) 31 ) 32 ) 33 ) as district_xml 34 from sample_data 35 group by reg 36 , div 37 , district 38 ) 39 group by reg, div 40 ) 41 group by reg ; REG REGION_XML --------- -------------------------------------------------------------------------------- NorthwestNorthwest Northern California North LA LAStore1 LAStore3 LAStore2 San Jose SJStore1 SJStore2 -
Inserting data in several related tables using the database
Hello world
I'm working on a BPM application using Oracle BPM 11.1.1.5.0 and JDeveloper 11.1.1.5.0.
In my database, I have two tables, loan and guarantee that are related by a field named employeeID (PK on loan) and FK in warranty.
Each line can have several lines of guarantee.
At this point, I'm doing an entry form for the user to insert data in the two tables.
I did successfully before with a single table that has no relations.
The way I'm doing here is, after the creation of the database successfully adapter, a type of LoanCollection is created in the types module, which can be used to create business objects and data objects of.
The problem is when I create an object of type loanCollection process data and then create a UI generated automatically on that basis, only the fields in the primary table (the Table of loan) appear in the form.
On the other hand, if I create a business object based on the LoanSchema, the form for all of the two tables is created automatically (the loan as a form, the guarantee in a table), but then, when I try to access it in the section processing service mission which calls the database adapter, I have no access to such.
In fact, the only type which can be used in the service task is the process based on the loanCollection data object.
To summorize, I have to use the type of business for my UI object to include all the fields in both tables, so I have to use the data object from the collection process in the transformation of service task dialog box.
And I can't find a way to map to another.
Can someone help me with this please?
Thank you very muchTry to follow these steps.
1. create a new module in your catalogue our BPM project management section
2. in this new module create 3 Business Objects - (LoanBusinessObject, GuaranteeBusinessObject and GuaranteeArrayBusinessObject)
3. Add the attributes appropriate to the LoanBusinessObject and the GuaranteeBusinessObject so that they mimic your database tables, then to the GuaranteeArrayBusinessObject add an array of type attribute GuraranteeBusinessObject
4. now you need to create two process data objects, type loanProcessObject LoanBusinessObject and type guaranteesProcessObject GuaranteeArrayBusinessObject
5. as inputs to your human task adds the loanProcessObject and guaranteesProcessObject, these should now be available in your data controls and can be used to auto generate the form
6. in your dbadapter you'll then use XSL Transformation and use for each so that it will write the data to the ready table and all the line items of warranty for the warranty table. -
Using data from the control table
Hello
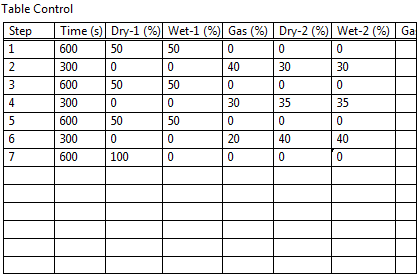
I would like to use the data entered in a table to automate volume/sequence of airflow for a test Chamber. As shown in the screenshot of control table, the first column indicates the number of iterations by elements of array in a series of tests and the second data column specifies the length of each line sequence. Entries in the other columns are specific to different valves and specify values set required in the flow meter.
I guess my question is how can I index/assign each column of the table such that the data to exploit the respective valves are obtained in subsequent iterations all acquire simultaneously with data from other components in the order? While I recognize that the solution may be very simple, I searched on through various examples and messages on the tables and the tables without knocking on a solution. The attached .vi allows me to be a part of the series of tests.
Best regards
Callisto
Hi Callisto,
If I understand your question then the solution is actually quite simple. The important point to keep in min is the fact that the Table control can actually be treated as an array of string. You can then use all the traditional table manipulation tools and techniques to manipulate your data as you wish. For example, use the Array Index function to retrieve specific columns and then if you want to spend the individual elements in a column in a loop, wire the table until the loop and ensure that indexing is enabled. If you then want to use these data elements to control your test application, you can convert a portion of the resulting string in more useful to digital.
All these concepts are illustrated in the attached VI. I hope this helps, but let me know if you have any other questions.
Best regards
Christian Hartshorne
NIUK
-
Best way to parse a string for use in a lookup table?
I am trying to create a system by which users can create a premade simulation and store simulations in order to easily load at their convenience. The way it works now is that when the user creates a simulation, information on the characteristics of the simulation are condensed down to a 12 string, which is written in a text file with the same name as its content. This string is then read, and ideally, I would have some sort of lookup table to convert characters in the information they have been condensed to. For example, a variable X can have possible values {650,720,851} who gets the mapping to {A, B, C} during the creation process. When loading, I would be able to send in a Sub C - VI and took her out in 851, group in a cluster. How can I perfectly realize this in LV? So far the best I have is this messy thing:

Basically, who runs the string character by character and includes the appropriate value for the character at the given offset.
You want to use the configuration VI palette.
These screws makes it stupid simple save and load the values in the file by using Sections and keys.
You can use the keys 'A', 'B' or 'C' and section 'X' to complete your example.
-
Date of max from the entire lookup table
Hello people:
I hope that this discussion finds you well. I have 2 tables (MED_IMMUNO and LU_MED_IMMUNO). "MED_IIMMUNO" is the base table, and "LU_MED_IMMUNO" is the lookup table for the column 'IMM_REC '. Please see CFDS below:
TABLE: MED_IMMUNO
CREATE TABLE 'MED_IMMUNO' ('ID', 'EMP_ID' NUMBER, NUMBER OF "IMM_REC", "IMM_DATE" DATE, VARCHAR2 (255) 'IMM_NOTES', 'IMM_APPLICABLE' NUMBER, NUMBER OF "IMM_REFUSED")
/
INSERTION of REM in MED_IMMUNO
TOGETHER TO DEFINE
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (55,8474,5,to_date('12-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (56,8474,6,to_date('26-JUN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (57,8474,8,to_date('10-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (58,8474,9,to_date('13-FEB-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (59,8474,10,to_date('26-JUN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (60,8474,22,to_date('10-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (61,8474,4,to_date('10-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (62,8474,16,to_date('10-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (63,8474,17,to_date('10-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (64,8474,11,to_date('10-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (65,5900,1,to_date('19-JUN-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (66,5900,2,to_date('17-JUL-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (67,5900,3,to_date('20-DEC-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (68,5900,22,to_date('19-JAN-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (69,5900,4,to_date('19-JAN-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (70,5900,14,to_date('19-JAN-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (71,5900,17,to_date('19-JAN-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (72,5900,16,to_date('19-JAN-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (73,10069,5,to_date('16-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (74,10069,6,to_date('24-FEB-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (75,10069,8,to_date('16-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (76,10069,9,to_date('24-FEB-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (77,10069,22,to_date('05-DEC-11','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (78,10069,4,to_date('02-JAN-12','DD-MON-RR'),null,null,null);
Insert into MED_IMMUNO (ID, EMP_ID, IMM_REC, IMM_DATE, IMM_NOTES, IMM_APPLICABLE, IMM_REFUSED) values (79,10069,16, null, null, null, null);
Try this:
WITH max_date AS
(
SELECT emp_id, imm_rec, max (imm_date) imm_date
OF MED_IMMUNO M
GROUP BY emp_id, imm_rec
)
DIS_MED_IMMUNO AS
(
SELECT DISTINCT M.emp_id
OF MED_IMMUNO M
)
tmp AS
(
SELECT *.
OF DIS_MED_IMMUNO
CROSS JOIN LU_MED_IMMUNO
)
Tmp.emp_id SELECT emp_id, tmp.ID, tmp. IMM_DESC, M.imm_date
OF tmp LEFT OUTER JOIN max_date M
ON tmp.emp_id = M.emp_id
AND tmp.ID = M.IMM_REC
ORDER BY tmp.emp_id, tmp.ord
-
Code to get the data in the child table in composite SOA using the IOM APIs
Hi all
I am a new bie to IOM. I have a query related to obtaining data in the child table using the API of the IOM in the task of embeded java SOA composite.
I've created a workflow that has a form of child of providing service of slef. I created a composite SOA custom also approval. In the composite approval I have embedded java code and I want to get the values entered in the child form using the API IOM inot the java code embeded in composite SOA.
I tried gettting the child form data by using getChildAttributes(), but I'm getting the following exception.
The local Exception stack:
Exception [EclipseLink-7242] (Eclipse - 2.1.3.v20110304 persistence Services - r9073): org.eclipse.persistence.exceptions.ValidationException
Description of the exception: an attempt was made to navigate a relationship using indirection that had a null Session. This often happens when an entity has a relationship of LAZY not instantiated is serialized and this lazy relationship is crossed after serialization. To avoid this problem, instantiate the LAZY relationship before serialization.
at org.eclipse.persistence.exceptions.ValidationException.instantiatingValueholderWithNullSession(ValidationException.java:994)
at org.eclipse.persistence.internal.indirection.UnitOfWorkValueHolder.instantiate(UnitOfWorkValueHolder.java:218)
at org.eclipse.persistence.internal.indirection.DatabaseValueHolder.getValue(DatabaseValueHolder.java:83)
at oracle.iam.request.vo.RequestBeneficiaryEntityAttribute.getChildAttributes(RequestBeneficiaryEntityAttribute.java:100)
to com. CASApproval.main (CASApproval.java:137)
Please suggest me if I'm following the correct procedure of the child form data or if we can use another approach.
Can we get the data using formInstanceOperationsIntf.getProcessFormChildData ().
Thanks in advance for the help.
Thank you
PTWhen you're in approvals, there is no form of process data. Process form data would come only when approvals are completed. If you want to read data from the child form of the DataSet (i.e. the form object as in OIM9.x) you can use the RequestService on the id of the request and read the data. Or another approach would be to the child the dataset data value in the payload of the request and read the XML payload in the composite.
Let me know if you need more information about the second approach. As for the first approach, search through the forums here and you should find my previous posting on how to reach child dataset values using the ask service API.-Marie
Found these for you:
OIM11G: Way to get values from dataset of the application for approval
Re: How to get the value of the AD details of payload of SOA user group -
How to load data from matrix report in the base using ODI table data
Hello
How to load matrix report data in the base table data using oracle Data Integrator?
Description of the requirement:
This is the data from matrix report:
Need to convert it to the format below:JOB DEPT10 DEPT20 ___________________________ _____________ ANALYST 6000 CLERK 1300 1900
Thank you for your help in advance. Let me know if any other explanation is needed.JOB Dept Salary _____________________________________________ ANALYST DEPT10 ANALYST DEPT20 6000 CLERK DEPT10 1300 CLERK DEPT20 1900Your list seems to be a bit restrictive, you can do much more with the procedures of ODI.
If you create the new procedure and add a step. In the 'source' tab command you define technology and pattern according to your source database. Use the unpivot operator as described in the link, please, instead of using "SELECT *' use the column names and aliases for example:"
SELECT workstation,
deptsal as deptsal,
saldesc as saledesc
OF pivoted_data
UNPIVOT)
deptsal-<-->
FOR saldesc-<-->
IN (d10_sal, d20_sal, d30_sal, d40_sal).<-->
)Then in your tab 'command on target' defined technology and drawing on your target db, then put your INSERT statement for example:
INSERT INTO job_sales
(employment,
deptsal,
saledesc
)
VALUES
(
: job,.
: deptsal,.
: saledesc
)That's why you use bind variables from source to load data into the target.
Obviously if the source and target table is in the same database, you can have it all in a single statement to the "command on target' as
INSERT INTO job_sales
(employment,
deptsal,
saledesc
)
SELECT workstation,
deptsal as deptsal,
saldesc as saledesc
OF pivoted_data
UNPIVOT)
deptsal-<-->
FOR saldesc-<-->
IN (d10_sal, d20_sal, d30_sal, d40_sal).<-->
)also assign the log count "Insert" on the tab corresponding to your INSERT statement, so that you know how many rows you insert into the table.
I hope this helps.
BUT remember that this feature is out in Oracle 11 g.
-
separate account using the lookup table
How can I get a separate count of column values by using another table?
Let's say I want to get a separate account of all 'company_name' files in the 'emp' table that corespond (soccer match) with table of 'research', 'State' category.
What I want is to find charges for all businesses that have a value of 'california' in the 'Status' column of the 'search' Table. I want the output to look like:
Sears 17
Pennys 22
Marshalls 6
Macys 9
I want the result to show me the company names dynamically as I don't know what they are, just that they are part of the group 'State' in the lookup Table object. Does make sense?
MIf you want a counter for each value of rfs_category, but instead of rfs_category you want to display, it's translated value lookup_value_desc.
This should do it for you:
select lookup_value_desc, the_count from lookup join (select rfs_category, count(*) the_count from RFS group by rfs_category) on rfs_category = lookup_type; -
I have the data into two table with the structure of similar column, I want to loop through the data in these two tables
based on some condition and runtime that I want to put the query in loop for example, the example is given, please help me
create table ab (a number, b varchar2 (20));
Insert into ab
Select rownum, rownum. "" sample "
of the double
connect by level < = 10
create table bc (a number, b varchar2 (20));
Insert into BC.
Select rownum + 1, rownum + 1 | "" sample "
of the double
connect by level < = 10
declare
l_statement varchar2 (2000);
Boolean bool;
Start
bool: = true;
If it is true, then
l_statement: =' select * ab ';
on the other
l_statement: =' select * from bc';
end if
I'm in execute immediate l_statement - something like that, but I don't know
loop
dbms_output.put_line (i.a);
end loop;
end;
Something like that, but this isn't a peace of the code work.
Try this and adapt according to your needs:
declare
l_statement varchar2 (2000);
c SYS_REFCURSOR;
l_a number;
l_b varchar2 (20);
Boolean bool;
Start
bool: = true;
If it is true, then
l_statement: = "select a, b, AB;
on the other
l_statement: = "select a, b from bc;
end if;
--
Open c for l_statement;
--
loop
extract the c in l_a, l_b;
When the output c % notfound;
dbms_output.put_line (l_a |') -' || l_b);
end loop;
close c;
end;
/
-
Transpose the text column of the Oracle using ODI table
Here's what I'm trying to do:
Source table that contains the columns:
Time, Blob, Item-ID
The expected target has the columns:
Time, data, Item1, Item2. ItemN
1. where Item1, Item2 are as shown: say for example the source table has 10 rows of different IDS, there are 10 columns in the table target from Item1 to article 10. (Assuming that no. different IDs are fixed)
How to do this? I learn ODI for a few weeks now. Understand the basics and terminology, I don't know how to do this.
2 data (the target table) is a return value from a stored procedure that would transform the Blob (of the Source table)
The stored procedure is ready, but how do you use the procedure to get the target to the source.
Any help/direction would be greatly helpful.
-Vincent
Published by: user12397263 on December 29, 2009 23:531. a question: How do you who would determine row goes to which column? You can say that the 1st line value becomes item1, but without a rank ORDER 1 will always random. If you have a way to ensure the order of the rows (say, a column that can store the rownum) then what you need is in the interface, you specify for n - th element mapping must be MAX (Case when n = rownum then point else ' ' end). Who should take care of it.
2. There is a way to do this in ODI. Because you are a beginner, I would recommend that you create a temporary table and you use a PL/SQL block to generate data of BLOB and serve another table of the source that can update the column of data in the temporary table target table.
-
Numbers ' 09-
We will generate a random date between 1752 and 2099!
A line, three columns over a single column as space reserved.
A1 - C1 and E1 (or other) for the placeholder that will be hidden at any given time.
A1 Gets the with year = HAZARD (1752, 2099).
B1 Gets the using month = MONTHNAME (ALEA (1: 12).
E1 determines if A1 is a leap year using = IF (OR (MOD(A1,400) = 0, AND (MOD(A1,4) = 0, MOD(A1,100) <>0)), "LY", "NOT of LY").
It was easy... now the fun part...
Here are the options I can not understand how to combine.
C1 Gets the date. We are not concerned by the day of the week because the point is to understand that mentally.
Very well. Then... 30 days has September, April, June and November. All the rest have 31. . .
= IF (OR (B1 = "September", B1 = "April", B1 = "June", B1 = "November"), ALEA (1, 30), ALEA (1: 31))
Except February which has 28, unless it's a leap year and then is 29, and interprets the above formula February which have 31 days.
We will temporarily to paste the formula down in C3 and change of B1 to the constant "February" for testing.
= IF ((ET (B1 = "Février", E1 = «LY»)), ALEA (1, 29), ALEA (1: 28))
During the test I also changed the true and false constants functions to see if it is working properly, and he does.
Somehow, I need to combine the two so that a single number that satisfies all the arguments appear in C1. To do this, I have to 'trap' of February by nesting it perfectly in there. It seems that it should fall after the months of 30 days trial with the other seven months with 31 days. In other words: IF cell B1 is not one of the 04:30 day month THEN assess February and if it isn't wouldn't that be, SO it's a thirty and one day months.
Thoughts. Alternatives.
Thank you
-Joe
I think you can simplify the solution with something like this:

This adds a random number of days between 0 and 127104 to the start date.
You can get the number of days between two days simply by subtracting B2 - A2, here. Or you can use = DATEDIFF (A2, B2, "D")
SG
-
Can you attribute programmatically size when you use the table in the Cluster service cluster
I use the table of the Cluster service. The only way I know to the size of the cluster is to right click on the function and set the Cluster size. But what happens if the length of my table changes? Is there a way to make the cluster size is the number of elements in the table? Seems like labview should do this automatically at run time. There may be some nodes of property I don't know.
I tried the SQL statements, but it always boils down to having to know the number of columns is in the database prior to execution.
What I did to generate the object to be a cluster to match database fields. My recordset is an array of objects. Then I a vi member to build a recordset from the database and another Member vi to retrieve an array of clusters of the recordset object. If the database changes, I have to change the subject and these two vi. All the other Subvi call these two for the manipulation of data. No other sub - VI have bundle and ungroup functions in them, only the vi of two members. Thus a change in the database requires a change of control and two vi. Not too bad.
(I'm tooting my Horn in choosing me as accetped solution provider. I learned this bad habit of others here on the forum.
 )
)

Maybe you are looking for
-
Firefox instantly hangs at startup
When I try to open Firefox it flashes an error instantly "Screenshot attached (Error)" and the past in the background report. Pop lasts for 1 or 2 frames so its went very quickly, try to click on safe mode or refresh does nothing. I tried to uninstal
-
Problem with the entrance to the details of admin/pw
I have a problem when you are prompted to enter my admin/user name and password, for example, when you install a new program, etc., the authentication box will appear, but no field will accept any form of entry (typing, pasting etc.) the two buttons
-
HP Pavilion Elite M9400f: recovery
The hard drive does not so I replaced it. Tried to install recovery disks - did not work I tried to install Linux Ubuntu - worked. Works very well. When I insert HP Recovery DVD #1, it starts - installs the files - and then I get a box entitled dialo
-
"You run lack of space on the disk"D "?
How can I remove this recurring message once and for all?
-
Where can I get a replacement for Sony Vaio E series SVE111 keyboard
Hi, I have a Sony Vaio laptop 11.6 ", SVE111. I need a new keyboard for this evil, no idea where to get one? I googled on the net and I can not find anywhere that carries parts for this particular model. Thank you.