Get missing dates as lines
WITH T1
AS (SELECT 'A' ITEM,
'L' LOC,
TO_DATE ('01-MAR-15', 'DD-MON-RR') EFF,
TO_DATE ('08-Mar-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A' ITEM,
'L' LOC,
TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF,
TO_DATE ('31-Mar-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A1' ITEM,
'L1' LOC,
TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF,
TO_DATE ('04-APR-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A1' ITEM,
'L1' LOC,
TO_DATE ('23-APR-15', 'DD-MON-RR') EFF,
TO_DATE ('24-APR-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A1' ITEM,
'L1' LOC,
TO_DATE ('05-MAY-15', 'DD-MON-RR') EFF,
TO_DATE ('04-JUL-15', 'DD-MON-RR') DISC
FROM DUAL)
SELECT T1.*
FROM T1;
Current output:

For section A and L Loc-> I need missing dates between 01 and 08 March and 15 March 2015 and 31 March 2015 I need another line 07th March and 14 March 2015
Expected results
| Header 1 | Header 2 | Header 3 | Header 4 |
|---|---|---|---|
| A | L | 01/03/2015 | 08/03/2015 |
| A | L | 09/03/2015 | 14/03/2015 |
| A | L | 15/03/2015 | 31/03/2015 |
| A1 | L1 | 15/03/2015 | 04/04/2015 |
| A1 | L1 | 05/04/2015 | 22/04/2015 |
| A1 | L1 | 23/04/2015 | 24/04/2015 |
| A1 | L1 | 25/04/2015 | 04/05/2015 |
| A1 | L1 | 05/05/2015 | 04/07/2015 |
I tried to use under request, but need to know how can I get new row.
WITH T1
AS (SELECT 'A' ITEM,
'L' LOC,
TO_DATE ('01-MAR-15', 'DD-MON-RR') EFF,
TO_DATE ('08-Mar-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A' ITEM,
'L' LOC,
TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF,
TO_DATE ('31-Mar-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A1' ITEM,
'L1' LOC,
TO_DATE ('15-MAR-15', 'DD-MON-RR') EFF,
TO_DATE ('04-APR-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A1' ITEM,
'L1' LOC,
TO_DATE ('23-APR-15', 'DD-MON-RR') EFF,
TO_DATE ('24-APR-15', 'DD-MON-RR') DISC
FROM DUAL
UNION ALL
SELECT 'A1' ITEM,
'L1' LOC,
TO_DATE ('05-MAY-15', 'DD-MON-RR') EFF,
TO_DATE ('04-JUL-15', 'DD-MON-RR') DISC
FROM DUAL)
SELECT T1.*,
NVL (
LAG (DISC) OVER (PARTITION BY ITEM, LOC ORDER BY ITEM, LOC, EFF)
- 1,
EFF)
NEW_EFF,
NVL (
LAG (EFF) OVER (PARTITION BY ITEM, LOC ORDER BY ITEM, LOC, EFF) - 1,
DISC)
NEW_DISC
FROM T1;
Hello
You can use UNION to combine the new lines that you generate using LAG or LEAD to actually the rows in the table:
WITH new_rows AS
(
SELECT the point AS header1
loc AS tete2
Disc + 1 AS header3
, ADVANCE (FEP) OVER (PARTITION BY point, loc
ORDER BY eff
) - 1 AS header4
FROM t1
)
SELECT *.
OF new_rows
WHERE header3<>
UNION ALL
SELECT the element, loc, eff, disc
FROM t1
--
ORDER BY 1, 2, 3
;
In any analytical function, there is never any point of order by the same expression that DIVIDE you BY.
Tags: Database
Similar Questions
-
I am running XP Pro. What respect should be reinstalled from the CD. After the reinstallation, Harmon Kardon speakers do not work because HD ADECK cannot be properly installed. Kept on getting vital missing data?
Any suggestions? Someone else's experiences loss of sound after a re - install?
I guess you have formatted the HD?
Therefore, you need to reinstall the relevant software for HD ADECK
See here:
http://www.Google.fr/search?q=HD+ADECK&ie=UTF-8&OE=UTF-8&AQ=t&RLS=org.Mozilla: en - GB:official & client = firefox-a
Happy trawling,
Jerry -
Point cloud with missing data and 3 sets of data
Hello
I'm doing a scatter diagram that has 3 sets of data in it (i.e. 3 plots on the same graph), except that 2 of my sets of data have a missing value while my third set has all the values. I end up getting 2 lines that are disconnected. I can't just remove the line containing the missing data for the 2 sets of data because since my category axis is time, my data points get shifted and no longer appear at the right time. This is the chart that I have.

Thank you.
Hi Gabrielle,.
If there is a diagram of dispersion, the x axis is a value axis. If you have auto selected for the min and max values on this axis, the scale may change when you remove the data point, 15, 85, but the rest remains in the same position relative to the values on each axis of ordinates. What change will be , however, is the curve on which 15 85 approached a local y maximum.
Scatterplots will always leave a gap in the line/curve of connection where there are a pair of missing data. There are two ways to close the gap.
If the chart is an essentially linear relationship, you can use a calculated value is pair up with the lack of value x. The downside of this is that the representation of this point will be indistinguishable on the map of the other data points, measured.
A better way would be to make two tables, one with the full data set, the other with the partial sets, but with the pair missing completely removed.
Adjust the cards the same size and have the same scales on each axis, then just remove one of the cards except the data points, the curves connecting the data points, the x axis of ordinates and the legend showing the color and the forms used to plot each series.
Give a graphic a transparent filling and place it in front of the other.
Kind regards
Barry
-
How to get the data from more than 100 domains in bulk API V2.0?
Hi all
I try to get data from Eloqua by APIs in bulk because of big data.
But my Contact 186 fields (more than the majority of export limitation 100). I think I need to get all the data by 2 exports.
How could I corresponds to 2 parts of a line and join together?
I'm afraid that any change of data between 2 relative to exports 2 synchronizations would make different order.
FOR EXAMPLE:
1. any document is deleted or modified (if it matches do not filter) after obtaining data of the first part and before getting the second part, then everyone behind it would have back in part result.
2. the data in some fields (included in both parts) are changed between the 2 synchronizations, then the values of the second part are more recent but the values of the first part are old.
All suggestions should.
Thank you
Biao
bhuang -
I don't know that you ever go to work around the fact that things will change in your database while you are synchronizing the data. You have to have a way to create exceptions on the side of the synchronization.
If I pushed Eloqua data to a different database and had to contend with the problem of matches change while I'm syncing, I would create a few additional columns in my database to track the status of synchronization for this folder. Or create another small table to track the data map. Here's how I'd do.
- I would have two additional columns: 'mapped fields 1' and '2 fields' mapped. They would be all two datetime fields.
- I would do only one set of synchronization both. First of all, synchronize all records for email + 99 fields. Do the entire list. For each batch, the datetime value of the lot in 'mapped fields 1' column.
- I would then synchronize all folders of email + other 86 fields. Repeat the entire list. For this batch of the datetime value of each batch in their 'mapped the 2 fields' column to now().
- For all records that had only 'mapped fields filled, 1' but' fields mapped 2' was empty, I would be re - run the second query Eloqua API using e-mail as the search value. If no results were returned, I would remove the line. Otherwise, update and the value 'mapped fields in 2' now
- For all the records that were only "fields mapped 2', I re - run against the first email query API Eloqua, fill in the missing data and define 'mapped the fields of 1' of the current datetime object." If the record has not returned, remove the line because it is probably not in the search longer.
- Finally, the value 'mapped fields 1' and 'mapped 2 fields' empty for all records, since you know that data is synchronized. This will allow you to use the same logic above on your next synchronization.
Who is? It is not super clean, but it will do the job, unless your synchronizations take a ridiculous amount of time and your great data changes often.
-
Fill in the missing dates with level
Think im a bad thing. I have some data that missing dates (days) and I want to just fill in the missing days with 0
This sql is to look right or I'm doing something wrong:
SELECT H.URL, H.V_DT, NVL CNT (P.CNT, 0))
SELECT CAL. URL, CAL. MIN_DATE + LEVEL AS V_DT OF)
SELECT the url, MIN (D) MIN_DATE, max (D) MAX_DATE
USER_LOG_TMP2_VW where the url is not null and current_url (select distinct URL of USER_LOG_TMP_VW)
GROUP BY URL
After MAX (D) > MIN (D)) CAL
CONNECT IN CAL. MIN_DATE + LEVEL < CAL. MAX_DATE
-GROUP BY URL, CAL. MIN_DATE + level
): LEFT JOIN USER_LOG_TMP2_VW P ON P.URL = H.URL AND F.F. = H.V_DT
There are only about 75 unique URL and when I run the present it works but I can't count because there are so many lines when it should be, perhaps a few thousand. the oldest date of min goes back only a few months.
im getting strange results. As if I add a specific url like this (below)... it works perfectly for this url. But when I go out as above where it captures all urls... it gives me weird super results. As the dates twice for duplicate URLS.
SELECT H.URL, H.V_DT, NVL CNT (P.CNT, 0))
SELECT CAL. URL, CAL. MIN_DATE + LEVEL AS V_DT OF)
SELECT the url, MIN (D) MIN_DATE, max (D) MAX_DATE
OF USER_LOG_TMP2_VW, where url is not null and current_url to (select url from USER_LOG_TMP_VW where url = 'http://testing123.com/test/test"")
GROUP BY URL
After MAX (D) > MIN (D)) CAL
CONNECT IN CAL. MIN_DATE + LEVEL < CAL. MAX_DATE
-GROUP BY URL, CAL. MIN_DATE + level
): LEFT JOIN USER_LOG_TMP2_VW P ON P.URL = H.URL AND F.F. = H.V_DT
I was not post create it for the views with her but I think that maybe im just something wrong with the level.
I tried the group according to the level of url cal.min_date +, but for some reason it just keeps running and the query never ends.
Hello
Depending on your needs and your version, you may want a CONNECT BY clause like this:
CONNECT BY LEVEL< max_date="" +="" 1="" -="">
AND PRIOR url = url
AND PRIOR SYS_GUID () IS NOT NULL
-
Missing data value on the export
I use FDM v11.1.2.2, and I get an error during the export step. The message export shows that there is no value for the record. I put the data value for the location as < entity currency >, and I don't know why the dimension value is missing from the dat file that is produced. The adapter is FM11X-G6-A. I don't have any scripts in the application.
Anyone seen this before?
Range: 2, error: cell invalid for the period Jan.
Actual; 2012; Jan; YTD; 2891_DIVN; FFS; [ICP no]; [None]; OM; LOAD;-182.49
> > > > > >
Error message in the error log
* FdmFM11XG6A Runtime Error Log entry to start [2013-23 / 01/11: 54:06] *.
-------------------------------------------------------------
Error:
Code of... 10002
Description... Data loading errors.
Process... clsHPDataManipulation.fDBLoad
Component... C:\Oracle\Middleware\EPMSystem11R1\products\FinancialDataQuality\SharedComponents\FM11X-G6-A_1016\AdapterComponents\fdmFM11XG6A\fdmFM11XG6A.dll
Version... 1116
Identification:
... The user xxxxxxxx
Name of the computer... XXXXXXXX
Connection of FINANCIAL MANAGEMENT:
Name of the application...
Name of the cluster...
Field...
Connect status... Open connectionCheck the .dat itself and see if the value is there. There is a bug where the user HFM error log does not display the data value. The .dat should be printing
If it is defined in the location. If it is printed in the .dat, the line can be an invalid intersection. -
Alert entered for the missing data file
I'm trying a simple payback scenario: remove a data file to a tablespace that is normal when the database is running, and the data file has been saved.
Before, the control point ends normally (I guess that still retains the file inode handle Oracle). When I choose to dba_data_files, the error occurred:
To my surprise, nothing has been recorded in the alerts log. And no trace of the files not generated in udump. And Oracle has refused to restore the data file when he was running.SQL> alter system checkpoint; System altered. SQL> select count(*) from dba_data_files; select count(*) from dba_data_files * ERROR at line 1: ORA-01116: error in opening database file 10 ORA-01110: data file 10: '/u01/oradata/data01.dbf' ORA-27041: unable to open file Linux Error: 2: No such file or directory Additional information: 3
The message appeared in the journal of alerts when trying to stop the database. After abort shutdown (Oracle refused to stop immediately) and restart the instance, I was able to restore and recover the data file.
This is the expected behavior? If so, how you would detect files of missing when db is running?
Oracle: 9.2.0.6, OS: RHEL31. it has not detected by the control point caused by a switch logfile because the file is not actually missing. Like other - inded you! -have, Unix/Linux, you can remove a file at any time, but if the file is in use, the inodes are allocated and the process using it continues to see it very well because it. Because, at the level of the inode, it IS absolutely still there! Either by the way, it is needless to say to make a logfile switch, because as data files are concerned, which does nothing, that the command of alter system checkpoint that you already tried.
I used to do demos of how to recover from the complete loss of a controlfile in Oracle University classes: I would like to make a burst of rm *.ctl commands and then significantly question the command checkpoint... and nothing happened. Very demoralizing the first time I did it. Deliver a force of startup, however here the inodes are released at that time, files are actually deleted and start falls in nomount State. Bouncing the instance was the only way I could get the data base to protest against the removal of a data file, too.
2. No, if a file has disappeared in a way allowing to detect Oracle, it wouldn't matter if the folder was empty because he's worried the presence/absence of the datafile headers. They need to be updated, even if nothing else does.
3. it would be in the alerts log if SMON has detected the lost file at startup (one of his jobs is, explicitly, to verify the existence of all the files mentioned in the control file). CKPT would not trigger an alert, because concerned, all right. Inodes are still held, after all. Your attempts to create tables and so forth inside the lost file do not generate display errors (I think) at this time, it's your server process that seeks to do things for the file, not CKPT or pre-existing other background process, constantly running.
4. it's specific to Unix, anyway, that Linux is a Variant.
-
variable sharing, missing data, the timestamp even for two consecutively given
Hello
I have a problem with missing data when I read a published network shared variable.
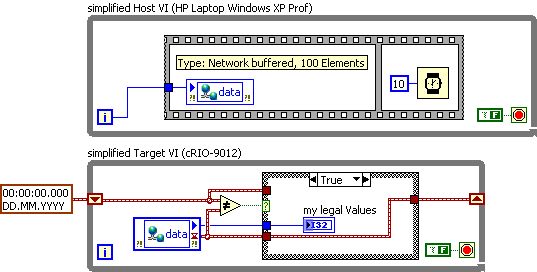
Host VI:
In a host of VI on my laptop (HP with Windows XP Prof.) I write data to the shared Variable 'data '. Between two consecutively write operations is a minimum milliseconds of wait time. I use it because I want to make sure that the time stamp of each new value of data is different then a preview (variables shared the resolution is 1 ms)
VI target:
the VI target cRIO-9012 bed only of new data in the way that it compares the timestamp of a new value with the time stamp of the last value on a device in real time.
Problem:
rarely, I'm missing a data point (sometimes everything works fine for several hours, transfer thousands of data correctly above all of a sudden failure occurs). With a workaround, I'm able to catch the missing data. I discovered that the missing data have the timestamp exactly the same, then the last point of data read, is so ignored in my data 'legal '.
To summarize, the missed value is written to the variable shared host, but ignores the target because its timestamp is wrong, respectively the same as the last value, despite the host waits for a minimum of 10 milliseconds each time before writing a new value.
Note:
The shared Variable is hosted on the laptop and configured using buffering.
The example is simple only to display the function of principle, in real time, I also use a handshake and I guarantee that there is no sub - positive and negative.
Simplified example:
Question:
Anyone has an idea why two consecutively data can have the same timestamp?
Where timestamping (evil) Finally comes (System?)?
What would be a possible solution (for the moment with shared Variables)?
-> I tried to work around the problem with the clusters where each data gets a unique ID. It works but it is slower that comparing the timestamps and I could get performance problems.
It would change anything when I animate the shared on the RT System Variable?
Thanks for your help
Concerning
Reto



This problem has been resolved in LabVIEW 2010. You can see other bugs corrections in theReadme of LabVIEW 2010.
-
Compare and get the data in the tables (see post for details)
I have two tables TableA and TableB. I struggle to write a query to get the dates of TableB (instead of TableA dates) where TableA dates don't coincide with the tableB (beginning and end).
Example 1: For account A1234,.
TableA got 2 rows 1/31/2014-3/3/2014 (which corresponds to TableB row), but TableA got another rank 31/01/2014 - 31/01/2014 that corresponds with the date of TableB Begin. In this case, I'm looking for output as below,
Use TableB start and end date and combine number two rows from TableA for this account
ACCOUNT TableB_BEGIN TableB_END AMOUNT A1234 31/01/2014 03/03/2014 100.0000000000 Example 2: For the B7777 account.
TableA end date aligns with the end dates of TableB for this account, in this case I want out put as,.
Use TableB start and end date and get the amount of TableA
ACCOUNT TableB_BEGIN TableB_END AMOUNT B7777 05/04/2013 06/05/2013 200.0000000000 Example 3: On behalf of D5555,.
Even a TableA line corresponds with TableA, there are two other rows in TableA matching start date with TableA and correspondence with the end date with TableA, in this case, that I put as,.
Use TableB start and end date and combine number three rows from TableA for this account.
ACCOUNT TableB_BEGIN TableB_END AMOUNT D5555 08/08/2014 10/09/2014 1100.0000000000 Example 4: To account E6666.
Table corresponds to a row with TableB and no additional lines in TableA, just display the data in A table
Tables and data:
create table TableA ( Account varchar2(10) not null, Begin date not null, End date not null, Amount number(19,10) not null ) ; create table TableB ( Account varchar2(10) not null, Begin date not null, End date not null, Amount number(19,10) not null ) ; TableA Data: insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('A1234', to_date('31-01-2014', 'dd-mm-yyyy'), to_date('31-01-2014', 'dd-mm-yyyy'), 0.0000000000); insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('A1234', to_date('31-01-2014', 'dd-mm-yyyy'), to_date('03-03-2014', 'dd-mm-yyyy'), 100.0000000000); insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('B7777', to_date('18-04-2013', 'dd-mm-yyyy'), to_date('06-05-2013', 'dd-mm-yyyy'), 120.0000000000); insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('C6666', to_date('25-06-2014', 'dd-mm-yyyy'), to_date('08-07-2014', 'dd-mm-yyyy'), 10.0000000000); insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('D5555', to_date('08-08-2014', 'dd-mm-yyyy'), to_date('16-08-2014', 'dd-mm-yyyy'), 1000.0000000000); insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('D5555', to_date('08-08-2014', 'dd-mm-yyyy'), to_date('10-09-2014', 'dd-mm-yyyy'), 0.0000000000); insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('D5555', to_date('16-08-2014', 'dd-mm-yyyy'), to_date('10-09-2014', 'dd-mm-yyyy'), 100.0000000000); insert into tablea (ACCOUNT, BEGIN, END, AMOUNT) values ('E6666', to_date('01-01-2014', 'dd-mm-yyyy'), to_date('01-02-2014', 'dd-mm-yyyy'), 100.0000000000); TableB Data: insert into tableb (ACCOUNT, BEGIN, END, AMOUNT) values ('A1234', to_date('31-01-2014', 'dd-mm-yyyy'), to_date('03-03-2014', 'dd-mm-yyyy'), 100.0000000000); insert into tableb (ACCOUNT, BEGIN, END, AMOUNT) values ('B7777', to_date('05-04-2013', 'dd-mm-yyyy'), to_date('06-05-2013', 'dd-mm-yyyy'), 200.0000000000); insert into tableb (ACCOUNT, BEGIN, END, AMOUNT) values ('C6666', to_date('06-06-2014', 'dd-mm-yyyy'), to_date('08-07-2014', 'dd-mm-yyyy'), 10.0000000000); insert into tableb (ACCOUNT, BEGIN, END, AMOUNT) values ('D5555', to_date('08-08-2014', 'dd-mm-yyyy'), to_date('10-09-2014', 'dd-mm-yyyy'), 1100.0000000000); insert into tableb (ACCOUNT, BEGIN, END, AMOUNT) values ('E6666', to_date('01-01-2014', 'dd-mm-yyyy'), to_date('01-02-2014', 'dd-mm-yyyy'), 100.0000000000); SELECT A.ACCOUNT, A.BEGIN, A.END, A.AMOUNT, B.ACCOUNT, B.BEGIN, B.END, B.AMOUNT FROM TABLEA A LEFT JOIN TABLEB B ON A.ACCOUNT = B.ACCOUNTHello
SeshuGiri wrote:
Hi Frank,.
Your query/solution works very well, but I forgot to mention something in the first post...
Please insert these additional lines and try the request again.
TableA Additional lines:
- Insert into TABLEA (ACCOUNT, BEGIN, END, QUANTITY)
- values ('F9999', to_date (January 2, 2014 ',' dd-mm-yyyy ""), to_date (3 January 2014 ', 'dd-mm-yyyy'), 999.0000000000);
- Insert into TABLEA (ACCOUNT, BEGIN, END, QUANTITY)
- values ('A1234', to_date (March 3, 2014 ',' dd-mm-yyyy ""), to_date (4 March 2014 ', 'dd-mm-yyyy'), 999.0000000000);
TableB Additional lines:
- Insert into TABLEb (ACCOUNT, BEGIN, END, QUANTITY)
- values ('A1234', to_date (March 3, 2014 ',' dd-mm-yyyy ""), to_date (4 March 2014 ', 'dd-mm-yyyy'), 999.0000000000);
Question 1:
The table has a rows for A1234 account (i.e. the time period different than the ranks for the same account)
one is A1234 31/01/2014-03/03/2014, A1234 03/03/2014-03/04/2014
Your query that returns two rows for A1234 account (which is what I want), but the amount is messed up.
ACCOUNT BEGIN END TOTAL_AMOUNT 1 A1234 31/01/2014 03/03/2014 1100 2 A1234 03/03/2014 03/04/2014 1100 Except:
ACCOUNT BEGIN END TOTAL_AMOUNT 1 A1234 31/01/2014 03/03/2014 101 2 A1234 03/03/2014 03/04/2014 999 Question 2:
In some cases TableA will have an account (F9999), but the TableB don't. I can just this line by making the Left Join right join?
I don't get the results with additional data. I get 1099 for two lines where account = 'A1234 '. I get 1100 as the amount on the line with the account = "D5555. You did it other changes to data?
Except:
ACCOUNT BEGIN END TOTAL_AMOUNT 1 A1234 31/01/2014 03/03/2014 101 2 A1234 03/03/2014 03/04/2014 999 Still, I don't see why you want to 101 for the amount of the first row. Why not 100?
How can you know which rows from tablea should get attached to what rows from tableb, when the account is not unique?
Maybe you want something like this:
SELECT a.account
b.begin
b.end
SUM (a.amount) AS total_amount
FROM tablea a
ON a.account = b.account JOIN tableb B
AND a.begin BETWEEN b.begin
AND b.end
AND a.end BETWEEN b.begin
AND b.end
GROUP OF a.account, b.begin, b.end
ORDER BY a.account
;
but I guess just to your needs, and guessing is not a very good or reliable way to solve problems.
Question 2:
In some cases TableA will have an account (F9999), but the TableB don't. I can just this line by making the Left Join right join?
Yes, it looks that you want an outer join. What happened when you tried? As always, post your code, the exact results you want from the given sample data, as well as an explanation of how you get these results from these data.
-
Get the data in table of javafx
Bat I can get the data in table as:
[code]
for (int i = 0; i < dtm.getRowCount (); i ++)
{
for (int j = 0; j < dtm.getColumnCount (); j ++)
dtm.getValueAt (i, j);
[/ code]
But how can I do this with javafx table? I google and google and google and no luck.
In JavaFX make data are stored on a basis per line. Each line contains an element of type T (where you have a TableView
), and each column specifies a value using a callback function that determines the value of the column of the value of a particular line. You can browse the data simply by practice
for (T item : table.getItems()) { // ... }And then get the value of each column for each element of the given line, since you "know" what each column represents.
For example, in the example of JavaFX documentation, you could do:
for (Person person : table.getItems()) { String firstName = person.getFirstName(); // value in firstName column String lastName = person.getLastName(); // value in lastName column String email = person.getEmail(); // value in email column }If you want something really generic, you can try
for (T item : table.getItems()) { for (TableColumnIf you have little chance to this need, unless you write some kind of framework. (I just typed it here, you may have get dirty you with guys a little to make things).
-
VM inventory report and missing data
All, I wrote a VM inventory report that seems to pull all the data I need, except for a single field, Type of NETWORK adapter. I get some data in this area, but the vast majority is left white. When I run a one-liner (Get - VM - < name of vm > |) Get-NetworkAdapter | Select the Type), I get the data you want. Can anyone help to determine why I get no coherent, fully poplulated data fields?
Here's the script:
$HostReport = @)
Get - VM | object sort name | {foreach ($_.name)}
$Report = "" | Select the host name, Cluster, NumCPU, MemoryMB, network, SCSI, Datastore, ToolsVersion, ToolsStatus
$Report.Hostname = $_. Name
$report. Cluster = ($_ |) Get - Cluster). Name
$report. NumCPU = $_. NumCPU
$report. MemoryMB = $_. MemoryMB
$report.Network = ($_ |) Get - NetworkAdapter). Type
$report. SCSI = ($_ |) Get - ScsiController). Type
$report. Data store = ($_ |) Get - Datastore). Name
$report. ToolsVersion = $_. ToolsVersion
$report. ToolsStatus = $_. ToolsVersionStatus
$HostReport += $Report
}
$HostReport | Export-Csv-path c:\TEMP\vm-hw.csv - NoTypeInformation - UseCultureTIA,
-gc
Hello, gary1012-
Maybe you have a few virtual machines with more than one network card? If so, this line that gets the Type to interconnect the virtual machine would produce no output for these machines. To manage the virtual machines with more than one NETWORK card, edit the "$report.Network =...". "line to something like:
$report.Network = ($_ | Get-NetworkAdapter | %{$_.Type}) -join ","This will give a single type for virtual machines with a NETWORK card or a string of separation by commas of type names for virtual machines with more than one NIC
How does do for you?
-
Using of "get the N first lines only" does / * + FIRST_ROWS ([N]) * / redundant index?
I know FIRST_ROWS indicator shows the optimizer to minimize the time of the first row. I know that the new feature of 12 c for "fetch [FIRST |]» [NEXT] [N] LINES [ONLY |] WITH LINKS] "get first/next N lines only / with ties" will implement the query using ROW_NUMBER(). Should I leave hint in case it improves performance, or the clause FETCH FIRST made this redundant suspicion?
Hi Wes and Hoek,
Oracle said on the indicators in the 12 c setting guide. Each version of this statement becomes stronger.
The disadvantage of the advice is additional code that you must manage, audit and control. Tips have been introduced in Oracle7, when users have little recourse if the optimizer generated suboptimal plans. Because changes in the database and host environment can make obsolete tips or negative consequences, it is a good practice to test the use of indicators, but use other techniques to manage the execution plans.
Oracle provides several tools, including how to set up SQL, SQL plan management and SQL Performance Analyzer to solve performance problems unresolved by the optimizer. Oracle strongly recommends that you use these tools instead of advice because they provide new solutions like the change of environment data and database.
Oracle presents advice in V7, basically as an admission that its optimizer based on CSSTidy based cost did not get things right all the time and tried to get rid of them since. In addition, the preferred method of setting when you are browsing the major updates was to review advice to remove them. It will be interesting to what extent can it be pushed in V12.
In what concerns the first lines index and ROWNUM limiting, unless you just try to get the garbage data, it's meaningless without the presence of an ORDER BY. Once you have an ORDER BY, the query must retrieve all the data before it can return anything. The exception to this rule is if there is an index that the database can use to retrieve already ordered data, that is to say on the order of columns. Therefore, the essence of the indication of FIRST LINES. It will be aggressive looking in the index in favor if the index is in line with the order of. (Try the setting of a SIEBEL instance if you need proof)
I don't have a 12 c to test at the moment, but looking at the examples of Martin, it appears the optimizer is aware of the new windowing function in the new FETCH FIRST/NEXT structure and selects a plan that gives the best answer. If you go through the effort to review suggested rownum limited requests to remove the tips if possible, maybe you should just rewrite with new windowing function.
Concerning
André
-
Need a sql query to get several dates in rows
Hi all
I need a query to get the dates of the last 7 days and each dates must be in a line...
but select sysdate double... gives a line...
Output of expexcted
Dates:
October 1, 2013
30 sep-2013
29 sep-2013
28 sep-2013
27 sep-2013
26 sep-2013
Try:
SQL > SELECT sysdate-7 + LEVEL FROM DUAL
2. CONNECT BY LEVEL<=>
3 * ORDER BY 1 DESC
SQL > /.
SYSDATE-LEVEL 7 +.
-----------------------------
October 1, 2013 13:04:52
30 - Sep - 2013 13:04:52
29 - Sep - 2013 13:04:52
28 - Sep - 2013 13:04:52
27 - Sep - 2013 13:04:52
26 - Sep - 2013 13:04:52
25 - Sep - 2013 13:04:52
7 selected lines.
-
Dear all,
I need query to find the missing dates between two columns in a given month.
CREATE TABLE emp_shift)
EmpNo number 4,
fr_date DATE,
TO_DATE DATE,
Maj VARCHAR2 (1));
CREATE TABLE emp)
EmpNo number 4
);
INSERT INTO emp
(empno
)
VALUES (7369
);
INSERT INTO emp
(empno
)
VALUES (7499
);
INSERT INTO emp
(empno
)
VALUES (7521
);
INSERT INTO emp
(empno
)
VALUES (7788
);
INSERT INTO emp_shift
(empno, fr_date, TO_DATE, Maj
)
VALUES (7369, '01 - sep - 12', ' 08-sep-12', 'A')
);
INSERT INTO emp_shift
(empno, fr_date, TO_DATE, Maj
)
VALUES (7369, '09 - sep - 12', 15-sep-12', 'B')
);
INSERT INTO emp_shift
(empno, fr_date, TO_DATE, Maj
)
VALUES (7369, 16-sep-12 ', 22-sep-12', 'A')
);
INSERT INTO emp_shift
(empno, fr_date, TO_DATE, Maj
)
VALUES (7369, 23-sep-12 ', 30-sep-12', 'B')
);
INSERT INTO emp_shift
(empno, fr_date, TO_DATE, Maj
)
VALUES (7499, '01 - sep - 12', ' 08-sep-12', 'A')
);
commit;
MISSING_DATES EMPNO
---------------------- ----------
09 SEP-12 TO 11-SEP-12-7499
23 SEP-12 TO 26-SEP-12 7499
01 sep-12-7521 30-SEP-12
01 12-sep-to 30-SEP-12 7788
SQL > select * from emp_shift;
EMPNO FR_DATE TO_DATE S
---------- --------- --------- -
7369 08-SEPT-12 TO 01-SEP-12
7369 15-SEP-12 B 09-SEP-12
7369 22-SEP-12 TO 16-SEP-12
7369 30-SEP-12 B 23-SEP-12
7499 08-SEPT-12 TO 01-SEP-12
7499 15-SEP-12 B 12-AUG-12
7499 22-SEP-12 TO 16-SEP-12
7499 30-SEP-12 B 27-SEP-12
As we can see that there is no missing date against empno 7369 so it is displayed in the output and empno 7499 is missing dates from 09-Sept-12 to 11 - sep-12 and 23-26-sep-12 sep-12.
7521 Empnos and 7788 has no entry in the table of emp_shift where these empno dates do not appear in the 01-sep-12 and 30-sep12
Please help to solve.As...
SQL> select * from emp1 order by 1; EMPNO ---------- 7369 7499 7521 7788 SQL> select * from emp_shift order by 1,2; EMPNO FR_DATE TO_DATE S ---------- --------- --------- - 7369 01-SEP-12 08-SEP-12 A 7369 09-SEP-12 15-SEP-12 B 7369 16-SEP-12 22-SEP-12 A 7369 23-SEP-12 30-SEP-12 B 7499 01-SEP-12 08-SEP-12 A 7499 15-SEP-12 28-SEP-12 A 7521 08-SEP-12 15-SEP-12 A 7 rows selected. SQL> with t as 2 (select to_date('01092012','ddmmyyyy')+level-1 dt 3 from dual 4 connect by to_date('01092012','ddmmyyyy')+level-1 <= to_date('30092012','ddmmyyyy') 5 ) 6 select empno,min(dt) fr_date,max(dt) to_date 7 from( 8 select empno,dt,sum(diff) over(partition by empno order by dt) sm 9 from( 10 select e1.empno,dt, 11 dt-nvl(lag(dt) 12 over(partition by e1.empno order by dt), 13 to_date('010912','ddmmyy')-1)-1 diff 14 from emp1 e1,t 15 where not exists 16 (Select null 17 from emp_shift e2 18 where t.dt between e2.fr_date and e2.to_date 19 and e1.empno = e2.empno) 20 ) 21 ) 22 group by empno,sm 23 order by 1,2; EMPNO FR_DATE TO_DATE ---------- --------- --------- 7499 09-SEP-12 14-SEP-12 7499 29-SEP-12 30-SEP-12 7521 01-SEP-12 07-SEP-12 7521 16-SEP-12 30-SEP-12 7788 01-SEP-12 30-SEP-12Published by: JAC Sep 27, 2012 12:23
table name used is EMP1.
A few lines are added to emp_shift for the test -
Download of CSV using Browse point (don't get no data found error)
Hello
I use procedure below to download CSV in my table.
CSV is to have null values in some places ex: 1,.
2,0.999
3,
4,0.696
below the procedure works fine when I am downloading as CSV: 1.0
2,0.999
3.0
4,0.696.
My table is seen as two columns, and I get no data found error when downloading a CSV of null values.
I went through import data in Excel to the database table but no use...
Please help me on this.
Procedure
===========
concerningDECLARE v_blob_data BLOB; v_blob_len NUMBER; v_position NUMBER; v_raw_chunk RAW(10000); v_char CHAR(1); c_chunk_len number := 1; v_line VARCHAR2 (32767) := NULL; v_data_array wwv_flow_global.vc_arr2; BEGIN -- Read data from wwv_flow_files select blob_content into v_blob_data from wwv_flow_files where UPDATED_BY = (select max(UPDATED_BY) from wwv_flow_files where UPDATED_BY = :APP_USER) AND id = (select max(id) from wwv_flow_files where updated_by = :APP_USER); v_blob_len := dbms_lob.getlength(v_blob_data); v_position := 1; -- Read and convert binary to char WHILE ( v_position <= v_blob_len ) LOOP v_raw_chunk := dbms_lob.substr(v_blob_data,c_chunk_len,v_position); v_char := chr(hex_to_decimal(rawtohex(v_raw_chunk))); v_line := v_line || v_char; v_position := v_position + c_chunk_len; -- When a whole line is retrieved IF v_char = CHR(10) THEN -- Convert comma to : to use wwv_flow_utilities v_line := substr(v_line, 1, length(v_line)-2); v_line := REPLACE (v_line, ',', ':'); -- Convert each column separated by : into array of data v_data_array := wwv_flow_utilities.STRING_to_table (v_line); -- Insert data into target table EXECUTE IMMEDIATE 'insert into table_name@Schema1 (col1,col2) values (:1,:2)' USING v_data_array(1), v_data_array(2); -- Clear out v_line := NULL; END IF; END LOOP; END;
Chauvet
Published by: Chaumont on 26 September 2012 10:52
Published by: Chaumont Sep 26, 2012 22:25
Published by: Chaumont on 27 September 2012 01:58Chambers,
You can use wwv_flow_utilities.array_element to avoid any no_data_found. The function does not raise any errors. For example, for the line which only have a value of table when you wait 2, it can be useful.
EXECUTE IMMEDIATE 'insert into table_name@Schema1 (col1,col2) values (:1,:2)' USING wwv_flow_utilities.array_element(v_data_array,1), wwv_flow_utilities.array_element(v_data_array,2);Kind regards
Christina

Maybe you are looking for
-
How can I know what Adobe programs I need on my computer?
My Adobe Flash Player keeps crashing. I just downloaded Flash Player Plugin from 14 and noticed that I have 5 other Adobe programs on my computer. How can I know which ones I need to keep? Those I have is: Acrobat.com installed 7/03/2010; Flash Playe
-
New Firefox v. 29 - Extension 'Cult' does not show in the main toolbar
Just got the latest update of Firefox this morning. I used to have the extension 'Sun Cult' on my 'add-on bar' and expected to see this extension in the main toolbar now. However, it is not. When I open "Customize", I can't see the extension, but is
-
Why when I click on a bookmark it opens a new window, it supports a window I'm working on that
Why when I click on a bookmark it opens a new window, it supports a window I'm working on that
-
This morning I installed Firefox 6 and he says that is not compatible with the Java Console 6.0.26 and deactivated. I use Windows 7 Professional 32 bit. Is this normal?
-
Where can I find the update of BIOS for Satellite A10?
Hello Anyone know where I can download the "BIOS update" for Satellite A10?Please I really need.Thank you