Help the fetaching data in dynamic PL/SQL tables
HelloI'm develioping a PL/SQL procedure in which I'm 24 tables of PL/SQL creation of the same type.
But while inserting data in them, I need to use the table dynamically names for example, immediate enforcement to put the data in the tables would remain even just I need for each loop for the Execute immediate statement, it must use the name in the other table.
See the code example below:
Varchar2 column (20);
Type RA_TABLE is table of the CALL_DETAIL_EXCEPTION. TYPE % IC_CIRCT_GR_CD
index of directory;
MY_RA1 RA_TABLE;
MY_RA2 RA_TABLE;
MY_RA3 RA_TABLE;
MY_RA4 RA_TABLE;
BEGIN
for idx in 1.cnt_interval loop
Column: = "MY_RA" | IDX;
Query1: = 'select Trunk_info bulk collect INTO MY_RA | IDX |' dbl.vw_cgi v where there is no (select 1 of dbl.varun f
where f.ic_circt_gr_cd = v.TRUNK_INFO and f.call_gmt_dnect_dt_time between
to_date('''|| stime ||'') (', "yyyymmddhh24miss") and to_date('''|| eTime ||'') ((', 'yyyymmddhh24miss'))';
Now, when I run this code, it gives me an error for query1 saying that it's a function not implemented in Oracle.
He is not able to choose this dynamic table name.
Help, please!
dbms_output.put_line(l_outertab(1)(1));
Tags: Database
Similar Questions
-
Is it possible to use the record type or a PL/SQL table in the Select statement
Hi all
My requirement is that.
I want to write a query and write a function, function, I want to return multiple columns at the same time in a Select statement.
I select the return values in the Select no statement in a PL/SQL block.
Is it possible to use the PL/SQL Table or Variable of Type record, or any other method in the statement Select?
Please help me understand the solution.
Kind regards830960 wrote:
do we like it?In general, Yes, if the function is a function table, you can do something like:
select t.col1, t.col2, f.col1, f.col2, f.col3 from table_name t, table(some_table_function(param1,...paramN)) f /SY.
-
How to find the second largest in a pl/sql table
Hello friends,
I want to find the first and second maximum items in a pl/sql table.
Here's the code...
DECLARE
Max_earnings_type TYPE TABLE IS NUMBER;
max_earnings_tab max_earnings_type: = max_earnings_type();
number of v_count: = 0;
number of v_max_earnings;
Can someone give me how to find the maximum first max and second in the type of the given table.
appreciate your help.
Thank you/kumar
Published by: kumar73 on October 21, 2010 09:42kumar73 wrote:
When I tried to implement your logic in my application, I get the following error...
PL/SQL: digital or value error: NULL index key value table
What happens if the PL/SQL table has NULL values. Question is how you want to handle NULL values. You want to ignore nulls as GROUP BY do? If you want to consider NULL values, you can say if you want to order the NULLS FIRST or NULLS LAST. I guess that logical GROUP BY:
DECLARE TYPE max_earnings_type IS TABLE OF NUMBER; TYPE max_earnings_sorted_type IS TABLE OF NUMBER INDEX BY BINARY_INTEGER; max_earnings_tab max_earnings_type; max_earnings_tab_sorted max_earnings_sorted_type; BEGIN SELECT sal + comm BULK COLLECT INTO max_earnings_tab FROM emp; FOR v_i in 1..max_earnings_tab.count LOOP IF max_earnings_tab(v_i) IS NOT NULL THEN max_earnings_tab_sorted(max_earnings_tab(v_i)) := 1; END IF; END LOOP; DBMS_OUTPUT.PUT_LINE('MAX value in PL/SQL table is ' || nvl(to_char(max_earnings_tab_sorted.last),'NULL')); DBMS_OUTPUT.PUT_LINE('Second MAX value in PL/SQL table is ' || nvl(to_char(max_earnings_tab_sorted.prior(max_earnings_tab_sorted.last)),'NULL')); END; / MAX value in PL/SQL table is 2650 Second MAX value in PL/SQL table is 1900 PL/SQL procedure successfully completed. SQL> SELECT sal + comm 2 FROM emp; SAL+COMM ---------- 1900 1750 2650 1500 SAL+COMM ---------- 14 rows selected. SQL>SY.
-
Access to the element in a dynamic PL/SQL trigger Action?
Hello
I have a form that is used to calculate the volume of a (large) number of tanks based on the heights of tank is entered.
I have a PL/SQL procedure that performs the calculation: it receives the name of the tank and the height and calculates the volume (each tank may have different physical characteristics).
I didn't create a dynamic Action by tank (I'm lazy and the number of tanks is important!). I currently have a dynamic Action that is triggered whenever one of the heights of the tank on the form changes. The PL/SQL action called the calculation for each tank. FOR EXAMPLE
:P1_TANK1_VOL := tank.vol('TANK1', :P1_TANK1_HEIGHT); :P1_TANK2_VOL := tank.vol('TANK2', :P1_TANK2_HEIGHT); ... :P1_TANK50_VOL := tank.vol('TANK50', :P1_TANK50_HEIGHT);This works, but is to perform calculations of 50 whenever one is necessary, and can seem slow.
Is there a way to identify the trigger for the action of PL/SQL? FOR EXAMPLE
IF TriggeringElement = 'P1_TANK1_HEIGHT' THEN :P1_TANK1_VOL := tank.vol('TANK1',:P1_TANK1_HEIGHT); END IF;Any ideas?
No PL/SQL directly. You could do a JavaScript action before your PL/SQL and write the id (which is the name of the element in the APEX), the item trigger in a hidden item, submit it to your PL/SQL action and now you know how it started.
Kind regards
Joni
-
How to create the constructor function for a pl/sql table?
I created a PL/SQL type as table below:
create or replace type typ_tbl_des_text is table of the typ_tof_des_text
OK so far, but I would like to have a constructor function which would be subject to validations and raise_application_error when a validation condition is not met.
How to do this?
The typ_tof_des_text that I created with a constructor function, so that the record-level validation are performed in the constructor. And I think the postings between several records shall be made in a constructor for typ_tbl_des_tex, but cannot figure out how to create such a constructor.
BEDE wrote:
So, if I have understood correctly, to a plsql table type, I can't have a member procedure. Or can I? I mean, just as for a type of failure I can have one or more constructors and possibly several procedures of Member.
For the standard tables in PL/SQL, you will need to create your own API (using procedures and functions) to handle beyond the basics provided by the language. No constructors and methods as it is no o - o.
After thinking a little deeper, I reformulate what I said earlier and actually wants to have a member procedure called add_item, who would be first to check if an item with a key value exists and, if so, it would be up-to-date and so not only extend the plsql table.
Two options.
As we already mentioned, an associative array can be considered - note however that this structure of table has name-value pairs.
Another method is to use a TWG (global temporary table). You define the structure of the once initial table. When a session uses the structure of the table, private copying is instantiated for this session. When the session ends, this copy is destroyed. The table is a temporary structure for this session only.
It can include indexes and so on – which means you can use the constraints of primary keys, unique indexes, secondary indexes and so on.
TWG scales are much better than collections or arrays that require a PGA (expensive private server) memory. In addition, SQL can be used natively against a GTT - unlike the arrays and collections.
-
need help to find column ID to market sql tables in a diagram
I want to build a query that will walk all tables in a schema in a loop and compare every possibility to associate it with an ID column
I need to know what are the tables have a result where the number of lines with names of columns ID is > 0, then show that only those who were the tables & how many match. I don't know the name of the columns ID, so that does not need to be a variable
Something along the idea of (not even close to real SQL but I hope that the idea comes through)
for i = 1 to the last-1 table
for j = 2 to the last table
Select
i table_name
j table_name
County (id_column)
Of
Table i
Table j
where
i.id_column = j.id_column
Next I
Next j
then to take all lines that result and get rid of those who have zero counties
Thank you
-----
Edit
----
I seem to have bad to convey my idea, I'll try again
I can write this:
--
Select count (id_column)
Table i table j
where i.ID = j.ID
--
and I can put in each pair of tables for the entire schema, but I don't want to really put 250 + names in this pair and go through all the possibilities of each pair of tables, I'm expecting something that looks like this when finished,
County of table table
----------------------------------------
customer address 500
phone customer 1000
customers accounts 300
Chargers cusomers 0
senders address 50
......
Published by: user7733176 on January 4, 2011 04:52user7733176 wrote:
---
Select count (id_column)
Table i table j
where i.ID = j.ID
----select a.table_name, b.table_name, extractvalue( xmltype( dbms_xmlgen.getxml( 'select count(*) cnt ' || ' from ' || a.table_name || ' a,' || ' ' || b.table_name || ' b' || ' where b.id = a.id' ) ), '/ROWSET/ROW/CNT' ) cnt from user_tab_columns a, user_tab_columns b where a.table_name > b.table_name and a.column_name = 'ID' and b.column_name = 'ID' group by a.table_name, b.table_name having extractvalue( xmltype( dbms_xmlgen.getxml( 'select count(*) cnt ' || ' from ' || a.table_name || ' a,' || ' ' || b.table_name || ' b' || ' where b.id = a.id' ) ), '/ROWSET/ROW/CNT' ) > '0' order by a.table_name, b.table_name /SY.
-
Performance issue Bulk Insert PL/SQL table type
Hi all
I put in work of a batch to fill a table with a large number of data records(>3,000,000). To reduce the execution time, I used PL/SQL tables to temporarily store data that must be written to the destination table. Once all documents are piling up in the PL/SQL table I use a FORALL operator for bulk insert the records in the physical table.
Currently, I follow two approaches to implement the process described above. (Please see the code segments below). I need to choose how to best wise performance between these two approaches. I really appreciate all the comments of experts about the runtime of the two approaches.
(I don't see much difference in consumption of time in my test environment that has limited the data series. This process involves building a complex set of structures of large product once deployed in the production environment).
Approach I:_
DECLARE
TYPE of test_type IS test_tab % ROWTYPE directory INDEX TABLE;
test_type_ test_type.
ins_idx_ NUMBER;
BEGIN
ins_idx_: = 1;
NESTED LOOPS
test_type_ (ins_idx_) .column1: = value1;
test_type_ (ins_idx_) .column2: = value2;
test_type_ (ins_idx_) .column3: = value3;
ins_idx_: = ins_idx_ + 1;
END LOOP;
I_ FORALL in 1.test_type_. COUNTY
INSERT INTO test_tab VALUES (i_) test_type_;
END;
/
Approach II:_
DECLARE
Column1 IS a TABLE OF TYPE test_tab.column1%TYPE INDEX DIRECTORY.
Column2 IS a TABLE OF TYPE test_tab.column2%TYPE INDEX DIRECTORY.
Column3 IS a TABLE OF TYPE test_tab.column3%TYPE INDEX DIRECTORY.
column1 column1_;
column2_ Column2;
column3_ Column3;
ins_idx_ NUMBER;
BEGIN
ins_idx_: = 1;
NESTED LOOPS
column1_ (ins_idx_): = value1;
column2_ (ins_idx_): = value2;
column3_ (ins_idx_): = value3;
ins_idx_: = ins_idx_ + 1;
END LOOP;
FORALL idx_ in 1.column1_. COUNTY
INSERT
IN n_part_cost_bucket_tab)
Column1,
Column2,
Column3)
VALUES)
column1_ (idx_),
column2_ (idx_),
column3_ (idx_));
END;
/
Best regards
Lorenzo
Published by: nipuna86 on January 3, 2013 22:23nipuna86 wrote:
I put in work of a batch to fill a table with a large number of data records(>3,000,000). To reduce the execution time, I used PL/SQL tables to temporarily store data that must be written to the destination table. Once all documents are piling up in the PL/SQL table I use a FORALL operator for bulk insert the records in the physical table.
Performance is more than just reducing the execution time.
Just as smashing a car stops more than a car in the fastest possible time.
If it was (breaking a car stopping all simply), then a brick with reinforced concrete wall construction, would have been the perfect way to stop all types of all sorts of speed motor vehicles.
Only problem (well more than one actually) is that stop a vehicle in this way is bad for the car, the engine, the driver, passengers and any other content inside.
And pushing 3 million records in a PL/SQL 'table' (btw, that is a WRONG terminology - there no PL/SQL table structure) in order to run a SQL cursor INSERT 3 million times, to reduce the execution times, is no different than using a brick wall to stop a car.
Both approaches are pretty well imperfect. Both places an unreasonable demand on the memory of the PGA. Both are still row-by-row (aka slow-by-slow) treatment.
-
Hi experts,
Could you please tell me how can I put all the ename column table emp in a work table pl/sql and display of the enmae in a sorted order.
Concerning
Rajat
Published by: Rene on July 15, 2010 09:47Rajat says:
Thanks, but I don't want to store the value in a table.Why not? The best place for data is in a SQL table - where is can be indexed, ordered, filtered, put together and so on.
It is also not such a thing as a «+ table PL +» This data structures is nothing like a table. It is a collection or a table - which is the correct terminology and terminology for the same data structures in languages ranging from Pascal to Java for Delphi and C/C++.
Calling it a + "PL table +" creates the false idea that the data structure is SQL table as... which could not be further from the truth. They have almost nothing in common. There is a huge difference between a table and a collection from a table SQL.
I want to
table ALIGNMENT (TYPE list IS TABLE OF r_empobj ;) is assigned (type r_empobj IS RECORD (empid number, ename varchar2 (100));)These data resides inside the PL language like PL data structures It is not a structure of SQL data.
The SQL language and the language PL are different languages with different runtimes. PL/SQL integrates and "connects" them--blurs the border between these two languages. But they are still clearly distinct and different languages.
If you have three choices:
- write a quick-sort /-bubble sort to sort the data PL. structure plastic
- Copy the entire structure of data of PL SQL data structure, use the SQL engine for sorting and then copy the entire structure of SQL data in PL.
- do not use a collection/table of PL structure, but use a SQL table instead.
-
I installed the SQL 4.0 developer and repository installation was a success. But the tools-> Data Miner-> Make visible option is not enabled. Also when I double click on the data minor user login I get the message workflow repository data need to be stored as xml binary on databases of version 11.2.0.4 or higher. You want to migrate your data from worklfow binary storage? WARNING: All sessions with the ODMRUSER role will be disconnected. Client version: 12.2.0.17.29 Version: 12.1.0.1.0 the database repository Version: 12.1.0.2.1. I don't have an older repository. Please help me solve this problem.
Try to create a data minor user account (for example DMUSER) using the script createuser.sql in the
\dataminer\scripts directory. Use this user account to connect instead of the anonymous account. Thank you.
-
How to identify columns that have the same data in a SQL query or function?
Deal all,
How to identify columns that have the same data in a SQL query or function? I have the sample data as below
!DEPT_ID EMP_ID Come on CITY STATE COUNTRY 1 1 1 June 1983 DELHI HUMAN RESOURCES India 1 2 18 January 1987 DELHI HUMAN RESOURCES India 1 3 28 November 1985 DELHI HUMAN RESOURCES India 1 4 4 June 1985 DELHI HUMAN RESOURCES India 2 5 5 June 1983 MUMBAI HD India 2 6 6 June 1983 MUMBAI HD India 2 7 7 June 1983 MUMBAI HD India 2 8 8 Jun MUMBAI HD India 3 9 9 GURGAON DL India 3 10 10 June 1983 GURGAON DL India Now, I want to Indify columns that have the same data for the same Department ID.
Is it possible in sql unique or do I have to write the function for this? Pls Help how to write?
Thanks in advance.
You can try this?
WITH T1)
DEPT_ID, EMP_ID, DATE OF BIRTH, CITY, STATE, COUNTRY
), ()
SELECT 1, 1, TO_DATE('1.) June 1983', 'JJ. LUN. (YYYY'), 'DELHI', 'HR', 'INDIA' OF THE DUAL UNION ALL
SELECT 1, 2, TO_DATE('18.) January 1987', 'JJ. LUN. (YYYY'), 'DELHI', 'HR', 'INDIA' OF THE DUAL UNION ALL
SELECT 1, 3, TO_DATE('28.) November 1985', 'JJ. LUN. (YYYY'), 'DELHI', 'HR', 'INDIA' OF THE DUAL UNION ALL
SELECT 1, 4, TO_DATE('4.) June 1985', 'JJ. LUN. (YYYY'), 'DELHI', 'HR', 'INDIA' OF THE DUAL UNION ALL
SELECT 2.5, TO_DATE('5.) June 1983', 'JJ. LUN. (YYYY'), 'BOMBAY', 'HD', 'INDIA' OF THE DUAL UNION ALL
SELECT 2.6, TO_DATE('6.) June 1983', 'JJ. LUN. (YYYY'), 'BOMBAY', 'HD', 'INDIA' OF THE DUAL UNION ALL
SELECT 2.7, TO_DATE('7.) June 1983', 'JJ. LUN. (YYYY'), 'BOMBAY', 'HD', 'INDIA' OF THE DUAL UNION ALL
SELECT 2.8, TO_DATE('8.) June 1983', 'JJ. LUN. (YYYY'), 'BOMBAY', 'HD', 'INDIA' OF THE DUAL UNION ALL
SELECT 3, 9, TO_DATE('9.) June 1983', 'JJ. LUN. (YYYY'), 'GURGAON', 'DL', 'INDIA' OF THE DUAL UNION ALL
SELECT 3.10, TO_DATE('10.) June 1983', 'JJ. LUN. (YYYY'), 'GURGAON', 'DL', 'INDIA' OF THE DOUBLE)
SELECT DEPT_ID,
RTRIM (XMLAGG (XMLELEMENT(A,VALS||',')). Extract ('//Text ()'), ',') COLUMNS_WITH_DUPLICATE
DE)
SELECT * FROM)
SELECT DEPT_ID,
EMP_ID,
Date of birth
CITY,
STATE,
COUNTRY
DE)
SELECT DEPT_ID,
EMP_ID,
Date of birth
CITY,
STATE,
COUNTRIES,
COUNT (*) OVER(PARTITION BY DEPT_ID ORDER BY EMP_ID DESC,DOB DESC,CITY DESC,STATE DESC, COUNTRY DESC) RN
DE)
SELECT DEPT_ID,
CASE WHEN(CEID>1) AND THEN 'YES' ELSE 'NO' END AS EMP_ID.
CASE WHEN(CDOB>1) THEN 'YES' ELSE 'NO' END AS DATE OF BIRTH,
CASE WHEN(CCITY>1) AND THEN 'YES' ELSE 'NO' END AS CITY.
CASE WHEN(CSTATE>1) AND THEN 'YES' ELSE 'NO' END AS STATE.
CASE WHEN(CCOUNTRY>1) THEN 'YES' ELSE 'NO' END AS A COUNTRY
DE)
SELECT DISTINCT
DEPT_ID,
CEID,
CDOB,
CITY,
CSTATE,
CCOUNTRY
DE)
SELECT DEPT_ID,
COUNT (*) TO THE CEID (DEPT_ID PARTITION, EMP_ID),.
COUNT (*) ON CDOB (DEPT_ID SCORE, DATE OF BIRTH),
COUNT (*) ON THE CITY (DEPT_ID PARTITION, CITY),
COUNT (*) ON CSTATE (DEPT_ID PARTITION, STATE).
COUNT (*) ON CCOUNTRY (DEPT_ID, COUNTRY PARTITION)
FROM T1)))
WHERE RN = 1)
UNPIVOT (CLO FOR (VALS) IN (EMP_ID, DATE OF BIRTH, CITY, STATE, COUNTRY)))
WHERE COLS = "YES".
DEPT_ID GROUP;
OUTPUT:
DEPT_ID COLUMNS_WITH_DUPLICATE
--------- ------------------------1 CITY, COUNTRY, STATE
2 CITY, COUNTRY, STATE
3 CITY, COUNTRY, STATEPost edited by: Parth272025
-
How to plan the report filtered by dynamic date based on the date, the Agent is running
Hello
I have a question about account using OBIEE agent.
If I run an agent today to deliver A report, can I me A report based on the date of last Monday or any dynamic dates?
For example, say is today, December 18, 2013, and my agent is run according to how I put the calendar. Now the content of the delivery report one being delivered. Now A report has a date column, normally this column is filtered by the current date. But if it comes through the agents to different users, the data should be the previous Monday, so in this case, 9 December 2013. When this agent is run once again, declared December 27, 2013, then the report must be filtered by December 16, 2013, which is the previous Monday 27 dec.
Something like this is possible in OBIEE 11 G?
Thanks in advance.
Yala,
Not in a straightforward way
(1) let the report through Agent with filter current Date
(2) after he ran for the first time you can see IBOT name/last execution time (LAST_RUNTIME_TS) in S_NQ_JOB
Create a variable reference 'last_run_agent' to aid in sql to get max (LAST_RUNTIME_TS)
SELECT max (LAST_RUNTIME_TS) from s_nq_job, whose name = "AGENT_NAME;
Change analysis with current date filter report and amend accordingly the condition of filter to filter on repository variable, newly created
Thank you
-
How to pass Variable PL/SQL to the Argument of the Planner data
Hi all. If possible, I would spend 2 dates in a pl/sql stored procedure arguments in a DBMS Scheduler position. Is this possible? My attempts have failed so far so any help would be appreciated.
My pl/slq is shown below. The dates are hard coded for testing purposes. In fact, they'll be in the pl/sql stored procedure input parameters. Is there a way of coding the variables containing the dates and use variables in the 4th and 5th arguments Planner?
declare
l_today_date DATE;
l_yester_date DATE;
Start
l_today_date: = July 15, 2011 "; -$ hardcoded to test only
l_yester_date: = June 1, 2011 "; -$ hardcoded to test only
CASE
WHEN l_process_name = "ENTRY" THEN
BEGIN
dbms_scheduler.create_job (job_name = > 'LOAD_INPUT_SCHED_TST',)
job_type = > 'PLSQL_BLOCK ',.
job_action = > ' start
PKG_INPUT_SCHED_TEST.sp_load_input ("LOAD_INPUT","TST ', CURRENT_TIMESTAMP, l_today_date, l_yester_date);
end;',
start_date = > sysdate + 1/24 / 59,
enabled = > TRUE,
auto_drop = > TRUE,
Comments = > 'LOAD DATA INPUT');
END;
END CASE;
END;
/Hello
It is a question of grammar of PL/SQL string. Your string contains the literal "l_today_date" instead of the concatenation of the value - which is probably what you expect.
Try this instead
job_action => ' begin
PKG_INPUT_SCHED_TEST.sp_load_input ("LOAD_INPUT","TST ', CURRENT_TIMESTAMP,"'| l_today_date | ") ','' ' || l_yester_date | " ') ;
end;',You can also do this by using job_type-online procedure_stockee, job_action-online 'PKG_INPUT_SCHED_TEST.sp_load_input', number_of_arguments-4 and then by 4 calls to set_job_argument_value before activating the work online.
Hope this helps,
Ravi. -
How can I find out what is the cause of this error in SQL Developer Data Modeler
Friends,
I am trying to import features in SQL Developer Oracle Designer 10.1.2.3 Data Modeler.
If you need perform the following steps to import:
Template file-> Import-> Oracle Designer-> select connection to the base-> select work area-> select System application-> select an entity-> click Finish-> begins to import
During the import process, I see an alert with the message dialog box:
Clicking Ok dismisses the alert box, and I see the following summary screen:There are errors in import - check Log file
The entity appear in the logical view in SQL Developer Data Modeler.Oracle SQL Developer Data Modeler Version: 2.0.0 Build: 584 Oracle SQL Developer Data Modeler Import Log Date and Time: 2010-08-09 14:27:26 Design Name: erdtest RDBMS: Oracle Database 10g All Statements: 32 Imported Statements: 32 Failed Statements: 0 Not Recognized Statements: 0
While they were inspecting the log file, I see the following entry:
Anyone can shed light on this error?2010-08-09 13:50:34,025 [Thread-11] ERROR ODExtractionHandler - Error during import from Designer Repository java.lang.NullPointerException at oracle.dbtools.crest.imports.oracledesigner.logical.ODORelation.createArcs(Unknown Source) at oracle.dbtools.crest.imports.oracledesigner.logical.ODORelation.generate(Unknown Source) at oracle.dbtools.crest.imports.oracledesigner.ODExtractionHandler.generateDesign(Unknown Source) at oracle.dbtools.crest.imports.oracledesigner.ODExtractionController$Runner.run(Unknown Source) at java.lang.Thread.run(Thread.java:619)
Thanks in advance for any help you may be able to provide.We have identified that objects recovered and on the branches are not considered by the Data Modeler. This bug has been connected (#10022016) and is being implemented.
What
-
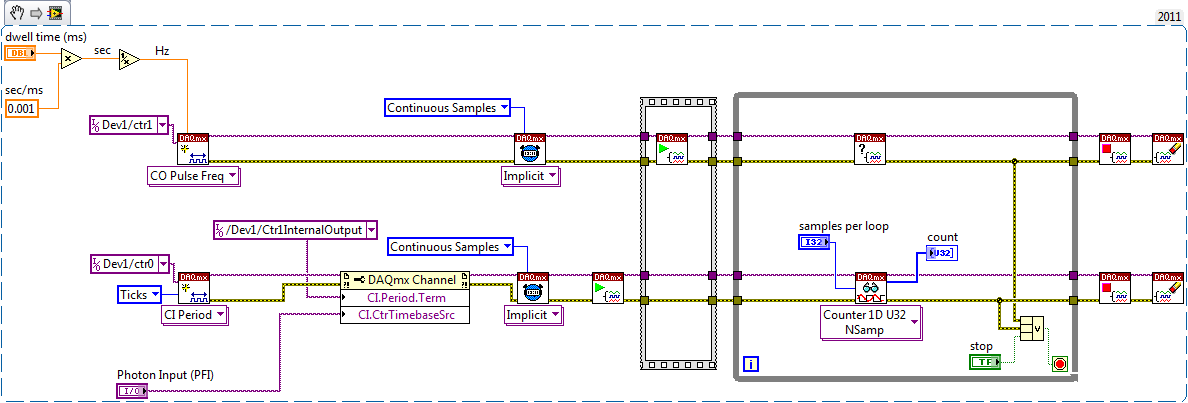
Helps the acquisition of photon counter data using LabView 12
Hey all,.
Student graduate Chemistry here new to LabView and are looking for some help moving in the right direction. I'm looking for help with connecting my meter to 12 LabView for data acquisition of trace-fluorescence photon PerkinElmer SPCM-AQR-14 (now owned by Excelitas Technologies). I just want to be able to acquire number of photon counts vs. time. Currently, I installed a PCI-6601 and use a BNC-2121 to connect the BNC of the sensor output. The detector has a pulse output digital TTL with 30 ns pulse width, and by contacting technical support on this issue, I was told that this pulse width was too short to always detected by the 6601, but can still go ahead and give it a try. Basically, if everyone is familiar with how to start with this configuration, ANY help would be greatly appreciated. As I said I'm all new to LabView and am currently spend all my spare time reading manuals and help files.
Please let me know if you need any kind of information to make me understand what I'm doing.
I would say something like this:
A measurement period the registry account out of the entrance of the samples as well as gives the meter. You will basically measure the 'period' of your sample clock fixed regarding ticks of the external photon signal.
According to the downtime, you may need to re-read several samples per loop so that the software can keep up with the incoming data. Also, the first sample is not useful because it represents the County between the software from the task of entry of the meter and the first clock signal - you should disregard/erase the first sample (or if you want you can set up a trigger to begin arms).
To do the same thing by using an edge County task would require using both the sample clock AND a counter reset signal - this not is not supported on 6601/6602 (even if it would be possible to set it up that way on a device of STC - 3 as a series of X).
Best regards
-
I accidentally the application data file in my windows 8. Help, please.
I accidentally the application data file in my windows 8 accordingly the tile on the start menu is missing only the office and the store remained, I lost too much profile in other games, how to restore lost especially applications apps built in? Help, please.
Hello
Please check section of applications that the built-in apps still exists or not. This will clear if the built-in apps are only missing the start screen or permanently missing. If you find them, re-PIN. If you can't find them, Refresh and they all will be back over your app so lost data file.Here's how to Update:Hope this helps, good luck :)
Maybe you are looking for
-
When I have my USB drive plugged into a USB hub, it will not work. It does not eject or accept disks. It's annoying because I have a MacBook Air that has only 2 USB ports. I have several devices that I use. Is there anything I can do to run the Hub o
-
Problem with watching a received video messages!
I use Skype on Win XP Service Pack 3 6.11! Yesterday I received a video message that I wasn't able to watch! First of all, the window became black with a little box in the upper left corner that says something about "Recent" & "Flash plugin! If you c
-
Need XP driver for Satellite L300D-10U
Hello I have the Satellite L300D-10U. I need drivers for XP Professional
-
It is possible to specify the length of Word and whole for the fixed point data format, and if so where this work? The module I use is a NI 9205 in a cRIO-9074 and seems to have a fixed point default data format of , which I interpret as meaning that
-
cannot open files or programs with icons
Whenever I try to open files by using icons or shortcuts, I get the following message: System call failed. It has a title of explorer.exe on the box. I can't even get into Control Panel