list employees whose salary greater than their salary of managers
Hi all
I have a requirement.i have two tables emp and dept tables in RPD. I want to get the report as employees whose salary greater than their salary of managers. The report contains empno, ename, salary.
Please give me any suggesion
Thanks and greetings
K.Lavanya
Are you able to see the table of discipline Manager?
If Yes, try this
Criteria - select sal EMP-> filter - > check the box to "convert this SQL filter '.
Now, you will get
"EMP". "" SAL "=.
then add below statement
"EMP". "' SAL ' > 'MANAGER '. "' SAL '
Note:
'MANAGER '. "' SAL ' denoted as wages of new table alias
Tags: Business Intelligence
Similar Questions
-
Hello world
Suppose I have a table emp that has thousands of lines of data. In this table of employees receive wages between 1000-10000.
Now I have to get only the employees whose salary is equal.
for example
empNo empName sal
----------- ------------- ---------
1 ram 5000
2 5000 Shyam
3 1000 Dilip
4 deepak 2000
5 sisi 1000
6 1000 Priya
so now...
Now without using ' select * from emp where Sal IN (5000,1000). "How can I get these employees with the same salary?
SELECT *.
EMP e1
WHERE EXISTS (SELECT 99 FROM emp e2 WHERE e2.sal = e1.sal AND e2.empno! = e1.empno)
or maybe
SELECT *.
WCP
WHERE sal IN (SELECT sal FROM emp GROUP BY sal HAVING COUNT (*) > 1)
-
name of the employee whose average sal is greater than an average salary of their
name of the employee whose sal is higher than an average wage of their respective Department
Published by: Kilian on December 27, 2009 11:52I guess you mean the employees whose salary is equal then the average salary in their own Department.
You can use Analytics:
SQL> select * from ( 2 select ename, deptno, avg(sal) over (partition by deptno) deptavg, sal 3 from emp 4 ) where sal>deptavg; ENAME DEPTNO DEPTAVG SAL ---------- ---------- ---------- ---------- KING 10 2916,66667 5000 JONES 20 2175 2975 FORD 20 2175 3000 SCOTT 20 2175 3000 ALLEN 30 1566,66667 1600 BLAKE 30 1566,66667 2850Or a classic correlated subquery:
SQL> select ename, deptno, sal 2 from emp e1 3 where sal>(select avg(sal) from emp e2 where e2.deptno=e1.deptno); ENAME DEPTNO SAL ---------- ---------- ---------- KING 10 5000 JONES 20 2975 SCOTT 20 3000 FORD 20 3000 ALLEN 30 1600 BLAKE 30 2850Max
[My Italian blog Oracle | http://oracleitalia.wordpress.com/2009/12/26/leggiamo-meglio-il-dizionario-dati-utilizzando-dbms_metadata/] -
Please allow solution query ename, whose salary is max *.
Hi all
Could you please solve the following query
I want to get the name of the employee whose salary is maximum in a single select statement. * without using Sub query / Inline / Co Sub request * related.
I tried below, but these are using subquery, inline
SELECT *.
FROM (SELECT *)
WCP
ORDER BY sal DESC)
WHERE ROWNUM = 1;
Select ename emp where sal = (select max (sal) from emp);
Thanks in advance
KrisTry this
SQL> ED Wrote file afiedt.buf 1 SELECT ENAME, MAX(SAL) OVER (ORDER BY SAL DESC), COUNT(*) 2 FROM EMPLOYEE 3 CONNECT BY PRIOR SAL> SAL 4 GROUP BY ENAME,SAL 5* HAVING COUNT(*)=1 SQL> / ENAME MAX(SAL)OVER(ORDERBYSALDESC) COUNT(*) ---------- ---------------------------- ---------- pritam 8000 1 -
Need to retrieve the records whose salary is higher than the max of avg salar
I wrote a query to retrieve the data whose salary exceeds the maximum salary of the avg of all departments
I would like to write that this query using the associates.SELECT * FROM EMP WHERE SAL> (SELECT MAX(AVG (SAL)) FROM EMP GROUP BY DEPTNO)
I tried
It gives me error that we cannot use a function nested in the collateral.SELECT EMPNO,ENAME,SAL FROM EMP E1 WHERE SAL > ANY( SELECT MAX(AVG(SAL)) FROM EMP E2 WHERE E1.DEPTNO = E2.DEPTNO)
What is the solution of the present?
ThnksThis?
select * from emp a where exists (select 1 from emp b where a.deptno=b.deptno and a.sal>(select round(max(avg(sal))) from emp group by deptno)); -
give meaning to cases where minimum effective_start_date is greater than the current date
Hi guys, I'm not a developer oracle as such, but I'm trying to get some information from oracle to send to other systems of the company, since we are dealing with oracle HRMS as the master system for employee information.
In particular, we would like to create people in our training and the security system when they are created in oracle.
I was told that the oracle per_all_people_f object acts as a slowly changing dimension of type 2, where a person can have several versions, which only is always the current version and the current version can be retrieved using the standard parttern of "date of current between the effective start date and actual end date. So far so good.
However, I can see there are cases where the minimum 'effective_start_date' is greater than the current date. It is, indeed, equal to their start_date. I guess start_date represents "the first day of work" of the person.But this means then there is no "current" information known to people who have not yet really started working for the company again. This seems odd. How can I have someone for whom we have no information "currently correct? I was told that the effective_start_date of the line is automatically set to their "first day of work" date on which the information is entered into the system, IE, the user to enter information doesn't have the ability to say 'this is the current version of the data for that person, who starts at a date in the future. "
For this reason, I cannot know these new people (who have been entered in oracle, but did not have actually to their first day of work still) training system. But we would obviously get people established in related systems so that they can use all of these systems on their first day of work.
Have I misunderstood something here? How can there be no correct version for a person at the date and time?
Hello
How normally "inform you" the training system on a new person record? If it's a kind of report or an interface, it may be useful changed to examine a number of days in the future, for example
+ 7 It is important to understand when you look at an Oracle HRMS instance through enforcement (i.e. the ' front end'), you look at the data on a date date (of the session) - by default, the date is the system date, but it is possible for a user to change this date to be in the future or the past as they see fit. The ability to implement the records in person in the future is a great feature to have, of course, but it must be understood that in this situation, at the date of the day the person's file logically does not exist yet from the point of view of the MFC features. Behind the scenes, however, in the per_all_people_f of the table, the line exist. Similarly, future update of changes to a person (e.g. marital status from Single to married) could be implemented, and the change in status would be visible if the session has been scheduled on a date or after the date of the marriage. As correctly observe you, behind the scenes, the table will hold all historic entries for this person_id with contiguous effective_start_date and effective_end_date beaches.
Either way, date_start value is not related to as such hiring date; It is actually the value of effective_start_date earlier for the person_id. All changes, regardless of how many or what the effective_start_date is in each case, will always carry this same start_date value. It * may * be identical to the hiring date (certainly the fact that you configure their hire date person records would cause that), but if the person has been created as a postulant effective from 1 September and was then hired has effect from 21 September, column start_date value would be still 1 September. The record of the person would be visible when the current date is on or after this date - the only difference is that they show that an employee until the 21st.
I hope this helps, but it is possible, that I just confused you more!
Clive
-
relaxation led when the value is greater than
Hey everybody! I have to do a project and im stuck because I'm a noobler with regard to labview. I'm using labview 6 and got to watch the pressure and temperature of a reactor in time. I need to create a system in which if a value is greater than it triggers an alarm (perhaps led can show it) or is less than a certain limit. I mean it should trigger an alarm when the temperature or pressure is beyond 100 and less than 10. And after that to generate a text document in which it is specified the time and date at which these values were exceeded. I also use randomly generated values. Can I get help please? I'm not manage it by myself
 )
)Line and force. as Norbert said.
You won't get much sympathy on overloaded around here. Three things occurred to me that I read your messages:
- You will be in trouble when you get a job if you think that you will be not always charged.
- If I help you, you'll probably end up working for me and I still have to do your homework.
- You'll be fine. Engineers outsource their work all the time.

-
ESXi 5.5 local RDM is greater than 2 TB
I recently added a set of 3 TB WD red SATA disks to an ESXi 5.5u2 host and set up their physical compatibility as cards attached to a guest Windows Server 2012 gross. These discs appeared as having a capacity of 512 b and the space unallocated on 16EB:

The first cards were created using vmkfstools as follows:
vmkfstools - z /vmfs/devices/disks/vml.0100000000202020202057442d574d43315430333739323233574443205744 WD_RED_1.vmdk
vmkfstools - z /vmfs/devices/disks/vml.0100000000202020202057442d574d43315430343235393733574443205744 WD_RED_2.vmdk
vmkfstools - z /vmfs/devices/disks/vml.0100000000202020202057442d574343344e484b3637433346574443205744 WD_RED_3.vmdk
If I take out discs, connect them to a physical host while I'm able to put a GPT disks and add a volume using Windows storage spaces. Once more attached to the ESXi host they work very well, although records show the same space of capacity / free.
Looking around, I see that others have encountered this problem, without any resolution:
https://communities.VMware.com/thread/468799
https://communities.VMware.com/thread/466442
Disk emulate a 512b sector size and I was wondering if this is likely to be part of my problem? I was wondering if anyone else has encountered this problem or could use directly attached cards raw device with greater than 2 TB disks?
This problem has been resolved in the upgrade to ESXi6.
The disks were already in GPT format and unfortunately version 10 of material did not help
-
Remove some fonts ligatures if follow-up greater than 0
I import files with certain fonts with follow-up set to different sizes. Some fonts with some ligatures do not work when monitoring is a value greater than 0 without first turning off the Standard Ligatures. I use a script that checks to see if these certain fonts are active and if yes then disable ligatures for this font.
My knowledge of javascript is very basic and I have created this script from especially copy and paste and change things, I found in the guide to script. So, I'm sure that my code could use some better organize. I got it first with a bunch of cases identified and then discovered that I could use the | use multiple values so I thought this might be a better way to write it?
I want to add another if the statement that first checks to see if these fonts have followed together whatever it is greater than 0, and if yes, then turn off ligatures, but if not keep as their market. They work a lot when the tracking is at 0 and I would like to be able to use them again instead of completely disable the.
var docRef = app.activeDocument; for (var w = 0; w < docRef.textFrames.length; w++) { var textRef = docRef.textFrames[w]; if ((textRef.textRange.characterAttributes.textFont == textFonts.getByName('Skitch')) || (textRef.textRange.characterAttributes.textFont == textFonts.getByName('AmarelinhaBold')) || (textRef.textRange.characterAttributes.textFont == textFonts.getByName('Amarelinha')) || (textRef.textRange.characterAttributes.textFont == textFonts.getByName('Zalderdash')) ) { textRef.textRange.characterAttributes.ligature = false; } } redraw();Again, I am very new to javascript, but I think that this should be a fairly simple addition? I honestly don't know even if the redraw(); is it necessary? Finally, I want to add to another script to import.
Thanks for your time!
It's ok, to optimize well enough, you can make a variable of any object that is called repeatedly, for example characterAttributes, moreover, there is that one way to know if you must redraw(), remove it and if you see that your code works, then it is not necessary
var docRef = app.activeDocument; for (var w = 0; w < docRef.textFrames.length; w++) { var textRef = docRef.textFrames[w]; var charAttributes = textRef.textRange.characterAttributes; var textfont = charAttributes.textFont; if ((textfont == textFonts.getByName('Skitch')) || (textfont == textFonts.getByName('AmarelinhaBold')) || (textfont == textFonts.getByName('Amarelinha')) || (textfont == textFonts.getByName('Zalderdash')) ) { if (charAttributes.tracking >= 1) { charAttributes.ligature = false; } } } -
SolidColorStroke not uniform thickness when it is greater than 1
I have some problems using the SolidColorStroke to add a border around a greater than one pixel thick rectangle. For some reason, he went weird. I rectangles in a horizontal list and on the left first rect and top edges are a pixel of thickness and right and downstairs are two and all other rectangles, the top is a pixel of thickness and all other sides are two. I guess that set the weight to any value would be uniformly defined thickness on all sides of the rect that value, but it doesn't look like it works like that. Is there something that I am missing?
This is the rect code I use.
<s:Rect width="101" height="71"> <s:stroke> <s:SolidColorStroke color="0x009DE0" weight="2"/> </s:stroke> <s:fill> <s:SolidColor color="0xFFFFFF"/> </s:fill> </s:Rect>
As test, try setting your rect x / y coords to half pixels (e.g. 10.5, 10.5) just to see if that corrects the way that the race appears.
-
"Greater than or equal to ' searches on pavement
How can I implement a search "superior or equal to ' on the pavement?
I created a Btree that allows keys duplicated like this (I'm using Python and pybsddb ):
db_object = db. DB (DBE)
db_object.set_flags (db. DB_DUP | DB. DB_DUPSORT)
db_object. Open (define_primary_db_name (primary_db_name), None, db. DB_BTREE, db. DB_CREATE)
The keys are a series of integers, which here is a partial list (before they are inserted into the Btree, they are converted to strings):
... 90700, 91500, 91900, 92500, 93159, 94500, 94700, 95300, 96400, 97779, 98600, 98900 99900, 100000, 101900...
I would like to be able to question the Btree amount and get all values is greater than or equal to a specified amount.
I wrote a function to open a cursor, point to the first value using DB_SET_RANGE, and then iterate (via DB_NEXT) until the end:
def greater_than_equal_to (amount):
AMT = int (amount)
[data =]
CUR = db_object.cursor)
REC = cur.get (amount, db. DB_SET_RANGE)
If rec:
Data.Append(Rec[0])
all REC:
REC = cur.get (amount, db. DB_NEXT)
If it's not rec:
breaking
If int(rec[0]) & gt; = amt:
Data.Append(Rec[0])
cur. Close()
return data
But when I tried, I got only some, not all, results that I wanted, like on this model:
% greater_than_equal_to('91500')
'91500', '91900', '92500', '93159', '94500 ', '94700', ' 95300', ' 96400 ', ' 97779', 98600', 98900', 99900'
So, obviously, the requirement that the keys are strings has an impact on the results, since any key not starting not not by "9" is ignored by the cursor / call DB_SET_RANGE.
Is there a way to get the cursor to look at the keys correctly (i.e., in the form of numbers) to make it work as I wish?Hello. Your analysis of the situation is correct, because your keys are stored as strings, functions of default comparison sorts 150000 before 9. In order to avoid a complete analysis of the database for your search, you will need to implement a custom comparer to tell BDB how to sort your data. You can find more information about it here:
http://www.jcea.es/Programacion/pybsddb_doc/4.7.3/DB.html#set_bt_compare
and here:
http://www.Oracle.com/technology/documentation/Berkeley-DB/DB/api_c/db_set_bt_compare.htmlIf all your keys are numeric, the comparison function must be simple, convert the two values and return leftKey less to rightKey. If your keys are not purely digital, design a correct comparison function will be much more difficult.
Ben Schmeckpeper
-
I found some help on older versions of Firefox, but I can't seem to find anything for the latest versions greater than 8. There must be a way to do this for imaging large scale.
Have you created a defaults\profile in the folder of the program Firefox (C:\Program Files\Mozilla Firefox\)?
All files in this folder will be moved into each newly created profile folder.
To give the prefs a default, it is best to do this via a mozilla.cfg file.
Use a mozilla.cfg file in the Firefox program folder to lock the prefs or specify default values.
Place a local file - settings.js in the defaults\pref folder where you will also find the channel - prefs.js to specify using mozilla.cfg file.pref("general.config.filename", "mozilla.cfg"); pref("general.config.obscure_value", 0); // use this to disable the byte-shiftSee:
You can use these functions in mozilla.cfg:
defaultPref(); // set new default value pref(); // set pref, but allow changes in current session lockPref(); // lock pref, disallow changes
-
IMAQ_USB - 1074396024 (coverage Minimum value must be greater than zero)
Hello
I have problems to use a USB WebCam when I try to run an executable file in a PC that not have installed LabVIEW. The error code that is displayed is 1074396024 (coverage Minimum value must be greater than zero).
When I run it on a PC that installed, LabVIEW everythings works great!
Someone has an idea to help me? The sample program is attached.
Thks
Hey neat,
To run your executable file in a free LabVIEW PC, you must install LAbVIEW Run-Time Engine and Vision Run-Time Engine.
http://digital.NI.com/public.nsf/allkb/3EB8C8AFC1593B4A8625712E0002869B
Engine performance vision application for permit.
Best regards
Abel Souza
Engineering applications
National Instruments Brazil
-
Read byte with a value up to 127 lire byte with an ASCII value greater than 7F (127 dec)
Hello
I have to read a byte with a value greater than 127, Labview turn 27.
In help I saw that Labview provides a description of ASCII that pour values ranging up to ' 127.
What do I need to do?
LabVIEW 6.1
Windows XP
Hello
I want to read a byte with a maximum value of 127, but Labiew reurn arround 27 value
How do I do?
Rigid wrote:
Thanks for your help. I'm not changing lyke I understand (my English is poor quiet...)
I have another program that communicate with the instrument. I know byte (6) must be greater than 18 (greater than 7F actually).
But with Labview, I'm only 18.
While it might be higher than 18 x, an I8 is signed, and therefore it cannot be greater than x7F - it has a range of-128 to 127. A U8 is not signed, and it's why he has a range from 0 to xFF. However, x 18 is the same if you treat as signed or not signed. I don't see how LabVIEW can read a wrong value on the serial port. Are you sure you're looking at the correct byte? Your code shows that you split the chain twice. Are you sure that you do this properly?
Given that you use on Windows you can recheck the chain received using PortMon. Allows you to see what is actually received by the driver for the serial port on Windows.
P.S. I actually meant the whole byte function.
-
Read/write file binary change greater than 128 bytes.
Hi all, maybe a strange question, but I'm scratching my head on this one. There is undocumented behavior in the function of read/write binary file, where U8 a value greater than 128/0 x 80 get automatically converted to 0x3F value?
I try to use LabVIEW to generate a binary file custom that we'll load in an EEPROM, so all data in the binary file is stored as values of U8. I have a "template" file, and eventually I'll take the logic implemented to replace the fields with the data from the true value. However, I am struck by the anomaly that when I just read the file in LabVIEW and then réécrirait, all the values 0x80 and more are truncated to 0x3F value. Has anyone seen this before, and is there a solution?
I noticed writing the value 0 x 80 directly to one generates a binary file (such as a U8) 0 x 90, 0 x 70 being written in the binary file. It is also rather undesirable, as it adds additional bytes in the bytestream, and the bytes of EEPROM must be in exact locations.
Join your data file.
This program is to give the images below? Are you sure that LabVIEW is to write the bytes differently? I really doubt that.
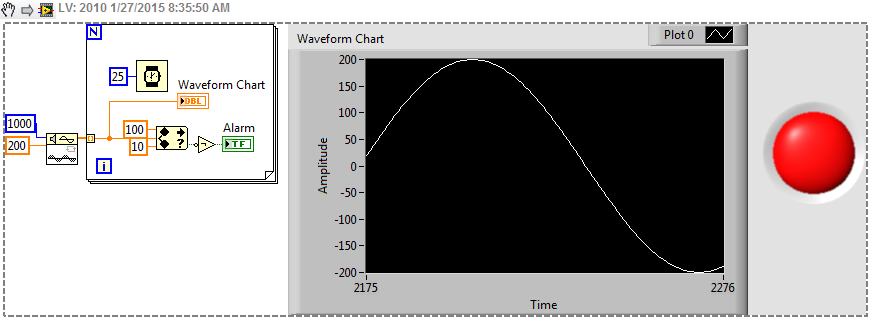

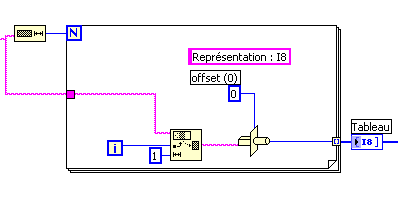
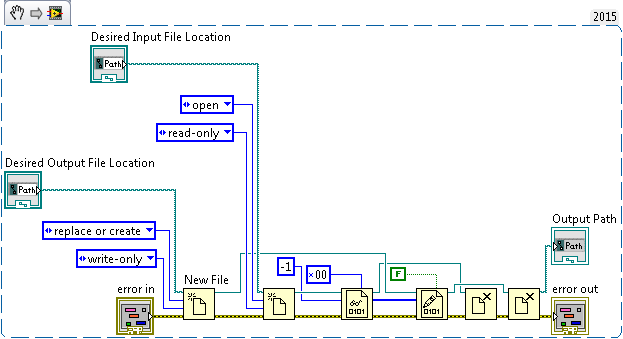
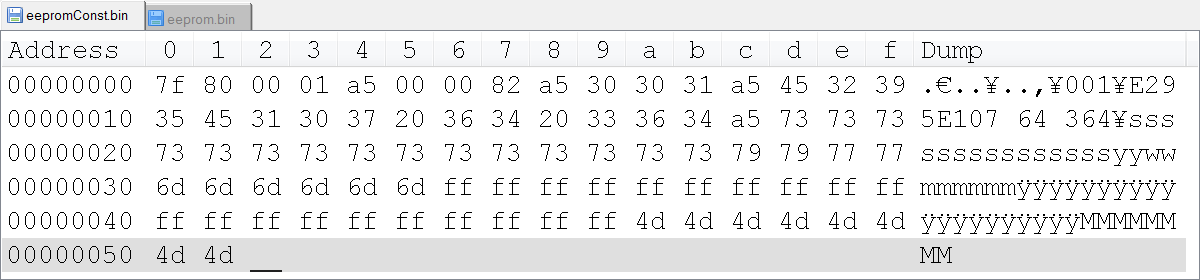
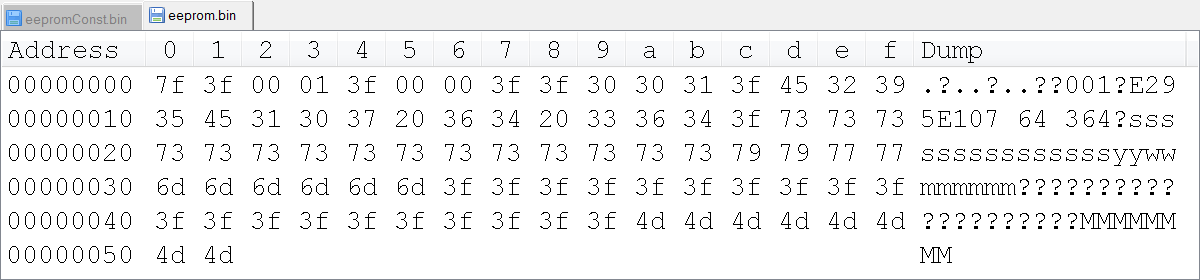
Maybe you are looking for
-
HP Pavilion n242se-15 Notebook PC with win 7
I have HP Pavilion n242se 15 Notebook PC with window 7 and he is there in no display driver, ethernet and many others where can I get this laptop driver for window 7 expert please help me. There are hardware ID missing drivers Bluetooth controller PC
-
A "Bookmarks" window appeared on the left side of my screen. How can I get rid of him?
On the left edge of my screen in all the bars, is a box with a black label "bookmarks". The label is a search box, and which are 3 entries in the drop-down list, Bookmarks Toolbar, bookmarks Menu and Unsorted Bookmarks. Since there are other places I
-
Re: Satellite A100-083 - letters keyboard automatically
Hello I work with a Satellite A100-083, Windows XP SP2. Since about a month ago following problem appears from time to time:While typing in my browser or e-mail program (both are by Mozilla) my computer types, the letters "ITU" turns on the capslock
-
I bought a laptop HP ProBook 450 G1 in March 2014. I got Windows 7 but it has got some problems so I instlled 8.1 Win. Now, everything fine except the problem shown in the picture above. How can I solve this?
-
Foxfire orange tab on the Gil is missing once again. Where can I find to install?
Foxfire has an orange tab that is normally on the top of my Google Homepage. But missing once again. Where can I install again?