manipulating data with several readings
Hi again,
So I can read the tensions out of the terminals of NI USB-6009. Now was that reading analog1 and B be analog2 reading. I want to calculate something like 2 * A - B. I can't understand how to do this.
I can read the values together and watch them on the same chart, but I can't deal with them. I enclose the file in which I read the values, put them through the filters and then display. But 'data' is only one variable, although there are two readings in it. I do not know how to separate one from the other.
Thanks for the help.
cartonn30gel,
Playback DAQmx returns an array of waveforms, each element of the array represents a data channel.
To split the individual channels out there, use primitive Table of indexes in the table Palette:
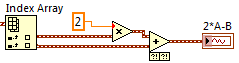
You can then use regular numeric operations on the waveform, or if all you care is the actual reading, you can get the table of voltages measured waveform using the primitive to get elements of waveform in the waveform Palette.

Thicker wires in LabVIEW represent arrays that contain several similar items. The waveform data type is a convenient way to manage measurement data because it combines information in time (t0 and dt) with the data table measured (Y).
I hope this helps.
Simon
Tags: NI Hardware
Similar Questions
-
external table data with several locations pump
Hello
I'm on:
Oracle Database 10 g Enterprise Edition release 10.2.0.3.0 - 64biit
SunOS 5.10
I am trying to create a table of data pump external at the same time, with the location of the files previously created using pump.
This is the same as the example given in step 10-13 here:
http://docs.Oracle.com/CD/B19306_01/server.102/b14215/et_dp_driver.htm#i1007502
But when I do this and select all the lines in the resulting table, I get the error:
ORA-29913: error in executing ODCIEXTTABLEFETCH legend
ORA-29400: data cartridge error
KUP-11011: file / < filepath > sys_tables.dmp is not valid for this load operation
ORA-06512: at "SYS." ORACLE_DATAPUMP', line 52
Can anyone help?
Here is a script of what I do...
create the directory message_archive_dir as ' / your/path/directory "; -change default directory
-chmod 777 your way
create the sys_tables table
external organization
(type ORACLE_DATAPUMP
THE DEFAULT DIRECTORY MESSAGE_ARCHIVE_DIR
LOCATION ("sys_tables.dmp"))
AS
Select object_id, object_type
of object
where owner = 'SYS '.
and object_type = 'TABLE '.
and rownum < 11;
create the table sys_indexes
external organization
(type ORACLE_DATAPUMP
THE DEFAULT DIRECTORY MESSAGE_ARCHIVE_DIR
LOCATION ("sys_indexes.dmp"))
AS
Select object_id, object_type
of object
where owner = 'SYS '.
and object_type = 'INDEX '.
and rownum < 11;
Select * from sys_tables
Union
Select * from sys_indexes;
-all 20 rows returned!
-now I combine the two dmp files in a single table...
create the table sys_objects
(
object_id NUMBER (14).
object_type VARCHAR2 (30)
)
EXTERNAL ORGANIZATION
(
TYPE ORACLE_DATAPUMP
THE DEFAULT DIRECTORY MESSAGE_ARCHIVE_DIR
LOCATION ('sys_indexes.dmp', 'sys_tables.dmp')
);
Select *.
of sys_objects
where rownum = 1;
-ok returnes one line (one of the dmp files work)
--Choose so all lines...
Select *.
of sys_objects;
ORA-29913: error in executing ODCIEXTTABLEFETCH legend
ORA-29400: data cartridge error
KUP-11011: file / < filepath > sys_tables.dmp is not valid for this load operation
ORA-06512: at "SYS." ORACLE_DATAPUMP', line 52
Can you see what I'm doing wrong?
Any help is greatly appreciated!
Thank you.user9969845 wrote:
... Etc...TYPE ORACLE_DATAPUMP
THE DEFAULT DIRECTORY MESSAGE_ARCHIVE_DIR
LOCATION ('sys_indexes.dmp', 'sys_tables.dmp')Combination dump files
Files dump populated by different external tables can all be specified in the LOCATION of another external table clause. For example, data from different databases can be unloaded in separate files, and these files can then be included in an external table defined in a data warehouse. This provides an easy way to aggregate data from multiple sources. The only restriction is that the metadata for all external tables is exactly the same. This means that the game characters, time zone, schema name, table name, and column names must match. In addition, the columns must be defined in the same order, and their data types must be identical. This means that after you create the first external table you must remove it so that you can use the same table name for the second outer table. This ensures that the metadata in two dump files is the same and they can be used together to create the external table even.
8 2 -
Several files of data with autoextend ON & OFF
Hello
Is there any negative impact, and if I add a new data file to the storage space with auto-prolonger ON, while the old data file for the same storage space is OFF.
Here is my scenario:
I have 3 groups of disks in my ASM (DATA1, DATA2, and DATA3) instance.
Now, all my tablespace's datafiles of Data1 with auto - THEY extend. (It was a mitake creating tablespace). To distribute the disk space, I intend to add a new data files of DATA 2 & 3 for half of the storage space.
And for these storage spaces, I'll turn off the auto-prolonger for old data files and marketing the autoextend for new data files.
The idea is, Oracle will begin to load the data for the new ASM disk groups in the future and I'll get the appropriate disk space distribution. Is there a problem with this approach? (In particular, when one of my datafile autoextend is DISABLED and other is lit).
Your advice is appreciated!
Kind regardsIn fact, it is a valid strategy to ensure that some datafile (s) in some single user grow while others stay the same size.
Correctly, several data files must have been created earlier so that data would have been divided on all files. However, you can always add new data with AUTOEXTEND ON files and set the old files of data AUTOEXTEND off at any time (and switch ON and OFF as needed if you need to dynamically manage the use of the space of the file system, when you move data to new file systems files).
Is there a negative impact
N °
Hemant K Collette
-
script process of sorting (with several column data) and average (some other column data)
Hello
I had a lot of help from my log of the bus data, previously.
My interest now is to sort them according to certain values of the column and then get an average result of them.
Given that the tiara doesn't seem to support the triage function after loading data, it seems to be a difficult issue for me;
It would be useful that I can get all related index/approach/function/Council to do this kind of script.
I've attached a file excel for example.
In the first "raw" sheet, there are rows of raw data with column names of "year, month, day, ID, ID2, point, condition.
Actual data had many more columns, but I simplified it for convenience.
What I try to do is, with the entry (from DialogBox or simply a script as a variable; I can do this) 'year' and 'months' (e.g.: 2015, 6).
to get the resulting data sheet 'expected results '.
The result is sorted by value 'ID' and 'condition '. 'Condition' is 0 or 1, then the average of the values of 'point' for each ID and the condition is obtained.
Group for the 'condition' of 2 will be the average of the results of the 'condition' 0 and 1 (collection of data). (So there are always three groups: for 'condition', 0, 1, and 2.)
Currently, 'ID' includes 12345 and 54321, but there may be more values, too.
"Num" column is the number of files RAW allows to get the average for the corresponding 'year-month-ID-condition'.
Is there an effective approach or the function that you recommend?
I think that you may need more details for example data, so please do not hesitate to ask me.
Thanks in advance.
Inyoung
The interactive part to modify data in DIAdem is collected in the 'ANALYSIS' left aon tab.
The second entry, 'Functions of channel' contains 'Values of Channel sorting' method.
To automate this process, it is possible to use the macro recorder in the tge script module.
-
How to read the data with different XML schemas within the unique connection?
- I have Oracle database 11g
- I access it via JDBC: Slim, version 11.2.0.3, same as xdb.
- I have several tables, each has an XMLType column, all based on patterns.
- There are three XML schemas different registered in the DB
- Maybe I need to read the XML data in multiple tables.
- If all the XMLTypes have the same XML schema, there is no problem,
- If patterns are different, the second reading will throw BindXMLException.
- If I reset the connection between the readings of the XMLType column with different schemas, it works.
The question is: How can I configure the driver, or the connection to be able to read the data with different XML schemas without resetting the connection (which is expensive).
Code to get data from XMLType is the implementation of case study:
1 ResultSet resultSet = statement.executeQuery( sql ) ;
2 String result = null ;
3 while(resultSet.next()) {
4 SQLXML sqlxml = resultSet.getSQLXML(1) ;
5 result = sqlxml.getString() ;
6 sqlxml.free();
7 }
8 resultSet.close();
9 return result ;It turns out, that I needed to serialize the XML on the server and read it as BLOB. Like this:
1 final Statement statement = connection.createStatement() ; 2 final String sql = String.format("select xmlserialize(content xml_content_column as blob encoding 'UTF-8') from %s where key='%s'", table, key ) ; 3 ResultSet resultSet = statement.executeQuery( sql ) ; 4 String result = null ; 5 while(resultSet.next()) { 6 Blob blob = resultSet.getBlob( 1 ); 7 InputStream inputStream = blob.getBinaryStream(); 8 result = new Scanner( inputStream ).useDelimiter( "\\A" ).next(); 9 inputStream.close(); 10 blob.free(); 11 } 12 resultSet.close(); 13 statement.close(); 14 15 System.out.println( result ); 16 return result ; 17Then it works. Still, can't get it work with XMLType in resultset. On the customer XML unwrapping explodes trying to pass to another XML schema. JDBC/XDB problem?
-
Dynamic data of several channels in table, then save in Excel
Hello
I am acquiring data from several channels (4-5) and I'd like to collect samples at low rates (10 Hz for 3 minutes max). For various reasons I use Dynamic Data type, although I know that it is not the best way (some say it is a wrong data type
 ). I also want to save data to a file (the best option would be data excel file).
). I also want to save data to a file (the best option would be data excel file).If I acquire data 10 times per second, it is quite slow to save in excel (this is the slowest option of all types of data). So I would like to fill a table or matrix of acquired data and then write Excel file (I use scripture to measure file). But I don't know how to do - if I convert DDT in DBL, build an array and connect it to change registry, it works but I lose the information in column names and I'm wasting time. If I connect to build the table a DDT and then shift record another, it returns the table 1 d of DDT. I would like to have 2D DDT, which collects all the information loop. Is there a suggestion how to solve?
I'm sure it would be easier solved my problem with the double data type but I also use select signals VI which is the VI I am not able to replace at this time.
Good day
Lefebvre
I don't know if there is a question here, or what. Doing what you say you want to make, acquire the data of 4-5 channels at low rates (10 Hz for 3 minutes) and save the data in an Excel file (I assume you mean really Excel, i.e. a file with the extension .xls or .xlsx) is really a very easy thing to do in LabVIEW, especially if you are not using :
- DAQ Assistant
- Dynamic Data
- Write to the action file.
Indeed, you seem to realize this, but I guess you want to 'do the hard', in any case.
Good luck.
Bob Schor
-
Digital control system, using limits of entry of data with global variables
Hello!
I have a Subvi with several digital control sliders. These control framerate, the pixel clock and exposure of a camera and their change in max/min/increment whenever one of them is changed - they are interdependent and get their information from the camera continuously during execution.
I'm trying to remote control this VI, but during the passage of a value using global variables, it doesn't "stick".
Example:
The value for exposure is 237,48 Ms. different values are constrained to the nearest value. So if I pick 240,00 ms at the Subvi, he should know that this is not a valid value and change to Mrs. 237,48.
But it is not do and I don't know why. When I enter the values manually, it works fine.
Any suggestions?
The limits on the controls that apply when their control from the front and is not passing values via the connector pane.
You should use something like "line and force" within the VI to validate the values are within the range (maybe constrain data or return an error).
-
Dynamic region with several task page fragment flow isn't refreshing VO
JDeveloper version is 12.1.3 and Weblogic Server is 12.1.3.
We have a dynamic region with several task page fragment flow. We have created a menu that will open on the workflow task in the dynamic region. Before defining the workflow id in the bean, we execute query on the original Version after setting the bind variable. When we click on the menu is open the flow of relevant tasks in the region and showing the Original data table.
But when we open the same request again to a different browser session, it shows all the data in the original Version when the user clicks on the relevant menu item...
I have attached the code used to navigate to the different workflow tasks written in the bean from the back of the home page.
We have no idea why anyone what happens, if it's a server problem or a code issue. Because unless and until we open the target application in a new browser it works fine.
We tried and deployed on a remote server as well, but it gives the same question...
Would be really grateful for the help...
The user, the code you posted has some serious problems. Never, I repeat never store a reference to an application module in a static variable in a bean. That is why you see only data once. After that, the second session reuses the application module from the first to the configuration data, but to display data it uses a module different application.
The way you try to configuration data is too bad. You must pass the parameters to the workflow and init data in the default action of the workflow instead of doing before installing the new workflow id. A workflow is a unit of work that is kind of a black box. You may not assume that the stuff you do outside of this black box can be seen inside the box. This is only true if the workflow share the same control of data as it's parent (share of data control).
I suggest you read some documents on the workflow and how they work. A good start is to look at this video https://www.youtube.com/watch?v=A3CmDhWHaG0
or work through this tutorial 12 c (12.1.3) Oracle JDeveloper tutorials - working with bounded task flows, regions and routers
Timo
-
All records in a block of tabular data of several records in the shadow
I have a block of tabular data of several recordings and would like all the other records in the data block to have a shaded background color. How do I would accomplish this? (Excel worksheet attached that shows what I'm trying to do with a block of data Oracle Form)
I don't know how to control the background color of the current record, but this is NOT what I'm asking.
In the event where you fill your block using EXECUTE_QUERY you can do the following:
-Create a Visual attribute with the desired colors and name it VA_BACKGROUND
-Create a parameter named P_BANDING
-Put the following code in your PRE-QUERY-trigger:
:PARAMETER.P_BANDING:=1;
-Put the following code in your POST-QUERY-trigger)
IF :PARAMETER.P_BANDING=1 THEN DISPLAY_ITEM('YOUR_ITEM_NAME_HERE', 'VA_BACKGROUND'); END IF; :PARAMETER.P_BANDING:=1-:PARAMETER.P_BANDING;Need DISPLAY_ITEM code once for each item that you want to color.
-
Save data in several collections of data control
Hello
In another post (), I asked how to merge data from several collections and display it in a table. FrankNimphius gave me the right answer. I now have my table with merged data from my control of data collections. But now I have reverse request: the table must allow to insert new lines and to store the data in the model represented by all of these collections.
I saw this blog https://blogs.oracle.com/jdevotnharvest/entry/how_to_add_new_adfand it is great, but works with a collectionModel, but the idea is exactly the same thing, just with several collectionModels in a parent one.
The table is not lined with a collectionModel, it is bounded to a list < MyObject > in my managed bean, in order to control the integrated data to create/delete operations from the parent collection do not work.
Another thing is: for me the model is a black box, I don't know anything about the model, I just know the datacontrol.
Thank you!
AAPDL
Hello
If you only have access to the data controls then it has no option to combine the two data sources in a single data control (for example, Pojo). Go with a suggested abstraction managed bean, the option I see is to expose a method in the managed bean that you can use to create a new empty - list entry. This then will be displayed as a blank line in the table after PPR.
The trickiest part is later - when you submit or commit the new line - to manually create new lines in other iterators or update other data sources accordingly (for which you will need to know what information goes on what iterator control or data). If other data controls are not BC of the ADF, and then to persist new lines, you will need to explicitly call the methods exposed on the data controls. So what you basically generate is a managed implementation bean of a two-phase commit. And then there's the case of deletion to consider as well.
Frank
-
How to create a subform with several rows initialized?
I have a repeating subform on my form that should start with several lines initialized.
I can create several blank lines by setting the binding "repeat subform for each data element" and set the number of 'min', but I would like to have values in one of the columns so that doesn't happen.
I can create multiple instances of my subform named and initialize the value of the column in question, but then if I have the "repeat subform for each data item" checked I get additional dups, but the first row and the button Delete (right-click action "this.parent.instanceManager.removeInstance (this.parent.index);" ')»» and Add button (click an action "_rates.addInstance (1)" "") erratic behavior. I mean here the button Add adds sometimes lines with values that have been deleted previously, and the delete button sometimes a warning saying something like "topmostSubform [0]: Page1 [0]: rates [10]: delete_button [0] .click on Index value is out of range.
There is no connection to a data source where I could get the values for the column, I want to initialize. In my opinion, I'm close, if only I could find the correct settings for the links palette.
Thanks for your suggestions!
If you have columns and rows, why not use a table instead of subform...
Check the setting of binding to "repeat the line for each data item.
Add the button 'Delete Row' to each line in the last column.
Add the button 'Add Row' under the Table.
Add text fields to the columns that you want the data displayed / modified by the user.
I hope this helps.
If not, let me know...
Thank you
Srini
-
Selection of data with or without the use of cursors in procedures
Hello
If we are able to access the data without using a cursor as shown below in a way:
CREATE OR REPLACE PROCEDURE tmr_exception
IS
x LINK_STATUS. COUNTRY_CODE % TYPE;
BEGIN
SELECT COUNTRY_CODE LINK_STATUS x;
EXCEPTION
WHEN TOO_MANY_ROWS THEN
dbms_output.put_line (' too many lines).
WHILE OTHERS THEN
dbms_output.put_line ("' another problem");
END tmr_exception;
*/*
So what is useful in the use of explicit cursors?(1) SELECT... Return exactly 1 row. If you try to deal with several rows of data, you will need another construction.
(2) A SELECT... INTO opens a cursor. He has simply done implicitly. Just like
BEGIN FOR emp_cur IN (SELECT * FROM emp) LOOP <> END LOOP; END; Opens an implicit cursor.
(3) no implicit and explicit cursors these days are generally useful when you do treatment in bulk and you want to extract the data in a local collection.
Justin
Published by: Justin Cave on October 9, 2010 20:17
(4) oh and you would never have in real code catch an exception and do nothing else than calling DBMS_OUTPUT. It's a quick way to produce a totally unmanageable code.
-
grouping data with a dynamic number of levels
Is it possible to do something like:
< cfloop... >
< cfoutput group =... >
...
< / cfloop >
< cfoutput >
...
< / cfoutput >
< cfloop... >
< / cfoutput >
< / cfloop >
I tried but it doesn't seem to work. I would like to consolidate data from several levels deep, with a dynamic number of levels. I don't know it in advance. Is it possible to do?
Thank you
RomanHello
You cannot place the
tag inside a it will throw an error... Why don't you do the grouping at the query level?...
-
ETL - split manually entered data on several lines
Hi people. The question of an experienced Oracle semi programmer...
I'm looking for some advice on an elegant solution and/or good performance for a lot of food data our database Oracle (10 g R2).
The source data are entered manually and contains invalid entries. More important, a good percentage of the data contains several purchase order numbers into one field in the source, for example ("123456789, 987654000, 987654003, 987654006, 4008-4010').
In the destination table, I want each of these purchase orders to be its own record.
Any thoughts on a good approach to this? I read a few articles on Asktom.com on the 'pipeline functions', but since it is done on the back-end (client only comes into play until after I confirmed the results), I didn't know if I could derive all the benefits of lines own 'pipes' to a single DML vs coating DML statement in my PL/SQL.
The database "at a distance" from the source is also Oracle 10 g 2, if that matters.
I recently discovered how elegantly I could go the other way - compilation of the string fields to multiple records in a single string concatenated to the destination folder using analytical functions. Could take a PL/SQL process that ran for almost half an hour up to seconds in a single SQL statement. = D
Hoping maybe one of the experts can point me in the right direction here. Thanks in advance for any advice you can offer.with t1 as ( select '100000,100,103,105-109' str from dual union all select '200000,200,203,205-209' str from dual ), t2 as ( select str, regexp_substr(str,'[^,]+') first_element, column_value element_number, regexp_substr(str,'[^,]+',1,column_value) element from t1, table(cast(multiset(select level from dual connect by level <= length(regexp_replace(str || ',','[^,]'))) as sys.odciNumberList)) ), t3 as ( select str, first_element, element_number, element, regexp_substr(element || '-' || element,'[^-]+') start_sub_element, regexp_substr(element || '-' || element,'[^-]+',1,2) end_sub_element from t2 ) select str, case element_number when 1 then to_number(first_element) else to_number(first_element) + to_number(start_sub_element) + column_value - 1 end val from t3, table(cast(multiset(select level from dual connect by level <= end_sub_element - start_sub_element + 1) as sys.odciNumberList)) / STR VAL ---------------------- ---------- 100000,100,103,105-109 100000 100000,100,103,105-109 100100 100000,100,103,105-109 100103 100000,100,103,105-109 100105 100000,100,103,105-109 100106 100000,100,103,105-109 100107 100000,100,103,105-109 100108 100000,100,103,105-109 100109 200000,200,203,205-209 200000 200000,200,203,205-209 200200 200000,200,203,205-209 200203 STR VAL ---------------------- ---------- 200000,200,203,205-209 200205 200000,200,203,205-209 200206 200000,200,203,205-209 200207 200000,200,203,205-209 200208 200000,200,203,205-209 200209 16 rows selected. SQL>SY.
-
Concatenation of data with the GROUP BY clause
Hi again!
Following my previous thread...
I tried to apply the GROUP BY clause instead of preforming my query with RANK() to manage records NULL... I have a scenario where I also need to concatenate data from several lines.
CREATE TABLE T_EMP (NUMBER OF EMP_NO, NAME VARCHAR2 (20));
INSERT INTO T_EMP VALUES (1001, 'MARK');
INSERT INTO T_EMP VALUES (1002, 'DAVID');
INSERT INTO T_EMP VALUES (1003, "SHAUN");
INSERT INTO T_EMP VALUES (1004, "JILL");
CREATE TABLE T_EMP_DEPT (NUMBER OF EMP_NO, DEPT_NO NUMBER);
INSERT INTO T_EMP_DEPT VALUES (1001, 10);
INSERT INTO T_EMP_DEPT VALUES (1001, 20);
INSERT INTO T_EMP_DEPT VALUES (1002, 10);
INSERT INTO T_EMP_DEPT VALUES (1002, 20);
INSERT INTO T_EMP_DEPT VALUES (1002, 30);
INSERT INTO T_EMP_DEPT VALUES (1003, 20);
INSERT INTO T_EMP_DEPT VALUES (1003, 30);
INSERT INTO T_EMP_DEPT VALUES (1004, 10);
CREATE TABLE T_EMP_VISITS (NUMBER OF EMP_NO, DEPT_NO NUMBER, VISITED DATE);
INSERT INTO T_EMP_VISITS VALUES (1001, 10, 1 JAN 2009');
INSERT INTO T_EMP_VISITS VALUES (1002, 10, 1 JAN 2009');
INSERT INTO T_EMP_VISITS VALUES (1002, 30, 11 APR 2009');
INSERT INTO T_EMP_VISITS VALUES (1003, 20, 3 MAY 2009');
INSERT INTO T_EMP_VISITS VALUES (1003, 30: 14 FEB 2009');
COMMIT;
I have a T_EMP master table that stores the name and number of the emp. Each emp is required to visit some departments. This mapping is stored in the T_EMP_DEPT table. An employee can visit one or more departments. T_EMP_VISITS table stores the dates where the employee visited the services required. I need to view the report which should show when an employee all completed visits, which is the maximum date when it finished to visit all departments. If he did not visit any of the report should display date max, otherwise NULL. I was able to do using GROUP BY such proposed by Salim, but how do I show a list separated by commas of the services required for an employee in the same query.
SELECT
EMP_NO,
NAME,
MAX (DEPT_NO) KEEP (DENSE_RANK LAST ORDER BY VISITED) MAX_DEPT_NO,.
MAX (VISITED) KEEP (DENSE_RANK LAST ORDER PER VISIT) VISITS_COMP
DE)
SELECT
T_EMP. EMP_NO,
NAME,
T_EMP_DEPT. DEPT_NO,
VISITED
OF T_EMP
LEFT OUTER JOIN T_EMP_DEPT
ON T_EMP. EMP_NO = T_EMP_DEPT. EMP_NO
LEFT OUTER JOIN T_EMP_VISITS
ON T_EMP_DEPT. EMP_NO = T_EMP_VISITS. EMP_NO
AND T_EMP_DEPT. DEPT_NO = T_EMP_VISITS. DEPT_NO)
GROUP EMP_NO, NAME;
Output
EMP_NO NAME MAX_DEPT_NO VISITS_COMP
1001 MARK 20
1002 DAVID 20
1003 SHAUN 20 3 MAY 09
JILL 1004
Power required
EMP_NO NAME REQ_DEPTS MAX_DEPT_NO VISITS_COMP
1001 MARC 20 10.20
1002 DAVID 10,20,30 20
1003 SHAUN 20,30 20 3 MAY 09
JILL 10 1004
Can we do this in a single query?Hello
user512647 wrote:
... Sanjay
The query you provided that stragg() use seems to work but my requirement is not in the result set. I don't know how to use stragg with
MAX (DEPT_NO) KEEP (DENSE_RANK LAST ORDER BY VISITED) MAX_DEPT_NO,.
MAX (VISITED) KEEP (DENSE_RANK LAST ORDER PER VISIT) VISITS_COMP
I need more, these two columns these gives me the date when they have completed all visits. If they missed any Department then the result must be NULL in the VISITS_COMP field.Just add them to the SELECT clause:
SELECT t_emp.emp_no, name, STRAGG (t_emp_dept.dept_no) AS deptno, MAX (t_emp_dept.dept_no) KEEP (DENSE_RANK LAST ORDER BY visited) AS max_dept_no, MAX (visited) AS visits_comp FROM t_emp LEFT OUTER JOIN t_emp_dept ON t_emp.emp_no = t_emp_dept.emp_no LEFT OUTER JOIN t_emp_visits ON t_emp_dept.emp_no = t_emp_visits.emp_no AND t_emp_dept.dept_no = t_emp_visits.dept_no GROUP BY t_emp.emp_no , name ;The column called visit_comp is simply the last visited, regardless of how the employee visited departments.
If you want to have the NULL value if the employee has not yet visited all 3 departments:... CASE WHEN COUNT (DISTINCT t_emp_dept.dept_no) = 3 THEN MAX (visited) END AS visits_compThe 'magic number' 3 is the total number of departments.
If you want to understand the correct value of that at the time of the execution of the query, replace the code literal 3 hard with a scalar subquery.Note that 'KEEP MAX (x) (DENSE_RANK OVER LAST SERVICE BY x)' (where the exact same column is used as an argument and that the ORDER BY column) is just "MAX (x)".
Maybe you are looking for
-
What is the best piano keyboard to use with a macbook air?
Hi all: I would like to know what piano keyboards do you recommend to use with Garageband AND recording via my Macbook Air. I would have preferred a keyboard with many features - modulation of pitch, a good Bank of sounds, at least 6 titles, etc. I k
-
Settlement data based on multiple selection ListBox reference need help
Hello again, The question that I have is selecting from a listbox with multiple selection to fill the tables with the selected data. My code is as follows: Void loadData_EventClick (ByRef This) Dim j Dim k k = 0 If ListBox.MultiSelection.Count = 0 Th
-
Why do I get updated Microsoft Office when I have no office or work installed, they is an integral part of Windows 7?My next question is can I stop all these updates from the Office to settle?
-
problem with installing xp pro on Pavilion dv4-1190ej
I got blue screen at first until I get xxxx step
-
I have a problem with the touch screen of Sony.
Original title: "Sony touchscreen issues." I am running Windows 7 Home Premium on a Sony All In One with touchscreen. For about 4 weeks, I got a problem with weird things happening on the screen. For example, I can use any application and it will aut