MERGE a remote table in another remote table
Hello
I have a DB source and a target DB. I do not have enough privileges on source and target DBs create DB Link. Therefore, I installed an instance of Oracle XE between them to create links from DB appropriate both source and target DBs and run a MERGE statement to replicate data from source to the target. But when I run the MERGE statement below I get an error:
MERGE INTO TAB_A@TARGER T
USING (SELECT... OF TAB_B@SOURCE) S
WE (S.ID = T.ID)
WHEN MATCHED THEN
UPDATE ALL...
WHEN NOT MATCHED THEN
INSERT VALUES (...) );
Error report-
SQL error: ORA-02019: description of the connection to the remote database not found
ORA-02063: preceding the 10th line
ORA-02063: preceding 2 lines of the TARGET
02019 00000 - "description of the connection to the remote database not found"
* Cause:
* Action:

I wonder if this statement is possible or not?
Iman
P.S. I get error if I create a copy of TAB_A (target) in OracleXE as an intermediate table and run 2 separate instructions of FUSION. What I want to do is to eliminate the intermediate table.
I couldn't reproduce your problem as demonstrated by executing below.
Even with the different versions of database Oracle
myuser@XE>
conn myuser/myuser@target_db;
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.3.0
Connected as myuser
CREATE TABLE TAB_A AS
SELECT ROWNUM i, 'A' c
FROM dual
WHERE 1 = 2;
Table created
Executed in 0,062 seconds
conn myuser/myuser@source_db;
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.3.0
Connected as myuser
CREATE TABLE TAB_B AS
SELECT ROWNUM i, 'B' c
FROM dual
CONNECT BY LEVEL <= 10;
Table created
Executed in 4,329 seconds
conn myuser/myuser@XE;
Connected to Oracle Database 10g Enterprise Edition Release 10.2.0.4.0
Connected as myuser
MERGE INTO TAB_A@target_db t
USING TAB_B@source_db u
ON (t.i = u.i)
WHEN MATCHED THEN
UPDATE
SET t.c = u.c
WHEN NOT MATCHED THEN
INSERT
VALUES (u.i, u.c);
Done
Executed in 0,828 seconds
SELECT *
FROM TAB_A@target_db;
I C
---------- -
1 B
2 B
3 B
4 B
5 B
6 B
7 B
8 B
9 B
10 B
10 rows selected
Executed in 0,078 seconds
conn myuser/myuser@target_db;
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.3.0
Connected as myuser
DROP TABLE TAB_A;
Table dropped
Executed in 0,125 seconds
conn myuser/myuser@source_db;
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.3.0
Connected as myuser
DROP TABLE TAB_B;
Table dropped
Executed in 2,016 seconds
myuser@source_db>
But, I don't use any EXPRESS EDITION on my tests.
I don't really know if there is a limitation with her, but isn't really seems to me that this is your problem.
The error:
SQL error: ORA-02019: description of the connection to the remote database not found
ORA-02063: preceding the XE line
ORA-02063: preceding 2 lines of the TARGET
suggests to me that you are running your merge statement in the instance of bad...
Tags: Database
Similar Questions
-
Hi all
I have three table as follows:
Table of values (2, 3, 5, 1, 0, 4)
Two Array (00, 01, 03, 04, 05, 02) values
Table 3 (name1, name2, Name3, name4, name5, Name6) values
Now I have to merge these three table in a table as follows:
Table (2_00_NAME1, 3_01_Name2, 5_03_Name3... and so on)
Can someone help me with this? I don't know how to merge it as one?
If anyone can help I'd be very happy...
Thanks in advance...
Pals
You don't know what it is just that you want, but this could be a start.
-
How to merge 3 different tables using ADF BC?
Hello
I have 3 tables (i.e. employee location, Dept)
First of all I must merge employee and Dept as "* EmployeeDept *" table with the primary key (EmployeeID) and then I should merge "* EmployeeDept *" with Dept table with the primary key (DeptID) from the Dept table.»»
I tried "* ViewLink *"I am however able to merge two tables (employee and Dept) as "EmployeeDept", no idea how to merge the third table (Dept) with her. "
Help, please.
Thanks in advanceEither by the method described by Shay or build you a new vo, select expert mode for the query and write the select statement. In this case, the data cannot be modified.
Timo
-
help with some merged cells in table
I'm just learning how to use Dreamweaver 8 and tables. I am trying to use a table with merged cells, filled with graphics - one graph per cell. I make my jpg size of my cell, which seems to fill. Then, when I download to view in the browser, it seems that the graph does not entire cell. At one point, he worked in Dreamweaver and the browser. Now, in the browser view, it seems that there is more space above the image and below. Any suggestions on what is happening?Thank you! It is now clear that I should not use tables with the graphics.
-
Need some tips to merge the two table-manipulation functions
Hi guys!
Thanks to Johnsold, Helmut O'Brian and Jcarmody, who helped me through a string function complicated (for me, the noob of LV), I got away with my project and I'm very close to its end.
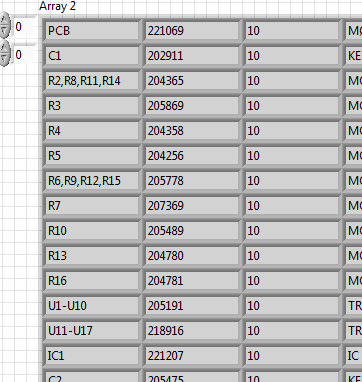
As I've described it here I wanted to explore an array of words combined with-, i.e. C1 - C10. Help, when I arrived, I was able to do. I also learned a few things and was able to do the following:
Original array: new table:
R1 R1
R2 R2
C1-C3 C1
K1 C2
C3
K1
I have this:
Original array: new table:
R1 R1
R2,R4,R7 R2
C1 R4
K1 R7
C1
K1
I was also able to combine these two functions

Now, back to my problem.
Until now, it was just a 1 d array that I worked with. In fact, it's a 2D array, I read a. CSV file:
As you can see there are a few places where things is combined with either - or by commas. I need to widen the first column as described above and as resolved in the thread I mentioned. Fact! No problem. I extracted the first column in table 1 d. Then expand it. Now, I need to replace in the original array and also expand all.
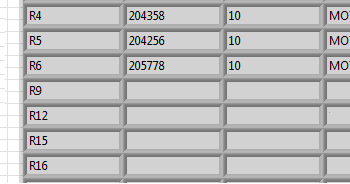
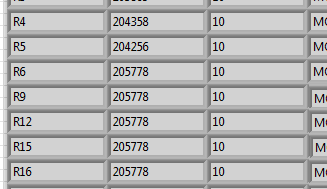
It should then look like this:
Then I only need to copy the position of the R6 line and paste it in the empty fields:
I enclose below two screws. Start by opening the main.vi. Then copy.vi. I tried to describe the problem here too. You can see what I've accomplished and what is missing.
Tasks:
1. replace the column expanded in the original array and expand all.
2 copy the needed lines.
In the main.vi, I do the 1 d expansion, but I have the problem with the expansion of table 2D. In copy.vi, I managed to copy the lines. If this part is done.
Basically, I need some advice on enlargement that I do and how do I get the 2D table also expanded. Because I have not much experience, I feel more comfortable working with 1 d arrays. But I can't seem to get any further with this 1 d-> expansion 2D.
I also really can't seem to find a smart way to implement my function of copy-line-in the main.vi.
P.S the joint screws are manufactured in LV2010.
Fortunately, I can attend some courses of basic home OR here in Norway, but so far, I'm still learning and I think that sometimes, I try to do things that are way out of my League

I don't know what I did but it works now
Thanks for the help, same!
You are even welcome!
Have attached the file if anyone wants to see what I did.
-
Replace/merge/replace/overlay table 3D
Dear community,
I was not the way to start this puzzle yet and I can't find an existing solution, so I'm sorry that I don't have any code to fix.
I've initialized a 3 dimensions array of size 500 x 500 x 200 with zeros that defines my VIEW where I then Index volume on the axis chosen flat to display in an image control.
My DATA table is also a table in 3 dimensions with the voxel values, but is not necessarily 500 x 500 x 200. I want to do is take some volume is the volume of DATA and replace/replace/overlay on the volume of DISPLAY to the {0,0,0} angle outward, so that the resulting table is full DATA and then completed up to 500 x 500 x 200 with zeros.
In my view, this should be a core function, but the only function I can find is the subset of the table replace which will replace only in 2D charts. I don't want to have to the index of each item and rebuild, because it would be incredibly slow and heavy memory. Also, I want really manually to "pad" on the DATA of 500 x 500 x 200 table because it feels very awkward and the curls would still be slow.
In my view, accession of element in Place could hold the key but cannot escape. Any help would be greatly appreciated.
Sincerely,
RG
PS. I am running LV 2015
Replace the subset of the table has to work, but the type it accepts changes of entry down according to the number of index entry that you wire in there. If you want to replace a table within a table 3D 3D, you will need to wire all the index entries 3 0.
Note that you may still have performance problems. Your array has elements of 50 M, which could be translated as hundreds of MB of RAM, depending on the type and the number of copies that you create, issue, because the arrays must be contiguous in memory.
In addition, the image control is not very effective with raster images, so you might have some problems there too.
-
Merge the three tables to get a single raw
Hello
I have the following tables 03
After I ran the above join I get several lines.SELECT * FROM tabA a WHERE a.id = '1234' -- here 2 rows found with 02 keyvalue = '62000' and '63000' SELECT * FROM tabB b WHERE b.key = '62000' --- 3 rows found here SELECT * FROM tabB b WHERE b.key = '63000' --- 3 rows found here SELECT * FROM tabC c WHERE c.key = '62000' -- only one row found here SELECT * FROM tabC c WHERE c.key = '63000' -- only one row found here SELECT * FROM tabA a, tabB b, tabC c WHERE a.key = b.key AND a.id = '1234' AND b.key = c.key
But I need to get that one folder for the id = '1234'
Rgds
sexyVanessa,
But on what basis do you think a single folder?
Use of rownum may not always the right solution.
Jacob
-
Help with the merger of the table
Hello. I have the following query:
Select a.prospect, b.status_dt, c.status_dt
ttms.prospect a, ttms.prospect_exfc b, ttms.prospect_imap c
where a.prospect = c.prospect (+)
and a.prospect = b.prospect (+)
and trunc (nvl (c.status_dt, b.status_dt)) > = (trunc(sysdate-45))
and nvl (c.status, b.status) in('S','S2','S3','I','W','SC','TM');
I would select only one of the two columns of status_dt. I want to get the status_dt for the most recent status_dt column. So, if b.status_dt is 2009-03-21 and c.status_dt is 2009-03-23 so I only shoot c.status date because it is the most recent. Is this possible?greatest() function is what you want, but be careful to NULL values:
with my_tab as (select trunc(sysdate) col1, sysdate col2 from dual union all select null col1, sysdate col2 from dual union all select sysdate-1 col1, null col2 from dual union all select sysdate-2 col1, sysdate - 1 col2 from dual) -- end of data setup select col1, col2, greatest(col1, col2) res1, greatest(nvl(col1, to_date('01/01/1900', 'dd/mm/yyyy')), nvl(col2, to_date('01/01/1900', 'dd/mm/yyyy'))) res2 from my_tab; COL1 COL2 RES1 RES2 --------------------- --------------------- --------------------- --------------------- 23/03/2009 00:0:00 23/03/2009 14:13:01 23/03/2009 14:13:01 23/03/2009 14:13:01 23/03/2009 14:13:01 23/03/2009 14:13:01 22/03/2009 14:13:01 22/03/2009 14:13:01 21/03/2009 14:13:01 22/03/2009 14:13:01 22/03/2009 14:13:01 22/03/2009 14:13:01 -
How to navigate the web application from merger of a page to another page.
Jin
I created an application in jdevloper 11g, which works very well in the default server. But when I deployed to ask the domain server customized at run time
I am facing problem of navigation. He's not going to another page. Please help me.
Thanking you
Rayudu SubrahmanyamDo not write in the writing of .jspx URL page without its extension name
-
Merger of the various tables in the form of a long table
Hi there, I have a problem with the merger of the table.
Due to the nature of my VI, I'll have to merged paintings together to form a single table.
I designed a VI using the loop and switching of cases but the current table keep to overwrite the previous table. I had to activate auto-indexation on the loop, but it couldn't work.
I am attaching two VI for illustration more far.
Try to merge the tables togther.vi is the program that I'm trying.
Desired output program.vi is the real thing, I want to get to the exit.
Thanks for all the help.
Keith Tan
Hi Keith,
It's the magic of the shift registers

You should always note what LV version you are using!
-
Hi all
Can I combine the records in the nested table
I have a table with 2 colum: col_1 and col_2
col_1: corresponds to the id (varchar2)
col_2: is a column nested with the type of table (sub_col_1 (number), sub_col_2 (number))
for example: I have 2 accounts table ('a', (1,2)) and ('b', (3,4)))
what I want is merged into this table with values ('a', '4.5')) + ('c', (6,7)) IN a single statement
What I should have after this operation ('a', (1,2,4,5)) + ('b', (3,4)) + ('c', (6,7)).
Can I do this?
Oracle version: 11.2.0.3CREATE OR REPLACE TYPE TEST_TYPE AS OBJECT(SUB_COL_1 NUMBER, SUB_COL_2 NUMBER) ; CREATE OR REPLACE TYPE TEST_TYPE_TABLE IS TABLE OF TEST_TYPE; CREATE TABLE TEST_MERGE_NESTED_TABLE (COL_1 VARCHAR2(1 CHAR), COL_2 TEST_TYPE_TABLE) NESTED TABLE COL_2 STORE AS COL_2_NESTED; INSERT INTO TEST_MERGE_NESTED_TABLE VALUES('a',TEST_TYPE_TABLE(TEST_TYPE(1,2) )); INSERT INTO TEST_MERGE_NESTED_TABLE VALUES('b',TEST_TYPE_TABLE(TEST_TYPE(3,4) ));
Thank you all.
Published by: 966205 on 20:18 21/02/2013
Published by: 966205 on 20:42 21/02/2013966205 wrote:
That means he does the same thing as what I want (adding? do not recreate this column in the physical layer).Actually, no.
All content of the nested table is first removed (for the given FK), then the result of the MULTISET UNION is reinserted.The evidence on:
SQL> alter session set events '10046 trace name context forever, level 12'; Session altered. SQL> merge into test_merge_nested_table t 2 using ( 3 select 'a' col_1, TEST_TYPE_TABLE(TEST_TYPE(4,5)) col_2 from dual union all 4 select 'c' , TEST_TYPE_TABLE(TEST_TYPE(6,7)) from dual 5 ) v 6 on ( t.col_1 = v.col_1 ) 7 when matched then update 8 set t.col_2 = t.col_2 multiset union v.col_2 9 when not matched then insert (col_1, col_2) 10 values (v.col_1, v.col_2) ; 2 rows merged. SQL> alter session set events '10046 trace name context off'; Session altered. SQL> select * from test_merge_nested_table; C COL_2(SUB_COL_1, SUB_COL_2) - -------------------------------------------------------------------------------- c TEST_TYPE_TABLE(TEST_TYPE(6, 7)) a TEST_TYPE_TABLE(TEST_TYPE(1, 2), TEST_TYPE(4, 5)) b TEST_TYPE_TABLE(TEST_TYPE(3, 4))TKPROF output:
DELETE, the nested table statement objectives associated with 'a' and deletes the line after line that it contains (1,2).
The later INSERTION is performed twice (run count = 2) and target the two nested table 'a' by inserting 2 ranks: former one (1,2) + the new one (4.5) and the nested table 'c' by inserting 1 row (6,7).SQL ID: 6bjc2z2t53csn Plan Hash: 132214516 DELETE /*+ REF_CASCADE_CURSOR */ FROM "DEV"."COL_2_NESTED" WHERE "NESTED_TABLE_ID" = :1 call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 1 3 1 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.00 0.00 0 1 3 1 Misses in library cache during parse: 0 Optimizer mode: CHOOSE Parsing user id: SYS (recursive depth: 1) Number of plan statistics captured: 1 Rows (1st) Rows (avg) Rows (max) Row Source Operation ---------- ---------- ---------- --------------------------------------------------- 0 0 0 DELETE COL_2_NESTED (cr=1 pr=0 pw=0 time=44 us) 1 1 1 INDEX RANGE SCAN SYS_FK0000023444N00002$ (cr=1 pr=0 pw=0 time=10 us)(object id 23446) **************************************************************************************************************************************************************** SQL ID: 0fzd5yk23jyas Plan Hash: 0 INSERT /*+ NO_PARTIAL_COMMIT REF_CASCADE_CURSOR */ INTO "DEV"."COL_2_NESTED" ("NESTED_TABLE_ID","SYS_NC_ROWINFO$") VALUES (:1, :2) call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 2 0.00 0.00 0 0 0 0 Execute 2 0.00 0.00 0 2 10 3 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 4 0.00 0.00 0 2 10 3 Misses in library cache during parse: 0 Optimizer mode: ALL_ROWS Parsing user id: 50 (recursive depth: 1) Number of plan statistics captured: 1 Rows (1st) Rows (avg) Rows (max) Row Source Operation ---------- ---------- ---------- --------------------------------------------------- 0 0 0 LOAD TABLE CONVENTIONAL (cr=1 pr=0 pw=0 time=113 us) ******************************************************************************** -
Hello
I have two partitioned tables.
Table 1 has 15 partitions and each partition has about 3 million documents.
Table 2 has 20 partitions and each partition has about 3 million documents.
I want to merge these two tables into a single table so that the new table has all the partitions with respective storage spaces.
All suggestions and what would be the best way to do it?
Thanks in advance.>
Can I swap partitions between two partitioned tables?
>
Yes - but not the way you try. You need to RTFM! I pointed out the exact section of the document that applies to your use case. You must make the Exchange, the way in which the documentation said: via a hash partitioned work table.Here's a solution that people may want to add to their Toolbox.
This code example moves actually 4 partitions of the table EMP_PART to the same, but empty, scores of the EMP_PART_NEW table by using the table of work EMP_PART_HASH.
-- EMP_PART table has 4 range partitions with data in each partition -- this data will be moved (via partition exchange) to the EMP_PART_NEW table DROP TABLE EMP_PART; CREATE TABLE emp_part (empno number(4), ename varchar2(10), deptno number(2), created_date DATE default sysdate) partition by range (created_date) SUBPARTITION BY HASH(deptno) subpartitions 4 ( partition p1 values less than (to_date('01-01-2013', 'mm-dd-yyyy')), partition p2 values less than (to_date('01-02-2013', 'mm-dd-yyyy')), partition p3 values less than (to_date('01-03-2013', 'mm-dd-yyyy')), partition p4 values less than (to_date('01-04-2013', 'mm-dd-yyyy'))); INSERT INTO EMP_PART VALUES (1, 'EMP1', 1, SYSDATE - 7); INSERT INTO EMP_PART VALUES (1, 'EMP1', 1, SYSDATE - 6); INSERT INTO EMP_PART VALUES (1, 'EMP1', 1, SYSDATE - 5); INSERT INTO EMP_PART VALUES (1, 'EMP1', 1, SYSDATE - 4); -- EMP_PART_NEW table has 7 range partitions - only partitions p5, p6 and p7 have data -- Partitions p1, p2, p3 and p4 will receive data from the emp_part table via the emp_part_hash -- work table DROP TABLE EMP_PART_NEW; CREATE TABLE emp_part_new (empno number(4), ename varchar2(10), deptno number(2), created_date DATE default sysdate) partition by range (created_date) SUBPARTITION BY HASH(deptno) subpartitions 4 ( partition p1 values less than (to_date('01-01-2013', 'mm-dd-yyyy')), partition p2 values less than (to_date('01-02-2013', 'mm-dd-yyyy')), partition p3 values less than (to_date('01-03-2013', 'mm-dd-yyyy')), partition p4 values less than (to_date('01-04-2013', 'mm-dd-yyyy')), partition p5 values less than (to_date('01-05-2013', 'mm-dd-yyyy')), partition p6 values less than (to_date('01-06-2013', 'mm-dd-yyyy')), partition p7 values less than (to_date('01-07-2013', 'mm-dd-yyyy'))); INSERT INTO EMP_PART_NEW VALUES (1, 'EMP1', 1, SYSDATE - 3); INSERT INTO EMP_PART_NEW VALUES (1, 'EMP1', 1, SYSDATE - 2); INSERT INTO EMP_PART_NEW VALUES (1, 'EMP1', 1, SYSDATE - 1); -- work table for the exchange DROP TABLE EMP_PART_HASH; CREATE TABLE emp_part_hash (empno number(4), ename varchar2(10), deptno number(2), created_date DATE default sysdate) partition by hash (deptno) partitions 4; SELECT * FROM EMP_PART PARTITION (P2); EMPNO ENAME DEPTNO CREATED_DATE 1 EMP1 1 1/1/2013 6:52:54 PM select * from emp_part order by created_date; EMPNO ENAME DEPTNO CREATED_DATE 1 EMP1 1 12/31/2012 6:52:52 PM 1 EMP1 1 1/1/2013 6:52:54 PM 1 EMP1 1 1/2/2013 6:52:56 PM 1 EMP1 1 1/3/2013 6:52:58 PM select * from emp_part_new partition (p6); EMPNO ENAME DEPTNO CREATED_DATE 1 EMP1 1 1/5/2013 6:53:21 PM select * from emp_part_new order by created_date; EMPNO ENAME DEPTNO CREATED_DATE 1 EMP1 1 1/4/2013 6:53:19 PM 1 EMP1 1 1/5/2013 6:53:21 PM 1 EMP1 1 1/6/2013 6:53:23 PM -- exchange each partition from emp_part with the work table -- and then exchange the work table with the same partition of the emp_part_new table alter table emp_part exchange partition p1 with table emp_part_hash; alter table emp_part_new exchange partition p1 with table emp_part_hash; alter table emp_part exchange partition p2 with table emp_part_hash; alter table emp_part_new exchange partition p2 with table emp_part_hash; alter table emp_part exchange partition p3 with table emp_part_hash; alter table emp_part_new exchange partition p3 with table emp_part_hash; alter table emp_part exchange partition p4 with table emp_part_hash; alter table emp_part_new exchange partition p4 with table emp_part_hash; select * from emp_part order by created_date; -- no data select * from emp_part_new order by created_date; EMPNO ENAME DEPTNO CREATED_DATE 1 EMP1 1 12/31/2012 6:52:52 PM 1 EMP1 1 1/1/2013 6:52:54 PM 1 EMP1 1 1/2/2013 6:52:56 PM 1 EMP1 1 1/3/2013 6:52:58 PM 1 EMP1 1 1/4/2013 6:53:19 PM 1 EMP1 1 1/5/2013 6:53:21 PM 1 EMP1 1 1/6/2013 6:53:23 PMNote that:
1. all three tables have the same structure
2. all three arrays have the same number of HASH partitions. For two actual tables, they are HASH subpartitions
3. the working table has ONLY hash partitions: there is no range partitions.
4. all exchanges are simply updates the data dictionary and finish in a fraction of second bit is important the amount of data in one of the actual scores. -
merge 2 tables (from sql query)
Ahoj!
I have 4-sql queries, each with the same structure, but it is not possible to do in a single query. for example:
Query 1: extension, County a-> table 1 report
Query 2: extension, County b-> report table 2
Query 3: extension, County-> report table 3 c
Question 4: extension, County d-> report table 4
the result in the apex is now, I have 4 different tables. is it possible to merge these 4 tables table 1 apex?
extension, number a, b number, County c County d-> report table
I use the standard sql-report, non-interactive.
THX,
ChristianYou can try something like this (not a not test it):
SELECT A.EXTENSION, $A.COUNT, C.COUNT, B.COUNT, D.COUNT
Of
(SELECT the extension, County)
A
) a
,
(SELECT the extension, County)
B
) b
,
(SELECT the extension, County)
C
) c
,
(SELECT the extension, County)
D
) d
WHERE a.extension = b.extension
AND b.extension = c.extension
AND c.extension = d.extensionConcerning
Roel -
Hello
We are working on a data warehousing project and wonder how do to join several tables that each are versioned separately (type SCD 2 with a valid and valid to date).
Because for example, we get our client from a single source of information (id customer, name, etc.) and the information on the rate of customer from another source. The sources are different, we have the separate tables for them and each of them gets versioned independently.
Here's my customer table (with its own valid and valuable to the columns).
ID Name of the customer Valid from Valid until the 1 CitiBank 1 JANUARY 14 JANUARY 1, 15 1 New CitiBank 2 JANUARY 15 FEBRUARY 1, 15 1 Latest CitiBank 2 FEBRUARY 15 APRIL 1, 15 And similarly the Client side ID and rating information.
ID Note Valid from Valid until the 1 Platinum 1 JANUARY 14 FEBRUARY 1, 14 1 Premium FEBRUARY 1, 14 1ST MARCH 15 I want to merge the two tables above and present information at a glance. I have some difficulty to determine validates the valid columns.
ID Name of the customer Note Valid from (Calculated) Valid until the (calculated) 1 CitiBank Platinum 1 JANUARY 14 FEBRUARY 1, 14 1 CitiBank Premium FEBRUARY 1, 14 JANUARY 1, 15 1 New CitiBank Premium 2 JANUARY 15 FEBRUARY 1, 15 1 Latest CitiBank Premium 2 FEBRUARY 15 1ST MARCH 15 And it's the query I used to get the above result:
SELECT client. id ,
customer . name ,
CRM . level ,
Greatest (client. vld_fm , crm. vld_fm ),
Least (client. vld_to , crm. vld_to )
DE client client,
client_rating crm
OÙ client. id = crm. id
AND ( client. vld_fm <= crm. vld_fm
AND client. vld_fm <= crm. vld_to
AND client. vld_fm >= crm. vld_fm
AND client. vld_fm >= crm. vld_to )
OR ( client. vld_fm BETWEEN crm. vld_fm AND crm. vld_to )
OR ( client. vld_to BETWEEN crm. vld_fm AND crm. vld_to );
The problem is we have several data sources (and each with its own versions) and joins become so very very complex. Is there a better way to write the query?Or maybe a better way to design our tables?
Thanks for your help.
Anand
Hello
you only need ranges that overlap to join.
Re: How do to sql query in a loop
Is a simpler way to test if the x_start to x_stop range comes into conflict with the range of y_start to y_stop
WHERE x_start <= y_stop AND y_start <= x_stopIn other words, two overlapping if and only if everyone will start before the other ends one. If this is not obvious (and it was certainly not clear to me when I heard it), then look at it this way: two ranges are not overlapping if and only if one of them starts after the end of the other.
Concerning
Marcus
-
Sorting table non-base point - this scenario is not possible?
I have a form running on a record of outgoing calls table named Call_Queue.
Each record in Call_Queue can be merged to the table of Call_Issues from Participant_Id , and may have several associated issues.
Each record in Call_Issues can be merged to the Call_Issue_Management table based on Issue_Id to obtain priority associated with the issue.
I want to sort my files to call out (Call_Queue) by the value of the highest priority on the Call_Issue_Management table. Is it possible to do an Order By another base table that would make reference to the value of higher priority issues assigned to the registration of Call_Queue?
Your help would be much appreciated!
Call_Queue --------------------------- PARTICIPANT_ID * CALL_STATUS Sample Data: 1234567 4 8904567 3 ABC4567 2 Call_Issues ----------------------------- PARTICIPANT_ID * ISSUE_ID ** Sample Data: 1234567 101 8904567 101 8904567 201 8904567 301 ABC4567 201 Call_Issues_Manangement ------------------------------------ ISSUE_ID ** ISSUE_DESCR PRIORITY Sample Data: 101 DESCRA 100 201 DESCRB 200 301 DESCRC 300 Call_Queue (WITH DESIRED SORT) --------------------------- PARTICIPANT_ID * CALL_STATUS PRIORITY (NON BASE TABLE) Sample Data: 8904567 3 300 ABC4567 2 200 1234567 4 100It is possible. In other words a MAX() around the emphasis in the subquery in the order of.
Maybe you are looking for
-
my iphone 5 s screen is not turn on
my iphone 5 s screen has suddenly exploded and no lights to the top... but the phone works as it sounds when I make a call on my phone from my other phone any help
-
Satellite A355-S6925 - SDHC not recognized
My Toshiba Satellite A355-S6925 does not recognize a Lexar Platinum II 32 GB SDHC card class 4. My last hard drive crashed and I replaced with a new one and installed Windows 7 from scratch. Am I missing a driver or firmware to use the built in reade
-
Can't stop the operating system
When I try to stop that I get a series of boxes to come and say that the laptop trying to close programs to which I am invited to click 'End now' or 'Cancel '. Why didn't he just closes everything?It takes forever to close all the latter.
-
Can not post on the discussion forum
Hello I tried to fill in information for the best of the knowledge to start a new discussion. Get a strange error when posting, there is no error message or of the text id. What Miss me? Thank you
-
Compaq MINI CQ10-101SO: Compaq CQ10 enter current password
My Compaq Mini CQ10 asks right CURRENT password after power on. s/n [personal information] p/n VZ422EA #UUW