to merge the three table
Hi all
I have three table as follows:
Table of values (2, 3, 5, 1, 0, 4)
Two Array (00, 01, 03, 04, 05, 02) values
Table 3 (name1, name2, Name3, name4, name5, Name6) values
Now I have to merge these three table in a table as follows:
Table (2_00_NAME1, 3_01_Name2, 5_03_Name3... and so on)
Can someone help me with this? I don't know how to merge it as one?
If anyone can help I'd be very happy...
Thanks in advance...
Pals
You don't know what it is just that you want, but this could be a start.
Tags: NI Software
Similar Questions
-
Merge the three tables to get a single raw
Hello
I have the following tables 03
After I ran the above join I get several lines.SELECT * FROM tabA a WHERE a.id = '1234' -- here 2 rows found with 02 keyvalue = '62000' and '63000' SELECT * FROM tabB b WHERE b.key = '62000' --- 3 rows found here SELECT * FROM tabB b WHERE b.key = '63000' --- 3 rows found here SELECT * FROM tabC c WHERE c.key = '62000' -- only one row found here SELECT * FROM tabC c WHERE c.key = '63000' -- only one row found here SELECT * FROM tabA a, tabB b, tabC c WHERE a.key = b.key AND a.id = '1234' AND b.key = c.key
But I need to get that one folder for the id = '1234'
Rgds
sexyVanessa,
But on what basis do you think a single folder?
Use of rownum may not always the right solution.
Jacob
-
Need some tips to merge the two table-manipulation functions
Hi guys!
Thanks to Johnsold, Helmut O'Brian and Jcarmody, who helped me through a string function complicated (for me, the noob of LV), I got away with my project and I'm very close to its end.
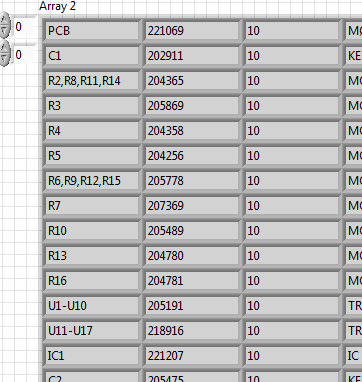
As I've described it here I wanted to explore an array of words combined with-, i.e. C1 - C10. Help, when I arrived, I was able to do. I also learned a few things and was able to do the following:
Original array: new table:
R1 R1
R2 R2
C1-C3 C1
K1 C2
C3
K1
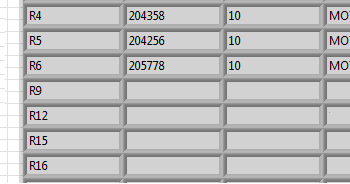
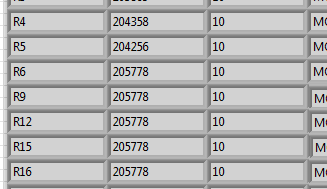
I have this:
Original array: new table:
R1 R1
R2,R4,R7 R2
C1 R4
K1 R7
C1
K1
I was also able to combine these two functions

Now, back to my problem.
Until now, it was just a 1 d array that I worked with. In fact, it's a 2D array, I read a. CSV file:
As you can see there are a few places where things is combined with either - or by commas. I need to widen the first column as described above and as resolved in the thread I mentioned. Fact! No problem. I extracted the first column in table 1 d. Then expand it. Now, I need to replace in the original array and also expand all.
It should then look like this:
Then I only need to copy the position of the R6 line and paste it in the empty fields:
I enclose below two screws. Start by opening the main.vi. Then copy.vi. I tried to describe the problem here too. You can see what I've accomplished and what is missing.
Tasks:
1. replace the column expanded in the original array and expand all.
2 copy the needed lines.
In the main.vi, I do the 1 d expansion, but I have the problem with the expansion of table 2D. In copy.vi, I managed to copy the lines. If this part is done.
Basically, I need some advice on enlargement that I do and how do I get the 2D table also expanded. Because I have not much experience, I feel more comfortable working with 1 d arrays. But I can't seem to get any further with this 1 d-> expansion 2D.
I also really can't seem to find a smart way to implement my function of copy-line-in the main.vi.
P.S the joint screws are manufactured in LV2010.
Fortunately, I can attend some courses of basic home OR here in Norway, but so far, I'm still learning and I think that sometimes, I try to do things that are way out of my League

I don't know what I did but it works now
Thanks for the help, same!
You are even welcome!
Have attached the file if anyone wants to see what I did.
-
How to merge 3 different tables using ADF BC?
Hello
I have 3 tables (i.e. employee location, Dept)
First of all I must merge employee and Dept as "* EmployeeDept *" table with the primary key (EmployeeID) and then I should merge "* EmployeeDept *" with Dept table with the primary key (DeptID) from the Dept table.»»
I tried "* ViewLink *"I am however able to merge two tables (employee and Dept) as "EmployeeDept", no idea how to merge the third table (Dept) with her. "
Help, please.
Thanks in advanceEither by the method described by Shay or build you a new vo, select expert mode for the query and write the select statement. In this case, the data cannot be modified.
Timo
-
While problems brought together three tables in Oracle
Hello
I'm trying to join the three tables in Oracle, but get unexpected results. Here it is the situation.
Table A has 10 rows and I want the line with Max date, table B has 20 rows and I want the line with Max date, so these 2 tables, I want 2 rows. Similarly, there are 10 tables with a huge amount of data.
So I created another table called table key and extract the name of the Table, the Table key (common across all the tables and plan called of code) and entered into force (it is a date max)
If key table now has a line of each table.
When I joined the table a (E221), table B (E227) and key table with query below, it does not result in any line. Can you please on how it should be resolved. Here it is the data from 3 tables.
Table A (E221)
PLAN_CODE DATE CAR GRP
12040005 19900801 1204 0005 20
12040005 19850201 1204 0005 19
12040005 19840801 1204 0005 20
12040004 20080806 1204 0004 20
12040004 20080804 1204 0004 20
12040004 20070701 1204 0004 20
12040004 20060101 1204 0004 20
12040004 20020101 1204 0004 20
12040004 20010730 1204 0004 20
TABLE B (E227)
12040005 19850201 1204 0005 0005
12040005 19840801 1204 0005 0080
12040004 20091001 1204 0004 6782
12040004 20070901 1204 0004 6782
12040004 20051101 1204 0004 6782
Key table
12040004 20080806 E221
12040005 20080806 E221
12040004 20091001 E227
12040005 20091001 E227
Query used
SELECT E221.*,
E227.*,
KEY_PLAN_CODE.*
OF E221
JOIN INTERNAL KEY_PLAN_CODE
ON KEY_PLAN_CODE. EC_PLAN_CD = E221. EC_PLAN_CD AND KEY_PLAN_CODE. MAX_EFF_DATE = E221.cg_cvr_BS_EFF_DT
AND KEY_PLAN_CODE. EC_TRAN_CODE = E221. EC_TRAN_CODE
JOIN IN-HOUSE E227
ON (KEY_PLAN_CODE. EC_PLAN_CD = E227. EC_PLAN_CD
AND E227. PLAN_EFF_DT = KEY_PLAN_CODE. MAX_EFF_DATE
AND KEY_PLAN_CODE. EC_TRAN_CODE = E227. EC_TRAN_CODE)
Any suggestions would be helpful.I'm still a little confused as to what should be returned.
Your key table includes:
12040004 20080806 E221
12040005 20080806 E221
12040004 20091001 E227
12040005 20091001 E227I suppose you want returned:
E221 line with plan_code 12040004 and the date 20080806
E221 line with plan_code 12040005 and the date 12040004
Line E227 with plan_code 12040004 and the date 20091001
Line E227 with plan_code 12040005 and the date 20091001Your query returns original nothing because, for example, the line containing plan_code 12040004 and date 20080806 can does not match anything in the E227 table with this plan_code and the date.
I think you are saying that what you want is, for each value of different plan_code, you want recording E221 corresponding to "E221" key_table folder with the date of the registration, and you also want to record E227 corresponding to "E227" key_table folder with the date of registration. I also guess that there must be a record E221 both INAT E227, otherwise nothing is returned for this plan_code.
I suppose also that there is no record more "E221" and no more a 'E227' record in key_table for any value special plan_code.
In this case, you want to do something like this:
SELECT K.*, E221.*, E227.* FROM ( SELECT k221.ec_plan_cd, k221.max_eff_date AS e221_date, k227.max_eff_date AS e227_date FROM key_plan_code k221 JOIN key_plan_code K227 ON k227.ec_plan_cd = k221.ec_plan_cd WHERE k221.ec_tran_code = 'E221' AND k227.ec_tran_code = 'E227' ) K INNER JOIN E221 ON (E221.ec_plan_cd = K.ec_plan_code AND E221.cg_cvr_bs_eff_dt = K.max_eff_date) INNER JOIN E227 ON (E227.ec_plan_cd = K.ec_plan_code AND E227.plan_eff_dt = K.max_eff_date)The subquery K Gets a line for each ec_plan_cd in key_plan_code with a record 'E221' and a «E227» folder
I'm assuning ec_tran_code is the column of key_plan_code with 'E221' and 'E227. " If this is not the case, use the correct name.
-Don
-
Left join with three-table join query
I am trying to create a query that left me speechless. Most of the query is simple enough, but I have a problem I do not know how to solve.
Background:
We have stock stored in i_action.
We have the attributes available for each type of action. The attributes available for each action are described in shared_action_attribute. Each type of action can have three attributes or none at all.
We have the values stored for the attributes in i_attribute_value.
An example says:
We have a transfer action (action_code B4). The action of B4 entry into i_action records the fact that the transfer took place and the date at which he spoke. The attributes available for a transfer action are the function code receiver, the receiving unit number and the reason of transfer code. These types of attributes available and their order are stored in shared_action_attribute. The actual values of the attributes for a specific action of transfer are stored in i_attribute_value.
Now i_action and i_attribute_value can be connected directly in action_seq in i_action and ia_action_seq in i_attribute_value. A left join on these two tables provides results for all actions (including actions that have no attributes) and assign values (see Query 1 below).
There are two questions. First of all, I want only the first two attributes. To specify the attributes of the first two, I also i_attribute_value a link to shared_action_attribute (which is where the order is stored). I can build a simple query (without the left join) which connects the three tables, but then shares without attributes would be excluded from my result (see Query 2 below).
The second problem is that I'd actually a row returned for each action with first_attribute and second_attribute in the form of columns instead of two lines.
The final query will be used to create a materialized view.
Here are the tables and examples of what is stored in the:
TABLE i_action
Name Type
----
ACTION_SEQ NUMBER (10)
DATE OF ACTION_DATE
ACTION_CODE VARCHAR2 (3)
VARCHAR2 (1) DELETED
EXAMPLE OF LINES
ACTION_SEQ ACTION_DATE DELETED ACTION_CODE
----
45765668 9 OCTOBER 09 B2 HAS
45765670 9 OCTOBER 09 BA HAS
45765672 B6 9 OCTOBER 09A
45765673 9 OCTOBER 09 B4 HAS
45765674 9 OCTOBER 09 G1 HAS
45765675 9 OCTOBER 09 M3 HAS
TABLE i_attribute_value
Name Type
---
IA_ACTION_SEQ NUMBER (10)
SACTATT_SACT_CODE VARCHAR2 (3)
SACTATT_SAT_TYPE VARCHAR2 (3)
VARCHAR2 VALUE (50)
EXAMPLE OF LINES
IA_ACTION_SEQ SACTATT_SACT_CODE SACTATT_SAT_TYPE VALUE
----
45765668 B2 COA 37 B
45765670 BA ROA D
45765670 BA ROR P
45765672 B6 CAT C
B4 45765673 RFC E
45765673 B4 TRC P
B4 45765673 RUN 7
45765674 G1 SS 23567
G1 45765674 ASG W
TABLE shared_action_attribute
Name Type
---
SACT_CODE VARCHAR2 (3)
SAT_TYPE VARCHAR2 (3)
ORDER NUMBER (2)
TITLE VARCHAR2 (60)
EXAMPLE OF LINES
SACT_CODE SAT_TYPE UNDER THE ORDER
----
B2 ACO 1 Office code
BA ROR 1 reason to re-open
Authority of BA ROA 2 reopen
B6 CAT 1 category
B4 RFC 1 reception function code
B4 RUN 2 receives the unit code
B4 TRC 3 transfer of reason code
Sequence of G1 SS 1 personal
Reason for G1 ASG 2 assignment
QUERY 1:
It's my current query as well as its results. Most are select simple but only one column is filled using the function analytic last_value (thank you guys). The last column in the view sub stores the value of the attribute. What I want is to replace this single column with two columns named first_attribute and second_attribute and eliminate all other attributes.
SELECT ia.action_seq, ia.action_date, ia.action_code cod,
NVL
(LAST_VALUE (CASE
WHEN ia.action_code = "G1".
AND iav.sactatt_sat_type = 'SS '.
THEN THE VALUE
WHEN ia.action_code IN ('A0', 'A1')
THEN '67089'
END IGNORE NULLS
) OVER (PARTITION BY ia.ici_charge_inquiry_seq ORDER BY ia.action_date,
IA.serial_number, ia.action_seq),
'67089'
) staff_seq,.
value
From i_action LEFT JOIN i_attribute_value iav AI
ON iav.ia_action_seq = ia.action_seq
WHERE ia.deleted = 'A ';
ACTION_SEQ ACTION_DA COD STAFF_SEQ VALUE
----
45765668 9 OCTOBER 09 B2 67089 37 B
45765670 9 OCTOBER 09 BA D 67089
45765670 9 OCTOBER 09 BA 67089 P
45765672 9 OCTOBER 09 B6 67089 C
45765673 9 OCTOBER 09 B4 67089 E
45765673 9 OCTOBER 09 B4 67089 P
45765673 9 OCTOBER 09 67089 7 B4
45765674 9 OCTOBER 09 23567 23567 G1
45765674 9 OCTOBER 09 G1 23567 W
45765675 9 OCTOBER 09 M3 23567
QUERY 2:
This query is limited to the first two attributes but he also filed actions which have no attributes, and it creates still several lines for each action instead of a single line with two columns for attributes.
SELECT ia.action_seq, ia.action_date, ia.action_code cod,
NVL
(LAST_VALUE (CASE
WHEN ia.action_code = "G1".
AND iav.sactatt_sat_type = 'SS '.
THEN THE VALUE
WHEN ia.action_code IN ('A0', 'A1')
THEN '67089'
END IGNORE NULLS
) OVER (PARTITION BY ia.ici_charge_inquiry_seq ORDER BY ia.action_date,
IA.serial_number, ia.action_seq),
'67089'
) staff_seq,.
value
OF shared_action_attribute saa, ims_action AI, ims_attribute_value iav
WHERE iav.ia_action_seq = ia.action_seq
AND iav.sactatt_sact_code = saa.sact_code
AND iav.sactatt_sat_type = saa.sat_type
AND saa.display_order IN ('1 ', ' 2')
AND ia.deleted = 'A ';
ACTION_SEQ ACTION_DA VALUE OF COD
----
45765668 9 OCTOBER 09 B2 67089 37 B
45765670 9 OCTOBER 09 BA D 67089
45765670 9 OCTOBER 09 BA 67089 P
45765672 9 OCTOBER 09 B6 67089 C
45765673 9 OCTOBER 09 B4 67089 E
45765673 9 OCTOBER 09 67089 7 B4
45765674 9 OCTOBER 09 23567 23567 G1
45765674 9 OCTOBER 09 G1 23567 W
I found it quite complex to try to write - I hope that I was clear.
Thank you very much!Hello
You can use an alias for column (such as staff_seq) in the ORDER BY. Unfortunately, it's the only place where you can use it in the same query, where it was defined.
You can use it anywhere in the super-requetes, however, so you can still work around this problem in assigning the aliases in a subquery and GROUP BY (or other) in a Super query, like this:WITH ungrouped_data AS ( SELECT ia.action_seq, ia.action_date, ia.action_code, NVL (LAST_VALUE (CASE WHEN ia.action_code = 'G1' AND sactatt_sat_type = 'SS' THEN VALUE WHEN ia.action_code IN ('A0', 'A1') THEN '67089' END IGNORE NULLS ) OVER (PARTITION BY ia.ici_charge_inquiry_seq ORDER BY ia.action_date, ia.action_seq), '67089' )staff_seq, (CASE WHEN display_order = '1' THEN VALUE END) first_attribute, (CASE WHEN display_order = '2' THEN VALUE END) second_attribute FROM i_action ia LEFT JOIN i_attribute_value iav ON iav.ia_action_seq = ia.action_seq LEFT JOIN shared_action_attribute ON sactatt_sact_code = sact_code AND sactatt_sat_type = sat_type WHERE ia.deleted = 'A' ) SELECT action_seq , action_date , action_code , staff_seq , MIN (first_attribute) AS first_attribute , MIN (second_attribute) AS second_attribute FROM ungrouped_data GROUP BY action_seq , action_date , action_code , staff_seq ;There are other alternatives for special cases, but none of them work in this particular case.
-
How to MERGE when the target table contains invisible columns?
Oracle running on Oracle Linux 6.4 12.1.0.2.0 database:
During his studies of FUSION with invisible columns, I discovered that invisible columns in the target table cannot be read. Workaround seems to be
MERGE INTO (SELECT <column list> FROM <target table>) AS <alias>
However, the documentation does not seem to allow this. Here are the details.
Test data
> CREATE TABLE t_target( k1 NUMBER PRIMARY KEY, c1 NUMBER, i1 NUMBER invisible ) table T_TARGET created. > INSERT INTO t_target (k1,c1,i1) SELECT 2, 2, 2 FROM dual UNION ALL SELECT 3, 3, 3 FROM dual UNION ALL SELECT 4, 4, 4 FROM dual 3 rows inserted. > CREATE TABLE t_source( k1 NUMBER PRIMARY KEY, c1 NUMBER, i1 NUMBER invisible ) table T_SOURCE created. > INSERT INTO t_source (k1,c1,i1) SELECT 1, 1, 1 FROM dual UNION ALL SELECT 2, 2, 9999 FROM dual UNION ALL SELECT 3, 3, 3 FROM dual 3 rows inserted.
First try
Please note that I have a WHERE clause in the WHEN MATCHED clause. Its purpose is to avoid the update of a row when data are already correct. The WHERE clause is trying to read the invisible column of the target table.
> MERGE INTO t_target o USING ( SELECT k1, c1, i1 FROM t_source ) n ON (o.k1 = n.k1) WHEN MATCHED THEN UPDATE SET c1=n.c1, i1=n.i1 WHERE 1 IN ( decode(o.c1,n.c1,0,1), decode(o.i1,n.i1,0,1) ) WHEN NOT MATCHED THEN INSERT (k1, c1, i1) VALUES(n.k1, n.c1, n.i1) ... Error at Command Line : 10 Column : 12 Error report - SQL Error: ORA-00904: "O"."I1": invalid identifier
As you can see, I put a subquery after the USING clause so that 'n.i1' would be 'visible', but this is not enough since the 'I1' column in the target table is always invisible.
Second test
> MERGE INTO ( SELECT k1, c1, i1 FROM t_target ) o USING ( SELECT k1, c1, i1 FROM t_source ) n ON (o.k1 = n.k1) WHEN MATCHED THEN UPDATE SET c1=n.c1, i1=n.i1 WHERE 1 IN ( decode(o.c1,n.c1,0,1), decode(o.i1,n.i1,0,1) ) WHEN NOT MATCHED THEN INSERT (k1, c1, i1) VALUES(n.k1, n.c1, n.i1) 2 rows merged.
Here I used a subquery in the INTO clause thus, and it worked.
Unfortunately, this does not seem to be admitted in the documentation: IN fact refers to a table or a view as schema objects.

My question is:
How can I refer to invisible columns in the target table without creating a new object? My workaround using a subquery solution seems to work very well, but can I recommend if it is not documented?
Can I replace a "inline view" for a view and still be supported?
During his studies of FUSION with invisible columns, I discovered that invisible columns in the target table cannot be read. Workaround seems to be
However, the documentation does not seem to allow this. Here are the details.
Here I used a subquery in the INTO clause thus, and it worked.
Unfortunately, this does not seem to be admitted in the documentation: IN fact refers to a table or a view as schema objects.
My question is:
How can I refer to invisible columns in the target table without creating a new object? My workaround using a subquery solution seems to work very well, but can I recommend if it is not documented?
Can I replace a "inline view" for a view and still be supported?
But the documentation DO ALLOWS not only! You use a view - a view online and those that can be changed in a MERGE statement.
All versions of the doc for FUSION since 9i specifically say this:
INTO clause
Use the
INTOtarget clause to specify the table or view you are updating or inserting into. To merge the data in a view, the view must be updated. Please refer to the "Notes on the editable views" for more information.Here are the links for the doc. 9i, 10g, 11g and c 12, ALL OF THEM (the last three), except 9i have this EXACT clause above.
SQL statements: INDICATED to ROLLBACK FALLS, 15 of 19
http://docs.Oracle.com/CD/B19306_01/server.102/b14200/statements_9016.htm
http://docs.Oracle.com/CD/B28359_01/server.111/b28286/statements_9016.htm
https://docs.Oracle.com/database/121/SQLRF/statements_9016.htm
9i doc does not have this specific quote in the INTO clause section, but it doesn't have that quote a little later:
Limitation of the update of a view
- You cannot specify
DEFAULTwhen refreshing a view. - You cannot update a column referenced in the
ONconditionclause.
merge_insert_clause
The
merge_insert_clausespecifies the values to insert into the column of the target table, if the condition of theONclause is false. If the insert clause is executed, then all insert triggers defined on the target table are activated.Restrictions on the merger in a view
You cannot specify
DEFAULTwhen refreshing a view.If your "workaround" isn't really a workaround solution. You SHOULD use an inline view if you need to reference a column "invisible" in the target table, since otherwise, these columns are INVISIBLE!
My workaround using a subquery solution seems to work very well, but can I recommend if it is not documented?
You can recomment it because IT IS documented.
- You cannot specify
-
Merger of the various tables in the form of a long table
Hi there, I have a problem with the merger of the table.
Due to the nature of my VI, I'll have to merged paintings together to form a single table.
I designed a VI using the loop and switching of cases but the current table keep to overwrite the previous table. I had to activate auto-indexation on the loop, but it couldn't work.
I am attaching two VI for illustration more far.
Try to merge the tables togther.vi is the program that I'm trying.
Desired output program.vi is the real thing, I want to get to the exit.
Thanks for all the help.
Keith Tan
Hi Keith,
It's the magic of the shift registers

You should always note what LV version you are using!
-
whenever I run this code I get this error
SQL Error: ORA-30926: failed to get a stable set of rows in the source tables
30926 00000 - "impossible to get a stable set of rows in the source tables.
* Cause: A stable set of rows could not be achieved due to the large dml
activity or one not deterministic where clause.
* Action: Remove any non deterministic of the clauses and reissue of the dml.
Don't know wht goes wrong!
SQL:
MERGE IN VENDORS_ACTIVE_DATE s
USING (nvl (d.VENDOR, s.VENDOR) selection of the SELLER,
NVL (d.COMPANY_CODE, s.COMPANY_CODE) COMPANY_CODE.
(case when ((d.VENDOR = s.VENDOR) and (d.COMPANY_CODE = s.COMPANY_CODE)))
)
then "MATCH".
When d.COMPANY_CODE is null
then 'DELETE '.
When s.COMPANY_CODE is null
then "INSERT."
else 'UPDATE '.
chck end)
from (select * from VENDORS_ACTIVE_DATE where COMPANY_CODE = 2) s
full outer join (select * provider where COMPANY_CODE = 2) d
on (d.COMPANY_CODE = s.COMPANY_CODE AND s.COMPANY_CODE = 2)
) d
WE (d.COMPANY_CODE = s.COMPANY_CODE AND d.chck in ('UPDATE', 'GAME', 'DELETE'))
WHEN MATCHED THEN
UPDATE SET s.VENDOR = d.VENDOR
WHERE d.chck in ('UPDATE', 'DELETE')
DELETE WHERE d.chck = 'DELETE '.
WHEN NOT MATCHED THEN
INSERT (SELLER, COMPANY_CODE)
VALUES (d.VENDOR, d.COMPANY_CODE)
Work request: (deleted the duplicate data in tables (source and target))
MERGE IN VENDORS_ACTIVE_DATE s
USING (nvl (d.VENDOR, s.VENDOR) selection of the SELLER,
NVL (d.ACTIVEDATE, s.ACTIVEDATE) ACTIVEDATE.
NVL (d.COMPANY_CODE, s.COMPANY_CODE) COMPANY_CODE.
(case when ((d.VENDOR = s.VENDOR))
- AND D.ACTIVEDATE = S.ACTIVEDATE
and NVL (d.ACTIVEDATE, trunc (sysdate)) = NVL (s.ACTIVEDATE, trunc (sysdate))
and (d.COMPANY_CODE = s.COMPANY_CODE)
)
then "MATCH".
When d.COMPANY_CODE is null
then 'DELETE '.
When s.COMPANY_CODE is null
then "INSERT."
else 'UPDATE '.
chck end)
from (select * from suppliers where COMPANY_CODE = 2) d
full outer join (select * from vendors_active_date where COMPANY_CODE = 2) s
on (d.COMPANY_CODE = s.COMPANY_CODE and s.vendor = d.vendor)
) d
WE (d.COMPANY_CODE = s.COMPANY_CODE AND d.VENDOR = s.VENDOR AND d.chck in ('UPDATE', 'GAME', 'DELETE'))
WHEN MATCHED THEN
S.ACTIVEDATE = UPDATE SET d.ACTIVEDATE
WHERE d.chck in ('UPDATE', 'DELETE')
DELETE WHERE d.chck = 'DELETE '.
WHEN NOT MATCHED THEN
INSERT (VENDOR, ACTIVEDATE, COMPANY_CODE)
VALUES (d.VENDOR, d.ACTIVEDATE, d.COMPANY_CODE)
-
Hi all
Can I combine the records in the nested table
I have a table with 2 colum: col_1 and col_2
col_1: corresponds to the id (varchar2)
col_2: is a column nested with the type of table (sub_col_1 (number), sub_col_2 (number))
for example: I have 2 accounts table ('a', (1,2)) and ('b', (3,4)))
what I want is merged into this table with values ('a', '4.5')) + ('c', (6,7)) IN a single statement
What I should have after this operation ('a', (1,2,4,5)) + ('b', (3,4)) + ('c', (6,7)).
Can I do this?
Oracle version: 11.2.0.3CREATE OR REPLACE TYPE TEST_TYPE AS OBJECT(SUB_COL_1 NUMBER, SUB_COL_2 NUMBER) ; CREATE OR REPLACE TYPE TEST_TYPE_TABLE IS TABLE OF TEST_TYPE; CREATE TABLE TEST_MERGE_NESTED_TABLE (COL_1 VARCHAR2(1 CHAR), COL_2 TEST_TYPE_TABLE) NESTED TABLE COL_2 STORE AS COL_2_NESTED; INSERT INTO TEST_MERGE_NESTED_TABLE VALUES('a',TEST_TYPE_TABLE(TEST_TYPE(1,2) )); INSERT INTO TEST_MERGE_NESTED_TABLE VALUES('b',TEST_TYPE_TABLE(TEST_TYPE(3,4) ));
Thank you all.
Published by: 966205 on 20:18 21/02/2013
Published by: 966205 on 20:42 21/02/2013966205 wrote:
That means he does the same thing as what I want (adding? do not recreate this column in the physical layer).Actually, no.
All content of the nested table is first removed (for the given FK), then the result of the MULTISET UNION is reinserted.The evidence on:
SQL> alter session set events '10046 trace name context forever, level 12'; Session altered. SQL> merge into test_merge_nested_table t 2 using ( 3 select 'a' col_1, TEST_TYPE_TABLE(TEST_TYPE(4,5)) col_2 from dual union all 4 select 'c' , TEST_TYPE_TABLE(TEST_TYPE(6,7)) from dual 5 ) v 6 on ( t.col_1 = v.col_1 ) 7 when matched then update 8 set t.col_2 = t.col_2 multiset union v.col_2 9 when not matched then insert (col_1, col_2) 10 values (v.col_1, v.col_2) ; 2 rows merged. SQL> alter session set events '10046 trace name context off'; Session altered. SQL> select * from test_merge_nested_table; C COL_2(SUB_COL_1, SUB_COL_2) - -------------------------------------------------------------------------------- c TEST_TYPE_TABLE(TEST_TYPE(6, 7)) a TEST_TYPE_TABLE(TEST_TYPE(1, 2), TEST_TYPE(4, 5)) b TEST_TYPE_TABLE(TEST_TYPE(3, 4))TKPROF output:
DELETE, the nested table statement objectives associated with 'a' and deletes the line after line that it contains (1,2).
The later INSERTION is performed twice (run count = 2) and target the two nested table 'a' by inserting 2 ranks: former one (1,2) + the new one (4.5) and the nested table 'c' by inserting 1 row (6,7).SQL ID: 6bjc2z2t53csn Plan Hash: 132214516 DELETE /*+ REF_CASCADE_CURSOR */ FROM "DEV"."COL_2_NESTED" WHERE "NESTED_TABLE_ID" = :1 call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 1 3 1 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.00 0.00 0 1 3 1 Misses in library cache during parse: 0 Optimizer mode: CHOOSE Parsing user id: SYS (recursive depth: 1) Number of plan statistics captured: 1 Rows (1st) Rows (avg) Rows (max) Row Source Operation ---------- ---------- ---------- --------------------------------------------------- 0 0 0 DELETE COL_2_NESTED (cr=1 pr=0 pw=0 time=44 us) 1 1 1 INDEX RANGE SCAN SYS_FK0000023444N00002$ (cr=1 pr=0 pw=0 time=10 us)(object id 23446) **************************************************************************************************************************************************************** SQL ID: 0fzd5yk23jyas Plan Hash: 0 INSERT /*+ NO_PARTIAL_COMMIT REF_CASCADE_CURSOR */ INTO "DEV"."COL_2_NESTED" ("NESTED_TABLE_ID","SYS_NC_ROWINFO$") VALUES (:1, :2) call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 2 0.00 0.00 0 0 0 0 Execute 2 0.00 0.00 0 2 10 3 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 4 0.00 0.00 0 2 10 3 Misses in library cache during parse: 0 Optimizer mode: ALL_ROWS Parsing user id: 50 (recursive depth: 1) Number of plan statistics captured: 1 Rows (1st) Rows (avg) Rows (max) Row Source Operation ---------- ---------- ---------- --------------------------------------------------- 0 0 0 LOAD TABLE CONVENTIONAL (cr=1 pr=0 pw=0 time=113 us) ******************************************************************************** -
How to remove data in three tables at once with the same key.
I am new to Oracle ADF, I have a requirement like these, I have three tables such as employee salaries, teams of all these have a common EmpNo as common attribute, I have the search form these returns all employees related to this search query, when I click on the button Delete the particular employee data should delete all tables of the three based on the EmpNo.
Any help is appreciated...(1) the easiest way is to mark the constraints of foreign key to WAGES employees and TEAMS of EMPLOYEES like ON DELETE CASCADE. The DB server then removes the necessary lines each time you remove a line from the employee.
(2) another way is to implement a Before delete e-DB trigger on the EMPLOYEES table, where you can remove the related rows in other tables (have in mind that if you have foreign keys you can get an Exception Table mutation, so this approach is perhaps not very good).
(3) an ADF is to implement a custom EntityImpl class for the Employee entity and substitute the remove() method where you can find the related entities of TeamMember and salary (via EntityAssoc accessors) and call remove() methods too.
(4) another way of the ADF is to implement a custom EntityImpl class for the Employee entity and override the doDML() method where you can remove the lines needed in SALARIES and TEAMS through JDBC calls tables whenever a DELETE operation is performed on the Employee of the underlying entity.
Dimitar
-
TO THE FUNCTION SUM WHILE JOINING THREE TABLES
Hello
I meet three tables as below in my oracle 9i DB.
and I have examples of data like thiscreate table ac (account_no varchar2(10), bal number) create table c (cid number, aid number, cname varchar2(50) ) create table mu (ms number, BILLING_ACC_NO varchar2(10), aid number, cid number)
I need the output as below help = 5050 table c.insert into ac (account_no,bal ) values ('1234',3456); insert into ac (account_no,bal ) values ('98767',567); insert into ac (account_no,bal ) values ('6754',6789); insert into ac (account_no,bal ) values ('54678',9453); insert into c (cid,aid,cname ) values (231,5050,'asdf'); insert into c (cid,aid,cname ) values (131,5150,'fghj'); insert into c (cid,aid,cname ) values (221,5050,'rtyu'); insert into c (cid,aid,cname ) values (931,5151,'asdf'); insert into MU (cid,aid,BILLING_ACC_NO ,MS) values (231,5050,'1234',987654); insert into MU (cid,aid,BILLING_ACC_NO ,MS) values (231,5050,'98767',8987654); insert into MU (cid,aid,BILLING_ACC_NO ,MS) values (221,5050,'6754',3434343); insert into MU (cid,aid,BILLING_ACC_NO ,MS) values (221,5050,'54678',667799); insert into MU (cid,aid,BILLING_ACC_NO ,MS) values (131,5150,'546738',66779933);
>
c.CID, c.cname, sum (ac.bal)
231, asdf, (3456 + 567 = 4023)
221, rtyu, (6789 + 9453 = 16242)
>
selected the cid, cname in table c and found the list BILLING_ACC_NO table mu for help 5050 and every cid after found the sum (bal) for all these account_no (BILLING_ACC_NO MU).
CID 231 cname asdf is to have BILLING_ACC_NO listed as 1234, 98767 and for these account_no in the ac table ball are 3 456 567 so its sum is needed.
hope I explained it clearly.
pls help me to get there.SELECT c.cid,
c.CNAME,
RTrim (regexp_replace (xmlagg (xmlelement (e, ac.bal |)))) ','))
. Extract ('//Text ()'),
',',
'+'),
'+') || '=' || Sum (AC.bal)
C, mu, ac
WHERE mu.cid = c.cid
AND mu.aid = c.aid
AND account_no = mu.billing_acc_no
GROUP OF c.cid, c.cname; -
Merge the XML document in a table
Hello
I want to merge some of the values of an xml document in a table "Project_Table".
CREATE TABLE Project_Table
(
TASK_ID NUMBER (15),
TASK_NAME VARCHAR2 (100 BYTE),
START_DATE DATE,
)
I am using the following procedure, that I adapted from another post. It inserts null values, I think because I'm not showing the nodes correctly.
DECLARE
BFILE v_bfile: = BFILENAME ("'DTEMP","test.xml");
v_clob CLOB.
BEGIN
-Create directory DTEMP as "C:\TEMP";
-grant read the < schema > DTEMP directory;
DBMS_LOB.CREATETEMPORARY (v_clob, TRUE);
DBMS_LOB. OPEN (v_bfile, DBMS_LOB.lob_readonly);
DBMS_LOB. LoadFromFile (v_clob, v_bfile, DBMS_LOB.lobmaxsize);
Dbms_output.put_line (v_clob);
MERGE IN project_table t
USING (SELECT TO_NUMBER (EXTRACTVALUE (VALUE (x), ' / task ')) task_id,)
To_date (EXTRACTVALUE (value (x), "/ start"), 'DD-MM-YYYY') start_date,
EXTRACTVALUE (value (x), "/ name") TaskName
(SELECT XMLTYPE (v_clob) XML
THE DOUBLE).
TABLE (XMLSEQUENCE (EXTRACT (xml, ' / project'))) x) r
WE (t.task_id = r.task_id)
WHEN MATCHED THEN
UPDATE
SET t.start_date = r.start_date, t.task_name = r.task_name
WHEN NOT MATCHED THEN
INSERT (task_id, start_date, taskname)
VALUES (r.task_id, r.start_date, r.task_name);
COMMIT;
END;
This is the document of test.xml.
<? XML version = "1.0" encoding = "UTF-8"? >
-name of the project 'ProjectName' company 'Company' webLink = = = "" view-date = '2009-12-14"see-index '0' = gantt-Divider-location = '300' resource-divider-card ="300"version ="2.0">"
< description / >
< zoom-view state = "default: 8" / >
-<!
->
-< calendars >
-day-types >
< day-type id = '0' / >
< day-type id = "1" / >
-< Calendar id = "1" name = "default" >
< Sun weeks default = '0' LUN '0' = TEU = '0' kills = '0' game = '0' Fri '0' = Saturday = '0' / >
< overloaded-day-types / >
< days / >
< / calendar >
< / day-types >
< / calendars >
-task color = "#8cb6ce" >
-< taskproperties >
< taskproperty id = "tpd0" name = 'type' type = 'default' valuetype = "icon" / >
< taskproperty id = "TDP1" name = 'priority' type = 'default' valuetype = "icon" / >
< taskproperty id = "tpd2" name = 'info' type = 'default' valuetype = "icon" / >
< taskproperty id = "tpd3" name = "name" type = 'default' valuetype = "text" / >
< taskproperty id = "tpd4" name = "begindate" type = 'default' valuetype = "date" / >
< taskproperty id = "tpd5" name = "enddate" type = 'default' valuetype = "date" / >
< taskproperty id = "tpd6" name = "Duration" type = 'default' valuetype = "int" / >
< taskproperty id = "tpd7" name = "completion" type = 'default' valuetype = "int" / >
< taskproperty id = "tpd8" name = "Coordinator" type = 'default' valuetype = "text" / >
< taskproperty id = "tpd9" name = "predecessorsr" type = "default" valuetype = "text" / >
< / taskproperties >
< job id = '0' name = 'TaskA"color =" #0099cc "form = meeting"0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0"="false"start ="2010-01-28"duration ="1"complete ="0"priority ="1"expand ="true"/ >
< task id = "1" name = "TaskB" color = "#ff0000" form = meeting "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" = "false" start = "2010-01-28" duration = "1" complete = "100" priority = "1" expand = "true" / >
< job id = "2" name = 'Day' color = "#ff9933" form = meeting "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" = "false" start = "2010-02-01" duration = "19" complete = "0" priority = "1" expand = "true" / >
< job id = "3" name = "TaskD" color = "#ff0000" form = "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" meeting = "false" start = "2010-02-01" duration = "32" full = "100" priority = "1" expand = "true" / >
< job id = "4" name = "TaskE" color = "#66ff99" form = meeting "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" = "false" start = "2010-02-01" duration = "67" complete = "0" priority = "1" expand = "true" / >
< job id = "5" name = "TaskF" color = "#66ff99" form = meeting "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" = "false" start = "2010-02-01" duration = "46" complete = "10" priority = "1" expand = "true" / >
< job id = "6" name = "TaskG" color = "#00cccc" form = meeting "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" = "false" start = "2010-03-15" duration = "30" complete = "0" priority = "1" expand = "true" / >
< job id = "7" name = "TaskH" color = "#00cccc" form = meeting "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" = "false" start = "2010-03-15" duration = "103" full '1' = '1' priority = expand = "true" / >
< job id = "8" name = "TaskI" color = "#0000ff" form = meeting "0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0" = "false" start = '2010-04-26' length = "11" complete = "0" priority = "1" expand = "true" / >
< job id = '9' name = 'TaskJ"color =" #0000ff "form = meeting"0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0"="false"start = '2010-04-26' length ="11"complete ="0"priority ="1"expand ="true"/ >
< job id = "10" name = "TaskK" color = "#000000" meeting = 'false' start time = "2010-07-12" = "65" full = "0" priority = "1" expand = "true" / >
< / tasks >
< resources / >
< allowances / >
< holiday / >
-< taskdisplaycolumns >
< displaycolumn property id = "tpd3" order = "0" width = "75" / >
< displaycolumn property id = "tpd4" order = "1" width = "75" / >
< displaycolumn property id = "tpd5" order = "2" width = "75" / >
< displaycolumn property id = "tpd7" order = "3" width = "75" / >
< / taskdisplaycolumns >
< Previous / >
< roles roles-name = "Default" / >
< / project >
Any ideas how to change the procedure, in order to merge the data in the xml document in the table?
Thank youHello
Here's what you need in your USING clause:
SELECT to_number(extractvalue(column_value, 'task/@id')) as task_id, to_date(extractvalue(column_value, 'task/@start'), 'YYYY-MM-DD') as start_date, extractvalue(column_value, 'task/@name') as task_name FROM TABLE( XMLSEQUENCE( EXTRACT(xmltype(v_clob), '//task') ) )Since you want nodes "task" request, just extract them directly. In addition, 'id', 'start', 'name' is attributes, you must access them with an '@'.
You can also take a look at function XMLTABLE (which tends to replace construction TABLE (XMLSEQUENCE (...))):
SELECT * FROM XMLTABLE( '//task' passing xmltype(v_clob) columns task_id number(15) path '/task/@id', start_date date path '/task/@start', task_name varchar2(100) path '/task/@name' )Edit: the XMLType constructor overload taking a BFILE type as an argument, so you can simplify the code a bit more:
DECLARE v_xml XMLTYPE := XMLTYPE( BFILENAME('DTEMP', 'test.xml'), nls_charset_id('AL32UTF8') ); BEGIN MERGE INTO project_table t USING ( SELECT * FROM XMLTABLE( '//task' passing v_xml columns task_id number(15) path '/task/@id', start_date date path '/task/@start', task_name varchar2(100) path '/task/@name' ) ) r ON (t.task_id = r.task_id) WHEN MATCHED THEN ... WHEN NOT MATCHED THEN ... ; ... END;HTH
Published by: odie_63 on March 18, 2010 12:13
Published by: odie_63 on March 18, 2010 12:15
-
Three blocks in the same way, belong to the same table
Hi people,
I am trying to find a way to make this work. I have currently 3 blocks on the form even where the first block is on the main canvas in blocks 2 and 3 will be on separate bunk canvases. According to a column value (Radio button group), I'll show stacked canvas 1 (block 2) or stacked canvas 2 (block 3). Unfortunately, all these elements must remain in the same table. I also keep them in separate blocks because some of the columns must be in two blocks.
Landing up, which happens is that before INSERT trigger pulls the two blocks (since BLOCK_STATUS of the second block's NEW as well) and I'm landing by creating two records which is obviously a no-no situation.
I tried the trigger for INSERTION WE with null, but then what's going on, it's that nothing is saved.
For any idea or suggestion would be greatly appreciated.
I use Forms 9i.
Have a great weekend.
Thank you!
Perhaps this - make sure that a single database block, which has the "mirror elements' (use to synchronize it with the Item property).
Kind regards
Zlatko
-
Cannot nest layout table in the layout table
I work through a training course on the design of websites using CS3, and one of the examples dealing with the mode layout is a layout table nested within a cell of another table of provision. I can get the result by editing the code, but I find no way in design view mode of disposal to accomplish the same thing after hours of trying. Help says you're supposed to be able to select a layout of the main layout and then table cell insert another table of provision in this cell, limit the size of the mesh, but the program won't let me anything inserted into an existing cell. I have attached the reference code. Can anyone tell if I should be able to create the nested table in Design view without just changing the code to force?Oops - sorry guys. I see that you already have a lot of suggestions.
And the link I gave you was the wrong one. I see that Tim has given you the right
one...--
Murray - ICQ 71997575
Adobe Community Expert
(If you * MUST * write me, don't don't LAUGH when you do!)
==================
http://www.projectseven.com/go - DW FAQs, tutorials & resources
http://www.dwfaq.com - DW FAQs, tutorials & resources
=================="Murray * AS *"
News:g5269k$pvk$1@forums. Macromedia.com...
> If you take a training course which is the training allows you to use the page layout
> mode, then throw this course or skip this chapter. You
> should never use mode of provision, for the reason that you are currently
> knows and many others.
>
> Here's a good reason to not use - read this and then look at your
> code below.
>
> http://apptools.com/examples/pagelayout101.php
>
> In my opinion, there are three serious problems with page-layout Mode
>
> 1. Perhaps more important still, it sits between you and * real * HTML tables,.
> and you fools in believing that concepts such as "layout cell" and
> 'Auto fit' really means something. They do not. As long as you use
> Layout mode, you're never going to learn one of the most important things for the new
> web
> developers - how to build solid and reliable tables.
>
> 2. In fact, wouldn't #1 * so * bad, except that the code that is
> writing
> set mode on the page is really bad code. For example, contains a layout table
> NUMBER of rows empty cells. This can contribute to the instability of the table.
> Also, if your initial positioning of the cells of the table is a little
> complex.
> Mode of disposal throw in the col - and rowspans aplenty as it merges and
> splits
> cells willy-nillly to get the pixelated layout you have specified.
> Once again,.
> It is a method of extremely poor to create stable tables, because it
> allows
> changes in form of a tiny cell (IE, dimensions) to ripple through the
> rest
> table, usually with the unexpected and sometimes disastrous
> consequences.
> This is one of the main reasons for the fragility of the final result - read
>-
>
> http://apptools.com/rants/spans.php
>
> 3. User interface for Mode layout is beyond confusing - many options you
> may
> to use are inaccessible, for example, insert another table, or layer on
> the page.
>
> I can understand the desire of the new user to use this tool to make their life
> easier.
> but the cost is just too heavy in my opinion.
>
> To make good tables, keep things simple. Put a table on the page and start
> to
> upload your content. If you want a layout on different tables, instead of
> merging or splitting cells, consider stacking tables or nesting simple
> tables instead, respectively.
>
> And most of all, do not try to create the whole page with a single table.
>
> Fortunately, Adobe includes the problems created for the untrained user
> which falls into this trap and chose to remove this function
> total of the next version of DW (CS4). The time has come for you
> to start working with tables correctly!
>
> To learn more about this approach, visit the DW FAQ link in my sig and run
> through the tutorials of the table.
>
> --
> Murray - ICQ 71997575
> Adobe Community Expert
> (If you * MUST * write me, don't don't LAUGH when you do!)
> ==================
> http://www.projectseven.com/go - DW FAQs, tutorials & resources
> http://www.dwfaq.com - DW FAQs, tutorials & resources
> ==================
>
>
> "tripap"
> news:[email protected]...
> I work through a training course on the design of websites using CS3 and one of
> the
> are examples treating mode layout a layout table nested within a cell of
> a different layout table. I can get the result by editing the code, but I can't
> find
> no way in design mode to mode of disposal to accomplish the same thing
> after
> hours of trying. Help says you're supposed to be able to select a page layout
> cell
> in the layout main table, then insert another table of provision in this
> cell,.
> limit dimensions of the mesh, but the program won't let me insert
> anything in an existing cell. I have attached the reference code.
> May
> anyone advise if I should be able to create the nested in table
> design
> mode without just modify the code to force it?
>>
>>
>>
>>
>>
> THE NAME OF THE WEB SITE HERE
>>
>>
>>
>>
>>
> border = "0" / >
>>
>>
>>
>>
>><>
> href = "" javascript:; "> HOME"
>>
>>
>>
>>
>>
>>
> border = "0" / >
>>
>>
>>
>>
> height = "1" border = "0" / >
>>
> height = "1" border = "0" / >
>>
>>
>>
>>Name of the page here
>>
>>
>>
>>
>>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam
> nonumy
> eirmod tempor invidunt ut developed and pain magna aliquyam erat, sed diam
> voluptua. At vero eos and accusam and justo duo dolores and ea rebum. STET
> clita
> kasd gubergren, no sea takimata sanctus is Lorem ipsum dolor sit amet.
> Lorem
> ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod
> tempor invidunt ut developed and pain magna aliquyam erat, sed diam
> voluptua. TO
> vero eos and accusam and justo duo dolores and ea rebum. STET clita kasd
> gubergren, no sea takimata sanctus is Lorem ipsum dolor sit amet.
>>
>>DUIs autem vel eum iriure dolor in hendrerit in fitness total esse
> molestie MPCs, vel illum pain had feugiat nulla facilisis at vero
> eros and
> accumsan and carystian odio dignissim which blandit praesent luptatum zzril
> delenit
> augue duis pain you feugait nulla facilisi. Lorem ipsum dolor sit amet,
> our adipiscing elit, sed diam nonummy nibh euismod tincidunt ut
> pain laoreet magna aliquam erat volutpat.
>>
>>
>>
>>
>> ?
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>
Maybe you are looking for
-
How can I change the display of Web sites
How can I change the size of the fonts/display of websites when using Firefox as my browser?
-
Delete the partition created in reformatting/reinstall for A50
Then when I got my Toshiba Satellite A50, he had no partition that I knew of, just a drive C with XP installed on it. But the disk that it came with to reformat the hard drive and reinstall XP is creating a partition! So it's not the original or set
-
iTunes saying update a completely updated iPhone update
Greetings. I have an iPhone 6 with iOS 4.2.1 updated overnight, it just came out via iTunes, as I have for always. Suddenly today, when I plug my phone in iTunes tells me that there is an update available... 4.2.1. If I try the software on my phone u
-
How to use the resistor Programmable 2720
Hello I'm using and programming with the PXI-2720. Could I put the value of the resistance to the CVI program? I put the niswitch.fp in my project. I do check all relays for making 30 ohms (example value) in my program? Could you help me if you have
-
I have a Thinkpad T42 has got a bit of water by accident 2 weeks ago. Now, the computer does not work. It is listed as error0200. Tried CD recovery used to correct, but it shows there is an internal error occurred and stop execution of the recovery.