Merger of reference groups
Hello
I have a code with several SubVIs, each with several objects. I would like references to all objects in a single source of group in order to access the properties of the objects through property nodes in another screw. Since I have a group of reference (which is populated by real references as a Subvi run) for each Subvi, I want to merge all of these clusters into one reference. However, when I do that, I lose all the labels on the objects. Is it possible to merge multiple clusters of reference as well as objects of Dungeon labels?
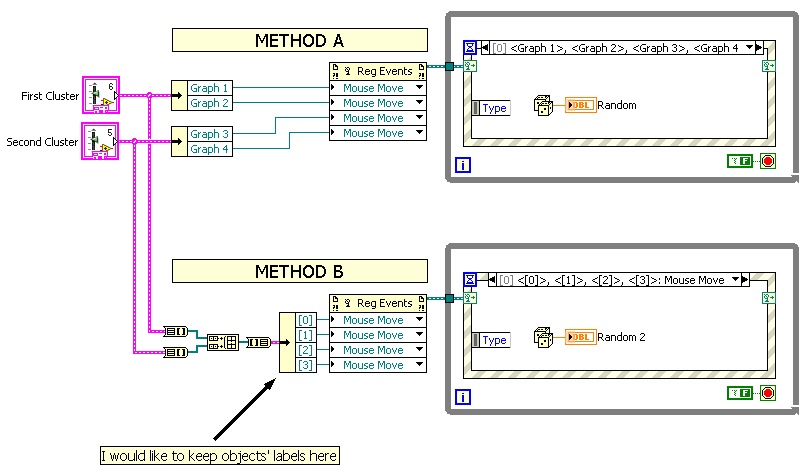
See attached picture for more information. I just used an example how of dynamic events can be used to trigger events in any of screws (dynamic events are essential for my code). Method A shows the ordinary way to get references from two different reference groups. As you can see, the labels are kept.
Method B, I try to make things easier and instead of having multiple "ungroup by name", I simply convert the clusters of berries, use a matrix to build function to concatenate all the references in a single table, and convert the table to a cluster. However, by doing this labels are not retained.
Thank you.
Dan07
Tags: NI Software
Similar Questions
-
Basic lines + empty reference groups?
I was playing with the images of ESXi tab and create a new baseline upgrade. Suddenly, I noticed that the screens cleared...

Somehow when I look at the images of ESXi tab you always see that it is connected to a reference database

Also when I used powerCLI to retrieve the patchbaselines they come back without flaw, to bad not groups: S
When you open the VUM log files, I also see that all the baselines are recovered. So somehow I thing the database seems ok.
-A tried to restart VUM. Create a new base line (this works, according to the newspaper, but is not displayed)
-Patch repository is filled and works.
-Baselines are always connected to the host and can be scanned

-When I try to do a new reference group, I get the below error. Selecting an image or selecting any two doesn't give the result below.

Personally, I think that there is something wrong with an image of ESXi and an upgrade of base.
Someone at - it an idea how to fix this or what to do?
-Updated
I noticed when I look in powerCLI, I get the error:
Get-database: 25/07/2014 11:19:37 Get-Baseline The given key was not present in the dictionary. On line: 1 char: 13
+ get-reference < < < <
+ CategoryInfo : NotSpecified: (:)) [Get-Baseline], VimException) + FullyQualifiedErrorId: Core_BaseCmdlet_UnknownError, VMware.VumAutomation.Commands.GetBaseline I don't have this on a different vCenter, here all the baselines are recovered very well.
Restore the database and returned to a situation of work again. No idea of what has past...
-
Hello
We have three tables, which each is configured in an autonomous group composed of a member. This made for historical reasons that no longer really relevant.
Assuming I got all revved up for the same firmware, what it will look like to merge the three into one? Is there a way to do everything while volumes or I am in a House of pain here?
Hello
There is no way to merge groups together and leave the data intact. If you have enough space, you can replicate from one table to another. Promote the volumes and reconnect. Then reset the table, add to this group and repeat the process for the third table.
It is easier to move data at the level of the host, sometimes larger volumes above and backup the rest if you have enough free space to replicate.
Kind regards
-
Reference a radiobutton in a group of components
I am new to export and work with catalyst for Flex project files. I imported a catalyst project into Flash Builder, and I have a problem.
This is my problem:
I have a component that contains a group that I must so I can add code to get the current value selected for the reference group. How can I make reference to this group? Catalyst the group name is "radioGroup". I don't see a reference like that in my Flash Builder project.
for example, it is similar to the structure of the component:
<>Group
...
< radiobutton id = "radiobutton2" / >
< radiobutton / >
...
< / Group >
Since I have an ID for the first item I thought I'd be able to get the parent group by referring to "radiobutton2". I don't know how to reference radiobutton2 with AS3 in Flash Builder/Flex.
Does anyone know how could reference "radiobutton2" so I can get the group like this: radiobutton2.group?
Thank you
-Eric
Main.MXML
xmlns:s = "library://ns.adobe.com/flex/spark".
xmlns:MX = "library://ns.adobe.com/flex/mx".
"minWidth ="955"="600"xmlns:local = minHeight" * ">
public function getValues (): void
{
Label1.text = myGroup.radioButton1.value.toString ();
Label2.text = myGroup.radioButton2.value.toString ();
If (myGroup.radioButtonGroup.selectedValue! = null)
{
Label3.text = myGroup.radioButtonGroup.selectedValue.toString ();
}
on the other
{
Label3.text = "nothing selected";
}
}
]]>
MyGroup.mxml
xmlns:s = "library://ns.adobe.com/flex/spark".
xmlns:MX = "library://ns.adobe.com/flex/mx" >
-
REP - 1213 reference frequency below his column group
Hello
In a report (6i) he demonstrated error like "REP - 1213 F_SUM_COLLECTIONS_RATIO field.
Column CS_COLLECTION_RATIO at a frequency lower than the reference group.
I know, it is a problem to repeat the image problem: -.
1. How can I check this error? And how can solve this problem?
Note: -.
Structure of the report is like that: -.
---------------------------------------------------------------------------------------------------------------
sales Man | Sales | Sales_ratio | Collection | Collection_ratio | Sales/Collection_ratio
---------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------
Total: 100% * 100% * %
---------------------------------------------------------------------------------------------------------------
In this sales_ratio, the collection_ratio, the sales? Coll._ratio I added columns formulas Corr. and create summaries
Corr. of columns each.
This summary columns having some problem.Hi Ngoyi,
Where did you create your analytical column fields? Seeing your example of report, it seems there is no grouping. In this case create an analytical column outside of the design of your query (extensible data block) and there, you can call the fields and set the property to reset to the report. Make sure, when you add these fields in the report, place the fields outside of your extensible framework.
Concerning
MP
-
Merge layers with blending modes
I have a layer in a group with a blending mode and opacity. During the merger of the group that a particular layer behaves as if the blending mode of the layer normal. I tried to place an empty layer underneath and merge down, like merging the layer with a blending mode and opacity in the empty layer even if this was not successful?
Here are the steps I did:
first screenshot shows my layer of mixture with the fracture mode at 60% opacity: I did a merge visible stamp ctrl-alt-shift-E to make this layer.

I selected the merged layer, but I ctrl-click on the layer break to make my choice.

Although I have him merge layer selected, I pressed ctrl-J to make a new layer for the selection and the merged layer:

I can then turn off the visibility of the merged layer and the original layer of the fracture. This is not exactly the same, but it will be as close as you can get.

-
Merge two display environments
Here's my question/situation. I have built my own VMware View environment in my business and run it for about 2 years. Very recently, we merged with another group which also has their own implementation of VMware View. I was instructed to merge the two environment under view connection server. Is there a way to export all of the set up a connection to the server and merge the information into another server connection?
My thought is to take the display configuration groups merged, export it all out, import into my existing connection server, add the vCenter server in my login server and takes control of all their connections Office directing their DNS name to my server connection via an alias.
Is there a preferred way to solve this problem without manually re-create all pools on my login server.
Thank you!!
Yes, I can see where this can be problematic. My only thought is it to have a legacy manual pool and then to channel new users into a pool of specialized automated.
-
I have a lot of data that I need to transform and "group of groups". Let me explain with an example:
Real-world data about 5 million lines.SQL> create table orig_data as 2 select distinct job, deptno 3 from scott.emp e 4 / Table created. SQL> select job 2 , deptno 3 from orig_data 4 order by 5 job 6 , deptno 7 / JOB DEPTNO --------- ---------- ANALYST 20 CLERK 10 CLERK 20 CLERK 30 MANAGER 10 MANAGER 20 MANAGER 30 PRESIDENT 10 SALESMAN 30 9 rows selected.
I have a working group (I use xmlagg here because I'm on version 11.1 and therefore no listagg ;-))):
I note here that the two jobs CLERK and MANAGER has the same set of deptnos.SQL> select od.job 2 , rtrim(xmlagg(xmlelement(d,od.deptno,',').extract('//text()') order by od.deptno),',') deptnos 3 from orig_data od 4 group by od.job 5 / JOB DEPTNOS --------- ------------------------------ ANALYST 20 CLERK 10,20,30 MANAGER 10,20,30 PRESIDENT 10 SALESMAN 30
So if I group by deptnos I get this result:
My requirement is to identify all of these unique groups of deptnos in my table of orig_data, give each group as a surrogate key in a parent table and then populate two tables of children with the deptnos of each group and the jobs that have this group of deptnos:SQL> select s2.deptnos 2 , rtrim(xmlagg(xmlelement(j,s2.job,',').extract('//text()') order by s2.job),',') jobs 3 from ( 4 select od.job 5 , rtrim(xmlagg(xmlelement(d,od.deptno,',').extract('//text()') order by od.deptno),',') deptnos 6 from orig_data od 7 group by od.job 8 ) s2 9 group by s2.deptnos 10 / DEPTNOS JOBS ------------------------------ ------------------------------ 10 PRESIDENT 10,20,30 CLERK,MANAGER 20 ANALYST 30 SALESMAN
For the substitution groupkey I can use a rownumber on my group by query deptnos:SQL> create table groups ( 2 groupkey number primary key 3 ) 4 / Table created. SQL> create table groups_depts ( 2 groupkey number references groups (groupkey) 3 , deptno number(2) 4 ) 5 / Table created. SQL> create table groups_jobs ( 2 groupkey number references groups (groupkey) 3 , job varchar2(9) 4 ) 5 / Table created.
This application, that I can use for a (slow) insert in my three tables in this simple way:SQL> select row_number() over (order by s2.deptnos) groupkey 2 , s2.deptnos 3 , rtrim(xmlagg(xmlelement(j,s2.job,',').extract('//text()') order by s2.job),',') jobs 4 from ( 5 select od.job 6 , rtrim(xmlagg(xmlelement(d,od.deptno,',').extract('//text()') order by od.deptno),',') deptnos 7 from orig_data od 8 group by od.job 9 ) s2 10 group by s2.deptnos 11 / GROUPKEY DEPTNOS JOBS ---------- ------------------------------ ------------------------------ 1 10 PRESIDENT 2 10,20,30 CLERK,MANAGER 3 20 ANALYST 4 30 SALESMAN
The tables now with these data:SQL> begin 2 for g in ( 3 select row_number() over (order by s2.deptnos) groupkey 4 , s2.deptnos 5 , rtrim(xmlagg(xmlelement(j,s2.job,',').extract('//text()') order by s2.job),',') jobs 6 from ( 7 select od.job 8 , rtrim(xmlagg(xmlelement(d,od.deptno,',').extract('//text()') order by od.deptno),',') deptnos 9 from orig_data od 10 group by od.job 11 ) s2 12 group by s2.deptnos 13 ) loop 14 insert into groups values (g.groupkey); 15 16 insert into groups_depts 17 select g.groupkey 18 , to_number(regexp_substr(str, '[^,]+', 1, level)) deptno 19 from ( 20 select rownum id 21 , g.deptnos str 22 from dual 23 ) 24 connect by instr(str, ',', 1, level-1) > 0 25 and id = prior id 26 and prior dbms_random.value is not null; 27 28 insert into groups_jobs 29 select g.groupkey 30 , regexp_substr(str, '[^,]+', 1, level) job 31 from ( 32 select rownum id 33 , g.jobs str 34 from dual 35 ) 36 connect by instr(str, ',', 1, level-1) > 0 37 and id = prior id 38 and prior dbms_random.value is not null; 39 40 end loop; 41 end; 42 / PL/SQL procedure successfully completed.
I can now these data the same result as before (just to test, I created the desired data):SQL> select * 2 from groups 3 order by groupkey 4 / GROUPKEY ---------- 1 2 3 4 SQL> select * 2 from groups_depts 3 order by groupkey, deptno 4 / GROUPKEY DEPTNO ---------- ---------- 1 10 2 10 2 20 2 30 3 20 4 30 6 rows selected. SQL> select * 2 from groups_jobs 3 order by groupkey, job 4 / GROUPKEY JOB ---------- --------- 1 PRESIDENT 2 CLERK 2 MANAGER 3 ANALYST 4 SALESMAN
So far so good. It works all the pretty much as desired - with the exception of a couple things:SQL> select g.groupkey 2 , d.deptnos 3 , j.jobs 4 from groups g 5 join ( 6 select groupkey 7 , rtrim(xmlagg(xmlelement(d,deptno,',').extract('//text()') order by deptno),',') deptnos 8 from groups_depts 9 group by groupkey 10 ) d 11 on d.groupkey = g.groupkey 12 join ( 13 select groupkey 14 , rtrim(xmlagg(xmlelement(j,job,',').extract('//text()') order by job),',') jobs 15 from groups_jobs 16 group by groupkey 17 ) j 18 on j.groupkey = g.groupkey 19 / GROUPKEY DEPTNOS JOBS ---------- ------------------------------ ------------------------------ 1 10 PRESIDENT 2 10,20,30 CLERK,MANAGER 3 20 ANALYST 4 30 SALESMAN
The insertion code very simple loop will be slow. OK, it's a work of unique conversion (in theory, but very few times at least), so that could probably be acceptable (except for my professional pride ;-).)
But it's worse, I have groups where the aggregation of string does not work - the chain should be about varchar2 (10000) which does not work in SQL in the group by :-(.
So I tried an attempt from the collections. First a collection of deptnos:
All very good - no problem here. But then a collection of jobs:SQL> create type deptno_tab_type as table of number(2) 2 / Type created. SQL> select od.job 2 , cast(collect(od.deptno order by od.deptno) as deptno_tab_type) deptnos 3 from orig_data od 4 group by od.job 5 / JOB DEPTNOS --------- ------------------------------ ANALYST DEPTNO_TAB_TYPE(20) CLERK DEPTNO_TAB_TYPE(10, 20, 30) MANAGER DEPTNO_TAB_TYPE(10, 20, 30) PRESIDENT DEPTNO_TAB_TYPE(10) SALESMAN DEPTNO_TAB_TYPE(30)
Now, it fails - I can't group by a collection data type...SQL> create type job_tab_type as table of varchar2(9) 2 / Type created. SQL> select s2.deptnos 2 , cast(collect(s2.job order by s2.job) as job_tab_type) jobs 3 from ( 4 select od.job 5 , cast(collect(od.deptno order by od.deptno) as deptno_tab_type) deptnos 6 from orig_data od 7 group by od.job 8 ) s2 9 group by s2.deptnos 10 / group by s2.deptnos * ERROR at line 9: ORA-00932: inkonsistente datatyper: forventede -, fik XAL_SUPERVISOR.DEPTNO_TAB_TYPE
I'm not asking anyone to write my code, but I know that there are sharper brains out there on the forums of ;-).
Someone would have an idea of something I could try that will allow me to create these "groups of groups" even for large aggregation of chain that technical groups can manage?
Thanks for any help, advice or tips ;-)The issue of "group-by-collection" can be resolved by creating a container object on which we define a method of CONTROL:
SQL> create type deptno_container as object ( 2 nt deptno_tab_type 3 , order member function match (o deptno_container) return integer 4 ); 5 / Type created SQL> create or replace type body deptno_container as 2 order member function match (o deptno_container) return integer is 3 begin 4 return case when nt = o.nt then 0 else 1 end; 5 end; 6 end; 7 / Type body createdThen an INSERT statement can do the job, after unnesting collections:
SQL> insert all 2 when rn0 = 1 then into groups (groupkey) values (gid) 3 when rn1 = 1 then into groups_jobs (groupkey, job) values(gid, job) 4 when rn2 = 1 then into groups_depts (groupkey, deptno) values(gid, deptno) 5 with all_groups as ( 6 select s2.deptnos 7 , cast(collect(s2.job order by s2.job) as job_tab_type) jobs 8 , row_number() over(order by null) gid 9 from ( 10 select od.job 11 , deptno_container( 12 cast(collect(od.deptno order by od.deptno) as deptno_tab_type) 13 ) deptnos 14 from orig_data od 15 group by od.job 16 ) s2 17 group by s2.deptnos 18 ) 19 select gid 20 , value(j) job 21 , value(d) deptno 22 , row_number() over(partition by gid order by null) rn0 23 , row_number() over(partition by gid, value(j) order by null) rn1 24 , row_number() over(partition by gid, value(d) order by null) rn2 25 from all_groups t 26 , table(t.jobs) j 27 , table(t.deptnos.nt) d 28 ; 15 rows inserted SQL> select * from groups; GROUPKEY ---------- 1 2 3 4 SQL> select * from groups_jobs; GROUPKEY JOB ---------- --------- 1 SALESMAN 2 PRESIDENT 3 CLERK 3 MANAGER 4 ANALYST SQL> select * from groups_depts; GROUPKEY DEPTNO ---------- ------ 1 30 2 10 3 10 3 30 3 20 4 20 6 rows selectedWorks very well on the sample data, but how this approach is changing on much (much) more large data set is another story :)
-
Missing reference in float Dreamweaver CM³
Download DreamWeaver CC and found that the float of reference is no longer available. But I checked the application directory and content are still there (in the Configuration content reference), it's just that the float is missing. Is it gone forever?
I tried to add it back thru menu.xml by copying the line Dreamweaver CS6, but I got an error saying that reference.htm isn't under Configuration/Floater. However, when I tried to search for the file in CS6, I found that there not this file.
Is there anyway that I can get it back? I know that the content of it is quite outdated, but it is very convenient when working on the codes and need some quick references.
Yes. The reference group has been deleted.
Thank you
VIANEY
-
SQL column as a select to be referenced in a group of
Y at - it a rating or solution to be able to make reference to a column that is an "inline" select statement in a group by such described below? Group a will not alias. I also tried to do the SQL a MAX to remove the need for the reference group and this returned invalid expression.
SELECT DISTINCT hdr. BUSINESS_UNIT,
HDR. SESSN_ID,
HDR. STREAM_ROOT_ID,
HDR. SESSN_STS_CD,
HDR. SESSN_CRE_DTTM,
CASE
When C.OPRID <>' ' THEN C.OPRID
OF OTHER S.OPERATOR
END OPRID
STRM. QS_APP_CONTEXT,
RECV. QTY_SH_RECVD Quantity_Received,
CASE
WHEN hdr. BUSINESS_UNIT = "MFG01" THEN MAX (G.MFDS_SGRP_SIZE)
ANY OTHER MAX (S.SESSN_SGRP_SIZE)
END Quantity_Inspected,
Max (S.QS_VALUEREADING_1) Defect_Count,
CASE
WHEN MAX (S.QS_VALUEREADING_1) = 0 THEN ' '
ANY OTHER MAX (G.MFDS_NAME)
Characteristic of the END,
MAX (CMNT. QS_COMMENT2) COMMENTS.
STRM. INV_ITEM_ID,
ITM. DESCR,
STRM. WORK_CENTER_CODE,
STRM. VENDOR_ID,
* (SELECT V.NAME1 FROM PS_VENDOR V WHERE strm. VENDOR_ID = V.VENDOR_ID AND V.SETID = (SELECT PS_SET_CNTRL_REC SETID *)
WHERE RECNAME = "SELLER".
AND SETCNTRLVALUE = strm. $vendor_name BUSINESS_UNIT));
STRM. PRDN_AREA_CODE,
strm.COMPL_OP_SEQ,
STRM. PRODUCTION_TYPE,
C.RECEIVER_ID,
C.RECV_LN_NBR,
RECV. PO_ID,
RECV. LINE_NBR,
RECV. SCHED_NBR,
C.PRODUCTION_ID,
C.SERIAL_ID,
C.INV_LOT_ID
OF PS_QS_SESSN_HDR8 hdr
LEFT OUTER JOIN PS_QS_SESSN_TRACE8 C
THE hdr. BUSINESS_UNIT = C.BUSINESS_UNIT
AND hdr. SESSN_ID = C.SESSN_ID
LEFT OUTER JOIN PS_RECV_INSPDTL_VW RECV
ON C.BUSINESS_UNIT = RECV. BUSINESS_UNIT
AND C.RECEIVER_ID = RECV. RECEIVER_ID
AND C.RECV_LN_NBR = RECV. RECV_LN_NBR
LEFT OUTER JOIN PS_QS_STREAM_ROOT strm
THE hdr. STREAM_ROOT_ID = strm. STREAM_ROOT_ID
AND hdr. BUSINESS_UNIT = strm. BUSINESS_UNIT
LEFT OUTER JOIN PS_QS_STREAM8_VW G
THE strm. STREAM_ROOT_ID = G.STREAM_ROOT_ID
AND strm. BUSINESS_UNIT = G.BUSINESS_UNIT
LEFT OUTER JOIN PS_QS_SUBGROUP S
THE hdr. BUSINESS_UNIT = S.BUSINESS_UNIT
AND hdr. SESSN_ID = S.SESSN_ID
AND S.STREAM_ID = G.STREAM_ID
LEFT OUTER JOIN PS_QS_SESSN_COMM8 CMNT
WE S.BUSINESS_UNIT = CMNT. BUSINESS_UNIT
AND S.SESSN_ID = CMNT. SESSN_ID
AND S.STREAM_ID = CMNT. STREAM_ID
AND C.SAMPLE = CMNT. SAMPLE
LEFT OUTER JOIN PS_MASTER_ITEM_TBL itm
ON itm. INV_ITEM_ID = strm. INV_ITEM_ID
LEFT OUTER JOIN PS_SET_CNTRL_REC cntrl
ON itm. SETID = cntrl. SETID
AND cntrl. RECNAME = "MASTER_ITEM_TBL."
AND cntrl. SETCNTRLVALUE = strm. BUSINESS_UNIT
WHERE S.QS_VALUEREADING_1 = (SELECT MAX (S2. QS_VALUEREADING_1)
OF PS_QS_SUBGROUP S2
WHERE S2. BUSINESS_UNIT = S.BUSINESS_UNIT
AND S2. SESSN_ID = S.SESSN_ID
AND S2. STREAM_ID = S.STREAM_ID)
GROUP BY hdr. BUSINESS_UNIT,
HDR. SESSN_ID,
HDR. STREAM_ROOT_ID,
HDR. SESSN_STS_CD,
HDR. SESSN_CRE_DTTM,
C.OPRID,
S.OPERATOR,
STRM. QS_APP_CONTEXT,
RECV. QTY_SH_RECVD,
STRM. INV_ITEM_ID,
ITM. DESCR,
STRM. WORK_CENTER_CODE,
STRM. VENDOR_ID,
$VENDOR_NAME,
STRM. PRDN_AREA_CODE,
strm.COMPL_OP_SEQ,
STRM. PRODUCTION_TYPE,
C.RECEIVER_ID,
C.RECV_LN_NBR,
RECV. PO_ID,
RECV. LINE_NBR,
RECV. SCHED_NBR,
C.PRODUCTION_ID,
C.SERIAL_ID,
C.INV_LOT_IDNo, you must use the Group of against advice online. For example:
SQL> select distinct deptno, 2 (select dname from dept d where d.deptno = e.deptno) dname, 3 job, 4 sum(sal) 5 from emp e 6 group by deptno, 7 dname, 8 job 9 / dname, * ERROR at line 7: ORA-00904: "DNAME": invalid identifier SQL> select distinct deptno, 2 dname, 3 job, 4 sum(sal) 5 from ( 6 select deptno, 7 (select dname from dept d where d.deptno = e.deptno) dname, 8 job, 9 sal 10 from emp e 11 ) 12 group by deptno, 13 dname, 14 job 15 / DEPTNO DNAME JOB SUM(SAL) ---------- -------------- --------- ---------- 20 RESEARCH MANAGER 2975 30 SALES MANAGER 2850 10 ACCOUNTING PRESIDENT 5000 30 SALES SALESMAN 5600 10 ACCOUNTING CLERK 1300 10 ACCOUNTING MANAGER 2450 20 RESEARCH ANALYST 6000 20 RESEARCH CLERK 1900 30 SALES CLERK 950 9 rows selected. SQL>SY.
-
I have long had a Zotero account and it works fine. I recently merged in a group with a few other people into account; We share the same set of references. Now I want to set up a personal account for different purposes, perhaps becoming a different group. When I try to set up the new user name and password, the same reference shows always. How can I start with an empty account for the new user name without clear items from the old account?
I know Zotero and just the second jscher2000 tips - if you want to actually different accounts, you must use separate profiles of FF.
The integrated solution for Zotero is to use groups for sharing of resources between people
www.Zotero.org/groups/
And have your own resources in a different group or in 'my library '. -
How can I perform a clean installation of Mac OS x for my iMAC, retina 5K late 2014 with drive of Fusion with the intact Recovery HD partition?
Pure how to install OSX on a Fusion drive and keep the recovery disc function
These instructions assume that your iMAC partitions or file systems has been damaged and you want to restore to the way most efficiency with fusion drive and the recovery partition, similar to what was built in the factory.
These instructions work for the iMAC, retina 5K end 2014 version comes with OSX Yosemite. The scores of major drive of the 128 G SSD and 3 TB of HARD drive has been configured as a logical drive (merger by car).
WARNING: These instructions here are shared for interest only. Readers to take their own risk by following these instructions. The author is not responsible for any damage caused by following these instructions.
This is the target disk partitions, and the configuration that we want to achieve.
Disk0 is the 128 GB SSD - solid state drive and holds the start of the partition (disk0s3)
Disk1 is the 3.0 to HDD - mechanical transmission and holds the Recovery HD partition.
There are two EFI partitions to partition table GUID on both hard drives (disk0s1, disk1s1).
Disk space remaining (partition disk0s2 and disk1s2) are used to create the disc of Fusion 3.1 to named "Macintosh HD".
/ dev/disk0 (internal, physical):
#: NAME SIZE TYPE IDENTIFIER
0: GUID_partition_scheme * GB 121,3 disk0
1: disk0s1 EFI EFI 209.7 MB
2: Apple_CoreStorage GB LVG 121.0 disk0s2
3: disk0s3 Apple_Boot Boot OS X 134,2 MB
/ dev/disk1 (internal, physical):
#: NAME SIZE TYPE IDENTIFIER
0: GUID_partition_scheme * 3.0 to disk1
1: EFI EFI 209.7 MB disk1s1
2: disk1s2 Apple_CoreStorage TB 3.0 LVG
3: disk1s3 Apple_Boot Recovery 650.0 MB HD
/ dev/disk2 (internal, virtual):
#: NAME SIZE TYPE IDENTIFIER
0: Apple_HFS Macintosh HD + 3.1 TB disk2
Logical volume on disk0s2, disk1s2
0D807F6E-FB7C-418F-AAF4-EF3EA3525D10
Fusion unencrypted drive
Here's how we do it.
- A. clean reinstallation of Mac OS x.
- 1. make sure that you back up all your data on the hard drive using Time Machine or other means. The following procedure will delete all data.
- 2. create the OSX install USB, insert it to the MAC workstation.
- 3. given that us will be operated on the internal trunk of the reader of the Mac, it must start on OSX install USB (see Y.).
- 4. in the menu at the top of the screen, select disk utilities.
- 5. turn highlighted the volume of disk Fusion called "Macintosh HD." Click clear to clean.
- 6. If his success, then go ahead to install OSX new to that partition, as usual.
- 7. otherwise, if it does not, that means fusion drive has been damaged.
- 8 follow the instructions below to fix it.
- . B. Split disc Fusion in the physical hard disks
- 1. Since us will be operated on the internal drive of the Mac trunk, assumes that we already have boot up OSX install USB drive (see Y.).
- 2. in the menu at the top of the screen, select utilities and Terminal.
- 3. on the screen of the terminal type:
- Cs diskutil list.
- You will see something similar to the screen below.
- 4 copy the long string after Logical Volume and replace the UUID with it in the following command to delete the logical volume of the disc fusion (aka coreStorage of logical volume):
- diskutil deletevolume cs UUID
- For example:
- diskutil deletevolume E59B5A99-F8C1-461A-AE54-6EC11B095161 cs
- 5 copy the long string after the logical volume group and replace the UUID with it in the following command to remove the drive (aka coreStorage) fusion:
- diskutil cs remove UUID
- p. ex. diskutil cs remove E03B3F30-6A1B-4DCD-9E14-5E927BC3F5DC
- 6. at this stage, the fusion drive has been deleted, and hardsisk SSD and mechanical hard drive will be reappear in diskutil or separate records.
- 7. If step 5 or 6 takes more than 30 minutes to complete, this means that the fusion drive has been corrupted. You can follow the commands below to clear the table to partition the hard way. First command clears the SSD drive, second command erases the HARD drive.
- The command does not return a response, after 1 minute, press Ctrl + Z to complete orders. 1 minute is enough data to code and erase the partition table on the disk.
- cat/etc/random >/dev/disk0
- cat/etc/random >/dev/disk1
- . C install a new copy of Mac OS x for the hard drive HDD and tested this disk partition hard recovery work.
- 1. go on diskutil to create a partition called Macintosh HD HDD hard drive using all the space there.
- 2 do the same with the mechanical hard drive.
- 3. follow the usual procedure to boot from the installation of OSX USB and install a new copy of Mac OS x hard disk SSD.
- 4. This will create the correct priming of the partitions, recovery hard drive partitions and PSX partitions hard disk HDD.
- 5. once the installation is complete, test if OSX may start successfully, but no need to go through the initial MAC OS x didn't put in place that we're going to waste this and do the installation again later.
- 6. we must now test if the recovery hard drive partition works.
- 7. reboot for hard drive recovery (see X - by pressing command and R at the same time during boot right after that you hear sound start and release only a few seconds after you see the apple logo and the progress bar for loading...)
- 8. it is important to test and make sure that the partition of hard drive recovery.
- D. recreate the fusion drive
- 1 since us will be operated on the internal trunk of the reader of the Mac, it must start on OSX install USB (see Y.).
- 2. in the menu at the top of the screen, select utilities and Terminal.
- 3
- diskutil list.
- You should find that we have a list of disk group hard physical volume only, no logic here still.
- 4. you will see something similar to the screen below.
- 5. search for the largest partition on the SSD hard drive, which should be close to the maximum size of HDD to the SSD (121 G, for example) and mark the name of the device, this will usually be something like/dev/disk0s2
- 6. search the largest disk partition mechanical forming fusion with the SSD hard drive. This should be close to the maximum size of the mechanical hard drive (for example 3 TB) hard disk and mark the name of the device, this will usually be something like/dev/disk1s2
- 7 . Now let's create the merger in car (group alias logical volume) in the Terminal, type: diskutil cs create nom_lecteur driveIDs
- The number of the driveIDs is unlimited, it may be a number of discs, or a number of disk partitions. Always put the faster discs first, for example for our SSD disk0s2
- For example:
- diskutil cs create fusiondrive disk0s2 disk1s2
- diskutil - the version of disk utility command line.
cs - This calls for Core Storage, which is necessary for the merger.
create - creates a basic storage group.
nom_lecteur - is the name of the drive and how you want that he - appear in the disk utility (not the Finder - that comes later). You can call it what you like; in our example, we named our Fusion table "Fusion".
- It is important that the faster hard drive appears first in the command, which in our case the disk0s2 (a partition in the SSD). In this way, drive fusion will use this disk as primary and the cache. The second disc in the command, in this case disk1s2 (a partition on the HARD disk). The secondary disk (HARD drive) is used to store less frequently used files. Otherwise, the fusion drive performance will be worse that it is designed for.
- 8. you will see something like below appear on the screen:
- Creation Volume logical storage of kernel
- Move isk0s2 storage of carrots
- Disk1s2 of switching for the storage of carrots
- Waiting for logical volume group appear
- Discovered the new group of logical volumes 'DBFEB690-107B-4EA6-905B-2971D10F5B53 '.
- Store LVG UUID: DBFEB690-107B-4EA6-905B-2971D10F5B53
- Finished CoreStorage operation
- 9 copy to the bottom of the string after "Discovering new Volume Logic Group" using the command + C
- 10. next, create the partition of the merger (alias logical volume) drive named "Macintosh HD".
- In the Terminal, type: diskutil createVolume groupString jhfs cs + size volumeName
- For example:
- Diskutil createVolume DBFEB690-107B-4EA6-905B-2971D10F5B53 jhfs cs + 'Macintosh HD' 100%
- diskutil - once again, this is the version of disk utility command line.
- cs - called the basic storage functions, which are necessary for this arrangement.
- createVolume - this is the command to create the storage area real for the reader who is represented by an icon on your desktop.
- groupstring - this is the long alphanumeric string you copied in the previous step. It identifies the table you created such as getting a volume placed on it.
- jhfs + -the format of the disc. It is Apple (journaled) extended Format, which is recommended for drives with an operating system installed on it.
- VolumeName - the actual name of the volume, how it should appear under the icon. If there is a space in the name, you must put the full name in quotes ("name") or put a slash before the (name Drive\) space. In our example, we made these, naming our volume "Macintosh HD".
- size : this is the size of the volume. In our example, we had a 1.1 TB drive. We used '1100g' to describe what 1100 GB (1.1 TB to base 10). Otherwise, we could have also used 1.1 T or even 100% as a size.
- 11. go to diskutil to verify that you can see this new partition on the list.
- 12. test by erasing all the data from it.
- 13. then you can go ahead to start on the USB drive to install OSX and install a new copy of Mac OS x on it.
- 14. This will allow you to keep the recovery disk feature.
- X. how Prime to recover partition
- Press and hold the command and button R set immediately after hearing the bells to boot.
- Only release it 2 seconds after you see the Apple logo on the screen and the progress bar for the start. This will start the partition of hard drive recovery.
- Y. how-to boot OSX install USB
- Press and hold the command and the optionkey together immediately after hearing the ringing of boot.
- Only release it 2 seconds after you see the Apple logo on the screen and it will give you a list of startup disk choice, choose the OSX install USB to boot from.
-
Store tabular data in file TDM tiara.
Hello
Is it possible to store tables in CT files?
After processing the data, my results are a list of values that is in table form. And normally save us only the TOC file (and not the file TDR), in this case if I want to save the table, that I have prepared what method could be used?
I hope that the issue is clearly else let me know.
Thanks in advance.
Kind regards
fazshah.
Hi fazshah,
Once you calculate the scalar measure to display your table list in the text field, first save this metric as a property attached to the root, or a group or a channel in the data portal:
Data.Root.Properties.Add 'PropName', varValeurProp
'----------------- or -------------------------
Set Group = Data.Root.ChannelGroups ("GroupName")
Group.Properties.Add 'PropName', varValeurProp
'----------------- or -------------------------
Adjust the strings = Group.Channels ("ChannelName")
Channel.Properties.Add 'PropName', varValeurPropYou can add the formula to the list of text field that displays this property you just write:
PropName = @Data.Root.Properties ("PropName"). Value @.
PropName = @Data.Root.ChannelGroups ("GroupName"). Properties ("propName"). Value @.
PropName = @Data.Root.ChannelGroups ("GroupName"). Channels ("ChannelName"). Properties ("propName"). Value @.You can also reference groups and channels by digital instead of the name index, if you prefer.
Brad Turpin
Tiara Product Support Engineer
National Instruments
-
A change of value through VI signalling Server
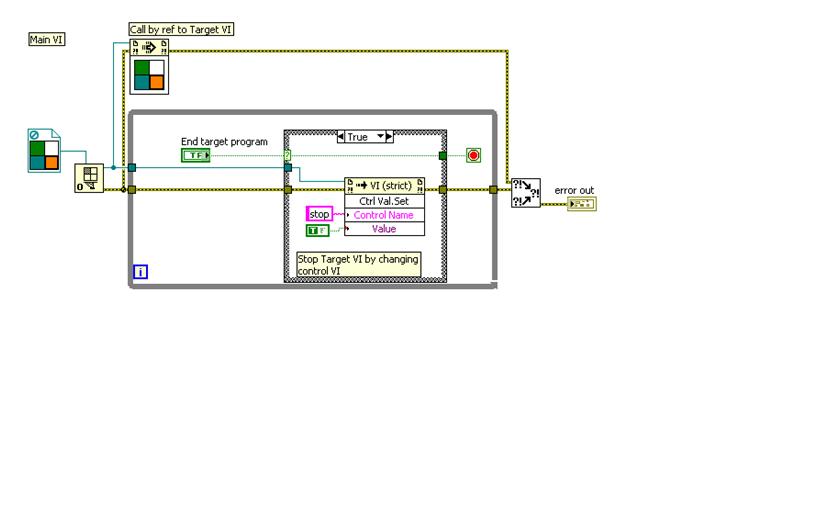
I have a sub - vi with the event structure that is called from a main vi by means of call by reference. I can change the values of the controls on the sub - vi, but the Sun-vi does not recognize the exchange value in the case where the structure. Is it possible to send a signal of change of value in the sub - vi of the main vi? My goal is to not have to make changed to the subvi. I have attached a Pseudo-exemple to show you what I'm trying to accomplish:
It's the main vi with a ref to the target vi call
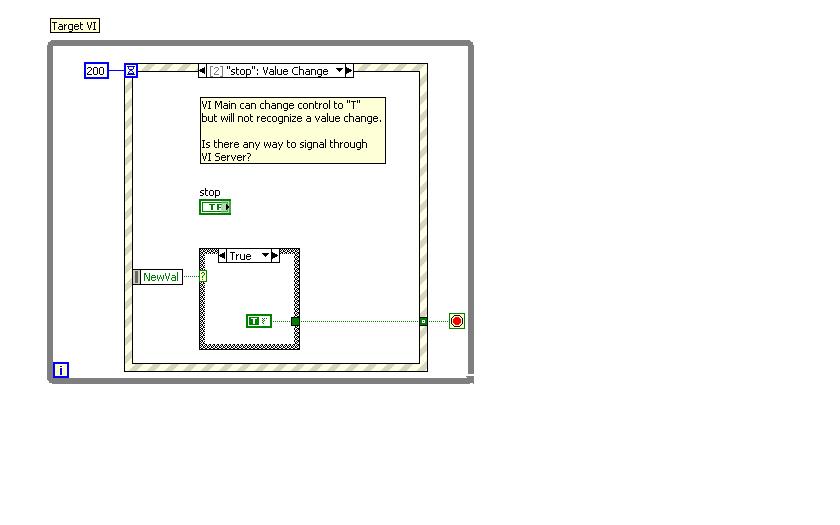
This is the target vi. A change in value is not recognized when the value of control is passed hand vi. Is it possible to do this?
You use the Value property (signs) on the reference of the order.
To get the control reference is to get the reference group of the VI, the controls property [the] property of the Panel. Then wrap using the search for one with the proper name.
-
miniature display of folder files no picture would present flv and avi extensions. MWV (windows media file) is ok. VLC files were ok until yesterday. I reinstalled VLC media player - earlier version too. I also uninstalled IE 8 automatic update - KB976749 - window update put back. Ofcause, I changed many times display options (list, thumbnail,...). I can read files with ok VLC, just that I can't see the image.
Hello Yonghwasik,
Thank you for your message. Since it is a recent issue, you can try a system restore. Click HERE for the system restore instructions.If you are still having these problems after system restore, you can click HERE for troubleshooting tips then a 3rd reference group software that can solve your problem.If the two previous solutions solves the problem, it is recommended that you visit VLC support page HERE and request assistance.Using third-party software, including hardware drivers can cause serious problems that may prevent your computer from starting properly. Microsoft cannot guarantee that problems resulting from the use of third-party software can be solved. Software using third party is at your own risk.See you soonEngineer Jason Microsoft Support answers visit our Microsoft answers feedback Forum and let us know what you think.








driveIDs - Here is the Player IDs of the readers you want as part of your Fusion table, separated by a space. In our example, they are 'disk0' and 'disk1', but it may be different in your configuration.
Maybe you are looking for
-
I'm using an iphone 5 s. Update ios 10.0.1. I can't cut my shutter sound camera even if I toggle the silence in silent mode button. The sound is so loud and noisy. Help, please
-
(Sony) After updating iOS 10 car stereo controls
I am really disappointed that since updating to iOS 10 on my iPhone 6 I can jump is no longer pieces of music using the buttons on my Sony car stereo when my phone is connected. The forward Skip button does nothing and the rear bucket go up to the be
-
In the past I've always had my open pages in a new window and not in a new tab, but it is useless if I can't see the entire page because I only have the address bar, and I can minimize and expand or close the page. There is no scrolling up and down.
-
Satellite 5200 903: Mini PCI card does not work
Hello I am a user of one:Satellite 5200 903: P4 - M 2.2 / 256 + 256 DDR/60 GB/15 t SXGA + / DVD - R - RW / nV FX 5600/SFP/WIFI ready/XP My computer is a Toshiba Wirless lan Mini PCI Card.I installed the card a few years ago - everything worked great.
-
Audio device removed during the restoration of the system
original title: restore accidentally deleted programs? How to restore accidentally deleted programs? Somehow, there is no sound, as he says we no longer have an audio device... Thank you!