Number of unique values in 7 columns
Hey there...I have a table of correspondence with 8 columns
ID = unique ID
U = Sunday,
M = Monday
T = TUE
W = married
R = Thur
F = Fri
S = Sat
Each of the columns 'day' can be a value between 1 and 1150, looks like this
ID U M T W R F S
1 15 15 16 15 17 345 17
What I'm trying to find is a county of the deviation of each line... or how many days have different values
So for the example above
ID U M T W R F S COUNTY
1 15 15 16 15 17 345 17 4
There are have 4 unique values in the week...
15,16,17,345
Any ideas on how this could be done in oracle? Puzzled!
SQL> create or replace
2 type NumberList
3 as
4 table of number
5 /
Type created.
SQL> with sample_table as(
2 select 1 ID,15 U,15 M,16 T,15 W,17 R,345 F,17 S from dual
3 )
4 select s.*,
5 cardinality(set(NumberList(U,M,T,W,R,F,S))) cnt
6 from sample_table s
7 /
ID U M T W R F S CNT
---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
1 15 15 16 15 17 345 17 4
SQL>
SY.
Tags: Database
Similar Questions
-
Column sum based on a single value of another column
Hi all
I've searched and searched, but just can't find if this is even possible, let alone how to do it. What I'm trying to do, it's the sum of a column. However, only summarize the results of this column if a specific value of another column is present. So, for example, the following is a sample database entry:
Rate of pay hours
2.3 $14.00
1.2 $14.00
2.4 $12.50
0.75 $12.50
So for that, I want the sum of hours worked column but only the sum of hours worked if the wage rate is $14.00 and $ 12.50. Because these numbers are generated in a database (with the various people who enter multiple rates of pay), I won't be able to set the where statement to have a specific amount (since I don't know the specific amount each registrant), the amount must be a variable in the where the statement. With MySQLI, I know not how to make the sum of hours worked, but I do not know how the sum of hours worked if and only if the line corresponds to the unique value in the rate column.
Then have it automatically loop through and total hours worked for other unique values in the column salary rate. Finally, out all unique values in the column rate in variables so that I can do the following for each game:
$total1 = $total_hours1 * $wage_rate1 $total2 = $total_hours2 * $wage_rate2 $overall_total = $total1 + $total2
where $wage_rate1 = $14.00 and $total_hours1 = 2.3 + 1.2: etc.
Is it still possible? If so, how? If possible, can someone please let me know a good reference so I can learn how to be the best way to implement?
Thank you
So with that, I get the correct $final_total printed, but I still get the error, 'notice: Undefined variable: final_total. Why is it not defined, but prints the total exact? How to remove the error?
You get this notice is because you use the assignment combined, operator that is normally used to add a value to a variable and assign the new value to it.
$final_total += $total;
is a shortcut for this:
$final_total = $final_total + $total;
The undefined $final_total is on the right side of the assignment operator. The first time through the loop, you add $total to a non-existent value. Because of the type of PHP juggling, this becomes:
$final_total = 0 + $total;
The next time the loop runs, $final_total has a value, so that you get the view variable not defined only once.
To avoid advice, initialize $final_total to zero before the start of the loop.
$final_total = 0;
While ($row = {$sql-> fetch_array())}
-
Number of unique key in a table column
Hi all...
Please help me with this problem. Looking for the number of threads, but could not understand how do.
I have a master form / retail users (main table) and responsibilities (detail table).
The problem is with the table Details (responsibilities), the detail is "" "FORM TABULAR" ".
A user can have the following responsibilities RESP1, RESP2, RESP3, RESP4 (it's a '' select list' ")
When the administrator creates users, they will strike "" Add line"," once they choose a responsibility of the selection list.
When they hit add line once again, "'chosen responsibility should display in the selection list.
EX: when they select RESP "RESP1' in the first row, if they hit add line once again,"RESP1"does not present it as an option for users to select.
EX: If the user already has an RESP "" RESP3"" in the database, "'' RESP3" ' should not display if they try to add another RESP.
Each select list should display different values depend on the values they have chosen so far *.
-> we can put constaint unique key on this column or put validation on this page, but I'm looking for the implementation
Please check the following application example:
http://Apex.Oracle.com/pls/Apex/f?p=42177
Please help me in this task
Thank youThere is no way to declaratively in the Apex to do this.
In version 4.x:
1. There is no declarative way to dynamically filter a list of values in a tabular presentation. For each line, the LOV is actually pre-built on a hidden row zero when the page first appears.
2. to do this, you will need to come up with a process, possibly including AJAX, to fill an array of values to the selection list, delete the values in the table if they have been selected on the other lines of the page and then re - fill the selection on the new list online.In version 3.x:
1 lines are stored in the database every time that you add a row (actually the page saves and repainted with a new line). You can set your LOV SQL to return the values valid less those already stored in the database that the user adds lines.
2. However, that won't necessarily work 100% if you look at a page with several lines already on it and want to update the existing lines and you need in any case a sort of validation or a unique constraint.It is not impossible, but it's very very labor intensive and maintainability is more difficult if another developer a year or two down the road to inherit this page you.
I'd really like to tell your business analyst or key functional end users what they ask for is not supported by Apex first review (and to tell you the truth, it is indeed non-supported, so you are not lying down or fake apology) and they consider like allowing more traditional validation via a unique constraint and page validation.
-
How to insert unique random values in 2 columns?
I have a table with 2 columns
Create table code_for_code)
first_code varchar2 (10) unique not null,.
second_code varchar2 (10) not null unique);
and I want to make PL/SQL code to Insert unique values at random in two columns , for example 20 record... How can I do something like that?DECLARE i NUMBER := 0; BEGIN LOOP INSERT INTO code_for_code SELECT first_code, second_code FROM (SELECT DBMS_RANDOM.STRING ('U', 20) first_code, DBMS_RANDOM.STRING ('U', 20) second_code FROM DUAL) a WHERE NOT EXISTS ( SELECT 1 FROM code_for_code WHERE first_code = a.first_code AND second_code = a.second_code); i := i + 1; EXIT WHEN i >= 20; END LOOP; COMMIT; END; -
How re - number values in a column...?
Hello
So I values in a column as a column looks like this...
Employee_id
------------------
72
73
74
75
76
100
30 s
102
103
108
121 of... and so on...
What I want to do is to renumber these so that they become
Employee_id
------------------
1 (previously 72)
2 (previously 73)
3 (previously 74)
4 (previously 75)
5 (previously 76)
6 (against 100)
7 and so forth...
8
9
10
11
12
any ideas on this can be reached?
Thank you!Hello
No it's not got the foreign keys and this isn't the primary key...
In this case, you should be able to MERGE, also:
SQL>create table test(pk_column number primary key 2 ,emp_id number not null unique); Table created. SQL> SQL>merge into test t 2 using (select row_number() over (order by emp_id) new_id, pk_column 3 from test) s 4 on (t.pk_column = s.pk_column) 5 when matched 6 then 7 update set t.emp_id = s.new_id; 0 rows merged. SQL>Concerning
Peter -
I II A
A A B B C B C C I wish I had a way to calculate the values in the column II of the values in the column I. I has many duplicates, and two column he only unique values. What is the best way to achieve this?
Here's a method:

Column B, the column in the Index, can be hidden.
Formulas:
in B2 and filled until the end of the column B:
IF (COUNTIF(A$2:A2,A2) = 1, MAX(B$1:B1) + 1"," ")
It counts the number of times the value of 'this line' column that has occurred in cells A2 to 'this line '. If the number is 1, the formula returns an index number one greater than the largest number already in the column in the index.
In C2 and filled until the end of the column C:
IF (LINE (−1) > MAX (B),"", LOOKUP (ROW () −1, B, A) ")
The first part of this is a switch that prevents the SEARCH part to act if all the distinct values have been retrieved. If thye have not, SEARCH returns the value to the column of the row whose column B contains a number one at least the number of line of 'the line '.
Kind regards
Barry
-
insertion of unique values as well as the value of the sequence
Hello gurus,
I need to copy values from table A to table B as well as the value of the sequence.
Please find the scripts below.
-Table A and insert
create a (varchar2 (40) of ename, space job_id varchar2 (40));
insert into a values ('Suri', 'THIS');
insert into a values ('Suri', 'THIS');
insert into a values ('ABC', 'Admin');
-Creation of table B
create table B (number empno, ename varchar2 (40), job_id varchar2 (40));
-sequence to fill data in table B empno
create sequences b_empno_seq.
Requirement is that we need fill out the unique values in table A in table B as well as the sequence (for the empno column) value
Please find below the insert and update statements I tried below.
Please let me know if we have a better approach
INSERT INTO B (ename, job_id)
SELECT DISTINCT ename, job_id
A.;
UPDATE b b1
SET empno = b_empno_seq. NEXTVAL
WHERE ename in (SELECT ename b B2 WHERE b2.ename = b1.ename);
-Suri ;-)
INSERT INTO B
() AS T
SELECT DISTINCT ename,
job_id
A
)
SELECT b_empno_seq.nextval,
Ename,
job_id
T
/
SY.
-
Hi all
I want a unique index on two columns, but when I try this it will show me
I want to do not overlap with the combination of these two1 CREATE UNIQUE INDEX sale_order_no 2* ON sale_order (sale_order_no, season_year) SQL> / ON sale_order (sale_order_no, season_year) * ERROR at line 2: ORA-01452: cannot CREATE UNIQUE INDEX; duplicate keys found
Plaese Guide
Thanks and greetings
VikasYou would this behavior if SALE_ORDER_NO has NULL values. If it contains NULL values, a unique single-column index will succeed but an index unique multi-column will fail when it finds duplicates in SEASON_YEAR.
See:
SQL> create table dummy_objects (object_id number, object_owner varchar2(30), object_name varchar2(30)); Table created. SQL> insert into dummy_objects values (0,'HEMANT','TABLE_A'); 1 row created. SQL> insert into dummy_objects values (1,'HEMANT','TABLE_B'); 1 row created. SQL> insert into dummy_objects values (NULL,'HEMANT','NULL_1'); 1 row created. SQL> insert into dummy_objects values (NULL,'HEMANT','NULL_2'); 1 row created. SQL> create unique index dummy_objects_u1 on dummy_objects(object_id); Index created. SQL> drop index dummy_objects_u1; Index dropped. SQL> create unique index dummy_objects_u2 on dummy_objects(object_id, object_owner); create unique index dummy_objects_u2 on dummy_objects(object_id, object_owner) * ERROR at line 1: ORA-01452: cannot CREATE UNIQUE INDEX; duplicate keys found SQL>Hemant K Collette
http://hemantoracledba.blogspot.com -
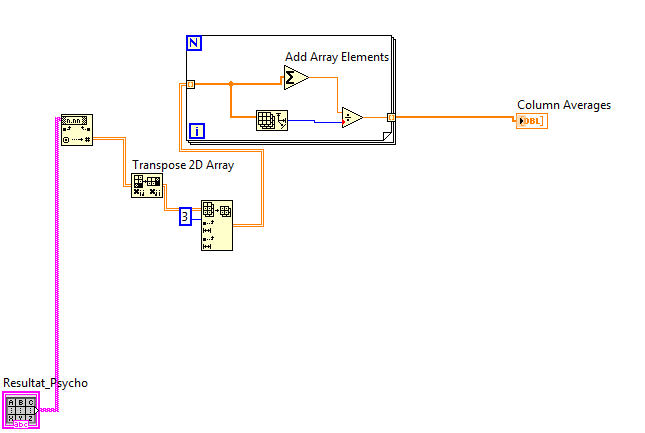
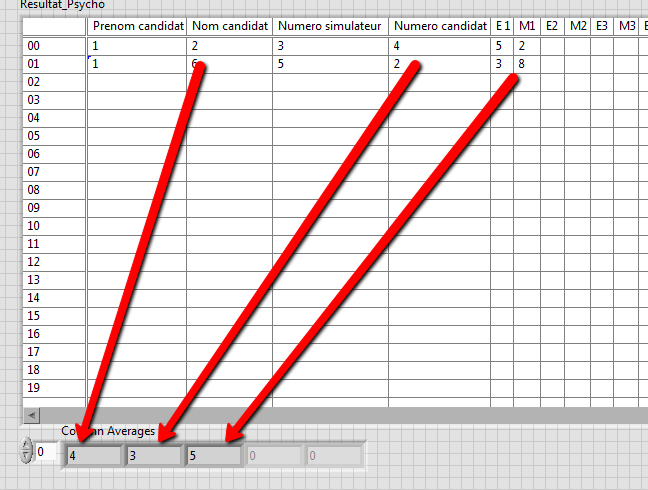
How to calculate the sum of the values of some columns in a table
Hello
I want to get the column just the average of the values of some columns not all columns of the table.what I have to change exactly in this block diagram.even if the table size is 25 average, I want the division as the number of values in each column (= number of lines)
just like that:
-
SQL question - aggregate rows based on the value of the columns
Hi all
DBA_EXTENTS reports on the number of starting point of measurement (column BLOCK_ID) and the size of the scale in the Oracle (BLOCKS column) blocks.
I'm trying to combine the lines of the segments of same as if their associated extensions are adjacent.
For example, assume that the data in the view are as follows:
Nom_segment Block_id BLOCKS EMP 10 8 EMP 18 8 DEPARTMENTS 26 16 DEPARTMENTS 42 8 EMP
50 16 EMP 66 8 And I want to do a set of results that looks like this:
Nom_segment Block_id BLOCKS EMP 10 16 DEPARTMENTS 26 24 EMP 50 16 I thought to use an analytical query, but I couldn't find something that meets this requirement.
Can you please help?
Hello
Here's a way to do that using the analytical SUM function:
WITH got_grp AS
(
SELECT nom_segment, block_id, blocks
, block_id - SUM (blocks) over (PARTITION BY nom_segment
ORDER BY block_id
) AS the grp
FROM the data
)
SELECT nom_segment
MIN (block_id) AS grp_block_id
SUM (blocks) AS grp_blocks
OF got_grp
GROUP BY nom_segment, grp
ORDER BY grp_block_id
;
The data you posted in response to #3:
Pini Dibask wrote:
Thanks Frank,.
If you would care to post CREATE TABLE and INSERT to your sample data and the version of your database, then I could show you exactly.
The Oracle version is 11.2.0.4
This is the CREATE TABLE and INSERT statements for the sample data:
CREATE THE TABLE DATA (NOM_SEGMENT VARCHAR2 (20), BLOCK_ID NUMBER, NUMBER OF BLOCKS);
INSERT IN DATA VALUES ("EMP", 10, 8);
INSERT IN DATA VALUES ("EMP", 18: 8);
INSERT IN DATA VALUES ("DEPARTMENTS", 28, 16);
INSERT IN DATA VALUES ("DEPARTMENTS", 42, 8);
INSERT IN DATA VALUES ("EMP", 50, 8);
INSERT IN DATA VALUES ("EMP", 66, 8);
is not the same as the data in your first post and the results are not the same, either.
The fixed difference technique involves lines don't overlap. In the sample data in response #3, 'DEPARTMENTS' lines overlap, i.e. blocks 42 and 43 belong to two segments.
-
update the value of the column to the next value
Hi all
create table xxc_test (date of from_date, to_date date, amount, number incr_amount);
Select 2014, 2015, 3000, the double null
If suppose if input data in the incr_amount then let say 1000 I want to update the value with incr_amount column amount
Select 2014, 2015, 4,000 of the double
If not even though it is as
Select 2014, 2015, 3000, the double null
and must be updated to the year
Note: I spend the year, amount,incr_amount manually (run-time)
Post edited by: Rajesh123 Note added in the subect
Hello
: new.incr_amount: = 0; also use it in code.
The condition " If : new.incr_amoun is > 0" then (sure fire or change the value only if the increment is positive. ).
,....
..
end if;
-Thank you
Pavan Kumar N
-
update line and reset the value of the column
I have table (CORS_MTR) with 3 columns...
SEQ ID of the EPR the ID of the child / / desc 100 22 1 one 101 22 2 two new entry as 1 number , that means change the flow of child #
102 22 3 three When I enter the new line in number of children 1 instead of 2 and then the values of the column (child id, desc) another need to be reset as...
SEQ ID of the EPR the ID of the child / / desc 100 22 2 two 101 22 1 one 102 22 3 three 103 22 4 four SEQ PRT_ID CHILD_ID DESC_ 100 22 1 one 101 22 2 two 102 22 3 three declare
number of p_seq: = 103;
number of p_prt_id: = 22;
number of p_child_id: = 1;
p_desc varchar2 (25): = 'a ';
Start
Update cors_mtr
set seq = case when child_id = p_child_id
then seq + 1
other seq - 1
end
where prt_id = p_prt_id
and child_id (p_child_id, p_child_id + 1);
insert into cors_mtr (seq, prt_id)
values(p_seq,p_prt_id);
Update cors_mtr
Set child_id = (select max (child_id) + 1 of the cors_mtr).
desc_ = (select to_char (to_date (max (child_id) + 1, 'J'), 'jsp') of cors_mtr)
where child_id is null.
end;
SEQ PRT_ID CHILD_ID DESC_ 100 22 2 two 101 22 1 one 102 22 3 three 103 22 4 four Concerning
Etbin
-
retriving of unique records on two columns
Hello world
Using sql query, that he must retrieve unique records on two columns.
Example of table source: raster columns [uwi, well_no]
Examples of data below
UWI well_no
----- --------
1 988311
1 988311
1 1032662
1 1032662
2 103
2 103
2 103
3
3 104
3 104
3 104
4 106
4 107
4
4 108
For a given
UWI: 1 there are 4 well_no which is having two distinct values where these documents I need to go get
UWI: 2 there are 3 well_no, all 3 well_no contains the same value as (103) Consequently, these documents should not seek
UWI: 3 there are 4 well_no (1 null and 3 values are the same (104)] where these records should not seek.)
UWI: 4 there are 4 well_no which is to have three separate with a single value zero so these 4 files, I need to get.
output:
UWI well_no
----- --------
1 988311
1 988311
1 1032662
1 1032662
4 106
4 107
4
4 108
Thank you
Jery
Hi, Michel,.
Whenever you have a question, please post CREATE TABLE and INSERT statements for your sample data, so people who want to help you can recreate the problem and test their ideas.
Format your message so that it is easy to read and understand.
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum: https://forums.oracle.com/message/9362002
Maybe you want something like this, which shows information about the jobs that have deptnos 2 or more not NULL:
WITH got_cnt AS
(
SOME jobs, deptno
, ACCOUNT (SEPARATE deptno) RESUMED (work PARTITION) AS cnt
FROM scott.emp
)
SOME jobs, deptno
OF got_cnt
WHERE cnt > 1
;
-
Specify a default value for a column in a Script
Greetings fellow Forum inhabitants,
Thank you in advance for taking the time to read and answer my post! (thumbs up)
I'll jump in full.
I've already created table:
CREATE TABLE Bill
(
OrdID number 4 NOT NULL,
Description VARCHAR2 (30) NOT NULL,
ProdID NUMBER (6)
actualprice NUMBER (8.2)
NUMBER Qty. (8).
itemtot NUMBER (8.2)
);.
I have to create a script to load the rows in the table of the invoice by the intervention of the user. However, I specify a default value for quantity
That's what I have so far:
INSERT INTO Bill (ordid, description, prodid, actualprice, qty, itemtot)
VALUES (& & ordid, & & description, & & prodid, & & actualprice, by DEFAULT, & & itemtot)
WHERE qty = DEFAULT;.
or
WHERE DEFAULT = 1;
or
??
I don't know where I am going wrong. I apologize if I'm unable to communicate what she I'm actually doing.
Any advice would be appreciated.
Thanks again for your time.
Hello
e752a7a0-bab5-4ee4-9ea4-bf7c4a2cadab wrote:
Greetings fellow Forum inhabitants,
Thank you in advance for taking the time to read and answer my post! (thumbs up)
I'll jump in full.
I've already created table:
CREATE TABLE Bill
(
OrdID number 4 NOT NULL,
Description VARCHAR2 (30) NOT NULL,
ProdID NUMBER (6)
actualprice NUMBER (8.2)
NUMBER Qty. (8).
itemtot NUMBER (8.2)
);.
I have to create a script to load the rows in the table of the invoice by the intervention of the user. However, I specify a default value for quantity
That's what I have so far:
INSERT INTO Bill (ordid, description, prodid, actualprice, qty, itemtot)
VALUES (& ordid, & description, & prodid, & actualprice, by DEFAULT, & itemtot)
WHERE qty = DEFAULT;.
or
WHERE DEFAULT = 1;
or
??
I don't know where I am going wrong. I apologize if I'm unable to communicate what she I'm actually doing.
Any advice would be appreciated.
Thanks again for your time.
Sorry, I can't understand what you want.
If you want the production order 1, then put a literal 1 for the value of this column:
INSERT INTO Bill (ordid, description, prodid, actualprice, qty, itemtot)
VALUES (& ordid, ' & description', & prodid, & actualprice, 1, & itemtot)
;
or, if that value is used elsewhere in your script, set a variable substitution:
DEFINE Qty = 1
INSERT INTO Bill (ordid, description, prodid, actualprice, qty, itemtot)
VALUES (& ordid, ' & description', & prodid, & actualprice, & qty, & itemtot)
;
I hope that answers your question.
If this isn't the case, post an example, such as:
"If the user types... then the created line must contain... but if the user types... then the new line should be... »
Simplify the question. Do you really need 6 columns to show what you don't understand? Why not just 2 or 3 columns?
See the FAQ forum: https://forums.oracle.com/message/9362002
-
Hello
I am new to Oracle. I was testing some queries and accidentally changed the values in a column special and done a COMMIT. I need to change the values in this column (INSTANCE_ID) back to what it was. Fortunately, there are just 4 rows, I need to change the values of (cos it is based on a unique ID). I am unable to change it. Please any help would be appreciated. What is the good query to run for this?
The column that needs to be changed-
Of
INSTANCE_ID CAPA_ID
10979360 MS-030091
10979360 MS-030091
10979360 MS-030091
10979360 MS-030091
TO
INSTANCE_ID
10979360 MS-030091
10979134 MS-030091
10979348 MS-030091
MS 11161903 - 030091
Grateful for your help!
Thank you very much for your answers! I went directly to the modified table of values in the INSTANCE_ID column and validation to success, went and ran a SELECT query in my editor, the values are changed and it worked!

Maybe you are looking for
-
Update BIOS question on the Qosmio F50/F55 series
I have advanced and updated the bios of the 1.30 the 2.20 and everything went well.I did not like the new bios for the portable was little more warm, so I went to downgrade to the 1.30.I have two toshiba Web site and has made the winphlash64. Thing i
-
new version of itunes is causing flickering of the screen
I just downloaded the latest version of Itunes, 12.3.2 for Windows and it is causing my laptop to twinkle screen. How should I do?
-
ProBook 430 G3: USB ethernet adapter cannot be enabled.
Hello I have to connect the public network with integrated lan card and share another PC via the USB ethernet adapter. After installation of the USB adapter, the card is automatically disabled and it displays the error code 22 in Device Manager. Once
-
HP6830: Failure of the print queue
HP replaced my 6830 due to failure of the print head. New printer works proud desktop using Vista. Previuosly I could print from my laptop wireless as well, but it's time the print queue says printing, fails to print and return to errot impression. I
-
Windows 8 - Winddows Explorer refreshes when I right click
Hello Just installed Windows 8 Pro and when I angle right click on the desktop, him refreshes the entire windows Explorer, it's like when you try to end task Windows Explorer. And when you start a program, like the time I type the whole page is flash