organize the output data
Hello world
I have the following table
CREATE TABLE TESTMANY
(
ITEM_CODE VARCHAR2 (20 BYTE) NOT NULL,
ITEM_YEAR NUMBER 4 NOT NULL,.
ITEM_NEW_CODE VARCHAR2 (20 BYTE) NOT NULL,
ITEM_NEW_YEAR NUMBER 4 NOT NULL
);
Insert into TESTMANY
(ITEM_CODE, ITEM_YEAR, ITEM_NEW_CODE, ITEM_NEW_YEAR)
Values
(24 X', 2009, 15 'V', 2007);
Insert into TESTMANY
(ITEM_CODE, ITEM_YEAR, ITEM_NEW_CODE, ITEM_NEW_YEAR)
Values
("32F", 2004, "30 YEARS", 2003);
Insert into TESTMANY
(ITEM_CODE, ITEM_YEAR, ITEM_NEW_CODE, ITEM_NEW_YEAR)
Values
("54W", 2004, 56 P', 2002);
Insert into TESTMANY
(ITEM_CODE, ITEM_YEAR, ITEM_NEW_CODE, ITEM_NEW_YEAR)
Values
("54W', 2004, ' 70 D ', 2002").
Insert into TESTMANY
(ITEM_CODE, ITEM_YEAR, ITEM_NEW_CODE, ITEM_NEW_YEAR)
Values
("54W', 2004, '65J", 2002);
Insert into TESTMANY
(ITEM_CODE, ITEM_YEAR, ITEM_NEW_CODE, ITEM_NEW_YEAR)
Values
(61 X', 2009, 15 'V', 2007);
COMMIT;
The data look like this
| Header 1 | Header 2 | Header 3 | Header 4 |
|---|---|---|---|
| 61 X | 2009 | 453 | 2010 |
| 349 | 2009 | 453 | 2010 |
| 446 | 2004 | 65J | 2012 |
| 446 | 2004 | 60% | 2012 |
| 32F | 2004 | 202 | 2012 |
| 446 | 2004 | 461 | 2013 |
You can see is 15v to 2 ranks to the point that I can see 15V 51 X and 24 X.
and 54W linked with 65J, 70 d abd 56 p.
the result of the will, I want that she, like one to many
| Header 1 | Header 2 | Header 3 | Header 4 |
|---|---|---|---|
| 453 | 2007 | 719 | 2009 |
| 349 | 2009 | ||
| 54W | 2004 | 65J | 2012 |
| 60% | 2012 | ||
| 56 P | 2013 | ||
| 22' | 2004 | 202 | 2012 |
see how to watch now, one to many not need to repeat the code.
How do you do?
Thank you
SQL> SELECT Nullif(header1, Lag(header1, 1)
2 over (
3 ORDER BY header1)) header1,
4 Nullif(header2, Lag(header2, 1)
5 over ( partition by header1
6 ORDER BY header1)) header2,
7 header3,
8 header4
9 FROM (SELECT CASE
10 WHEN cnt > 1 THEN item_new_code
11 ELSE item_code
12 END header1,
13 item_year header2,
14 CASE
15 WHEN cnt > 1 THEN item_code
16 ELSE item_new_code
17 END header3,
18 item_new_year header4
19 FROM (SELECT item_new_code,
20 item_new_year,
21 item_code,
22 item_year,
23 Count(item_new_code)
24 over (
25 PARTITION BY item_new_code
26 ORDER BY item_new_code) cnt
27 FROM testmany)) /* Make modification to display in desired order */
28 ;
HEADER1 HEADER2 HEADER3 HEADER4
-------------------- ---------- -------------------- ----------
15V 2009 24X 2010
61X 2010
32F 2004 30S 2012
54W 2004 56P 2013
65J 2012
70D 2012
6 rows selected.
SQL>
Tags: Database
Similar Questions
-
Fluke Hydra 2625 with NI LabVIEW drivers: can not read the output data
I work with a Fluke Hydra data logger 2625 have downloaded the drivers from NI LabVIEW, crossed the config., initialize and modes files and now trying to read data from a thermocouple.
Initially, I was getting an error message ("17" I think) but now, after correcting the port numbers, the recorder data and LabVIEW seem to communicate without error. I would like to know where I should look (in the panels before different drivers) for temperature data output.
Any advice would be appreciated at this point. Thank you.
There is a driver not supported here. I have the instrument and you have not used one in quite a few years, but if using the example, the function can be set to temperature temperature with the 751 RTD or thermocouple. The results indicators min/max/last.
The pilot could really benefit from a full rewrite, but it seems that most of the basic functions are there.
-
Organize the hexadecimal data / USB interface
Hello
I implemented a program that send BCD codes on a microcontroller (PIC16F877) (transmission of 8-bit each) via the USB port. Due to synchronization problems, data are transmitted continuously. I can receive the data on labview. However, I cannot read the data all the time and therefore the data read aren't on the right order. I added a starting framework to my data and I would like to know how I can move my bytes to organize them in the right order (Frame/Data1/Data2 /...)? (Perhaps using a loop with a comparison)
So how can I select only some bits? Do I have to reset the other bits?
I hope that I was clear enough. I'm quite a beginner with labview (started a few weeks ago)
Thank you
Hello
Information read in the buffer are types of channels. To work on the BCD code, I probably have to change it to a byte array and then decode byte by byte. But it does not work. The translation is wrong. Do you have any idea why?
I have attached my VI. This is just a test code that I will implement after on my VI read the USB input
-
How working batch entity Match to staged the output data?
Hello
I want all the duplicate with score of table records mid-range performer stand single entity lots of output. I don't know how to make for output account entity attributes (name, address and telephone, etc.) could you please somebody guide me how to do this?
Thank you
Most likely, you should not Match results - prepare and Match result - output in your work process. Clone work (drag up to the jobs node to create a copy with a different name) and delete these processes and the export of your job task. Then add a recorder to your game from UK - process of the entity with the data you need and an export job if you need to write the results to the outside.
Note that you can also activate game review if necessary.
-
compare the data and the output data that do not exist
Hello
I've written a procedure to insert data into a table 3 where I compare the data between two tables, if it matches it insert in the table test_a Joanie. If the exists not or other tables i.e. test_code and test_type it should output this data, where there is no. my code works for a single table, which is test_code. It's not DBMS display a line that is not in the table test_type. could just tell my why? Assume that if test_code a line which is only not in test_type it should out saying this line of incompatibilities with test_type and vice versa.
-Here's my code
Test of CREATE OR REPLACE PROCEDURE. GET_data
IS
BEGIN
DELETE test.test_a;
FOR c IN (select a.cCODE,
a.type,
a.Indicator,
RTrim (xmlagg (xmlelement (e, a.codenum |))) (') a.codenum order) .extract ('/ / text()'), ',') codeNUMber.
b.CCODE cc,
b.type tp,
b.Indicator ind
test.test_code a, test.test_type b
where a.ccode = b.ccode (+)
AND a.type = b.type (+)
AND a.indicator = b.indicator (+)
Group of a.ccode, a.type, a.indicator, b.CCODE, b.type, b.indicator
order of a.ccode)
LOOP
BEGIN
IF (c.cCODE = C.c.c.
AND C.type = C.tp
AND C.indicator = C.ind
AND C.SYS_IND = C.SYSIND) THEN
insert into test.test_a (CCODE, type indicator)
values (C.cCODE, C.type, C.indicator);
ON THE OTHER
dbms_output.put_line (' rules for cCODE issue: ' |) C.cCODE);
dbms_output.put_line ('type: ' |) C.type);
dbms_output.put_line (' indicator: ' |) C.Indicator);
dbms_output.put_line (' problem of rules for CC: ' |) C.C.C.) ;
dbms_output.put_line ('tp: ' |) C.TP);
dbms_output.put_line ('ind: ' |) C.IND);
END IF;
EXCEPTION
WHILE OTHERS THEN
dbms_output.put_line (' rules for cCODE issue: ' |) C.cCODE);
dbms_output.put_line ('type: ' |) C.type);
dbms_output.put_line (' indicator: ' |) C.Indicator);
dbms_output.put_line (' problem of rules for CC: ' |) C.C.C.) ;
dbms_output.put_line ('tp: ' |) C.TP);
dbms_output.put_line ('ind: ' |) C.IND);
END;
end loop;
commit;
END;
/
Thank youYou must use a FULL OUTER JOIN instead an OUTER JOIN for this.
Just curious, why do you need to use dbms_output instead to execute the SQL query with additional conditions (if part of your procedure)?. You can use two times, one to insert those that match and one for the selection of others who do not match.
Kind regards.
-
The GPS data with other analyzed data record
Hello!
I am a new user of DASYLab and not very good with coding, so please bear with me! I try to record (timestamp, latitude, longitude) already analysed GPS data with other data (accelerometer, etc.) in the same. DDF file. Right, GPS analysed is now sent through a series of three demultiplexers for each signal and only 1 of 16 channels, reducing the size of the output data. This data is then saved in a. The CAD file. Other data on average, recorded in one. DDF file, then saved another. The CAD file. We used to compare the data from the GPS and other devices by comparing timestamps.
I would like to save all data to a file, either. DDF of. CSA (.) DDF would be preferable).
When I try to add more channels in the. DDF save the module after the demultiplexer black box and GPS data to it, I get an error saying "the data to an entry in this module are the wrong type." I also receive this error when trying to send the data GPS to the. CSA Save module. I learned that this means that the size of the files is not the same of this thread. My question is, how can I make sure that the data have the same characteristics of time so I can save to the same file?
If you need more information I would be happy to provide it, I apologize if I have something important to go.
Thanks for reading,
etdiv
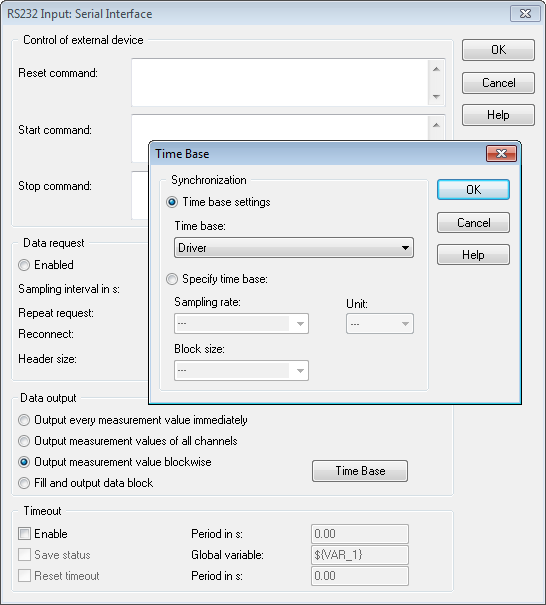
That's what I needed. Your time is the driver. In the RS232 input module, click the Options button.
Select the measurement of output value, and then click the button on the time Base and select sync/time Base driver.
That should allow you to write to the DDF file.
-
How to synchronize the analog input and the output of two different USB data acquisition boards
Hi all
I have two tips very different USB NI USB 6008 case, which I use to acquire the data (analog input) and a USB of NI 9263 is a output analog only site I use to route a signal (in this case a square pulse). The reason why I use the outputs analog 6008 is because I need to deliver negative tension and need the full +/-10 v range.
Looking at similar positions, I'm pretty sure that I can't use an external trigger or a common clock, I also tried to use the timed synchronization of the structures but no cigar.
I'm including a quick vi I whipped showing how the jitters because of the lack of synchronization signal. The OD of the 9263 connects to AI in the 6008 in this example.
I talked to a specialist in the phone and tols me that's not possible.

-
Add headers of data channel to the output file
I've seen several threads, discussing how to get names on the column headers in the data output dynamic in a file and thought I'd give a simple example of how to do it.
The example generates a Y = 2 X 2 data flow and sends them to a XY Chart and an output text file.
It is necessary to convert the dynamic data to a waveform and waveform VI attribute allows you to add the attribute named NI_ChannelName.
The waveform is then converted into dynamic data.
It's the solution, I developed and confirmation of more experienced users would appreciate it if this is the best way.
Colin
Hi Colin
Just to let you know that your method is the best way to deal with dynamic data - there is no way to directly add dynamic data headers. If you have any other questions, feel free to ask.
Best regards
-
How the lack of dates online results of the query and convert the output
Hi Experts,
My inline query returns the data in this format
2-jan-2016 10 4-jan-2016 33 5-jan-2016 20 7-jan-2016 70 8-jan-2016 77
I want to display the output as
1-jan-2016 2-jan-2016 3-jan-2016 4-jan-2016 5-jan-2016 6-jan-2016 7-jan-2016 8-jan-2016 9-jan-2016 10-jan-2016 0 10 0 33 20 0 70 77 0 0
Can you please help me with query how over the missing dates, is it tier, collar or pivot?
Thanks in advance.
Kind regards
IVW
Hello
Is that what you are looking for?
WITH
SampleSet
AS (SELECT TO_DATE (' 2 January 2016', 'DD-mon-yyyy') dt, val 10 FROM DUAL)
UNION ALL
SELECT TO_DATE (' 4 January 2016', 'DD-mon-yyyy'), 33 FROM DUAL
UNION ALL
SELECT TO_DATE (' 5 January 2016', 'DD-mon-yyyy'), 20 FROM DUAL
UNION ALL
SELECT TO_DATE (' 7 January 2016', 'DD-mon-yyyy'), 70 FROM DUAL
UNION ALL
SELECT TO_DATE (' 8 January 2016', 'DD-mon-yyyy'), 77 FROM DUAL
)
sample_rn as
(
Select
DT
val
, dt - min (dt) (order 1) + 1 rn
2 line_no
Of
SampleSet
order by
DT
)
mindate as
(select min (dt) dt sampleset)
dates in the FORM
(
SELECT
DT + level 1 - dt
null val
level rn
1 line_no
Of
MinDate
CONNECT BY ROWNUM<= 10 ="" --="" number="" of="">
)
a, as
(
Select
to_char Col (DT)
rn
line_no
Of
dates d
Union
Select
to_char Col (Val)
rn
line_no
Of
sample_rn
where
RN<= 10 ="" --="" number="" of="">
)
Select
*
Of
a pivot (pass the max (col) of rn (1,2,3,4,5,6,7,8,9,10))--liste of columns 1 to))What makes a list with 2 rows. Line 1 has dates starting with the first data of sampleset. and line 2 has the values. The number of columns, you can determine yourself.
Kind regards
Peter
-
4.0 ai2: wish that the export for not writing tool option date in the output of export file
Hello
The new export feature Cart in 4.0 that can be run as a command of sdcli is a very popular feature
As an improvement, I would like to see an option in the export tool where it is possible to choose whether the date should be
written in the file result of export or not. Currently, it is always written in the output of export file.
Why I don't want a line whose date is when you create one or more result export files, using the
function directly in a directory of the source code management, for example a SubVersion directory, the export of the basket sdcli
will be almost always indicated as changed because of the line with the date, even if the exported data are unchanged.
Would it not possible to add such export tool option for the new version 4.0 of SQL Developer?
With sincere friendships.
Christian
There is now a preference to determine the behavior of date. This just missed getting into ai2 but will be there in the next EA.
-
Any way to customize the output of tag_eventfromdate to view a different date format?
The {tag_eventfromdate} and {tag_eventtodate} out of the dates in the format DD-MMM-AA is not-very-nice. Is it possible to adjust the output format to something more human of the environment as 'November 22, 2014?
In the live platform - only with javascript at the moment.
-
CC of Dreamweaver takes conditional text? Specifically, can I put all of my tech data in a doc of DW and the output of the subsets of data (doc Admin against doc user versus doc Marketing) based on tags or other methods?
I don't have any front-end text editor (such as FrameMaker) or I'd do it here. Dreamweaver can do this without complex workarounds or procedures not supported?
Thank you very much.
Mike the Newbie
OK, that's fine. DW not conditionalization and I'll see if I can get what I need to do or find another approach.
Thanks a lot for your help.
Michael
-
Order DATAEXPORT does not Level0 data in the output file.
We use essbase worm 9.3.1.3 well explicitly programmed for lev0 members in the output file, output file has no-Level0 members.
Please see the code...
=========================
SET DATAEXPORTOPTIONS
{DataExportLevel "Level0";
DATAEXPORTCOLFORMAT ON;
DATAEXPORTOVERWRITEFILE ON;
WE DataExportRelationalFile;
};
/ DIFFICULTY (@RELATIVE ("distributable (allocated) income ', 0), @RELATIVE (" income Net Control", 0"),)
@RELATIVE ("accounts balance sheet", 0),
@RELATIVE("Qtr1",0), @RELATIVE("Qtr2",0), @RELATIVE("Qtr3",0), @RELATIVE("Qtr4",0),
@RELATIVE("FY2010",0), @RELATIVE("FY2011",0),
@RELATIVE("Organization",0))
DATAEXPORT 'File ' ' | ' 'Filename.txt ';
ENDFIX
=======================================
Can you please help?
Thank you
AVIMembers that are not zero-level, look to see if they are the parents of an only child. If so, do the parents share ever and it will solve your problem.
-
How to get the CSV file, RTF model output DATA
Hi, Jorge
Thanks for your help.
as in the link you gave the model RTF can have the type of output CSV DATA but in the preview, I see only html, powerpoint, pdf, html, excel.
How to see the result in SCV, DATA format using my RTF model do I have to do a specific design for these outputs.
Thnaks in advanceThis is because it has been preconfigured with these outputs.
Edit and add types of outputs more simply go to:1. change your report
2. click on 'Display list' (upper right corner)
3. click on the "output formats" (corresponding to your page layout) and
4. check the formats (add) additional output you want your report to have.see you soon
Jorge
-
SQL Developer: How to copy the data with the output grid column headers?
Hello
I use the 2.1.1.64 Version.
I run a SQL query, down the results grid in the "Query result" window below. Say that I get 10 rows returned, with 5 columns.
I want to copy this whole grid, as well as the names/column headers to the Clipboard. If I can stick under the original query to document the results of this query.
I can't find any way to do this. I can copy/paste the results grid, but it does not copy the headers.
The only way I think to do is to go through many steps to export in a TXT file, then paste that. Unfortunately, that's a lot of steps wasted if I need to do it again and again, and more, the output is pasted in an ugly format with double quotes, etc..
It seems that the easiest feature is copy and paste the entire grid of the results, and of course, you could the headers. Why is it so difficult/impossible to do?
(I think that the toad has the same problem. DBArtisan lets you copy and paste the results together, as well as headers, however.)
Any help would be appreciated!
Thank you
JohnShift-Ctrl-C will copy the headers of columns as well as the selected data.
Maybe you are looking for
-
Satellite L20-121 does not start normally
Hi guys Can someone tell me what seems to be the problem with my pc. I can start t normally, after contact with TOMORROW TOSHIBA, the screen stays white with Dim lights and I have to press F12 or entry to load windows. Sometimes I can't drag files, w
-
Codex missing - Windows XP 64 - ripping library
Download the missing codex of error. The Codex is available in Windows 7, WMP 12, is available from 12 for XP 64 bit?
-
Error message below Re: I got the cumulative update for IE 9-64 - bit to fail repeatedly. The error code is listed below. How much of a problem is the following and, if serious, how can I get the system to install this update? I'm running Vista 64
-
When I put the system in standby mode, it usually does not restart. I need to turn the machine off and then start it from scratch?
-
How to install netflix to my windows media center on Windows Vista Edition Home Premium
Original title:? How to install netflix on my windows media center, I have windows vista Home premium