Partial insertion with secondary index
I would like to use partial inserts (DB_DBT_PARTIAL).However, I also need secondary indexes. Now when I insert partial data, the secondary index function is called immediately, but again, I don't have enough data to calculate the secondary key. I tried to provide some app_data is the DBT, but it does not reach the secondary index function.
Is it possible that I can use partial inserts as well as secondary indexes?
Hello
Your secondary index callback function detects when there is not enough data to generate the secondary key? If so, you can return your callback function DB_DONOTINDEX.
For more information about DB_DONOTINDEX, see the db-> documentation here: http://download.oracle.com/docs/cd/E17076_02/html/api_reference/C/dbassociate.html
DB_DONOTINDEX basically tells the library is not to create a secondary key for this record. Subsequent updates to the data structure (that do contain the data that you need) can then return the value of secondary key appropriate to the callback function.
Kind regards
Dave
Tags: Database
Similar Questions
-
Performance problem when inserting in an indexed table space with JDBC
We have a table named 'feature' that has a "sdo_geometry" column, and we created the spatial index on this column,
CREATE TABLE (ID, desc varchar, sdo_gemotry oshape) feature
CREATE INDEX feature_sp_idx ON feature (oshape) INDEXTYPE IS MDSYS. SPATIAL_INDEX;
Then we executed following SQL to insert some 800 records in this table (we tried this using the DB Viewer and)
our Java application, both of them were using JDBC driver to connect to the database oracle 11 g 2).
insert into feature (id, desc, oshape) values (1001, xxx, xxxxx);
insert into a values (id, desc, oshape) feature (1002, xxx, xxxxx);
...........................
insert into a values (id, desc, oshape) feature (1800, xxx, xxxxx);
We met the same problem as this topic
Performance of the insert with spatial index
It takes almost 1 dry for inserting a record, compared with 50 records inserted per second without spatial index.
which is 50 x slow performance when you perform the insertion with the spatial index.
However, when we copy and paste these scripts inserted in Oracle Client(same test and same table with spatial index), we got a completely different performance results:
more than 50 records inserted in 1 seconds, as fast as the insertion without having to build the spatial index.
Is it because that the Oracle Client not using JDBC? Perhaps JDBC has been something bad when updating of these tables indexed on the space.
Edited by: 860605 09/19/2011 18:57
Edited by: 860605 09/19/2011 18:58
Published by: 860605 on 19/09/2011 19:00JDBC normally use autocommit. So each insert can leads to a commit.
I know not all customer Oracle. In sqlplus, insert is just an insert,
and you run "commit" to commit your changes explicitly.
So maybe that's the reason. -
Hello world
I have a table with an index.
Here is my script:
CREATE TABLE MM_STAT_SCREEN (NO_EMIARTE VARCHAR2(12 BYTE), REASSEMBLY VARCHAR2(1 BYTE), CHANNEL NUMBER (1), DATE_AUDIENCE DATE, VARCHAR2(30 BYTE), PUBLIC DISPLAY NUMBER, FILLED CHAR (1 BYTE), DATE_MOD DATE, PERS_MOD VARCHAR2 (20 BYTE), EXTRACT NUMBER, VARCHAR2 (30 BYTE) PLATFORM NOT NULL) TABLESPACE STUBBORN RESULT_CACHE (DEFAULT MODE) PCTUSED PCTFREE, INITRANS 10 0 1 MAXTRANS 255 STORAGE (64 K INITIAL NEXT 1 M MINEXTENTS 1 MAXEXTENTS UNLIMITED 0 USER_TABLES FLASH_CACHE DEFAULT PCTINCREASE BY) DEFAULT CELL_FLASH_CACHE DEFAULT LOGGING) NOCOMPRESS NOCACHE NOPARALLEL SURVEILLANCE;
CREATE INDEX MM_STAT_SCREEN_DATE_IDX ON MM_STAT_SCREEN (DATE_AUDIENCE) RECORD TABLESPACE STUBBORN PCTFREE, INITRANS 10 2 MAXTRANS 255 STORAGE (64 K INITIAL NEXT 1 M MINEXTENTS 1 MAXEXTENTS UNLIMITED 0 USER_TABLES FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT PCTINCREASE) NOPARALLEL;
CREATE INDEX MM_STAT_SCREEN_NO_EM_IDX ON MM_STAT_SCREEN (NO_EMIARTE, REASSEMBLY) RECORD TABLESPACE STUBBORN PCTFREE, INITRANS 10 2 MAXTRANS 255 STORAGE (64 K INITIAL NEXT 1 M MINEXTENTS 1 MAXEXTENTS UNLIMITED 0 USER_TABLES FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT PCTINCREASE) NOPARALLEL;
CREATE INDEX MM_STAT_SCREEN_PLATFORM_IDX ON MM_STAT_SCREEN (PLATFORM) RECORD TABLESPACE STUBBORN PCTFREE, INITRANS 10 2 MAXTRANS 255 STORAGE (64 K INITIAL NEXT 1 M MINEXTENTS 1 MAXEXTENTS UNLIMITED 0 USER_TABLES FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT PCTINCREASE) NOPARALLEL;
CREATE A UNIQUE MM_STAT_SCREEN_UNIQUE ON MM_STAT_SCREEN INDEX (NO_EMIARTE, WINDING, CHANNEL, DATE_AUDIENCE, DISPLAY, EXTRACT, PLATFORM) RECORD TABLESPACE XENTETE PCTFREE, INITRANS 10 2 MAXTRANS 255 STORAGE (64 K INITIAL NEXT 1 M MINEXTENTS 1 MAXEXTENTS UNLIMITED 0 USER_TABLES FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT PCTINCREASE) NOPARALLEL;
CREATE OR REPLACE MM_STAT_SCREEN FOR MM_STAT_SCREEN PUBLIC SYNONYM;
GRANT DELETE, INSERT, SELECT, UPDATE ON MM_STAT_SCREEN TO GROUNDNUT.
GRANT SELECT ON MM_STAT_SCREEN TO APIOS_CONSULT;
When I make this request:
Select * from mm_stat_screen WHERE NO_EMIARTE = ' 052734-000' AND WINDING = "A" AND CHANNEL 2 AND DISPLAY = 'MOBILE' AND DATE_AUDIENCE = TO_DATE('07/10/2014','DD/MM/YYYY') =
AND EXTRACT = 1
AND PLATFORM = "TVGUIDE";
I can see explain plan, it uses the wrong index, it uses MM_STAT_SCREEN_PLATFORM_IDX instedad of MM_STAT_SCREEN_UNIQUE.
If I run
Select * from mm_stat_screen WHERE NO_EMIARTE = ' 052734-000' AND WINDING = "A" AND CHANNEL 2 AND DISPLAY = 'MOBILE' AND DATE_AUDIENCE = TO_DATE('07/10/2014','DD/MM/YYYY') =
AND EXTRACT = 1;
I use the clue MM_STAT_SCREEN_UNIQUE?
Concerning
OK, thank you very much Ajay.
I'll removes the previous to stay with one.
Good day.
Kind regards.
-
One of the secondary index is not complete
Hello
I had an entity having 18847 record. It contains a primary key and secondary keys several. Since the next release to check, we see it, all indexes are complete except ProductId. What should I do to fix this error?
Verification of data persist #gdlogs #test. TableWhProductStorageCard
Tree control to persist #gdlogs #test. TableWhProductStorageCard
BTree: Composition of the btree, types and number of nodes.
binCount = 149
binEntriesHistogram = [40-49%: 1; 80 to 89%: 1, 90-99%: 147]
binsByLevel = [level 1: count = 149]
deletedLNCount = 0
inCount = 3
insByLevel = [level 2: number = 2; level 3: count = 1]
lnCount = 18, 847
mainTreeMaxDepth = 3
BTree: Composition of the btree, types and number of nodes.
Verification of data persist #gdlogs #test. TableWhProductStorageCard #BatchNo
Tree control to persist #gdlogs #test. TableWhProductStorageCard #BatchNo
BTree: Composition of the btree, types and number of nodes.
binCount = 243
binEntriesHistogram = [% 40-49: 43; 50 to 59%: 121, 60-69%: 30; 70-79%: 23; 80 to 89%: 17; 90-99%: 9]
binsByLevel = [level 1: count = 243]
deletedLNCount = 0
inCount = 4
insByLevel = [level 2: number = 3; level 3: count = 1]
lnCount = 18, 847
mainTreeMaxDepth = 3
BTree: Composition of the btree, types and number of nodes.
This secondary index is correct. (the lnCount is the same as the primary index)
Verification of data persist #gdlogs #test. TableWhProductStorageCard #ProductId
Tree control to persist #gdlogs #test. TableWhProductStorageCard #ProductId
BTree: Composition of the btree, types and number of nodes.
binCount = 168
binEntriesHistogram = [% 40-49: 16; 50 to 59%: 47; 60 to 69%: 39; 70-79%: 26; 80 to 89%: 26; 90-99%: 14]
binsByLevel = [level 1: count = 168]
deletedLNCount = 0
inCount = 3
insByLevel = [level 2: number = 2; level 3: count = 1]
lnCount = 14: 731
mainTreeMaxDepth = 3
BTree: Composition of the btree, types and number of nodes.
This index is not complete. (lnCount is less than the primary index) Then when use this index to iterate through the lines, only the first record 14731 is returned.
Apparently, somehow your secondary index DB became not synchronized with your primary. Normally, this is caused by not using is not a transactional store (EntityStore.setTransactional). But whatever the cause, I will describe how to correct the situation by rebuilding the index.
(1) take your application offline so that no other operations occur.
(2) make a backup in case a problem occurs during this procedure.
(3) do not open the EntityStore yet.
(4) delete the database index that is out of sync (persist #gdlogs #test. TableWhProductStorageCard #ProductId) by calling the Environment.removeDatabase with this name.
(5) rebuild the index database simply by opening the EntityStore. It will take more time than usual, since the index will be rebuilt before the return of the EntityStore constructor.
(6) confirm that the index is rebuilt correctly.
(7) bring your online return request.
-mark
-
PCT_DIRECT_ACCESS of secondary indexes of the IOT
Facing a performance problem to DELETE statement due to ignorance of a secondary index on ITO by the optimizer.
Version: 11.1.0.7.0
We did the "update block references" for secondary indexes, here's what we tested.
At this point, we have updated the block reference and gathered stats.SQL> select owner,index_name,PCT_DIRECT_ACCESS from dba_indexes where index_name in ('XYZ1'); OWNER INDEX_NAME PCT_DIRECT_ACCESS ------------------------------ ------------------------------ ----------------- DLF5 XYZ1 91 DLF7 XYZ1 87 DLF4 XYZ1 90 DLF0 XYZ1 92 DLF3 XYZ1 85 DLF1 XYZ1 97 DLF6 XYZ1 93 DLF2 XYZ1 91 SQL> delete FROM DLF0.LOCATE D WHERE GUID = 'Iwfegjie2jgigqwwuenbqw' AND C_ID = 30918 AND ((S_ID < 8672) OR (S_ID <= 8672 AND DELETE_FLAG = 'Y')); 0 rows deleted. SQL> select PLAN_TABLE_OUTPUT from table(dbms_xplan.display_cursor(null,null,'RUNSTATS_LAST')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------ SQL_ID 7qxyur0npcpvh, child number 0 ------------------------------------- delete FROM DLF0.LOCATE D WHERE GUID = :"SYS_B_0" AND C_ID = :"SYS_B_1" AND ((S_ID < :"SYS_B_2") OR (S_ID <= :"SYS_B_3" AND DELETE_FLAG = :"SYS_B_4")) Plan hash value: 310264634 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------- | 0 | DELETE STATEMENT | | 1 | | 0 |00:00:00.01 | 1260 | | 1 | DELETE | LOCATE | 1 | | 0 |00:00:00.01 | 1260 | | 2 | CONCATENATION | | 1 | | 0 |00:00:00.01 | 1260 | |* 3 | INDEX RANGE SCAN| DLF0PK | 1 | 1 | 0 |00:00:00.01 | 630 | |* 4 | INDEX RANGE SCAN| DLF0PK | 1 | 1 | 0 |00:00:00.01 | 630 | ------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("C_ID"=:SYS_B_1 AND "GUID"=:SYS_B_0 AND "DELETE_FLAG"=:SYS_B_4 AND "S_ID"<=:SYS_B_3) filter(("GUID"=:SYS_B_0 AND "DELETE_FLAG"=:SYS_B_4)) 4 - access("C_ID"=:SYS_B_1 AND "GUID"=:SYS_B_0 AND "S_ID"<:SYS_B_2) filter(("GUID"=:SYS_B_0 AND (LNNVL("S_ID"<=:SYS_B_3) OR LNNVL("DELETE_FLAG"=:SYS_B_4)))) 28 rows selected. SQL> rollback; Rollback complete.
So it made no difference.SQL> select owner,index_name,PCT_DIRECT_ACCESS from dba_indexes where index_name in ('XYZ1'); OWNER INDEX_NAME PCT_DIRECT_ACCESS ------------------------------ ------------------------------ ----------------- DLF0 XYZ1 100 DLF1 XYZ1 100 DLF2 XYZ1 100 DLF3 XYZ1 100 DLF4 XYZ1 100 DLF5 XYZ1 100 DLF6 XYZ1 100 DLF7 XYZ1 100 8 rows selected. SQL> delete FROM DLF0.LOCATE D WHERE GUID = 'Iwfegjie2jgigqwwuenbqw' AND C_ID = 30918 AND ((S_ID < 8672) OR (S_ID <= 8672 AND DELETE_FLAG = 'Y')); 0 rows deleted. Elapsed: 00:00:00.03 SQL> select PLAN_TABLE_OUTPUT from table(dbms_xplan.display_cursor(null,null,'RUNSTATS_LAST')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------ SQL_ID fmrp501t70s66, child number 0 ------------------------------------- delete FROM DLF0.LOCATE D WHERE GUID = :"SYS_B_0" AND C_ID = :"SYS_B_1" AND ((S_ID < :"SYS_B_2") OR (S_ID <= :"SYS_B_3" AND DELETE_FLAG = :"SYS_B_4")) Plan hash value: 310264634 ------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------- | 0 | DELETE STATEMENT | | 1 | | 0 |00:00:00.02 | 1260 | | 1 | DELETE | LOCATE | 1 | | 0 |00:00:00.02 | 1260 | | 2 | CONCATENATION | | 1 | | 0 |00:00:00.02 | 1260 | |* 3 | INDEX RANGE SCAN| DLF0PK | 1 | 1 | 0 |00:00:00.01 | 630 | |* 4 | INDEX RANGE SCAN| DLF0PK | 1 | 1 | 0 |00:00:00.02 | 630 | ------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("C_ID"=:SYS_B_1 AND "GUID"=:SYS_B_0 AND "DELETE_FLAG"=:SYS_B_4 AND "S_ID"<=:SYS_B_3) filter(("GUID"=:SYS_B_0 AND "DELETE_FLAG"=:SYS_B_4)) 4 - access("C_ID"=:SYS_B_1 AND "GUID"=:SYS_B_0 AND "S_ID"<:SYS_B_2) filter(("GUID"=:SYS_B_0 AND (LNNVL("S_ID"<=:SYS_B_3) OR LNNVL("DELETE_FLAG"=:SYS_B_4)))) 28 rows selected. Elapsed: 00:00:00.01 SQL> rollback; Rollback complete. Elapsed: 00:00:00.00
With the help of suspicion is much better.
Could someone please help us to get the cause for the ignorance of a secondary by the optimizer index when secondary Index is to have 100% PCT_DIRECT_ACCESS.SQL> delete /*+ index(D XYZ1) */ FROM DLF0.LOCATE D WHERE GUID = 'Iwfegjie2jgigqwwuenbqw' AND C_ID = 30918 AND ((S_ID < 8672) OR (S_ID <= 8672 AND DELETE_FLAG = 'Y')); 0 rows deleted. Elapsed: 00:00:00.00 SQL> select PLAN_TABLE_OUTPUT from table(dbms_xplan.display_cursor(null,null,'RUNSTATS_LAST')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------ SQL_ID 0cf13mwxuksht, child number 0 ------------------------------------- delete /*+ index(D XYZ1) */ FROM DLF0.LOCATE D WHERE GUID = :"SYS_B_0" AND C_ID = :"SYS_B_1" AND ((S_ID < :"SYS_B_2") OR (S_ID <= :"SYS_B_3" AND DELETE_FLAG = :"SYS_B_4")) Plan hash value: 2359760181 ------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------ | 0 | DELETE STATEMENT | | 1 | | 0 |00:00:00.01 | 3 | | 1 | DELETE | LOCATE | 1 | | 0 |00:00:00.01 | 3 | |* 2 | INDEX RANGE SCAN| XYZ1 | 1 | 1 | 0 |00:00:00.01 | 3 | ------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("GUID"=:SYS_B_0) filter(("C_ID"=:SYS_B_1 AND ("S_ID"<:SYS_B_2 OR ("S_ID"<=:SYS_B_3 AND "DELETE_FLAG"=:SYS_B_4)))) 23 rows selected. Elapsed: 00:00:00.01 SQL> rollback; Rollback complete.
It seems to be processing problem with predicate of GOLD... but could not connect as I don't know many with ITO.
-Yasser
Published by: Yasu on 23 April 2012 16:39Its no different then any other optimizer choice, why did - it go one way rather than the other, its because he thought that less expensive.
If you really want to prove, suggest a with and without suspicion 10053 trace, read both and see the costing. the wonderful Mr. lewis has a note on this thing with the GSIS ignored with IOT, it seems that the work is already done for you
http://jonathanlewis.WordPress.com/2008/02/25/iots-and-10053/
-
Question on UniqueConstraintException and secondary indexes.
Hello
We use the BDB DPL package for loading and reading data.
We have created ONE_TO_MANY secondary Index on for example ID-> Account_NOs
During the loading of data, using for example. primaryIndex.put(id,account_nos); -UniqueConstraintException is thrown when there are duplicate account numbers existing id
But although UniqueConstraintException is thrown, the secondary key duplicate data are still load in BDB. I think that the data should not get charged if an Exception is thrown. Can I know if I am missing something here?
for example.
ID = 101-> accounts = 12345, 34567 - loading successfully of the key = 101
ID = 201-> accounts = 77788, 12345 - throw an Exception but data is still to take key = 201.Your store is transactional? If this isn't the case, it is what explains and I suggest you do your transactional shop. A non-transactional store with secondary clues ask trouble, and you are responsible for the manual correction of errors of integrity if the primary and the secondary to be out of sync.
See 'Special Considerations for the use of secondary databases with or without Transactions' here:
http://download.Oracle.com/docs/CD/E17277_02/HTML/Java/COM/Sleepycat/je/SecondaryDatabase.html-mark
-
Question about the use of secondary indexes in application
Hi, I'm a newbie to Berkeley DB. We use Berkeley DB for our application that has tables in the following structure.
Key to value1 value2
------- --------- ----------
1) E_ID-> E_Attr, A_ID - where A_ID is String for example. A_ID = A1; A2; A3
-where E_ID is unique but for example A1 or A2 may be part of multiple F_VITA say E1, E3, E5 etc.
So my question is that it is possible to create secondary indexes on individual items of Value2 (e.g., A1, A2 or A3)?
Another question, lets say we have two tables
Key to value1 value2
------- --------- ----------
2) X_ID-> X_Attr, E_ID
E_ID-> E_Attr, A_ID - where A_ID is String for example. A_ID = A1; A2; A3
In this case, can create us E_ID as a secondary Index but with primary Table-> E_Attr, A_ID E_ID?
While X_ID given, we can get the chronogram, E_ID-> E_Attr, table allocation A_ID?
Don't know if its possible.
Thanks for reading.(1) when talking about data & Index, I was referring to READ ONLY BDB with no. UPDATES where you download entire files allows for example on a weekly basis. In this case, I believe that the data will be stored directly in the tree. It will not be stored in the transaction as such logs. This hypothesis is correct?
# Storage I is nothing other than a transaction log. Read the white paper, that I mentioned.
(2) and about the Garbage Collection operation, I meant BDB 'Cache éviction' algorithms. Sorry I have not communicated before.
I use an LRU algorithm. What do you need exactly to know, that you can not get the doc?
-mark
-
putNoOverwrite taints a secondary index
Context: BDB v4.7.25, DPL via the Java API, enabled replication subsystem (so with the transactions, logging, etc..)
I encounter strange behavior, using putNoOverwrite on an existing entity with secondary keys.
One of the two secondary indexes declared in the entity gets broken.
Let me explain with an example case.
The entity:
@Entity (version = 0)
public class SomeEntity
{
@PrimaryKey
private int pk;
@SecondaryKey (= Relationship.MANY_TO_ONE, relatedEntity = AnotherEntity.class, onRelatedEntityDelete = DeleteAction.ABORT Chronicles)
private int fk;
@SecondaryKey (relate = Relationship.MANY_TO_ONE)
deprived of the String status = "UNKNOWN";
}
The first put or putNoOverwrite is perfect:
putNoOverwrite (pk = 1, fk = 10, State = "OK")
My entity is not in DB, can I get it back through the secondary database 'State' with the value 'OK' (method SecondaryIndex.subIndex).
Then the defective putNoOverwrite:
putNoOverwrite (pk = 1, fk = 10, State = "UNKNOWN")
This call should have no effect. In turn, my entity is still present in DB and when I recover via is PK, I get it intact.
But when I retrieve via the secondary index 'State' with the value 'OK' (method SecondaryIndex.subIndex), there is no match. The only present secondary key in the secondary index is 'UNKNOWN '.
I encounter this problem repeatedly.
Thanks for your helpHello. This bug has been fixed in the latest version of BDB (4.8.24.) The change log entry is 1 in general changes of access method:
http://www.Oracle.com/technology/documentation/Berkeley-DB/DB/programmer_reference/changelog_4_8.htmlYou will need to upgrade the BDB to solve this problem, because the fix has not been backported to version 4.7.
Ben Schmeckpeper
-
How to divide each unique number in a matrix by the number with an index in another matrix?
Hello
Basically, the calculation, I tried to do is called "dividing element by element". It is a transaction between two matrices with few passes and lines. The result matrix also has the same demension and each element is obtained by dividing the element with the same index in a matrix of the element with the index even in a different matrix. for examlpe,.
A = [2 4 6
3 9 6]
B = [2 2 3
3 3 2]
the result will be
C = [1, 2-2
1 3 3]
Is there an easy way to do another going out each element using the table to index?
Thank you very much
Hao Liu
Use the 2D tables instead of the matrix data type, then just use a simple primitive division. the operation will be done by item automatically.

(Generally you should always use table 2D instead of the special matrix data type. The matrix data type is most useful for linear algebra)
(Die, he must be very careful, for example, if you multiply two 2D tables, you get a multiplication of element by element, but if you do the same operation on two matrices, LabVIEW will substitute for a real matrix multiplication, which is not the same. For the division, it seems that the matrices are divided piece-by-piece, so it might work for you directly. You should just be aware that the matrices are often treated differently. "They are a very special type of data).
-
Indexing of a table with multiple indexes
Hi all
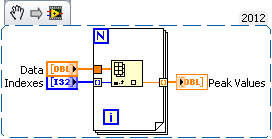
I just used the detector of Ridge VI on table 1 d with a threshold. I now have an array of index I need to round to use as a real index. My question is, with this index corresponding to the points picture, how, I take the peak values
To give a bit of context:
1. I have three time correlated signals. I filter them, normalize, then add them so that I can increase the signal-to-noise ratio.
2 pic DetectionVI gives me a table where are these pics
3. I want my end result
A. Signal1 [peak_indices]
B. Signal2 [peak_indices]
C.Signal3 [peak_indices]
Now I think about it in the way I have d code in MATLAB which is much easier, but I would like to do this in Labview and would be very happy to any idea.
Thank you
-Joe
As you said, once you have rounded tip to the nearest value locations you have an array of markings. From there on, it should be a simple matter of passing this table in a for loop that auto-index of the results that you went out to generate a table of peak values.
-
kindly tell how to use the unique value of a table with the index 0
kindly tell how to use the unique value of a table with the index 0
Hi
Yep, use Index Array as Gerd says. Also, using the context help (+ h) and looking through the array palette will help you get an understanding of what each VI does.
This is fundamental LabVIEW stuff, perhaps you'd be better spending some time going through the basics.
-CC
-
multiplying the elements of an array with their index
How can I multiply the elements of an array with their index values.
Thanks in advance.
Hi aksoy,.
Multiply the elements with their index:

-
Copy a table with its index of Oracle 12 to another instance oracle 12
Hello
I m using 64 bit Win8
I have a huge table T1 (about 200 million) on user storage space and its index is on different tablespaces on DB1
I built an other empty DB2 with the same names of storage spaces. I d like copy the table T1 of DB1 with all its indexes in DB2 so that the table will in User tablespace and the index go to their corresponding storage spaces.
Is it possible to do?
Currently I T1 to export into a CSV file and re - import to DB2 and build all indexes manually.
Concerning
Hussien Sharaf
1. What is the exact syntax to export and import a table with its index?
You will need to use the "Table". An export of table mode is specified by the parameter TABLES. Mode table, only a specified set of tables, partitions, and their dependent objects are unloaded. See: https://docs.oracle.com/cloud/latest/db121/SUTIL/dp_export.htm#i1007514
2 How can I import the indexes in one tablespace other than the table itself?
You can only export the table first without the index by specifying the EXCLUSION clause in order to exclude from the index (see: https://docs.oracle.com/cloud/latest/db121/SUTIL/dp_export.htm#i1007829) and then manually create the index and specify the different tablespace when you create.
-
Parallel insert with noappend hint
Hello
I have a question about parallel to insert with the noappend indicator. Oracle Documentation says that:
Append mode is the default for a parallel insert operation: data are always inserted in a new block, which is allocated to the table. Therefore, the
APPENDis optional. You must use Add method to increase the speed ofINSERToperations, but not when the use of space must be optimized. You can useNOAPPENDto void append mode.When I delete (all) and insert (parallel use noappend) and I see the number of blocks used by my table always increases. The blocks must not be reused due to remove it before insert?
Version; Oracle Database 11g Enterprise Edition Release 11.2.0.4.0
Here is the script I used:
drop table all_objs;
create the table all_objs in select * from object where rownum < 10000;
Start
DBMS_STATS.gather_table_stats (User, 'ALL_OBJS');
end;
Select the blocks of all_tables where table_name = 'ALL_OBJS ';
ALTER session enable parallel dml.
Start
I'm in 1.5
loop
delete from all_objs;
Insert / * + NOAPPEND PARALLEL (8 O) * /.
in all_objs O
Select * from object where rownum < 10000;
end loop;
end;
commit;
Start
DBMS_STATS.gather_table_stats (User, 'ALL_OBJS');
end;
Select blocks of all_tables
where table_name = 'ALL_OBJS ';
Output:
Deleted table.
Table created.
PL/SQL procedure successfully completed.
BLOCKS
----------
142
1 selected line.
Modified session.
PL/SQL procedure successfully completed.
Validation complete.
PL/SQL procedure successfully completed.
BLOCKS
----------
634
1 selected line.
Why block increase of 142 to 634 even with the noappend trick?
Thank you.
Well, looks like the expected result:
Repeated insertions PARALLELS - a lot of direct path writes, table size increases as the lines are added above the HWM, final size after ten iterations = 10 x original size
NOAPPEND PARALLEL repeated inserts - no direct path did not write, size of the table increases do not significantly, lines inserted under the HWM
The NOAPPEND PARALLEL insert clearly is re-use of space released by the deletion. However, I wonder why there is an overload of 3,000 blocks? It would be interesting to see how the overhead varies according to the degree of parallelism.
-
Insert / * + parallel * / performance index
Insert / * + parallel * / performance index
Hello
I performed the procedure below
CREATE OR REPLACE PROCEDURE bulk_collect
IS
SID TYPE TABLE IS NUMBER;
Screated_date TYPE IS an ARRAY OF DATE;
Slookup_id TYPE TABLE IS NUMBER;
Surlabasedesdonneesdufabricantduballast ARRAY TYPE IS VARCHAR2 (50);
l_sid sid;
l_screated_date screated_date;
l_slookup_id slookup_id;
l_sdata surlabasedesdonneesdufabricantduballast;
l_start NUMBER;
BEGIN
l_start: = DBMS_UTILITY.get_time;
SELECT id, created_date, lookup_id, data
BULK COLLECT INTO l_sid, l_screated_date, l_slookup_id, l_sdata
FROM big_table;
-dbms_output.put_line (' after collection in bulk: ' | systimestamp);
FORALL indx IN l_sid. FIRST... l_sid. LAST
INSERT / * + parallel (big_table2, 2) * / INTO big_table2 values (l_sid (indx), l_screated_date (indx), l_slookup_id (indx), l_sdata (indx));
-dbms_output.put_line (' after FORALL: ' | systimestamp);
COMMIT;
Dbms_output.put_line ('Total elapsed:-' |) (DBMS_UTILITY.get_time - l_start) | "hsecs");
END;
/
DISPLAY ERRORS;
I want to confirm if the query is running in parallel. I checked the tables below to confirm if the insert statement is run in parallel, but none of them returns all the rows.
Select * from V$ PX_SESSION where sid = 768
Select * from V$ PX_SESSTAT
Select * from V$ PX_PROCESS
Select * from V$ PX_PROCESS_SYSSTAT
Select * from V$ PQ_SESSTAT
Please may I know how to find out the parallel execution of / * + parallel (table_name, 2) * / reference
Thank you
I'd go for the SQL insert/selection option as suggested.
Bulk insert is the APPEND_VALUES of 11r2 trick that will lead to a direct path load. Parallel is to directly load path, but if you are bench marking may include this as an additional test.
Maybe you are looking for
-
Is there a way to tell the total number of songs that are in libraries?
Is it possible to say how many songs total is in its library?
-
TCP/IP connection with the external device
Hello I need establish a TCP/IP connection to my hardware device that ip (10.102.20.90) and the port no 9012 by static ip setting. Since I'm new to this Protocol, I am a little worried about how to make the communication between my pc hardware. Here
-
When sp2 for vista will be available?
-
I have windows XP, .NET 4.0 (4.5)?, service packs1, 2, 3, 4.0 and 4.5. I have a HP Pavilion a620n. I do not know is that 4 or if I need and IE8. I tried to remove several programs in Add/Remove Programs, and it said an ending with .msi file that is "
-
can not find my hp laptop support web site
Product name: HP Pavilion PC Sleekbook 15 Serial number: 5CD2419PSJ Product number: C6K58EA #ABV im not able to find my product on the hp support web site. I need the network and bluetooth drivers for my laptop. It is not bad possiable with the suppo