Indexing of a table with multiple indexes
Hi all
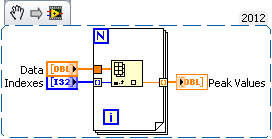
I just used the detector of Ridge VI on table 1 d with a threshold. I now have an array of index I need to round to use as a real index. My question is, with this index corresponding to the points picture, how, I take the peak values
To give a bit of context:
1. I have three time correlated signals. I filter them, normalize, then add them so that I can increase the signal-to-noise ratio.
2 pic DetectionVI gives me a table where are these pics
3. I want my end result
A. Signal1 [peak_indices]
B. Signal2 [peak_indices]
C.Signal3 [peak_indices]
Now I think about it in the way I have d code in MATLAB which is much easier, but I would like to do this in Labview and would be very happy to any idea.
Thank you
-Joe
As you said, once you have rounded tip to the nearest value locations you have an array of markings. From there on, it should be a simple matter of passing this table in a for loop that auto-index of the results that you went out to generate a table of peak values.
Tags: NI Software
Similar Questions
-
Gears - error when you try to insert values into a table with multiple columns
Hello
I started playing with the gears and SQlLite today and I get an error when I try to insert values into a table with multiple columns.
I have:
var db = google.gears.factory.create('beta.database'); db.open('developerSet'); db.execute('create table if not exists Developers (DeveloperName text, DeveloperAge int)'); var devName = "Davy" var devAge = 32; try { db.execute('insert into Developers values (?, ?)', [devName, devAge]); alert('success'); } catch (e) { alert(e); }I get the error:
net.rim.device.api.database.DatabaseException; insert into developers values (?,?): SQL logic error or missing database.
I use this reference: http://code.google.com/apis/gears/api_database.html
Everything works if I have only one field as:
var db = google.gears.factory.create('beta.database'); db.open('developerSet'); db.execute('create table if not exists Developers (DeveloperName text)'); var devName = "Davy" var devAge = 32; try { db.execute('insert into Developers values (?)', [devName]); alert('success'); } catch (e) { alert(e); }I use the plug-in Visual Studio 2.0 for 2008 that are running Windows XP SP and Simulator 2.13.0.56
Thank you
Davy
Yes, a SQLite database will persist between battery pulls. The database is registered either to internal MEM or removable media (not the device memory), depending on which is available on your device.
In general, its not considered a best practice to remove your table as soon as it is empty and re - create it again when you want to add data. This adds extra overhead fresh for the final, delete and insert first for a given table. Instead, define and finalize your drawing before you create your table. Once created, review the static schema.
That being said, for development purposes, it may be easier to provide an easy way to drop your tables while you develop your schema.
See you soon,.
Adam
-
Declare a type of table with multiple columns
I have a table with a column of type, and I want to create one with two columns.
My type is:
create or replace type "NUMBER_TABLE" in the table of the number;
And I use it in function:
FUNCTION GetValues()
return NUMBER_TABLE
as
results NUMBER_TABLE: = NUMBER_TABLE();
Start
Select OrderId bulk collect in: results from (select * from tbl_orders);
-Other code...
end;
I want select it be like this:
Select OrderId, OrderAddress bulk collect into: results from (select * from tbl_orders);
How to do this?Is that what you are looking for:
CREATE OR REPLACE TYPE two_col_rec AS OBJECT (empno NUMBER, ename VARCHAR2(10)) / CREATE OR REPLACE TYPE two_col_table AS TABLE OF two_col; / CREATE OR REPLACE FUNCTION GetValues RETURN two_col_table AS results two_col_table := two_col_table(); BEGIN SELECT two_col(empno, ename) BULK COLLECT INTO results FROM emp; -- RETURN results; END; / show errors -
can bind us a single external table with multiple files in OWB 11 g?
Hello
I wanted to ask if it is possible to link an external table with several source files in same or different places? Or an external table must be bound to a single source file and one place.
Thanks in advance,
Ann.
Published by: Ann on October 8, 2010 09:38Hello Ann,.
Can you please help me by telling me the steps to achieve this.
Right-click on the external table in the project tree, from the menu choose Configure.
then open right clock the node data files dialog Configuration properties and choose from the menu - Create
you will get a new record for the file - name of file data propertyAlso the link of the OWB user guide
http://download.Oracle.com/docs/CD/B28359_01/OWB.111/b31278/ref_def_flatfiles.htm#i1126304Kind regards
Oleg -
Table with multiple partitions
Hello
I've got a big look up postcodes dimension table:
create table zip (from_zip number(5), to_zip number(5));
It's almost 1 billion record table and the content of the table is:
from_zip: it has all postal codes in the United States, about 40,000 nationwide).
to_zip: it lists all zip codes to 400 miles of the zip code in the from_zip column.
I need to run a query such as:
select a.* from TRX_TABLE a, ZIP where a.ZIP = ZIP.TO_ZIP where from_zip = 10001;
I only provide a zip code in where clause above. Because the ZipCode table is so great, I thought that the best way to partition the table zip by list (from_zip) so that a single partition will contain a zip code of from_zip. This would create about 40 000 partitions since there are 40 000 postal codes in the United States. And since I only provide a zip code in the where clause, it would only be to access a zip. Is 40 000 partitions too? Exceeds the appropriate design? Would it be useful to have a local index on to_zip? the TRX_TABLE has about 10 million documents.
Y at - it an easy way to create a partition for each zip or do I have to list each of the zip codes in the partitions?
Help, please.
41004 projection in accordance with (the United States) is a coordinate system where the coordinates are projected on a plan, coordinates x, Y in meters. Sorry I didn't say that. The sdo_dim_array must therefore:
MDSYS. () SDO_DIM_ARRAY
MDSYS. SDO_DIM_ELEMENT ('X', - 20000000.0, 20000000.0, 1),
MDSYS. SDO_DIM_ELEMENT('Y',-20000000.0, 20000000.0, 1))
These ranges of X and there are enough to cover almost everyone and are what we use for in my work projected coordinate systems. A tolerance of 1 meter (a little more than a yard) seems fine for your application. 50 even would be OK for you.
Create the actual error of your index finger is hidden in the Middle "ORA-13375: the layer is of type [2002] while inserted geometry has type [2001]"-J' made a mistake and stuck in the bad example for the spatial index. "" I'm sorry. A few points of index
CREATE INDEX xxx_SPIND ON xxx (COORDINATES) INDEXTYPE IS MDSYS. SPATIAL_INDEX PARAMETERS ('layer_gtype =POINT');
To convert the long/lat 41004 use:
sdo_cs. Transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (v_long, v_lat, NULL), NULL, NUll), 41004)
To use SDO_WITHIN_DISTANCE to 41004, you give a unit type or give the distance in meters. 1 mile = 1609.344 Mr. (we went metric in the 1970s here in Australia, so I'm comfortable in both).
Here is an example that I did to make sure I had not missed anything else.
create table t_point (name varchar2 (20) null, mdsys uncoordinated.) SDO_GEOMETRY);
insert into (TABLE_NAME, COLUMN_NAME, DIMINFO, SRID) user_sdo_geom_metadata
values ('T_POINT', 'Contact INFORMATION', MDSYS. SDO_DIM_ARRAY (MDSYS. SDO_DIM_ELEMENT ('X', - 20000000.0, 20000000.0, 1),
MDSYS. (SDO_DIM_ELEMENT('Y',-20000000.0, 20000000.0, 1)), 41004);
insert into t_point values ('HOME', sdo_cs.transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (-96,23, NULL), NULL, NULL), 41004));
insert into t_point values ('1', sdo_cs.transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (-96,24, NULL), NULL, NULL), 41004));
insert into t_point values ('Hemisphere.2', sdo_cs.transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (-96,25, NULL), NULL, NULL), 41004));
insert into t_point values ('NORTH3', sdo_cs.transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (-96,27, NULL), NULL, NULL), 41004));
create index t_point_spind on t_point (coordinates) INDEXTYPE IS MDSYS. SPATIAL_INDEX PARAMETERS ('layer_gtype = POINT');
-Request less than 100 miles - search 2 points
Select * from t_point
where sdo_within_distance (coordinates, sdo_cs.transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (-96.1,22.9, NULL), NULL, NULL), 41004))
'unit = mile = 100 distance') = 'TRUE ';
- Or giving counters:
Select * from t_point
where sdo_within_distance (coordinates, sdo_cs.transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (-96.1,22.9, NULL), NULL, NULL), 41004))
'distance =' | TO_CHAR (100 * 1609.344, '99999999')) = "TRUE";
-Interview to 200 miles
Select * from t_point
where sdo_within_distance (coordinates, sdo_cs.transform (SDO_GEOMETRY (2001, 8307, SDO_POINT (-96.1,22.9, NULL), NULL, NULL), 41004))
'unit = distance = 200 mile') = 'TRUE ';
Kind regards
David
-
Select all / all - check the boxes in a table with multiple lines
Adobe Livecycle Designer ES2
Hello
I have several boxes that I need to do a check of all the option for. I work but this is inneficient and much time given the number of times it needs to be done. I need like 5 of these per page, 20 lines per page, 10 pages per document and about 7 total documents: S
During the click event of the box has the following code:
If (this.rawValue is '1')
{
Form1.facility.Table6.row2.Subform7.pharmacy1.RawValue = '1';
Form1.facility.Table6.Row3.Subform7.pharmacy2.RawValue = '1';
<>...
}
on the other
{
Form1.facility.Table6.Row2.Subform7.pharmacy1.rawValue = '0';
Form1.facility.Table6.Row3.Subform7.pharmacy2.RawValue = '0';
<>...
}The name 'subform7' does not change, table 6 made but I can always rename the rest of them, does not change form1, installing Exchange (and not only facility1, installation2... etc, has no guaranteed).With the help of this hierarchy is there a better way to check these? Here's what I was playing around with, but it did not work:for (var in form1.facility.Table6 myRows){Renamed all to be 'pharmacy '.myRows.Subform7.pharmacy.rawValue = '1';}If anyone can shed some light it would be great.You use formCalc and lines should be renamed so that LCD shows them as Row [0], row [1], row [3]... etc. in the hierarchy tab
I'm a little confused by the subform residing on a table row - although it is possible to do. So, I guess it's okay. A good way to ensure that you have the good SOM for the checkbox control is to CTRL-click one of these check boxes while your cursor is in the Scrpt Editor.
Good luck!
-
Unique table with several columns or several tables split?
What is the best.
A table with multiple columns inside or divided into several tables. Why?
How will the performance in the two scenarios?Hello
user13024762 wrote:
I have a table EMP that has column EMP_ID, EMP_NAME MGR_ID, MGR_NAME, SALARY, EXP_IN_MNTHS, EXP_IN_YRS... etc with multiple columnsI have the following tables
EMP-> EMP_ID, EMP_NAMEEach row in the table emp thie represents a separate employee. I guess other columns in the emp table might be birth_date, social_security_number and status (by example, 'Active', 'Leave', 'complete'). Here's what an employee has (at least) one of. If there is a one-to-many relationship between an employee and an attribute, then you probably want another table for this attribute.
BISHOP-> EMP_ID, MGR_ID, MGR_NAME
There is a one-to-many relationship between employees and managers? In other words, an employee may have 2 or more managers? If Yes, then you need another table.
If there is only a one-to-one relationship between employees and managers (in other words, if an employee is never more than 1 Manager) so why don't you just have a mgr_id column in the emp table?
Managers are also used for? (This is often the case, as in scott.emp and hr.employees.) If so, do not store their names in the EME and tables of mgr. Store name (and date of birth and other information) in the table emp only and, if you need a table of Bishop, just the emp_id and mgr_id column.SAL-> EMP_ID, SALARY
There is a one-to-many relationship between the employees and wages? In other words, an employee may have 2 or more treatments? If so, how will you use the values? Is a special treatments in some way, as it will be used more often than others? (In other words, you may have a current and past wages salary, but the last wages are rarely used.)
If you never have more than 1 salary for a given employee, why not just have a sal column in the emp table?EXP-> EMP_ID, EXP_IN_MNTHS, EXP_IN_YRS
There is a one-to-many relationship between the employees and what whether you store in this table?
etc. with more tables
What is the best based on
(1) performance and data recovery
(2) ease of use
(3) maintainabilityA one-to-many relationship requires an additional table. If an employee can have up to 3 managers, don't have mgr1, mgr2 and mgr3 columns in the emp table. Use a separate table, with up to 3 lines for the same employee, instead.
For 1-1 relationships, it is usually best to not have separate tables. -
How to index a table on multiple sites?
Hello
How to index a table on multiple sites?
I searched this issue and was not able to find the answer. I understand that it can be done with loops, but I don't know how.
I use the detector of crete vi for frequency domain data collected a VNA (s2p) file. The products contain a table of amplitudes and a table of locations. The problem is that the locations refer to the index of table of amplitude, which is not the same as the frequency. My idea is that I can use this output of the places table to index the frequency to the detected peak frequencies table and then draw these, as well as some analysis data and manipulation on them. Currently, I can do this only by consulting table on the front panel.
The entrance to the peak detector is currently a table 1 d of the scale (what is the problem?).
I also looked at the supply frequency & estimate VI, but this VI seems only exit of scalar data for the largest peak, not exactly what I'm looking for.
Thanks for your help.
You have a second table for the tested frequency? If so, then you are right that you just need to index this table with the indexes by the Ridge detector. Use a loop for. Automatic index to the index, use index in array to get the value of the frequency and autoindex on frequencies.

-
kindly tell how to use the unique value of a table with the index 0
kindly tell how to use the unique value of a table with the index 0
Hi
Yep, use Index Array as Gerd says. Also, using the context help (+ h) and looking through the array palette will help you get an understanding of what each VI does.
This is fundamental LabVIEW stuff, perhaps you'd be better spending some time going through the basics.
-CC
-
Hello
I have a loop 'for' which can take different number of iterations according to the number of measures that the user wants to do.
Inside this loop, I'm auto-indexation four different 1 d arrays. This means that the size of the tables will be different in the different phases of the execution of the program (the size will equal the number of measures).
My question is: the auto-indexation of the tables with different sizes will affect the performance of the program? I think it slows down my Vi...
Thank you very much.
My first thought is that the compiler to the LabVIEW actually removes the Matlab node because the outputs are not used. Once you son upward, LabVIEW must then call Matlab and wait for it to run. I know from experience, the call of Matlab to run the script is SLOW. I also recommend to do the math in native LabVIEW.
-
Copy a table with its index of Oracle 12 to another instance oracle 12
Hello
I m using 64 bit Win8
I have a huge table T1 (about 200 million) on user storage space and its index is on different tablespaces on DB1
I built an other empty DB2 with the same names of storage spaces. I d like copy the table T1 of DB1 with all its indexes in DB2 so that the table will in User tablespace and the index go to their corresponding storage spaces.
Is it possible to do?
Currently I T1 to export into a CSV file and re - import to DB2 and build all indexes manually.
Concerning
Hussien Sharaf
1. What is the exact syntax to export and import a table with its index?
You will need to use the "Table". An export of table mode is specified by the parameter TABLES. Mode table, only a specified set of tables, partitions, and their dependent objects are unloaded. See: https://docs.oracle.com/cloud/latest/db121/SUTIL/dp_export.htm#i1007514
2 How can I import the indexes in one tablespace other than the table itself?
You can only export the table first without the index by specifying the EXCLUSION clause in order to exclude from the index (see: https://docs.oracle.com/cloud/latest/db121/SUTIL/dp_export.htm#i1007829) and then manually create the index and specify the different tablespace when you create.
-
bug using dbms_redefinition on table with the altered text index?
I think I can found a bug when you use DBMS_REDEFINITION on a table with a text index that has been modified using ALTER INDEX index-name REBUILD PARAMETERS (REPLACE...). It seems that DBMS_REDEFINITION does not recognize the syntax with REPLACE and redefining fails. However, if I remove the text index and re-create it with all the parameters set during the initial creation and no ALTER INDEX command, then redo the redefinition, it works correctly. I have provided below a script that reproduces the problem, then use workaround mentioned. I have provided a copy of the script and executing the script separately, so that it can be copied and pasted to reproduce the problem. It is a simplification of a problem which has emerged over the diagnosis of a larger problem presented by someone on another forum, where the objective was to perform a loop on a group of tables that meet certain criteria and change some columns varchar2, nvarchar2 columns of these tables, where there are indexes in full text on the other columns in the tables and indexes have been changed using the syntax above. This seems to be a bug or am I missing something or is at - it an easier solution for the redefinition?
-version:
-run the script:SCOTT@orcl_11gR2> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production PL/SQL Release 11.2.0.1.0 - Production CORE 11.2.0.1.0 Production TNS for 64-bit Windows: Version 11.2.0.1.0 - Production NLSRTL Version 11.2.0.1.0 - Production 5 rows selected. SCOTT@orcl_11gR2>
-script:SCOTT@orcl_11gR2> -- table, data, altered text index: SCOTT@orcl_11gR2> CREATE TABLE t_test 2 (col1 NUMBER PRIMARY KEY, 3 col2 VARCHAR2 (10), 4 col3 CLOB) 5 / Table created. SCOTT@orcl_11gR2> INSERT INTO t_test VALUES (1, 'A', 'test data') 2 / 1 row created. SCOTT@orcl_11gR2> CREATE INDEX i1 ON t_test (col3) INDEXTYPE IS CTXSYS.CONTEXT 2 / Index created. SCOTT@orcl_11gR2> ALTER INDEX i1 REBUILD PARAMETERS ('REPLACE SYNC (ON COMMIT)') 2 / Index altered. SCOTT@orcl_11gR2> SELECT * FROM t_test WHERE CONTAINS (col3, 'test data') > 0 2 / COL1 COL2 COL3 ---------- ---------- ---------- 1 A test data 1 row selected. SCOTT@orcl_11gR2> -- redefinition that fails: SCOTT@orcl_11gR2> CREATE TABLE t_test_interim 2 (col1 NUMBER, 3 col2 NVARCHAR2 (10), 4 col3 CLOB) 5 / Table created. SCOTT@orcl_11gR2> DECLARE 2 v_num_errors NUMBER; 3 BEGIN 4 DBMS_REDEFINITION.CAN_REDEF_TABLE 5 (USER, 'T_TEST', DBMS_REDEFINITION.CONS_USE_PK); 6 DBMS_REDEFINITION.START_REDEF_TABLE 7 (USER, 'T_TEST', 'T_TEST_INTERIM', 8 'COL1 COL1,TO_NCHAR(COL2) COL2,COL3 COL3', 9 DBMS_REDEFINITION.CONS_USE_PK); 10 DBMS_REDEFINITION.SYNC_INTERIM_TABLE 11 (USER, 'T_TEST', 'T_TEST_INTERIM'); 12 DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS 13 (USER, 'T_TEST', 'T_TEST_INTERIM', 14 DBMS_REDEFINITION.CONS_ORIG_PARAMS, 15 TRUE, TRUE, TRUE, FALSE, v_num_errors, TRUE); 16 DBMS_REDEFINITION.FINISH_REDEF_TABLE 17 (USER, 'T_TEST', 'T_TEST_INTERIM'); 18 END; 19 / DECLARE * ERROR at line 1: ORA-29855: error occurred in the execution of ODCIINDEXCREATE routine ORA-20000: Oracle Text error: DRG-11000: invalid keyword REPLACE ORA-06512: at "SYS.DBMS_REDEFINITION", line 1364 ORA-06512: at "SYS.DBMS_REDEFINITION", line 2025 ORA-06512: at line 12 SCOTT@orcl_11gR2> -- clean up the mess: SCOTT@orcl_11gR2> DROP MATERIALIZED VIEW t_test_interim 2 / Materialized view dropped. SCOTT@orcl_11gR2> DROP TABLE t_test_interim CASCADE CONSTRAINTS 2 / Table dropped. SCOTT@orcl_11gR2> BEGIN 2 DBMS_REDEFINITION.ABORT_REDEF_TABLE 3 (USER, 'T_TEST', 'T_TEST_INTERIM'); 4 END; 5 / PL/SQL procedure successfully completed. SCOTT@orcl_11gR2> -- drop and recreate index with all parameters without altering: SCOTT@orcl_11gR2> DROP INDEX I1 2 / Index dropped. SCOTT@orcl_11gR2> CREATE INDEX I1 ON T_TEST (COL3) INDEXTYPE IS CTXSYS.CONTEXT 2 PARAMETERS ('SYNC (ON COMMIT)') 3 / Index created. SCOTT@orcl_11gR2> -- redo redefinition: SCOTT@orcl_11gR2> CREATE TABLE t_test_interim 2 (col1 NUMBER, 3 col2 NVARCHAR2 (10), 4 col3 CLOB) 5 / Table created. SCOTT@orcl_11gR2> DECLARE 2 v_num_errors NUMBER; 3 BEGIN 4 DBMS_REDEFINITION.CAN_REDEF_TABLE 5 (USER, 'T_TEST', DBMS_REDEFINITION.CONS_USE_PK); 6 DBMS_REDEFINITION.START_REDEF_TABLE 7 (USER, 'T_TEST', 'T_TEST_INTERIM', 8 'COL1 COL1,TO_NCHAR(COL2) COL2,COL3 COL3', 9 DBMS_REDEFINITION.CONS_USE_PK); 10 DBMS_REDEFINITION.SYNC_INTERIM_TABLE 11 (USER, 'T_TEST', 'T_TEST_INTERIM'); 12 DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS 13 (USER, 'T_TEST', 'T_TEST_INTERIM', 14 DBMS_REDEFINITION.CONS_ORIG_PARAMS, 15 TRUE, TRUE, TRUE, FALSE, v_num_errors, TRUE); 16 DBMS_REDEFINITION.FINISH_REDEF_TABLE 17 (USER, 'T_TEST', 'T_TEST_INTERIM'); 18 END; 19 / PL/SQL procedure successfully completed. SCOTT@orcl_11gR2> DROP TABLE t_test_interim CASCADE CONSTRAINTS 2 / Table dropped. SCOTT@orcl_11gR2> -- results: SCOTT@orcl_11gR2> DESC t_test Name Null? Type ----------------------------------------- -------- ---------------------------- COL1 NUMBER COL2 NVARCHAR2(10) COL3 CLOB SCOTT@orcl_11gR2> COLUMN col3 FORMAT A10 SCOTT@orcl_11gR2> SELECT * FROM t_test WHERE CONTAINS (col3, 'test data') > 0 2 / COL1 COL2 COL3 ---------- ---------- ---------- 1 A test data 1 row selected. SCOTT@orcl_11gR2> -- clean-up: SCOTT@orcl_11gR2> DROP TABLE t_test 2 / Table dropped. SCOTT@orcl_11gR2>-- table, data, altered text index: CREATE TABLE t_test (col1 NUMBER PRIMARY KEY, col2 VARCHAR2 (10), col3 CLOB) / INSERT INTO t_test VALUES (1, 'A', 'test data') / CREATE INDEX i1 ON t_test (col3) INDEXTYPE IS CTXSYS.CONTEXT / ALTER INDEX i1 REBUILD PARAMETERS ('REPLACE SYNC (ON COMMIT)') / SELECT * FROM t_test WHERE CONTAINS (col3, 'test data') > 0 / -- redefinition that fails: CREATE TABLE t_test_interim (col1 NUMBER, col2 NVARCHAR2 (10), col3 CLOB) / DECLARE v_num_errors NUMBER; BEGIN DBMS_REDEFINITION.CAN_REDEF_TABLE (USER, 'T_TEST', DBMS_REDEFINITION.CONS_USE_PK); DBMS_REDEFINITION.START_REDEF_TABLE (USER, 'T_TEST', 'T_TEST_INTERIM', 'COL1 COL1,TO_NCHAR(COL2) COL2,COL3 COL3', DBMS_REDEFINITION.CONS_USE_PK); DBMS_REDEFINITION.SYNC_INTERIM_TABLE (USER, 'T_TEST', 'T_TEST_INTERIM'); DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS (USER, 'T_TEST', 'T_TEST_INTERIM', DBMS_REDEFINITION.CONS_ORIG_PARAMS, TRUE, TRUE, TRUE, FALSE, v_num_errors, TRUE); DBMS_REDEFINITION.FINISH_REDEF_TABLE (USER, 'T_TEST', 'T_TEST_INTERIM'); END; / -- clean up the mess: DROP MATERIALIZED VIEW t_test_interim / DROP TABLE t_test_interim CASCADE CONSTRAINTS / BEGIN DBMS_REDEFINITION.ABORT_REDEF_TABLE (USER, 'T_TEST', 'T_TEST_INTERIM'); END; / -- drop and recreate index with all parameters without altering: DROP INDEX I1 / CREATE INDEX I1 ON T_TEST (COL3) INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS ('SYNC (ON COMMIT)') / -- redo redefinition: CREATE TABLE t_test_interim (col1 NUMBER, col2 NVARCHAR2 (10), col3 CLOB) / DECLARE v_num_errors NUMBER; BEGIN DBMS_REDEFINITION.CAN_REDEF_TABLE (USER, 'T_TEST', DBMS_REDEFINITION.CONS_USE_PK); DBMS_REDEFINITION.START_REDEF_TABLE (USER, 'T_TEST', 'T_TEST_INTERIM', 'COL1 COL1,TO_NCHAR(COL2) COL2,COL3 COL3', DBMS_REDEFINITION.CONS_USE_PK); DBMS_REDEFINITION.SYNC_INTERIM_TABLE (USER, 'T_TEST', 'T_TEST_INTERIM'); DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS (USER, 'T_TEST', 'T_TEST_INTERIM', DBMS_REDEFINITION.CONS_ORIG_PARAMS, TRUE, TRUE, TRUE, FALSE, v_num_errors, TRUE); DBMS_REDEFINITION.FINISH_REDEF_TABLE (USER, 'T_TEST', 'T_TEST_INTERIM'); END; / DROP TABLE t_test_interim CASCADE CONSTRAINTS / -- results: DESC t_test COLUMN col3 FORMAT A10 SELECT * FROM t_test WHERE CONTAINS (col3, 'test data') > 0 / -- clean-up: DROP TABLE t_test /No real workaround DBMS_REDEFINITION uses function DBMS_METADATA. GET_DDL() and a string of invalid parameter is returned due to known bugs when you use the ALTER INDEX REBUILD with parameter REPLACE; try to avoid changing the index with REPLACE if you export or use DBMS_REDEFINITION for this table/index.
Note to change the text index metadata, to change the existing class preference, you can use the REPLACE METADATA, IE
ALTER INDEX i1 REBUILD PARAMETERS ("replace metadata sync (on commit)" ");
Will not rebuild the index so that your DOF is to rebuild the index
ALTER INDEX i1 REBUILD PARAMETERS ('REPLACE SYNC (ON COMMIT)")
-
Collections [PL/SQL] table with a unique index
Hello
Is it possible to create a table with a unique index collection?
example:
declare
type tabletype is the table of non-null number IN directory INDEXES;
tabletype_nummer tabletype;
Start
tabletype_nummer (1): = 1;
tabletype_nummer (2): = 2;
tabletype_nummer (3): = 2;
end;
2nd and 3rd index have the same value.
so he could not fill the index 3.
Thank you.
Ludo
Published by: Ludock on December 10, 2009 11:36
The unique index should be the value.Yes, he is not required to start the index within the collection of 1... regardless of the number...
Here put your index to the collection and the value of the collection as even... so you can launch it from 12 to...
Him even when modified a bitDECLARE type tabletype IS TABLE OF NUMBER NOT NULL INDEX BY BINARY_INTEGER; tabletype_nummer tabletype; v_num NUMBER; v_num1 NUMBER; BEGIN v_num := 12; tabletype_nummer(v_num) := v_num; v_num := 2; tabletype_nummer(v_num) := v_num; v_num := 2; tabletype_nummer(v_num) := v_num; v_num :=5; tabletype_nummer(v_num) := v_num; v_num1 :=tabletype_nummer.First; WHILE v_num1 IS NOT NULL LOOP dbms_output.put_line(v_num1); v_num1 := tabletype_nummer.Next(v_num1); END LOOP; END;I assigned collection it beginning with 12 and next 2 I assigned twice and 5 next time... So now, if you check the o/p, you will get 2,5,12 which are distinct values, you want to store in the collection.
Ravi Kumar
-
date max with multiple joins of tables
Looking for expert advice on the use of max (date) with multiple joins of tables. Several people have tried (and failed) - HELP Please!
The goal is to retrieve the most current joined line of NBRJOBS_EFFECTIVE_DATE for each unique NBRJOBS_PIDM. There are several lines by PIDM with various EFFECTIVE_DATEs. The following SQL returns about 1/3 of the files and there are also some multiples.
The keys are PIDM, POSN and suff
Select NBRJOBS. NBRJOBS.*,
NBRBJOB. NBRBJOB.*
of POSNCTL. Inner join of NBRBJOB NBRBJOB POSNCTL. NBRJOBS NBRJOBS on (NBRBJOB. NBRBJOB_PIDM = NBRJOBS. NBRJOBS_PIDM) and (NBRBJOB. NBRBJOB_POSN = NBRJOBS. NBRJOBS_POSN) and (NBRBJOB. NBRBJOB_SUFF = NBRJOBS. NBRJOBS_SUFF)
where NBRJOBS. NBRJOBS_SUFF <>'LS '.
and NBRBJOB. NBRBJOB_CONTRACT_TYPE = 'P '.
and NBRJOBS. NBRJOBS_EFFECTIVE_DATE =
(select Max (NBRJOBS1. NBRJOBS_EFFECTIVE_DATE) as 'EffectDate '.
of POSNCTL. NBRJOBS NBRJOBS1
where NBRJOBS1. NBRJOBS_PIDM = NBRJOBS. NBRJOBS_PIDM
and NBRJOBS1. NBRJOBS_POSN = NBRJOBS. NBRJOBS_POSN
and NBRJOBS1. NBRJOBS_SUFF = NBRJOBS. NBRJOBS_SUFF
and NBRJOBS1. NBRJOBS_SUFF <>'LS '.
and NBRJOBS1. NBRJOBS_EFFECTIVE_DATE < = to_date('2011/11/15','yy/mm/dd'))
order of NBRJOBS. NBRJOBS_PIDMWelcome to the forum!
We don't know what you are trying to do.
You want all of the columns in the rows where NBRJOBS_EFFECTIVE_DATE is the date limit before a given date (November 15, 2011 in this example) for all rows in the result set with this NBRJOBS_PIDM? If so, here is one way:with GOT_R_NUM as ( select NBRJOBS.NBRJOBS.*, NBRBJOB.NBRBJOB.* -- You may have to give aliases, so that every column has a unique name , rank () over ( partition by NBRJOBS.NBRJOBS_PIDM order by NBRJOBS.NBRJOBS_EFFECTIVE_DATE desc ) as R_NUM from POSNCTL.NBRBJOB NBRBJOB inner join POSNCTL.NBRJOBS NBRJOBS on (NBRBJOB.NBRBJOB_PIDM = NBRJOBS.NBRJOBS_PIDM) and (NBRBJOB.NBRBJOB_POSN = NBRJOBS.NBRJOBS_POSN) and (NBRBJOB.NBRBJOB_SUFF = NBRJOBS.NBRJOBS_SUFF) where NBRJOBS.NBRJOBS_SUFF != 'LS' -- Is this what you meant? and NBRBJOB.NBRBJOB_CONTRACT_TYPE ='P' and NBRJOBS.NBRJOBS_EFFECTIVE_DATE <= to_date ('2011/11/15', 'yyyy/mm/dd') ) select * -- Or list all columns except R_NUM from GOT_R_NUM where R_NUM = 1 order by NBRJOBS_PIDM ;Normally this site does not display the <>inequality operator; He thinks it's some kind of beacon.
Whenever you post on this site, use the other inequality operator (equivalent), *! = *.I hope that answers your question.
If not, post a small example of data (CREATE TABLE and INSERT, only relevant columns instructions) for all the tables involved and the results desired from these data.
Explain, using specific examples, how you get these results from these data.
Always tell what version of Oracle you are using.
You will get better results faster if you always include this information whenever you have a problem. -
DB update multiple records in a table with a form
I'm developing an online proofing system that displays a number of images and then allow the client to approve each image, but also to comment.
I currently have a configuration table with the different elements (an image dynamically takes its name, details about the image and the required form fields). See this Image for layout
I would then apply a repeat region (the number of signs vary) and you want to update all records with feedback from the customer and approval with a single form. How this is done? I downloaded a trial of the Toolbox for developers, but the documentation is horrible. I'd be willing to buy an extension that will allow, as appropriate.
I found an extension that does this in two minutes:
http://www.WebAssist.com/Professional/products/ProductDetails.asp?pid=117
Great software, highly recommended. Easy to figure out and got this "problem" solved quickly.
Maybe you are looking for
-
Impossible to scan with Windows 7
I have a HP Photosmart D110 series printer and it is connected to my newer computer operating systems Windows 7. Since I bought this new computer, I have not been able to use the function scanner of the printer. I can still use it on my old system
-
Svchost.exe consumes 90-100% cpu memory
When I start my computer there are 5-6 processes svchost.exe and none of them use 90% above the memory of the cpu. There is that one, IE, idle system process that uses more than 90% cpu. But when I turn off my net by right clicking on the icon in the
-
I know that a restoration of 1.4-> 2.0 database is not supported. However, if we export 1.4 XML mappings, can those imported in 2.0? I could not find any documentation on it. (We note some odd results, and PI 2.0 has been turning it is "Please wait"
-
Microsoft Arc Mouse does not work properly.
Original title: arc mouse problem I have an arc mouse. When I turn on the computer it works, but when everything started the pointer just stops and of course the mouse does not respond. I tried several times to uninstall and then install the drivers